mirror of
https://github.com/AFLplusplus/AFLplusplus.git
synced 2025-06-24 14:43:22 +00:00
Compare commits
254 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 3a4226a28b | |||
| 1a47a5a739 | |||
| 760416c1a0 | |||
| 5955dd4e25 | |||
| e0f9aa3508 | |||
| b31dff6bee | |||
| 1b3f971330 | |||
| abf61ecc8f | |||
| 71bf2d8826 | |||
| 52bfd1fc3d | |||
| a8d96967c4 | |||
| f7a400878a | |||
| e1f18f6212 | |||
| 9705ccee67 | |||
| 7151651ea9 | |||
| 0d7ecd4327 | |||
| 50530c144e | |||
| 45f00e45be | |||
| e969afc627 | |||
| f094908f54 | |||
| f3617bd83b | |||
| 3bfd88aabb | |||
| d47ef88fcd | |||
| b24639d011 | |||
| 2ae4ca91b4 | |||
| e9d968e060 | |||
| 1652831f1d | |||
| 39c4bb7a49 | |||
| 6cb07a9131 | |||
| e76ad2980f | |||
| af5fd8c819 | |||
| 3b3df4e3cb | |||
| c124576a4d | |||
| 659037eef5 | |||
| 500a378fdf | |||
| 4f3c417753 | |||
| 113fc168ab | |||
| 0ba49eacc9 | |||
| bbd9441fc6 | |||
| 22454ce60b | |||
| 5036cb54cc | |||
| 2eeb07d164 | |||
| ca6ac09dcc | |||
| eadd378f6c | |||
| 7b36afd5f1 | |||
| f677427f68 | |||
| 132ad08885 | |||
| d3e173b6e6 | |||
| 3f2a317af0 | |||
| 892513708b | |||
| 733c8e4c34 | |||
| 80f175daac | |||
| c5e0b29a22 | |||
| bec9b307db | |||
| aca63d4986 | |||
| bae398a9a4 | |||
| 0d001c09c3 | |||
| cd259fe118 | |||
| d7b707a71c | |||
| 17228d27e5 | |||
| 10df5ad0ac | |||
| 7338568125 | |||
| 4adca18337 | |||
| b6f5e1635c | |||
| 0e59a59169 | |||
| 6b45deaf97 | |||
| e72d4a96bf | |||
| b79adc01fa | |||
| 790d717543 | |||
| b1ebd62c78 | |||
| fcc349467f | |||
| cc55e5c6d8 | |||
| a51d4227b6 | |||
| 742aed4f2e | |||
| d3d0682310 | |||
| 53012ff41c | |||
| dd734a01dc | |||
| 2053731ebc | |||
| a3b863d312 | |||
| 7cb0658b00 | |||
| 96c76a8333 | |||
| 925cfba424 | |||
| f63318a20f | |||
| f5d4912ca8 | |||
| 642cf8b5ff | |||
| 0612aa2b65 | |||
| 3937764ac5 | |||
| ed603dcba2 | |||
| 41d2e7d6b6 | |||
| 73d02f3a80 | |||
| e1183be22e | |||
| 2971b5b315 | |||
| 65a3a9773d | |||
| 8b6a4e5759 | |||
| 07df1e3034 | |||
| 09c95b7ea7 | |||
| a6fe8ae0af | |||
| dc2c46e23c | |||
| 0f476a289f | |||
| ae3f058ff0 | |||
| 1315021388 | |||
| ccb231e4f4 | |||
| aad485128e | |||
| 54bb9f4b55 | |||
| af823d6486 | |||
| 487a87df02 | |||
| b14fead592 | |||
| ebf2c8caa5 | |||
| 84855737b3 | |||
| 7a608d1346 | |||
| 3e418ecb6e | |||
| 89769c836f | |||
| 7c8470b1dc | |||
| 81bab528b2 | |||
| d6beac5235 | |||
| a949b40d11 | |||
| 7ca22cd552 | |||
| 30586e634d | |||
| 2b6fe347ae | |||
| f97409dd2d | |||
| c384367f17 | |||
| eea1c6606c | |||
| 8f4f45c524 | |||
| db2392b778 | |||
| ce842648ae | |||
| ad1c4bf202 | |||
| 5969b7cdbc | |||
| 6013d20aef | |||
| dfb3bd8e33 | |||
| d6c2db9620 | |||
| 00dc8a0ad5 | |||
| 9246f21f2a | |||
| 2237319ebb | |||
| 6fa95008bc | |||
| 3789a56225 | |||
| 0a2d9af2a1 | |||
| 2b7a627181 | |||
| f697752b52 | |||
| 914426d887 | |||
| 302e717790 | |||
| 27928fbc94 | |||
| 253056b932 | |||
| 1d1d0d9b6f | |||
| c7887abb64 | |||
| 47525f0dd6 | |||
| 5ac5d91c6b | |||
| 322b5a736b | |||
| 907c054142 | |||
| 7b6d51a9d0 | |||
| d3eba93c7d | |||
| 866e22355c | |||
| fe084b9866 | |||
| 5f7e3025d9 | |||
| 13b8bc1a89 | |||
| 054cec8a5d | |||
| 8dc326e1f1 | |||
| 81dd1aea82 | |||
| 5b2cb426be | |||
| 5fa19f2801 | |||
| 4f5acb8f52 | |||
| cf71c53559 | |||
| 80c98f4d0c | |||
| 73f8ab3aa8 | |||
| da372335bf | |||
| 0af9f664db | |||
| 995eb0cd79 | |||
| 9f07965876 | |||
| 8a4cdd56d4 | |||
| 3252523823 | |||
| 2628f9f61b | |||
| 0d217e15d5 | |||
| 520c85c7b7 | |||
| 82d70e0720 | |||
| 054976c390 | |||
| da8e03e18a | |||
| 4a80dbdd10 | |||
| 013a1731d5 | |||
| e664024853 | |||
| 495f3b9a68 | |||
| 98a6963911 | |||
| c204efaaab | |||
| 0f13137616 | |||
| 864056fcaa | |||
| 5c0830f628 | |||
| e96a2dd681 | |||
| f45332e1ab | |||
| 5508e30854 | |||
| 3e14d63a0a | |||
| eddfddccb2 | |||
| c067ef0216 | |||
| f7d9019b8c | |||
| 519678192f | |||
| c3083a77d4 | |||
| 891ab3951b | |||
| 11251c77ca | |||
| 71e22d9263 | |||
| 3095d96715 | |||
| 198946231c | |||
| b2f0b6f2b4 | |||
| d9c70c7b8c | |||
| 7ae61e7393 | |||
| 984ae35948 | |||
| 0d6cddda4d | |||
| 18e031d346 | |||
| c0332ad98b | |||
| 7f6aaa5314 | |||
| 14aa5fe521 | |||
| 9199967022 | |||
| 04c92c8470 | |||
| 00b22e37df | |||
| aaa810c64a | |||
| b57b2073ac | |||
| 771a9e9cd2 | |||
| cc48f4499a | |||
| 3e2f2ddb56 | |||
| 0ca6df6f09 | |||
| 37a379f959 | |||
| 625d6c2ed7 | |||
| c2edb3e22f | |||
| fedbd54325 | |||
| 134d2bd766 | |||
| 9eb2cd7327 | |||
| c0347c80b2 | |||
| d9ff84e39e | |||
| 7256e6d203 | |||
| c083fd895c | |||
| 0cd7a3d216 | |||
| aa4fc44a80 | |||
| f07d49e877 | |||
| 45be91ff48 | |||
| c657b3d072 | |||
| 5dfb3ded17 | |||
| 0104e99caa | |||
| e16593c9b1 | |||
| 1cc69df0f4 | |||
| 2db576f52b | |||
| 421edce623 | |||
| 549b83504f | |||
| d10ebd1a68 | |||
| 4e3d921f1a | |||
| 1d6e1ec61c | |||
| db3cc11195 | |||
| d64efa6a68 | |||
| 7b5905bda6 | |||
| f5ba5ffe80 | |||
| 0113c4f834 | |||
| 1c2ed83960 | |||
| 7a236b11b8 | |||
| a0328bbcf8 | |||
| 46e58b434a | |||
| 7955f8a7cb | |||
| 263fd37590 | |||
| ba37bf13d6 | |||
| b59d71546b |
148
.clang-format
Normal file
148
.clang-format
Normal file
@ -0,0 +1,148 @@
|
||||
---
|
||||
Language: Cpp
|
||||
# BasedOnStyle: Google
|
||||
AccessModifierOffset: -1
|
||||
AlignAfterOpenBracket: Align
|
||||
AlignConsecutiveAssignments: false
|
||||
AlignConsecutiveDeclarations: true
|
||||
AlignEscapedNewlines: Left
|
||||
AlignOperands: true
|
||||
AlignTrailingComments: true
|
||||
AllowAllParametersOfDeclarationOnNextLine: true
|
||||
AllowShortBlocksOnASingleLine: true
|
||||
AllowShortCaseLabelsOnASingleLine: true
|
||||
AllowShortFunctionsOnASingleLine: false
|
||||
AllowShortIfStatementsOnASingleLine: true
|
||||
AllowShortLoopsOnASingleLine: false
|
||||
AlwaysBreakAfterDefinitionReturnType: None
|
||||
AlwaysBreakAfterReturnType: None
|
||||
AlwaysBreakBeforeMultilineStrings: true
|
||||
AlwaysBreakTemplateDeclarations: Yes
|
||||
BinPackArguments: true
|
||||
BinPackParameters: true
|
||||
BraceWrapping:
|
||||
AfterClass: false
|
||||
AfterControlStatement: false
|
||||
AfterEnum: false
|
||||
AfterFunction: false
|
||||
AfterNamespace: false
|
||||
AfterObjCDeclaration: false
|
||||
AfterStruct: false
|
||||
AfterUnion: false
|
||||
AfterExternBlock: false
|
||||
BeforeCatch: false
|
||||
BeforeElse: false
|
||||
IndentBraces: false
|
||||
SplitEmptyFunction: true
|
||||
SplitEmptyRecord: true
|
||||
SplitEmptyNamespace: true
|
||||
BreakBeforeBinaryOperators: None
|
||||
BreakBeforeBraces: Attach
|
||||
BreakBeforeInheritanceComma: false
|
||||
BreakInheritanceList: BeforeColon
|
||||
BreakBeforeTernaryOperators: true
|
||||
BreakConstructorInitializersBeforeComma: false
|
||||
BreakConstructorInitializers: BeforeColon
|
||||
BreakAfterJavaFieldAnnotations: false
|
||||
BreakStringLiterals: true
|
||||
ColumnLimit: 80
|
||||
CommentPragmas: '^ IWYU pragma:'
|
||||
CompactNamespaces: false
|
||||
ConstructorInitializerAllOnOneLineOrOnePerLine: true
|
||||
ConstructorInitializerIndentWidth: 4
|
||||
ContinuationIndentWidth: 4
|
||||
Cpp11BracedListStyle: true
|
||||
DerivePointerAlignment: true
|
||||
DisableFormat: false
|
||||
ExperimentalAutoDetectBinPacking: false
|
||||
FixNamespaceComments: true
|
||||
ForEachMacros:
|
||||
- foreach
|
||||
- Q_FOREACH
|
||||
- BOOST_FOREACH
|
||||
IncludeBlocks: Preserve
|
||||
IncludeCategories:
|
||||
- Regex: '^<ext/.*\.h>'
|
||||
Priority: 2
|
||||
- Regex: '^<.*\.h>'
|
||||
Priority: 1
|
||||
- Regex: '^<.*'
|
||||
Priority: 2
|
||||
- Regex: '.*'
|
||||
Priority: 3
|
||||
IncludeIsMainRegex: '([-_](test|unittest))?$'
|
||||
IndentCaseLabels: true
|
||||
IndentPPDirectives: None
|
||||
IndentWidth: 2
|
||||
IndentWrappedFunctionNames: false
|
||||
JavaScriptQuotes: Leave
|
||||
JavaScriptWrapImports: true
|
||||
KeepEmptyLinesAtTheStartOfBlocks: false
|
||||
MacroBlockBegin: ''
|
||||
MacroBlockEnd: ''
|
||||
MaxEmptyLinesToKeep: 1
|
||||
NamespaceIndentation: None
|
||||
ObjCBinPackProtocolList: Never
|
||||
ObjCBlockIndentWidth: 2
|
||||
ObjCSpaceAfterProperty: false
|
||||
ObjCSpaceBeforeProtocolList: true
|
||||
PenaltyBreakAssignment: 2
|
||||
PenaltyBreakBeforeFirstCallParameter: 1
|
||||
PenaltyBreakComment: 300
|
||||
PenaltyBreakFirstLessLess: 120
|
||||
PenaltyBreakString: 1000
|
||||
PenaltyBreakTemplateDeclaration: 10
|
||||
PenaltyExcessCharacter: 1000000
|
||||
PenaltyReturnTypeOnItsOwnLine: 200
|
||||
PointerAlignment: Right
|
||||
RawStringFormats:
|
||||
- Language: Cpp
|
||||
Delimiters:
|
||||
- cc
|
||||
- CC
|
||||
- cpp
|
||||
- Cpp
|
||||
- CPP
|
||||
- 'c++'
|
||||
- 'C++'
|
||||
CanonicalDelimiter: ''
|
||||
BasedOnStyle: google
|
||||
- Language: TextProto
|
||||
Delimiters:
|
||||
- pb
|
||||
- PB
|
||||
- proto
|
||||
- PROTO
|
||||
EnclosingFunctions:
|
||||
- EqualsProto
|
||||
- EquivToProto
|
||||
- PARSE_PARTIAL_TEXT_PROTO
|
||||
- PARSE_TEST_PROTO
|
||||
- PARSE_TEXT_PROTO
|
||||
- ParseTextOrDie
|
||||
- ParseTextProtoOrDie
|
||||
CanonicalDelimiter: ''
|
||||
BasedOnStyle: google
|
||||
ReflowComments: true
|
||||
SortIncludes: false
|
||||
SortUsingDeclarations: true
|
||||
SpaceAfterCStyleCast: false
|
||||
SpaceAfterTemplateKeyword: true
|
||||
SpaceBeforeAssignmentOperators: true
|
||||
SpaceBeforeCpp11BracedList: false
|
||||
SpaceBeforeCtorInitializerColon: true
|
||||
SpaceBeforeInheritanceColon: true
|
||||
SpaceBeforeParens: ControlStatements
|
||||
SpaceBeforeRangeBasedForLoopColon: true
|
||||
SpaceInEmptyParentheses: false
|
||||
SpacesBeforeTrailingComments: 2
|
||||
SpacesInAngles: false
|
||||
SpacesInContainerLiterals: true
|
||||
SpacesInCStyleCastParentheses: false
|
||||
SpacesInParentheses: false
|
||||
SpacesInSquareBrackets: false
|
||||
Standard: Auto
|
||||
TabWidth: 8
|
||||
UseTab: Never
|
||||
...
|
||||
|
||||
102
.custom-format.py
Executable file
102
.custom-format.py
Executable file
@ -0,0 +1,102 @@
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import subprocess
|
||||
import sys
|
||||
import os
|
||||
import re
|
||||
|
||||
# string_re = re.compile('(\\"(\\\\.|[^"\\\\])*\\")') # future use
|
||||
|
||||
with open(".clang-format") as f:
|
||||
fmt = f.read()
|
||||
|
||||
CLANG_FORMAT_BIN = os.getenv("CLANG_FORMAT_BIN")
|
||||
if CLANG_FORMAT_BIN is None:
|
||||
p = subprocess.Popen(["clang-format", "--version"], stdout=subprocess.PIPE)
|
||||
o, _ = p.communicate()
|
||||
o = str(o, "utf-8")
|
||||
o = o[len("clang-format version "):].strip()
|
||||
o = o[:o.find(".")]
|
||||
o = int(o)
|
||||
if o < 7:
|
||||
if subprocess.call(['which', 'clang-format-7'], stdout=subprocess.PIPE) == 0:
|
||||
CLANG_FORMAT_BIN = 'clang-format-7'
|
||||
elif subprocess.call(['which', 'clang-format-8'], stdout=subprocess.PIPE) == 0:
|
||||
CLANG_FORMAT_BIN = 'clang-format-8'
|
||||
elif subprocess.call(['which', 'clang-format-9'], stdout=subprocess.PIPE) == 0:
|
||||
CLANG_FORMAT_BIN = 'clang-format-9'
|
||||
elif subprocess.call(['which', 'clang-format-10'], stdout=subprocess.PIPE) == 0:
|
||||
CLANG_FORMAT_BIN = 'clang-format-10'
|
||||
else:
|
||||
print ("clang-format 7 or above is needed. Aborted.")
|
||||
exit(1)
|
||||
else:
|
||||
CLANG_FORMAT_BIN = 'clang-format'
|
||||
|
||||
COLUMN_LIMIT = 80
|
||||
for line in fmt.split("\n"):
|
||||
line = line.split(":")
|
||||
if line[0].strip() == "ColumnLimit":
|
||||
COLUMN_LIMIT = int(line[1].strip())
|
||||
|
||||
|
||||
def custom_format(filename):
|
||||
p = subprocess.Popen([CLANG_FORMAT_BIN, filename], stdout=subprocess.PIPE)
|
||||
src, _ = p.communicate()
|
||||
src = str(src, "utf-8")
|
||||
|
||||
in_define = False
|
||||
last_line = None
|
||||
out = ""
|
||||
|
||||
for line in src.split("\n"):
|
||||
if line.startswith("#"):
|
||||
if line.startswith("#define"):
|
||||
in_define = True
|
||||
|
||||
if "/*" in line and not line.strip().startswith("/*") and line.endswith("*/") and len(line) < (COLUMN_LIMIT-2):
|
||||
cmt_start = line.rfind("/*")
|
||||
line = line[:cmt_start] + " " * (COLUMN_LIMIT-2 - len(line)) + line[cmt_start:]
|
||||
|
||||
define_padding = 0
|
||||
if last_line is not None and in_define and last_line.endswith("\\"):
|
||||
last_line = last_line[:-1]
|
||||
define_padding = max(0, len(last_line[last_line.rfind("\n")+1:]))
|
||||
|
||||
if last_line is not None and last_line.strip().endswith("{") and line.strip() != "":
|
||||
line = (" " * define_padding + "\\" if in_define else "") + "\n" + line
|
||||
elif last_line is not None and last_line.strip().startswith("}") and line.strip() != "":
|
||||
line = (" " * define_padding + "\\" if in_define else "") + "\n" + line
|
||||
elif line.strip().startswith("}") and last_line is not None and last_line.strip() != "":
|
||||
line = (" " * define_padding + "\\" if in_define else "") + "\n" + line
|
||||
|
||||
if not line.endswith("\\"):
|
||||
in_define = False
|
||||
|
||||
out += line + "\n"
|
||||
last_line = line
|
||||
|
||||
return (out)
|
||||
|
||||
args = sys.argv[1:]
|
||||
if len(args) == 0:
|
||||
print ("Usage: ./format.py [-i] <filename>")
|
||||
print ()
|
||||
print (" The -i option, if specified, let the script to modify in-place")
|
||||
print (" the source files. By default the results are written to stdout.")
|
||||
print()
|
||||
exit(1)
|
||||
|
||||
in_place = False
|
||||
if args[0] == "-i":
|
||||
in_place = True
|
||||
args = args[1:]
|
||||
|
||||
for filename in args:
|
||||
code = custom_format(filename)
|
||||
if in_place:
|
||||
with open(filename, "w") as f:
|
||||
f.write(code)
|
||||
else:
|
||||
print(code)
|
||||
|
||||
23
.gitignore
vendored
Normal file
23
.gitignore
vendored
Normal file
@ -0,0 +1,23 @@
|
||||
*.o
|
||||
*.so
|
||||
afl-analyze
|
||||
afl-as
|
||||
afl-clang
|
||||
afl-clang++
|
||||
afl-clang-fast
|
||||
afl-clang-fast++
|
||||
afl-fuzz
|
||||
afl-g++
|
||||
afl-gcc
|
||||
afl-gcc-fast
|
||||
afl-g++-fast
|
||||
afl-gotcpu
|
||||
afl-qemu-trace
|
||||
afl-showmap
|
||||
afl-tmin
|
||||
as
|
||||
qemu_mode/qemu-3.1.0
|
||||
qemu_mode/qemu-3.1.0.tar.xz
|
||||
unicorn_mode/unicorn
|
||||
unicorn_mode/unicorn-*
|
||||
unicorn_mode/*.tar.gz
|
||||
11
.travis.yml
Normal file
11
.travis.yml
Normal file
@ -0,0 +1,11 @@
|
||||
language: c
|
||||
|
||||
env:
|
||||
- AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=1 AFL_NO_UI=1
|
||||
|
||||
script:
|
||||
- make
|
||||
- ./afl-gcc ./test-instr.c -o test-instr
|
||||
- mkdir seeds; mkdir out
|
||||
- echo "" > seeds/nil_seed
|
||||
- timeout --preserve-status 5s ./afl-fuzz -i seeds -o out/ -- ./test-instr
|
||||
1
Android.mk
Symbolic link
1
Android.mk
Symbolic link
@ -0,0 +1 @@
|
||||
Makefile
|
||||
14
CONTRIBUTING.md
Normal file
14
CONTRIBUTING.md
Normal file
@ -0,0 +1,14 @@
|
||||
# How to submit a Pull Request to AFLplusplus
|
||||
|
||||
Each modified source file, before merging, must be formatted.
|
||||
|
||||
```
|
||||
make code-formatter
|
||||
```
|
||||
|
||||
This should be fine if you modified one of the file already present in the
|
||||
project, otherwise run:
|
||||
|
||||
```
|
||||
./.custom-format.py -i file-that-you-have-created.c
|
||||
```
|
||||
211
Makefile
211
Makefile
@ -13,24 +13,33 @@
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
|
||||
# For Heiko:
|
||||
#TEST_MMAP=1
|
||||
|
||||
PROGNAME = afl
|
||||
VERSION = $(shell grep '^\#define VERSION ' config.h | cut -d '"' -f2)
|
||||
VERSION = $(shell grep '^\#define VERSION ' include/config.h | cut -d '"' -f2)
|
||||
|
||||
PREFIX ?= /usr/local
|
||||
BIN_PATH = $(PREFIX)/bin
|
||||
HELPER_PATH = $(PREFIX)/lib/afl
|
||||
DOC_PATH = $(PREFIX)/share/doc/afl
|
||||
MISC_PATH = $(PREFIX)/share/afl
|
||||
MAN_PATH = $(PREFIX)/man/man8
|
||||
|
||||
# PROGS intentionally omit afl-as, which gets installed elsewhere.
|
||||
|
||||
PROGS = afl-gcc afl-fuzz afl-showmap afl-tmin afl-gotcpu afl-analyze
|
||||
SH_PROGS = afl-plot afl-cmin afl-whatsup afl-system-config
|
||||
MANPAGES=$(foreach p, $(PROGS) $(SH_PROGS), $(p).8)
|
||||
|
||||
CFLAGS ?= -O3 -funroll-loops
|
||||
CFLAGS += -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign \
|
||||
CFLAGS += -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -I include/ \
|
||||
-DAFL_PATH=\"$(HELPER_PATH)\" -DDOC_PATH=\"$(DOC_PATH)\" \
|
||||
-DBIN_PATH=\"$(BIN_PATH)\"
|
||||
-DBIN_PATH=\"$(BIN_PATH)\" -Wno-unused-function
|
||||
|
||||
AFL_FUZZ_FILES = $(wildcard src/afl-fuzz*.c)
|
||||
|
||||
PYTHON_INCLUDE ?= /usr/include/python2.7
|
||||
|
||||
ifneq "$(filter Linux GNU%,$(shell uname))" ""
|
||||
LDFLAGS += -ldl
|
||||
@ -42,17 +51,42 @@ else
|
||||
TEST_CC = afl-clang
|
||||
endif
|
||||
|
||||
COMM_HDR = alloc-inl.h config.h debug.h types.h
|
||||
COMM_HDR = include/alloc-inl.h include/config.h include/debug.h include/types.h
|
||||
|
||||
|
||||
ifeq "$(shell echo '\#include <Python.h>@int main() {return 0; }' | tr @ '\n' | $(CC) -x c - -o .test -I$(PYTHON_INCLUDE) -lpython2.7 2>/dev/null && echo 1 || echo 0 )" "1"
|
||||
PYTHON_OK=1
|
||||
PYFLAGS=-DUSE_PYTHON -I$(PYTHON_INCLUDE) -lpython2.7
|
||||
else
|
||||
PYTHON_OK=0
|
||||
PYFLAGS=
|
||||
endif
|
||||
|
||||
|
||||
ifeq "$(shell echo '\#include <sys/ipc.h>@\#include <sys/shm.h>@int main() { int _id = shmget(IPC_PRIVATE, 65536, IPC_CREAT | IPC_EXCL | 0600); shmctl(_id, IPC_RMID, 0); return 0;}' | tr @ '\n' | $(CC) -x c - -o .test2 2>/dev/null && echo 1 || echo 0 )" "1"
|
||||
SHMAT_OK=1
|
||||
else
|
||||
SHMAT_OK=0
|
||||
CFLAGS+=-DUSEMMAP=1
|
||||
LDFLAGS+=-Wno-deprecated-declarations -lrt
|
||||
endif
|
||||
|
||||
ifeq "$(TEST_MMAP)" "1"
|
||||
SHMAT_OK=0
|
||||
CFLAGS+=-DUSEMMAP=1
|
||||
LDFLAGS+=-Wno-deprecated-declarations -lrt
|
||||
endif
|
||||
|
||||
|
||||
all: test_x86 test_shm test_python27 ready $(PROGS) afl-as test_build all_done
|
||||
|
||||
all: test_x86 $(PROGS) afl-as test_build all_done
|
||||
|
||||
ifndef AFL_NO_X86
|
||||
|
||||
test_x86:
|
||||
@echo "[*] Checking for the ability to compile x86 code..."
|
||||
@echo 'main() { __asm__("xorb %al, %al"); }' | $(CC) -w -x c - -o .test || ( echo; echo "Oops, looks like your compiler can't generate x86 code."; echo; echo "Don't panic! You can use the LLVM or QEMU mode, but see docs/INSTALL first."; echo "(To ignore this error, set AFL_NO_X86=1 and try again.)"; echo; exit 1 )
|
||||
@rm -f .test
|
||||
@echo "[+] Everything seems to be working, ready to compile."
|
||||
@echo 'main() { __asm__("xorb %al, %al"); }' | $(CC) -w -x c - -o .test1 || ( echo; echo "Oops, looks like your compiler can't generate x86 code."; echo; echo "Don't panic! You can use the LLVM or QEMU mode, but see docs/INSTALL first."; echo "(To ignore this error, set AFL_NO_X86=1 and try again.)"; echo; exit 1 )
|
||||
@rm -f .test1
|
||||
|
||||
else
|
||||
|
||||
@ -61,38 +95,97 @@ test_x86:
|
||||
|
||||
endif
|
||||
|
||||
afl-gcc: afl-gcc.c $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $@.c -o $@ $(LDFLAGS)
|
||||
|
||||
ifeq "$(SHMAT_OK)" "1"
|
||||
|
||||
test_shm:
|
||||
@echo "[+] shmat seems to be working."
|
||||
@rm -f .test2
|
||||
|
||||
else
|
||||
|
||||
test_shm:
|
||||
@echo "[-] shmat seems not to be working, switching to mmap implementation"
|
||||
|
||||
endif
|
||||
|
||||
|
||||
ifeq "$(PYTHON_OK)" "1"
|
||||
|
||||
test_python27:
|
||||
@rm -f .test 2> /dev/null
|
||||
@echo "[+] Python 2.7 support seems to be working."
|
||||
|
||||
else
|
||||
|
||||
test_python27:
|
||||
@echo "[-] You seem to need to install the package python2.7-dev, but it is optional so we continue"
|
||||
|
||||
endif
|
||||
|
||||
|
||||
ready:
|
||||
@echo "[+] Everything seems to be working, ready to compile."
|
||||
|
||||
afl-gcc: src/afl-gcc.c $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) src/$@.c -o $@ $(LDFLAGS)
|
||||
set -e; for i in afl-g++ afl-clang afl-clang++; do ln -sf afl-gcc $$i; done
|
||||
|
||||
afl-as: afl-as.c afl-as.h $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $@.c -o $@ $(LDFLAGS)
|
||||
afl-as: src/afl-as.c include/afl-as.h $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) src/$@.c -o $@ $(LDFLAGS)
|
||||
ln -sf afl-as as
|
||||
|
||||
afl-fuzz: afl-fuzz.c $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $@.c -o $@ $(LDFLAGS)
|
||||
afl-common.o : src/afl-common.c include/common.h
|
||||
$(CC) $(CFLAGS) -c src/afl-common.c
|
||||
|
||||
afl-showmap: afl-showmap.c $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $@.c -o $@ $(LDFLAGS)
|
||||
afl-forkserver.o : src/afl-forkserver.c include/forkserver.h
|
||||
$(CC) $(CFLAGS) -c src/afl-forkserver.c
|
||||
|
||||
afl-tmin: afl-tmin.c $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $@.c -o $@ $(LDFLAGS)
|
||||
afl-sharedmem.o : src/afl-sharedmem.c include/sharedmem.h
|
||||
$(CC) $(CFLAGS) -c src/afl-sharedmem.c
|
||||
|
||||
afl-analyze: afl-analyze.c $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $@.c -o $@ $(LDFLAGS)
|
||||
afl-fuzz: include/afl-fuzz.h $(AFL_FUZZ_FILES) afl-common.o afl-sharedmem.o afl-forkserver.o $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $(AFL_FUZZ_FILES) afl-common.o afl-sharedmem.o afl-forkserver.o -o $@ $(LDFLAGS) $(PYFLAGS)
|
||||
|
||||
afl-showmap: src/afl-showmap.c afl-common.o afl-sharedmem.o $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) src/$@.c afl-common.o afl-sharedmem.o -o $@ $(LDFLAGS)
|
||||
|
||||
afl-tmin: src/afl-tmin.c afl-common.o afl-sharedmem.o afl-forkserver.o $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) src/$@.c afl-common.o afl-sharedmem.o afl-forkserver.o -o $@ $(LDFLAGS)
|
||||
|
||||
afl-analyze: src/afl-analyze.c afl-common.o afl-sharedmem.o $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) src/$@.c afl-common.o afl-sharedmem.o -o $@ $(LDFLAGS)
|
||||
|
||||
afl-gotcpu: src/afl-gotcpu.c $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) src/$@.c -o $@ $(LDFLAGS)
|
||||
|
||||
|
||||
code-format:
|
||||
./.custom-format.py -i src/*.c
|
||||
./.custom-format.py -i include/*.h
|
||||
./.custom-format.py -i libdislocator/*.c
|
||||
./.custom-format.py -i libtokencap/*.c
|
||||
./.custom-format.py -i llvm_mode/*.c
|
||||
./.custom-format.py -i llvm_mode/*.h
|
||||
./.custom-format.py -i llvm_mode/*.cc
|
||||
./.custom-format.py -i qemu_mode/patches/*.h
|
||||
./.custom-format.py -i qemu_mode/libcompcov/*.c
|
||||
./.custom-format.py -i qemu_mode/libcompcov/*.cc
|
||||
./.custom-format.py -i qemu_mode/libcompcov/*.h
|
||||
./.custom-format.py -i unicorn_mode/patches/*.h
|
||||
./.custom-format.py -i *.h
|
||||
./.custom-format.py -i *.c
|
||||
|
||||
afl-gotcpu: afl-gotcpu.c $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $@.c -o $@ $(LDFLAGS)
|
||||
|
||||
ifndef AFL_NO_X86
|
||||
|
||||
test_build: afl-gcc afl-as afl-showmap
|
||||
@echo "[*] Testing the CC wrapper and instrumentation output..."
|
||||
unset AFL_USE_ASAN AFL_USE_MSAN; AFL_QUIET=1 AFL_INST_RATIO=100 AFL_PATH=. ./$(TEST_CC) $(CFLAGS) test-instr.c -o test-instr $(LDFLAGS)
|
||||
echo 0 | ./afl-showmap -m none -q -o .test-instr0 ./test-instr
|
||||
unset AFL_USE_ASAN AFL_USE_MSAN AFL_CC; AFL_QUIET=1 AFL_INST_RATIO=100 AFL_PATH=. ./$(TEST_CC) $(CFLAGS) test-instr.c -o test-instr $(LDFLAGS)
|
||||
./afl-showmap -m none -q -o .test-instr0 ./test-instr < /dev/null
|
||||
echo 1 | ./afl-showmap -m none -q -o .test-instr1 ./test-instr
|
||||
@rm -f test-instr
|
||||
@cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation does not seem to be behaving correctly!"; echo; echo "Please ping <lcamtuf@google.com> to troubleshoot the issue."; echo; exit 1; fi
|
||||
@cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation does not seem to be behaving correctly!"; echo; echo "Please post to https://github.com/vanhauser-thc/AFLplusplus/issues to troubleshoot the issue."; echo; exit 1; fi
|
||||
@echo "[+] All right, the instrumentation seems to be working!"
|
||||
|
||||
else
|
||||
@ -102,29 +195,51 @@ test_build: afl-gcc afl-as afl-showmap
|
||||
|
||||
endif
|
||||
|
||||
|
||||
all_done: test_build
|
||||
@if [ ! "`which clang 2>/dev/null`" = "" ]; then echo "[+] LLVM users: see llvm_mode/README.llvm for a faster alternative to afl-gcc."; fi
|
||||
@echo "[+] All done! Be sure to review README - it's pretty short and useful."
|
||||
@echo "[+] All done! Be sure to review the README.md - it's pretty short and useful."
|
||||
@if [ "`uname`" = "Darwin" ]; then printf "\nWARNING: Fuzzing on MacOS X is slow because of the unusually high overhead of\nfork() on this OS. Consider using Linux or *BSD. You can also use VirtualBox\n(virtualbox.org) to put AFL inside a Linux or *BSD VM.\n\n"; fi
|
||||
@! tty <&1 >/dev/null || printf "\033[0;30mNOTE: If you can read this, your terminal probably uses white background.\nThis will make the UI hard to read. See docs/status_screen.txt for advice.\033[0m\n" 2>/dev/null
|
||||
|
||||
.NOTPARALLEL: clean
|
||||
|
||||
clean:
|
||||
rm -f $(PROGS) afl-as as afl-g++ afl-clang afl-clang++ *.o *~ a.out core core.[1-9][0-9]* *.stackdump test .test test-instr .test-instr0 .test-instr1 qemu_mode/qemu-2.10.0.tar.bz2 afl-qemu-trace
|
||||
rm -rf out_dir qemu_mode/qemu-2.10.0
|
||||
rm -f $(PROGS) afl-as as afl-g++ afl-clang afl-clang++ *.o *~ a.out core core.[1-9][0-9]* *.stackdump test .test .test1 .test2 test-instr .test-instr0 .test-instr1 qemu_mode/qemu-3.1.0.tar.xz afl-qemu-trace afl-gcc-fast afl-gcc-pass.so afl-gcc-rt.o afl-g++-fast *.so unicorn_mode/24f55a7973278f20f0de21b904851d99d4716263.tar.gz *.8
|
||||
rm -rf out_dir qemu_mode/qemu-3.1.0 unicorn_mode/unicorn
|
||||
$(MAKE) -C llvm_mode clean
|
||||
$(MAKE) -C libdislocator clean
|
||||
$(MAKE) -C libtokencap clean
|
||||
$(MAKE) -C qemu_mode/libcompcov clean
|
||||
|
||||
install: all
|
||||
%.8: %
|
||||
@echo .TH $* 8 `date --iso-8601` "afl++" > $@
|
||||
@echo .SH NAME >> $@
|
||||
@echo .B $* >> $@
|
||||
@echo >> $@
|
||||
@echo .SH SYNOPSIS >> $@
|
||||
@./$* -h 2>&1 | head -n 3 | tail -n 1 | sed 's/^\.\///' >> $@
|
||||
@echo >> $@
|
||||
@echo .SH OPTIONS >> $@
|
||||
@echo .nf >> $@
|
||||
@./$* -h 2>&1 | tail -n +4 >> $@
|
||||
@echo >> $@
|
||||
@echo .SH AUTHOR >> $@
|
||||
@echo "afl++ was written by Michal \"lcamtuf\" Zalewski and is maintained by Marc \"van Hauser\" Heuse <mh@mh-sec.de>, Heiko \"hexc0der\" Eissfeldt <heiko.eissfeldt@hexco.de> and Andrea Fioraldi <andreafioraldi@gmail.com>" >> $@
|
||||
@echo The homepage of afl++ is: https://github.com/vanhauser-thc/AFLplusplus >> $@
|
||||
@echo >> $@
|
||||
@echo .SH LICENSE >> $@
|
||||
@echo Apache License Version 2.0, January 2004 >> $@
|
||||
|
||||
install: all $(MANPAGES)
|
||||
mkdir -p -m 755 $${DESTDIR}$(BIN_PATH) $${DESTDIR}$(HELPER_PATH) $${DESTDIR}$(DOC_PATH) $${DESTDIR}$(MISC_PATH)
|
||||
rm -f $${DESTDIR}$(BIN_PATH)/afl-plot.sh
|
||||
install -m 755 $(PROGS) $(SH_PROGS) $${DESTDIR}$(BIN_PATH)
|
||||
rm -f $${DESTDIR}$(BIN_PATH)/afl-as
|
||||
if [ -f afl-qemu-trace ]; then install -m 755 afl-qemu-trace $${DESTDIR}$(BIN_PATH); fi
|
||||
#if [ -f afl-gcc-fast ]; then set e; install -m 755 afl-gcc-fast $${DESTDIR}$(BIN_PATH); ln -sf afl-gcc-fast $${DESTDIR}$(BIN_PATH)/afl-g++-fast; install -m 755 afl-gcc-pass.so afl-gcc-rt.o $${DESTDIR}$(HELPER_PATH); fi
|
||||
ifndef AFL_TRACE_PC
|
||||
if [ -f afl-clang-fast -a -f afl-llvm-pass.so -a -f afl-llvm-rt.o ]; then set -e; install -m 755 afl-clang-fast $${DESTDIR}$(BIN_PATH); ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang-fast++; install -m 755 afl-llvm-pass.so afl-llvm-rt.o $${DESTDIR}$(HELPER_PATH); fi
|
||||
if [ -f afl-clang-fast -a -f libLLVMInsTrim.so -a -f afl-llvm-rt.o ]; then set -e; install -m 755 afl-clang-fast $${DESTDIR}$(BIN_PATH); ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang-fast++; install -m 755 libLLVMInsTrim.so afl-llvm-pass.so afl-llvm-rt.o $${DESTDIR}$(HELPER_PATH); fi
|
||||
else
|
||||
if [ -f afl-clang-fast -a -f afl-llvm-rt.o ]; then set -e; install -m 755 afl-clang-fast $${DESTDIR}$(BIN_PATH); ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang-fast++; install -m 755 afl-llvm-rt.o $${DESTDIR}$(HELPER_PATH); fi
|
||||
endif
|
||||
@ -133,25 +248,31 @@ endif
|
||||
if [ -f compare-transform-pass.so ]; then set -e; install -m 755 compare-transform-pass.so $${DESTDIR}$(HELPER_PATH); fi
|
||||
if [ -f split-compares-pass.so ]; then set -e; install -m 755 split-compares-pass.so $${DESTDIR}$(HELPER_PATH); fi
|
||||
if [ -f split-switches-pass.so ]; then set -e; install -m 755 split-switches-pass.so $${DESTDIR}$(HELPER_PATH); fi
|
||||
if [ -f libcompcov.so ]; then set -e; install -m 755 libcompcov.so $${DESTDIR}$(HELPER_PATH); fi
|
||||
|
||||
set -e; ln -sf afl-gcc $${DESTDIR}$(BIN_PATH)/afl-g++
|
||||
set -e; if [ -f afl-clang-fast ] ; then ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang ; ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang++ ; else ln -sf afl-gcc $${DESTDIR}$(BIN_PATH)/afl-clang ; ln -sf afl-gcc $${DESTDIR}$(BIN_PATH)/afl-clang++; fi
|
||||
|
||||
mkdir -m 0755 -p $(MAN_PATH)
|
||||
install -m0644 -D *.8 $(MAN_PATH)
|
||||
|
||||
set -e; for i in afl-g++ afl-clang afl-clang++; do ln -sf afl-gcc $${DESTDIR}$(BIN_PATH)/$$i; done
|
||||
install -m 755 afl-as $${DESTDIR}$(HELPER_PATH)
|
||||
ln -sf afl-as $${DESTDIR}$(HELPER_PATH)/as
|
||||
install -m 644 docs/README docs/ChangeLog docs/*.txt $${DESTDIR}$(DOC_PATH)
|
||||
install -m 644 docs/README.md docs/ChangeLog docs/*.txt $${DESTDIR}$(DOC_PATH)
|
||||
cp -r testcases/ $${DESTDIR}$(MISC_PATH)
|
||||
cp -r dictionaries/ $${DESTDIR}$(MISC_PATH)
|
||||
|
||||
publish: clean
|
||||
test "`basename $$PWD`" = "afl" || exit 1
|
||||
test -f ~/www/afl/releases/$(PROGNAME)-$(VERSION).tgz; if [ "$$?" = "0" ]; then echo; echo "Change program version in config.h, mmkay?"; echo; exit 1; fi
|
||||
cd ..; rm -rf $(PROGNAME)-$(VERSION); cp -pr $(PROGNAME) $(PROGNAME)-$(VERSION); \
|
||||
tar -cvz -f ~/www/afl/releases/$(PROGNAME)-$(VERSION).tgz $(PROGNAME)-$(VERSION)
|
||||
chmod 644 ~/www/afl/releases/$(PROGNAME)-$(VERSION).tgz
|
||||
( cd ~/www/afl/releases/; ln -s -f $(PROGNAME)-$(VERSION).tgz $(PROGNAME)-latest.tgz )
|
||||
cat docs/README >~/www/afl/README.txt
|
||||
cat docs/status_screen.txt >~/www/afl/status_screen.txt
|
||||
cat docs/historical_notes.txt >~/www/afl/historical_notes.txt
|
||||
cat docs/technical_details.txt >~/www/afl/technical_details.txt
|
||||
cat docs/ChangeLog >~/www/afl/ChangeLog.txt
|
||||
cat docs/QuickStartGuide.txt >~/www/afl/QuickStartGuide.txt
|
||||
echo -n "$(VERSION)" >~/www/afl/version.txt
|
||||
# test "`basename $$PWD`" = "afl" || exit 1
|
||||
# test -f ~/www/afl/releases/$(PROGNAME)-$(VERSION).tgz; if [ "$$?" = "0" ]; then echo; echo "Change program version in config.h, mmkay?"; echo; exit 1; fi
|
||||
# cd ..; rm -rf $(PROGNAME)-$(VERSION); cp -pr $(PROGNAME) $(PROGNAME)-$(VERSION); \
|
||||
# tar -cvz -f ~/www/afl/releases/$(PROGNAME)-$(VERSION).tgz $(PROGNAME)-$(VERSION)
|
||||
# chmod 644 ~/www/afl/releases/$(PROGNAME)-$(VERSION).tgz
|
||||
# ( cd ~/www/afl/releases/; ln -s -f $(PROGNAME)-$(VERSION).tgz $(PROGNAME)-latest.tgz )
|
||||
# cat docs/README.md >~/www/afl/README.txt
|
||||
# cat docs/status_screen.txt >~/www/afl/status_screen.txt
|
||||
# cat docs/historical_notes.txt >~/www/afl/historical_notes.txt
|
||||
# cat docs/technical_details.txt >~/www/afl/technical_details.txt
|
||||
# cat docs/ChangeLog >~/www/afl/ChangeLog.txt
|
||||
# cat docs/QuickStartGuide.txt >~/www/afl/QuickStartGuide.txt
|
||||
# echo -n "$(VERSION)" >~/www/afl/version.txt
|
||||
|
||||
@ -1,42 +1,64 @@
|
||||
============================
|
||||
american fuzzy lop plus plus
|
||||
============================
|
||||
# american fuzzy lop plus plus (afl++)
|
||||
|
||||
Written by Michal Zalewski <lcamtuf@google.com>
|
||||
Release Version: 2.54c
|
||||
|
||||
Repository: https://github.com/vanhauser-thc/AFLplusplus
|
||||
Github Version: 2.54d
|
||||
|
||||
afl++ is maintained by Marc Heuse <mh@mh-sec.de> and Heiko Eissfeldt
|
||||
<heiko.eissfeldt@hexco.de> as there have been no updates to afl since
|
||||
November 2017.
|
||||
|
||||
This version has several bug fixes, new features and speed enhancements
|
||||
based on community patches from https://github.com/vanhauser-thc/afl-patches
|
||||
To see the list of which patches have been applied, see the PATCHES file.
|
||||
Originally developed by Michal "lcamtuf" Zalewski.
|
||||
|
||||
Additionally AFLfast's power schedules by Marcel Boehme from
|
||||
github.com/mboehme/aflfast have been incorporated.
|
||||
Repository: [https://github.com/vanhauser-thc/AFLplusplus](https://github.com/vanhauser-thc/AFLplusplus)
|
||||
|
||||
Plus it was upgraded to qemu 3.1 from 2.1 with the work of
|
||||
https://github.com/andreafioraldi/afl and got the community patches applied
|
||||
to it.
|
||||
afl++ is maintained by Marc "van Hauser" Heuse <mh@mh-sec.de>,
|
||||
Heiko "hexc0der" Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>.
|
||||
|
||||
Note that although afl now has a Google afl repository [https://github.com/Google/afl](https://github.com/Google/afl),
|
||||
it is unlikely to receive any noteable enhancements: [https://twitter.com/Dor3s/status/1154737061787660288](https://twitter.com/Dor3s/status/1154737061787660288)
|
||||
|
||||
|
||||
## The enhancements compared to the original stock afl
|
||||
|
||||
Many improvements were made over the official afl release - which did not
|
||||
get any improvements since November 2017.
|
||||
|
||||
Among others afl++ has a more performant llvm_mode, supporting
|
||||
llvm up to version 9, Qemu 3.1, more speed and crashfixes for Qemu,
|
||||
better *BSD and Android support and much, much more.
|
||||
|
||||
Additionally the following patches have been integrated:
|
||||
|
||||
* AFLfast's power schedules by Marcel Böhme: [https://github.com/mboehme/aflfast](https://github.com/mboehme/aflfast)
|
||||
|
||||
* the new excellent MOpt mutator: [https://github.com/puppet-meteor/MOpt-AFL](https://github.com/puppet-meteor/MOpt-AFL)
|
||||
|
||||
* instrim, a very effective CFG llvm_mode instrumentation implementation for large targets: [https://github.com/csienslab/instrim](https://github.com/csienslab/instrim)
|
||||
|
||||
* C. Holler's afl-fuzz Python mutator module and llvm_mode whitelist support: [https://github.com/choller/afl](https://github.com/choller/afl)
|
||||
|
||||
* Custom mutator by a library (instead of Python) by kyakdan
|
||||
|
||||
* unicorn_mode which allows fuzzing of binaries from completely different platforms (integration provided by domenukk)
|
||||
|
||||
* laf-intel (compcov) support for llvm_mode, qemu_mode and unicorn_mode
|
||||
|
||||
* neverZero patch for afl-gcc, llvm_mode, qemu_mode and unicorn_mode which prevents a wrapping map value to zero, increases coverage (by Andrea Fioraldi)
|
||||
|
||||
A more thorough list is available in the PATCHES file.
|
||||
|
||||
So all in all this is the best-of AFL that is currently out there :-)
|
||||
|
||||
|
||||
Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved.
|
||||
Released under terms and conditions of Apache License, Version 2.0.
|
||||
|
||||
For new versions and additional information, check out:
|
||||
http://lcamtuf.coredump.cx/afl/
|
||||
[https://github.com/vanhauser-thc/AFLplusplus](https://github.com/vanhauser-thc/AFLplusplus)
|
||||
|
||||
To compare notes with other users or get notified about major new features,
|
||||
send a mail to <afl-users+subscribe@googlegroups.com>.
|
||||
|
||||
** See QuickStartGuide.txt if you don't have time to read this file. **
|
||||
See [docs/QuickStartGuide.txt](docs/QuickStartGuide.txt) if you don't have time to
|
||||
read this file.
|
||||
|
||||
1) Challenges of guided fuzzing
|
||||
-------------------------------
|
||||
|
||||
## 1) Challenges of guided fuzzing
|
||||
|
||||
Fuzzing is one of the most powerful and proven strategies for identifying
|
||||
security issues in real-world software; it is responsible for the vast
|
||||
@ -62,8 +84,8 @@ All these methods are extremely promising in experimental settings, but tend
|
||||
to suffer from reliability and performance problems in practical uses - and
|
||||
currently do not offer a viable alternative to "dumb" fuzzing techniques.
|
||||
|
||||
2) The afl-fuzz approach
|
||||
------------------------
|
||||
|
||||
## 2) The afl-fuzz approach
|
||||
|
||||
American Fuzzy Lop is a brute-force fuzzer coupled with an exceedingly simple
|
||||
but rock-solid instrumentation-guided genetic algorithm. It uses a modified
|
||||
@ -101,8 +123,13 @@ closed-source tools.
|
||||
The fuzzer is thoroughly tested to deliver out-of-the-box performance far
|
||||
superior to blind fuzzing or coverage-only tools.
|
||||
|
||||
3) Instrumenting programs for use with AFL
|
||||
------------------------------------------
|
||||
|
||||
## 3) Instrumenting programs for use with AFL
|
||||
|
||||
PLEASE NOTE: llvm_mode compilation with afl-clang-fast/afl-clang-fast++
|
||||
instead of afl-gcc/afl-g++ is much faster and has a few cool features.
|
||||
See llvm_mode/ - however few code does not compile with llvm.
|
||||
We support llvm versions 3.8.0 to 9.
|
||||
|
||||
When source code is available, instrumentation can be injected by a companion
|
||||
tool that works as a drop-in replacement for gcc or clang in any standard build
|
||||
@ -115,38 +142,45 @@ or even faster than possible with traditional tools.
|
||||
The correct way to recompile the target program may vary depending on the
|
||||
specifics of the build process, but a nearly-universal approach would be:
|
||||
|
||||
```shell
|
||||
$ CC=/path/to/afl/afl-gcc ./configure
|
||||
$ make clean all
|
||||
```
|
||||
|
||||
For C++ programs, you'd would also want to set CXX=/path/to/afl/afl-g++.
|
||||
For C++ programs, you'd would also want to set `CXX=/path/to/afl/afl-g++`.
|
||||
|
||||
The clang wrappers (afl-clang and afl-clang++) can be used in the same way;
|
||||
clang users may also opt to leverage a higher-performance instrumentation mode,
|
||||
as described in llvm_mode/README.llvm.
|
||||
Clang/LLVM has a much better performance, but only works with LLVM up to and
|
||||
including 6.0.1.
|
||||
as described in [llvm_mode/README.llvm](llvm_mode/README.llvm).
|
||||
Clang/LLVM has a much better performance and works with LLVM version 3.8.0 to 9.
|
||||
|
||||
Using the LAF Intel performance enhancements are also recommended, see
|
||||
docs/README.laf-intel
|
||||
[llvm_mode/README.laf-intel](llvm_mode/README.laf-intel)
|
||||
|
||||
Using partial instrumentation is also recommended, see
|
||||
[llvm_mode/README.whitelist](llvm_mode/README.whitelist)
|
||||
|
||||
When testing libraries, you need to find or write a simple program that reads
|
||||
data from stdin or from a file and passes it to the tested library. In such a
|
||||
case, it is essential to link this executable against a static version of the
|
||||
instrumented library, or to make sure that the correct .so file is loaded at
|
||||
runtime (usually by setting LD_LIBRARY_PATH). The simplest option is a static
|
||||
runtime (usually by setting `LD_LIBRARY_PATH`). The simplest option is a static
|
||||
build, usually possible via:
|
||||
|
||||
```shell
|
||||
$ CC=/path/to/afl/afl-gcc ./configure --disable-shared
|
||||
```
|
||||
|
||||
Setting AFL_HARDEN=1 when calling 'make' will cause the CC wrapper to
|
||||
Setting `AFL_HARDEN=1` when calling 'make' will cause the CC wrapper to
|
||||
automatically enable code hardening options that make it easier to detect
|
||||
simple memory bugs. Libdislocator, a helper library included with AFL (see
|
||||
libdislocator/README.dislocator) can help uncover heap corruption issues, too.
|
||||
[libdislocator/README.dislocator](libdislocator/README.dislocator)) can help uncover heap corruption issues, too.
|
||||
|
||||
PS. ASAN users are advised to review notes_for_asan.txt file for important
|
||||
caveats.
|
||||
PS. ASAN users are advised to review [docs/notes_for_asan.txt](docs/notes_for_asan.txt)
|
||||
file for important caveats.
|
||||
|
||||
4) Instrumenting binary-only apps
|
||||
---------------------------------
|
||||
|
||||
## 4) Instrumenting binary-only apps
|
||||
|
||||
When source code is *NOT* available, the fuzzer offers experimental support for
|
||||
fast, on-the-fly instrumentation of black-box binaries. This is accomplished
|
||||
@ -155,23 +189,63 @@ with a version of QEMU running in the lesser-known "user space emulation" mode.
|
||||
QEMU is a project separate from AFL, but you can conveniently build the
|
||||
feature by doing:
|
||||
|
||||
```shell
|
||||
$ cd qemu_mode
|
||||
$ ./build_qemu_support.sh
|
||||
```
|
||||
|
||||
For additional instructions and caveats, see qemu_mode/README.qemu.
|
||||
For additional instructions and caveats, see [qemu_mode/README.qemu](qemu_mode/README.qemu).
|
||||
|
||||
The mode is approximately 2-5x slower than compile-time instrumentation, is
|
||||
less conductive to parallelization, and may have some other quirks.
|
||||
|
||||
5) Choosing initial test cases
|
||||
------------------------------
|
||||
If [afl-dyninst](https://github.com/vanhauser-thc/afl-dyninst) works for
|
||||
your binary, then you can use afl-fuzz normally and it will have twice
|
||||
the speed compared to qemu_mode.
|
||||
|
||||
A more comprehensive description of these and other options can be found in
|
||||
[docs/binaryonly_fuzzing.txt](docs/binaryonly_fuzzing.txt)
|
||||
|
||||
|
||||
## 5) Power schedules
|
||||
|
||||
The power schedules were copied from Marcel Böhme's excellent AFLfast
|
||||
implementation and expands on the ability to discover new paths and
|
||||
therefore the coverage.
|
||||
|
||||
The available schedules are:
|
||||
|
||||
- explore (default)
|
||||
- fast
|
||||
- coe
|
||||
- quad
|
||||
- lin
|
||||
- exploit
|
||||
|
||||
In parallel mode (-M/-S, several instances with shared queue), we suggest to
|
||||
run the master using the exploit schedule (-p exploit) and the slaves with a
|
||||
combination of cut-off-exponential (-p coe), exponential (-p fast; default),
|
||||
and explore (-p explore) schedules.
|
||||
|
||||
In single mode, using -p fast is usually more beneficial than the default
|
||||
explore mode.
|
||||
(We don't want to change the default behaviour of afl, so "fast" has not been
|
||||
made the default mode).
|
||||
|
||||
More details can be found in the paper published at the 23rd ACM Conference on
|
||||
Computer and Communications Security (CCS'16):
|
||||
|
||||
(https://www.sigsac.org/ccs/CCS2016/accepted-papers/)[https://www.sigsac.org/ccs/CCS2016/accepted-papers/]
|
||||
|
||||
|
||||
## 6) Choosing initial test cases
|
||||
|
||||
To operate correctly, the fuzzer requires one or more starting file that
|
||||
contains a good example of the input data normally expected by the targeted
|
||||
application. There are two basic rules:
|
||||
|
||||
- Keep the files small. Under 1 kB is ideal, although not strictly necessary.
|
||||
For a discussion of why size matters, see perf_tips.txt.
|
||||
For a discussion of why size matters, see [perf_tips.txt](docs/perf_tips.txt).
|
||||
|
||||
- Use multiple test cases only if they are functionally different from
|
||||
each other. There is no point in using fifty different vacation photos
|
||||
@ -184,8 +258,8 @@ PS. If a large corpus of data is available for screening, you may want to use
|
||||
the afl-cmin utility to identify a subset of functionally distinct files that
|
||||
exercise different code paths in the target binary.
|
||||
|
||||
6) Fuzzing binaries
|
||||
-------------------
|
||||
|
||||
## 7) Fuzzing binaries
|
||||
|
||||
The fuzzing process itself is carried out by the afl-fuzz utility. This program
|
||||
requires a read-only directory with initial test cases, a separate place to
|
||||
@ -193,13 +267,17 @@ store its findings, plus a path to the binary to test.
|
||||
|
||||
For target binaries that accept input directly from stdin, the usual syntax is:
|
||||
|
||||
```shell
|
||||
$ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program [...params...]
|
||||
```
|
||||
|
||||
For programs that take input from a file, use '@@' to mark the location in
|
||||
the target's command line where the input file name should be placed. The
|
||||
fuzzer will substitute this for you:
|
||||
|
||||
```shell
|
||||
$ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program @@
|
||||
```
|
||||
|
||||
You can also use the -f option to have the mutated data written to a specific
|
||||
file. This is useful if the program expects a particular file extension or so.
|
||||
@ -211,19 +289,19 @@ You can use -t and -m to override the default timeout and memory limit for the
|
||||
executed process; rare examples of targets that may need these settings touched
|
||||
include compilers and video decoders.
|
||||
|
||||
Tips for optimizing fuzzing performance are discussed in perf_tips.txt.
|
||||
Tips for optimizing fuzzing performance are discussed in [perf_tips.txt](docs/perf_tips.txt).
|
||||
|
||||
Note that afl-fuzz starts by performing an array of deterministic fuzzing
|
||||
steps, which can take several days, but tend to produce neat test cases. If you
|
||||
want quick & dirty results right away - akin to zzuf and other traditional
|
||||
fuzzers - add the -d option to the command line.
|
||||
|
||||
7) Interpreting output
|
||||
----------------------
|
||||
|
||||
See the status_screen.txt file for information on how to interpret the
|
||||
displayed stats and monitor the health of the process. Be sure to consult this
|
||||
file especially if any UI elements are highlighted in red.
|
||||
## 8) Interpreting output
|
||||
|
||||
See the [docs/status_screen.txt](docs/status_screen.txt) file for information on
|
||||
how to interpret the displayed stats and monitor the health of the process. Be
|
||||
sure to consult this file especially if any UI elements are highlighted in red.
|
||||
|
||||
The fuzzing process will continue until you press Ctrl-C. At minimum, you want
|
||||
to allow the fuzzer to complete one queue cycle, which may take anywhere from a
|
||||
@ -261,34 +339,38 @@ queue entries. This should help with debugging.
|
||||
When you can't reproduce a crash found by afl-fuzz, the most likely cause is
|
||||
that you are not setting the same memory limit as used by the tool. Try:
|
||||
|
||||
```shell
|
||||
$ LIMIT_MB=50
|
||||
$ ( ulimit -Sv $[LIMIT_MB << 10]; /path/to/tested_binary ... )
|
||||
```
|
||||
|
||||
Change LIMIT_MB to match the -m parameter passed to afl-fuzz. On OpenBSD,
|
||||
also change -Sv to -Sd.
|
||||
|
||||
Any existing output directory can be also used to resume aborted jobs; try:
|
||||
|
||||
```shell
|
||||
$ ./afl-fuzz -i- -o existing_output_dir [...etc...]
|
||||
```
|
||||
|
||||
If you have gnuplot installed, you can also generate some pretty graphs for any
|
||||
active fuzzing task using afl-plot. For an example of how this looks like,
|
||||
see http://lcamtuf.coredump.cx/afl/plot/.
|
||||
see [http://lcamtuf.coredump.cx/afl/plot/](http://lcamtuf.coredump.cx/afl/plot/).
|
||||
|
||||
8) Parallelized fuzzing
|
||||
-----------------------
|
||||
|
||||
## 9) Parallelized fuzzing
|
||||
|
||||
Every instance of afl-fuzz takes up roughly one core. This means that on
|
||||
multi-core systems, parallelization is necessary to fully utilize the hardware.
|
||||
For tips on how to fuzz a common target on multiple cores or multiple networked
|
||||
machines, please refer to parallel_fuzzing.txt.
|
||||
machines, please refer to [docs/parallel_fuzzing.txt](docs/parallel_fuzzing.txt).
|
||||
|
||||
The parallel fuzzing mode also offers a simple way for interfacing AFL to other
|
||||
fuzzers, to symbolic or concolic execution engines, and so forth; again, see the
|
||||
last section of parallel_fuzzing.txt for tips.
|
||||
last section of [docs/parallel_fuzzing.txt](docs/parallel_fuzzing.txt) for tips.
|
||||
|
||||
9) Fuzzer dictionaries
|
||||
----------------------
|
||||
|
||||
## 10) Fuzzer dictionaries
|
||||
|
||||
By default, afl-fuzz mutation engine is optimized for compact data formats -
|
||||
say, images, multimedia, compressed data, regular expression syntax, or shell
|
||||
@ -298,13 +380,13 @@ redundant verbiage - notably including HTML, SQL, or JavaScript.
|
||||
To avoid the hassle of building syntax-aware tools, afl-fuzz provides a way to
|
||||
seed the fuzzing process with an optional dictionary of language keywords,
|
||||
magic headers, or other special tokens associated with the targeted data type
|
||||
- and use that to reconstruct the underlying grammar on the go:
|
||||
-- and use that to reconstruct the underlying grammar on the go:
|
||||
|
||||
http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html
|
||||
[http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html](http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html)
|
||||
|
||||
To use this feature, you first need to create a dictionary in one of the two
|
||||
formats discussed in dictionaries/README.dictionaries; and then point the fuzzer
|
||||
to it via the -x option in the command line.
|
||||
formats discussed in [dictionaries/README.dictionaries](ictionaries/README.dictionaries);
|
||||
and then point the fuzzer to it via the -x option in the command line.
|
||||
|
||||
(Several common dictionaries are already provided in that subdirectory, too.)
|
||||
|
||||
@ -312,7 +394,7 @@ There is no way to provide more structured descriptions of the underlying
|
||||
syntax, but the fuzzer will likely figure out some of this based on the
|
||||
instrumentation feedback alone. This actually works in practice, say:
|
||||
|
||||
http://lcamtuf.blogspot.com/2015/04/finding-bugs-in-sqlite-easy-way.html
|
||||
[http://lcamtuf.blogspot.com/2015/04/finding-bugs-in-sqlite-easy-way.html](http://lcamtuf.blogspot.com/2015/04/finding-bugs-in-sqlite-easy-way.html)
|
||||
|
||||
PS. Even when no explicit dictionary is given, afl-fuzz will try to extract
|
||||
existing syntax tokens in the input corpus by watching the instrumentation
|
||||
@ -321,10 +403,10 @@ parsers and grammars, but isn't nearly as good as the -x mode.
|
||||
|
||||
If a dictionary is really hard to come by, another option is to let AFL run
|
||||
for a while, and then use the token capture library that comes as a companion
|
||||
utility with AFL. For that, see libtokencap/README.tokencap.
|
||||
utility with AFL. For that, see [libtokencap/README.tokencap](libtokencap/README.tokencap).
|
||||
|
||||
10) Crash triage
|
||||
----------------
|
||||
|
||||
## 11) Crash triage
|
||||
|
||||
The coverage-based grouping of crashes usually produces a small data set that
|
||||
can be quickly triaged manually or with a very simple GDB or Valgrind script.
|
||||
@ -352,7 +434,9 @@ beneath.
|
||||
Oh, one more thing: for test case minimization, give afl-tmin a try. The tool
|
||||
can be operated in a very simple way:
|
||||
|
||||
```shell
|
||||
$ ./afl-tmin -i test_case -o minimized_result -- /path/to/program [...]
|
||||
```
|
||||
|
||||
The tool works with crashing and non-crashing test cases alike. In the crash
|
||||
mode, it will happily accept instrumented and non-instrumented binaries. In the
|
||||
@ -367,10 +451,10 @@ file, attempts to sequentially flip bytes, and observes the behavior of the
|
||||
tested program. It then color-codes the input based on which sections appear to
|
||||
be critical, and which are not; while not bulletproof, it can often offer quick
|
||||
insights into complex file formats. More info about its operation can be found
|
||||
near the end of technical_details.txt.
|
||||
near the end of [docs/technical_details.txt](docs/technical_details.txt).
|
||||
|
||||
11) Going beyond crashes
|
||||
------------------------
|
||||
|
||||
## 12) Going beyond crashes
|
||||
|
||||
Fuzzing is a wonderful and underutilized technique for discovering non-crashing
|
||||
design and implementation errors, too. Quite a few interesting bugs have been
|
||||
@ -390,11 +474,11 @@ found by modifying the target programs to call abort() when, say:
|
||||
|
||||
Implementing these or similar sanity checks usually takes very little time;
|
||||
if you are the maintainer of a particular package, you can make this code
|
||||
conditional with #ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION (a flag also
|
||||
shared with libfuzzer) or #ifdef __AFL_COMPILER (this one is just for AFL).
|
||||
conditional with `#ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION` (a flag also
|
||||
shared with libfuzzer) or `#ifdef __AFL_COMPILER` (this one is just for AFL).
|
||||
|
||||
12) Common-sense risks
|
||||
----------------------
|
||||
|
||||
## 13) Common-sense risks
|
||||
|
||||
Please keep in mind that, similarly to many other computationally-intensive
|
||||
tasks, fuzzing may put strain on your hardware and on the OS. In particular:
|
||||
@ -419,10 +503,12 @@ tasks, fuzzing may put strain on your hardware and on the OS. In particular:
|
||||
|
||||
A good way to monitor disk I/O on Linux is the 'iostat' command:
|
||||
|
||||
```shell
|
||||
$ iostat -d 3 -x -k [...optional disk ID...]
|
||||
```
|
||||
|
||||
13) Known limitations & areas for improvement
|
||||
---------------------------------------------
|
||||
|
||||
## 14) Known limitations & areas for improvement
|
||||
|
||||
Here are some of the most important caveats for AFL:
|
||||
|
||||
@ -439,35 +525,36 @@ Here are some of the most important caveats for AFL:
|
||||
To work around this, you can comment out the relevant checks (see
|
||||
experimental/libpng_no_checksum/ for inspiration); if this is not possible,
|
||||
you can also write a postprocessor, as explained in
|
||||
experimental/post_library/.
|
||||
experimental/post_library/ (with AFL_POST_LIBRARY)
|
||||
|
||||
- There are some unfortunate trade-offs with ASAN and 64-bit binaries. This
|
||||
isn't due to any specific fault of afl-fuzz; see notes_for_asan.txt for
|
||||
tips.
|
||||
isn't due to any specific fault of afl-fuzz; see [docs/notes_for_asan.txt](docs/notes_for_asan.txt)
|
||||
for tips.
|
||||
|
||||
- There is no direct support for fuzzing network services, background
|
||||
daemons, or interactive apps that require UI interaction to work. You may
|
||||
need to make simple code changes to make them behave in a more traditional
|
||||
way. Preeny may offer a relatively simple option, too - see:
|
||||
https://github.com/zardus/preeny
|
||||
[https://github.com/zardus/preeny](https://github.com/zardus/preeny)
|
||||
|
||||
Some useful tips for modifying network-based services can be also found at:
|
||||
https://www.fastly.com/blog/how-to-fuzz-server-american-fuzzy-lop
|
||||
[https://www.fastly.com/blog/how-to-fuzz-server-american-fuzzy-lop](https://www.fastly.com/blog/how-to-fuzz-server-american-fuzzy-lop)
|
||||
|
||||
- AFL doesn't output human-readable coverage data. If you want to monitor
|
||||
coverage, use afl-cov from Michael Rash: https://github.com/mrash/afl-cov
|
||||
coverage, use afl-cov from Michael Rash: [https://github.com/mrash/afl-cov](https://github.com/mrash/afl-cov)
|
||||
|
||||
- Occasionally, sentient machines rise against their creators. If this
|
||||
happens to you, please consult http://lcamtuf.coredump.cx/prep/.
|
||||
happens to you, please consult [http://lcamtuf.coredump.cx/prep/](http://lcamtuf.coredump.cx/prep/).
|
||||
|
||||
Beyond this, see INSTALL for platform-specific tips.
|
||||
|
||||
14) Special thanks
|
||||
------------------
|
||||
|
||||
Many of the improvements to afl-fuzz wouldn't be possible without feedback,
|
||||
bug reports, or patches from:
|
||||
## 15) Special thanks
|
||||
|
||||
Many of the improvements to the original afl and afl++ wouldn't be possible
|
||||
without feedback, bug reports, or patches from:
|
||||
|
||||
```
|
||||
Jann Horn Hanno Boeck
|
||||
Felix Groebert Jakub Wilk
|
||||
Richard W. M. Jones Alexander Cherepanov
|
||||
@ -507,27 +594,19 @@ bug reports, or patches from:
|
||||
Rene Freingruber Sergey Davidoff
|
||||
Sami Liedes Craig Young
|
||||
Andrzej Jackowski Daniel Hodson
|
||||
Nathan Voss Dominik Maier
|
||||
Andrea Biondo Vincent Le Garrec
|
||||
Khaled Yakdan Kuang-che Wu
|
||||
```
|
||||
|
||||
Thank you!
|
||||
|
||||
15) Contact
|
||||
-----------
|
||||
|
||||
Questions? Concerns? Bug reports? The author can be usually reached at
|
||||
<lcamtuf@google.com>.
|
||||
## 16) Contact
|
||||
|
||||
There is also a mailing list for the project; to join, send a mail to
|
||||
Questions? Concerns? Bug reports? The contributors can be reached via
|
||||
[https://github.com/vanhauser-thc/AFLplusplus](https://github.com/vanhauser-thc/AFLplusplus)
|
||||
|
||||
There is also a mailing list for the afl project; to join, send a mail to
|
||||
<afl-users+subscribe@googlegroups.com>. Or, if you prefer to browse
|
||||
archives first, try:
|
||||
|
||||
https://groups.google.com/group/afl-users
|
||||
|
||||
PS. If you wish to submit raw code to be incorporated into the project, please
|
||||
be aware that the copyright on most of AFL is claimed by Google. While you do
|
||||
retain copyright on your contributions, they do ask people to agree to a simple
|
||||
CLA first:
|
||||
|
||||
https://cla.developers.google.com/clas
|
||||
|
||||
Sorry about the hassle. Of course, no CLA is required for feature requests or
|
||||
bug reports.
|
||||
archives first, try: [https://groups.google.com/group/afl-users](https://groups.google.com/group/afl-users)
|
||||
61
TODO
Normal file
61
TODO
Normal file
@ -0,0 +1,61 @@
|
||||
Roadmap 2.53d:
|
||||
==============
|
||||
|
||||
afl-fuzz:
|
||||
- custom mutator lib: example and readme
|
||||
|
||||
man:
|
||||
- man page for afl-clang-fast
|
||||
|
||||
|
||||
Roadmap 2.54d:
|
||||
==============
|
||||
|
||||
gcc_plugin:
|
||||
- needs to be rewritten
|
||||
- whitelist support
|
||||
- skip over uninteresting blocks
|
||||
- laf-intel
|
||||
- neverZero
|
||||
|
||||
qemu_mode:
|
||||
- update to 4.x (probably this will be skipped :( )
|
||||
|
||||
unit testing / or large testcase campaign
|
||||
|
||||
Problem: Average targets (tiff, jpeg, unrar) go through 1500 edges.
|
||||
At afl's default map that means ~16 collisions and ~3 wrappings.
|
||||
Solution #1: increase map size.
|
||||
every +1 decreases fuzzing speed by ~10% and halfs the collisions
|
||||
birthday paradox predicts collisions at this # of edges:
|
||||
mapsize => collisions
|
||||
2^16 = 302
|
||||
2^17 = 427
|
||||
2^18 = 603
|
||||
2^19 = 853
|
||||
2^20 = 1207
|
||||
2^21 = 1706
|
||||
2^22 = 2412
|
||||
2^23 = 3411
|
||||
2^24 = 4823
|
||||
Increasing the map is an easy solution but also not a good one.
|
||||
Solution #2: use dynamic map size and collision free basic block IDs
|
||||
This only works in llvm_mode and llvm >= 9 though
|
||||
A potential good future solution. Heiko/hexcoder follows this up
|
||||
Solution #3: write instruction pointers to a big shared map
|
||||
512kb/1MB shared map and the instrumented code writes the instruction
|
||||
pointer into the map. Map must be big enough but could be command line
|
||||
controlled.
|
||||
Good: complete coverage information, nothing is lost. choice of analysis
|
||||
impacts speed, but this can be decided by user options
|
||||
Neutral: a little bit slower but no loss of coverage
|
||||
Bad: completely changes how afl uses the map and the scheduling.
|
||||
Overall another very good solution, Marc Heuse/vanHauser follows this up
|
||||
|
||||
qemu_mode:
|
||||
- persistent mode patching the return address (WinAFL style)
|
||||
- deferred mode with AFL_DEFERRED_QEMU=0xaddress
|
||||
(AFL_ENTRYPOINT let you to specify only a basic block address as starting
|
||||
point. This will be implemented togheter with the logic for persistent
|
||||
mode.)
|
||||
|
||||
17
afl-cmin
17
afl-cmin
@ -49,12 +49,15 @@ MEM_LIMIT=100
|
||||
TIMEOUT=none
|
||||
|
||||
unset IN_DIR OUT_DIR STDIN_FILE EXTRA_PAR MEM_LIMIT_GIVEN \
|
||||
AFL_CMIN_CRASHES_ONLY AFL_CMIN_ALLOW_ANY QEMU_MODE
|
||||
AFL_CMIN_CRASHES_ONLY AFL_CMIN_ALLOW_ANY QEMU_MODE UNICORN_MODE
|
||||
|
||||
while getopts "+i:o:f:m:t:eQC" opt; do
|
||||
while getopts "+i:o:f:m:t:eQUCh" opt; do
|
||||
|
||||
case "$opt" in
|
||||
|
||||
"h")
|
||||
;;
|
||||
|
||||
"i")
|
||||
IN_DIR="$OPTARG"
|
||||
;;
|
||||
@ -83,6 +86,11 @@ while getopts "+i:o:f:m:t:eQC" opt; do
|
||||
test "$MEM_LIMIT_GIVEN" = "" && MEM_LIMIT=250
|
||||
QEMU_MODE=1
|
||||
;;
|
||||
"U")
|
||||
EXTRA_PAR="$EXTRA_PAR -U"
|
||||
test "$MEM_LIMIT_GIVEN" = "" && MEM_LIMIT=250
|
||||
UNICORN_MODE=1
|
||||
;;
|
||||
"?")
|
||||
exit 1
|
||||
;;
|
||||
@ -111,7 +119,8 @@ Execution control settings:
|
||||
-m megs - memory limit for child process ($MEM_LIMIT MB)
|
||||
-t msec - run time limit for child process (none)
|
||||
-Q - use binary-only instrumentation (QEMU mode)
|
||||
|
||||
-U - use unicorn-based instrumentation (Unicorn mode)
|
||||
|
||||
Minimization settings:
|
||||
|
||||
-C - keep crashing inputs, reject everything else
|
||||
@ -196,7 +205,7 @@ if [ ! -f "$TARGET_BIN" -o ! -x "$TARGET_BIN" ]; then
|
||||
|
||||
fi
|
||||
|
||||
if [ "$AFL_SKIP_BIN_CHECK" = "" -a "$QEMU_MODE" = "" ]; then
|
||||
if [ "$AFL_SKIP_BIN_CHECK" = "" -a "$QEMU_MODE" = "" -a "$UNICORN_MODE" = "" ]; then
|
||||
|
||||
if ! grep -qF "__AFL_SHM_ID" "$TARGET_BIN"; then
|
||||
echo "[-] Error: binary '$TARGET_BIN' doesn't appear to be instrumented." 1>&2
|
||||
|
||||
8271
afl-fuzz.c
8271
afl-fuzz.c
File diff suppressed because it is too large
Load Diff
4
afl-plot
4
afl-plot
@ -21,10 +21,10 @@ echo
|
||||
if [ ! "$#" = "2" ]; then
|
||||
|
||||
cat 1>&2 <<_EOF_
|
||||
This program generates gnuplot images from afl-fuzz output data. Usage:
|
||||
|
||||
$0 afl_state_dir graph_output_dir
|
||||
|
||||
This program generates gnuplot images from afl-fuzz output data. Usage:
|
||||
|
||||
The afl_state_dir parameter should point to an existing state directory for any
|
||||
active or stopped instance of afl-fuzz; while graph_output_dir should point to
|
||||
an empty directory where this tool can write the resulting plots to.
|
||||
|
||||
@ -1,5 +1,24 @@
|
||||
#!/bin/sh
|
||||
test "$1" = "-h" && {
|
||||
echo afl-system-config by Marc Heuse
|
||||
echo
|
||||
echo $0
|
||||
echo
|
||||
echo afl-system-config has no command line options
|
||||
echo
|
||||
echo afl-system reconfigures the system to a high performance fuzzing state
|
||||
echo WARNING: this reduces the security of the system
|
||||
echo
|
||||
exit 1
|
||||
}
|
||||
|
||||
PLATFORM=`uname -s`
|
||||
echo This reconfigures the system to have a better fuzzing performance
|
||||
if [ '!' "$EUID" = 0 ] && [ '!' `id -u` = 0 ] ; then
|
||||
echo Error you need to be root to run this
|
||||
exit 1
|
||||
fi
|
||||
if [ "$PLATFORM" = "Linux" ] ; then
|
||||
sysctl -w kernel.core_pattern=core
|
||||
sysctl -w kernel.randomize_va_space=0
|
||||
sysctl -w kernel.sched_child_runs_first=1
|
||||
@ -7,9 +26,27 @@ sysctl -w kernel.sched_autogroup_enabled=1
|
||||
sysctl -w kernel.sched_migration_cost_ns=50000000
|
||||
sysctl -w kernel.sched_latency_ns=250000000
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor > /dev/null
|
||||
test -e /sys/devices/system/cpu/cpufreq/scaling_governor && echo performance | tee /sys/devices/system/cpu/cpufreq/scaling_governor
|
||||
test -e /sys/devices/system/cpu/cpufreq/policy0/scaling_governor && echo performance | tee /sys/devices/system/cpu/cpufreq/policy*/scaling_governor
|
||||
test -e /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor && echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
|
||||
test -e /sys/devices/system/cpu/intel_pstate/no_turbo && echo 0 > /sys/devices/system/cpu/intel_pstate/no_turbo
|
||||
test -e /sys/devices/system/cpu/cpufreq/boost && echo 1 > /sys/devices/system/cpu/cpufreq/boost
|
||||
echo
|
||||
echo It is recommended to boot the kernel with lots of security off - if you are running a machine that is in a secured network - so set this:
|
||||
echo '/etc/default/grub:GRUB_CMDLINE_LINUX_DEFAULT="ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off"'
|
||||
fi
|
||||
if [ "$PLATFORM" = "FreeBSD" ] ; then
|
||||
sysctl kern.elf32.aslr.enable=0
|
||||
sysctl kern.elf64.aslr.enable=0
|
||||
echo
|
||||
echo It is recommended to boot the kernel with lots of security off - if you are running a machine that is in a secured network - so set this:
|
||||
echo 'sysctl hw.ibrs_disable=1'
|
||||
echo
|
||||
echo 'Setting kern.pmap.pg_ps_enabled=0 into /boot/loader.conf might be helpful too.'
|
||||
fi
|
||||
if [ "$PLATFORM" = "OpenBSD" ] ; then
|
||||
echo
|
||||
echo 'System security features cannot be disabled on OpenBSD.'
|
||||
fi
|
||||
echo
|
||||
echo Also use AFL_TMPDIR to use a tmpfs for the input file
|
||||
|
||||
@ -19,6 +19,13 @@
|
||||
|
||||
echo "status check tool for afl-fuzz by <lcamtuf@google.com>"
|
||||
echo
|
||||
test "$1" = "-h" && {
|
||||
echo $0
|
||||
echo
|
||||
echo afl-whatsup has no command line options
|
||||
echo
|
||||
exit 1
|
||||
}
|
||||
|
||||
if [ "$1" = "-s" ]; then
|
||||
|
||||
@ -54,7 +61,7 @@ fi
|
||||
|
||||
CUR_TIME=`date +%s`
|
||||
|
||||
TMP=`mktemp -t .afl-whatsup-XXXXXXXX` || exit 1
|
||||
TMP=`mktemp -t .afl-whatsup-XXXXXXXX` || TMP=`mktemp -p /data/local/tmp .afl-whatsup-XXXXXXXX` || exit 1
|
||||
|
||||
ALIVE_CNT=0
|
||||
DEAD_CNT=0
|
||||
|
||||
354
config.h
354
config.h
@ -1,354 +0,0 @@
|
||||
/*
|
||||
american fuzzy lop plus plus - vaguely configurable bits
|
||||
----------------------------------------------
|
||||
|
||||
Written and maintained by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
*/
|
||||
|
||||
#ifndef _HAVE_CONFIG_H
|
||||
#define _HAVE_CONFIG_H
|
||||
|
||||
#include "types.h"
|
||||
|
||||
/* Version string: */
|
||||
|
||||
#define VERSION "++2.52c"
|
||||
|
||||
/******************************************************
|
||||
* *
|
||||
* Settings that may be of interest to power users: *
|
||||
* *
|
||||
******************************************************/
|
||||
|
||||
/* Comment out to disable terminal colors (note that this makes afl-analyze
|
||||
a lot less nice): */
|
||||
|
||||
#define USE_COLOR
|
||||
|
||||
/* Comment out to disable fancy ANSI boxes and use poor man's 7-bit UI: */
|
||||
|
||||
#define FANCY_BOXES
|
||||
|
||||
/* Default timeout for fuzzed code (milliseconds). This is the upper bound,
|
||||
also used for detecting hangs; the actual value is auto-scaled: */
|
||||
|
||||
#define EXEC_TIMEOUT 1000
|
||||
|
||||
/* Timeout rounding factor when auto-scaling (milliseconds): */
|
||||
|
||||
#define EXEC_TM_ROUND 20
|
||||
|
||||
/* Default memory limit for child process (MB): */
|
||||
|
||||
#ifndef __x86_64__
|
||||
# define MEM_LIMIT 25
|
||||
#else
|
||||
# define MEM_LIMIT 50
|
||||
#endif /* ^!__x86_64__ */
|
||||
|
||||
/* Default memory limit when running in QEMU mode (MB): */
|
||||
|
||||
#define MEM_LIMIT_QEMU 200
|
||||
|
||||
/* Number of calibration cycles per every new test case (and for test
|
||||
cases that show variable behavior): */
|
||||
|
||||
#define CAL_CYCLES 8
|
||||
#define CAL_CYCLES_LONG 40
|
||||
|
||||
/* Number of subsequent timeouts before abandoning an input file: */
|
||||
|
||||
#define TMOUT_LIMIT 250
|
||||
|
||||
/* Maximum number of unique hangs or crashes to record: */
|
||||
|
||||
#define KEEP_UNIQUE_HANG 500
|
||||
#define KEEP_UNIQUE_CRASH 5000
|
||||
|
||||
/* Baseline number of random tweaks during a single 'havoc' stage: */
|
||||
|
||||
#define HAVOC_CYCLES 256
|
||||
#define HAVOC_CYCLES_INIT 1024
|
||||
|
||||
/* Maximum multiplier for the above (should be a power of two, beware
|
||||
of 32-bit int overflows): */
|
||||
|
||||
#define HAVOC_MAX_MULT 16
|
||||
|
||||
/* Absolute minimum number of havoc cycles (after all adjustments): */
|
||||
|
||||
#define HAVOC_MIN 16
|
||||
|
||||
/* Power Schedule Divisor */
|
||||
#define POWER_BETA 1
|
||||
#define MAX_FACTOR (POWER_BETA * 32)
|
||||
|
||||
/* Maximum stacking for havoc-stage tweaks. The actual value is calculated
|
||||
like this:
|
||||
|
||||
n = random between 1 and HAVOC_STACK_POW2
|
||||
stacking = 2^n
|
||||
|
||||
In other words, the default (n = 7) produces 2, 4, 8, 16, 32, 64, or
|
||||
128 stacked tweaks: */
|
||||
|
||||
#define HAVOC_STACK_POW2 7
|
||||
|
||||
/* Caps on block sizes for cloning and deletion operations. Each of these
|
||||
ranges has a 33% probability of getting picked, except for the first
|
||||
two cycles where smaller blocks are favored: */
|
||||
|
||||
#define HAVOC_BLK_SMALL 32
|
||||
#define HAVOC_BLK_MEDIUM 128
|
||||
#define HAVOC_BLK_LARGE 1500
|
||||
|
||||
/* Extra-large blocks, selected very rarely (<5% of the time): */
|
||||
|
||||
#define HAVOC_BLK_XL 32768
|
||||
|
||||
/* Probabilities of skipping non-favored entries in the queue, expressed as
|
||||
percentages: */
|
||||
|
||||
#define SKIP_TO_NEW_PROB 99 /* ...when there are new, pending favorites */
|
||||
#define SKIP_NFAV_OLD_PROB 95 /* ...no new favs, cur entry already fuzzed */
|
||||
#define SKIP_NFAV_NEW_PROB 75 /* ...no new favs, cur entry not fuzzed yet */
|
||||
|
||||
/* Splicing cycle count: */
|
||||
|
||||
#define SPLICE_CYCLES 15
|
||||
|
||||
/* Nominal per-splice havoc cycle length: */
|
||||
|
||||
#define SPLICE_HAVOC 32
|
||||
|
||||
/* Maximum offset for integer addition / subtraction stages: */
|
||||
|
||||
#define ARITH_MAX 35
|
||||
|
||||
/* Limits for the test case trimmer. The absolute minimum chunk size; and
|
||||
the starting and ending divisors for chopping up the input file: */
|
||||
|
||||
#define TRIM_MIN_BYTES 4
|
||||
#define TRIM_START_STEPS 16
|
||||
#define TRIM_END_STEPS 1024
|
||||
|
||||
/* Maximum size of input file, in bytes (keep under 100MB): */
|
||||
|
||||
#define MAX_FILE (1 * 1024 * 1024)
|
||||
|
||||
/* The same, for the test case minimizer: */
|
||||
|
||||
#define TMIN_MAX_FILE (10 * 1024 * 1024)
|
||||
|
||||
/* Block normalization steps for afl-tmin: */
|
||||
|
||||
#define TMIN_SET_MIN_SIZE 4
|
||||
#define TMIN_SET_STEPS 128
|
||||
|
||||
/* Maximum dictionary token size (-x), in bytes: */
|
||||
|
||||
#define MAX_DICT_FILE 128
|
||||
|
||||
/* Length limits for auto-detected dictionary tokens: */
|
||||
|
||||
#define MIN_AUTO_EXTRA 3
|
||||
#define MAX_AUTO_EXTRA 32
|
||||
|
||||
/* Maximum number of user-specified dictionary tokens to use in deterministic
|
||||
steps; past this point, the "extras/user" step will be still carried out,
|
||||
but with proportionally lower odds: */
|
||||
|
||||
#define MAX_DET_EXTRAS 200
|
||||
|
||||
/* Maximum number of auto-extracted dictionary tokens to actually use in fuzzing
|
||||
(first value), and to keep in memory as candidates. The latter should be much
|
||||
higher than the former. */
|
||||
|
||||
#define USE_AUTO_EXTRAS 50
|
||||
#define MAX_AUTO_EXTRAS (USE_AUTO_EXTRAS * 10)
|
||||
|
||||
/* Scaling factor for the effector map used to skip some of the more
|
||||
expensive deterministic steps. The actual divisor is set to
|
||||
2^EFF_MAP_SCALE2 bytes: */
|
||||
|
||||
#define EFF_MAP_SCALE2 3
|
||||
|
||||
/* Minimum input file length at which the effector logic kicks in: */
|
||||
|
||||
#define EFF_MIN_LEN 128
|
||||
|
||||
/* Maximum effector density past which everything is just fuzzed
|
||||
unconditionally (%): */
|
||||
|
||||
#define EFF_MAX_PERC 90
|
||||
|
||||
/* UI refresh frequency (Hz): */
|
||||
|
||||
#define UI_TARGET_HZ 5
|
||||
|
||||
/* Fuzzer stats file and plot update intervals (sec): */
|
||||
|
||||
#define STATS_UPDATE_SEC 60
|
||||
#define PLOT_UPDATE_SEC 5
|
||||
|
||||
/* Smoothing divisor for CPU load and exec speed stats (1 - no smoothing). */
|
||||
|
||||
#define AVG_SMOOTHING 16
|
||||
|
||||
/* Sync interval (every n havoc cycles): */
|
||||
|
||||
#define SYNC_INTERVAL 5
|
||||
|
||||
/* Output directory reuse grace period (minutes): */
|
||||
|
||||
#define OUTPUT_GRACE 25
|
||||
|
||||
/* Uncomment to use simple file names (id_NNNNNN): */
|
||||
|
||||
// #define SIMPLE_FILES
|
||||
|
||||
/* List of interesting values to use in fuzzing. */
|
||||
|
||||
#define INTERESTING_8 \
|
||||
-128, /* Overflow signed 8-bit when decremented */ \
|
||||
-1, /* */ \
|
||||
0, /* */ \
|
||||
1, /* */ \
|
||||
16, /* One-off with common buffer size */ \
|
||||
32, /* One-off with common buffer size */ \
|
||||
64, /* One-off with common buffer size */ \
|
||||
100, /* One-off with common buffer size */ \
|
||||
127 /* Overflow signed 8-bit when incremented */
|
||||
|
||||
#define INTERESTING_16 \
|
||||
-32768, /* Overflow signed 16-bit when decremented */ \
|
||||
-129, /* Overflow signed 8-bit */ \
|
||||
128, /* Overflow signed 8-bit */ \
|
||||
255, /* Overflow unsig 8-bit when incremented */ \
|
||||
256, /* Overflow unsig 8-bit */ \
|
||||
512, /* One-off with common buffer size */ \
|
||||
1000, /* One-off with common buffer size */ \
|
||||
1024, /* One-off with common buffer size */ \
|
||||
4096, /* One-off with common buffer size */ \
|
||||
32767 /* Overflow signed 16-bit when incremented */
|
||||
|
||||
#define INTERESTING_32 \
|
||||
-2147483648LL, /* Overflow signed 32-bit when decremented */ \
|
||||
-100663046, /* Large negative number (endian-agnostic) */ \
|
||||
-32769, /* Overflow signed 16-bit */ \
|
||||
32768, /* Overflow signed 16-bit */ \
|
||||
65535, /* Overflow unsig 16-bit when incremented */ \
|
||||
65536, /* Overflow unsig 16 bit */ \
|
||||
100663045, /* Large positive number (endian-agnostic) */ \
|
||||
2147483647 /* Overflow signed 32-bit when incremented */
|
||||
|
||||
/***********************************************************
|
||||
* *
|
||||
* Really exotic stuff you probably don't want to touch: *
|
||||
* *
|
||||
***********************************************************/
|
||||
|
||||
/* Call count interval between reseeding the libc PRNG from /dev/urandom: */
|
||||
|
||||
#define RESEED_RNG 10000
|
||||
|
||||
/* Maximum line length passed from GCC to 'as' and used for parsing
|
||||
configuration files: */
|
||||
|
||||
#define MAX_LINE 8192
|
||||
|
||||
/* Environment variable used to pass SHM ID to the called program. */
|
||||
|
||||
#define SHM_ENV_VAR "__AFL_SHM_ID"
|
||||
|
||||
/* Other less interesting, internal-only variables. */
|
||||
|
||||
#define CLANG_ENV_VAR "__AFL_CLANG_MODE"
|
||||
#define AS_LOOP_ENV_VAR "__AFL_AS_LOOPCHECK"
|
||||
#define PERSIST_ENV_VAR "__AFL_PERSISTENT"
|
||||
#define DEFER_ENV_VAR "__AFL_DEFER_FORKSRV"
|
||||
|
||||
/* In-code signatures for deferred and persistent mode. */
|
||||
|
||||
#define PERSIST_SIG "##SIG_AFL_PERSISTENT##"
|
||||
#define DEFER_SIG "##SIG_AFL_DEFER_FORKSRV##"
|
||||
|
||||
/* Distinctive bitmap signature used to indicate failed execution: */
|
||||
|
||||
#define EXEC_FAIL_SIG 0xfee1dead
|
||||
|
||||
/* Distinctive exit code used to indicate MSAN trip condition: */
|
||||
|
||||
#define MSAN_ERROR 86
|
||||
|
||||
/* Designated file descriptors for forkserver commands (the application will
|
||||
use FORKSRV_FD and FORKSRV_FD + 1): */
|
||||
|
||||
#define FORKSRV_FD 198
|
||||
|
||||
/* Fork server init timeout multiplier: we'll wait the user-selected
|
||||
timeout plus this much for the fork server to spin up. */
|
||||
|
||||
#define FORK_WAIT_MULT 10
|
||||
|
||||
/* Calibration timeout adjustments, to be a bit more generous when resuming
|
||||
fuzzing sessions or trying to calibrate already-added internal finds.
|
||||
The first value is a percentage, the other is in milliseconds: */
|
||||
|
||||
#define CAL_TMOUT_PERC 125
|
||||
#define CAL_TMOUT_ADD 50
|
||||
|
||||
/* Number of chances to calibrate a case before giving up: */
|
||||
|
||||
#define CAL_CHANCES 3
|
||||
|
||||
/* Map size for the traced binary (2^MAP_SIZE_POW2). Must be greater than
|
||||
2; you probably want to keep it under 18 or so for performance reasons
|
||||
(adjusting AFL_INST_RATIO when compiling is probably a better way to solve
|
||||
problems with complex programs). You need to recompile the target binary
|
||||
after changing this - otherwise, SEGVs may ensue. */
|
||||
|
||||
#define MAP_SIZE_POW2 16
|
||||
#define MAP_SIZE (1 << MAP_SIZE_POW2)
|
||||
|
||||
/* Maximum allocator request size (keep well under INT_MAX): */
|
||||
|
||||
#define MAX_ALLOC 0x40000000
|
||||
|
||||
/* A made-up hashing seed: */
|
||||
|
||||
#define HASH_CONST 0xa5b35705
|
||||
|
||||
/* Constants for afl-gotcpu to control busy loop timing: */
|
||||
|
||||
#define CTEST_TARGET_MS 5000
|
||||
#define CTEST_CORE_TRG_MS 1000
|
||||
#define CTEST_BUSY_CYCLES (10 * 1000 * 1000)
|
||||
|
||||
/* Uncomment this to use inferior block-coverage-based instrumentation. Note
|
||||
that you need to recompile the target binary for this to have any effect: */
|
||||
|
||||
// #define COVERAGE_ONLY
|
||||
|
||||
/* Uncomment this to ignore hit counts and output just one bit per tuple.
|
||||
As with the previous setting, you will need to recompile the target
|
||||
binary: */
|
||||
|
||||
// #define SKIP_COUNTS
|
||||
|
||||
/* Uncomment this to use instrumentation data to record newly discovered paths,
|
||||
but do not use them as seeds for fuzzing. This is useful for conveniently
|
||||
measuring coverage that could be attained by a "dumb" fuzzing algorithm: */
|
||||
|
||||
// #define IGNORE_FINDS
|
||||
|
||||
#endif /* ! _HAVE_CONFIG_H */
|
||||
2
custom_mutators/README
Normal file
2
custom_mutators/README
Normal file
@ -0,0 +1,2 @@
|
||||
This is a simple example for the AFL_CUSTOM_MUTATOR_LIBRARY feature.
|
||||
For more information see docs/custom_mutator.txt
|
||||
49
custom_mutators/simple_mutator.c
Normal file
49
custom_mutators/simple_mutator.c
Normal file
@ -0,0 +1,49 @@
|
||||
/*
|
||||
Simple Custom Mutator for AFL
|
||||
|
||||
Written by Khaled Yakdan <yakdan@code-intelligence.de>
|
||||
|
||||
This a simple mutator that assumes that the generates messages starting with
|
||||
one of the three strings GET, PUT, or DEL followed by a payload. The mutator
|
||||
randomly selects a commend and mutates the payload of the seed provided as
|
||||
input.
|
||||
*/
|
||||
|
||||
#include <stdint.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
|
||||
static const char *commands[] = {
|
||||
|
||||
"GET",
|
||||
"PUT",
|
||||
"DEL",
|
||||
|
||||
};
|
||||
|
||||
static size_t data_size = 100;
|
||||
|
||||
size_t afl_custom_mutator(uint8_t *data, size_t size, uint8_t *mutated_out,
|
||||
size_t max_size, unsigned int seed) {
|
||||
|
||||
// Seed the PRNG
|
||||
srand(seed);
|
||||
|
||||
// Make sure that the packet size does not exceed the maximum size expected by
|
||||
// the fuzzer
|
||||
size_t mutated_size = data_size <= max_size ? data_size : max_size;
|
||||
|
||||
// Randomly select a command string to add as a header to the packet
|
||||
memcpy(mutated_out, commands[rand() % 3], 3);
|
||||
|
||||
// Mutate the payload of the packet
|
||||
for (int i = 3; i < mutated_size; i++) {
|
||||
|
||||
mutated_out[i] = (data[i] + rand() % 10) & 0xff;
|
||||
|
||||
}
|
||||
|
||||
return mutated_size;
|
||||
|
||||
}
|
||||
|
||||
251
debug.h
251
debug.h
@ -1,251 +0,0 @@
|
||||
/*
|
||||
american fuzzy lop - debug / error handling macros
|
||||
--------------------------------------------------
|
||||
|
||||
Written and maintained by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
*/
|
||||
|
||||
#ifndef _HAVE_DEBUG_H
|
||||
#define _HAVE_DEBUG_H
|
||||
|
||||
#include <errno.h>
|
||||
|
||||
#include "types.h"
|
||||
#include "config.h"
|
||||
|
||||
/*******************
|
||||
* Terminal colors *
|
||||
*******************/
|
||||
|
||||
#ifdef USE_COLOR
|
||||
|
||||
# define cBLK "\x1b[0;30m"
|
||||
# define cRED "\x1b[0;31m"
|
||||
# define cGRN "\x1b[0;32m"
|
||||
# define cBRN "\x1b[0;33m"
|
||||
# define cBLU "\x1b[0;34m"
|
||||
# define cMGN "\x1b[0;35m"
|
||||
# define cCYA "\x1b[0;36m"
|
||||
# define cLGR "\x1b[0;37m"
|
||||
# define cGRA "\x1b[1;90m"
|
||||
# define cLRD "\x1b[1;91m"
|
||||
# define cLGN "\x1b[1;92m"
|
||||
# define cYEL "\x1b[1;93m"
|
||||
# define cLBL "\x1b[1;94m"
|
||||
# define cPIN "\x1b[1;95m"
|
||||
# define cLCY "\x1b[1;96m"
|
||||
# define cBRI "\x1b[1;97m"
|
||||
# define cRST "\x1b[0m"
|
||||
|
||||
# define bgBLK "\x1b[40m"
|
||||
# define bgRED "\x1b[41m"
|
||||
# define bgGRN "\x1b[42m"
|
||||
# define bgBRN "\x1b[43m"
|
||||
# define bgBLU "\x1b[44m"
|
||||
# define bgMGN "\x1b[45m"
|
||||
# define bgCYA "\x1b[46m"
|
||||
# define bgLGR "\x1b[47m"
|
||||
# define bgGRA "\x1b[100m"
|
||||
# define bgLRD "\x1b[101m"
|
||||
# define bgLGN "\x1b[102m"
|
||||
# define bgYEL "\x1b[103m"
|
||||
# define bgLBL "\x1b[104m"
|
||||
# define bgPIN "\x1b[105m"
|
||||
# define bgLCY "\x1b[106m"
|
||||
# define bgBRI "\x1b[107m"
|
||||
|
||||
#else
|
||||
|
||||
# define cBLK ""
|
||||
# define cRED ""
|
||||
# define cGRN ""
|
||||
# define cBRN ""
|
||||
# define cBLU ""
|
||||
# define cMGN ""
|
||||
# define cCYA ""
|
||||
# define cLGR ""
|
||||
# define cGRA ""
|
||||
# define cLRD ""
|
||||
# define cLGN ""
|
||||
# define cYEL ""
|
||||
# define cLBL ""
|
||||
# define cPIN ""
|
||||
# define cLCY ""
|
||||
# define cBRI ""
|
||||
# define cRST ""
|
||||
|
||||
# define bgBLK ""
|
||||
# define bgRED ""
|
||||
# define bgGRN ""
|
||||
# define bgBRN ""
|
||||
# define bgBLU ""
|
||||
# define bgMGN ""
|
||||
# define bgCYA ""
|
||||
# define bgLGR ""
|
||||
# define bgGRA ""
|
||||
# define bgLRD ""
|
||||
# define bgLGN ""
|
||||
# define bgYEL ""
|
||||
# define bgLBL ""
|
||||
# define bgPIN ""
|
||||
# define bgLCY ""
|
||||
# define bgBRI ""
|
||||
|
||||
#endif /* ^USE_COLOR */
|
||||
|
||||
/*************************
|
||||
* Box drawing sequences *
|
||||
*************************/
|
||||
|
||||
#ifdef FANCY_BOXES
|
||||
|
||||
# define SET_G1 "\x1b)0" /* Set G1 for box drawing */
|
||||
# define RESET_G1 "\x1b)B" /* Reset G1 to ASCII */
|
||||
# define bSTART "\x0e" /* Enter G1 drawing mode */
|
||||
# define bSTOP "\x0f" /* Leave G1 drawing mode */
|
||||
# define bH "q" /* Horizontal line */
|
||||
# define bV "x" /* Vertical line */
|
||||
# define bLT "l" /* Left top corner */
|
||||
# define bRT "k" /* Right top corner */
|
||||
# define bLB "m" /* Left bottom corner */
|
||||
# define bRB "j" /* Right bottom corner */
|
||||
# define bX "n" /* Cross */
|
||||
# define bVR "t" /* Vertical, branch right */
|
||||
# define bVL "u" /* Vertical, branch left */
|
||||
# define bHT "v" /* Horizontal, branch top */
|
||||
# define bHB "w" /* Horizontal, branch bottom */
|
||||
|
||||
#else
|
||||
|
||||
# define SET_G1 ""
|
||||
# define RESET_G1 ""
|
||||
# define bSTART ""
|
||||
# define bSTOP ""
|
||||
# define bH "-"
|
||||
# define bV "|"
|
||||
# define bLT "+"
|
||||
# define bRT "+"
|
||||
# define bLB "+"
|
||||
# define bRB "+"
|
||||
# define bX "+"
|
||||
# define bVR "+"
|
||||
# define bVL "+"
|
||||
# define bHT "+"
|
||||
# define bHB "+"
|
||||
|
||||
#endif /* ^FANCY_BOXES */
|
||||
|
||||
/***********************
|
||||
* Misc terminal codes *
|
||||
***********************/
|
||||
|
||||
#define TERM_HOME "\x1b[H"
|
||||
#define TERM_CLEAR TERM_HOME "\x1b[2J"
|
||||
#define cEOL "\x1b[0K"
|
||||
#define CURSOR_HIDE "\x1b[?25l"
|
||||
#define CURSOR_SHOW "\x1b[?25h"
|
||||
|
||||
/************************
|
||||
* Debug & error macros *
|
||||
************************/
|
||||
|
||||
/* Just print stuff to the appropriate stream. */
|
||||
|
||||
#ifdef MESSAGES_TO_STDOUT
|
||||
# define SAYF(x...) printf(x)
|
||||
#else
|
||||
# define SAYF(x...) fprintf(stderr, x)
|
||||
#endif /* ^MESSAGES_TO_STDOUT */
|
||||
|
||||
/* Show a prefixed warning. */
|
||||
|
||||
#define WARNF(x...) do { \
|
||||
SAYF(cYEL "[!] " cBRI "WARNING: " cRST x); \
|
||||
SAYF(cRST "\n"); \
|
||||
} while (0)
|
||||
|
||||
/* Show a prefixed "doing something" message. */
|
||||
|
||||
#define ACTF(x...) do { \
|
||||
SAYF(cLBL "[*] " cRST x); \
|
||||
SAYF(cRST "\n"); \
|
||||
} while (0)
|
||||
|
||||
/* Show a prefixed "success" message. */
|
||||
|
||||
#define OKF(x...) do { \
|
||||
SAYF(cLGN "[+] " cRST x); \
|
||||
SAYF(cRST "\n"); \
|
||||
} while (0)
|
||||
|
||||
/* Show a prefixed fatal error message (not used in afl). */
|
||||
|
||||
#define BADF(x...) do { \
|
||||
SAYF(cLRD "\n[-] " cRST x); \
|
||||
SAYF(cRST "\n"); \
|
||||
} while (0)
|
||||
|
||||
/* Die with a verbose non-OS fatal error message. */
|
||||
|
||||
#define FATAL(x...) do { \
|
||||
SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD "\n[-] PROGRAM ABORT : " \
|
||||
cBRI x); \
|
||||
SAYF(cLRD "\n Location : " cRST "%s(), %s:%u\n\n", \
|
||||
__FUNCTION__, __FILE__, __LINE__); \
|
||||
exit(1); \
|
||||
} while (0)
|
||||
|
||||
/* Die by calling abort() to provide a core dump. */
|
||||
|
||||
#define ABORT(x...) do { \
|
||||
SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD "\n[-] PROGRAM ABORT : " \
|
||||
cBRI x); \
|
||||
SAYF(cLRD "\n Stop location : " cRST "%s(), %s:%u\n\n", \
|
||||
__FUNCTION__, __FILE__, __LINE__); \
|
||||
abort(); \
|
||||
} while (0)
|
||||
|
||||
/* Die while also including the output of perror(). */
|
||||
|
||||
#define PFATAL(x...) do { \
|
||||
fflush(stdout); \
|
||||
SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD "\n[-] SYSTEM ERROR : " \
|
||||
cBRI x); \
|
||||
SAYF(cLRD "\n Stop location : " cRST "%s(), %s:%u\n", \
|
||||
__FUNCTION__, __FILE__, __LINE__); \
|
||||
SAYF(cLRD " OS message : " cRST "%s\n", strerror(errno)); \
|
||||
exit(1); \
|
||||
} while (0)
|
||||
|
||||
/* Die with FAULT() or PFAULT() depending on the value of res (used to
|
||||
interpret different failure modes for read(), write(), etc). */
|
||||
|
||||
#define RPFATAL(res, x...) do { \
|
||||
if (res < 0) PFATAL(x); else FATAL(x); \
|
||||
} while (0)
|
||||
|
||||
/* Error-checking versions of read() and write() that call RPFATAL() as
|
||||
appropriate. */
|
||||
|
||||
#define ck_write(fd, buf, len, fn) do { \
|
||||
u32 _len = (len); \
|
||||
s32 _res = write(fd, buf, _len); \
|
||||
if (_res != _len) RPFATAL(_res, "Short write to %s", fn); \
|
||||
} while (0)
|
||||
|
||||
#define ck_read(fd, buf, len, fn) do { \
|
||||
u32 _len = (len); \
|
||||
s32 _res = read(fd, buf, _len); \
|
||||
if (_res != _len) RPFATAL(_res, "Short read from %s", fn); \
|
||||
} while (0)
|
||||
|
||||
#endif /* ! _HAVE_DEBUG_H */
|
||||
@ -13,14 +13,88 @@ Want to stay in the loop on major new features? Join our mailing list by
|
||||
sending a mail to <afl-users+subscribe@googlegroups.com>.
|
||||
|
||||
|
||||
--------------------------
|
||||
Version ++2.54c (release):
|
||||
--------------------------
|
||||
|
||||
- big code refactoring:
|
||||
* all includes are now in include/
|
||||
* all afl sources are now in src/ - see src/README.src
|
||||
* afl-fuzz was splitted up in various individual files for including
|
||||
functionality in other programs (e.g. forkserver, memory map, etc.)
|
||||
for better readability.
|
||||
* new code indention everywhere
|
||||
- auto-generating man pages for all (main) tools
|
||||
- added AFL_FORCE_UI to show the UI even if the terminal is not detected
|
||||
- llvm 9 is now supported (still needs testing)
|
||||
- Android is now supported (thank to JoeyJiao!) - still need to modify the Makefile though
|
||||
- fix building qemu on some Ubuntus (thanks to floyd!)
|
||||
- custom mutator by a loaded library is now supported (thanks to kyakdan!)
|
||||
- added PR that includes peak_rss_mb and slowest_exec_ms in the fuzzer_stats report
|
||||
- more support for *BSD (thanks to devnexen!)
|
||||
- fix building on *BSD (thanks to tobias.kortkamp for the patch)
|
||||
- fix for a few features to support different map sized than 2^16
|
||||
- afl-showmap: new option -r now shows the real values in the buckets (stock
|
||||
afl never did), plus shows tuple content summary information now
|
||||
- small docu updates
|
||||
- NeverZero counters for QEMU
|
||||
- NeverZero counters for Unicorn
|
||||
- CompareCoverage Unicorn
|
||||
- immediates-only instrumentation for CompareCoverage
|
||||
|
||||
|
||||
--------------------------
|
||||
Version ++2.53c (release):
|
||||
--------------------------
|
||||
|
||||
- README is now README.md
|
||||
- imported the few minor changes from the 2.53b release
|
||||
- unicorn_mode got added - thanks to domenukk for the patch!
|
||||
- fix llvm_mode AFL_TRACE_PC with modern llvm
|
||||
- fix a crash in qemu_mode which also exists in stock afl
|
||||
- added libcompcov, a laf-intel implementation for qemu! :)
|
||||
see qemu_mode/libcompcov/README.libcompcov
|
||||
- afl-fuzz now displays the selected core in the status screen (blue {#})
|
||||
- updated afl-fuzz and afl-system-config for new scaling governor location
|
||||
in modern kernels
|
||||
- using the old ineffective afl-gcc will now show a deprecation warning
|
||||
- all queue, hang and crash files now have their discovery time in their name
|
||||
- if llvm_mode was compiled, afl-clang/afl-clang++ will point to these
|
||||
instead of afl-gcc
|
||||
- added instrim, a much faster llvm_mode instrumentation at the cost of
|
||||
path discovery. See llvm_mode/README.instrim (https://github.com/csienslab/instrim)
|
||||
- added MOpt (github.com/puppet-meteor/MOpt-AFL) mode, see docs/README.MOpt
|
||||
- added code to make it more portable to other platforms than Intel Linux
|
||||
- added never zero counters for afl-gcc and optionally (because of an
|
||||
optimization issue in llvm < 9) for llvm_mode (AFL_LLVM_NEVER_ZERO=1)
|
||||
- added a new doc about binary only fuzzing: docs/binaryonly_fuzzing.txt
|
||||
- more cpu power for afl-system-config
|
||||
- added forkserver patch to afl-tmin, makes it much faster (originally from
|
||||
github.com/nccgroup/TriforceAFL)
|
||||
- added whitelist support for llvm_mode via AFL_LLVM_WHITELIST to allow
|
||||
only to instrument what is actually interesting. Gives more speed and less
|
||||
map pollution (originally by choller@mozilla)
|
||||
- added Python Module mutator support, python2.7-dev is autodetected.
|
||||
see docs/python_mutators.txt (originally by choller@mozilla)
|
||||
- added AFL_CAL_FAST for slow applications and AFL_DEBUG_CHILD_OUTPUT for
|
||||
debugging
|
||||
- added -V time and -E execs option to better comparison runs, runs afl-fuzz
|
||||
for a specific time/executions.
|
||||
- added a -s seed switch to allow afl run with a fixed initial
|
||||
seed that is not updated. This is good for performance and path discovery
|
||||
tests as the random numbers are deterministic then
|
||||
- llvm_mode LAF_... env variables can now be specified as AFL_LLVM_LAF_...
|
||||
that is longer but in line with other llvm specific env vars
|
||||
|
||||
|
||||
-----------------------------
|
||||
Version ++2.52c (2019-05-28):
|
||||
Version ++2.52c (2019-06-05):
|
||||
-----------------------------
|
||||
|
||||
- Applied community patches. See docs/PATCHES for the full list.
|
||||
LLVM and Qemu modes are now faster.
|
||||
Important changes:
|
||||
afl-fuzz: -e EXTENSION commandline option
|
||||
afl-fuzz: -e EXTENSION commandline option
|
||||
llvm_mode: LAF-intel performance (needs activation, see llvm/README.laf-intel)
|
||||
a few new environment variables for afl-fuzz, llvm and qemu, see docs/env_variables.txt
|
||||
- Added the power schedules of AFLfast by Marcel Boehme, but set the default
|
||||
|
||||
10
docs/PATCHES
10
docs/PATCHES
@ -17,7 +17,15 @@ afl-qemu-optimize-entrypoint.diff by mh(at)mh-sec(dot)de
|
||||
afl-qemu-speed.diff by abiondo on github
|
||||
afl-qemu-optimize-map.diff by mh(at)mh-sec(dot)de
|
||||
|
||||
additionally AFLfast additions (github.com/mboehme/aflfast) were incorporated.
|
||||
+ Custom mutator (native library) (by kyakdan)
|
||||
+ unicorn_mode (modernized and updated by domenukk)
|
||||
+ instrim (https://github.com/csienslab/instrim) was integrated
|
||||
+ MOpt (github.com/puppet-meteor/MOpt-AFL) was imported
|
||||
+ AFLfast additions (github.com/mboehme/aflfast) were incorporated.
|
||||
+ Qemu 3.1 upgrade with enhancement patches (github.com/andreafioraldi/afl)
|
||||
+ Python mutator modules support (github.com/choller/afl)
|
||||
+ Whitelisting in LLVM mode (github.com/choller/afl)
|
||||
+ forkserver patch for afl-tmin (github.com/nccgroup/TriforceAFL)
|
||||
|
||||
|
||||
NOT INSTALLED
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
AFL quick start guide
|
||||
=====================
|
||||
|
||||
You should read docs/README. It's pretty short. If you really can't, here's
|
||||
You should read docs/README.md - it's pretty short. If you really can't, here's
|
||||
how to hit the ground running:
|
||||
|
||||
1) Compile AFL with 'make'. If build fails, see docs/INSTALL for tips.
|
||||
@ -12,10 +12,12 @@ how to hit the ground running:
|
||||
If testing a network service, modify it to run in the foreground and read
|
||||
from stdin. When fuzzing a format that uses checksums, comment out the
|
||||
checksum verification code, too.
|
||||
If this is not possible (e.g. in -Q(emu) mode) then use AFL_POST_LIBRARY
|
||||
to calculate the values with your own library.
|
||||
|
||||
The program must crash properly when a fault is encountered. Watch out for
|
||||
custom SIGSEGV or SIGABRT handlers and background processes. For tips on
|
||||
detecting non-crashing flaws, see section 11 in docs/README.
|
||||
detecting non-crashing flaws, see section 11 in docs/README.md .
|
||||
|
||||
3) Compile the program / library to be fuzzed using afl-gcc. A common way to
|
||||
do this would be:
|
||||
@ -40,10 +42,13 @@ how to hit the ground running:
|
||||
6) Investigate anything shown in red in the fuzzer UI by promptly consulting
|
||||
docs/status_screen.txt.
|
||||
|
||||
7) compile and use llvm_mode (afl-clang-fast/afl-clang-fast++) as it is way
|
||||
faster and has a few cool features
|
||||
|
||||
That's it. Sit back, relax, and - time permitting - try to skim through the
|
||||
following files:
|
||||
|
||||
- docs/README - A general introduction to AFL,
|
||||
- docs/README.md - A general introduction to AFL,
|
||||
- docs/perf_tips.txt - Simple tips on how to fuzz more quickly,
|
||||
- docs/status_screen.txt - An explanation of the tidbits shown in the UI,
|
||||
- docs/parallel_fuzzing.txt - Advice on running AFL on multiple cores.
|
||||
|
||||
51
docs/README.MOpt
Normal file
51
docs/README.MOpt
Normal file
@ -0,0 +1,51 @@
|
||||
# MOpt(imized) AFL by <puppet@zju.edu.cn>
|
||||
|
||||
### 1. Description
|
||||
MOpt-AFL is a AFL-based fuzzer that utilizes a customized Particle Swarm
|
||||
Optimization (PSO) algorithm to find the optimal selection probability
|
||||
distribution of operators with respect to fuzzing effectiveness.
|
||||
More details can be found in the technical report.
|
||||
|
||||
### 2. Cite Information
|
||||
Chenyang Lyu, Shouling Ji, Chao Zhang, Yuwei Li, Wei-Han Lee, Yu Song and
|
||||
Raheem Beyah, MOPT: Optimized Mutation Scheduling for Fuzzers,
|
||||
USENIX Security 2019.
|
||||
|
||||
### 3. Seed Sets
|
||||
We open source all the seed sets used in the paper
|
||||
"MOPT: Optimized Mutation Scheduling for Fuzzers".
|
||||
|
||||
### 4. Experiment Results
|
||||
The experiment results can be found in
|
||||
https://drive.google.com/drive/folders/184GOzkZGls1H2NuLuUfSp9gfqp1E2-lL?usp=sharing.
|
||||
We only open source the crash files since the space is limited.
|
||||
|
||||
### 5. Technical Report
|
||||
MOpt_TechReport.pdf is the technical report of the paper
|
||||
"MOPT: Optimized Mutation Scheduling for Fuzzers", which contains more deatails.
|
||||
|
||||
### 6. Parameter Introduction
|
||||
Most important, you must add the parameter `-L` (e.g., `-L 0`) to launch the
|
||||
MOpt scheme.
|
||||
|
||||
Option '-L' controls the time to move on to the pacemaker fuzzing mode.
|
||||
'-L t': when MOpt-AFL finishes the mutation of one input, if it has not
|
||||
discovered any new unique crash or path for more than t minutes, MOpt-AFL will
|
||||
enter the pacemaker fuzzing mode.
|
||||
|
||||
Setting 0 will enter the pacemaker fuzzing mode at first, which is
|
||||
recommended in a short time-scale evaluation.
|
||||
|
||||
Other important parameters can be found in afl-fuzz.c, for instance,
|
||||
|
||||
'swarm_num': the number of the PSO swarms used in the fuzzing process.
|
||||
'period_pilot': how many times MOpt-AFL will execute the target program
|
||||
in the pilot fuzzing module, then it will enter the core fuzzing module.
|
||||
'period_core': how many times MOpt-AFL will execute the target program in the
|
||||
core fuzzing module, then it will enter the PSO updating module.
|
||||
'limit_time_bound': control how many interesting test cases need to be found
|
||||
before MOpt-AFL quits the pacemaker fuzzing mode and reuses the deterministic stage.
|
||||
0 < 'limit_time_bound' < 1, MOpt-AFL-tmp.
|
||||
'limit_time_bound' >= 1, MOpt-AFL-ever.
|
||||
|
||||
Have fun with MOpt in AFL!
|
||||
1
docs/README.md
Symbolic link
1
docs/README.md
Symbolic link
@ -0,0 +1 @@
|
||||
../README.md
|
||||
140
docs/binaryonly_fuzzing.txt
Normal file
140
docs/binaryonly_fuzzing.txt
Normal file
@ -0,0 +1,140 @@
|
||||
|
||||
Fuzzing binary-only programs with afl++
|
||||
=======================================
|
||||
|
||||
afl++, libfuzzer and others are great if you have the source code, and
|
||||
it allows for very fast and coverage guided fuzzing.
|
||||
|
||||
However, if there is only the binary program and not source code available,
|
||||
then standard afl++ (dumb mode) is not effective.
|
||||
|
||||
The following is a description of how these can be fuzzed with afl++
|
||||
|
||||
!!!!!
|
||||
TL;DR: try DYNINST with afl-dyninst. If it produces too many crashes then
|
||||
use afl -Q qemu_mode, or better: use both in parallel.
|
||||
!!!!!
|
||||
|
||||
|
||||
QEMU
|
||||
----
|
||||
Qemu is the "native" solution to the program.
|
||||
It is available in the ./qemu_mode/ directory and once compiled it can
|
||||
be accessed by the afl-fuzz -Q command line option.
|
||||
The speed decrease is at about 50%
|
||||
It is the easiest to use alternative and even works for cross-platform binaries.
|
||||
|
||||
As it is included in afl++ this needs no URL.
|
||||
|
||||
|
||||
UNICORN
|
||||
-------
|
||||
Unicorn is a fork of QEMU. The instrumentation is, therefore, very similar.
|
||||
In contrast to QEMU, Unicorn does not offer a full system or even userland emulation.
|
||||
Runtime environment and/or loaders have to be written from scratch, if needed.
|
||||
On top, block chaining has been removed. This means the speed boost introduced in
|
||||
to the patched QEMU Mode of afl++ cannot simply be ported over to Unicorn.
|
||||
For further information, check out ./unicorn_mode.txt.
|
||||
|
||||
|
||||
DYNINST
|
||||
-------
|
||||
Dyninst is a binary instrumentation framework similar to Pintool and Dynamorio
|
||||
(see far below). However whereas Pintool and Dynamorio work at runtime, dyninst
|
||||
instruments the target at load time, and then let it run.
|
||||
This is great for some things, e.g. fuzzing, and not so effective for others,
|
||||
e.g. malware analysis.
|
||||
|
||||
So what we can do with dyninst is taking every basic block, and put afl's
|
||||
instrumention code in there - and then save the binary.
|
||||
Afterwards we can just fuzz the newly saved target binary with afl-fuzz.
|
||||
Sounds great? It is. The issue though - it is a non-trivial problem to
|
||||
insert instructions, which change addresses in the process space, so
|
||||
everything is still working afterwards. Hence more often than not binaries
|
||||
crash when they are run (because of instrumentation).
|
||||
|
||||
The speed decrease is about 15-35%, depending on the optimization options
|
||||
used with afl-dyninst.
|
||||
|
||||
So if dyninst works, it is the best option available. Otherwise it just doesn't
|
||||
work well.
|
||||
|
||||
https://github.com/vanhauser-thc/afl-dyninst
|
||||
|
||||
|
||||
INTEL-PT
|
||||
--------
|
||||
If you have a newer Intel CPU, you can make use of Intels processor trace.
|
||||
The big issue with Intel's PT is the small buffer size and the complex
|
||||
encoding of the debug information collected through PT.
|
||||
This makes the decoding very CPU intensive and hence slow.
|
||||
As a result, the overall speed decrease is about 70-90% (depending on
|
||||
the implementation and other factors).
|
||||
|
||||
There are two afl intel-pt implementations:
|
||||
|
||||
1. https://github.com/junxzm1990/afl-pt
|
||||
=> this needs Ubuntu 14.04.05 without any updates and the 4.4 kernel.
|
||||
|
||||
2. https://github.com/hunter-ht-2018/ptfuzzer
|
||||
=> this needs a 4.14 or 4.15 kernel. the "nopti" kernel boot option must
|
||||
be used. This one is faster than the other.
|
||||
|
||||
|
||||
CORESIGHT
|
||||
---------
|
||||
|
||||
Coresight is ARM's answer to Intel's PT.
|
||||
There is no implementation so far which handle coresight and getting
|
||||
it working on an ARM Linux is very difficult due to custom kernel building
|
||||
on embedded systems is difficult. And finding one that has coresight in
|
||||
the ARM chip is difficult too.
|
||||
My guess is that it is slower than Qemu, but faster than Intel PT.
|
||||
If anyone finds any coresight implementation for afl please ping me:
|
||||
vh@thc.org
|
||||
|
||||
|
||||
PIN & DYNAMORIO
|
||||
---------------
|
||||
|
||||
Pintool and Dynamorio are dynamic instrumentation engines, and they can be
|
||||
used for getting basic block information at runtime.
|
||||
Pintool is only available for Intel x32/x64 on Linux, Mac OS and Windows
|
||||
whereas Dynamorio is additionally available for ARM and AARCH64.
|
||||
Dynamorio is also 10x faster than Pintool.
|
||||
|
||||
The big issue with Dynamorio (and therefore Pintool too) is speed.
|
||||
Dynamorio has a speed decrease of 98-99%
|
||||
Pintool has a speed decrease of 99.5%
|
||||
|
||||
Hence Dynamorio is the option to go for if everything fails, and Pintool
|
||||
only if Dynamorio fails too.
|
||||
|
||||
Dynamorio solutions:
|
||||
https://github.com/vanhauser-thc/afl-dynamorio
|
||||
https://github.com/mxmssh/drAFL
|
||||
https://github.com/googleprojectzero/winafl/ <= very good but windows only
|
||||
|
||||
Pintool solutions:
|
||||
https://github.com/vanhauser-thc/afl-pin
|
||||
https://github.com/mothran/aflpin
|
||||
https://github.com/spinpx/afl_pin_mode <= only old Pintool version supported
|
||||
|
||||
|
||||
Non-AFL solutions
|
||||
-----------------
|
||||
|
||||
There are many binary-only fuzzing frameworks. Some are great for CTFs but don't
|
||||
work with large binaries, others are very slow but have good path discovery,
|
||||
some are very hard to set-up ...
|
||||
|
||||
QSYM: https://github.com/sslab-gatech/qsym
|
||||
Manticore: https://github.com/trailofbits/manticore
|
||||
S2E: https://github.com/S2E
|
||||
<please send me any missing that are good>
|
||||
|
||||
|
||||
|
||||
That's it!
|
||||
News, corrections, updates?
|
||||
Email vh@thc.org
|
||||
34
docs/custom_mutator.txt
Normal file
34
docs/custom_mutator.txt
Normal file
@ -0,0 +1,34 @@
|
||||
==================================================
|
||||
Adding custom mutators to AFL using
|
||||
==================================================
|
||||
This file describes how you can implement custom mutations to be used in AFL.
|
||||
|
||||
Implemented by Khaled Yakdan from Code Intelligence <yakdan@code-intelligence.de>
|
||||
|
||||
|
||||
1) Description
|
||||
--------------
|
||||
|
||||
Custom mutator libraries can be passed to afl-fuzz to perform custom mutations
|
||||
on test cases beyond those available in AFL - for example, to enable structure-aware
|
||||
fuzzing by using libraries that perform mutations according to a given grammar.
|
||||
|
||||
The custom mutator library is passed to afl-fuzz via the AFL_CUSTOM_MUTATOR_LIBRARY
|
||||
environment variable. The library must export the afl_custom_mutator() function and
|
||||
must be compiled as a shared object. For example:
|
||||
$CC -shared -Wall -O3 <lib-name>.c -o <lib-name>.so
|
||||
|
||||
AFL will call the afl_custom_mutator() function every time it needs to mutate
|
||||
a test case. For some cases, the format of the mutated data returned from
|
||||
the custom mutator is not suitable to directly execute the target with this input.
|
||||
For example, when using libprotobuf-mutator, the data returned is in a protobuf
|
||||
format which corresponds to a given grammar. In order to execute the target,
|
||||
the protobuf data must be converted to the plain-text format expected by the target.
|
||||
In such scenarios, the user can define the afl_pre_save_handler() function. This function
|
||||
is then transforms the data into the format expected by the API before executing the target.
|
||||
afl_pre_save_handler is optional and does not have to be implemented if its functionality
|
||||
is not needed.
|
||||
|
||||
2) Example
|
||||
----------
|
||||
A simple example is provided in ../custom_mutators/
|
||||
@ -7,8 +7,8 @@ Environmental variables
|
||||
users or for some types of custom fuzzing setups. See README for the general
|
||||
instruction manual.
|
||||
|
||||
1) Settings for afl-gcc, afl-clang, and afl-as
|
||||
----------------------------------------------
|
||||
1) Settings for afl-gcc, afl-clang, and afl-as - and gcc_plugin afl-gcc-fast
|
||||
----------------------------------------------------------------------------
|
||||
|
||||
Because they can't directly accept command-line options, the compile-time
|
||||
tools make fairly broad use of environmental variables:
|
||||
@ -68,8 +68,11 @@ tools make fairly broad use of environmental variables:
|
||||
- Setting AFL_QUIET will prevent afl-cc and afl-as banners from being
|
||||
displayed during compilation, in case you find them distracting.
|
||||
|
||||
2) Settings for afl-clang-fast
|
||||
------------------------------
|
||||
- Setting AFL_CAL_FAST will speed up the initial calibration, if the
|
||||
application is very slow
|
||||
|
||||
2) Settings for afl-clang-fast / afl-clang-fast++
|
||||
-------------------------------------------------
|
||||
|
||||
The native LLVM instrumentation helper accepts a subset of the settings
|
||||
discussed in section #1, with the exception of:
|
||||
@ -79,9 +82,57 @@ discussed in section #1, with the exception of:
|
||||
- TMPDIR and AFL_KEEP_ASSEMBLY, since no temporary assembly files are
|
||||
created.
|
||||
|
||||
Note that AFL_INST_RATIO will behave a bit differently than for afl-gcc,
|
||||
because functions are *not* instrumented unconditionally - so low values
|
||||
will have a more striking effect. For this tool, 0 is not a valid choice.
|
||||
- AFL_INST_RATIO, as we switched for instrim instrumentation which
|
||||
is more effective but makes not much sense together with this option.
|
||||
|
||||
Then there are a few specific features that are only available in llvm_mode:
|
||||
|
||||
LAF-INTEL
|
||||
=========
|
||||
This great feature will split compares to series of single byte comparisons
|
||||
to allow afl-fuzz to find otherwise rather impossible paths. It is not
|
||||
restricted to Intel CPUs ;-)
|
||||
|
||||
- Setting AFL_LLVM_LAF_SPLIT_SWITCHES will split switch()es
|
||||
|
||||
- Setting AFL_LLVM_LAF_TRANSFORM_COMPARES will split string compare functions
|
||||
|
||||
- Setting AFL_LLVM_LAF_SPLIT_COMPARES will split > 8 bit CMP instructions
|
||||
|
||||
See llvm_mode/README.laf-intel for more information.
|
||||
|
||||
WHITELIST
|
||||
=========
|
||||
This feature allows selectively instrumentation of the source
|
||||
|
||||
- Setting AFL_LLVM_WHITELIST with a filename will only instrument those
|
||||
files that match the names listed in this file.
|
||||
|
||||
See llvm_mode/README.whitelist for more information.
|
||||
|
||||
INSTRIM
|
||||
=======
|
||||
This feature increases the speed by whopping 20% but at the cost of a
|
||||
lower path discovery and therefore coverage.
|
||||
|
||||
- Setting AFL_LLVM_INSTRIM activates this mode
|
||||
|
||||
- Setting AFL_LLVM_INSTRIM_LOOPHEAD=1 expands on INSTRIM to optimize loops.
|
||||
afl-fuzz will only be able to see the path the loop took, but not how
|
||||
many times it was called (unless it is a complex loop).
|
||||
|
||||
See llvm_mode/README.instrim
|
||||
|
||||
NOT_ZERO
|
||||
========
|
||||
|
||||
- Setting AFL_LLVM_NOT_ZERO=1 during compilation will use counters
|
||||
that skip zero on overflow. This is the default for llvm >= 9,
|
||||
however for llvm versions below that this will increase an unnecessary
|
||||
slowdown due a performance issue that is only fixed in llvm 9+.
|
||||
This feature increases path discovery by a little bit.
|
||||
|
||||
See llvm_mode/README.neverzero
|
||||
|
||||
3) Settings for afl-fuzz
|
||||
------------------------
|
||||
@ -132,8 +183,8 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
|
||||
- AFL_TMPDIR is used to write the .cur_input file to if exists, and in
|
||||
the normal output directory otherwise. You would use this to point to
|
||||
a ramdisk/tmpfs. This increases the speed by a very minimal value but
|
||||
also reduces the stress on SSDs.
|
||||
a ramdisk/tmpfs. This increases the speed by a small value but also
|
||||
reduces the stress on SSDs.
|
||||
|
||||
- When developing custom instrumentation on top of afl-fuzz, you can use
|
||||
AFL_SKIP_BIN_CHECK to inhibit the checks for non-instrumented binaries
|
||||
@ -150,6 +201,11 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
mutated files - say, to fix up checksums. See experimental/post_library/
|
||||
for more.
|
||||
|
||||
- For AFL_PYTHON_MODULE and AFL_PYTHON_ONLY - they require to be compiled
|
||||
with -DUSE_PYTHON. Please see docs/python_mutators.txt
|
||||
This feature allows to configure custom mutators which can be very helpful
|
||||
in e.g. fuzzing XML or other highly flexible structured input.
|
||||
|
||||
- AFL_FAST_CAL keeps the calibration stage about 2.5x faster (albeit less
|
||||
precise), which can help when starting a session against a slow target.
|
||||
|
||||
@ -167,6 +223,9 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
some basic stats. This behavior is also automatically triggered when the
|
||||
output from afl-fuzz is redirected to a file or to a pipe.
|
||||
|
||||
- Setting AFL_FORCE_UI will force painting the UI on the screen even if
|
||||
no valid terminal was detected (for virtual consoles)
|
||||
|
||||
- If you are Jakub, you may need AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES.
|
||||
Others need not apply.
|
||||
|
||||
@ -174,6 +233,9 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
processing the first queue entry; and AFL_BENCH_UNTIL_CRASH causes it to
|
||||
exit soon after the first crash is found.
|
||||
|
||||
- Setting AFL_DEBUG_CHILD_OUTPUT will not suppress the child output.
|
||||
Not pretty but good for debugging purposes.
|
||||
|
||||
4) Settings for afl-qemu-trace
|
||||
------------------------------
|
||||
|
||||
@ -185,6 +247,20 @@ The QEMU wrapper used to instrument binary-only code supports several settings:
|
||||
|
||||
- Setting AFL_INST_LIBS causes the translator to also instrument the code
|
||||
inside any dynamically linked libraries (notably including glibc).
|
||||
|
||||
- Setting AFL_COMPCOV_LEVEL enables the CompareCoverage tracing of all cmp
|
||||
and sub in x86 and x86_64 and memory comparions functions (e.g. strcmp,
|
||||
memcmp, ...) when libcompcov is preloaded using AFL_PRELOAD.
|
||||
More info at qemu_mode/libcompcov/README.compcov.
|
||||
There are two levels at the moment, AFL_COMPCOV_LEVEL=1 that instruments
|
||||
only comparisons with immediate values / read-only memory and
|
||||
AFL_COMPCOV_LEVEL=2 that instruments all the comparions. Level 2 is more
|
||||
accurate but may need a larger shared memory.
|
||||
|
||||
- Setting AFL_QEMU_COMPCOV enables the CompareCoverage tracing of all
|
||||
cmp and sub in x86 and x86_64.
|
||||
This is an alias of AFL_COMPCOV_LEVEL=1 when AFL_COMPCOV_LEVEL is
|
||||
not specified.
|
||||
|
||||
- The underlying QEMU binary will recognize any standard "user space
|
||||
emulation" variables (e.g., QEMU_STACK_SIZE), but there should be no
|
||||
@ -194,9 +270,10 @@ The QEMU wrapper used to instrument binary-only code supports several settings:
|
||||
Use this if you are unsure if the entrypoint might be wrong - but
|
||||
use it directly, e.g. afl-qemu-trace ./program
|
||||
|
||||
- If you want to specify a specific entrypoint into the binary (this can
|
||||
be very good for the performance!), use AFL_ENTRYPOINT for this.
|
||||
- AFL_ENTRYPOINT allows you to specify a specific entrypoint into the
|
||||
binary (this can be very good for the performance!).
|
||||
The entrypoint is specified as hex address, e.g. 0x4004110
|
||||
Note that the address must be the address of a basic block.
|
||||
|
||||
5) Settings for afl-cmin
|
||||
------------------------
|
||||
|
||||
@ -64,6 +64,14 @@ that can offer huge benefits for programs with high startup overhead. Both
|
||||
modes require you to edit the source code of the fuzzed program, but the
|
||||
changes often amount to just strategically placing a single line or two.
|
||||
|
||||
If there are important data comparisons performed (e.g. strcmp(ptr, MAGIC_HDR)
|
||||
then using laf-intel (see llvm_mode/README.laf-intel) will help afl-fuzz a lot
|
||||
to get to the important parts in the code.
|
||||
|
||||
If you are only intested in specific parts of the code being fuzzed, you can
|
||||
whitelist the files that are actually relevant. This improves the speed and
|
||||
accuracy of afl. See llvm_mode/README.whitelist
|
||||
|
||||
4) Profile and optimize the binary
|
||||
----------------------------------
|
||||
|
||||
@ -191,7 +199,7 @@ There are several OS-level factors that may affect fuzzing speed:
|
||||
- Use the afl-system-config script to set all proc/sys settings above
|
||||
|
||||
- Disable all the spectre, meltdown etc. security countermeasures in the
|
||||
kernel if your machine is properly seperated:
|
||||
kernel if your machine is properly separated:
|
||||
"ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off
|
||||
no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable
|
||||
nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off
|
||||
|
||||
@ -1,31 +1,26 @@
|
||||
This document was copied and modified from AFLfast at github.com/mboehme/aflfast
|
||||
afl++'s power schedules based on AFLfast
|
||||
|
||||
<a href="https://comp.nus.edu.sg/~mboehme/paper/CCS16.pdf"><img src="https://comp.nus.edu.sg/~mboehme/paper/CCS16.png" align="right" width="250"></a>
|
||||
Power schedules implemented by Marcel Böhme \<marcel.boehme@acm.org\>.
|
||||
AFLFast is an extension of AFL which was written by Michal Zalewski \<lcamtuf@google.com\>.
|
||||
|
||||
Essentially, we observed that most generated inputs exercise the same few
|
||||
"high-frequency" paths and developed strategies to gravitate towards
|
||||
low-frequency paths, to stress significantly more program behavior in the
|
||||
same amount of time. We devised several **search strategies** that decide
|
||||
in which order the seeds should be fuzzed and **power schedules** that
|
||||
smartly regulate the number of inputs generated from a seed (i.e., the
|
||||
time spent fuzzing a seed). We call the number of inputs generated from a
|
||||
seed, the seed's **energy**.
|
||||
AFLfast has helped in the success of Team Codejitsu at the finals of the DARPA Cyber Grand Challenge where their bot Galactica took **2nd place** in terms of #POVs proven (see red bar at https://www.cybergrandchallenge.com/event#results). AFLFast exposed several previously unreported CVEs that could not be exposed by AFL in 24 hours and otherwise exposed vulnerabilities significantly faster than AFL while generating orders of magnitude more unique crashes.
|
||||
|
||||
Old AFL used -p exploit which had a too high cost, current AFL uses -p explore.
|
||||
Essentially, we observed that most generated inputs exercise the same few "high-frequency" paths and developed strategies to gravitate towards low-frequency paths, to stress significantly more program behavior in the same amount of time. We devised several **search strategies** that decide in which order the seeds should be fuzzed and **power schedules** that smartly regulate the number of inputs generated from a seed (i.e., the time spent fuzzing a seed). We call the number of inputs generated from a seed, the seed's **energy**.
|
||||
|
||||
AFLfast implemented 4 new power schedules which are highly recommended to run
|
||||
in parallel.
|
||||
We find that AFL's exploitation-based constant schedule assigns **too much energy to seeds exercising high-frequency paths** (e.g., paths that reject invalid inputs) and not enough energy to seeds exercising low-frequency paths (e.g., paths that stress interesting behaviors). Technically, we modified the computation of a seed's performance score (`calculate_score`), which seed is marked as favourite (`update_bitmap_score`), and which seed is chosen next from the circular queue (`main`). We implemented the following schedules (in the order of their effectiveness, best first):
|
||||
|
||||
| AFL flag | Power Schedule |
|
||||
| ------------- | -------------------------- |
|
||||
| `-p fast` (default)| 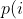=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) |
|
||||
| `-p explore` (default)| 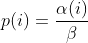 |
|
||||
| `-p fast` | 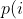=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) |
|
||||
| `-p coe` | 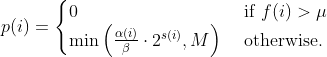 |
|
||||
| `-p explore` | 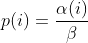 |
|
||||
| `-p quad` | 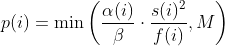 |
|
||||
| `-p lin` | 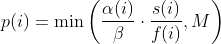 |
|
||||
| `-p exploit` (AFL) | 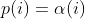 |
|
||||
where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path.
|
||||
|
||||
More details can be found in our paper that was recently accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/).
|
||||
More details can be found in the paper that was accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/).
|
||||
|
||||
PS: In parallel mode (several instances with shared queue), we suggest to run the master using the exploit schedule (-p exploit) and the slaves with a combination of cut-off-exponential (-p coe), exponential (-p fast; default), and explore (-p explore) schedules. In single mode, the default settings will do. **EDIT:** In parallel mode, AFLFast seems to perform poorly because the path probability estimates are incorrect for the imported seeds. Pull requests to fix this issue by syncing the estimates accross instances are appreciated :)
|
||||
|
||||
|
||||
152
docs/python_mutators.txt
Normal file
152
docs/python_mutators.txt
Normal file
@ -0,0 +1,152 @@
|
||||
==================================================
|
||||
Adding custom mutators to AFL using Python modules
|
||||
==================================================
|
||||
|
||||
This file describes how you can utilize the external Python API to write
|
||||
your own custom mutation routines.
|
||||
|
||||
Note: This feature is highly experimental. Use at your own risk.
|
||||
|
||||
Implemented by Christian Holler (:decoder) <choller@mozilla.com>.
|
||||
|
||||
NOTE: This is for Python 2.7 !
|
||||
Anyone who wants to add Python 3.7 support is happily welcome :)
|
||||
|
||||
For an example and a template see ../python_mutators/
|
||||
|
||||
|
||||
1) Description and purpose
|
||||
--------------------------
|
||||
|
||||
While AFLFuzz comes with a good selection of generic deterministic and
|
||||
non-deterministic mutation operations, it sometimes might make sense to extend
|
||||
these to implement strategies more specific to the target you are fuzzing.
|
||||
|
||||
For simplicity and in order to allow people without C knowledge to extend
|
||||
AFLFuzz, I implemented a "Python" stage that can make use of an external
|
||||
module (written in Python) that implements a custom mutation stage.
|
||||
|
||||
The main motivation behind this is to lower the barrier for people
|
||||
experimenting with this tool. Hopefully, someone will be able to do useful
|
||||
things with this extension.
|
||||
|
||||
If you find it useful, have questions or need additional features added to the
|
||||
interface, feel free to send a mail to <choller@mozilla.com>.
|
||||
|
||||
See the following information to get a better pictures:
|
||||
https://www.agarri.fr/docs/XML_Fuzzing-NullCon2017-PUBLIC.pdf
|
||||
https://bugs.chromium.org/p/chromium/issues/detail?id=930663
|
||||
|
||||
|
||||
2) How the Python module looks like
|
||||
-----------------------------------
|
||||
|
||||
You can find a simple example in pymodules/example.py including documentation
|
||||
explaining each function. In the same directory, you can find another simple
|
||||
module that performs simple mutations.
|
||||
|
||||
Right now, "init" is called at program startup and can be used to perform any
|
||||
kinds of one-time initializations while "fuzz" is called each time a mutation
|
||||
is requested.
|
||||
|
||||
There is also optional support for a trimming API, see the section below for
|
||||
further information about this feature.
|
||||
|
||||
|
||||
3) How to compile AFLFuzz with Python support
|
||||
---------------------------------------------
|
||||
|
||||
You must install the python 2.7 development package of your Linux distribution
|
||||
before this will work. On Debian/Ubuntu/Kali this can be done with:
|
||||
apt install python2.7-dev
|
||||
|
||||
A prerequisite for using this mode is to compile AFLFuzz with Python support.
|
||||
|
||||
The afl Makefile performs some magic and detects Python 2.7 if it is in the
|
||||
default path and compiles afl-fuzz with the feature if available (which is
|
||||
/usr/include/python2.7 for the Python.h include and /usr/lib/x86_64-linux-gnu
|
||||
for the libpython2.7.a library)
|
||||
|
||||
In case your setup is different set the necessary variables like this:
|
||||
PYTHON_INCLUDE=/path/to/python2.7/include LDFLAGS=-L/path/to/python2.7/lib make
|
||||
|
||||
|
||||
4) How to run AFLFuzz with your custom module
|
||||
---------------------------------------------
|
||||
|
||||
You must pass the module name inside the env variable AFL_PYTHON_MODULE.
|
||||
|
||||
In addition, if you are trying to load the module from the local directory,
|
||||
you must adjust your PYTHONPATH to reflect this circumstance. The following
|
||||
command should work if you are inside the aflfuzz directory:
|
||||
|
||||
$ AFL_PYTHON_MODULE="pymodules.test" PYTHONPATH=. ./afl-fuzz
|
||||
|
||||
Optionally, the following environment variables are supported:
|
||||
|
||||
AFL_PYTHON_ONLY - Disable all other mutation stages. This can prevent broken
|
||||
testcases (those that your Python module can't work with
|
||||
anymore) to fill up your queue. Best combined with a custom
|
||||
trimming routine (see below) because trimming can cause the
|
||||
same test breakage like havoc and splice.
|
||||
|
||||
AFL_DEBUG - When combined with AFL_NO_UI, this causes the C trimming code
|
||||
to emit additional messages about the performance and actions
|
||||
of your custom Python trimmer. Use this to see if it works :)
|
||||
|
||||
|
||||
5) Order and statistics
|
||||
-----------------------
|
||||
|
||||
The Python stage is set to be the first non-deterministic stage (right before
|
||||
the havoc stage). In the statistics however, it shows up as the third number
|
||||
under "havoc". That's because I'm lazy and I didn't want to mess with the UI
|
||||
too much ;)
|
||||
|
||||
|
||||
6) Trimming support
|
||||
-------------------
|
||||
|
||||
The generic trimming routines implemented in AFLFuzz can easily destroy the
|
||||
structure of complex formats, possibly leading to a point where you have a lot
|
||||
of testcases in the queue that your Python module cannot process anymore but
|
||||
your target application still accepts. This is especially the case when your
|
||||
target can process a part of the input (causing coverage) and then errors out
|
||||
on the remaining input.
|
||||
|
||||
In such cases, it makes sense to implement a custom trimming routine in Python.
|
||||
The API consists of multiple methods because after each trimming step, we have
|
||||
to go back into the C code to check if the coverage bitmap is still the same
|
||||
for the trimmed input. Here's a quick API description:
|
||||
|
||||
init_trim: This method is called at the start of each trimming operation
|
||||
and receives the initial buffer. It should return the amount
|
||||
of iteration steps possible on this input (e.g. if your input
|
||||
has n elements and you want to remove them one by one, return n,
|
||||
if you do a binary search, return log(n), and so on...).
|
||||
|
||||
If your trimming algorithm doesn't allow you to determine the
|
||||
amount of (remaining) steps easily (esp. while running), then you
|
||||
can alternatively return 1 here and always return 0 in post_trim
|
||||
until you are finished and no steps remain. In that case,
|
||||
returning 1 in post_trim will end the trimming routine. The whole
|
||||
current index/max iterations stuff is only used to show progress.
|
||||
|
||||
trim: This method is called for each trimming operation. It doesn't
|
||||
have any arguments because we already have the initial buffer
|
||||
from init_trim and we can memorize the current state in global
|
||||
variables. This can also save reparsing steps for each iteration.
|
||||
It should return the trimmed input buffer, where the returned data
|
||||
must not exceed the initial input data in length. Returning anything
|
||||
that is larger than the original data (passed to init_trim) will
|
||||
result in a fatal abort of AFLFuzz.
|
||||
|
||||
post_trim: This method is called after each trim operation to inform you
|
||||
if your trimming step was successful or not (in terms of coverage).
|
||||
If you receive a failure here, you should reset your input to the
|
||||
last known good state.
|
||||
In any case, this method must return the next trim iteration index
|
||||
(from 0 to the maximum amount of steps you returned in init_trim).
|
||||
|
||||
Omitting any of the methods will cause Python trimming to be disabled and
|
||||
trigger a fallback to the builtin default trimming routine.
|
||||
@ -6,6 +6,10 @@ Sister projects
|
||||
designed for, or meant to integrate with AFL. See README for the general
|
||||
instruction manual.
|
||||
|
||||
!!!
|
||||
!!! This list is outdated and needs an update, missing: e.g. Angora, FairFuzz
|
||||
!!!
|
||||
|
||||
-------------------------------------------
|
||||
Support for other languages / environments:
|
||||
-------------------------------------------
|
||||
@ -263,7 +267,7 @@ Static binary-only instrumentation (Aleksandar Nikolich)
|
||||
reports better performance compared to QEMU, but occasional translation
|
||||
errors with stripped binaries.
|
||||
|
||||
https://github.com/vrtadmin/moflow/tree/master/afl-dyninst
|
||||
https://github.com/vanhauser-thc/afl-dyninst
|
||||
|
||||
AFL PIN (Parker Thompson)
|
||||
-------------------------
|
||||
|
||||
@ -33,6 +33,16 @@ other side effects - sorry about that.
|
||||
|
||||
With that out of the way, let's talk about what's actually on the screen...
|
||||
|
||||
0) The status bar
|
||||
|
||||
The top line shows you which mode afl-fuzz is running in
|
||||
(normal: "american fuzy lop", crash exploration mode: "peruvian rabbit mode")
|
||||
and the version of afl++.
|
||||
Next to the version is the banner, which, if not set with -T by hand, will
|
||||
either show the binary name being fuzzed, or the -M/-S master/slave name for
|
||||
parallel fuzzing.
|
||||
Finally, the last item is the power schedule mode being run (default: explore).
|
||||
|
||||
1) Process timing
|
||||
-----------------
|
||||
|
||||
@ -397,6 +407,9 @@ directory. This includes:
|
||||
- variable_paths - number of test cases showing variable behavior
|
||||
- unique_crashes - number of unique crashes recorded
|
||||
- unique_hangs - number of unique hangs encountered
|
||||
- command_line - full command line used for the fuzzing session
|
||||
- slowest_exec_ms- real time of the slowest execution in seconds
|
||||
- peak_rss_mb - max rss usage reached during fuzzing in MB
|
||||
|
||||
Most of these map directly to the UI elements discussed earlier on.
|
||||
|
||||
|
||||
@ -1,12 +1,15 @@
|
||||
/*
|
||||
american fuzzy lop - injectable parts
|
||||
-------------------------------------
|
||||
american fuzzy lop++ - injectable parts
|
||||
---------------------------------------
|
||||
|
||||
Written and maintained by Michal Zalewski <lcamtuf@google.com>
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Forkserver design by Jann Horn <jannhorn@googlemail.com>
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2013, 2014, 2015 Google Inc. All rights reserved.
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
@ -37,7 +40,7 @@
|
||||
#include "config.h"
|
||||
#include "types.h"
|
||||
|
||||
/*
|
||||
/*
|
||||
------------------
|
||||
Performances notes
|
||||
------------------
|
||||
@ -106,47 +109,47 @@
|
||||
|
||||
static const u8* trampoline_fmt_32 =
|
||||
|
||||
"\n"
|
||||
"/* --- AFL TRAMPOLINE (32-BIT) --- */\n"
|
||||
"\n"
|
||||
".align 4\n"
|
||||
"\n"
|
||||
"leal -16(%%esp), %%esp\n"
|
||||
"movl %%edi, 0(%%esp)\n"
|
||||
"movl %%edx, 4(%%esp)\n"
|
||||
"movl %%ecx, 8(%%esp)\n"
|
||||
"movl %%eax, 12(%%esp)\n"
|
||||
"movl $0x%08x, %%ecx\n"
|
||||
"call __afl_maybe_log\n"
|
||||
"movl 12(%%esp), %%eax\n"
|
||||
"movl 8(%%esp), %%ecx\n"
|
||||
"movl 4(%%esp), %%edx\n"
|
||||
"movl 0(%%esp), %%edi\n"
|
||||
"leal 16(%%esp), %%esp\n"
|
||||
"\n"
|
||||
"/* --- END --- */\n"
|
||||
"\n";
|
||||
"\n"
|
||||
"/* --- AFL TRAMPOLINE (32-BIT) --- */\n"
|
||||
"\n"
|
||||
".align 4\n"
|
||||
"\n"
|
||||
"leal -16(%%esp), %%esp\n"
|
||||
"movl %%edi, 0(%%esp)\n"
|
||||
"movl %%edx, 4(%%esp)\n"
|
||||
"movl %%ecx, 8(%%esp)\n"
|
||||
"movl %%eax, 12(%%esp)\n"
|
||||
"movl $0x%08x, %%ecx\n"
|
||||
"call __afl_maybe_log\n"
|
||||
"movl 12(%%esp), %%eax\n"
|
||||
"movl 8(%%esp), %%ecx\n"
|
||||
"movl 4(%%esp), %%edx\n"
|
||||
"movl 0(%%esp), %%edi\n"
|
||||
"leal 16(%%esp), %%esp\n"
|
||||
"\n"
|
||||
"/* --- END --- */\n"
|
||||
"\n";
|
||||
|
||||
static const u8* trampoline_fmt_64 =
|
||||
|
||||
"\n"
|
||||
"/* --- AFL TRAMPOLINE (64-BIT) --- */\n"
|
||||
"\n"
|
||||
".align 4\n"
|
||||
"\n"
|
||||
"leaq -(128+24)(%%rsp), %%rsp\n"
|
||||
"movq %%rdx, 0(%%rsp)\n"
|
||||
"movq %%rcx, 8(%%rsp)\n"
|
||||
"movq %%rax, 16(%%rsp)\n"
|
||||
"movq $0x%08x, %%rcx\n"
|
||||
"call __afl_maybe_log\n"
|
||||
"movq 16(%%rsp), %%rax\n"
|
||||
"movq 8(%%rsp), %%rcx\n"
|
||||
"movq 0(%%rsp), %%rdx\n"
|
||||
"leaq (128+24)(%%rsp), %%rsp\n"
|
||||
"\n"
|
||||
"/* --- END --- */\n"
|
||||
"\n";
|
||||
"\n"
|
||||
"/* --- AFL TRAMPOLINE (64-BIT) --- */\n"
|
||||
"\n"
|
||||
".align 4\n"
|
||||
"\n"
|
||||
"leaq -(128+24)(%%rsp), %%rsp\n"
|
||||
"movq %%rdx, 0(%%rsp)\n"
|
||||
"movq %%rcx, 8(%%rsp)\n"
|
||||
"movq %%rax, 16(%%rsp)\n"
|
||||
"movq $0x%08x, %%rcx\n"
|
||||
"call __afl_maybe_log\n"
|
||||
"movq 16(%%rsp), %%rax\n"
|
||||
"movq 8(%%rsp), %%rcx\n"
|
||||
"movq 0(%%rsp), %%rdx\n"
|
||||
"leaq (128+24)(%%rsp), %%rsp\n"
|
||||
"\n"
|
||||
"/* --- END --- */\n"
|
||||
"\n";
|
||||
|
||||
static const u8* main_payload_32 =
|
||||
|
||||
@ -183,13 +186,14 @@ static const u8* main_payload_32 =
|
||||
" movl %ecx, __afl_prev_loc\n"
|
||||
#else
|
||||
" movl %ecx, %edi\n"
|
||||
#endif /* ^!COVERAGE_ONLY */
|
||||
#endif /* ^!COVERAGE_ONLY */
|
||||
"\n"
|
||||
#ifdef SKIP_COUNTS
|
||||
" orb $1, (%edx, %edi, 1)\n"
|
||||
#else
|
||||
" incb (%edx, %edi, 1)\n"
|
||||
#endif /* ^SKIP_COUNTS */
|
||||
" adcb $0, (%edx, %edi, 1)\n" // never zero counter implementation. slightly better path discovery and little performance impact
|
||||
#endif /* ^SKIP_COUNTS */
|
||||
"\n"
|
||||
"__afl_return:\n"
|
||||
"\n"
|
||||
@ -220,6 +224,29 @@ static const u8* main_payload_32 =
|
||||
" testl %eax, %eax\n"
|
||||
" je __afl_setup_abort\n"
|
||||
"\n"
|
||||
#ifdef USEMMAP
|
||||
" pushl $384 /* shm_open mode 0600 */\n"
|
||||
" pushl $2 /* flags O_RDWR */\n"
|
||||
" pushl %eax /* SHM file path */\n"
|
||||
" call shm_open\n"
|
||||
" addl $12, %esp\n"
|
||||
"\n"
|
||||
" cmpl $-1, %eax\n"
|
||||
" je __afl_setup_abort\n"
|
||||
"\n"
|
||||
" pushl $0 /* mmap off */\n"
|
||||
" pushl %eax /* shm fd */\n"
|
||||
" pushl $1 /* mmap flags */\n"
|
||||
" pushl $3 /* mmap prot */\n"
|
||||
" pushl $"STRINGIFY(MAP_SIZE)" /* mmap len */\n"
|
||||
" pushl $0 /* mmap addr */\n"
|
||||
" call mmap\n"
|
||||
" addl $12, %esp\n"
|
||||
"\n"
|
||||
" cmpl $-1, %eax\n"
|
||||
" je __afl_setup_abort\n"
|
||||
"\n"
|
||||
#else
|
||||
" pushl %eax\n"
|
||||
" call atoi\n"
|
||||
" addl $4, %esp\n"
|
||||
@ -233,6 +260,7 @@ static const u8* main_payload_32 =
|
||||
" cmpl $-1, %eax\n"
|
||||
" je __afl_setup_abort\n"
|
||||
"\n"
|
||||
#endif
|
||||
" /* Store the address of the SHM region. */\n"
|
||||
"\n"
|
||||
" movl %eax, __afl_area_ptr\n"
|
||||
@ -354,7 +382,7 @@ static const u8* main_payload_32 =
|
||||
" .comm __afl_setup_failure, 1, 32\n"
|
||||
#ifndef COVERAGE_ONLY
|
||||
" .comm __afl_prev_loc, 4, 32\n"
|
||||
#endif /* !COVERAGE_ONLY */
|
||||
#endif /* !COVERAGE_ONLY */
|
||||
" .comm __afl_fork_pid, 4, 32\n"
|
||||
" .comm __afl_temp, 4, 32\n"
|
||||
"\n"
|
||||
@ -373,10 +401,10 @@ static const u8* main_payload_32 =
|
||||
recognize .string. */
|
||||
|
||||
#ifdef __APPLE__
|
||||
# define CALL_L64(str) "call _" str "\n"
|
||||
#define CALL_L64(str) "call _" str "\n"
|
||||
#else
|
||||
# define CALL_L64(str) "call " str "@PLT\n"
|
||||
#endif /* ^__APPLE__ */
|
||||
#define CALL_L64(str) "call " str "@PLT\n"
|
||||
#endif /* ^__APPLE__ */
|
||||
|
||||
static const u8* main_payload_64 =
|
||||
|
||||
@ -390,11 +418,11 @@ static const u8* main_payload_64 =
|
||||
"\n"
|
||||
"__afl_maybe_log:\n"
|
||||
"\n"
|
||||
#if defined(__OpenBSD__) || (defined(__FreeBSD__) && (__FreeBSD__ < 9))
|
||||
#if defined(__OpenBSD__) || (defined(__FreeBSD__) && (__FreeBSD__ < 9))
|
||||
" .byte 0x9f /* lahf */\n"
|
||||
#else
|
||||
" lahf\n"
|
||||
#endif /* ^__OpenBSD__, etc */
|
||||
#endif /* ^__OpenBSD__, etc */
|
||||
" seto %al\n"
|
||||
"\n"
|
||||
" /* Check if SHM region is already mapped. */\n"
|
||||
@ -411,22 +439,23 @@ static const u8* main_payload_64 =
|
||||
" xorq __afl_prev_loc(%rip), %rcx\n"
|
||||
" xorq %rcx, __afl_prev_loc(%rip)\n"
|
||||
" shrq $1, __afl_prev_loc(%rip)\n"
|
||||
#endif /* ^!COVERAGE_ONLY */
|
||||
#endif /* ^!COVERAGE_ONLY */
|
||||
"\n"
|
||||
#ifdef SKIP_COUNTS
|
||||
" orb $1, (%rdx, %rcx, 1)\n"
|
||||
#else
|
||||
" incb (%rdx, %rcx, 1)\n"
|
||||
#endif /* ^SKIP_COUNTS */
|
||||
" adcb $0, (%rdx, %rcx, 1)\n" // never zero counter implementation. slightly better path discovery and little performance impact
|
||||
#endif /* ^SKIP_COUNTS */
|
||||
"\n"
|
||||
"__afl_return:\n"
|
||||
"\n"
|
||||
" addb $127, %al\n"
|
||||
#if defined(__OpenBSD__) || (defined(__FreeBSD__) && (__FreeBSD__ < 9))
|
||||
#if defined(__OpenBSD__) || (defined(__FreeBSD__) && (__FreeBSD__ < 9))
|
||||
" .byte 0x9e /* sahf */\n"
|
||||
#else
|
||||
" sahf\n"
|
||||
#endif /* ^__OpenBSD__, etc */
|
||||
#endif /* ^__OpenBSD__, etc */
|
||||
" ret\n"
|
||||
"\n"
|
||||
".align 8\n"
|
||||
@ -445,7 +474,7 @@ static const u8* main_payload_64 =
|
||||
" movq (%rdx), %rdx\n"
|
||||
#else
|
||||
" movq __afl_global_area_ptr(%rip), %rdx\n"
|
||||
#endif /* !^__APPLE__ */
|
||||
#endif /* !^__APPLE__ */
|
||||
" testq %rdx, %rdx\n"
|
||||
" je __afl_setup_first\n"
|
||||
"\n"
|
||||
@ -501,6 +530,27 @@ static const u8* main_payload_64 =
|
||||
" testq %rax, %rax\n"
|
||||
" je __afl_setup_abort\n"
|
||||
"\n"
|
||||
#ifdef USEMMAP
|
||||
" movl $384, %edx /* shm_open mode 0600 */\n"
|
||||
" movl $2, %esi /* flags O_RDWR */\n"
|
||||
" movq %rax, %rdi /* SHM file path */\n"
|
||||
CALL_L64("shm_open")
|
||||
"\n"
|
||||
" cmpq $-1, %rax\n"
|
||||
" je __afl_setup_abort\n"
|
||||
"\n"
|
||||
" movl $0, %r9d\n"
|
||||
" movl %eax, %r8d\n"
|
||||
" movl $1, %ecx\n"
|
||||
" movl $3, %edx\n"
|
||||
" movl $"STRINGIFY(MAP_SIZE)", %esi\n"
|
||||
" movl $0, %edi\n"
|
||||
CALL_L64("mmap")
|
||||
"\n"
|
||||
" cmpq $-1, %rax\n"
|
||||
" je __afl_setup_abort\n"
|
||||
"\n"
|
||||
#else
|
||||
" movq %rax, %rdi\n"
|
||||
CALL_L64("atoi")
|
||||
"\n"
|
||||
@ -512,6 +562,7 @@ static const u8* main_payload_64 =
|
||||
" cmpq $-1, %rax\n"
|
||||
" je __afl_setup_abort\n"
|
||||
"\n"
|
||||
#endif
|
||||
" /* Store the address of the SHM region. */\n"
|
||||
"\n"
|
||||
" movq %rax, %rdx\n"
|
||||
@ -522,7 +573,7 @@ static const u8* main_payload_64 =
|
||||
#else
|
||||
" movq __afl_global_area_ptr@GOTPCREL(%rip), %rdx\n"
|
||||
" movq %rax, (%rdx)\n"
|
||||
#endif /* ^__APPLE__ */
|
||||
#endif /* ^__APPLE__ */
|
||||
" movq %rax, %rdx\n"
|
||||
"\n"
|
||||
"__afl_forkserver:\n"
|
||||
@ -691,7 +742,7 @@ static const u8* main_payload_64 =
|
||||
" .comm __afl_area_ptr, 8\n"
|
||||
#ifndef COVERAGE_ONLY
|
||||
" .comm __afl_prev_loc, 8\n"
|
||||
#endif /* !COVERAGE_ONLY */
|
||||
#endif /* !COVERAGE_ONLY */
|
||||
" .comm __afl_fork_pid, 4\n"
|
||||
" .comm __afl_temp, 4\n"
|
||||
" .comm __afl_setup_failure, 1\n"
|
||||
@ -701,12 +752,12 @@ static const u8* main_payload_64 =
|
||||
" .lcomm __afl_area_ptr, 8\n"
|
||||
#ifndef COVERAGE_ONLY
|
||||
" .lcomm __afl_prev_loc, 8\n"
|
||||
#endif /* !COVERAGE_ONLY */
|
||||
#endif /* !COVERAGE_ONLY */
|
||||
" .lcomm __afl_fork_pid, 4\n"
|
||||
" .lcomm __afl_temp, 4\n"
|
||||
" .lcomm __afl_setup_failure, 1\n"
|
||||
|
||||
#endif /* ^__APPLE__ */
|
||||
#endif /* ^__APPLE__ */
|
||||
|
||||
" .comm __afl_global_area_ptr, 8, 8\n"
|
||||
"\n"
|
||||
@ -716,4 +767,5 @@ static const u8* main_payload_64 =
|
||||
"/* --- END --- */\n"
|
||||
"\n";
|
||||
|
||||
#endif /* !_HAVE_AFL_AS_H */
|
||||
#endif /* !_HAVE_AFL_AS_H */
|
||||
|
||||
662
include/afl-fuzz.h
Normal file
662
include/afl-fuzz.h
Normal file
@ -0,0 +1,662 @@
|
||||
/*
|
||||
american fuzzy lop++ - fuzzer header
|
||||
------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This is the real deal: the program takes an instrumented binary and
|
||||
attempts a variety of basic fuzzing tricks, paying close attention to
|
||||
how they affect the execution path.
|
||||
|
||||
*/
|
||||
|
||||
#ifndef _AFL_FUZZ_H
|
||||
#define _AFL_FUZZ_H
|
||||
|
||||
#define AFL_MAIN
|
||||
#define MESSAGES_TO_STDOUT
|
||||
|
||||
#ifndef _GNU_SOURCE
|
||||
#define _GNU_SOURCE
|
||||
#endif
|
||||
#define _FILE_OFFSET_BITS 64
|
||||
|
||||
#ifdef __ANDROID__
|
||||
#include "android-ashmem.h"
|
||||
#endif
|
||||
|
||||
#include "config.h"
|
||||
#include "types.h"
|
||||
#include "debug.h"
|
||||
#include "alloc-inl.h"
|
||||
#include "hash.h"
|
||||
#include "sharedmem.h"
|
||||
#include "forkserver.h"
|
||||
#include "common.h"
|
||||
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
#include <time.h>
|
||||
#include <errno.h>
|
||||
#include <signal.h>
|
||||
#include <dirent.h>
|
||||
#include <ctype.h>
|
||||
#include <fcntl.h>
|
||||
#include <termios.h>
|
||||
#include <dlfcn.h>
|
||||
#include <sched.h>
|
||||
|
||||
#include <sys/wait.h>
|
||||
#include <sys/time.h>
|
||||
#include <sys/shm.h>
|
||||
#include <sys/stat.h>
|
||||
#include <sys/types.h>
|
||||
#include <sys/resource.h>
|
||||
#include <sys/mman.h>
|
||||
#include <sys/ioctl.h>
|
||||
#include <sys/file.h>
|
||||
|
||||
#if defined(__APPLE__) || defined(__FreeBSD__) || defined(__OpenBSD__)
|
||||
#include <sys/sysctl.h>
|
||||
#define HAVE_ARC4RANDOM 1
|
||||
#endif /* __APPLE__ || __FreeBSD__ || __OpenBSD__ */
|
||||
|
||||
/* For systems that have sched_setaffinity; right now just Linux, but one
|
||||
can hope... */
|
||||
|
||||
#ifdef __linux__
|
||||
#define HAVE_AFFINITY 1
|
||||
#endif /* __linux__ */
|
||||
|
||||
#ifndef SIMPLE_FILES
|
||||
#define CASE_PREFIX "id:"
|
||||
#else
|
||||
#define CASE_PREFIX "id_"
|
||||
#endif /* ^!SIMPLE_FILES */
|
||||
|
||||
struct queue_entry {
|
||||
|
||||
u8* fname; /* File name for the test case */
|
||||
u32 len; /* Input length */
|
||||
|
||||
u8 cal_failed, /* Calibration failed? */
|
||||
trim_done, /* Trimmed? */
|
||||
was_fuzzed, /* historical, but needed for MOpt */
|
||||
passed_det, /* Deterministic stages passed? */
|
||||
has_new_cov, /* Triggers new coverage? */
|
||||
var_behavior, /* Variable behavior? */
|
||||
favored, /* Currently favored? */
|
||||
fs_redundant; /* Marked as redundant in the fs? */
|
||||
|
||||
u32 bitmap_size, /* Number of bits set in bitmap */
|
||||
fuzz_level, /* Number of fuzzing iterations */
|
||||
exec_cksum; /* Checksum of the execution trace */
|
||||
|
||||
u64 exec_us, /* Execution time (us) */
|
||||
handicap, /* Number of queue cycles behind */
|
||||
n_fuzz, /* Number of fuzz, does not overflow */
|
||||
depth; /* Path depth */
|
||||
|
||||
u8* trace_mini; /* Trace bytes, if kept */
|
||||
u32 tc_ref; /* Trace bytes ref count */
|
||||
|
||||
struct queue_entry *next, /* Next element, if any */
|
||||
*next_100; /* 100 elements ahead */
|
||||
|
||||
};
|
||||
|
||||
struct extra_data {
|
||||
|
||||
u8* data; /* Dictionary token data */
|
||||
u32 len; /* Dictionary token length */
|
||||
u32 hit_cnt; /* Use count in the corpus */
|
||||
|
||||
};
|
||||
|
||||
/* Fuzzing stages */
|
||||
|
||||
enum {
|
||||
|
||||
/* 00 */ STAGE_FLIP1,
|
||||
/* 01 */ STAGE_FLIP2,
|
||||
/* 02 */ STAGE_FLIP4,
|
||||
/* 03 */ STAGE_FLIP8,
|
||||
/* 04 */ STAGE_FLIP16,
|
||||
/* 05 */ STAGE_FLIP32,
|
||||
/* 06 */ STAGE_ARITH8,
|
||||
/* 07 */ STAGE_ARITH16,
|
||||
/* 08 */ STAGE_ARITH32,
|
||||
/* 09 */ STAGE_INTEREST8,
|
||||
/* 10 */ STAGE_INTEREST16,
|
||||
/* 11 */ STAGE_INTEREST32,
|
||||
/* 12 */ STAGE_EXTRAS_UO,
|
||||
/* 13 */ STAGE_EXTRAS_UI,
|
||||
/* 14 */ STAGE_EXTRAS_AO,
|
||||
/* 15 */ STAGE_HAVOC,
|
||||
/* 16 */ STAGE_SPLICE,
|
||||
/* 17 */ STAGE_PYTHON,
|
||||
/* 18 */ STAGE_CUSTOM_MUTATOR
|
||||
|
||||
};
|
||||
|
||||
/* Stage value types */
|
||||
|
||||
enum {
|
||||
|
||||
/* 00 */ STAGE_VAL_NONE,
|
||||
/* 01 */ STAGE_VAL_LE,
|
||||
/* 02 */ STAGE_VAL_BE
|
||||
|
||||
};
|
||||
|
||||
/* Execution status fault codes */
|
||||
|
||||
enum {
|
||||
|
||||
/* 00 */ FAULT_NONE,
|
||||
/* 01 */ FAULT_TMOUT,
|
||||
/* 02 */ FAULT_CRASH,
|
||||
/* 03 */ FAULT_ERROR,
|
||||
/* 04 */ FAULT_NOINST,
|
||||
/* 05 */ FAULT_NOBITS
|
||||
|
||||
};
|
||||
|
||||
/* MOpt:
|
||||
Lots of globals, but mostly for the status UI and other things where it
|
||||
really makes no sense to haul them around as function parameters. */
|
||||
extern u64 limit_time_puppet, orig_hit_cnt_puppet, last_limit_time_start,
|
||||
tmp_pilot_time, total_pacemaker_time, total_puppet_find, temp_puppet_find,
|
||||
most_time_key, most_time, most_execs_key, most_execs, old_hit_count;
|
||||
|
||||
extern s32 SPLICE_CYCLES_puppet, limit_time_sig, key_puppet, key_module;
|
||||
|
||||
extern double w_init, w_end, w_now;
|
||||
|
||||
extern s32 g_now;
|
||||
extern s32 g_max;
|
||||
|
||||
#define operator_num 16
|
||||
#define swarm_num 5
|
||||
#define period_core 500000
|
||||
|
||||
extern u64 tmp_core_time;
|
||||
extern s32 swarm_now;
|
||||
|
||||
extern double x_now[swarm_num][operator_num], L_best[swarm_num][operator_num],
|
||||
eff_best[swarm_num][operator_num], G_best[operator_num],
|
||||
v_now[swarm_num][operator_num], probability_now[swarm_num][operator_num],
|
||||
swarm_fitness[swarm_num];
|
||||
|
||||
extern u64 stage_finds_puppet[swarm_num][operator_num], /* Patterns found per
|
||||
fuzz stage */
|
||||
stage_finds_puppet_v2[swarm_num][operator_num],
|
||||
stage_cycles_puppet_v2[swarm_num][operator_num],
|
||||
stage_cycles_puppet_v3[swarm_num][operator_num],
|
||||
stage_cycles_puppet[swarm_num][operator_num],
|
||||
operator_finds_puppet[operator_num],
|
||||
core_operator_finds_puppet[operator_num],
|
||||
core_operator_finds_puppet_v2[operator_num],
|
||||
core_operator_cycles_puppet[operator_num],
|
||||
core_operator_cycles_puppet_v2[operator_num],
|
||||
core_operator_cycles_puppet_v3[operator_num]; /* Execs per fuzz stage */
|
||||
|
||||
#define RAND_C (rand() % 1000 * 0.001)
|
||||
#define v_max 1
|
||||
#define v_min 0.05
|
||||
#define limit_time_bound 1.1
|
||||
#define SPLICE_CYCLES_puppet_up 25
|
||||
#define SPLICE_CYCLES_puppet_low 5
|
||||
#define STAGE_RANDOMBYTE 12
|
||||
#define STAGE_DELETEBYTE 13
|
||||
#define STAGE_Clone75 14
|
||||
#define STAGE_OverWrite75 15
|
||||
#define period_pilot 50000
|
||||
|
||||
extern double period_pilot_tmp;
|
||||
extern s32 key_lv;
|
||||
|
||||
extern u8 *in_dir, /* Input directory with test cases */
|
||||
*out_dir, /* Working & output directory */
|
||||
*tmp_dir, /* Temporary directory for input */
|
||||
*sync_dir, /* Synchronization directory */
|
||||
*sync_id, /* Fuzzer ID */
|
||||
*power_name, /* Power schedule name */
|
||||
*use_banner, /* Display banner */
|
||||
*in_bitmap, /* Input bitmap */
|
||||
*file_extension, /* File extension */
|
||||
*orig_cmdline, /* Original command line */
|
||||
*doc_path, /* Path to documentation dir */
|
||||
*target_path, /* Path to target binary */
|
||||
*out_file; /* File to fuzz, if any */
|
||||
|
||||
extern u32 exec_tmout; /* Configurable exec timeout (ms) */
|
||||
extern u32 hang_tmout; /* Timeout used for hang det (ms) */
|
||||
|
||||
extern u64 mem_limit; /* Memory cap for child (MB) */
|
||||
|
||||
extern u8 cal_cycles, /* Calibration cycles defaults */
|
||||
cal_cycles_long, debug, /* Debug mode */
|
||||
python_only; /* Python-only mode */
|
||||
|
||||
extern u32 stats_update_freq; /* Stats update frequency (execs) */
|
||||
|
||||
enum {
|
||||
|
||||
/* 00 */ EXPLORE, /* AFL default, Exploration-based constant schedule */
|
||||
/* 01 */ FAST, /* Exponential schedule */
|
||||
/* 02 */ COE, /* Cut-Off Exponential schedule */
|
||||
/* 03 */ LIN, /* Linear schedule */
|
||||
/* 04 */ QUAD, /* Quadratic schedule */
|
||||
/* 05 */ EXPLOIT, /* AFL's exploitation-based const. */
|
||||
|
||||
POWER_SCHEDULES_NUM
|
||||
|
||||
};
|
||||
|
||||
extern char* power_names[POWER_SCHEDULES_NUM];
|
||||
|
||||
extern u8 schedule; /* Power schedule (default: EXPLORE)*/
|
||||
extern u8 havoc_max_mult;
|
||||
|
||||
extern u8 skip_deterministic, /* Skip deterministic stages? */
|
||||
force_deterministic, /* Force deterministic stages? */
|
||||
use_splicing, /* Recombine input files? */
|
||||
dumb_mode, /* Run in non-instrumented mode? */
|
||||
score_changed, /* Scoring for favorites changed? */
|
||||
kill_signal, /* Signal that killed the child */
|
||||
resuming_fuzz, /* Resuming an older fuzzing job? */
|
||||
timeout_given, /* Specific timeout given? */
|
||||
not_on_tty, /* stdout is not a tty */
|
||||
term_too_small, /* terminal dimensions too small */
|
||||
no_forkserver, /* Disable forkserver? */
|
||||
crash_mode, /* Crash mode! Yeah! */
|
||||
in_place_resume, /* Attempt in-place resume? */
|
||||
auto_changed, /* Auto-generated tokens changed? */
|
||||
no_cpu_meter_red, /* Feng shui on the status screen */
|
||||
no_arith, /* Skip most arithmetic ops */
|
||||
shuffle_queue, /* Shuffle input queue? */
|
||||
bitmap_changed, /* Time to update bitmap? */
|
||||
qemu_mode, /* Running in QEMU mode? */
|
||||
unicorn_mode, /* Running in Unicorn mode? */
|
||||
skip_requested, /* Skip request, via SIGUSR1 */
|
||||
run_over10m, /* Run time over 10 minutes? */
|
||||
persistent_mode, /* Running in persistent mode? */
|
||||
deferred_mode, /* Deferred forkserver mode? */
|
||||
fixed_seed, /* do not reseed */
|
||||
fast_cal, /* Try to calibrate faster? */
|
||||
uses_asan; /* Target uses ASAN? */
|
||||
|
||||
extern s32 out_fd, /* Persistent fd for out_file */
|
||||
#ifndef HAVE_ARC4RANDOM
|
||||
dev_urandom_fd, /* Persistent fd for /dev/urandom */
|
||||
#endif
|
||||
dev_null_fd, /* Persistent fd for /dev/null */
|
||||
fsrv_ctl_fd, /* Fork server control pipe (write) */
|
||||
fsrv_st_fd; /* Fork server status pipe (read) */
|
||||
|
||||
extern s32 forksrv_pid, /* PID of the fork server */
|
||||
child_pid, /* PID of the fuzzed program */
|
||||
out_dir_fd; /* FD of the lock file */
|
||||
|
||||
extern u8* trace_bits; /* SHM with instrumentation bitmap */
|
||||
|
||||
extern u8 virgin_bits[MAP_SIZE], /* Regions yet untouched by fuzzing */
|
||||
virgin_tmout[MAP_SIZE], /* Bits we haven't seen in tmouts */
|
||||
virgin_crash[MAP_SIZE]; /* Bits we haven't seen in crashes */
|
||||
|
||||
extern u8 var_bytes[MAP_SIZE]; /* Bytes that appear to be variable */
|
||||
|
||||
extern volatile u8 stop_soon, /* Ctrl-C pressed? */
|
||||
clear_screen, /* Window resized? */
|
||||
child_timed_out; /* Traced process timed out? */
|
||||
|
||||
extern u32 queued_paths, /* Total number of queued testcases */
|
||||
queued_variable, /* Testcases with variable behavior */
|
||||
queued_at_start, /* Total number of initial inputs */
|
||||
queued_discovered, /* Items discovered during this run */
|
||||
queued_imported, /* Items imported via -S */
|
||||
queued_favored, /* Paths deemed favorable */
|
||||
queued_with_cov, /* Paths with new coverage bytes */
|
||||
pending_not_fuzzed, /* Queued but not done yet */
|
||||
pending_favored, /* Pending favored paths */
|
||||
cur_skipped_paths, /* Abandoned inputs in cur cycle */
|
||||
cur_depth, /* Current path depth */
|
||||
max_depth, /* Max path depth */
|
||||
useless_at_start, /* Number of useless starting paths */
|
||||
var_byte_count, /* Bitmap bytes with var behavior */
|
||||
current_entry, /* Current queue entry ID */
|
||||
havoc_div; /* Cycle count divisor for havoc */
|
||||
|
||||
extern u64 total_crashes, /* Total number of crashes */
|
||||
unique_crashes, /* Crashes with unique signatures */
|
||||
total_tmouts, /* Total number of timeouts */
|
||||
unique_tmouts, /* Timeouts with unique signatures */
|
||||
unique_hangs, /* Hangs with unique signatures */
|
||||
total_execs, /* Total execve() calls */
|
||||
slowest_exec_ms, /* Slowest testcase non hang in ms */
|
||||
start_time, /* Unix start time (ms) */
|
||||
last_path_time, /* Time for most recent path (ms) */
|
||||
last_crash_time, /* Time for most recent crash (ms) */
|
||||
last_hang_time, /* Time for most recent hang (ms) */
|
||||
last_crash_execs, /* Exec counter at last crash */
|
||||
queue_cycle, /* Queue round counter */
|
||||
cycles_wo_finds, /* Cycles without any new paths */
|
||||
trim_execs, /* Execs done to trim input files */
|
||||
bytes_trim_in, /* Bytes coming into the trimmer */
|
||||
bytes_trim_out, /* Bytes coming outa the trimmer */
|
||||
blocks_eff_total, /* Blocks subject to effector maps */
|
||||
blocks_eff_select; /* Blocks selected as fuzzable */
|
||||
|
||||
extern u32 subseq_tmouts; /* Number of timeouts in a row */
|
||||
|
||||
extern u8 *stage_name, /* Name of the current fuzz stage */
|
||||
*stage_short, /* Short stage name */
|
||||
*syncing_party; /* Currently syncing with... */
|
||||
|
||||
extern s32 stage_cur, stage_max; /* Stage progression */
|
||||
extern s32 splicing_with; /* Splicing with which test case? */
|
||||
|
||||
extern u32 master_id, master_max; /* Master instance job splitting */
|
||||
|
||||
extern u32 syncing_case; /* Syncing with case #... */
|
||||
|
||||
extern s32 stage_cur_byte, /* Byte offset of current stage op */
|
||||
stage_cur_val; /* Value used for stage op */
|
||||
|
||||
extern u8 stage_val_type; /* Value type (STAGE_VAL_*) */
|
||||
|
||||
extern u64 stage_finds[32], /* Patterns found per fuzz stage */
|
||||
stage_cycles[32]; /* Execs per fuzz stage */
|
||||
|
||||
#ifndef HAVE_ARC4RANDOM
|
||||
extern u32 rand_cnt; /* Random number counter */
|
||||
#endif
|
||||
|
||||
extern u64 total_cal_us, /* Total calibration time (us) */
|
||||
total_cal_cycles; /* Total calibration cycles */
|
||||
|
||||
extern u64 total_bitmap_size, /* Total bit count for all bitmaps */
|
||||
total_bitmap_entries; /* Number of bitmaps counted */
|
||||
|
||||
extern s32 cpu_core_count; /* CPU core count */
|
||||
|
||||
#ifdef HAVE_AFFINITY
|
||||
|
||||
extern s32 cpu_aff; /* Selected CPU core */
|
||||
|
||||
#endif /* HAVE_AFFINITY */
|
||||
|
||||
extern FILE* plot_file; /* Gnuplot output file */
|
||||
|
||||
extern struct queue_entry *queue, /* Fuzzing queue (linked list) */
|
||||
*queue_cur, /* Current offset within the queue */
|
||||
*queue_top, /* Top of the list */
|
||||
*q_prev100; /* Previous 100 marker */
|
||||
|
||||
extern struct queue_entry*
|
||||
top_rated[MAP_SIZE]; /* Top entries for bitmap bytes */
|
||||
|
||||
extern struct extra_data* extras; /* Extra tokens to fuzz with */
|
||||
extern u32 extras_cnt; /* Total number of tokens read */
|
||||
|
||||
extern struct extra_data* a_extras; /* Automatically selected extras */
|
||||
extern u32 a_extras_cnt; /* Total number of tokens available */
|
||||
|
||||
u8* (*post_handler)(u8* buf, u32* len);
|
||||
|
||||
/* hooks for the custom mutator function */
|
||||
/**
|
||||
* Perform custom mutations on a given input
|
||||
* @param data Input data to be mutated
|
||||
* @param size Size of input data
|
||||
* @param mutated_out Buffer to store the mutated input
|
||||
* @param max_size Maximum size of the mutated output. The mutation must not
|
||||
* produce data larger than max_size.
|
||||
* @param seed Seed used for the mutation. The mutation should produce the same
|
||||
* output given the same seed.
|
||||
* @return Size of the mutated output.
|
||||
*/
|
||||
size_t (*custom_mutator)(u8* data, size_t size, u8* mutated_out,
|
||||
size_t max_size, unsigned int seed);
|
||||
/**
|
||||
* A post-processing function to use right before AFL writes the test case to
|
||||
* disk in order to execute the target. If this functionality is not needed,
|
||||
* Simply don't define this function.
|
||||
* @param data Buffer containing the test case to be executed.
|
||||
* @param size Size of the test case.
|
||||
* @param new_data Buffer to store the test case after processing
|
||||
* @return Size of data after processing.
|
||||
*/
|
||||
size_t (*pre_save_handler)(u8* data, size_t size, u8** new_data);
|
||||
|
||||
/* Interesting values, as per config.h */
|
||||
|
||||
extern s8 interesting_8[INTERESTING_8_LEN];
|
||||
extern s16 interesting_16[INTERESTING_8_LEN + INTERESTING_16_LEN];
|
||||
extern s32
|
||||
interesting_32[INTERESTING_8_LEN + INTERESTING_16_LEN + INTERESTING_32_LEN];
|
||||
|
||||
/* Python stuff */
|
||||
#ifdef USE_PYTHON
|
||||
|
||||
#include <Python.h>
|
||||
|
||||
extern PyObject* py_module;
|
||||
|
||||
enum {
|
||||
|
||||
/* 00 */ PY_FUNC_INIT,
|
||||
/* 01 */ PY_FUNC_FUZZ,
|
||||
/* 02 */ PY_FUNC_INIT_TRIM,
|
||||
/* 03 */ PY_FUNC_POST_TRIM,
|
||||
/* 04 */ PY_FUNC_TRIM,
|
||||
PY_FUNC_COUNT
|
||||
|
||||
};
|
||||
|
||||
extern PyObject* py_functions[PY_FUNC_COUNT];
|
||||
|
||||
#endif
|
||||
|
||||
/**** Prototypes ****/
|
||||
|
||||
/* Python */
|
||||
#ifdef USE_PYTHON
|
||||
int init_py();
|
||||
void finalize_py();
|
||||
void fuzz_py(char*, size_t, char*, size_t, char**, size_t*);
|
||||
u32 init_trim_py(char*, size_t);
|
||||
u32 post_trim_py(char);
|
||||
void trim_py(char**, size_t*);
|
||||
u8 trim_case_python(char**, struct queue_entry*, u8*);
|
||||
#endif
|
||||
|
||||
/* Queue */
|
||||
|
||||
void mark_as_det_done(struct queue_entry*);
|
||||
void mark_as_variable(struct queue_entry*);
|
||||
void mark_as_redundant(struct queue_entry*, u8);
|
||||
void add_to_queue(u8*, u32, u8);
|
||||
void destroy_queue(void);
|
||||
void update_bitmap_score(struct queue_entry*);
|
||||
void cull_queue(void);
|
||||
u32 calculate_score(struct queue_entry*);
|
||||
|
||||
/* Bitmap */
|
||||
|
||||
void write_bitmap(void);
|
||||
void read_bitmap(u8*);
|
||||
u8 has_new_bits(u8*);
|
||||
u32 count_bits(u8*);
|
||||
u32 count_bytes(u8*);
|
||||
u32 count_non_255_bytes(u8*);
|
||||
#ifdef __x86_64__
|
||||
void simplify_trace(u64*);
|
||||
void classify_counts(u64*);
|
||||
#else
|
||||
void simplify_trace(u32*);
|
||||
void classify_counts(u32*);
|
||||
#endif
|
||||
void init_count_class16(void);
|
||||
void minimize_bits(u8*, u8*);
|
||||
#ifndef SIMPLE_FILES
|
||||
u8* describe_op(u8);
|
||||
#endif
|
||||
u8 save_if_interesting(char**, void*, u32, u8);
|
||||
|
||||
/* Misc */
|
||||
|
||||
u8* DI(u64);
|
||||
u8* DF(double);
|
||||
u8* DMS(u64);
|
||||
u8* DTD(u64, u64);
|
||||
|
||||
/* Extras */
|
||||
|
||||
void load_extras_file(u8*, u32*, u32*, u32);
|
||||
void load_extras(u8*);
|
||||
void maybe_add_auto(u8*, u32);
|
||||
void save_auto(void);
|
||||
void load_auto(void);
|
||||
void destroy_extras(void);
|
||||
|
||||
/* Stats */
|
||||
|
||||
void write_stats_file(double, double, double);
|
||||
void maybe_update_plot_file(double, double);
|
||||
void show_stats(void);
|
||||
void show_init_stats(void);
|
||||
|
||||
/* Run */
|
||||
|
||||
u8 run_target(char**, u32);
|
||||
void write_to_testcase(void*, u32);
|
||||
void write_with_gap(void*, u32, u32, u32);
|
||||
u8 calibrate_case(char**, struct queue_entry*, u8*, u32, u8);
|
||||
void sync_fuzzers(char**);
|
||||
u8 trim_case(char**, struct queue_entry*, u8*);
|
||||
u8 common_fuzz_stuff(char**, u8*, u32);
|
||||
|
||||
/* Fuzz one */
|
||||
|
||||
u8 fuzz_one_original(char**);
|
||||
u8 pilot_fuzzing(char**);
|
||||
u8 core_fuzzing(char**);
|
||||
void pso_updating(void);
|
||||
u8 fuzz_one(char**);
|
||||
|
||||
/* Init */
|
||||
|
||||
#ifdef HAVE_AFFINITY
|
||||
void bind_to_free_cpu(void);
|
||||
#endif
|
||||
void setup_post(void);
|
||||
void setup_custom_mutator(void);
|
||||
void read_testcases(void);
|
||||
void perform_dry_run(char**);
|
||||
void pivot_inputs(void);
|
||||
u32 find_start_position(void);
|
||||
void find_timeout(void);
|
||||
double get_runnable_processes(void);
|
||||
void nuke_resume_dir(void);
|
||||
void maybe_delete_out_dir(void);
|
||||
void setup_dirs_fds(void);
|
||||
void setup_cmdline_file(char**);
|
||||
void setup_stdio_file(void);
|
||||
void check_crash_handling(void);
|
||||
void check_cpu_governor(void);
|
||||
void get_core_count(void);
|
||||
void fix_up_sync(void);
|
||||
void check_asan_opts(void);
|
||||
void check_binary(u8*);
|
||||
void fix_up_banner(u8*);
|
||||
void check_if_tty(void);
|
||||
void setup_signal_handlers(void);
|
||||
char** get_qemu_argv(u8*, char**, int);
|
||||
void save_cmdline(u32, char**);
|
||||
|
||||
/**** Inline routines ****/
|
||||
|
||||
/* Generate a random number (from 0 to limit - 1). This may
|
||||
have slight bias. */
|
||||
|
||||
static inline u32 UR(u32 limit) {
|
||||
|
||||
#ifdef HAVE_ARC4RANDOM
|
||||
if (fixed_seed) { return random() % limit; }
|
||||
|
||||
/* The boundary not being necessarily a power of 2,
|
||||
we need to ensure the result uniformity. */
|
||||
return arc4random_uniform(limit);
|
||||
#else
|
||||
if (!fixed_seed && unlikely(!rand_cnt--)) {
|
||||
|
||||
u32 seed[2];
|
||||
|
||||
ck_read(dev_urandom_fd, &seed, sizeof(seed), "/dev/urandom");
|
||||
srandom(seed[0]);
|
||||
rand_cnt = (RESEED_RNG / 2) + (seed[1] % RESEED_RNG);
|
||||
|
||||
}
|
||||
|
||||
return random() % limit;
|
||||
#endif
|
||||
|
||||
}
|
||||
|
||||
/* Find first power of two greater or equal to val (assuming val under
|
||||
2^63). */
|
||||
|
||||
static u64 next_p2(u64 val) {
|
||||
|
||||
u64 ret = 1;
|
||||
while (val > ret)
|
||||
ret <<= 1;
|
||||
return ret;
|
||||
|
||||
}
|
||||
|
||||
/* Get unix time in milliseconds */
|
||||
|
||||
static u64 get_cur_time(void) {
|
||||
|
||||
struct timeval tv;
|
||||
struct timezone tz;
|
||||
|
||||
gettimeofday(&tv, &tz);
|
||||
|
||||
return (tv.tv_sec * 1000ULL) + (tv.tv_usec / 1000);
|
||||
|
||||
}
|
||||
|
||||
/* Get unix time in microseconds */
|
||||
|
||||
static u64 get_cur_time_us(void) {
|
||||
|
||||
struct timeval tv;
|
||||
struct timezone tz;
|
||||
|
||||
gettimeofday(&tv, &tz);
|
||||
|
||||
return (tv.tv_sec * 1000000ULL) + tv.tv_usec;
|
||||
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,10 +1,15 @@
|
||||
/*
|
||||
american fuzzy lop - error-checking, memory-zeroing alloc routines
|
||||
------------------------------------------------------------------
|
||||
american fuzzy lop++ - error-checking, memory-zeroing alloc routines
|
||||
--------------------------------------------------------------------
|
||||
|
||||
Written and maintained by Michal Zalewski <lcamtuf@google.com>
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Copyright 2013, 2014, 2015 Google Inc. All rights reserved.
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
@ -31,76 +36,128 @@
|
||||
|
||||
/* User-facing macro to sprintf() to a dynamically allocated buffer. */
|
||||
|
||||
#define alloc_printf(_str...) ({ \
|
||||
u8* _tmp; \
|
||||
s32 _len = snprintf(NULL, 0, _str); \
|
||||
#define alloc_printf(_str...) \
|
||||
({ \
|
||||
\
|
||||
u8* _tmp; \
|
||||
s32 _len = snprintf(NULL, 0, _str); \
|
||||
if (_len < 0) FATAL("Whoa, snprintf() fails?!"); \
|
||||
_tmp = ck_alloc(_len + 1); \
|
||||
snprintf((char*)_tmp, _len + 1, _str); \
|
||||
_tmp; \
|
||||
_tmp = ck_alloc(_len + 1); \
|
||||
snprintf((char*)_tmp, _len + 1, _str); \
|
||||
_tmp; \
|
||||
\
|
||||
})
|
||||
|
||||
/* Macro to enforce allocation limits as a last-resort defense against
|
||||
integer overflows. */
|
||||
|
||||
#define ALLOC_CHECK_SIZE(_s) do { \
|
||||
if ((_s) > MAX_ALLOC) \
|
||||
ABORT("Bad alloc request: %u bytes", (_s)); \
|
||||
#define ALLOC_CHECK_SIZE(_s) \
|
||||
do { \
|
||||
\
|
||||
if ((_s) > MAX_ALLOC) ABORT("Bad alloc request: %u bytes", (_s)); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Macro to check malloc() failures and the like. */
|
||||
|
||||
#define ALLOC_CHECK_RESULT(_r, _s) do { \
|
||||
if (!(_r)) \
|
||||
ABORT("Out of memory: can't allocate %u bytes", (_s)); \
|
||||
#define ALLOC_CHECK_RESULT(_r, _s) \
|
||||
do { \
|
||||
\
|
||||
if (!(_r)) ABORT("Out of memory: can't allocate %u bytes", (_s)); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Magic tokens used to mark used / freed chunks. */
|
||||
|
||||
#define ALLOC_MAGIC_C1 0xFF00FF00 /* Used head (dword) */
|
||||
#define ALLOC_MAGIC_F 0xFE00FE00 /* Freed head (dword) */
|
||||
#define ALLOC_MAGIC_C2 0xF0 /* Used tail (byte) */
|
||||
#define ALLOC_MAGIC_C1 0xFF00FF00 /* Used head (dword) */
|
||||
#define ALLOC_MAGIC_F 0xFE00FE00 /* Freed head (dword) */
|
||||
#define ALLOC_MAGIC_C2 0xF0 /* Used tail (byte) */
|
||||
|
||||
/* Positions of guard tokens in relation to the user-visible pointer. */
|
||||
|
||||
#define ALLOC_C1(_ptr) (((u32*)(_ptr))[-2])
|
||||
#define ALLOC_S(_ptr) (((u32*)(_ptr))[-1])
|
||||
#define ALLOC_C2(_ptr) (((u8*)(_ptr))[ALLOC_S(_ptr)])
|
||||
#define ALLOC_C1(_ptr) (((u32*)(_ptr))[-2])
|
||||
#define ALLOC_S(_ptr) (((u32*)(_ptr))[-1])
|
||||
#define ALLOC_C2(_ptr) (((u8*)(_ptr))[ALLOC_S(_ptr)])
|
||||
|
||||
#define ALLOC_OFF_HEAD 8
|
||||
#define ALLOC_OFF_HEAD 8
|
||||
#define ALLOC_OFF_TOTAL (ALLOC_OFF_HEAD + 1)
|
||||
|
||||
/* Allocator increments for ck_realloc_block(). */
|
||||
|
||||
#define ALLOC_BLK_INC 256
|
||||
#define ALLOC_BLK_INC 256
|
||||
|
||||
/* Sanity-checking macros for pointers. */
|
||||
|
||||
#define CHECK_PTR(_p) \
|
||||
do { \
|
||||
\
|
||||
if (_p) { \
|
||||
\
|
||||
if (ALLOC_C1(_p) ^ ALLOC_MAGIC_C1) { \
|
||||
\
|
||||
if (ALLOC_C1(_p) == ALLOC_MAGIC_F) \
|
||||
ABORT("Use after free."); \
|
||||
else \
|
||||
ABORT("Corrupted head alloc canary."); \
|
||||
\
|
||||
} \
|
||||
\
|
||||
} \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/*
|
||||
#define CHECK_PTR(_p) do { \
|
||||
\
|
||||
\
|
||||
\
|
||||
\
|
||||
if (_p) { \
|
||||
\
|
||||
\
|
||||
\
|
||||
\
|
||||
if (ALLOC_C1(_p) ^ ALLOC_MAGIC_C1) {\
|
||||
\
|
||||
\
|
||||
\
|
||||
\
|
||||
if (ALLOC_C1(_p) == ALLOC_MAGIC_F) \
|
||||
ABORT("Use after free."); \
|
||||
else ABORT("Corrupted head alloc canary."); \
|
||||
\
|
||||
} \
|
||||
\
|
||||
\
|
||||
\
|
||||
if (ALLOC_C2(_p) ^ ALLOC_MAGIC_C2) \
|
||||
ABORT("Corrupted tail alloc canary."); \
|
||||
\
|
||||
} \
|
||||
\
|
||||
\
|
||||
\
|
||||
\
|
||||
\
|
||||
} while (0)
|
||||
|
||||
#define CHECK_PTR_EXPR(_p) ({ \
|
||||
typeof (_p) _tmp = (_p); \
|
||||
CHECK_PTR(_tmp); \
|
||||
_tmp; \
|
||||
})
|
||||
*/
|
||||
|
||||
#define CHECK_PTR_EXPR(_p) \
|
||||
({ \
|
||||
\
|
||||
typeof(_p) _tmp = (_p); \
|
||||
CHECK_PTR(_tmp); \
|
||||
_tmp; \
|
||||
\
|
||||
})
|
||||
|
||||
/* Allocate a buffer, explicitly not zeroing it. Returns NULL for zero-sized
|
||||
requests. */
|
||||
|
||||
static inline void* DFL_ck_alloc_nozero(u32 size) {
|
||||
|
||||
void* ret;
|
||||
u8* ret;
|
||||
|
||||
if (!size) return NULL;
|
||||
|
||||
@ -111,14 +168,13 @@ static inline void* DFL_ck_alloc_nozero(u32 size) {
|
||||
ret += ALLOC_OFF_HEAD;
|
||||
|
||||
ALLOC_C1(ret) = ALLOC_MAGIC_C1;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_C2(ret) = ALLOC_MAGIC_C2;
|
||||
|
||||
return ret;
|
||||
return (void*)ret;
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Allocate a buffer, returning zeroed memory. */
|
||||
|
||||
static inline void* DFL_ck_alloc(u32 size) {
|
||||
@ -132,7 +188,6 @@ static inline void* DFL_ck_alloc(u32 size) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Free memory, checking for double free and corrupted heap. When DEBUG_BUILD
|
||||
is set, the old memory will be also clobbered with 0xFF. */
|
||||
|
||||
@ -147,23 +202,23 @@ static inline void DFL_ck_free(void* mem) {
|
||||
/* Catch pointer issues sooner. */
|
||||
memset(mem, 0xFF, ALLOC_S(mem));
|
||||
|
||||
#endif /* DEBUG_BUILD */
|
||||
#endif /* DEBUG_BUILD */
|
||||
|
||||
ALLOC_C1(mem) = ALLOC_MAGIC_F;
|
||||
|
||||
free(mem - ALLOC_OFF_HEAD);
|
||||
u8* realStart = mem;
|
||||
free(realStart - ALLOC_OFF_HEAD);
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Re-allocate a buffer, checking for issues and zeroing any newly-added tail.
|
||||
With DEBUG_BUILD, the buffer is always reallocated to a new addresses and the
|
||||
old memory is clobbered with 0xFF. */
|
||||
|
||||
static inline void* DFL_ck_realloc(void* orig, u32 size) {
|
||||
|
||||
void* ret;
|
||||
u32 old_size = 0;
|
||||
u8* ret;
|
||||
u32 old_size = 0;
|
||||
|
||||
if (!size) {
|
||||
|
||||
@ -178,10 +233,12 @@ static inline void* DFL_ck_realloc(void* orig, u32 size) {
|
||||
|
||||
#ifndef DEBUG_BUILD
|
||||
ALLOC_C1(orig) = ALLOC_MAGIC_F;
|
||||
#endif /* !DEBUG_BUILD */
|
||||
#endif /* !DEBUG_BUILD */
|
||||
|
||||
old_size = ALLOC_S(orig);
|
||||
orig -= ALLOC_OFF_HEAD;
|
||||
old_size = ALLOC_S(orig);
|
||||
u8* origu8 = orig;
|
||||
origu8 -= ALLOC_OFF_HEAD;
|
||||
orig = origu8;
|
||||
|
||||
ALLOC_CHECK_SIZE(old_size);
|
||||
|
||||
@ -204,31 +261,30 @@ static inline void* DFL_ck_realloc(void* orig, u32 size) {
|
||||
|
||||
if (orig) {
|
||||
|
||||
memcpy(ret + ALLOC_OFF_HEAD, orig + ALLOC_OFF_HEAD, MIN(size, old_size));
|
||||
memset(orig + ALLOC_OFF_HEAD, 0xFF, old_size);
|
||||
u8* origu8 = orig;
|
||||
memcpy(ret + ALLOC_OFF_HEAD, origu8 + ALLOC_OFF_HEAD, MIN(size, old_size));
|
||||
memset(origu8 + ALLOC_OFF_HEAD, 0xFF, old_size);
|
||||
|
||||
ALLOC_C1(orig + ALLOC_OFF_HEAD) = ALLOC_MAGIC_F;
|
||||
ALLOC_C1(origu8 + ALLOC_OFF_HEAD) = ALLOC_MAGIC_F;
|
||||
|
||||
free(orig);
|
||||
|
||||
}
|
||||
|
||||
#endif /* ^!DEBUG_BUILD */
|
||||
#endif /* ^!DEBUG_BUILD */
|
||||
|
||||
ret += ALLOC_OFF_HEAD;
|
||||
|
||||
ALLOC_C1(ret) = ALLOC_MAGIC_C1;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_C2(ret) = ALLOC_MAGIC_C2;
|
||||
|
||||
if (size > old_size)
|
||||
memset(ret + old_size, 0, size - old_size);
|
||||
if (size > old_size) memset(ret + old_size, 0, size - old_size);
|
||||
|
||||
return ret;
|
||||
return (void*)ret;
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Re-allocate a buffer with ALLOC_BLK_INC increments (used to speed up
|
||||
repeated small reallocs without complicating the user code). */
|
||||
|
||||
@ -246,19 +302,18 @@ static inline void* DFL_ck_realloc_block(void* orig, u32 size) {
|
||||
|
||||
}
|
||||
|
||||
#endif /* !DEBUG_BUILD */
|
||||
#endif /* !DEBUG_BUILD */
|
||||
|
||||
return DFL_ck_realloc(orig, size);
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Create a buffer with a copy of a string. Returns NULL for NULL inputs. */
|
||||
|
||||
static inline u8* DFL_ck_strdup(u8* str) {
|
||||
|
||||
void* ret;
|
||||
u32 size;
|
||||
u8* ret;
|
||||
u32 size;
|
||||
|
||||
if (!str) return NULL;
|
||||
|
||||
@ -271,38 +326,36 @@ static inline u8* DFL_ck_strdup(u8* str) {
|
||||
ret += ALLOC_OFF_HEAD;
|
||||
|
||||
ALLOC_C1(ret) = ALLOC_MAGIC_C1;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_C2(ret) = ALLOC_MAGIC_C2;
|
||||
|
||||
return memcpy(ret, str, size);
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Create a buffer with a copy of a memory block. Returns NULL for zero-sized
|
||||
or NULL inputs. */
|
||||
|
||||
static inline void* DFL_ck_memdup(void* mem, u32 size) {
|
||||
|
||||
void* ret;
|
||||
u8* ret;
|
||||
|
||||
if (!mem || !size) return NULL;
|
||||
|
||||
ALLOC_CHECK_SIZE(size);
|
||||
ret = malloc(size + ALLOC_OFF_TOTAL);
|
||||
ALLOC_CHECK_RESULT(ret, size);
|
||||
|
||||
|
||||
ret += ALLOC_OFF_HEAD;
|
||||
|
||||
ALLOC_C1(ret) = ALLOC_MAGIC_C1;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_C2(ret) = ALLOC_MAGIC_C2;
|
||||
|
||||
return memcpy(ret, mem, size);
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Create a buffer with a block of text, appending a NUL terminator at the end.
|
||||
Returns NULL for zero-sized or NULL inputs. */
|
||||
|
||||
@ -315,11 +368,11 @@ static inline u8* DFL_ck_memdup_str(u8* mem, u32 size) {
|
||||
ALLOC_CHECK_SIZE(size);
|
||||
ret = malloc(size + ALLOC_OFF_TOTAL + 1);
|
||||
ALLOC_CHECK_RESULT(ret, size);
|
||||
|
||||
|
||||
ret += ALLOC_OFF_HEAD;
|
||||
|
||||
ALLOC_C1(ret) = ALLOC_MAGIC_C1;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_S(ret) = size;
|
||||
ALLOC_C2(ret) = ALLOC_MAGIC_C2;
|
||||
|
||||
memcpy(ret, mem, size);
|
||||
@ -329,20 +382,19 @@ static inline u8* DFL_ck_memdup_str(u8* mem, u32 size) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
#ifndef DEBUG_BUILD
|
||||
|
||||
/* In non-debug mode, we just do straightforward aliasing of the above functions
|
||||
to user-visible names such as ck_alloc(). */
|
||||
|
||||
#define ck_alloc DFL_ck_alloc
|
||||
#define ck_alloc_nozero DFL_ck_alloc_nozero
|
||||
#define ck_realloc DFL_ck_realloc
|
||||
#define ck_realloc_block DFL_ck_realloc_block
|
||||
#define ck_strdup DFL_ck_strdup
|
||||
#define ck_memdup DFL_ck_memdup
|
||||
#define ck_memdup_str DFL_ck_memdup_str
|
||||
#define ck_free DFL_ck_free
|
||||
#define ck_alloc DFL_ck_alloc
|
||||
#define ck_alloc_nozero DFL_ck_alloc_nozero
|
||||
#define ck_realloc DFL_ck_realloc
|
||||
#define ck_realloc_block DFL_ck_realloc_block
|
||||
#define ck_strdup DFL_ck_strdup
|
||||
#define ck_memdup DFL_ck_memdup
|
||||
#define ck_memdup_str DFL_ck_memdup_str
|
||||
#define ck_free DFL_ck_free
|
||||
|
||||
#define alloc_report()
|
||||
|
||||
@ -353,12 +405,14 @@ static inline u8* DFL_ck_memdup_str(u8* mem, u32 size) {
|
||||
|
||||
/* Alloc tracking data structures: */
|
||||
|
||||
#define ALLOC_BUCKETS 4096
|
||||
#define ALLOC_BUCKETS 4096
|
||||
|
||||
struct TRK_obj {
|
||||
void *ptr;
|
||||
|
||||
void* ptr;
|
||||
char *file, *func;
|
||||
u32 line;
|
||||
u32 line;
|
||||
|
||||
};
|
||||
|
||||
#ifdef AFL_MAIN
|
||||
@ -366,22 +420,21 @@ struct TRK_obj {
|
||||
struct TRK_obj* TRK[ALLOC_BUCKETS];
|
||||
u32 TRK_cnt[ALLOC_BUCKETS];
|
||||
|
||||
# define alloc_report() TRK_report()
|
||||
#define alloc_report() TRK_report()
|
||||
|
||||
#else
|
||||
|
||||
extern struct TRK_obj* TRK[ALLOC_BUCKETS];
|
||||
extern u32 TRK_cnt[ALLOC_BUCKETS];
|
||||
extern u32 TRK_cnt[ALLOC_BUCKETS];
|
||||
|
||||
# define alloc_report()
|
||||
#define alloc_report()
|
||||
|
||||
#endif /* ^AFL_MAIN */
|
||||
#endif /* ^AFL_MAIN */
|
||||
|
||||
/* Bucket-assigning function for a given pointer: */
|
||||
|
||||
#define TRKH(_ptr) (((((u32)(_ptr)) >> 16) ^ ((u32)(_ptr))) % ALLOC_BUCKETS)
|
||||
|
||||
|
||||
/* Add a new entry to the list of allocated objects. */
|
||||
|
||||
static inline void TRK_alloc_buf(void* ptr, const char* file, const char* func,
|
||||
@ -399,7 +452,7 @@ static inline void TRK_alloc_buf(void* ptr, const char* file, const char* func,
|
||||
|
||||
if (!TRK[bucket][i].ptr) {
|
||||
|
||||
TRK[bucket][i].ptr = ptr;
|
||||
TRK[bucket][i].ptr = ptr;
|
||||
TRK[bucket][i].file = (char*)file;
|
||||
TRK[bucket][i].func = (char*)func;
|
||||
TRK[bucket][i].line = line;
|
||||
@ -409,10 +462,10 @@ static inline void TRK_alloc_buf(void* ptr, const char* file, const char* func,
|
||||
|
||||
/* No space available - allocate more. */
|
||||
|
||||
TRK[bucket] = DFL_ck_realloc_block(TRK[bucket],
|
||||
(TRK_cnt[bucket] + 1) * sizeof(struct TRK_obj));
|
||||
TRK[bucket] = DFL_ck_realloc_block(
|
||||
TRK[bucket], (TRK_cnt[bucket] + 1) * sizeof(struct TRK_obj));
|
||||
|
||||
TRK[bucket][i].ptr = ptr;
|
||||
TRK[bucket][i].ptr = ptr;
|
||||
TRK[bucket][i].file = (char*)file;
|
||||
TRK[bucket][i].func = (char*)func;
|
||||
TRK[bucket][i].line = line;
|
||||
@ -421,7 +474,6 @@ static inline void TRK_alloc_buf(void* ptr, const char* file, const char* func,
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Remove entry from the list of allocated objects. */
|
||||
|
||||
static inline void TRK_free_buf(void* ptr, const char* file, const char* func,
|
||||
@ -444,12 +496,11 @@ static inline void TRK_free_buf(void* ptr, const char* file, const char* func,
|
||||
|
||||
}
|
||||
|
||||
WARNF("ALLOC: Attempt to free non-allocated memory in %s (%s:%u)",
|
||||
func, file, line);
|
||||
WARNF("ALLOC: Attempt to free non-allocated memory in %s (%s:%u)", func, file,
|
||||
line);
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Do a final report on all non-deallocated objects. */
|
||||
|
||||
static inline void TRK_report(void) {
|
||||
@ -466,7 +517,6 @@ static inline void TRK_report(void) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Simple wrappers for non-debugging functions: */
|
||||
|
||||
static inline void* TRK_ck_alloc(u32 size, const char* file, const char* func,
|
||||
@ -478,7 +528,6 @@ static inline void* TRK_ck_alloc(u32 size, const char* file, const char* func,
|
||||
|
||||
}
|
||||
|
||||
|
||||
static inline void* TRK_ck_realloc(void* orig, u32 size, const char* file,
|
||||
const char* func, u32 line) {
|
||||
|
||||
@ -489,7 +538,6 @@ static inline void* TRK_ck_realloc(void* orig, u32 size, const char* file,
|
||||
|
||||
}
|
||||
|
||||
|
||||
static inline void* TRK_ck_realloc_block(void* orig, u32 size, const char* file,
|
||||
const char* func, u32 line) {
|
||||
|
||||
@ -500,7 +548,6 @@ static inline void* TRK_ck_realloc_block(void* orig, u32 size, const char* file,
|
||||
|
||||
}
|
||||
|
||||
|
||||
static inline void* TRK_ck_strdup(u8* str, const char* file, const char* func,
|
||||
u32 line) {
|
||||
|
||||
@ -510,7 +557,6 @@ static inline void* TRK_ck_strdup(u8* str, const char* file, const char* func,
|
||||
|
||||
}
|
||||
|
||||
|
||||
static inline void* TRK_ck_memdup(void* mem, u32 size, const char* file,
|
||||
const char* func, u32 line) {
|
||||
|
||||
@ -520,7 +566,6 @@ static inline void* TRK_ck_memdup(void* mem, u32 size, const char* file,
|
||||
|
||||
}
|
||||
|
||||
|
||||
static inline void* TRK_ck_memdup_str(void* mem, u32 size, const char* file,
|
||||
const char* func, u32 line) {
|
||||
|
||||
@ -530,9 +575,8 @@ static inline void* TRK_ck_memdup_str(void* mem, u32 size, const char* file,
|
||||
|
||||
}
|
||||
|
||||
|
||||
static inline void TRK_ck_free(void* ptr, const char* file,
|
||||
const char* func, u32 line) {
|
||||
static inline void TRK_ck_free(void* ptr, const char* file, const char* func,
|
||||
u32 line) {
|
||||
|
||||
TRK_free_buf(ptr, file, func, line);
|
||||
DFL_ck_free(ptr);
|
||||
@ -541,11 +585,9 @@ static inline void TRK_ck_free(void* ptr, const char* file,
|
||||
|
||||
/* Aliasing user-facing names to tracking functions: */
|
||||
|
||||
#define ck_alloc(_p1) \
|
||||
TRK_ck_alloc(_p1, __FILE__, __FUNCTION__, __LINE__)
|
||||
#define ck_alloc(_p1) TRK_ck_alloc(_p1, __FILE__, __FUNCTION__, __LINE__)
|
||||
|
||||
#define ck_alloc_nozero(_p1) \
|
||||
TRK_ck_alloc(_p1, __FILE__, __FUNCTION__, __LINE__)
|
||||
#define ck_alloc_nozero(_p1) TRK_ck_alloc(_p1, __FILE__, __FUNCTION__, __LINE__)
|
||||
|
||||
#define ck_realloc(_p1, _p2) \
|
||||
TRK_ck_realloc(_p1, _p2, __FILE__, __FUNCTION__, __LINE__)
|
||||
@ -553,8 +595,7 @@ static inline void TRK_ck_free(void* ptr, const char* file,
|
||||
#define ck_realloc_block(_p1, _p2) \
|
||||
TRK_ck_realloc_block(_p1, _p2, __FILE__, __FUNCTION__, __LINE__)
|
||||
|
||||
#define ck_strdup(_p1) \
|
||||
TRK_ck_strdup(_p1, __FILE__, __FUNCTION__, __LINE__)
|
||||
#define ck_strdup(_p1) TRK_ck_strdup(_p1, __FILE__, __FUNCTION__, __LINE__)
|
||||
|
||||
#define ck_memdup(_p1, _p2) \
|
||||
TRK_ck_memdup(_p1, _p2, __FILE__, __FUNCTION__, __LINE__)
|
||||
@ -562,9 +603,9 @@ static inline void TRK_ck_free(void* ptr, const char* file,
|
||||
#define ck_memdup_str(_p1, _p2) \
|
||||
TRK_ck_memdup_str(_p1, _p2, __FILE__, __FUNCTION__, __LINE__)
|
||||
|
||||
#define ck_free(_p1) \
|
||||
TRK_ck_free(_p1, __FILE__, __FUNCTION__, __LINE__)
|
||||
#define ck_free(_p1) TRK_ck_free(_p1, __FILE__, __FUNCTION__, __LINE__)
|
||||
|
||||
#endif /* ^!DEBUG_BUILD */
|
||||
#endif /* ^!DEBUG_BUILD */
|
||||
|
||||
#endif /* ! _HAVE_ALLOC_INL_H */
|
||||
|
||||
#endif /* ! _HAVE_ALLOC_INL_H */
|
||||
104
include/android-ashmem.h
Normal file
104
include/android-ashmem.h
Normal file
@ -0,0 +1,104 @@
|
||||
/*
|
||||
american fuzzy lop++ - android shared memory compatibility layer
|
||||
----------------------------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This header re-defines the shared memory routines used by AFL++
|
||||
using the Andoid API.
|
||||
|
||||
*/
|
||||
|
||||
#ifndef _ANDROID_ASHMEM_H
|
||||
#define _ANDROID_ASHMEM_H
|
||||
|
||||
#include <fcntl.h>
|
||||
#include <linux/shm.h>
|
||||
#include <linux/ashmem.h>
|
||||
#include <sys/ioctl.h>
|
||||
#include <sys/mman.h>
|
||||
|
||||
#if __ANDROID_API__ >= 26
|
||||
#define shmat bionic_shmat
|
||||
#define shmctl bionic_shmctl
|
||||
#define shmdt bionic_shmdt
|
||||
#define shmget bionic_shmget
|
||||
#endif
|
||||
#include <sys/shm.h>
|
||||
#undef shmat
|
||||
#undef shmctl
|
||||
#undef shmdt
|
||||
#undef shmget
|
||||
#include <stdio.h>
|
||||
|
||||
#define ASHMEM_DEVICE "/dev/ashmem"
|
||||
|
||||
static inline int shmctl(int __shmid, int __cmd, struct shmid_ds *__buf) {
|
||||
|
||||
int ret = 0;
|
||||
if (__cmd == IPC_RMID) {
|
||||
|
||||
int length = ioctl(__shmid, ASHMEM_GET_SIZE, NULL);
|
||||
struct ashmem_pin pin = {0, length};
|
||||
ret = ioctl(__shmid, ASHMEM_UNPIN, &pin);
|
||||
close(__shmid);
|
||||
|
||||
}
|
||||
|
||||
return ret;
|
||||
|
||||
}
|
||||
|
||||
static inline int shmget(key_t __key, size_t __size, int __shmflg) {
|
||||
|
||||
int fd, ret;
|
||||
char ourkey[11];
|
||||
|
||||
fd = open(ASHMEM_DEVICE, O_RDWR);
|
||||
if (fd < 0) return fd;
|
||||
|
||||
sprintf(ourkey, "%d", __key);
|
||||
ret = ioctl(fd, ASHMEM_SET_NAME, ourkey);
|
||||
if (ret < 0) goto error;
|
||||
|
||||
ret = ioctl(fd, ASHMEM_SET_SIZE, __size);
|
||||
if (ret < 0) goto error;
|
||||
|
||||
return fd;
|
||||
|
||||
error:
|
||||
close(fd);
|
||||
return ret;
|
||||
|
||||
}
|
||||
|
||||
static inline void *shmat(int __shmid, const void *__shmaddr, int __shmflg) {
|
||||
|
||||
int size;
|
||||
void *ptr;
|
||||
|
||||
size = ioctl(__shmid, ASHMEM_GET_SIZE, NULL);
|
||||
if (size < 0) { return NULL; }
|
||||
|
||||
ptr = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, __shmid, 0);
|
||||
if (ptr == MAP_FAILED) { return NULL; }
|
||||
|
||||
return ptr;
|
||||
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
32
include/common.h
Normal file
32
include/common.h
Normal file
@ -0,0 +1,32 @@
|
||||
/*
|
||||
american fuzzy lop++ - common routines header
|
||||
---------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Gather some functions common to multiple executables
|
||||
|
||||
- detect_file_args
|
||||
|
||||
*/
|
||||
|
||||
#ifndef __AFLCOMMON_H
|
||||
#define __AFLCOMMON_H
|
||||
#include "types.h"
|
||||
|
||||
void detect_file_args(char **argv, u8 *prog_in);
|
||||
#endif
|
||||
|
||||
375
include/config.h
Normal file
375
include/config.h
Normal file
@ -0,0 +1,375 @@
|
||||
/*
|
||||
american fuzzy lop++ - vaguely configurable bits
|
||||
------------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
*/
|
||||
|
||||
#ifndef _HAVE_CONFIG_H
|
||||
#define _HAVE_CONFIG_H
|
||||
|
||||
#include "types.h"
|
||||
|
||||
/* Version string: */
|
||||
|
||||
#define VERSION "++2.54c" // c = release, d = volatile github dev
|
||||
|
||||
/******************************************************
|
||||
* *
|
||||
* Settings that may be of interest to power users: *
|
||||
* *
|
||||
******************************************************/
|
||||
|
||||
/* Comment out to disable terminal colors (note that this makes afl-analyze
|
||||
a lot less nice): */
|
||||
|
||||
#define USE_COLOR
|
||||
|
||||
/* Comment out to disable fancy ANSI boxes and use poor man's 7-bit UI: */
|
||||
|
||||
#define FANCY_BOXES
|
||||
|
||||
/* Default timeout for fuzzed code (milliseconds). This is the upper bound,
|
||||
also used for detecting hangs; the actual value is auto-scaled: */
|
||||
|
||||
#define EXEC_TIMEOUT 1000
|
||||
|
||||
/* Timeout rounding factor when auto-scaling (milliseconds): */
|
||||
|
||||
#define EXEC_TM_ROUND 20
|
||||
|
||||
/* Default memory limit for child process (MB): */
|
||||
|
||||
#ifndef __x86_64__
|
||||
#define MEM_LIMIT 25
|
||||
#else
|
||||
#define MEM_LIMIT 50
|
||||
#endif /* ^!__x86_64__ */
|
||||
|
||||
/* Default memory limit when running in QEMU mode (MB): */
|
||||
|
||||
#define MEM_LIMIT_QEMU 200
|
||||
|
||||
/* Default memory limit when running in Unicorn mode (MB): */
|
||||
|
||||
#define MEM_LIMIT_UNICORN 200
|
||||
|
||||
/* Number of calibration cycles per every new test case (and for test
|
||||
cases that show variable behavior): */
|
||||
|
||||
#define CAL_CYCLES 8
|
||||
#define CAL_CYCLES_LONG 40
|
||||
|
||||
/* Number of subsequent timeouts before abandoning an input file: */
|
||||
|
||||
#define TMOUT_LIMIT 250
|
||||
|
||||
/* Maximum number of unique hangs or crashes to record: */
|
||||
|
||||
#define KEEP_UNIQUE_HANG 500
|
||||
#define KEEP_UNIQUE_CRASH 5000
|
||||
|
||||
/* Baseline number of random tweaks during a single 'havoc' stage: */
|
||||
|
||||
#define HAVOC_CYCLES 256
|
||||
#define HAVOC_CYCLES_INIT 1024
|
||||
|
||||
/* Maximum multiplier for the above (should be a power of two, beware
|
||||
of 32-bit int overflows): */
|
||||
|
||||
#define HAVOC_MAX_MULT 16
|
||||
#define HAVOC_MAX_MULT_MOPT 32
|
||||
|
||||
/* Absolute minimum number of havoc cycles (after all adjustments): */
|
||||
|
||||
#define HAVOC_MIN 16
|
||||
|
||||
/* Power Schedule Divisor */
|
||||
#define POWER_BETA 1
|
||||
#define MAX_FACTOR (POWER_BETA * 32)
|
||||
|
||||
/* Maximum stacking for havoc-stage tweaks. The actual value is calculated
|
||||
like this:
|
||||
|
||||
n = random between 1 and HAVOC_STACK_POW2
|
||||
stacking = 2^n
|
||||
|
||||
In other words, the default (n = 7) produces 2, 4, 8, 16, 32, 64, or
|
||||
128 stacked tweaks: */
|
||||
|
||||
#define HAVOC_STACK_POW2 7
|
||||
|
||||
/* Caps on block sizes for cloning and deletion operations. Each of these
|
||||
ranges has a 33% probability of getting picked, except for the first
|
||||
two cycles where smaller blocks are favored: */
|
||||
|
||||
#define HAVOC_BLK_SMALL 32
|
||||
#define HAVOC_BLK_MEDIUM 128
|
||||
#define HAVOC_BLK_LARGE 1500
|
||||
|
||||
/* Extra-large blocks, selected very rarely (<5% of the time): */
|
||||
|
||||
#define HAVOC_BLK_XL 32768
|
||||
|
||||
/* Probabilities of skipping non-favored entries in the queue, expressed as
|
||||
percentages: */
|
||||
|
||||
#define SKIP_TO_NEW_PROB 99 /* ...when there are new, pending favorites */
|
||||
#define SKIP_NFAV_OLD_PROB 95 /* ...no new favs, cur entry already fuzzed */
|
||||
#define SKIP_NFAV_NEW_PROB 75 /* ...no new favs, cur entry not fuzzed yet */
|
||||
|
||||
/* Splicing cycle count: */
|
||||
|
||||
#define SPLICE_CYCLES 15
|
||||
|
||||
/* Nominal per-splice havoc cycle length: */
|
||||
|
||||
#define SPLICE_HAVOC 32
|
||||
|
||||
/* Maximum offset for integer addition / subtraction stages: */
|
||||
|
||||
#define ARITH_MAX 35
|
||||
|
||||
/* Limits for the test case trimmer. The absolute minimum chunk size; and
|
||||
the starting and ending divisors for chopping up the input file: */
|
||||
|
||||
#define TRIM_MIN_BYTES 4
|
||||
#define TRIM_START_STEPS 16
|
||||
#define TRIM_END_STEPS 1024
|
||||
|
||||
/* Maximum size of input file, in bytes (keep under 100MB): */
|
||||
|
||||
#define MAX_FILE (1 * 1024 * 1024)
|
||||
|
||||
/* The same, for the test case minimizer: */
|
||||
|
||||
#define TMIN_MAX_FILE (10 * 1024 * 1024)
|
||||
|
||||
/* Block normalization steps for afl-tmin: */
|
||||
|
||||
#define TMIN_SET_MIN_SIZE 4
|
||||
#define TMIN_SET_STEPS 128
|
||||
|
||||
/* Maximum dictionary token size (-x), in bytes: */
|
||||
|
||||
#define MAX_DICT_FILE 128
|
||||
|
||||
/* Length limits for auto-detected dictionary tokens: */
|
||||
|
||||
#define MIN_AUTO_EXTRA 3
|
||||
#define MAX_AUTO_EXTRA 32
|
||||
|
||||
/* Maximum number of user-specified dictionary tokens to use in deterministic
|
||||
steps; past this point, the "extras/user" step will be still carried out,
|
||||
but with proportionally lower odds: */
|
||||
|
||||
#define MAX_DET_EXTRAS 200
|
||||
|
||||
/* Maximum number of auto-extracted dictionary tokens to actually use in fuzzing
|
||||
(first value), and to keep in memory as candidates. The latter should be much
|
||||
higher than the former. */
|
||||
|
||||
#define USE_AUTO_EXTRAS 50
|
||||
#define MAX_AUTO_EXTRAS (USE_AUTO_EXTRAS * 10)
|
||||
|
||||
/* Scaling factor for the effector map used to skip some of the more
|
||||
expensive deterministic steps. The actual divisor is set to
|
||||
2^EFF_MAP_SCALE2 bytes: */
|
||||
|
||||
#define EFF_MAP_SCALE2 3
|
||||
|
||||
/* Minimum input file length at which the effector logic kicks in: */
|
||||
|
||||
#define EFF_MIN_LEN 128
|
||||
|
||||
/* Maximum effector density past which everything is just fuzzed
|
||||
unconditionally (%): */
|
||||
|
||||
#define EFF_MAX_PERC 90
|
||||
|
||||
/* UI refresh frequency (Hz): */
|
||||
|
||||
#define UI_TARGET_HZ 5
|
||||
|
||||
/* Fuzzer stats file and plot update intervals (sec): */
|
||||
|
||||
#define STATS_UPDATE_SEC 60
|
||||
#define PLOT_UPDATE_SEC 5
|
||||
|
||||
/* Smoothing divisor for CPU load and exec speed stats (1 - no smoothing). */
|
||||
|
||||
#define AVG_SMOOTHING 16
|
||||
|
||||
/* Sync interval (every n havoc cycles): */
|
||||
|
||||
#define SYNC_INTERVAL 5
|
||||
|
||||
/* Output directory reuse grace period (minutes): */
|
||||
|
||||
#define OUTPUT_GRACE 25
|
||||
|
||||
/* Uncomment to use simple file names (id_NNNNNN): */
|
||||
|
||||
// #define SIMPLE_FILES
|
||||
|
||||
/* List of interesting values to use in fuzzing. */
|
||||
|
||||
#define INTERESTING_8 \
|
||||
-128, /* Overflow signed 8-bit when decremented */ \
|
||||
-1, /* */ \
|
||||
0, /* */ \
|
||||
1, /* */ \
|
||||
16, /* One-off with common buffer size */ \
|
||||
32, /* One-off with common buffer size */ \
|
||||
64, /* One-off with common buffer size */ \
|
||||
100, /* One-off with common buffer size */ \
|
||||
127 /* Overflow signed 8-bit when incremented */
|
||||
|
||||
#define INTERESTING_8_LEN 9
|
||||
|
||||
#define INTERESTING_16 \
|
||||
-32768, /* Overflow signed 16-bit when decremented */ \
|
||||
-129, /* Overflow signed 8-bit */ \
|
||||
128, /* Overflow signed 8-bit */ \
|
||||
255, /* Overflow unsig 8-bit when incremented */ \
|
||||
256, /* Overflow unsig 8-bit */ \
|
||||
512, /* One-off with common buffer size */ \
|
||||
1000, /* One-off with common buffer size */ \
|
||||
1024, /* One-off with common buffer size */ \
|
||||
4096, /* One-off with common buffer size */ \
|
||||
32767 /* Overflow signed 16-bit when incremented */
|
||||
|
||||
#define INTERESTING_16_LEN 10
|
||||
|
||||
#define INTERESTING_32 \
|
||||
-2147483648LL, /* Overflow signed 32-bit when decremented */ \
|
||||
-100663046, /* Large negative number (endian-agnostic) */ \
|
||||
-32769, /* Overflow signed 16-bit */ \
|
||||
32768, /* Overflow signed 16-bit */ \
|
||||
65535, /* Overflow unsig 16-bit when incremented */ \
|
||||
65536, /* Overflow unsig 16 bit */ \
|
||||
100663045, /* Large positive number (endian-agnostic) */ \
|
||||
2147483647 /* Overflow signed 32-bit when incremented */
|
||||
|
||||
#define INTERESTING_32_LEN 8
|
||||
|
||||
/***********************************************************
|
||||
* *
|
||||
* Really exotic stuff you probably don't want to touch: *
|
||||
* *
|
||||
***********************************************************/
|
||||
|
||||
/* Call count interval between reseeding the libc PRNG from /dev/urandom: */
|
||||
|
||||
#define RESEED_RNG 10000
|
||||
|
||||
/* Maximum line length passed from GCC to 'as' and used for parsing
|
||||
configuration files: */
|
||||
|
||||
#define MAX_LINE 8192
|
||||
|
||||
/* Environment variable used to pass SHM ID to the called program. */
|
||||
|
||||
#define SHM_ENV_VAR "__AFL_SHM_ID"
|
||||
|
||||
/* Other less interesting, internal-only variables. */
|
||||
|
||||
#define CLANG_ENV_VAR "__AFL_CLANG_MODE"
|
||||
#define AS_LOOP_ENV_VAR "__AFL_AS_LOOPCHECK"
|
||||
#define PERSIST_ENV_VAR "__AFL_PERSISTENT"
|
||||
#define DEFER_ENV_VAR "__AFL_DEFER_FORKSRV"
|
||||
|
||||
/* In-code signatures for deferred and persistent mode. */
|
||||
|
||||
#define PERSIST_SIG "##SIG_AFL_PERSISTENT##"
|
||||
#define DEFER_SIG "##SIG_AFL_DEFER_FORKSRV##"
|
||||
|
||||
/* Distinctive bitmap signature used to indicate failed execution: */
|
||||
|
||||
#define EXEC_FAIL_SIG 0xfee1dead
|
||||
|
||||
/* Distinctive exit code used to indicate MSAN trip condition: */
|
||||
|
||||
#define MSAN_ERROR 86
|
||||
|
||||
/* Designated file descriptors for forkserver commands (the application will
|
||||
use FORKSRV_FD and FORKSRV_FD + 1): */
|
||||
|
||||
#define FORKSRV_FD 198
|
||||
|
||||
/* Fork server init timeout multiplier: we'll wait the user-selected
|
||||
timeout plus this much for the fork server to spin up. */
|
||||
|
||||
#define FORK_WAIT_MULT 10
|
||||
|
||||
/* Calibration timeout adjustments, to be a bit more generous when resuming
|
||||
fuzzing sessions or trying to calibrate already-added internal finds.
|
||||
The first value is a percentage, the other is in milliseconds: */
|
||||
|
||||
#define CAL_TMOUT_PERC 125
|
||||
#define CAL_TMOUT_ADD 50
|
||||
|
||||
/* Number of chances to calibrate a case before giving up: */
|
||||
|
||||
#define CAL_CHANCES 3
|
||||
|
||||
/* Map size for the traced binary (2^MAP_SIZE_POW2). Must be greater than
|
||||
2; you probably want to keep it under 18 or so for performance reasons
|
||||
(adjusting AFL_INST_RATIO when compiling is probably a better way to solve
|
||||
problems with complex programs). You need to recompile the target binary
|
||||
after changing this - otherwise, SEGVs may ensue. */
|
||||
|
||||
#define MAP_SIZE_POW2 16
|
||||
#define MAP_SIZE (1 << MAP_SIZE_POW2)
|
||||
|
||||
/* Maximum allocator request size (keep well under INT_MAX): */
|
||||
|
||||
#define MAX_ALLOC 0x40000000
|
||||
|
||||
/* A made-up hashing seed: */
|
||||
|
||||
#define HASH_CONST 0xa5b35705
|
||||
|
||||
/* Constants for afl-gotcpu to control busy loop timing: */
|
||||
|
||||
#define CTEST_TARGET_MS 5000
|
||||
#define CTEST_CORE_TRG_MS 1000
|
||||
#define CTEST_BUSY_CYCLES (10 * 1000 * 1000)
|
||||
|
||||
/* Enable NeverZero counters in QEMU mode */
|
||||
|
||||
#define AFL_QEMU_NOT_ZERO
|
||||
|
||||
/* Uncomment this to use inferior block-coverage-based instrumentation. Note
|
||||
that you need to recompile the target binary for this to have any effect: */
|
||||
|
||||
// #define COVERAGE_ONLY
|
||||
|
||||
/* Uncomment this to ignore hit counts and output just one bit per tuple.
|
||||
As with the previous setting, you will need to recompile the target
|
||||
binary: */
|
||||
|
||||
// #define SKIP_COUNTS
|
||||
|
||||
/* Uncomment this to use instrumentation data to record newly discovered paths,
|
||||
but do not use them as seeds for fuzzing. This is useful for conveniently
|
||||
measuring coverage that could be attained by a "dumb" fuzzing algorithm: */
|
||||
|
||||
// #define IGNORE_FINDS
|
||||
|
||||
#endif /* ! _HAVE_CONFIG_H */
|
||||
|
||||
290
include/debug.h
Normal file
290
include/debug.h
Normal file
@ -0,0 +1,290 @@
|
||||
/*
|
||||
american fuzzy lop++ - debug / error handling macros
|
||||
----------------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
*/
|
||||
|
||||
#ifndef _HAVE_DEBUG_H
|
||||
#define _HAVE_DEBUG_H
|
||||
|
||||
#include <errno.h>
|
||||
|
||||
#include "types.h"
|
||||
#include "config.h"
|
||||
|
||||
/*******************
|
||||
* Terminal colors *
|
||||
*******************/
|
||||
|
||||
#ifdef USE_COLOR
|
||||
|
||||
#define cBLK "\x1b[0;30m"
|
||||
#define cRED "\x1b[0;31m"
|
||||
#define cGRN "\x1b[0;32m"
|
||||
#define cBRN "\x1b[0;33m"
|
||||
#define cBLU "\x1b[0;34m"
|
||||
#define cMGN "\x1b[0;35m"
|
||||
#define cCYA "\x1b[0;36m"
|
||||
#define cLGR "\x1b[0;37m"
|
||||
#define cGRA "\x1b[1;90m"
|
||||
#define cLRD "\x1b[1;91m"
|
||||
#define cLGN "\x1b[1;92m"
|
||||
#define cYEL "\x1b[1;93m"
|
||||
#define cLBL "\x1b[1;94m"
|
||||
#define cPIN "\x1b[1;95m"
|
||||
#define cLCY "\x1b[1;96m"
|
||||
#define cBRI "\x1b[1;97m"
|
||||
#define cRST "\x1b[0m"
|
||||
|
||||
#define bgBLK "\x1b[40m"
|
||||
#define bgRED "\x1b[41m"
|
||||
#define bgGRN "\x1b[42m"
|
||||
#define bgBRN "\x1b[43m"
|
||||
#define bgBLU "\x1b[44m"
|
||||
#define bgMGN "\x1b[45m"
|
||||
#define bgCYA "\x1b[46m"
|
||||
#define bgLGR "\x1b[47m"
|
||||
#define bgGRA "\x1b[100m"
|
||||
#define bgLRD "\x1b[101m"
|
||||
#define bgLGN "\x1b[102m"
|
||||
#define bgYEL "\x1b[103m"
|
||||
#define bgLBL "\x1b[104m"
|
||||
#define bgPIN "\x1b[105m"
|
||||
#define bgLCY "\x1b[106m"
|
||||
#define bgBRI "\x1b[107m"
|
||||
|
||||
#else
|
||||
|
||||
#define cBLK ""
|
||||
#define cRED ""
|
||||
#define cGRN ""
|
||||
#define cBRN ""
|
||||
#define cBLU ""
|
||||
#define cMGN ""
|
||||
#define cCYA ""
|
||||
#define cLGR ""
|
||||
#define cGRA ""
|
||||
#define cLRD ""
|
||||
#define cLGN ""
|
||||
#define cYEL ""
|
||||
#define cLBL ""
|
||||
#define cPIN ""
|
||||
#define cLCY ""
|
||||
#define cBRI ""
|
||||
#define cRST ""
|
||||
|
||||
#define bgBLK ""
|
||||
#define bgRED ""
|
||||
#define bgGRN ""
|
||||
#define bgBRN ""
|
||||
#define bgBLU ""
|
||||
#define bgMGN ""
|
||||
#define bgCYA ""
|
||||
#define bgLGR ""
|
||||
#define bgGRA ""
|
||||
#define bgLRD ""
|
||||
#define bgLGN ""
|
||||
#define bgYEL ""
|
||||
#define bgLBL ""
|
||||
#define bgPIN ""
|
||||
#define bgLCY ""
|
||||
#define bgBRI ""
|
||||
|
||||
#endif /* ^USE_COLOR */
|
||||
|
||||
/*************************
|
||||
* Box drawing sequences *
|
||||
*************************/
|
||||
|
||||
#ifdef FANCY_BOXES
|
||||
|
||||
#define SET_G1 "\x1b)0" /* Set G1 for box drawing */
|
||||
#define RESET_G1 "\x1b)B" /* Reset G1 to ASCII */
|
||||
#define bSTART "\x0e" /* Enter G1 drawing mode */
|
||||
#define bSTOP "\x0f" /* Leave G1 drawing mode */
|
||||
#define bH "q" /* Horizontal line */
|
||||
#define bV "x" /* Vertical line */
|
||||
#define bLT "l" /* Left top corner */
|
||||
#define bRT "k" /* Right top corner */
|
||||
#define bLB "m" /* Left bottom corner */
|
||||
#define bRB "j" /* Right bottom corner */
|
||||
#define bX "n" /* Cross */
|
||||
#define bVR "t" /* Vertical, branch right */
|
||||
#define bVL "u" /* Vertical, branch left */
|
||||
#define bHT "v" /* Horizontal, branch top */
|
||||
#define bHB "w" /* Horizontal, branch bottom */
|
||||
|
||||
#else
|
||||
|
||||
#define SET_G1 ""
|
||||
#define RESET_G1 ""
|
||||
#define bSTART ""
|
||||
#define bSTOP ""
|
||||
#define bH "-"
|
||||
#define bV "|"
|
||||
#define bLT "+"
|
||||
#define bRT "+"
|
||||
#define bLB "+"
|
||||
#define bRB "+"
|
||||
#define bX "+"
|
||||
#define bVR "+"
|
||||
#define bVL "+"
|
||||
#define bHT "+"
|
||||
#define bHB "+"
|
||||
|
||||
#endif /* ^FANCY_BOXES */
|
||||
|
||||
/***********************
|
||||
* Misc terminal codes *
|
||||
***********************/
|
||||
|
||||
#define TERM_HOME "\x1b[H"
|
||||
#define TERM_CLEAR TERM_HOME "\x1b[2J"
|
||||
#define cEOL "\x1b[0K"
|
||||
#define CURSOR_HIDE "\x1b[?25l"
|
||||
#define CURSOR_SHOW "\x1b[?25h"
|
||||
|
||||
/************************
|
||||
* Debug & error macros *
|
||||
************************/
|
||||
|
||||
/* Just print stuff to the appropriate stream. */
|
||||
|
||||
#ifdef MESSAGES_TO_STDOUT
|
||||
#define SAYF(x...) printf(x)
|
||||
#else
|
||||
#define SAYF(x...) fprintf(stderr, x)
|
||||
#endif /* ^MESSAGES_TO_STDOUT */
|
||||
|
||||
/* Show a prefixed warning. */
|
||||
|
||||
#define WARNF(x...) \
|
||||
do { \
|
||||
\
|
||||
SAYF(cYEL "[!] " cBRI "WARNING: " cRST x); \
|
||||
SAYF(cRST "\n"); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Show a prefixed "doing something" message. */
|
||||
|
||||
#define ACTF(x...) \
|
||||
do { \
|
||||
\
|
||||
SAYF(cLBL "[*] " cRST x); \
|
||||
SAYF(cRST "\n"); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Show a prefixed "success" message. */
|
||||
|
||||
#define OKF(x...) \
|
||||
do { \
|
||||
\
|
||||
SAYF(cLGN "[+] " cRST x); \
|
||||
SAYF(cRST "\n"); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Show a prefixed fatal error message (not used in afl). */
|
||||
|
||||
#define BADF(x...) \
|
||||
do { \
|
||||
\
|
||||
SAYF(cLRD "\n[-] " cRST x); \
|
||||
SAYF(cRST "\n"); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Die with a verbose non-OS fatal error message. */
|
||||
|
||||
#define FATAL(x...) \
|
||||
do { \
|
||||
\
|
||||
SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD \
|
||||
"\n[-] PROGRAM ABORT : " cRST x); \
|
||||
SAYF(cLRD "\n Location : " cRST "%s(), %s:%u\n\n", __FUNCTION__, \
|
||||
__FILE__, __LINE__); \
|
||||
exit(1); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Die by calling abort() to provide a core dump. */
|
||||
|
||||
#define ABORT(x...) \
|
||||
do { \
|
||||
\
|
||||
SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD \
|
||||
"\n[-] PROGRAM ABORT : " cRST x); \
|
||||
SAYF(cLRD "\n Stop location : " cRST "%s(), %s:%u\n\n", __FUNCTION__, \
|
||||
__FILE__, __LINE__); \
|
||||
abort(); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Die while also including the output of perror(). */
|
||||
|
||||
#define PFATAL(x...) \
|
||||
do { \
|
||||
\
|
||||
fflush(stdout); \
|
||||
SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD \
|
||||
"\n[-] SYSTEM ERROR : " cRST x); \
|
||||
SAYF(cLRD "\n Stop location : " cRST "%s(), %s:%u\n", __FUNCTION__, \
|
||||
__FILE__, __LINE__); \
|
||||
SAYF(cLRD " OS message : " cRST "%s\n", strerror(errno)); \
|
||||
exit(1); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Die with FAULT() or PFAULT() depending on the value of res (used to
|
||||
interpret different failure modes for read(), write(), etc). */
|
||||
|
||||
#define RPFATAL(res, x...) \
|
||||
do { \
|
||||
\
|
||||
if (res < 0) \
|
||||
PFATAL(x); \
|
||||
else \
|
||||
FATAL(x); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Error-checking versions of read() and write() that call RPFATAL() as
|
||||
appropriate. */
|
||||
|
||||
#define ck_write(fd, buf, len, fn) \
|
||||
do { \
|
||||
\
|
||||
u32 _len = (len); \
|
||||
s32 _res = write(fd, buf, _len); \
|
||||
if (_res != _len) RPFATAL(_res, "Short write to %s", fn); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
#define ck_read(fd, buf, len, fn) \
|
||||
do { \
|
||||
\
|
||||
u32 _len = (len); \
|
||||
s32 _res = read(fd, buf, _len); \
|
||||
if (_res != _len) RPFATAL(_res, "Short read from %s", fn); \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
#endif /* ! _HAVE_DEBUG_H */
|
||||
|
||||
51
include/forkserver.h
Normal file
51
include/forkserver.h
Normal file
@ -0,0 +1,51 @@
|
||||
/*
|
||||
american fuzzy lop++ - forkserver header
|
||||
----------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Forkserver design by Jann Horn <jannhorn@googlemail.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Shared code that implements a forkserver. This is used by the fuzzer
|
||||
as well the other components like afl-tmin.
|
||||
|
||||
*/
|
||||
|
||||
#ifndef __AFL_FORKSERVER_H
|
||||
#define __AFL_FORKSERVER_H
|
||||
|
||||
void handle_timeout(int sig);
|
||||
void init_forkserver(char **argv);
|
||||
|
||||
#ifdef __APPLE__
|
||||
#define MSG_FORK_ON_APPLE \
|
||||
" - On MacOS X, the semantics of fork() syscalls are non-standard and " \
|
||||
"may\n" \
|
||||
" break afl-fuzz performance optimizations when running " \
|
||||
"platform-specific\n" \
|
||||
" targets. To fix this, set AFL_NO_FORKSRV=1 in the environment.\n\n"
|
||||
#else
|
||||
#define MSG_FORK_ON_APPLE ""
|
||||
#endif
|
||||
|
||||
#ifdef RLIMIT_AS
|
||||
#define MSG_ULIMIT_USAGE " ( ulimit -Sv $[%llu << 10];"
|
||||
#else
|
||||
#define MSG_ULIMIT_USAGE " ( ulimit -Sd $[%llu << 10];"
|
||||
#endif /* ^RLIMIT_AS */
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
/*
|
||||
american fuzzy lop - hashing function
|
||||
-------------------------------------
|
||||
american fuzzy lop++ - hashing function
|
||||
---------------------------------------
|
||||
|
||||
The hash32() function is a variant of MurmurHash3, a good
|
||||
non-cryptosafe hashing function developed by Austin Appleby.
|
||||
@ -31,12 +31,12 @@
|
||||
|
||||
#ifdef __x86_64__
|
||||
|
||||
#define ROL64(_x, _r) ((((u64)(_x)) << (_r)) | (((u64)(_x)) >> (64 - (_r))))
|
||||
#define ROL64(_x, _r) ((((u64)(_x)) << (_r)) | (((u64)(_x)) >> (64 - (_r))))
|
||||
|
||||
static inline u32 hash32(const void* key, u32 len, u32 seed) {
|
||||
|
||||
const u64* data = (u64*)key;
|
||||
u64 h1 = seed ^ len;
|
||||
u64 h1 = seed ^ len;
|
||||
|
||||
len >>= 3;
|
||||
|
||||
@ -45,12 +45,12 @@ static inline u32 hash32(const void* key, u32 len, u32 seed) {
|
||||
u64 k1 = *data++;
|
||||
|
||||
k1 *= 0x87c37b91114253d5ULL;
|
||||
k1 = ROL64(k1, 31);
|
||||
k1 = ROL64(k1, 31);
|
||||
k1 *= 0x4cf5ad432745937fULL;
|
||||
|
||||
h1 ^= k1;
|
||||
h1 = ROL64(h1, 27);
|
||||
h1 = h1 * 5 + 0x52dce729;
|
||||
h1 = ROL64(h1, 27);
|
||||
h1 = h1 * 5 + 0x52dce729;
|
||||
|
||||
}
|
||||
|
||||
@ -64,14 +64,14 @@ static inline u32 hash32(const void* key, u32 len, u32 seed) {
|
||||
|
||||
}
|
||||
|
||||
#else
|
||||
#else
|
||||
|
||||
#define ROL32(_x, _r) ((((u32)(_x)) << (_r)) | (((u32)(_x)) >> (32 - (_r))))
|
||||
#define ROL32(_x, _r) ((((u32)(_x)) << (_r)) | (((u32)(_x)) >> (32 - (_r))))
|
||||
|
||||
static inline u32 hash32(const void* key, u32 len, u32 seed) {
|
||||
|
||||
const u32* data = (u32*)key;
|
||||
u32 h1 = seed ^ len;
|
||||
const u32* data = (u32*)key;
|
||||
u32 h1 = seed ^ len;
|
||||
|
||||
len >>= 2;
|
||||
|
||||
@ -80,12 +80,12 @@ static inline u32 hash32(const void* key, u32 len, u32 seed) {
|
||||
u32 k1 = *data++;
|
||||
|
||||
k1 *= 0xcc9e2d51;
|
||||
k1 = ROL32(k1, 15);
|
||||
k1 = ROL32(k1, 15);
|
||||
k1 *= 0x1b873593;
|
||||
|
||||
h1 ^= k1;
|
||||
h1 = ROL32(h1, 13);
|
||||
h1 = h1 * 5 + 0xe6546b64;
|
||||
h1 = ROL32(h1, 13);
|
||||
h1 = h1 * 5 + 0xe6546b64;
|
||||
|
||||
}
|
||||
|
||||
@ -99,6 +99,7 @@ static inline u32 hash32(const void* key, u32 len, u32 seed) {
|
||||
|
||||
}
|
||||
|
||||
#endif /* ^__x86_64__ */
|
||||
#endif /* ^__x86_64__ */
|
||||
|
||||
#endif /* !_HAVE_HASH_H */
|
||||
|
||||
#endif /* !_HAVE_HASH_H */
|
||||
34
include/sharedmem.h
Normal file
34
include/sharedmem.h
Normal file
@ -0,0 +1,34 @@
|
||||
/*
|
||||
american fuzzy lop++ - shared memory related header
|
||||
---------------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Forkserver design by Jann Horn <jannhorn@googlemail.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Shared code to handle the shared memory. This is used by the fuzzer
|
||||
as well the other components like afl-tmin, afl-showmap, etc...
|
||||
|
||||
*/
|
||||
|
||||
#ifndef __AFL_SHAREDMEM_H
|
||||
#define __AFL_SHAREDMEM_H
|
||||
|
||||
void setup_shm(unsigned char dumb_mode);
|
||||
void remove_shm(void);
|
||||
|
||||
#endif
|
||||
|
||||
101
include/types.h
Normal file
101
include/types.h
Normal file
@ -0,0 +1,101 @@
|
||||
/*
|
||||
american fuzzy lop++ - type definitions and minor macros
|
||||
--------------------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
*/
|
||||
|
||||
#ifndef _HAVE_TYPES_H
|
||||
#define _HAVE_TYPES_H
|
||||
|
||||
#include <stdint.h>
|
||||
#include <stdlib.h>
|
||||
|
||||
typedef uint8_t u8;
|
||||
typedef uint16_t u16;
|
||||
typedef uint32_t u32;
|
||||
|
||||
/*
|
||||
|
||||
Ugh. There is an unintended compiler / glibc #include glitch caused by
|
||||
combining the u64 type an %llu in format strings, necessitating a workaround.
|
||||
|
||||
In essence, the compiler is always looking for 'unsigned long long' for %llu.
|
||||
On 32-bit systems, the u64 type (aliased to uint64_t) is expanded to
|
||||
'unsigned long long' in <bits/types.h>, so everything checks out.
|
||||
|
||||
But on 64-bit systems, it is #ifdef'ed in the same file as 'unsigned long'.
|
||||
Now, it only happens in circumstances where the type happens to have the
|
||||
expected bit width, *but* the compiler does not know that... and complains
|
||||
about 'unsigned long' being unsafe to pass to %llu.
|
||||
|
||||
*/
|
||||
|
||||
#ifdef __x86_64__
|
||||
typedef unsigned long long u64;
|
||||
#else
|
||||
typedef uint64_t u64;
|
||||
#endif /* ^__x86_64__ */
|
||||
|
||||
typedef int8_t s8;
|
||||
typedef int16_t s16;
|
||||
typedef int32_t s32;
|
||||
typedef int64_t s64;
|
||||
|
||||
#ifndef MIN
|
||||
#define MIN(_a, _b) ((_a) > (_b) ? (_b) : (_a))
|
||||
#define MAX(_a, _b) ((_a) > (_b) ? (_a) : (_b))
|
||||
#endif /* !MIN */
|
||||
|
||||
#define SWAP16(_x) \
|
||||
({ \
|
||||
\
|
||||
u16 _ret = (_x); \
|
||||
(u16)((_ret << 8) | (_ret >> 8)); \
|
||||
\
|
||||
})
|
||||
|
||||
#define SWAP32(_x) \
|
||||
({ \
|
||||
\
|
||||
u32 _ret = (_x); \
|
||||
(u32)((_ret << 24) | (_ret >> 24) | ((_ret << 8) & 0x00FF0000) | \
|
||||
((_ret >> 8) & 0x0000FF00)); \
|
||||
\
|
||||
})
|
||||
|
||||
#ifdef AFL_LLVM_PASS
|
||||
#define AFL_R(x) (random() % (x))
|
||||
#else
|
||||
#define R(x) (random() % (x))
|
||||
#endif /* ^AFL_LLVM_PASS */
|
||||
|
||||
#define STRINGIFY_INTERNAL(x) #x
|
||||
#define STRINGIFY(x) STRINGIFY_INTERNAL(x)
|
||||
|
||||
#define MEM_BARRIER() __asm__ volatile("" ::: "memory")
|
||||
|
||||
#if __GNUC__ < 6
|
||||
#define likely(_x) (_x)
|
||||
#define unlikely(_x) (_x)
|
||||
#else
|
||||
#define likely(_x) __builtin_expect(!!(_x), 1)
|
||||
#define unlikely(_x) __builtin_expect(!!(_x), 0)
|
||||
#endif
|
||||
|
||||
#endif /* ! _HAVE_TYPES_H */
|
||||
|
||||
@ -18,7 +18,7 @@ HELPER_PATH = $(PREFIX)/lib/afl
|
||||
|
||||
VERSION = $(shell grep '^\#define VERSION ' ../config.h | cut -d '"' -f2)
|
||||
|
||||
CFLAGS ?= -O3 -funroll-loops
|
||||
CFLAGS ?= -O3 -funroll-loops -I ../include/
|
||||
CFLAGS += -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign
|
||||
|
||||
all: libdislocator.so
|
||||
|
||||
@ -1,6 +1,4 @@
|
||||
===================================
|
||||
libdislocator, an abusive allocator
|
||||
===================================
|
||||
# libdislocator, an abusive allocator
|
||||
|
||||
(See ../docs/README for the general instruction manual.)
|
||||
|
||||
@ -45,7 +43,9 @@ when fuzzing small, self-contained binaries.
|
||||
|
||||
To use this library, run AFL like so:
|
||||
|
||||
```
|
||||
AFL_PRELOAD=/path/to/libdislocator.so ./afl-fuzz [...other params...]
|
||||
```
|
||||
|
||||
You *have* to specify path, even if it's just ./libdislocator.so or
|
||||
$PWD/libdislocator.so.
|
||||
@ -25,36 +25,48 @@
|
||||
#include <limits.h>
|
||||
#include <sys/mman.h>
|
||||
|
||||
#include "../config.h"
|
||||
#include "../types.h"
|
||||
#include "config.h"
|
||||
#include "types.h"
|
||||
|
||||
#ifndef PAGE_SIZE
|
||||
# define PAGE_SIZE 4096
|
||||
#endif /* !PAGE_SIZE */
|
||||
#define PAGE_SIZE 4096
|
||||
#endif /* !PAGE_SIZE */
|
||||
|
||||
#ifndef MAP_ANONYMOUS
|
||||
# define MAP_ANONYMOUS MAP_ANON
|
||||
#endif /* !MAP_ANONYMOUS */
|
||||
#define MAP_ANONYMOUS MAP_ANON
|
||||
#endif /* !MAP_ANONYMOUS */
|
||||
|
||||
/* Error / message handling: */
|
||||
|
||||
#define DEBUGF(_x...) do { \
|
||||
if (alloc_verbose) { \
|
||||
if (++call_depth == 1) { \
|
||||
#define DEBUGF(_x...) \
|
||||
do { \
|
||||
\
|
||||
if (alloc_verbose) { \
|
||||
\
|
||||
if (++call_depth == 1) { \
|
||||
\
|
||||
fprintf(stderr, "[AFL] " _x); \
|
||||
fprintf(stderr, "\n"); \
|
||||
} \
|
||||
call_depth--; \
|
||||
} \
|
||||
fprintf(stderr, "\n"); \
|
||||
\
|
||||
} \
|
||||
call_depth--; \
|
||||
\
|
||||
} \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
#define FATAL(_x...) do { \
|
||||
if (++call_depth == 1) { \
|
||||
#define FATAL(_x...) \
|
||||
do { \
|
||||
\
|
||||
if (++call_depth == 1) { \
|
||||
\
|
||||
fprintf(stderr, "*** [AFL] " _x); \
|
||||
fprintf(stderr, " ***\n"); \
|
||||
abort(); \
|
||||
} \
|
||||
call_depth--; \
|
||||
fprintf(stderr, " ***\n"); \
|
||||
abort(); \
|
||||
\
|
||||
} \
|
||||
call_depth--; \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* Macro to count the number of pages needed to store a buffer: */
|
||||
@ -63,7 +75,7 @@
|
||||
|
||||
/* Canary & clobber bytes: */
|
||||
|
||||
#define ALLOC_CANARY 0xAACCAACC
|
||||
#define ALLOC_CANARY 0xAACCAACC
|
||||
#define ALLOC_CLOBBER 0xCC
|
||||
|
||||
#define PTR_C(_p) (((u32*)(_p))[-1])
|
||||
@ -73,14 +85,13 @@
|
||||
|
||||
static u32 max_mem = MAX_ALLOC; /* Max heap usage to permit */
|
||||
static u8 alloc_verbose, /* Additional debug messages */
|
||||
hard_fail, /* abort() when max_mem exceeded? */
|
||||
no_calloc_over; /* abort() on calloc() overflows? */
|
||||
hard_fail, /* abort() when max_mem exceeded? */
|
||||
no_calloc_over; /* abort() on calloc() overflows? */
|
||||
|
||||
static __thread size_t total_mem; /* Currently allocated mem */
|
||||
|
||||
static __thread u32 call_depth; /* To avoid recursion via fprintf() */
|
||||
|
||||
|
||||
/* This is the main alloc function. It allocates one page more than necessary,
|
||||
sets that tailing page to PROT_NONE, and then increments the return address
|
||||
so that it is right-aligned to that boundary. Since it always uses mmap(),
|
||||
@ -90,14 +101,11 @@ static void* __dislocator_alloc(size_t len) {
|
||||
|
||||
void* ret;
|
||||
|
||||
|
||||
if (total_mem + len > max_mem || total_mem + len < total_mem) {
|
||||
|
||||
if (hard_fail)
|
||||
FATAL("total allocs exceed %u MB", max_mem / 1024 / 1024);
|
||||
if (hard_fail) FATAL("total allocs exceed %u MB", max_mem / 1024 / 1024);
|
||||
|
||||
DEBUGF("total allocs exceed %u MB, returning NULL",
|
||||
max_mem / 1024 / 1024);
|
||||
DEBUGF("total allocs exceed %u MB, returning NULL", max_mem / 1024 / 1024);
|
||||
|
||||
return NULL;
|
||||
|
||||
@ -142,7 +150,6 @@ static void* __dislocator_alloc(size_t len) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* The "user-facing" wrapper for calloc(). This just checks for overflows and
|
||||
displays debug messages if requested. */
|
||||
|
||||
@ -157,8 +164,11 @@ void* calloc(size_t elem_len, size_t elem_cnt) {
|
||||
if (elem_cnt && len / elem_cnt != elem_len) {
|
||||
|
||||
if (no_calloc_over) {
|
||||
DEBUGF("calloc(%zu, %zu) would overflow, returning NULL", elem_len, elem_cnt);
|
||||
|
||||
DEBUGF("calloc(%zu, %zu) would overflow, returning NULL", elem_len,
|
||||
elem_cnt);
|
||||
return NULL;
|
||||
|
||||
}
|
||||
|
||||
FATAL("calloc(%zu, %zu) would overflow", elem_len, elem_cnt);
|
||||
@ -174,7 +184,6 @@ void* calloc(size_t elem_len, size_t elem_cnt) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* The wrapper for malloc(). Roughly the same, also clobbers the returned
|
||||
memory (unlike calloc(), malloc() is not guaranteed to return zeroed
|
||||
memory). */
|
||||
@ -193,7 +202,6 @@ void* malloc(size_t len) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* The wrapper for free(). This simply marks the entire region as PROT_NONE.
|
||||
If the region is already freed, the code will segfault during the attempt to
|
||||
read the canary. Not very graceful, but works, right? */
|
||||
@ -224,7 +232,6 @@ void free(void* ptr) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Realloc is pretty straightforward, too. We forcibly reallocate the buffer,
|
||||
move data, and then free (aka mprotect()) the original one. */
|
||||
|
||||
@ -249,7 +256,6 @@ void* realloc(void* ptr, size_t len) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
__attribute__((constructor)) void __dislocator_init(void) {
|
||||
|
||||
u8* tmp = getenv("AFL_LD_LIMIT_MB");
|
||||
@ -266,3 +272,4 @@ __attribute__((constructor)) void __dislocator_init(void) {
|
||||
no_calloc_over = !!getenv("AFL_LD_NO_CALLOC_OVER");
|
||||
|
||||
}
|
||||
|
||||
|
||||
@ -18,7 +18,7 @@ HELPER_PATH = $(PREFIX)/lib/afl
|
||||
|
||||
VERSION = $(shell grep '^\#define VERSION ' ../config.h | cut -d '"' -f2)
|
||||
|
||||
CFLAGS ?= -O3 -funroll-loops
|
||||
CFLAGS ?= -O3 -funroll-loops -I ../include/
|
||||
CFLAGS += -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign
|
||||
|
||||
all: libtokencap.so
|
||||
|
||||
@ -1,10 +1,8 @@
|
||||
=========================================
|
||||
strcmp() / memcmp() token capture library
|
||||
=========================================
|
||||
# strcmp() / memcmp() token capture library
|
||||
|
||||
(See ../docs/README for the general instruction manual.)
|
||||
|
||||
This Linux-only companion library allows you to instrument strcmp(), memcmp(),
|
||||
This Linux-only companion library allows you to instrument `strcmp()`, `memcmp()`,
|
||||
and related functions to automatically extract syntax tokens passed to any of
|
||||
these libcalls. The resulting list of tokens may be then given as a starting
|
||||
dictionary to afl-fuzz (the -x option) to improve coverage on subsequent
|
||||
@ -31,15 +29,18 @@ with -fno-builtin and is linked dynamically. If you wish to automate the first
|
||||
part without mucking with CFLAGS in Makefiles, you can set AFL_NO_BUILTIN=1
|
||||
when using afl-gcc. This setting specifically adds the following flags:
|
||||
|
||||
```
|
||||
-fno-builtin-strcmp -fno-builtin-strncmp -fno-builtin-strcasecmp
|
||||
-fno-builtin-strcasencmp -fno-builtin-memcmp -fno-builtin-strstr
|
||||
-fno-builtin-strcasestr
|
||||
```
|
||||
|
||||
The next step is simply loading this library via LD_PRELOAD. The optimal usage
|
||||
pattern is to allow afl-fuzz to fuzz normally for a while and build up a corpus,
|
||||
and then fire off the target binary, with libtokencap.so loaded, on every file
|
||||
found by AFL in that earlier run. This demonstrates the basic principle:
|
||||
|
||||
```
|
||||
export AFL_TOKEN_FILE=$PWD/temp_output.txt
|
||||
|
||||
for i in <out_dir>/queue/id*; do
|
||||
@ -48,6 +49,7 @@ found by AFL in that earlier run. This demonstrates the basic principle:
|
||||
done
|
||||
|
||||
sort -u temp_output.txt >afl_dictionary.txt
|
||||
```
|
||||
|
||||
If you don't get any results, the target library is probably not using strcmp()
|
||||
and memcmp() to parse input; or you haven't compiled it with -fno-builtin; or
|
||||
@ -55,7 +57,7 @@ the whole thing isn't dynamically linked, and LD_PRELOAD is having no effect.
|
||||
|
||||
PS. The library is Linux-only because there is probably no particularly portable
|
||||
and non-invasive way to distinguish between read-only and read-write memory
|
||||
mappings. The __tokencap_load_mappings() function is the only thing that would
|
||||
mappings. The `__tokencap_load_mappings()` function is the only thing that would
|
||||
need to be changed for other OSes. Porting to platforms with /proc/<pid>/maps
|
||||
(e.g., FreeBSD) should be trivial.
|
||||
|
||||
@ -27,30 +27,26 @@
|
||||
#include "../config.h"
|
||||
|
||||
#ifndef __linux__
|
||||
# error "Sorry, this library is Linux-specific for now!"
|
||||
#endif /* !__linux__ */
|
||||
|
||||
#error "Sorry, this library is Linux-specific for now!"
|
||||
#endif /* !__linux__ */
|
||||
|
||||
/* Mapping data and such */
|
||||
|
||||
#define MAX_MAPPINGS 1024
|
||||
|
||||
static struct mapping {
|
||||
void *st, *en;
|
||||
} __tokencap_ro[MAX_MAPPINGS];
|
||||
static struct mapping { void *st, *en; } __tokencap_ro[MAX_MAPPINGS];
|
||||
|
||||
static u32 __tokencap_ro_cnt;
|
||||
static u8 __tokencap_ro_loaded;
|
||||
static FILE* __tokencap_out_file;
|
||||
|
||||
|
||||
/* Identify read-only regions in memory. Only parameters that fall into these
|
||||
ranges are worth dumping when passed to strcmp() and so on. Read-write
|
||||
regions are far more likely to contain user input instead. */
|
||||
|
||||
static void __tokencap_load_mappings(void) {
|
||||
|
||||
u8 buf[MAX_LINE];
|
||||
u8 buf[MAX_LINE];
|
||||
FILE* f = fopen("/proc/self/maps", "r");
|
||||
|
||||
__tokencap_ro_loaded = 1;
|
||||
@ -59,8 +55,8 @@ static void __tokencap_load_mappings(void) {
|
||||
|
||||
while (fgets(buf, MAX_LINE, f)) {
|
||||
|
||||
u8 rf, wf;
|
||||
void* st, *en;
|
||||
u8 rf, wf;
|
||||
void *st, *en;
|
||||
|
||||
if (sscanf(buf, "%p-%p %c%c", &st, &en, &rf, &wf) != 4) continue;
|
||||
if (wf == 'w' || rf != 'r') continue;
|
||||
@ -76,7 +72,6 @@ static void __tokencap_load_mappings(void) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Check an address against the list of read-only mappings. */
|
||||
|
||||
static u8 __tokencap_is_ro(const void* ptr) {
|
||||
@ -85,20 +80,19 @@ static u8 __tokencap_is_ro(const void* ptr) {
|
||||
|
||||
if (!__tokencap_ro_loaded) __tokencap_load_mappings();
|
||||
|
||||
for (i = 0; i < __tokencap_ro_cnt; i++)
|
||||
for (i = 0; i < __tokencap_ro_cnt; i++)
|
||||
if (ptr >= __tokencap_ro[i].st && ptr <= __tokencap_ro[i].en) return 1;
|
||||
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Dump an interesting token to output file, quoting and escaping it
|
||||
properly. */
|
||||
|
||||
static void __tokencap_dump(const u8* ptr, size_t len, u8 is_text) {
|
||||
|
||||
u8 buf[MAX_AUTO_EXTRA * 4 + 1];
|
||||
u8 buf[MAX_AUTO_EXTRA * 4 + 1];
|
||||
u32 i;
|
||||
u32 pos = 0;
|
||||
|
||||
@ -120,9 +114,7 @@ static void __tokencap_dump(const u8* ptr, size_t len, u8 is_text) {
|
||||
pos += 4;
|
||||
break;
|
||||
|
||||
default:
|
||||
|
||||
buf[pos++] = ptr[i];
|
||||
default: buf[pos++] = ptr[i];
|
||||
|
||||
}
|
||||
|
||||
@ -130,11 +122,10 @@ static void __tokencap_dump(const u8* ptr, size_t len, u8 is_text) {
|
||||
|
||||
buf[pos] = 0;
|
||||
|
||||
fprintf(__tokencap_out_file, "\"%s\"\n", buf);
|
||||
fprintf(__tokencap_out_file, "\"%s\"\n", buf);
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Replacements for strcmp(), memcmp(), and so on. Note that these will be used
|
||||
only if the target is compiled with -fno-builtins and linked dynamically. */
|
||||
|
||||
@ -151,13 +142,13 @@ int strcmp(const char* str1, const char* str2) {
|
||||
|
||||
if (c1 != c2) return (c1 > c2) ? 1 : -1;
|
||||
if (!c1) return 0;
|
||||
str1++; str2++;
|
||||
str1++;
|
||||
str2++;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
#undef strncmp
|
||||
|
||||
int strncmp(const char* str1, const char* str2, size_t len) {
|
||||
@ -171,7 +162,8 @@ int strncmp(const char* str1, const char* str2, size_t len) {
|
||||
|
||||
if (!c1) return 0;
|
||||
if (c1 != c2) return (c1 > c2) ? 1 : -1;
|
||||
str1++; str2++;
|
||||
str1++;
|
||||
str2++;
|
||||
|
||||
}
|
||||
|
||||
@ -179,7 +171,6 @@ int strncmp(const char* str1, const char* str2, size_t len) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
#undef strcasecmp
|
||||
|
||||
int strcasecmp(const char* str1, const char* str2) {
|
||||
@ -193,13 +184,13 @@ int strcasecmp(const char* str1, const char* str2) {
|
||||
|
||||
if (c1 != c2) return (c1 > c2) ? 1 : -1;
|
||||
if (!c1) return 0;
|
||||
str1++; str2++;
|
||||
str1++;
|
||||
str2++;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
#undef strncasecmp
|
||||
|
||||
int strncasecmp(const char* str1, const char* str2, size_t len) {
|
||||
@ -213,7 +204,8 @@ int strncasecmp(const char* str1, const char* str2, size_t len) {
|
||||
|
||||
if (!c1) return 0;
|
||||
if (c1 != c2) return (c1 > c2) ? 1 : -1;
|
||||
str1++; str2++;
|
||||
str1++;
|
||||
str2++;
|
||||
|
||||
}
|
||||
|
||||
@ -221,7 +213,6 @@ int strncasecmp(const char* str1, const char* str2, size_t len) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
#undef memcmp
|
||||
|
||||
int memcmp(const void* mem1, const void* mem2, size_t len) {
|
||||
@ -233,7 +224,8 @@ int memcmp(const void* mem1, const void* mem2, size_t len) {
|
||||
|
||||
unsigned char c1 = *(const char*)mem1, c2 = *(const char*)mem2;
|
||||
if (c1 != c2) return (c1 > c2) ? 1 : -1;
|
||||
mem1++; mem2++;
|
||||
mem1++;
|
||||
mem2++;
|
||||
|
||||
}
|
||||
|
||||
@ -241,7 +233,6 @@ int memcmp(const void* mem1, const void* mem2, size_t len) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
#undef strstr
|
||||
|
||||
char* strstr(const char* haystack, const char* needle) {
|
||||
@ -249,16 +240,17 @@ char* strstr(const char* haystack, const char* needle) {
|
||||
if (__tokencap_is_ro(haystack))
|
||||
__tokencap_dump(haystack, strlen(haystack), 1);
|
||||
|
||||
if (__tokencap_is_ro(needle))
|
||||
__tokencap_dump(needle, strlen(needle), 1);
|
||||
if (__tokencap_is_ro(needle)) __tokencap_dump(needle, strlen(needle), 1);
|
||||
|
||||
do {
|
||||
|
||||
const char* n = needle;
|
||||
const char* h = haystack;
|
||||
|
||||
while(*n && *h && *n == *h) n++, h++;
|
||||
while (*n && *h && *n == *h)
|
||||
n++, h++;
|
||||
|
||||
if(!*n) return (char*)haystack;
|
||||
if (!*n) return (char*)haystack;
|
||||
|
||||
} while (*(haystack++));
|
||||
|
||||
@ -266,7 +258,6 @@ char* strstr(const char* haystack, const char* needle) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
#undef strcasestr
|
||||
|
||||
char* strcasestr(const char* haystack, const char* needle) {
|
||||
@ -274,25 +265,24 @@ char* strcasestr(const char* haystack, const char* needle) {
|
||||
if (__tokencap_is_ro(haystack))
|
||||
__tokencap_dump(haystack, strlen(haystack), 1);
|
||||
|
||||
if (__tokencap_is_ro(needle))
|
||||
__tokencap_dump(needle, strlen(needle), 1);
|
||||
if (__tokencap_is_ro(needle)) __tokencap_dump(needle, strlen(needle), 1);
|
||||
|
||||
do {
|
||||
|
||||
const char* n = needle;
|
||||
const char* h = haystack;
|
||||
|
||||
while(*n && *h && tolower(*n) == tolower(*h)) n++, h++;
|
||||
while (*n && *h && tolower(*n) == tolower(*h))
|
||||
n++, h++;
|
||||
|
||||
if(!*n) return (char*)haystack;
|
||||
if (!*n) return (char*)haystack;
|
||||
|
||||
} while(*(haystack++));
|
||||
} while (*(haystack++));
|
||||
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Init code to open the output file (or default to stderr). */
|
||||
|
||||
__attribute__((constructor)) void __tokencap_init(void) {
|
||||
|
||||
443
llvm_mode/LLVMInsTrim.so.cc
Normal file
443
llvm_mode/LLVMInsTrim.so.cc
Normal file
@ -0,0 +1,443 @@
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <stdarg.h>
|
||||
#include <unistd.h>
|
||||
|
||||
#include "llvm/ADT/DenseMap.h"
|
||||
#include "llvm/ADT/DenseSet.h"
|
||||
#include "llvm/IR/CFG.h"
|
||||
#include "llvm/IR/Dominators.h"
|
||||
#include "llvm/IR/IRBuilder.h"
|
||||
#include "llvm/IR/Instructions.h"
|
||||
#include "llvm/IR/LegacyPassManager.h"
|
||||
#include "llvm/IR/Module.h"
|
||||
#include "llvm/Pass.h"
|
||||
#include "llvm/Support/raw_ostream.h"
|
||||
#include "llvm/Transforms/IPO/PassManagerBuilder.h"
|
||||
#include "llvm/Transforms/Utils/BasicBlockUtils.h"
|
||||
#include "llvm/IR/DebugInfo.h"
|
||||
#include "llvm/IR/BasicBlock.h"
|
||||
#include "llvm/IR/CFG.h"
|
||||
#include <unordered_set>
|
||||
#include <random>
|
||||
#include <list>
|
||||
#include <string>
|
||||
#include <fstream>
|
||||
|
||||
#include "config.h"
|
||||
#include "debug.h"
|
||||
|
||||
#include "MarkNodes.h"
|
||||
|
||||
using namespace llvm;
|
||||
|
||||
static cl::opt<bool> MarkSetOpt("markset", cl::desc("MarkSet"),
|
||||
cl::init(false));
|
||||
static cl::opt<bool> LoopHeadOpt("loophead", cl::desc("LoopHead"),
|
||||
cl::init(false));
|
||||
|
||||
namespace {
|
||||
|
||||
struct InsTrim : public ModulePass {
|
||||
|
||||
protected:
|
||||
std::list<std::string> myWhitelist;
|
||||
|
||||
private:
|
||||
std::mt19937 generator;
|
||||
int total_instr = 0;
|
||||
|
||||
unsigned int genLabel() {
|
||||
|
||||
return generator() & (MAP_SIZE - 1);
|
||||
|
||||
}
|
||||
|
||||
public:
|
||||
static char ID;
|
||||
InsTrim() : ModulePass(ID), generator(0) {
|
||||
|
||||
char *instWhiteListFilename = getenv("AFL_LLVM_WHITELIST");
|
||||
if (instWhiteListFilename) {
|
||||
|
||||
std::string line;
|
||||
std::ifstream fileStream;
|
||||
fileStream.open(instWhiteListFilename);
|
||||
if (!fileStream) report_fatal_error("Unable to open AFL_LLVM_WHITELIST");
|
||||
getline(fileStream, line);
|
||||
while (fileStream) {
|
||||
|
||||
myWhitelist.push_back(line);
|
||||
getline(fileStream, line);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void getAnalysisUsage(AnalysisUsage &AU) const override {
|
||||
|
||||
AU.addRequired<DominatorTreeWrapperPass>();
|
||||
|
||||
}
|
||||
|
||||
#if LLVM_VERSION_MAJOR < 4
|
||||
const char *
|
||||
#else
|
||||
StringRef
|
||||
#endif
|
||||
getPassName() const override {
|
||||
|
||||
return "InstTrim Instrumentation";
|
||||
|
||||
}
|
||||
|
||||
bool runOnModule(Module &M) override {
|
||||
|
||||
char be_quiet = 0;
|
||||
|
||||
if (isatty(2) && !getenv("AFL_QUIET")) {
|
||||
|
||||
SAYF(cCYA "LLVMInsTrim" VERSION cRST " by csienslab\n");
|
||||
|
||||
} else
|
||||
|
||||
be_quiet = 1;
|
||||
|
||||
#if LLVM_VERSION_MAJOR < 9
|
||||
char *neverZero_counters_str;
|
||||
if ((neverZero_counters_str = getenv("AFL_LLVM_NOT_ZERO")) != NULL)
|
||||
OKF("LLVM neverZero activated (by hexcoder)\n");
|
||||
#endif
|
||||
|
||||
if (getenv("AFL_LLVM_INSTRIM_LOOPHEAD") != NULL ||
|
||||
getenv("LOOPHEAD") != NULL) {
|
||||
|
||||
LoopHeadOpt = true;
|
||||
|
||||
}
|
||||
|
||||
// this is our default
|
||||
MarkSetOpt = true;
|
||||
|
||||
/* // I dont think this makes sense to port into LLVMInsTrim
|
||||
char* inst_ratio_str = getenv("AFL_INST_RATIO");
|
||||
unsigned int inst_ratio = 100;
|
||||
if (inst_ratio_str) {
|
||||
|
||||
if (sscanf(inst_ratio_str, "%u", &inst_ratio) != 1 || !inst_ratio ||
|
||||
inst_ratio > 100) FATAL("Bad value of AFL_INST_RATIO (must be between 1
|
||||
and 100)");
|
||||
|
||||
}
|
||||
|
||||
*/
|
||||
|
||||
LLVMContext &C = M.getContext();
|
||||
IntegerType *Int8Ty = IntegerType::getInt8Ty(C);
|
||||
IntegerType *Int32Ty = IntegerType::getInt32Ty(C);
|
||||
|
||||
GlobalVariable *CovMapPtr = new GlobalVariable(
|
||||
M, PointerType::getUnqual(Int8Ty), false, GlobalValue::ExternalLinkage,
|
||||
nullptr, "__afl_area_ptr");
|
||||
|
||||
GlobalVariable *OldPrev = new GlobalVariable(
|
||||
M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_loc", 0,
|
||||
GlobalVariable::GeneralDynamicTLSModel, 0, false);
|
||||
|
||||
u64 total_rs = 0;
|
||||
u64 total_hs = 0;
|
||||
|
||||
for (Function &F : M) {
|
||||
|
||||
if (!F.size()) { continue; }
|
||||
|
||||
if (!myWhitelist.empty()) {
|
||||
|
||||
bool instrumentBlock = false;
|
||||
DebugLoc Loc;
|
||||
StringRef instFilename;
|
||||
|
||||
for (auto &BB : F) {
|
||||
|
||||
BasicBlock::iterator IP = BB.getFirstInsertionPt();
|
||||
IRBuilder<> IRB(&(*IP));
|
||||
if (!Loc) Loc = IP->getDebugLoc();
|
||||
|
||||
}
|
||||
|
||||
if (Loc) {
|
||||
|
||||
DILocation *cDILoc = dyn_cast<DILocation>(Loc.getAsMDNode());
|
||||
|
||||
unsigned int instLine = cDILoc->getLine();
|
||||
instFilename = cDILoc->getFilename();
|
||||
|
||||
if (instFilename.str().empty()) {
|
||||
|
||||
/* If the original location is empty, try using the inlined location
|
||||
*/
|
||||
DILocation *oDILoc = cDILoc->getInlinedAt();
|
||||
if (oDILoc) {
|
||||
|
||||
instFilename = oDILoc->getFilename();
|
||||
instLine = oDILoc->getLine();
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* Continue only if we know where we actually are */
|
||||
if (!instFilename.str().empty()) {
|
||||
|
||||
for (std::list<std::string>::iterator it = myWhitelist.begin();
|
||||
it != myWhitelist.end(); ++it) {
|
||||
|
||||
if (instFilename.str().length() >= it->length()) {
|
||||
|
||||
if (instFilename.str().compare(
|
||||
instFilename.str().length() - it->length(),
|
||||
it->length(), *it) == 0) {
|
||||
|
||||
instrumentBlock = true;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* Either we couldn't figure out our location or the location is
|
||||
* not whitelisted, so we skip instrumentation. */
|
||||
if (!instrumentBlock) {
|
||||
|
||||
if (!instFilename.str().empty())
|
||||
SAYF(cYEL "[!] " cBRI "Not in whitelist, skipping %s ...\n",
|
||||
instFilename.str().c_str());
|
||||
else
|
||||
SAYF(cYEL "[!] " cBRI "No filename information found, skipping it");
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
std::unordered_set<BasicBlock *> MS;
|
||||
if (!MarkSetOpt) {
|
||||
|
||||
for (auto &BB : F) {
|
||||
|
||||
MS.insert(&BB);
|
||||
|
||||
}
|
||||
|
||||
total_rs += F.size();
|
||||
|
||||
} else {
|
||||
|
||||
auto Result = markNodes(&F);
|
||||
auto RS = Result.first;
|
||||
auto HS = Result.second;
|
||||
|
||||
MS.insert(RS.begin(), RS.end());
|
||||
if (!LoopHeadOpt) {
|
||||
|
||||
MS.insert(HS.begin(), HS.end());
|
||||
total_rs += MS.size();
|
||||
|
||||
} else {
|
||||
|
||||
DenseSet<std::pair<BasicBlock *, BasicBlock *>> EdgeSet;
|
||||
DominatorTreeWrapperPass * DTWP =
|
||||
&getAnalysis<DominatorTreeWrapperPass>(F);
|
||||
auto DT = &DTWP->getDomTree();
|
||||
|
||||
total_rs += RS.size();
|
||||
total_hs += HS.size();
|
||||
|
||||
for (BasicBlock *BB : HS) {
|
||||
|
||||
bool Inserted = false;
|
||||
for (auto BI = pred_begin(BB), BE = pred_end(BB); BI != BE; ++BI) {
|
||||
|
||||
auto Edge = BasicBlockEdge(*BI, BB);
|
||||
if (Edge.isSingleEdge() && DT->dominates(Edge, BB)) {
|
||||
|
||||
EdgeSet.insert({*BI, BB});
|
||||
Inserted = true;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (!Inserted) {
|
||||
|
||||
MS.insert(BB);
|
||||
total_rs += 1;
|
||||
total_hs -= 1;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
for (auto I = EdgeSet.begin(), E = EdgeSet.end(); I != E; ++I) {
|
||||
|
||||
auto PredBB = I->first;
|
||||
auto SuccBB = I->second;
|
||||
auto NewBB =
|
||||
SplitBlockPredecessors(SuccBB, {PredBB}, ".split", DT, nullptr,
|
||||
#if LLVM_VERSION_MAJOR >= 8
|
||||
nullptr,
|
||||
#endif
|
||||
false);
|
||||
MS.insert(NewBB);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
auto *EBB = &F.getEntryBlock();
|
||||
if (succ_begin(EBB) == succ_end(EBB)) {
|
||||
|
||||
MS.insert(EBB);
|
||||
total_rs += 1;
|
||||
|
||||
}
|
||||
|
||||
for (BasicBlock &BB : F) {
|
||||
|
||||
if (MS.find(&BB) == MS.end()) { continue; }
|
||||
IRBuilder<> IRB(&*BB.getFirstInsertionPt());
|
||||
IRB.CreateStore(ConstantInt::get(Int32Ty, genLabel()), OldPrev);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
for (BasicBlock &BB : F) {
|
||||
|
||||
auto PI = pred_begin(&BB);
|
||||
auto PE = pred_end(&BB);
|
||||
if (MarkSetOpt && MS.find(&BB) == MS.end()) { continue; }
|
||||
|
||||
IRBuilder<> IRB(&*BB.getFirstInsertionPt());
|
||||
Value * L = NULL;
|
||||
if (PI == PE) {
|
||||
|
||||
L = ConstantInt::get(Int32Ty, genLabel());
|
||||
|
||||
} else {
|
||||
|
||||
auto *PN = PHINode::Create(Int32Ty, 0, "", &*BB.begin());
|
||||
DenseMap<BasicBlock *, unsigned> PredMap;
|
||||
for (auto PI = pred_begin(&BB), PE = pred_end(&BB); PI != PE; ++PI) {
|
||||
|
||||
BasicBlock *PBB = *PI;
|
||||
auto It = PredMap.insert({PBB, genLabel()});
|
||||
unsigned Label = It.first->second;
|
||||
PN->addIncoming(ConstantInt::get(Int32Ty, Label), PBB);
|
||||
|
||||
}
|
||||
|
||||
L = PN;
|
||||
|
||||
}
|
||||
|
||||
/* Load prev_loc */
|
||||
LoadInst *PrevLoc = IRB.CreateLoad(OldPrev);
|
||||
PrevLoc->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
|
||||
Value *PrevLocCasted = IRB.CreateZExt(PrevLoc, IRB.getInt32Ty());
|
||||
|
||||
/* Load SHM pointer */
|
||||
LoadInst *MapPtr = IRB.CreateLoad(CovMapPtr);
|
||||
MapPtr->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
|
||||
Value *MapPtrIdx =
|
||||
IRB.CreateGEP(MapPtr, IRB.CreateXor(PrevLocCasted, L));
|
||||
|
||||
/* Update bitmap */
|
||||
LoadInst *Counter = IRB.CreateLoad(MapPtrIdx);
|
||||
Counter->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
|
||||
|
||||
Value *Incr = IRB.CreateAdd(Counter, ConstantInt::get(Int8Ty, 1));
|
||||
|
||||
#if LLVM_VERSION_MAJOR < 9
|
||||
if (neverZero_counters_str !=
|
||||
NULL) // with llvm 9 we make this the default as the bug in llvm is
|
||||
// then fixed
|
||||
#else
|
||||
if (1) // with llvm 9 we make this the default as the bug in llvm is
|
||||
// then fixed
|
||||
#endif
|
||||
{
|
||||
|
||||
/* hexcoder: Realize a counter that skips zero during overflow.
|
||||
* Once this counter reaches its maximum value, it next increments to
|
||||
* 1
|
||||
*
|
||||
* Instead of
|
||||
* Counter + 1 -> Counter
|
||||
* we inject now this
|
||||
* Counter + 1 -> {Counter, OverflowFlag}
|
||||
* Counter + OverflowFlag -> Counter
|
||||
*/
|
||||
auto cf = IRB.CreateICmpEQ(Incr, ConstantInt::get(Int8Ty, 0));
|
||||
auto carry = IRB.CreateZExt(cf, Int8Ty);
|
||||
Incr = IRB.CreateAdd(Incr, carry);
|
||||
|
||||
}
|
||||
|
||||
IRB.CreateStore(Incr, MapPtrIdx)
|
||||
->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
|
||||
|
||||
/* Set prev_loc to cur_loc >> 1 */
|
||||
/*
|
||||
StoreInst *Store = IRB.CreateStore(ConstantInt::get(Int32Ty, L >> 1),
|
||||
OldPrev); Store->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C,
|
||||
None));
|
||||
*/
|
||||
|
||||
total_instr++;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
OKF("Instrumented %u locations (%llu, %llu) (%s mode)\n" /*", ratio
|
||||
%u%%)."*/
|
||||
,
|
||||
total_instr, total_rs, total_hs,
|
||||
getenv("AFL_HARDEN")
|
||||
? "hardened"
|
||||
: ((getenv("AFL_USE_ASAN") || getenv("AFL_USE_MSAN"))
|
||||
? "ASAN/MSAN"
|
||||
: "non-hardened") /*, inst_ratio*/);
|
||||
return false;
|
||||
|
||||
}
|
||||
|
||||
}; // end of struct InsTrim
|
||||
|
||||
} // end of anonymous namespace
|
||||
|
||||
char InsTrim::ID = 0;
|
||||
|
||||
static void registerAFLPass(const PassManagerBuilder &,
|
||||
legacy::PassManagerBase &PM) {
|
||||
|
||||
PM.add(new InsTrim());
|
||||
|
||||
}
|
||||
|
||||
static RegisterStandardPasses RegisterAFLPass(
|
||||
PassManagerBuilder::EP_OptimizerLast, registerAFLPass);
|
||||
|
||||
static RegisterStandardPasses RegisterAFLPass0(
|
||||
PassManagerBuilder::EP_EnabledOnOptLevel0, registerAFLPass);
|
||||
|
||||
@ -16,57 +16,124 @@
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
|
||||
# For Heiko:
|
||||
#TEST_MMAP=1
|
||||
|
||||
PREFIX ?= /usr/local
|
||||
HELPER_PATH = $(PREFIX)/lib/afl
|
||||
BIN_PATH = $(PREFIX)/bin
|
||||
|
||||
VERSION = $(shell grep '^\#define VERSION ' ../config.h | cut -d '"' -f2)
|
||||
|
||||
LLVM_CONFIG ?= llvm-config
|
||||
#LLVM_OK = $(shell $(LLVM_CONFIG) --version | egrep -q '^[5-6]' && echo 0 || echo 1 )
|
||||
LLVM_UNSUPPORTED = $(shell $(LLVM_CONFIG) --version | egrep -q '^9|3.0' && echo 1 || echo 0 )
|
||||
ifeq "$(shell uname)" "OpenBSD"
|
||||
LLVM_CONFIG ?= $(BIN_PATH)/llvm-config
|
||||
HAS_OPT = $(shell test -x $(BIN_PATH)/opt && echo 0 || echo 1)
|
||||
ifeq "$(HAS_OPT)" "1"
|
||||
$(error llvm_mode needs a complete llvm installation (versions 3.8.0 up to 9) -> e.g. "pkg_add llvm-7.0.1p9")
|
||||
endif
|
||||
else
|
||||
LLVM_CONFIG ?= llvm-config
|
||||
endif
|
||||
|
||||
LLVMVER = $(shell $(LLVM_CONFIG) --version)
|
||||
LLVM_UNSUPPORTED = $(shell $(LLVM_CONFIG) --version | egrep -q '^[12]|^3\.0|^1[0-9]' && echo 1 || echo 0 )
|
||||
LLVM_MAJOR = ($shell $(LLVM_CONFIG) --version | sed 's/\..*//')
|
||||
|
||||
ifeq "$(LLVM_UNSUPPORTED)" "1"
|
||||
$(warn llvm_mode only supports versions 3.8.0 up to 8.x )
|
||||
$(warn llvm_mode only supports versions 3.8.0 up to 9)
|
||||
endif
|
||||
|
||||
# this is not visible yet:
|
||||
ifeq "$(LLVM_MAJOR)" "9"
|
||||
$(info llvm_mode deteted llvm 9, enabling neverZero implementation)
|
||||
endif
|
||||
|
||||
CFLAGS ?= -O3 -funroll-loops
|
||||
CFLAGS += -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign \
|
||||
CFLAGS += -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -I ../include/ \
|
||||
-DAFL_PATH=\"$(HELPER_PATH)\" -DBIN_PATH=\"$(BIN_PATH)\" \
|
||||
-DVERSION=\"$(VERSION)\"
|
||||
-DVERSION=\"$(VERSION)\"
|
||||
ifdef AFL_TRACE_PC
|
||||
CFLAGS += -DUSE_TRACE_PC=1
|
||||
endif
|
||||
|
||||
CXXFLAGS ?= -O3 -funroll-loops
|
||||
CXXFLAGS += -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign \
|
||||
CXXFLAGS += -Wall -D_FORTIFY_SOURCE=2 -g -I ../include/ \
|
||||
-DVERSION=\"$(VERSION)\" -Wno-variadic-macros
|
||||
|
||||
CLANG_CFL = `$(LLVM_CONFIG) --cxxflags` -Wl,-znodelete -fno-rtti -fpic $(CXXFLAGS)
|
||||
CLANG_LFL = `$(LLVM_CONFIG) --ldflags` $(LDFLAGS)
|
||||
|
||||
# User teor2345 reports that this is required to make things work on MacOS X.
|
||||
|
||||
# User teor2345 reports that this is required to make things work on MacOS X.
|
||||
ifeq "$(shell uname)" "Darwin"
|
||||
CLANG_LFL += -Wl,-flat_namespace -Wl,-undefined,suppress
|
||||
endif
|
||||
|
||||
ifeq "$(shell uname)" "OpenBSD"
|
||||
CLANG_LFL += `$(LLVM_CONFIG) --libdir`/libLLVM.so
|
||||
endif
|
||||
|
||||
# We were using llvm-config --bindir to get the location of clang, but
|
||||
# this seems to be busted on some distros, so using the one in $PATH is
|
||||
# probably better.
|
||||
|
||||
ifeq "$(origin CC)" "default"
|
||||
CC = clang
|
||||
CXX = clang++
|
||||
ifeq "$(shell uname)" "OpenBSD"
|
||||
CC = $(BIN_PATH)/clang
|
||||
CXX = $(BIN_PATH)/clang++
|
||||
else
|
||||
CC = clang
|
||||
CXX = clang++
|
||||
endif
|
||||
endif
|
||||
|
||||
# sanity check.
|
||||
# Are versions of clang --version and llvm-config --version equal?
|
||||
CLANGVER = $(shell $(CC) --version | sed -E -ne '/^.*version\ ([0-9]\.[0-9]\.[0-9]).*/s//\1/p')
|
||||
|
||||
|
||||
ifeq "$(shell echo '\#include <sys/ipc.h>@\#include <sys/shm.h>@int main() { int _id = shmget(IPC_PRIVATE, 65536, IPC_CREAT | IPC_EXCL | 0600); shmctl(_id, IPC_RMID, 0); return 0;}' | tr @ '\n' | $(CC) -x c - -o .test2 2>/dev/null && echo 1 || echo 0 )" "1"
|
||||
SHMAT_OK=1
|
||||
else
|
||||
SHMAT_OK=0
|
||||
CFLAGS+=-DUSEMMAP=1
|
||||
LDFLAGS += -lrt
|
||||
endif
|
||||
|
||||
ifeq "$(TEST_MMAP)" "1"
|
||||
SHMAT_OK=0
|
||||
CFLAGS+=-DUSEMMAP=1
|
||||
LDFLAGS += -lrt
|
||||
endif
|
||||
|
||||
|
||||
ifndef AFL_TRACE_PC
|
||||
PROGS = ../afl-clang-fast ../afl-llvm-pass.so ../afl-llvm-rt.o ../afl-llvm-rt-32.o ../afl-llvm-rt-64.o ../compare-transform-pass.so ../split-compares-pass.so ../split-switches-pass.so
|
||||
PROGS = ../afl-clang-fast ../afl-llvm-pass.so ../libLLVMInsTrim.so ../afl-llvm-rt.o ../afl-llvm-rt-32.o ../afl-llvm-rt-64.o ../compare-transform-pass.so ../split-compares-pass.so ../split-switches-pass.so
|
||||
else
|
||||
PROGS = ../afl-clang-fast ../afl-llvm-rt.o ../afl-llvm-rt-32.o ../afl-llvm-rt-64.o ../compare-transform-pass.so ../split-compares-pass.so ../split-switches-pass.so
|
||||
endif
|
||||
|
||||
all: test_deps $(PROGS) test_build all_done
|
||||
ifneq "$(CLANGVER)" "$(LLVMVER)"
|
||||
CC = $(shell llvm-config --bindir)/clang
|
||||
CXX = $(shell llvm-config --bindir)/clang++
|
||||
endif
|
||||
|
||||
all: test_shm test_deps $(PROGS) test_build all_done
|
||||
|
||||
|
||||
ifeq "$(SHMAT_OK)" "1"
|
||||
|
||||
test_shm:
|
||||
@echo "[+] shmat seems to be working."
|
||||
@rm -f .test2
|
||||
|
||||
else
|
||||
|
||||
test_shm:
|
||||
@echo "[-] shmat seems not to be working, switching to mmap implementation"
|
||||
|
||||
endif
|
||||
|
||||
|
||||
test_deps:
|
||||
ifndef AFL_TRACE_PC
|
||||
@ -77,6 +144,13 @@ else
|
||||
endif
|
||||
@echo "[*] Checking for working '$(CC)'..."
|
||||
@which $(CC) >/dev/null 2>&1 || ( echo "[-] Oops, can't find '$(CC)'. Make sure that it's in your \$$PATH (or set \$$CC and \$$CXX)."; exit 1 )
|
||||
@echo "[*] Checking for matching versions of '$(CC)' and '$(LLVM_CONFIG)'"
|
||||
ifneq "$(CLANGVER)" "$(LLVMVER)"
|
||||
@echo "[!] WARNING: we have llvm-config version $(LLVMVER) and a clang version $(CLANGVER)"
|
||||
@echo "[!] Retrying with the clang compiler from llvm: CC=`llvm-config --bindir`/clang"
|
||||
else
|
||||
@echo "[*] We have llvm-config version $(LLVMVER) with a clang version $(CLANGVER), good."
|
||||
endif
|
||||
@echo "[*] Checking for '../afl-showmap'..."
|
||||
@test -f ../afl-showmap || ( echo "[-] Oops, can't find '../afl-showmap'. Be sure to compile AFL first."; exit 1 )
|
||||
@echo "[+] All set and ready to build."
|
||||
@ -85,8 +159,11 @@ endif
|
||||
$(CC) $(CFLAGS) $< -o $@ $(LDFLAGS)
|
||||
ln -sf afl-clang-fast ../afl-clang-fast++
|
||||
|
||||
../libLLVMInsTrim.so: LLVMInsTrim.so.cc MarkNodes.cc | test_deps
|
||||
$(CXX) $(CLANG_CFL) -DLLVMInsTrim_EXPORTS -fno-rtti -fPIC -std=gnu++11 -shared $< MarkNodes.cc -o $@ $(CLANG_LFL)
|
||||
|
||||
../afl-llvm-pass.so: afl-llvm-pass.so.cc | test_deps
|
||||
$(CXX) $(CLANG_CFL) -shared $< -o $@ $(CLANG_LFL)
|
||||
$(CXX) $(CLANG_CFL) -DLLVMInsTrim_EXPORTS -fno-rtti -fPIC -std=gnu++11 -shared $< -o $@ $(CLANG_LFL)
|
||||
|
||||
# laf
|
||||
../split-switches-pass.so: split-switches-pass.so.cc | test_deps
|
||||
@ -110,11 +187,11 @@ endif
|
||||
|
||||
test_build: $(PROGS)
|
||||
@echo "[*] Testing the CC wrapper and instrumentation output..."
|
||||
unset AFL_USE_ASAN AFL_USE_MSAN AFL_INST_RATIO; AFL_QUIET=1 AFL_PATH=. AFL_CC=$(CC) LAF_SPLIT_SWITCHES=1 LAF_TRANSFORM_COMPARES=1 LAF_SPLIT_COMPARES=1 ../afl-clang-fast $(CFLAGS) ../test-instr.c -o test-instr $(LDFLAGS)
|
||||
echo 0 | ../afl-showmap -m none -q -o .test-instr0 ./test-instr
|
||||
unset AFL_USE_ASAN AFL_USE_MSAN AFL_INST_RATIO; AFL_QUIET=1 AFL_PATH=. AFL_CC=$(CC) AFL_LLVM_LAF_SPLIT_SWITCHES=1 AFL_LLVM_LAF_TRANSFORM_COMPARES=1 AFL_LLVM_LAF_SPLIT_COMPARES=1 ../afl-clang-fast $(CFLAGS) ../test-instr.c -o test-instr $(LDFLAGS)
|
||||
../afl-showmap -m none -q -o .test-instr0 ./test-instr < /dev/null
|
||||
echo 1 | ../afl-showmap -m none -q -o .test-instr1 ./test-instr
|
||||
@rm -f test-instr
|
||||
@cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation does not seem to be behaving correctly!"; echo; echo "Please ping <lcamtuf@google.com> to troubleshoot the issue."; echo; exit 1; fi
|
||||
@cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation does not seem to be behaving correctly!"; echo; echo "Please post to https://github.com/vanhauser-thc/AFLplusplus/issues to troubleshoot the issue."; echo; exit 1; fi
|
||||
@echo "[+] All right, the instrumentation seems to be working!"
|
||||
|
||||
all_done: test_build
|
||||
@ -123,5 +200,5 @@ all_done: test_build
|
||||
.NOTPARALLEL: clean
|
||||
|
||||
clean:
|
||||
rm -f *.o *.so *~ a.out core core.[1-9][0-9]* test-instr .test-instr0 .test-instr1
|
||||
rm -f *.o *.so *~ a.out core core.[1-9][0-9]* .test2 test-instr .test-instr0 .test-instr1
|
||||
rm -f $(PROGS) ../afl-clang-fast++
|
||||
|
||||
465
llvm_mode/MarkNodes.cc
Normal file
465
llvm_mode/MarkNodes.cc
Normal file
@ -0,0 +1,465 @@
|
||||
#include <algorithm>
|
||||
#include <map>
|
||||
#include <queue>
|
||||
#include <set>
|
||||
#include <vector>
|
||||
#include "llvm/ADT/DenseMap.h"
|
||||
#include "llvm/ADT/DenseSet.h"
|
||||
#include "llvm/ADT/SmallVector.h"
|
||||
#include "llvm/IR/BasicBlock.h"
|
||||
#include "llvm/IR/CFG.h"
|
||||
#include "llvm/IR/Constants.h"
|
||||
#include "llvm/IR/Function.h"
|
||||
#include "llvm/IR/IRBuilder.h"
|
||||
#include "llvm/IR/Instructions.h"
|
||||
#include "llvm/IR/Module.h"
|
||||
#include "llvm/Pass.h"
|
||||
#include "llvm/Support/Debug.h"
|
||||
#include "llvm/Support/raw_ostream.h"
|
||||
|
||||
using namespace llvm;
|
||||
|
||||
DenseMap<BasicBlock *, uint32_t> LMap;
|
||||
std::vector<BasicBlock *> Blocks;
|
||||
std::set<uint32_t> Marked, Markabove;
|
||||
std::vector<std::vector<uint32_t> > Succs, Preds;
|
||||
|
||||
void reset() {
|
||||
|
||||
LMap.clear();
|
||||
Blocks.clear();
|
||||
Marked.clear();
|
||||
Markabove.clear();
|
||||
|
||||
}
|
||||
|
||||
uint32_t start_point;
|
||||
|
||||
void labelEachBlock(Function *F) {
|
||||
|
||||
// Fake single endpoint;
|
||||
LMap[NULL] = Blocks.size();
|
||||
Blocks.push_back(NULL);
|
||||
|
||||
// Assign the unique LabelID to each block;
|
||||
for (auto I = F->begin(), E = F->end(); I != E; ++I) {
|
||||
|
||||
BasicBlock *BB = &*I;
|
||||
LMap[BB] = Blocks.size();
|
||||
Blocks.push_back(BB);
|
||||
|
||||
}
|
||||
|
||||
start_point = LMap[&F->getEntryBlock()];
|
||||
|
||||
}
|
||||
|
||||
void buildCFG(Function *F) {
|
||||
|
||||
Succs.resize(Blocks.size());
|
||||
Preds.resize(Blocks.size());
|
||||
for (size_t i = 0; i < Succs.size(); i++) {
|
||||
|
||||
Succs[i].clear();
|
||||
Preds[i].clear();
|
||||
|
||||
}
|
||||
|
||||
// uint32_t FakeID = 0;
|
||||
for (auto S = F->begin(), E = F->end(); S != E; ++S) {
|
||||
|
||||
BasicBlock *BB = &*S;
|
||||
uint32_t MyID = LMap[BB];
|
||||
// if (succ_begin(BB) == succ_end(BB)) {
|
||||
|
||||
// Succs[MyID].push_back(FakeID);
|
||||
// Marked.insert(MyID);
|
||||
//}
|
||||
for (auto I = succ_begin(BB), E = succ_end(BB); I != E; ++I) {
|
||||
|
||||
Succs[MyID].push_back(LMap[*I]);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
std::vector<std::vector<uint32_t> > tSuccs;
|
||||
std::vector<bool> tag, indfs;
|
||||
|
||||
void DFStree(size_t now_id) {
|
||||
|
||||
if (tag[now_id]) return;
|
||||
tag[now_id] = true;
|
||||
indfs[now_id] = true;
|
||||
for (auto succ : tSuccs[now_id]) {
|
||||
|
||||
if (tag[succ] and indfs[succ]) {
|
||||
|
||||
Marked.insert(succ);
|
||||
Markabove.insert(succ);
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
Succs[now_id].push_back(succ);
|
||||
Preds[succ].push_back(now_id);
|
||||
DFStree(succ);
|
||||
|
||||
}
|
||||
|
||||
indfs[now_id] = false;
|
||||
|
||||
}
|
||||
|
||||
void turnCFGintoDAG(Function *F) {
|
||||
|
||||
tSuccs = Succs;
|
||||
tag.resize(Blocks.size());
|
||||
indfs.resize(Blocks.size());
|
||||
for (size_t i = 0; i < Blocks.size(); ++i) {
|
||||
|
||||
Succs[i].clear();
|
||||
tag[i] = false;
|
||||
indfs[i] = false;
|
||||
|
||||
}
|
||||
|
||||
DFStree(start_point);
|
||||
for (size_t i = 0; i < Blocks.size(); ++i)
|
||||
if (Succs[i].empty()) {
|
||||
|
||||
Succs[i].push_back(0);
|
||||
Preds[0].push_back(i);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
uint32_t timeStamp;
|
||||
namespace DominatorTree {
|
||||
|
||||
std::vector<std::vector<uint32_t> > cov;
|
||||
std::vector<uint32_t> dfn, nfd, par, sdom, idom, mom, mn;
|
||||
|
||||
bool Compare(uint32_t u, uint32_t v) {
|
||||
|
||||
return dfn[u] < dfn[v];
|
||||
|
||||
}
|
||||
|
||||
uint32_t eval(uint32_t u) {
|
||||
|
||||
if (mom[u] == u) return u;
|
||||
uint32_t res = eval(mom[u]);
|
||||
if (Compare(sdom[mn[mom[u]]], sdom[mn[u]])) { mn[u] = mn[mom[u]]; }
|
||||
return mom[u] = res;
|
||||
|
||||
}
|
||||
|
||||
void DFS(uint32_t now) {
|
||||
|
||||
timeStamp += 1;
|
||||
dfn[now] = timeStamp;
|
||||
nfd[timeStamp - 1] = now;
|
||||
for (auto succ : Succs[now]) {
|
||||
|
||||
if (dfn[succ] == 0) {
|
||||
|
||||
par[succ] = now;
|
||||
DFS(succ);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void DominatorTree(Function *F) {
|
||||
|
||||
if (Blocks.empty()) return;
|
||||
uint32_t s = start_point;
|
||||
|
||||
// Initialization
|
||||
mn.resize(Blocks.size());
|
||||
cov.resize(Blocks.size());
|
||||
dfn.resize(Blocks.size());
|
||||
nfd.resize(Blocks.size());
|
||||
par.resize(Blocks.size());
|
||||
mom.resize(Blocks.size());
|
||||
sdom.resize(Blocks.size());
|
||||
idom.resize(Blocks.size());
|
||||
|
||||
for (uint32_t i = 0; i < Blocks.size(); i++) {
|
||||
|
||||
dfn[i] = 0;
|
||||
nfd[i] = Blocks.size();
|
||||
cov[i].clear();
|
||||
idom[i] = mom[i] = mn[i] = sdom[i] = i;
|
||||
|
||||
}
|
||||
|
||||
timeStamp = 0;
|
||||
DFS(s);
|
||||
|
||||
for (uint32_t i = Blocks.size() - 1; i >= 1u; i--) {
|
||||
|
||||
uint32_t now = nfd[i];
|
||||
if (now == Blocks.size()) { continue; }
|
||||
for (uint32_t pre : Preds[now]) {
|
||||
|
||||
if (dfn[pre]) {
|
||||
|
||||
eval(pre);
|
||||
if (Compare(sdom[mn[pre]], sdom[now])) { sdom[now] = sdom[mn[pre]]; }
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
cov[sdom[now]].push_back(now);
|
||||
mom[now] = par[now];
|
||||
for (uint32_t x : cov[par[now]]) {
|
||||
|
||||
eval(x);
|
||||
if (Compare(sdom[mn[x]], par[now])) {
|
||||
|
||||
idom[x] = mn[x];
|
||||
|
||||
} else {
|
||||
|
||||
idom[x] = par[now];
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
for (uint32_t i = 1; i < Blocks.size(); i += 1) {
|
||||
|
||||
uint32_t now = nfd[i];
|
||||
if (now == Blocks.size()) { continue; }
|
||||
if (idom[now] != sdom[now]) idom[now] = idom[idom[now]];
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
} // namespace DominatorTree
|
||||
|
||||
std::vector<uint32_t> Visited, InStack;
|
||||
std::vector<uint32_t> TopoOrder, InDeg;
|
||||
std::vector<std::vector<uint32_t> > t_Succ, t_Pred;
|
||||
|
||||
void Go(uint32_t now, uint32_t tt) {
|
||||
|
||||
if (now == tt) return;
|
||||
Visited[now] = InStack[now] = timeStamp;
|
||||
|
||||
for (uint32_t nxt : Succs[now]) {
|
||||
|
||||
if (Visited[nxt] == timeStamp and InStack[nxt] == timeStamp) {
|
||||
|
||||
Marked.insert(nxt);
|
||||
|
||||
}
|
||||
|
||||
t_Succ[now].push_back(nxt);
|
||||
t_Pred[nxt].push_back(now);
|
||||
InDeg[nxt] += 1;
|
||||
if (Visited[nxt] == timeStamp) { continue; }
|
||||
Go(nxt, tt);
|
||||
|
||||
}
|
||||
|
||||
InStack[now] = 0;
|
||||
|
||||
}
|
||||
|
||||
void TopologicalSort(uint32_t ss, uint32_t tt) {
|
||||
|
||||
timeStamp += 1;
|
||||
|
||||
Go(ss, tt);
|
||||
|
||||
TopoOrder.clear();
|
||||
std::queue<uint32_t> wait;
|
||||
wait.push(ss);
|
||||
while (not wait.empty()) {
|
||||
|
||||
uint32_t now = wait.front();
|
||||
wait.pop();
|
||||
TopoOrder.push_back(now);
|
||||
for (uint32_t nxt : t_Succ[now]) {
|
||||
|
||||
InDeg[nxt] -= 1;
|
||||
if (InDeg[nxt] == 0u) { wait.push(nxt); }
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
std::vector<std::set<uint32_t> > NextMarked;
|
||||
bool Indistinguish(uint32_t node1, uint32_t node2) {
|
||||
|
||||
if (NextMarked[node1].size() > NextMarked[node2].size()) {
|
||||
|
||||
uint32_t _swap = node1;
|
||||
node1 = node2;
|
||||
node2 = _swap;
|
||||
|
||||
}
|
||||
|
||||
for (uint32_t x : NextMarked[node1]) {
|
||||
|
||||
if (NextMarked[node2].find(x) != NextMarked[node2].end()) { return true; }
|
||||
|
||||
}
|
||||
|
||||
return false;
|
||||
|
||||
}
|
||||
|
||||
void MakeUniq(uint32_t now) {
|
||||
|
||||
bool StopFlag = false;
|
||||
if (Marked.find(now) == Marked.end()) {
|
||||
|
||||
for (uint32_t pred1 : t_Pred[now]) {
|
||||
|
||||
for (uint32_t pred2 : t_Pred[now]) {
|
||||
|
||||
if (pred1 == pred2) continue;
|
||||
if (Indistinguish(pred1, pred2)) {
|
||||
|
||||
Marked.insert(now);
|
||||
StopFlag = true;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (StopFlag) { break; }
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (Marked.find(now) != Marked.end()) {
|
||||
|
||||
NextMarked[now].insert(now);
|
||||
|
||||
} else {
|
||||
|
||||
for (uint32_t pred : t_Pred[now]) {
|
||||
|
||||
for (uint32_t x : NextMarked[pred]) {
|
||||
|
||||
NextMarked[now].insert(x);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void MarkSubGraph(uint32_t ss, uint32_t tt) {
|
||||
|
||||
TopologicalSort(ss, tt);
|
||||
if (TopoOrder.empty()) return;
|
||||
|
||||
for (uint32_t i : TopoOrder) {
|
||||
|
||||
NextMarked[i].clear();
|
||||
|
||||
}
|
||||
|
||||
NextMarked[TopoOrder[0]].insert(TopoOrder[0]);
|
||||
for (uint32_t i = 1; i < TopoOrder.size(); i += 1) {
|
||||
|
||||
MakeUniq(TopoOrder[i]);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void MarkVertice(Function *F) {
|
||||
|
||||
uint32_t s = start_point;
|
||||
|
||||
InDeg.resize(Blocks.size());
|
||||
Visited.resize(Blocks.size());
|
||||
InStack.resize(Blocks.size());
|
||||
t_Succ.resize(Blocks.size());
|
||||
t_Pred.resize(Blocks.size());
|
||||
NextMarked.resize(Blocks.size());
|
||||
|
||||
for (uint32_t i = 0; i < Blocks.size(); i += 1) {
|
||||
|
||||
Visited[i] = InStack[i] = InDeg[i] = 0;
|
||||
t_Succ[i].clear();
|
||||
t_Pred[i].clear();
|
||||
|
||||
}
|
||||
|
||||
timeStamp = 0;
|
||||
uint32_t t = 0;
|
||||
// MarkSubGraph(s, t);
|
||||
// return;
|
||||
|
||||
while (s != t) {
|
||||
|
||||
MarkSubGraph(DominatorTree::idom[t], t);
|
||||
t = DominatorTree::idom[t];
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
// return {marked nodes}
|
||||
std::pair<std::vector<BasicBlock *>, std::vector<BasicBlock *> > markNodes(
|
||||
Function *F) {
|
||||
|
||||
assert(F->size() > 0 && "Function can not be empty");
|
||||
|
||||
reset();
|
||||
labelEachBlock(F);
|
||||
buildCFG(F);
|
||||
turnCFGintoDAG(F);
|
||||
DominatorTree::DominatorTree(F);
|
||||
MarkVertice(F);
|
||||
|
||||
std::vector<BasicBlock *> Result, ResultAbove;
|
||||
for (uint32_t x : Markabove) {
|
||||
|
||||
auto it = Marked.find(x);
|
||||
if (it != Marked.end()) Marked.erase(it);
|
||||
if (x) ResultAbove.push_back(Blocks[x]);
|
||||
|
||||
}
|
||||
|
||||
for (uint32_t x : Marked) {
|
||||
|
||||
if (x == 0) {
|
||||
|
||||
continue;
|
||||
|
||||
} else {
|
||||
|
||||
Result.push_back(Blocks[x]);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
return {Result, ResultAbove};
|
||||
|
||||
}
|
||||
|
||||
12
llvm_mode/MarkNodes.h
Normal file
12
llvm_mode/MarkNodes.h
Normal file
@ -0,0 +1,12 @@
|
||||
#ifndef __MARK_NODES__
|
||||
#define __MARK_NODES__
|
||||
|
||||
#include "llvm/IR/BasicBlock.h"
|
||||
#include "llvm/IR/Function.h"
|
||||
#include <vector>
|
||||
|
||||
std::pair<std::vector<llvm::BasicBlock *>, std::vector<llvm::BasicBlock *>>
|
||||
markNodes(llvm::Function *F);
|
||||
|
||||
#endif
|
||||
|
||||
24
llvm_mode/README.instrim.md
Normal file
24
llvm_mode/README.instrim.md
Normal file
@ -0,0 +1,24 @@
|
||||
# InsTrim
|
||||
|
||||
InsTrim: Lightweight Instrumentation for Coverage-guided Fuzzing
|
||||
|
||||
## Introduction
|
||||
|
||||
InsTrim uses CFG and markers to instrument just what is necessary in the
|
||||
binary in llvm_mode. It is about 20-25% faster but as a cost has a lower
|
||||
path discovery.
|
||||
|
||||
## Usage
|
||||
|
||||
Set the environment variable `AFL_LLVM_INSTRIM=1`.
|
||||
|
||||
There is also an advanced mode which instruments loops in a way so that
|
||||
afl-fuzz can see which loop path has been selected but not being able to
|
||||
see how often the loop has been rerun.
|
||||
This again is a tradeoff for speed for less path information.
|
||||
To enable this mode set `AFL_LLVM_INSTRIM_LOOPHEAD=1`.
|
||||
|
||||
## Background
|
||||
|
||||
The paper: [InsTrim: Lightweight Instrumentation for Coverage-guided Fuzzing]
|
||||
(https://www.ndss-symposium.org/wp-content/uploads/2018/07/bar2018_14_Hsu_paper.pdf)
|
||||
@ -1,20 +0,0 @@
|
||||
Usage
|
||||
=====
|
||||
|
||||
By default the passes will not run when you compile programs using
|
||||
afl-clang-fast. Hence, you can use AFL as usual.
|
||||
To enable the passes you must set environment variables before you
|
||||
compile the target project.
|
||||
|
||||
The following options exist:
|
||||
|
||||
export LAF_SPLIT_SWITCHES=1 Enables the split-switches pass.
|
||||
|
||||
export LAF_TRANSFORM_COMPARES=1 Enables the transform-compares pass
|
||||
(strcmp, memcmp, strncmp, strcasecmp, strncasecmp).
|
||||
|
||||
export LAF_SPLIT_COMPARES=1 Enables the split-compares pass.
|
||||
By default it will split all compares with a bit width <= 64 bits.
|
||||
You can change this behaviour by setting
|
||||
export LAF_SPLIT_COMPARES_BITW=<bit_width>.
|
||||
|
||||
25
llvm_mode/README.laf-intel.md
Normal file
25
llvm_mode/README.laf-intel.md
Normal file
@ -0,0 +1,25 @@
|
||||
# laf-intel instrumentation
|
||||
|
||||
## Usage
|
||||
|
||||
By default the passes will not run when you compile programs using
|
||||
afl-clang-fast. Hence, you can use AFL as usual.
|
||||
To enable the passes you must set environment variables before you
|
||||
compile the target project.
|
||||
|
||||
The following options exist:
|
||||
|
||||
`export AFL_LLVM_LAF_SPLIT_SWITCHES=1`
|
||||
|
||||
Enables the split-switches pass.
|
||||
|
||||
`export AFL_LLVM_LAF_TRANSFORM_COMPARES=1`
|
||||
|
||||
Enables the transform-compares pass (strcmp, memcmp, strncmp, strcasecmp, strncasecmp).
|
||||
|
||||
`export AFL_LLVM_LAF_SPLIT_COMPARES=1`
|
||||
|
||||
Enables the split-compares pass.
|
||||
By default it will split all compares with a bit width <= 64 bits.
|
||||
You can change this behaviour by setting `export AFL_LLVM_LAF_SPLIT_COMPARES_BITW=<bit_width>`.
|
||||
|
||||
@ -1,14 +1,11 @@
|
||||
============================================
|
||||
Fast LLVM-based instrumentation for afl-fuzz
|
||||
============================================
|
||||
# Fast LLVM-based instrumentation for afl-fuzz
|
||||
|
||||
(See ../docs/README for the general instruction manual.)
|
||||
(See ../gcc_plugin/README.gcc for the GCC-based instrumentation.)
|
||||
|
||||
1) Introduction
|
||||
---------------
|
||||
## 1) Introduction
|
||||
|
||||
! llvm_mode works with llvm version 3.8.1 up to 8.x !
|
||||
! llvm version 9 does not work yet !
|
||||
! llvm_mode works with llvm versions 3.8.0 up to 9 !
|
||||
|
||||
The code in this directory allows you to instrument programs for AFL using
|
||||
true compiler-level instrumentation, instead of the more crude
|
||||
@ -30,7 +27,7 @@ several interesting properties:
|
||||
- The instrumentation can cope a bit better with multi-threaded targets.
|
||||
|
||||
- Because the feature relies on the internals of LLVM, it is clang-specific
|
||||
and will *not* work with GCC.
|
||||
and will *not* work with GCC (see ../gcc_plugin/ for an alternative).
|
||||
|
||||
Once this implementation is shown to be sufficiently robust and portable, it
|
||||
will probably replace afl-clang. For now, it can be built separately and
|
||||
@ -38,8 +35,7 @@ co-exists with the original code.
|
||||
|
||||
The idea and much of the implementation comes from Laszlo Szekeres.
|
||||
|
||||
2) How to use
|
||||
-------------
|
||||
## 2) How to use this
|
||||
|
||||
In order to leverage this mechanism, you need to have clang installed on your
|
||||
system. You should also make sure that the llvm-config tool is in your path
|
||||
@ -63,27 +59,52 @@ called afl-clang-fast and afl-clang-fast++ in the parent directory. Once this
|
||||
is done, you can instrument third-party code in a way similar to the standard
|
||||
operating mode of AFL, e.g.:
|
||||
|
||||
```
|
||||
CC=/path/to/afl/afl-clang-fast ./configure [...options...]
|
||||
make
|
||||
```
|
||||
|
||||
Be sure to also include CXX set to afl-clang-fast++ for C++ code.
|
||||
|
||||
The tool honors roughly the same environmental variables as afl-gcc (see
|
||||
../docs/env_variables.txt). This includes AFL_INST_RATIO, AFL_USE_ASAN,
|
||||
AFL_HARDEN, and AFL_DONT_OPTIMIZE.
|
||||
../docs/env_variables.txt). This includes AFL_USE_ASAN,
|
||||
AFL_HARDEN, and AFL_DONT_OPTIMIZE. However AFL_INST_RATIO is not honored
|
||||
as it does not serve a good purpose with the more effective instrim CFG
|
||||
analysis.
|
||||
|
||||
Note: if you want the LLVM helper to be installed on your system for all
|
||||
users, you need to build it before issuing 'make install' in the parent
|
||||
directory.
|
||||
|
||||
3) Gotchas, feedback, bugs
|
||||
--------------------------
|
||||
## 3) Options
|
||||
|
||||
Several options are present to make llvm_mode faster or help it rearrange
|
||||
the code to make afl-fuzz path discovery easier.
|
||||
|
||||
If you need just to instrument specific parts of the code, you can whitelist
|
||||
which C/C++ files to actually intrument. See README.whitelist
|
||||
|
||||
For splitting memcmp, strncmp, etc. please see README.laf-intel
|
||||
|
||||
Then there is an optimized instrumentation strategy that uses CFGs and
|
||||
markers to just instrument what is needed. This increases speed by 20-25%
|
||||
however has a lower path discovery.
|
||||
If you want to use this, set AFL_LLVM_INSTRIM=1
|
||||
See README.instrim
|
||||
|
||||
Finally if your llvm version is 8 or lower, you can activate a mode that
|
||||
prevents that a counter overflow result in a 0 value. This is good for
|
||||
path discovery, but the llvm implementation for intel for this functionality
|
||||
is not optimal and was only fixed in llvm 9.
|
||||
You can set this with AFL_LLVM_NOT_ZERO=1
|
||||
See README.neverzero
|
||||
|
||||
## 4) Gotchas, feedback, bugs
|
||||
|
||||
This is an early-stage mechanism, so field reports are welcome. You can send bug
|
||||
reports to <afl-users@googlegroups.com>.
|
||||
|
||||
4) Bonus feature #1: deferred instrumentation
|
||||
---------------------------------------------
|
||||
## 5) Bonus feature #1: deferred initialization
|
||||
|
||||
AFL tries to optimize performance by executing the targeted binary just once,
|
||||
stopping it just before main(), and then cloning this "master" process to get
|
||||
@ -119,9 +140,11 @@ a location after:
|
||||
|
||||
With the location selected, add this code in the appropriate spot:
|
||||
|
||||
```c
|
||||
#ifdef __AFL_HAVE_MANUAL_CONTROL
|
||||
__AFL_INIT();
|
||||
#endif
|
||||
```
|
||||
|
||||
You don't need the #ifdef guards, but including them ensures that the program
|
||||
will keep working normally when compiled with a tool other than afl-clang-fast.
|
||||
@ -129,8 +152,7 @@ will keep working normally when compiled with a tool other than afl-clang-fast.
|
||||
Finally, recompile the program with afl-clang-fast (afl-gcc or afl-clang will
|
||||
*not* generate a deferred-initialization binary) - and you should be all set!
|
||||
|
||||
5) Bonus feature #2: persistent mode
|
||||
------------------------------------
|
||||
## 6) Bonus feature #2: persistent mode
|
||||
|
||||
Some libraries provide APIs that are stateless, or whose state can be reset in
|
||||
between processing different input files. When such a reset is performed, a
|
||||
@ -139,6 +161,7 @@ eliminating the need for repeated fork() calls and the associated OS overhead.
|
||||
|
||||
The basic structure of the program that does this would be:
|
||||
|
||||
```c
|
||||
while (__AFL_LOOP(1000)) {
|
||||
|
||||
/* Read input data. */
|
||||
@ -148,6 +171,7 @@ The basic structure of the program that does this would be:
|
||||
}
|
||||
|
||||
/* Exit normally */
|
||||
```
|
||||
|
||||
The numerical value specified within the loop controls the maximum number
|
||||
of iterations before AFL will restart the process from scratch. This minimizes
|
||||
@ -156,8 +180,8 @@ and going much higher increases the likelihood of hiccups without giving you
|
||||
any real performance benefits.
|
||||
|
||||
A more detailed template is shown in ../experimental/persistent_demo/.
|
||||
Similarly to the previous mode, the feature works only with afl-clang-fast;
|
||||
#ifdef guards can be used to suppress it when using other compilers.
|
||||
Similarly to the previous mode, the feature works only with afl-clang-fast; #ifdef
|
||||
guards can be used to suppress it when using other compilers.
|
||||
|
||||
Note that as with the previous mode, the feature is easy to misuse; if you
|
||||
do not fully reset the critical state, you may end up with false positives or
|
||||
@ -169,8 +193,7 @@ PS. Because there are task switches still involved, the mode isn't as fast as
|
||||
faster than the normal fork() model, and compared to in-process fuzzing,
|
||||
should be a lot more robust.
|
||||
|
||||
6) Bonus feature #3: new 'trace-pc-guard' mode
|
||||
----------------------------------------------
|
||||
## 8) Bonus feature #3: new 'trace-pc-guard' mode
|
||||
|
||||
Recent versions of LLVM are shipping with a built-in execution tracing feature
|
||||
that provides AFL with the necessary tracing data without the need to
|
||||
@ -178,12 +201,12 @@ post-process the assembly or install any compiler plugins. See:
|
||||
|
||||
http://clang.llvm.org/docs/SanitizerCoverage.html#tracing-pcs-with-guards
|
||||
|
||||
As of this writing, the feature is only available on SVN trunk, and is yet to
|
||||
make it to an official release of LLVM. Nevertheless, if you have a
|
||||
sufficiently recent compiler and want to give it a try, build afl-clang-fast
|
||||
this way:
|
||||
If you have a sufficiently recent compiler and want to give it a try, build
|
||||
afl-clang-fast this way:
|
||||
|
||||
```
|
||||
AFL_TRACE_PC=1 make clean all
|
||||
```
|
||||
|
||||
Note that this mode is currently about 20% slower than "vanilla" afl-clang-fast,
|
||||
and about 5-10% slower than afl-clang. This is likely because the
|
||||
24
llvm_mode/README.neverzero.md
Normal file
24
llvm_mode/README.neverzero.md
Normal file
@ -0,0 +1,24 @@
|
||||
# NeverZero counters for LLVM instrumentation
|
||||
|
||||
## Usage
|
||||
|
||||
In larger, complex or reiterative programs the map that collects the edge pairs
|
||||
can easily fill up and wrap.
|
||||
This is not that much of an issue - unless by chance it wraps just to a 0
|
||||
when the program execution ends.
|
||||
In this case afl-fuzz is not able to see that the pair has been accessed and
|
||||
will ignore it.
|
||||
|
||||
NeverZero prevents this behaviour. If a counter wraps, it jumps over the 0
|
||||
directly to a 1. This improves path discovery (by a very little amount)
|
||||
at a very little cost (one instruction per edge).
|
||||
|
||||
This is implemented in afl-gcc, however for llvm_mode this is optional if
|
||||
the llvm version is below 9 - as there is a perfomance bug that is only fixed
|
||||
in version 9 and onwards.
|
||||
|
||||
If you want to enable this for llvm < 9 then set
|
||||
|
||||
```
|
||||
export AFL_LLVM_NOT_ZERO=1
|
||||
```
|
||||
75
llvm_mode/README.whitelist.md
Normal file
75
llvm_mode/README.whitelist.md
Normal file
@ -0,0 +1,75 @@
|
||||
# Using afl++ with partial instrumentation
|
||||
|
||||
This file describes how you can selectively instrument only the source files
|
||||
that are interesting to you using the LLVM instrumentation provided by
|
||||
afl++
|
||||
|
||||
Originally developed by Christian Holler (:decoder) <choller@mozilla.com>.
|
||||
|
||||
## 1) Description and purpose
|
||||
|
||||
When building and testing complex programs where only a part of the program is
|
||||
the fuzzing target, it often helps to only instrument the necessary parts of
|
||||
the program, leaving the rest uninstrumented. This helps to focus the fuzzer
|
||||
on the important parts of the program, avoiding undesired noise and
|
||||
disturbance by uninteresting code being exercised.
|
||||
|
||||
For this purpose, I have added a "partial instrumentation" support to the LLVM
|
||||
mode of AFLFuzz that allows you to specify on a source file level which files
|
||||
should be compiled with or without instrumentation.
|
||||
|
||||
|
||||
## 2) Building the LLVM module
|
||||
|
||||
The new code is part of the existing afl++ LLVM module in the llvm_mode/
|
||||
subdirectory. There is nothing specifically to do :)
|
||||
|
||||
|
||||
## 3) How to use the partial instrumentation mode
|
||||
|
||||
In order to build with partial instrumentation, you need to build with
|
||||
afl-clang-fast and afl-clang-fast++ respectively. The only required change is
|
||||
that you need to set the environment variable AFL_LLVM_WHITELIST when calling
|
||||
the compiler.
|
||||
|
||||
The environment variable must point to a file containing all the filenames
|
||||
that should be instrumented. For matching, the filename that is being compiled
|
||||
must end in the filename contained in this whitelist (to avoid breaking the
|
||||
matching when absolute paths are used during compilation).
|
||||
|
||||
For example if your source tree looks like this:
|
||||
|
||||
```
|
||||
project/
|
||||
project/feature_a/a1.cpp
|
||||
project/feature_a/a2.cpp
|
||||
project/feature_b/b1.cpp
|
||||
project/feature_b/b2.cpp
|
||||
```
|
||||
|
||||
And you only want to test feature_a, then create a whitelist file containing:
|
||||
|
||||
```
|
||||
feature_a/a1.cpp
|
||||
feature_a/a2.cpp
|
||||
```
|
||||
|
||||
However if the whitelist file contains this, it works as well:
|
||||
|
||||
```
|
||||
a1.cpp
|
||||
a2.cpp
|
||||
```
|
||||
|
||||
but it might lead to files being unwantedly instrumented if the same filename
|
||||
exists somewhere else in the project.
|
||||
|
||||
The created whitelist file is then set to AFL_INST_WHITELIST when you compile
|
||||
your program. For each file that didn't match the whitelist, the compiler will
|
||||
issue a warning at the end stating that no blocks were instrumented. If you
|
||||
didn't intend to instrument that file, then you can safely ignore that warning.
|
||||
|
||||
For old LLVM versions this feature might require to be compiled with debug
|
||||
information (-g), however at least from llvm version 6.0 onwards this is not
|
||||
required anymore (and might hurt performance and crash detection, so better not
|
||||
use -g)
|
||||
@ -23,26 +23,26 @@
|
||||
|
||||
#define AFL_MAIN
|
||||
|
||||
#include "../config.h"
|
||||
#include "../types.h"
|
||||
#include "../debug.h"
|
||||
#include "../alloc-inl.h"
|
||||
#include "config.h"
|
||||
#include "types.h"
|
||||
#include "debug.h"
|
||||
#include "alloc-inl.h"
|
||||
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
#include <assert.h>
|
||||
|
||||
static u8* obj_path; /* Path to runtime libraries */
|
||||
static u8** cc_params; /* Parameters passed to the real CC */
|
||||
static u32 cc_par_cnt = 1; /* Param count, including argv0 */
|
||||
|
||||
static u8* obj_path; /* Path to runtime libraries */
|
||||
static u8** cc_params; /* Parameters passed to the real CC */
|
||||
static u32 cc_par_cnt = 1; /* Param count, including argv0 */
|
||||
|
||||
/* Try to find the runtime libraries. If that fails, abort. */
|
||||
|
||||
static void find_obj(u8* argv0) {
|
||||
|
||||
u8 *afl_path = getenv("AFL_PATH");
|
||||
u8* afl_path = getenv("AFL_PATH");
|
||||
u8 *slash, *tmp;
|
||||
|
||||
if (afl_path) {
|
||||
@ -50,9 +50,11 @@ static void find_obj(u8* argv0) {
|
||||
tmp = alloc_printf("%s/afl-llvm-rt.o", afl_path);
|
||||
|
||||
if (!access(tmp, R_OK)) {
|
||||
|
||||
obj_path = afl_path;
|
||||
ck_free(tmp);
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
ck_free(tmp);
|
||||
@ -63,7 +65,7 @@ static void find_obj(u8* argv0) {
|
||||
|
||||
if (slash) {
|
||||
|
||||
u8 *dir;
|
||||
u8* dir;
|
||||
|
||||
*slash = 0;
|
||||
dir = ck_strdup(argv0);
|
||||
@ -72,9 +74,11 @@ static void find_obj(u8* argv0) {
|
||||
tmp = alloc_printf("%s/afl-llvm-rt.o", dir);
|
||||
|
||||
if (!access(tmp, R_OK)) {
|
||||
|
||||
obj_path = dir;
|
||||
ck_free(tmp);
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
ck_free(tmp);
|
||||
@ -83,75 +87,103 @@ static void find_obj(u8* argv0) {
|
||||
}
|
||||
|
||||
if (!access(AFL_PATH "/afl-llvm-rt.o", R_OK)) {
|
||||
|
||||
obj_path = AFL_PATH;
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
FATAL("Unable to find 'afl-llvm-rt.o' or 'afl-llvm-pass.so'. Please set AFL_PATH");
|
||||
|
||||
}
|
||||
FATAL(
|
||||
"Unable to find 'afl-llvm-rt.o' or 'afl-llvm-pass.so.cc'. Please set "
|
||||
"AFL_PATH");
|
||||
|
||||
}
|
||||
|
||||
/* Copy argv to cc_params, making the necessary edits. */
|
||||
|
||||
static void edit_params(u32 argc, char** argv) {
|
||||
|
||||
u8 fortify_set = 0, asan_set = 0, x_set = 0, maybe_linking = 1, bit_mode = 0;
|
||||
u8 *name;
|
||||
u8 fortify_set = 0, asan_set = 0, x_set = 0, maybe_linking = 1, bit_mode = 0;
|
||||
u8* name;
|
||||
|
||||
cc_params = ck_alloc((argc + 128) * sizeof(u8*));
|
||||
|
||||
name = strrchr(argv[0], '/');
|
||||
if (!name) name = argv[0]; else name++;
|
||||
if (!name)
|
||||
name = argv[0];
|
||||
else
|
||||
name++;
|
||||
|
||||
if (!strcmp(name, "afl-clang-fast++")) {
|
||||
|
||||
u8* alt_cxx = getenv("AFL_CXX");
|
||||
cc_params[0] = alt_cxx ? alt_cxx : (u8*)"clang++";
|
||||
|
||||
} else {
|
||||
|
||||
u8* alt_cc = getenv("AFL_CC");
|
||||
cc_params[0] = alt_cc ? alt_cc : (u8*)"clang";
|
||||
|
||||
}
|
||||
|
||||
/* There are two ways to compile afl-clang-fast. In the traditional mode, we
|
||||
use afl-llvm-pass.so to inject instrumentation. In the experimental
|
||||
/* There are three ways to compile with afl-clang-fast. In the traditional
|
||||
mode, we use afl-llvm-pass.so, then there is libLLVMInsTrim.so which is
|
||||
much faster but has less coverage. Finally tere is the experimental
|
||||
'trace-pc-guard' mode, we use native LLVM instrumentation callbacks
|
||||
instead. The latter is a very recent addition - see:
|
||||
|
||||
http://clang.llvm.org/docs/SanitizerCoverage.html#tracing-pcs-with-guards */
|
||||
instead. For trace-pc-guard see:
|
||||
http://clang.llvm.org/docs/SanitizerCoverage.html#tracing-pcs-with-guards
|
||||
*/
|
||||
|
||||
// laf
|
||||
if (getenv("LAF_SPLIT_SWITCHES")) {
|
||||
if (getenv("LAF_SPLIT_SWITCHES") || getenv("AFL_LLVM_LAF_SPLIT_SWITCHES")) {
|
||||
|
||||
cc_params[cc_par_cnt++] = "-Xclang";
|
||||
cc_params[cc_par_cnt++] = "-load";
|
||||
cc_params[cc_par_cnt++] = "-Xclang";
|
||||
cc_params[cc_par_cnt++] = alloc_printf("%s/split-switches-pass.so", obj_path);
|
||||
cc_params[cc_par_cnt++] =
|
||||
alloc_printf("%s/split-switches-pass.so", obj_path);
|
||||
|
||||
}
|
||||
|
||||
if (getenv("LAF_TRANSFORM_COMPARES")) {
|
||||
if (getenv("LAF_TRANSFORM_COMPARES") ||
|
||||
getenv("AFL_LLVM_LAF_TRANSFORM_COMPARES")) {
|
||||
|
||||
cc_params[cc_par_cnt++] = "-Xclang";
|
||||
cc_params[cc_par_cnt++] = "-load";
|
||||
cc_params[cc_par_cnt++] = "-Xclang";
|
||||
cc_params[cc_par_cnt++] = alloc_printf("%s/compare-transform-pass.so", obj_path);
|
||||
cc_params[cc_par_cnt++] =
|
||||
alloc_printf("%s/compare-transform-pass.so", obj_path);
|
||||
|
||||
}
|
||||
|
||||
if (getenv("LAF_SPLIT_COMPARES")) {
|
||||
if (getenv("LAF_SPLIT_COMPARES") || getenv("AFL_LLVM_LAF_SPLIT_COMPARES")) {
|
||||
|
||||
cc_params[cc_par_cnt++] = "-Xclang";
|
||||
cc_params[cc_par_cnt++] = "-load";
|
||||
cc_params[cc_par_cnt++] = "-Xclang";
|
||||
cc_params[cc_par_cnt++] = alloc_printf("%s/split-compares-pass.so", obj_path);
|
||||
cc_params[cc_par_cnt++] =
|
||||
alloc_printf("%s/split-compares-pass.so", obj_path);
|
||||
|
||||
}
|
||||
|
||||
// /laf
|
||||
|
||||
#ifdef USE_TRACE_PC
|
||||
cc_params[cc_par_cnt++] = "-fsanitize-coverage=trace-pc-guard";
|
||||
cc_params[cc_par_cnt++] = "-mllvm";
|
||||
cc_params[cc_par_cnt++] = "-sanitizer-coverage-block-threshold=0";
|
||||
cc_params[cc_par_cnt++] =
|
||||
"-fsanitize-coverage=trace-pc-guard"; // edge coverage by default
|
||||
// cc_params[cc_par_cnt++] = "-mllvm";
|
||||
// cc_params[cc_par_cnt++] =
|
||||
// "-fsanitize-coverage=trace-cmp,trace-div,trace-gep";
|
||||
// cc_params[cc_par_cnt++] = "-sanitizer-coverage-block-threshold=0";
|
||||
#else
|
||||
cc_params[cc_par_cnt++] = "-Xclang";
|
||||
cc_params[cc_par_cnt++] = "-load";
|
||||
cc_params[cc_par_cnt++] = "-Xclang";
|
||||
cc_params[cc_par_cnt++] = alloc_printf("%s/afl-llvm-pass.so", obj_path);
|
||||
#endif /* ^USE_TRACE_PC */
|
||||
if (getenv("AFL_LLVM_INSTRIM") != NULL || getenv("INSTRIM_LIB") != NULL)
|
||||
cc_params[cc_par_cnt++] = alloc_printf("%s/libLLVMInsTrim.so", obj_path);
|
||||
else
|
||||
cc_params[cc_par_cnt++] = alloc_printf("%s/afl-llvm-pass.so", obj_path);
|
||||
#endif /* ^USE_TRACE_PC */
|
||||
|
||||
cc_params[cc_par_cnt++] = "-Qunused-arguments";
|
||||
|
||||
@ -160,6 +192,7 @@ static void edit_params(u32 argc, char** argv) {
|
||||
if (argc == 1 && !strcmp(argv[1], "-v")) maybe_linking = 0;
|
||||
|
||||
while (--argc) {
|
||||
|
||||
u8* cur = *(++argv);
|
||||
|
||||
if (!strcmp(cur, "-m32")) bit_mode = 32;
|
||||
@ -170,15 +203,15 @@ static void edit_params(u32 argc, char** argv) {
|
||||
if (!strcmp(cur, "-c") || !strcmp(cur, "-S") || !strcmp(cur, "-E"))
|
||||
maybe_linking = 0;
|
||||
|
||||
if (!strcmp(cur, "-fsanitize=address") ||
|
||||
!strcmp(cur, "-fsanitize=memory")) asan_set = 1;
|
||||
if (!strcmp(cur, "-fsanitize=address") || !strcmp(cur, "-fsanitize=memory"))
|
||||
asan_set = 1;
|
||||
|
||||
if (strstr(cur, "FORTIFY_SOURCE")) fortify_set = 1;
|
||||
|
||||
if (!strcmp(cur, "-shared")) maybe_linking = 0;
|
||||
|
||||
if (!strcmp(cur, "-Wl,-z,defs") ||
|
||||
!strcmp(cur, "-Wl,--no-undefined")) continue;
|
||||
if (!strcmp(cur, "-Wl,-z,defs") || !strcmp(cur, "-Wl,--no-undefined"))
|
||||
continue;
|
||||
|
||||
cc_params[cc_par_cnt++] = cur;
|
||||
|
||||
@ -188,8 +221,7 @@ static void edit_params(u32 argc, char** argv) {
|
||||
|
||||
cc_params[cc_par_cnt++] = "-fstack-protector-all";
|
||||
|
||||
if (!fortify_set)
|
||||
cc_params[cc_par_cnt++] = "-D_FORTIFY_SOURCE=2";
|
||||
if (!fortify_set) cc_params[cc_par_cnt++] = "-D_FORTIFY_SOURCE=2";
|
||||
|
||||
}
|
||||
|
||||
@ -197,8 +229,7 @@ static void edit_params(u32 argc, char** argv) {
|
||||
|
||||
if (getenv("AFL_USE_ASAN")) {
|
||||
|
||||
if (getenv("AFL_USE_MSAN"))
|
||||
FATAL("ASAN and MSAN are mutually exclusive");
|
||||
if (getenv("AFL_USE_MSAN")) FATAL("ASAN and MSAN are mutually exclusive");
|
||||
|
||||
if (getenv("AFL_HARDEN"))
|
||||
FATAL("ASAN and AFL_HARDEN are mutually exclusive");
|
||||
@ -208,8 +239,7 @@ static void edit_params(u32 argc, char** argv) {
|
||||
|
||||
} else if (getenv("AFL_USE_MSAN")) {
|
||||
|
||||
if (getenv("AFL_USE_ASAN"))
|
||||
FATAL("ASAN and MSAN are mutually exclusive");
|
||||
if (getenv("AFL_USE_ASAN")) FATAL("ASAN and MSAN are mutually exclusive");
|
||||
|
||||
if (getenv("AFL_HARDEN"))
|
||||
FATAL("MSAN and AFL_HARDEN are mutually exclusive");
|
||||
@ -226,7 +256,7 @@ static void edit_params(u32 argc, char** argv) {
|
||||
if (getenv("AFL_INST_RATIO"))
|
||||
FATAL("AFL_INST_RATIO not available at compile time with 'trace-pc'.");
|
||||
|
||||
#endif /* USE_TRACE_PC */
|
||||
#endif /* USE_TRACE_PC */
|
||||
|
||||
if (!getenv("AFL_DONT_OPTIMIZE")) {
|
||||
|
||||
@ -246,6 +276,10 @@ static void edit_params(u32 argc, char** argv) {
|
||||
|
||||
}
|
||||
|
||||
#ifdef USEMMAP
|
||||
cc_params[cc_par_cnt++] = "-lrt";
|
||||
#endif
|
||||
|
||||
cc_params[cc_par_cnt++] = "-D__AFL_HAVE_MANUAL_CONTROL=1";
|
||||
cc_params[cc_par_cnt++] = "-D__AFL_COMPILER=1";
|
||||
cc_params[cc_par_cnt++] = "-DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1";
|
||||
@ -270,35 +304,41 @@ static void edit_params(u32 argc, char** argv) {
|
||||
|
||||
*/
|
||||
|
||||
cc_params[cc_par_cnt++] = "-D__AFL_LOOP(_A)="
|
||||
"({ static volatile char *_B __attribute__((used)); "
|
||||
" _B = (char*)\"" PERSIST_SIG "\"; "
|
||||
cc_params[cc_par_cnt++] =
|
||||
"-D__AFL_LOOP(_A)="
|
||||
"({ static volatile char *_B __attribute__((used)); "
|
||||
" _B = (char*)\"" PERSIST_SIG
|
||||
"\"; "
|
||||
#ifdef __APPLE__
|
||||
"__attribute__((visibility(\"default\"))) "
|
||||
"int _L(unsigned int) __asm__(\"___afl_persistent_loop\"); "
|
||||
"__attribute__((visibility(\"default\"))) "
|
||||
"int _L(unsigned int) __asm__(\"___afl_persistent_loop\"); "
|
||||
#else
|
||||
"__attribute__((visibility(\"default\"))) "
|
||||
"int _L(unsigned int) __asm__(\"__afl_persistent_loop\"); "
|
||||
#endif /* ^__APPLE__ */
|
||||
"_L(_A); })";
|
||||
"__attribute__((visibility(\"default\"))) "
|
||||
"int _L(unsigned int) __asm__(\"__afl_persistent_loop\"); "
|
||||
#endif /* ^__APPLE__ */
|
||||
"_L(_A); })";
|
||||
|
||||
cc_params[cc_par_cnt++] = "-D__AFL_INIT()="
|
||||
"do { static volatile char *_A __attribute__((used)); "
|
||||
" _A = (char*)\"" DEFER_SIG "\"; "
|
||||
cc_params[cc_par_cnt++] =
|
||||
"-D__AFL_INIT()="
|
||||
"do { static volatile char *_A __attribute__((used)); "
|
||||
" _A = (char*)\"" DEFER_SIG
|
||||
"\"; "
|
||||
#ifdef __APPLE__
|
||||
"__attribute__((visibility(\"default\"))) "
|
||||
"void _I(void) __asm__(\"___afl_manual_init\"); "
|
||||
"__attribute__((visibility(\"default\"))) "
|
||||
"void _I(void) __asm__(\"___afl_manual_init\"); "
|
||||
#else
|
||||
"__attribute__((visibility(\"default\"))) "
|
||||
"void _I(void) __asm__(\"__afl_manual_init\"); "
|
||||
#endif /* ^__APPLE__ */
|
||||
"_I(); } while (0)";
|
||||
"__attribute__((visibility(\"default\"))) "
|
||||
"void _I(void) __asm__(\"__afl_manual_init\"); "
|
||||
#endif /* ^__APPLE__ */
|
||||
"_I(); } while (0)";
|
||||
|
||||
if (maybe_linking) {
|
||||
|
||||
if (x_set) {
|
||||
|
||||
cc_params[cc_par_cnt++] = "-x";
|
||||
cc_params[cc_par_cnt++] = "none";
|
||||
|
||||
}
|
||||
|
||||
switch (bit_mode) {
|
||||
@ -331,7 +371,6 @@ static void edit_params(u32 argc, char** argv) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Main entry point */
|
||||
|
||||
int main(int argc, char** argv) {
|
||||
@ -339,46 +378,53 @@ int main(int argc, char** argv) {
|
||||
if (isatty(2) && !getenv("AFL_QUIET")) {
|
||||
|
||||
#ifdef USE_TRACE_PC
|
||||
SAYF(cCYA "afl-clang-fast" VERSION cRST " [tpcg] by <lszekeres@google.com>\n");
|
||||
SAYF(cCYA "afl-clang-fast" VERSION cRST
|
||||
" [tpcg] by <lszekeres@google.com>\n");
|
||||
#else
|
||||
SAYF(cCYA "afl-clang-fast" VERSION cRST " by <lszekeres@google.com>\n");
|
||||
#endif /* ^USE_TRACE_PC */
|
||||
SAYF(cCYA "afl-clang-fast" VERSION cRST " by <lszekeres@google.com>\n");
|
||||
#endif /* ^USE_TRACE_PC */
|
||||
|
||||
}
|
||||
|
||||
if (argc < 2) {
|
||||
|
||||
SAYF("\n"
|
||||
"This is a helper application for afl-fuzz. It serves as a drop-in replacement\n"
|
||||
"for clang, letting you recompile third-party code with the required runtime\n"
|
||||
"instrumentation. A common use pattern would be one of the following:\n\n"
|
||||
SAYF(
|
||||
"\n"
|
||||
"This is a helper application for afl-fuzz. It serves as a drop-in "
|
||||
"replacement\n"
|
||||
"for clang, letting you recompile third-party code with the required "
|
||||
"runtime\n"
|
||||
"instrumentation. A common use pattern would be one of the "
|
||||
"following:\n\n"
|
||||
|
||||
" CC=%s/afl-clang-fast ./configure\n"
|
||||
" CXX=%s/afl-clang-fast++ ./configure\n\n"
|
||||
" CC=%s/afl-clang-fast ./configure\n"
|
||||
" CXX=%s/afl-clang-fast++ ./configure\n\n"
|
||||
|
||||
"In contrast to the traditional afl-clang tool, this version is implemented as\n"
|
||||
"an LLVM pass and tends to offer improved performance with slow programs.\n\n"
|
||||
"In contrast to the traditional afl-clang tool, this version is "
|
||||
"implemented as\n"
|
||||
"an LLVM pass and tends to offer improved performance with slow "
|
||||
"programs.\n\n"
|
||||
|
||||
"You can specify custom next-stage toolchain via AFL_CC and AFL_CXX. Setting\n"
|
||||
"AFL_HARDEN enables hardening optimizations in the compiled code.\n\n",
|
||||
BIN_PATH, BIN_PATH);
|
||||
"You can specify custom next-stage toolchain via AFL_CC and AFL_CXX. "
|
||||
"Setting\n"
|
||||
"AFL_HARDEN enables hardening optimizations in the compiled code.\n\n",
|
||||
BIN_PATH, BIN_PATH);
|
||||
|
||||
exit(1);
|
||||
|
||||
}
|
||||
|
||||
|
||||
find_obj(argv[0]);
|
||||
|
||||
edit_params(argc, argv);
|
||||
|
||||
/*
|
||||
int i = 0;
|
||||
printf("EXEC:");
|
||||
while (cc_params[i] != NULL)
|
||||
printf(" %s", cc_params[i++]);
|
||||
printf("\n");
|
||||
*/
|
||||
/*
|
||||
int i = 0;
|
||||
printf("EXEC:");
|
||||
while (cc_params[i] != NULL)
|
||||
printf(" %s", cc_params[i++]);
|
||||
printf("\n");
|
||||
*/
|
||||
|
||||
execvp(cc_params[0], (char**)cc_params);
|
||||
|
||||
@ -387,3 +433,4 @@ int main(int argc, char** argv) {
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
|
||||
@ -24,13 +24,18 @@
|
||||
|
||||
#define AFL_LLVM_PASS
|
||||
|
||||
#include "../config.h"
|
||||
#include "../debug.h"
|
||||
#include "config.h"
|
||||
#include "debug.h"
|
||||
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <unistd.h>
|
||||
|
||||
#include <list>
|
||||
#include <string>
|
||||
#include <fstream>
|
||||
|
||||
#include "llvm/IR/DebugInfo.h"
|
||||
#include "llvm/IR/BasicBlock.h"
|
||||
#include "llvm/IR/IRBuilder.h"
|
||||
#include "llvm/IR/LegacyPassManager.h"
|
||||
@ -43,32 +48,52 @@ using namespace llvm;
|
||||
|
||||
namespace {
|
||||
|
||||
class AFLCoverage : public ModulePass {
|
||||
class AFLCoverage : public ModulePass {
|
||||
|
||||
public:
|
||||
public:
|
||||
static char ID;
|
||||
AFLCoverage() : ModulePass(ID) {
|
||||
|
||||
static char ID;
|
||||
AFLCoverage() : ModulePass(ID) { }
|
||||
char *instWhiteListFilename = getenv("AFL_LLVM_WHITELIST");
|
||||
if (instWhiteListFilename) {
|
||||
|
||||
bool runOnModule(Module &M) override;
|
||||
std::string line;
|
||||
std::ifstream fileStream;
|
||||
fileStream.open(instWhiteListFilename);
|
||||
if (!fileStream) report_fatal_error("Unable to open AFL_LLVM_WHITELIST");
|
||||
getline(fileStream, line);
|
||||
while (fileStream) {
|
||||
|
||||
// StringRef getPassName() const override {
|
||||
// return "American Fuzzy Lop Instrumentation";
|
||||
// }
|
||||
myWhitelist.push_back(line);
|
||||
getline(fileStream, line);
|
||||
|
||||
};
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
bool runOnModule(Module &M) override;
|
||||
|
||||
// StringRef getPassName() const override {
|
||||
|
||||
// return "American Fuzzy Lop Instrumentation";
|
||||
// }
|
||||
|
||||
protected:
|
||||
std::list<std::string> myWhitelist;
|
||||
|
||||
};
|
||||
|
||||
} // namespace
|
||||
|
||||
char AFLCoverage::ID = 0;
|
||||
|
||||
|
||||
bool AFLCoverage::runOnModule(Module &M) {
|
||||
|
||||
LLVMContext &C = M.getContext();
|
||||
|
||||
IntegerType *Int8Ty = IntegerType::getInt8Ty(C);
|
||||
IntegerType *Int8Ty = IntegerType::getInt8Ty(C);
|
||||
IntegerType *Int32Ty = IntegerType::getInt32Ty(C);
|
||||
unsigned int cur_loc = 0;
|
||||
|
||||
@ -80,11 +105,13 @@ bool AFLCoverage::runOnModule(Module &M) {
|
||||
|
||||
SAYF(cCYA "afl-llvm-pass" VERSION cRST " by <lszekeres@google.com>\n");
|
||||
|
||||
} else be_quiet = 1;
|
||||
} else
|
||||
|
||||
be_quiet = 1;
|
||||
|
||||
/* Decide instrumentation ratio */
|
||||
|
||||
char* inst_ratio_str = getenv("AFL_INST_RATIO");
|
||||
char * inst_ratio_str = getenv("AFL_INST_RATIO");
|
||||
unsigned int inst_ratio = 100;
|
||||
|
||||
if (inst_ratio_str) {
|
||||
@ -95,6 +122,10 @@ bool AFLCoverage::runOnModule(Module &M) {
|
||||
|
||||
}
|
||||
|
||||
#if LLVM_VERSION_MAJOR < 9
|
||||
char *neverZero_counters_str = getenv("AFL_LLVM_NOT_ZERO");
|
||||
#endif
|
||||
|
||||
/* Get globals for the SHM region and the previous location. Note that
|
||||
__afl_prev_loc is thread-local. */
|
||||
|
||||
@ -102,9 +133,14 @@ bool AFLCoverage::runOnModule(Module &M) {
|
||||
new GlobalVariable(M, PointerType::get(Int8Ty, 0), false,
|
||||
GlobalValue::ExternalLinkage, 0, "__afl_area_ptr");
|
||||
|
||||
#ifdef __ANDROID__
|
||||
GlobalVariable *AFLPrevLoc = new GlobalVariable(
|
||||
M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_loc",
|
||||
0, GlobalVariable::GeneralDynamicTLSModel, 0, false);
|
||||
M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_loc");
|
||||
#else
|
||||
GlobalVariable *AFLPrevLoc = new GlobalVariable(
|
||||
M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_loc", 0,
|
||||
GlobalVariable::GeneralDynamicTLSModel, 0, false);
|
||||
#endif
|
||||
|
||||
/* Instrument all the things! */
|
||||
|
||||
@ -114,13 +150,77 @@ bool AFLCoverage::runOnModule(Module &M) {
|
||||
for (auto &BB : F) {
|
||||
|
||||
BasicBlock::iterator IP = BB.getFirstInsertionPt();
|
||||
IRBuilder<> IRB(&(*IP));
|
||||
IRBuilder<> IRB(&(*IP));
|
||||
|
||||
if (!myWhitelist.empty()) {
|
||||
|
||||
bool instrumentBlock = false;
|
||||
|
||||
/* Get the current location using debug information.
|
||||
* For now, just instrument the block if we are not able
|
||||
* to determine our location. */
|
||||
DebugLoc Loc = IP->getDebugLoc();
|
||||
if (Loc) {
|
||||
|
||||
DILocation *cDILoc = dyn_cast<DILocation>(Loc.getAsMDNode());
|
||||
|
||||
unsigned int instLine = cDILoc->getLine();
|
||||
StringRef instFilename = cDILoc->getFilename();
|
||||
|
||||
if (instFilename.str().empty()) {
|
||||
|
||||
/* If the original location is empty, try using the inlined location
|
||||
*/
|
||||
DILocation *oDILoc = cDILoc->getInlinedAt();
|
||||
if (oDILoc) {
|
||||
|
||||
instFilename = oDILoc->getFilename();
|
||||
instLine = oDILoc->getLine();
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* Continue only if we know where we actually are */
|
||||
if (!instFilename.str().empty()) {
|
||||
|
||||
for (std::list<std::string>::iterator it = myWhitelist.begin();
|
||||
it != myWhitelist.end(); ++it) {
|
||||
|
||||
/* We don't check for filename equality here because
|
||||
* filenames might actually be full paths. Instead we
|
||||
* check that the actual filename ends in the filename
|
||||
* specified in the list. */
|
||||
if (instFilename.str().length() >= it->length()) {
|
||||
|
||||
if (instFilename.str().compare(
|
||||
instFilename.str().length() - it->length(),
|
||||
it->length(), *it) == 0) {
|
||||
|
||||
instrumentBlock = true;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* Either we couldn't figure out our location or the location is
|
||||
* not whitelisted, so we skip instrumentation. */
|
||||
if (!instrumentBlock) continue;
|
||||
|
||||
}
|
||||
|
||||
if (AFL_R(100) >= inst_ratio) continue;
|
||||
|
||||
/* Make up cur_loc */
|
||||
|
||||
//cur_loc++;
|
||||
// cur_loc++;
|
||||
cur_loc = AFL_R(MAP_SIZE);
|
||||
|
||||
// only instrument if this basic block is the destination of a previous
|
||||
@ -128,24 +228,27 @@ bool AFLCoverage::runOnModule(Module &M) {
|
||||
// this gets rid of ~5-10% of instrumentations that are unnecessary
|
||||
// result: a little more speed and less map pollution
|
||||
int more_than_one = -1;
|
||||
//fprintf(stderr, "BB %u: ", cur_loc);
|
||||
// fprintf(stderr, "BB %u: ", cur_loc);
|
||||
for (BasicBlock *Pred : predecessors(&BB)) {
|
||||
|
||||
int count = 0;
|
||||
if (more_than_one == -1)
|
||||
more_than_one = 0;
|
||||
//fprintf(stderr, " %p=>", Pred);
|
||||
if (more_than_one == -1) more_than_one = 0;
|
||||
// fprintf(stderr, " %p=>", Pred);
|
||||
for (BasicBlock *Succ : successors(Pred)) {
|
||||
//if (count > 0)
|
||||
|
||||
// if (count > 0)
|
||||
// fprintf(stderr, "|");
|
||||
if (Succ != NULL) count++;
|
||||
//fprintf(stderr, "%p", Succ);
|
||||
// fprintf(stderr, "%p", Succ);
|
||||
|
||||
}
|
||||
if (count > 1)
|
||||
more_than_one = 1;
|
||||
|
||||
if (count > 1) more_than_one = 1;
|
||||
|
||||
}
|
||||
//fprintf(stderr, " == %d\n", more_than_one);
|
||||
if (more_than_one != 1)
|
||||
continue;
|
||||
|
||||
// fprintf(stderr, " == %d\n", more_than_one);
|
||||
if (more_than_one != 1) continue;
|
||||
|
||||
ConstantInt *CurLoc = ConstantInt::get(Int32Ty, cur_loc);
|
||||
|
||||
@ -166,7 +269,77 @@ bool AFLCoverage::runOnModule(Module &M) {
|
||||
|
||||
LoadInst *Counter = IRB.CreateLoad(MapPtrIdx);
|
||||
Counter->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
|
||||
|
||||
Value *Incr = IRB.CreateAdd(Counter, ConstantInt::get(Int8Ty, 1));
|
||||
|
||||
#if LLVM_VERSION_MAJOR < 9
|
||||
if (neverZero_counters_str !=
|
||||
NULL) { // with llvm 9 we make this the default as the bug in llvm is
|
||||
// then fixed
|
||||
#endif
|
||||
/* hexcoder: Realize a counter that skips zero during overflow.
|
||||
* Once this counter reaches its maximum value, it next increments to 1
|
||||
*
|
||||
* Instead of
|
||||
* Counter + 1 -> Counter
|
||||
* we inject now this
|
||||
* Counter + 1 -> {Counter, OverflowFlag}
|
||||
* Counter + OverflowFlag -> Counter
|
||||
*/
|
||||
/* // we keep the old solutions just in case
|
||||
// Solution #1
|
||||
if (neverZero_counters_str[0] == '1') {
|
||||
|
||||
CallInst *AddOv =
|
||||
IRB.CreateBinaryIntrinsic(Intrinsic::uadd_with_overflow, Counter,
|
||||
ConstantInt::get(Int8Ty, 1));
|
||||
AddOv->setMetadata(M.getMDKindID("nosanitize"),
|
||||
MDNode::get(C, None)); Value *SumWithOverflowBit = AddOv; Incr =
|
||||
IRB.CreateAdd(IRB.CreateExtractValue(SumWithOverflowBit, 0), // sum
|
||||
IRB.CreateZExt( // convert from one bit
|
||||
type to 8 bits type IRB.CreateExtractValue(SumWithOverflowBit, 1), //
|
||||
overflow Int8Ty));
|
||||
// Solution #2
|
||||
|
||||
} else if (neverZero_counters_str[0] == '2') {
|
||||
|
||||
auto cf = IRB.CreateICmpEQ(Counter,
|
||||
ConstantInt::get(Int8Ty, 255)); Value *HowMuch =
|
||||
IRB.CreateAdd(ConstantInt::get(Int8Ty, 1), cf); Incr =
|
||||
IRB.CreateAdd(Counter, HowMuch);
|
||||
// Solution #3
|
||||
|
||||
} else if (neverZero_counters_str[0] == '3') {
|
||||
|
||||
*/
|
||||
// this is the solution we choose because llvm9 should do the right
|
||||
// thing here
|
||||
auto cf = IRB.CreateICmpEQ(Incr, ConstantInt::get(Int8Ty, 0));
|
||||
auto carry = IRB.CreateZExt(cf, Int8Ty);
|
||||
Incr = IRB.CreateAdd(Incr, carry);
|
||||
/*
|
||||
// Solution #4
|
||||
|
||||
} else if (neverZero_counters_str[0] == '4') {
|
||||
|
||||
auto cf = IRB.CreateICmpULT(Incr, ConstantInt::get(Int8Ty, 1));
|
||||
auto carry = IRB.CreateZExt(cf, Int8Ty);
|
||||
Incr = IRB.CreateAdd(Incr, carry);
|
||||
|
||||
} else {
|
||||
|
||||
fprintf(stderr, "Error: unknown value for AFL_NZERO_COUNTS: %s
|
||||
(valid is 1-4)\n", neverZero_counters_str); exit(-1);
|
||||
|
||||
}
|
||||
|
||||
*/
|
||||
#if LLVM_VERSION_MAJOR < 9
|
||||
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
IRB.CreateStore(Incr, MapPtrIdx)
|
||||
->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
|
||||
|
||||
@ -184,11 +357,16 @@ bool AFLCoverage::runOnModule(Module &M) {
|
||||
|
||||
if (!be_quiet) {
|
||||
|
||||
if (!inst_blocks) WARNF("No instrumentation targets found.");
|
||||
else OKF("Instrumented %u locations (%s mode, ratio %u%%).",
|
||||
inst_blocks, getenv("AFL_HARDEN") ? "hardened" :
|
||||
((getenv("AFL_USE_ASAN") || getenv("AFL_USE_MSAN")) ?
|
||||
"ASAN/MSAN" : "non-hardened"), inst_ratio);
|
||||
if (!inst_blocks)
|
||||
WARNF("No instrumentation targets found.");
|
||||
else
|
||||
OKF("Instrumented %u locations (%s mode, ratio %u%%).", inst_blocks,
|
||||
getenv("AFL_HARDEN")
|
||||
? "hardened"
|
||||
: ((getenv("AFL_USE_ASAN") || getenv("AFL_USE_MSAN"))
|
||||
? "ASAN/MSAN"
|
||||
: "non-hardened"),
|
||||
inst_ratio);
|
||||
|
||||
}
|
||||
|
||||
@ -196,7 +374,6 @@ bool AFLCoverage::runOnModule(Module &M) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
static void registerAFLPass(const PassManagerBuilder &,
|
||||
legacy::PassManagerBase &PM) {
|
||||
|
||||
@ -204,9 +381,9 @@ static void registerAFLPass(const PassManagerBuilder &,
|
||||
|
||||
}
|
||||
|
||||
|
||||
static RegisterStandardPasses RegisterAFLPass(
|
||||
PassManagerBuilder::EP_OptimizerLast, registerAFLPass);
|
||||
|
||||
static RegisterStandardPasses RegisterAFLPass0(
|
||||
PassManagerBuilder::EP_EnabledOnOptLevel0, registerAFLPass);
|
||||
|
||||
|
||||
@ -19,8 +19,11 @@
|
||||
|
||||
*/
|
||||
|
||||
#include "../config.h"
|
||||
#include "../types.h"
|
||||
#ifdef __ANDROID__
|
||||
#include "android-ashmem.h"
|
||||
#endif
|
||||
#include "config.h"
|
||||
#include "types.h"
|
||||
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
@ -39,32 +42,36 @@
|
||||
the LLVM-generated runtime initialization pass, not before. */
|
||||
|
||||
#ifdef USE_TRACE_PC
|
||||
# define CONST_PRIO 5
|
||||
#define CONST_PRIO 5
|
||||
#else
|
||||
# define CONST_PRIO 0
|
||||
#endif /* ^USE_TRACE_PC */
|
||||
#define CONST_PRIO 0
|
||||
#endif /* ^USE_TRACE_PC */
|
||||
|
||||
#include <sys/mman.h>
|
||||
#include <fcntl.h>
|
||||
|
||||
/* Globals needed by the injected instrumentation. The __afl_area_initial region
|
||||
is used for instrumentation output before __afl_map_shm() has a chance to run.
|
||||
It will end up as .comm, so it shouldn't be too wasteful. */
|
||||
is used for instrumentation output before __afl_map_shm() has a chance to
|
||||
run. It will end up as .comm, so it shouldn't be too wasteful. */
|
||||
|
||||
u8 __afl_area_initial[MAP_SIZE];
|
||||
u8* __afl_area_ptr = __afl_area_initial;
|
||||
|
||||
#ifdef __ANDROID__
|
||||
u32 __afl_prev_loc;
|
||||
#else
|
||||
__thread u32 __afl_prev_loc;
|
||||
|
||||
#endif
|
||||
|
||||
/* Running in persistent mode? */
|
||||
|
||||
static u8 is_persistent;
|
||||
|
||||
|
||||
/* SHM setup. */
|
||||
|
||||
static void __afl_map_shm(void) {
|
||||
|
||||
u8 *id_str = getenv(SHM_ENV_VAR);
|
||||
u8* id_str = getenv(SHM_ENV_VAR);
|
||||
|
||||
/* If we're running under AFL, attach to the appropriate region, replacing the
|
||||
early-stage __afl_area_initial region that is needed to allow some really
|
||||
@ -72,13 +79,42 @@ static void __afl_map_shm(void) {
|
||||
|
||||
if (id_str) {
|
||||
|
||||
#ifdef USEMMAP
|
||||
const char* shm_file_path = id_str;
|
||||
int shm_fd = -1;
|
||||
unsigned char* shm_base = NULL;
|
||||
|
||||
/* create the shared memory segment as if it was a file */
|
||||
shm_fd = shm_open(shm_file_path, O_RDWR, 0600);
|
||||
if (shm_fd == -1) {
|
||||
|
||||
printf("shm_open() failed\n");
|
||||
exit(1);
|
||||
|
||||
}
|
||||
|
||||
/* map the shared memory segment to the address space of the process */
|
||||
shm_base = mmap(0, MAP_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, shm_fd, 0);
|
||||
if (shm_base == MAP_FAILED) {
|
||||
|
||||
close(shm_fd);
|
||||
shm_fd = -1;
|
||||
|
||||
printf("mmap() failed\n");
|
||||
exit(2);
|
||||
|
||||
}
|
||||
|
||||
__afl_area_ptr = shm_base;
|
||||
#else
|
||||
u32 shm_id = atoi(id_str);
|
||||
|
||||
__afl_area_ptr = shmat(shm_id, NULL, 0);
|
||||
#endif
|
||||
|
||||
/* Whooooops. */
|
||||
|
||||
if (__afl_area_ptr == (void *)-1) _exit(1);
|
||||
if (__afl_area_ptr == (void*)-1) _exit(1);
|
||||
|
||||
/* Write something into the bitmap so that even with low AFL_INST_RATIO,
|
||||
our parent doesn't give up on us. */
|
||||
@ -89,16 +125,15 @@ static void __afl_map_shm(void) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Fork server logic. */
|
||||
|
||||
static void __afl_start_forkserver(void) {
|
||||
|
||||
static u8 tmp[4];
|
||||
s32 child_pid;
|
||||
s32 child_pid;
|
||||
|
||||
u8 child_stopped = 0;
|
||||
|
||||
u8 child_stopped = 0;
|
||||
|
||||
void (*old_sigchld_handler)(int) = signal(SIGCHLD, SIG_DFL);
|
||||
|
||||
/* Phone home and tell the parent that we're OK. If parent isn't there,
|
||||
@ -120,8 +155,10 @@ static void __afl_start_forkserver(void) {
|
||||
process. */
|
||||
|
||||
if (child_stopped && was_killed) {
|
||||
|
||||
child_stopped = 0;
|
||||
if (waitpid(child_pid, &status, 0) < 0) _exit(1);
|
||||
|
||||
}
|
||||
|
||||
if (!child_stopped) {
|
||||
@ -134,12 +171,13 @@ static void __afl_start_forkserver(void) {
|
||||
/* In child process: close fds, resume execution. */
|
||||
|
||||
if (!child_pid) {
|
||||
|
||||
signal(SIGCHLD, old_sigchld_handler);
|
||||
|
||||
close(FORKSRV_FD);
|
||||
close(FORKSRV_FD + 1);
|
||||
return;
|
||||
|
||||
|
||||
}
|
||||
|
||||
} else {
|
||||
@ -173,7 +211,6 @@ static void __afl_start_forkserver(void) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* A simplified persistent mode handler, used as explained in README.llvm. */
|
||||
|
||||
int __afl_persistent_loop(unsigned int max_cnt) {
|
||||
@ -193,9 +230,10 @@ int __afl_persistent_loop(unsigned int max_cnt) {
|
||||
memset(__afl_area_ptr, 0, MAP_SIZE);
|
||||
__afl_area_ptr[0] = 1;
|
||||
__afl_prev_loc = 0;
|
||||
|
||||
}
|
||||
|
||||
cycle_cnt = max_cnt;
|
||||
cycle_cnt = max_cnt;
|
||||
first_pass = 0;
|
||||
return 1;
|
||||
|
||||
@ -228,7 +266,6 @@ int __afl_persistent_loop(unsigned int max_cnt) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* This one can be called from user code when deferred forkserver mode
|
||||
is enabled. */
|
||||
|
||||
@ -246,7 +283,6 @@ void __afl_manual_init(void) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Proper initialization routine. */
|
||||
|
||||
__attribute__((constructor(CONST_PRIO))) void __afl_auto_init(void) {
|
||||
@ -259,7 +295,6 @@ __attribute__((constructor(CONST_PRIO))) void __afl_auto_init(void) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* The following stuff deals with supporting -fsanitize-coverage=trace-pc-guard.
|
||||
It remains non-operational in the traditional, plugin-backed LLVM mode.
|
||||
For more info about 'trace-pc-guard', see README.llvm.
|
||||
@ -268,9 +303,10 @@ __attribute__((constructor(CONST_PRIO))) void __afl_auto_init(void) {
|
||||
edge (as opposed to every basic block). */
|
||||
|
||||
void __sanitizer_cov_trace_pc_guard(uint32_t* guard) {
|
||||
__afl_area_ptr[*guard]++;
|
||||
}
|
||||
|
||||
__afl_area_ptr[*guard]++;
|
||||
|
||||
}
|
||||
|
||||
/* Init callback. Populates instrumentation IDs. Note that we're using
|
||||
ID of 0 as a special value to indicate non-instrumented bits. That may
|
||||
@ -287,8 +323,10 @@ void __sanitizer_cov_trace_pc_guard_init(uint32_t* start, uint32_t* stop) {
|
||||
if (x) inst_ratio = atoi(x);
|
||||
|
||||
if (!inst_ratio || inst_ratio > 100) {
|
||||
|
||||
fprintf(stderr, "[-] ERROR: Invalid AFL_INST_RATIO (must be 1-100).\n");
|
||||
abort();
|
||||
|
||||
}
|
||||
|
||||
/* Make sure that the first element in the range is always set - we use that
|
||||
@ -299,11 +337,14 @@ void __sanitizer_cov_trace_pc_guard_init(uint32_t* start, uint32_t* stop) {
|
||||
|
||||
while (start < stop) {
|
||||
|
||||
if (R(100) < inst_ratio) *start = R(MAP_SIZE - 1) + 1;
|
||||
else *start = 0;
|
||||
if (R(100) < inst_ratio)
|
||||
*start = R(MAP_SIZE - 1) + 1;
|
||||
else
|
||||
*start = 0;
|
||||
|
||||
start++;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
@ -36,191 +36,236 @@ using namespace llvm;
|
||||
|
||||
namespace {
|
||||
|
||||
class CompareTransform : public ModulePass {
|
||||
class CompareTransform : public ModulePass {
|
||||
|
||||
public:
|
||||
static char ID;
|
||||
CompareTransform() : ModulePass(ID) {
|
||||
}
|
||||
public:
|
||||
static char ID;
|
||||
CompareTransform() : ModulePass(ID) {
|
||||
|
||||
bool runOnModule(Module &M) override;
|
||||
}
|
||||
|
||||
bool runOnModule(Module &M) override;
|
||||
|
||||
#if LLVM_VERSION_MAJOR < 4
|
||||
const char * getPassName() const override {
|
||||
#else
|
||||
StringRef getPassName() const override {
|
||||
#endif
|
||||
return "transforms compare functions";
|
||||
}
|
||||
private:
|
||||
bool transformCmps(Module &M, const bool processStrcmp, const bool processMemcmp
|
||||
,const bool processStrncmp, const bool processStrcasecmp, const bool processStrncasecmp);
|
||||
};
|
||||
}
|
||||
const char *getPassName() const override {
|
||||
|
||||
#else
|
||||
StringRef getPassName() const override {
|
||||
|
||||
#endif
|
||||
return "transforms compare functions";
|
||||
|
||||
}
|
||||
|
||||
private:
|
||||
bool transformCmps(Module &M, const bool processStrcmp,
|
||||
const bool processMemcmp, const bool processStrncmp,
|
||||
const bool processStrcasecmp,
|
||||
const bool processStrncasecmp);
|
||||
|
||||
};
|
||||
|
||||
} // namespace
|
||||
|
||||
char CompareTransform::ID = 0;
|
||||
|
||||
bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, const bool processMemcmp
|
||||
, const bool processStrncmp, const bool processStrcasecmp, const bool processStrncasecmp) {
|
||||
bool CompareTransform::transformCmps(Module &M, const bool processStrcmp,
|
||||
const bool processMemcmp,
|
||||
const bool processStrncmp,
|
||||
const bool processStrcasecmp,
|
||||
const bool processStrncasecmp) {
|
||||
|
||||
std::vector<CallInst*> calls;
|
||||
LLVMContext &C = M.getContext();
|
||||
IntegerType *Int8Ty = IntegerType::getInt8Ty(C);
|
||||
IntegerType *Int32Ty = IntegerType::getInt32Ty(C);
|
||||
IntegerType *Int64Ty = IntegerType::getInt64Ty(C);
|
||||
std::vector<CallInst *> calls;
|
||||
LLVMContext & C = M.getContext();
|
||||
IntegerType * Int8Ty = IntegerType::getInt8Ty(C);
|
||||
IntegerType * Int32Ty = IntegerType::getInt32Ty(C);
|
||||
IntegerType * Int64Ty = IntegerType::getInt64Ty(C);
|
||||
|
||||
#if LLVM_VERSION_MAJOR < 9
|
||||
Constant*
|
||||
Constant *
|
||||
#else
|
||||
FunctionCallee
|
||||
#endif
|
||||
c = M.getOrInsertFunction("tolower",
|
||||
Int32Ty,
|
||||
Int32Ty
|
||||
c = M.getOrInsertFunction("tolower", Int32Ty, Int32Ty
|
||||
#if LLVM_VERSION_MAJOR < 5
|
||||
, nullptr
|
||||
,
|
||||
nullptr
|
||||
#endif
|
||||
);
|
||||
#if LLVM_VERSION_MAJOR < 9
|
||||
Function *tolowerFn = cast<Function>(c);
|
||||
#else
|
||||
FunctionCallee tolowerFn = c;
|
||||
#endif
|
||||
);
|
||||
Function* tolowerFn = cast<Function>(c);
|
||||
|
||||
/* iterate over all functions, bbs and instruction and add suitable calls to strcmp/memcmp/strncmp/strcasecmp/strncasecmp */
|
||||
/* iterate over all functions, bbs and instruction and add suitable calls to
|
||||
* strcmp/memcmp/strncmp/strcasecmp/strncasecmp */
|
||||
for (auto &F : M) {
|
||||
|
||||
for (auto &BB : F) {
|
||||
for(auto &IN: BB) {
|
||||
CallInst* callInst = nullptr;
|
||||
|
||||
for (auto &IN : BB) {
|
||||
|
||||
CallInst *callInst = nullptr;
|
||||
|
||||
if ((callInst = dyn_cast<CallInst>(&IN))) {
|
||||
|
||||
bool isStrcmp = processStrcmp;
|
||||
bool isMemcmp = processMemcmp;
|
||||
bool isStrncmp = processStrncmp;
|
||||
bool isStrcasecmp = processStrcasecmp;
|
||||
bool isStrcmp = processStrcmp;
|
||||
bool isMemcmp = processMemcmp;
|
||||
bool isStrncmp = processStrncmp;
|
||||
bool isStrcasecmp = processStrcasecmp;
|
||||
bool isStrncasecmp = processStrncasecmp;
|
||||
|
||||
Function *Callee = callInst->getCalledFunction();
|
||||
if (!Callee)
|
||||
continue;
|
||||
if (callInst->getCallingConv() != llvm::CallingConv::C)
|
||||
continue;
|
||||
if (!Callee) continue;
|
||||
if (callInst->getCallingConv() != llvm::CallingConv::C) continue;
|
||||
StringRef FuncName = Callee->getName();
|
||||
isStrcmp &= !FuncName.compare(StringRef("strcmp"));
|
||||
isMemcmp &= !FuncName.compare(StringRef("memcmp"));
|
||||
isStrncmp &= !FuncName.compare(StringRef("strncmp"));
|
||||
isStrcasecmp &= !FuncName.compare(StringRef("strcasecmp"));
|
||||
isStrcmp &= !FuncName.compare(StringRef("strcmp"));
|
||||
isMemcmp &= !FuncName.compare(StringRef("memcmp"));
|
||||
isStrncmp &= !FuncName.compare(StringRef("strncmp"));
|
||||
isStrcasecmp &= !FuncName.compare(StringRef("strcasecmp"));
|
||||
isStrncasecmp &= !FuncName.compare(StringRef("strncasecmp"));
|
||||
|
||||
if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && !isStrncasecmp)
|
||||
if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp &&
|
||||
!isStrncasecmp)
|
||||
continue;
|
||||
|
||||
/* Verify the strcmp/memcmp/strncmp/strcasecmp/strncasecmp function prototype */
|
||||
/* Verify the strcmp/memcmp/strncmp/strcasecmp/strncasecmp function
|
||||
* prototype */
|
||||
FunctionType *FT = Callee->getFunctionType();
|
||||
|
||||
|
||||
isStrcmp &= FT->getNumParams() == 2 &&
|
||||
FT->getReturnType()->isIntegerTy(32) &&
|
||||
FT->getParamType(0) == FT->getParamType(1) &&
|
||||
FT->getParamType(0) == IntegerType::getInt8PtrTy(M.getContext());
|
||||
isStrcasecmp &= FT->getNumParams() == 2 &&
|
||||
FT->getReturnType()->isIntegerTy(32) &&
|
||||
FT->getParamType(0) == FT->getParamType(1) &&
|
||||
FT->getParamType(0) == IntegerType::getInt8PtrTy(M.getContext());
|
||||
isMemcmp &= FT->getNumParams() == 3 &&
|
||||
isStrcmp &=
|
||||
FT->getNumParams() == 2 && FT->getReturnType()->isIntegerTy(32) &&
|
||||
FT->getParamType(0) == FT->getParamType(1) &&
|
||||
FT->getParamType(0) == IntegerType::getInt8PtrTy(M.getContext());
|
||||
isStrcasecmp &=
|
||||
FT->getNumParams() == 2 && FT->getReturnType()->isIntegerTy(32) &&
|
||||
FT->getParamType(0) == FT->getParamType(1) &&
|
||||
FT->getParamType(0) == IntegerType::getInt8PtrTy(M.getContext());
|
||||
isMemcmp &= FT->getNumParams() == 3 &&
|
||||
FT->getReturnType()->isIntegerTy(32) &&
|
||||
FT->getParamType(0)->isPointerTy() &&
|
||||
FT->getParamType(1)->isPointerTy() &&
|
||||
FT->getParamType(2)->isIntegerTy();
|
||||
isStrncmp &= FT->getNumParams() == 3 &&
|
||||
FT->getReturnType()->isIntegerTy(32) &&
|
||||
FT->getParamType(0) == FT->getParamType(1) &&
|
||||
FT->getParamType(0) == IntegerType::getInt8PtrTy(M.getContext()) &&
|
||||
FT->getParamType(2)->isIntegerTy();
|
||||
isStrncmp &= FT->getNumParams() == 3 &&
|
||||
FT->getReturnType()->isIntegerTy(32) &&
|
||||
FT->getParamType(0) == FT->getParamType(1) &&
|
||||
FT->getParamType(0) ==
|
||||
IntegerType::getInt8PtrTy(M.getContext()) &&
|
||||
FT->getParamType(2)->isIntegerTy();
|
||||
isStrncasecmp &= FT->getNumParams() == 3 &&
|
||||
FT->getReturnType()->isIntegerTy(32) &&
|
||||
FT->getParamType(0) == FT->getParamType(1) &&
|
||||
FT->getParamType(0) == IntegerType::getInt8PtrTy(M.getContext()) &&
|
||||
FT->getParamType(2)->isIntegerTy();
|
||||
FT->getReturnType()->isIntegerTy(32) &&
|
||||
FT->getParamType(0) == FT->getParamType(1) &&
|
||||
FT->getParamType(0) ==
|
||||
IntegerType::getInt8PtrTy(M.getContext()) &&
|
||||
FT->getParamType(2)->isIntegerTy();
|
||||
|
||||
if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && !isStrncasecmp)
|
||||
if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp &&
|
||||
!isStrncasecmp)
|
||||
continue;
|
||||
|
||||
/* is a str{n,}{case,}cmp/memcmp, check is we have
|
||||
/* is a str{n,}{case,}cmp/memcmp, check if we have
|
||||
* str{case,}cmp(x, "const") or str{case,}cmp("const", x)
|
||||
* strn{case,}cmp(x, "const", ..) or strn{case,}cmp("const", x, ..)
|
||||
* memcmp(x, "const", ..) or memcmp("const", x, ..) */
|
||||
Value *Str1P = callInst->getArgOperand(0), *Str2P = callInst->getArgOperand(1);
|
||||
Value *Str1P = callInst->getArgOperand(0),
|
||||
*Str2P = callInst->getArgOperand(1);
|
||||
StringRef Str1, Str2;
|
||||
bool HasStr1 = getConstantStringInfo(Str1P, Str1);
|
||||
bool HasStr2 = getConstantStringInfo(Str2P, Str2);
|
||||
bool HasStr1 = getConstantStringInfo(Str1P, Str1);
|
||||
bool HasStr2 = getConstantStringInfo(Str2P, Str2);
|
||||
|
||||
/* handle cases of one string is const, one string is variable */
|
||||
if (!(HasStr1 ^ HasStr2))
|
||||
continue;
|
||||
if (!(HasStr1 ^ HasStr2)) continue;
|
||||
|
||||
if (isMemcmp || isStrncmp || isStrncasecmp) {
|
||||
|
||||
/* check if third operand is a constant integer
|
||||
* strlen("constStr") and sizeof() are treated as constant */
|
||||
Value *op2 = callInst->getArgOperand(2);
|
||||
ConstantInt* ilen = dyn_cast<ConstantInt>(op2);
|
||||
if (!ilen)
|
||||
continue;
|
||||
/* final precaution: if size of compare is larger than constant string skip it*/
|
||||
uint64_t literalLength = HasStr1 ? GetStringLength(Str1P) : GetStringLength(Str2P);
|
||||
if (literalLength < ilen->getZExtValue())
|
||||
continue;
|
||||
Value * op2 = callInst->getArgOperand(2);
|
||||
ConstantInt *ilen = dyn_cast<ConstantInt>(op2);
|
||||
if (!ilen) continue;
|
||||
/* final precaution: if size of compare is larger than constant
|
||||
* string skip it*/
|
||||
uint64_t literalLength =
|
||||
HasStr1 ? GetStringLength(Str1P) : GetStringLength(Str2P);
|
||||
if (literalLength < ilen->getZExtValue()) continue;
|
||||
|
||||
}
|
||||
|
||||
calls.push_back(callInst);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (!calls.size())
|
||||
return false;
|
||||
errs() << "Replacing " << calls.size() << " calls to strcmp/memcmp/strncmp/strcasecmp/strncasecmp\n";
|
||||
if (!calls.size()) return false;
|
||||
errs() << "Replacing " << calls.size()
|
||||
<< " calls to strcmp/memcmp/strncmp/strcasecmp/strncasecmp\n";
|
||||
|
||||
for (auto &callInst: calls) {
|
||||
for (auto &callInst : calls) {
|
||||
|
||||
Value *Str1P = callInst->getArgOperand(0), *Str2P = callInst->getArgOperand(1);
|
||||
StringRef Str1, Str2, ConstStr;
|
||||
Value *VarStr;
|
||||
bool HasStr1 = getConstantStringInfo(Str1P, Str1);
|
||||
Value *Str1P = callInst->getArgOperand(0),
|
||||
*Str2P = callInst->getArgOperand(1);
|
||||
StringRef Str1, Str2, ConstStr;
|
||||
std::string TmpConstStr;
|
||||
Value * VarStr;
|
||||
bool HasStr1 = getConstantStringInfo(Str1P, Str1);
|
||||
getConstantStringInfo(Str2P, Str2);
|
||||
uint64_t constLen, sizedLen;
|
||||
bool isMemcmp = !callInst->getCalledFunction()->getName().compare(StringRef("memcmp"));
|
||||
bool isSizedcmp = isMemcmp
|
||||
|| !callInst->getCalledFunction()->getName().compare(StringRef("strncmp"))
|
||||
|| !callInst->getCalledFunction()->getName().compare(StringRef("strncasecmp"));
|
||||
bool isCaseInsensitive = !callInst->getCalledFunction()->getName().compare(StringRef("strcasecmp"))
|
||||
|| !callInst->getCalledFunction()->getName().compare(StringRef("strncasecmp"));
|
||||
bool isMemcmp =
|
||||
!callInst->getCalledFunction()->getName().compare(StringRef("memcmp"));
|
||||
bool isSizedcmp = isMemcmp ||
|
||||
!callInst->getCalledFunction()->getName().compare(
|
||||
StringRef("strncmp")) ||
|
||||
!callInst->getCalledFunction()->getName().compare(
|
||||
StringRef("strncasecmp"));
|
||||
bool isCaseInsensitive = !callInst->getCalledFunction()->getName().compare(
|
||||
StringRef("strcasecmp")) ||
|
||||
!callInst->getCalledFunction()->getName().compare(
|
||||
StringRef("strncasecmp"));
|
||||
|
||||
if (isSizedcmp) {
|
||||
Value *op2 = callInst->getArgOperand(2);
|
||||
ConstantInt* ilen = dyn_cast<ConstantInt>(op2);
|
||||
|
||||
Value * op2 = callInst->getArgOperand(2);
|
||||
ConstantInt *ilen = dyn_cast<ConstantInt>(op2);
|
||||
sizedLen = ilen->getZExtValue();
|
||||
|
||||
}
|
||||
|
||||
if (HasStr1) {
|
||||
ConstStr = Str1;
|
||||
|
||||
TmpConstStr = Str1.str();
|
||||
VarStr = Str2P;
|
||||
constLen = isMemcmp ? sizedLen : GetStringLength(Str1P);
|
||||
}
|
||||
else {
|
||||
ConstStr = Str2;
|
||||
|
||||
} else {
|
||||
|
||||
TmpConstStr = Str2.str();
|
||||
VarStr = Str1P;
|
||||
constLen = isMemcmp ? sizedLen : GetStringLength(Str2P);
|
||||
}
|
||||
if (isSizedcmp && constLen > sizedLen) {
|
||||
constLen = sizedLen;
|
||||
|
||||
}
|
||||
|
||||
errs() << callInst->getCalledFunction()->getName() << ": len " << constLen << ": " << ConstStr << "\n";
|
||||
/* properly handle zero terminated C strings by adding the terminating 0 to
|
||||
* the StringRef (in comparison to std::string a StringRef has built-in
|
||||
* runtime bounds checking, which makes debugging easier) */
|
||||
TmpConstStr.append("\0", 1);
|
||||
ConstStr = StringRef(TmpConstStr);
|
||||
|
||||
if (isSizedcmp && constLen > sizedLen) { constLen = sizedLen; }
|
||||
|
||||
errs() << callInst->getCalledFunction()->getName() << ": len " << constLen
|
||||
<< ": " << ConstStr << "\n";
|
||||
|
||||
/* split before the call instruction */
|
||||
BasicBlock *bb = callInst->getParent();
|
||||
BasicBlock *end_bb = bb->splitBasicBlock(BasicBlock::iterator(callInst));
|
||||
BasicBlock *next_bb = BasicBlock::Create(C, "cmp_added", end_bb->getParent(), end_bb);
|
||||
BasicBlock *next_bb =
|
||||
BasicBlock::Create(C, "cmp_added", end_bb->getParent(), end_bb);
|
||||
BranchInst::Create(end_bb, next_bb);
|
||||
PHINode *PN = PHINode::Create(Int32Ty, constLen + 1, "cmp_phi");
|
||||
|
||||
@ -238,74 +283,81 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, const
|
||||
|
||||
char c = isCaseInsensitive ? tolower(ConstStr[i]) : ConstStr[i];
|
||||
|
||||
|
||||
BasicBlock::iterator IP = next_bb->getFirstInsertionPt();
|
||||
IRBuilder<> IRB(&*IP);
|
||||
IRBuilder<> IRB(&*IP);
|
||||
|
||||
Value* v = ConstantInt::get(Int64Ty, i);
|
||||
Value *ele = IRB.CreateInBoundsGEP(VarStr, v, "empty");
|
||||
Value *v = ConstantInt::get(Int64Ty, i);
|
||||
Value *ele = IRB.CreateInBoundsGEP(VarStr, v, "empty");
|
||||
Value *load = IRB.CreateLoad(ele);
|
||||
if (isCaseInsensitive) {
|
||||
|
||||
// load >= 'A' && load <= 'Z' ? load | 0x020 : load
|
||||
std::vector<Value *> args;
|
||||
args.push_back(load);
|
||||
load = IRB.CreateCall(tolowerFn, args, "tmp");
|
||||
load = IRB.CreateTrunc(load, Int8Ty);
|
||||
|
||||
}
|
||||
|
||||
Value *isub;
|
||||
if (HasStr1)
|
||||
isub = IRB.CreateSub(ConstantInt::get(Int8Ty, c), load);
|
||||
else
|
||||
isub = IRB.CreateSub(load, ConstantInt::get(Int8Ty, c));
|
||||
|
||||
Value *sext = IRB.CreateSExt(isub, Int32Ty);
|
||||
Value *sext = IRB.CreateSExt(isub, Int32Ty);
|
||||
PN->addIncoming(sext, cur_bb);
|
||||
|
||||
|
||||
if (i < constLen - 1) {
|
||||
next_bb = BasicBlock::Create(C, "cmp_added", end_bb->getParent(), end_bb);
|
||||
|
||||
next_bb =
|
||||
BasicBlock::Create(C, "cmp_added", end_bb->getParent(), end_bb);
|
||||
BranchInst::Create(end_bb, next_bb);
|
||||
|
||||
#if LLVM_VERSION_MAJOR < 8
|
||||
TerminatorInst *term = cur_bb->getTerminator();
|
||||
#else
|
||||
Instruction *term = cur_bb->getTerminator();
|
||||
#endif
|
||||
Value *icmp = IRB.CreateICmpEQ(isub, ConstantInt::get(Int8Ty, 0));
|
||||
IRB.CreateCondBr(icmp, next_bb, end_bb);
|
||||
term->eraseFromParent();
|
||||
cur_bb->getTerminator()->eraseFromParent();
|
||||
|
||||
} else {
|
||||
//IRB.CreateBr(end_bb);
|
||||
|
||||
// IRB.CreateBr(end_bb);
|
||||
|
||||
}
|
||||
|
||||
//add offset to varstr
|
||||
//create load
|
||||
//create signed isub
|
||||
//create icmp
|
||||
//create jcc
|
||||
//create next_bb
|
||||
// add offset to varstr
|
||||
// create load
|
||||
// create signed isub
|
||||
// create icmp
|
||||
// create jcc
|
||||
// create next_bb
|
||||
|
||||
}
|
||||
|
||||
/* since the call is the first instruction of the bb it is safe to
|
||||
* replace it with a phi instruction */
|
||||
BasicBlock::iterator ii(callInst);
|
||||
ReplaceInstWithInst(callInst->getParent()->getInstList(), ii, PN);
|
||||
|
||||
}
|
||||
|
||||
|
||||
return true;
|
||||
|
||||
}
|
||||
|
||||
bool CompareTransform::runOnModule(Module &M) {
|
||||
|
||||
llvm::errs() << "Running compare-transform-pass by laf.intel@gmail.com, extended by heiko@hexco.de\n";
|
||||
if (getenv("AFL_QUIET") == NULL)
|
||||
llvm::errs() << "Running compare-transform-pass by laf.intel@gmail.com, "
|
||||
"extended by heiko@hexco.de\n";
|
||||
transformCmps(M, true, true, true, true, true);
|
||||
verifyModule(M);
|
||||
|
||||
return true;
|
||||
|
||||
}
|
||||
|
||||
static void registerCompTransPass(const PassManagerBuilder &,
|
||||
legacy::PassManagerBase &PM) {
|
||||
legacy::PassManagerBase &PM) {
|
||||
|
||||
auto p = new CompareTransform();
|
||||
PM.add(p);
|
||||
|
||||
@ -27,117 +27,126 @@
|
||||
using namespace llvm;
|
||||
|
||||
namespace {
|
||||
class SplitComparesTransform : public ModulePass {
|
||||
public:
|
||||
static char ID;
|
||||
SplitComparesTransform() : ModulePass(ID) {}
|
||||
|
||||
bool runOnModule(Module &M) override;
|
||||
class SplitComparesTransform : public ModulePass {
|
||||
|
||||
public:
|
||||
static char ID;
|
||||
SplitComparesTransform() : ModulePass(ID) {
|
||||
|
||||
}
|
||||
|
||||
bool runOnModule(Module &M) override;
|
||||
#if LLVM_VERSION_MAJOR >= 4
|
||||
StringRef getPassName() const override {
|
||||
#else
|
||||
const char * getPassName() const override {
|
||||
#endif
|
||||
return "simplifies and splits ICMP instructions";
|
||||
}
|
||||
private:
|
||||
bool splitCompares(Module &M, unsigned bitw);
|
||||
bool simplifyCompares(Module &M);
|
||||
bool simplifySignedness(Module &M);
|
||||
StringRef getPassName() const override {
|
||||
|
||||
};
|
||||
}
|
||||
#else
|
||||
const char *getPassName() const override {
|
||||
|
||||
#endif
|
||||
return "simplifies and splits ICMP instructions";
|
||||
|
||||
}
|
||||
|
||||
private:
|
||||
bool splitCompares(Module &M, unsigned bitw);
|
||||
bool simplifyCompares(Module &M);
|
||||
bool simplifySignedness(Module &M);
|
||||
|
||||
};
|
||||
|
||||
} // namespace
|
||||
|
||||
char SplitComparesTransform::ID = 0;
|
||||
|
||||
/* This function splits ICMP instructions with xGE or xLE predicates into two
|
||||
/* This function splits ICMP instructions with xGE or xLE predicates into two
|
||||
* ICMP instructions with predicate xGT or xLT and EQ */
|
||||
bool SplitComparesTransform::simplifyCompares(Module &M) {
|
||||
LLVMContext &C = M.getContext();
|
||||
std::vector<Instruction*> icomps;
|
||||
IntegerType *Int1Ty = IntegerType::getInt1Ty(C);
|
||||
|
||||
LLVMContext & C = M.getContext();
|
||||
std::vector<Instruction *> icomps;
|
||||
IntegerType * Int1Ty = IntegerType::getInt1Ty(C);
|
||||
|
||||
/* iterate over all functions, bbs and instruction and add
|
||||
* all integer comparisons with >= and <= predicates to the icomps vector */
|
||||
for (auto &F : M) {
|
||||
|
||||
for (auto &BB : F) {
|
||||
for (auto &IN: BB) {
|
||||
CmpInst* selectcmpInst = nullptr;
|
||||
|
||||
for (auto &IN : BB) {
|
||||
|
||||
CmpInst *selectcmpInst = nullptr;
|
||||
|
||||
if ((selectcmpInst = dyn_cast<CmpInst>(&IN))) {
|
||||
|
||||
if (selectcmpInst->getPredicate() != CmpInst::ICMP_UGE &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_SGE &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_ULE &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_SLE ) {
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_SLE) {
|
||||
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
auto op0 = selectcmpInst->getOperand(0);
|
||||
auto op1 = selectcmpInst->getOperand(1);
|
||||
|
||||
IntegerType* intTyOp0 = dyn_cast<IntegerType>(op0->getType());
|
||||
IntegerType* intTyOp1 = dyn_cast<IntegerType>(op1->getType());
|
||||
IntegerType *intTyOp0 = dyn_cast<IntegerType>(op0->getType());
|
||||
IntegerType *intTyOp1 = dyn_cast<IntegerType>(op1->getType());
|
||||
|
||||
/* this is probably not needed but we do it anyway */
|
||||
if (!intTyOp0 || !intTyOp1) {
|
||||
continue;
|
||||
}
|
||||
if (!intTyOp0 || !intTyOp1) { continue; }
|
||||
|
||||
icomps.push_back(selectcmpInst);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (!icomps.size()) {
|
||||
return false;
|
||||
}
|
||||
if (!icomps.size()) { return false; }
|
||||
|
||||
for (auto &IcmpInst : icomps) {
|
||||
|
||||
for (auto &IcmpInst: icomps) {
|
||||
BasicBlock* bb = IcmpInst->getParent();
|
||||
BasicBlock *bb = IcmpInst->getParent();
|
||||
|
||||
auto op0 = IcmpInst->getOperand(0);
|
||||
auto op1 = IcmpInst->getOperand(1);
|
||||
|
||||
/* find out what the new predicate is going to be */
|
||||
auto pred = dyn_cast<CmpInst>(IcmpInst)->getPredicate();
|
||||
auto pred = dyn_cast<CmpInst>(IcmpInst)->getPredicate();
|
||||
CmpInst::Predicate new_pred;
|
||||
switch(pred) {
|
||||
case CmpInst::ICMP_UGE:
|
||||
new_pred = CmpInst::ICMP_UGT;
|
||||
break;
|
||||
case CmpInst::ICMP_SGE:
|
||||
new_pred = CmpInst::ICMP_SGT;
|
||||
break;
|
||||
case CmpInst::ICMP_ULE:
|
||||
new_pred = CmpInst::ICMP_ULT;
|
||||
break;
|
||||
case CmpInst::ICMP_SLE:
|
||||
new_pred = CmpInst::ICMP_SLT;
|
||||
break;
|
||||
default: // keep the compiler happy
|
||||
switch (pred) {
|
||||
|
||||
case CmpInst::ICMP_UGE: new_pred = CmpInst::ICMP_UGT; break;
|
||||
case CmpInst::ICMP_SGE: new_pred = CmpInst::ICMP_SGT; break;
|
||||
case CmpInst::ICMP_ULE: new_pred = CmpInst::ICMP_ULT; break;
|
||||
case CmpInst::ICMP_SLE: new_pred = CmpInst::ICMP_SLT; break;
|
||||
default: // keep the compiler happy
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
/* split before the icmp instruction */
|
||||
BasicBlock* end_bb = bb->splitBasicBlock(BasicBlock::iterator(IcmpInst));
|
||||
BasicBlock *end_bb = bb->splitBasicBlock(BasicBlock::iterator(IcmpInst));
|
||||
|
||||
/* the old bb now contains a unconditional jump to the new one (end_bb)
|
||||
* we need to delete it later */
|
||||
|
||||
/* create the ICMP instruction with new_pred and add it to the old basic
|
||||
* block bb it is now at the position where the old IcmpInst was */
|
||||
Instruction* icmp_np;
|
||||
Instruction *icmp_np;
|
||||
icmp_np = CmpInst::Create(Instruction::ICmp, new_pred, op0, op1);
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), icmp_np);
|
||||
|
||||
/* create a new basic block which holds the new EQ icmp */
|
||||
Instruction *icmp_eq;
|
||||
/* insert middle_bb before end_bb */
|
||||
BasicBlock* middle_bb = BasicBlock::Create(C, "injected",
|
||||
end_bb->getParent(), end_bb);
|
||||
BasicBlock *middle_bb =
|
||||
BasicBlock::Create(C, "injected", end_bb->getParent(), end_bb);
|
||||
icmp_eq = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_EQ, op0, op1);
|
||||
middle_bb->getInstList().push_back(icmp_eq);
|
||||
/* add an unconditional branch to the end of middle_bb with destination
|
||||
@ -150,7 +159,6 @@ bool SplitComparesTransform::simplifyCompares(Module &M) {
|
||||
BranchInst::Create(end_bb, middle_bb, icmp_np, bb);
|
||||
term->eraseFromParent();
|
||||
|
||||
|
||||
/* replace the old IcmpInst (which is the first inst in end_bb) with a PHI
|
||||
* inst to wire up the loose ends */
|
||||
PHINode *PN = PHINode::Create(Int1Ty, 2, "");
|
||||
@ -162,118 +170,139 @@ bool SplitComparesTransform::simplifyCompares(Module &M) {
|
||||
/* replace the old IcmpInst with our new and shiny PHI inst */
|
||||
BasicBlock::iterator ii(IcmpInst);
|
||||
ReplaceInstWithInst(IcmpInst->getParent()->getInstList(), ii, PN);
|
||||
|
||||
}
|
||||
|
||||
return true;
|
||||
|
||||
}
|
||||
|
||||
/* this function transforms signed compares to equivalent unsigned compares */
|
||||
bool SplitComparesTransform::simplifySignedness(Module &M) {
|
||||
LLVMContext &C = M.getContext();
|
||||
std::vector<Instruction*> icomps;
|
||||
IntegerType *Int1Ty = IntegerType::getInt1Ty(C);
|
||||
|
||||
LLVMContext & C = M.getContext();
|
||||
std::vector<Instruction *> icomps;
|
||||
IntegerType * Int1Ty = IntegerType::getInt1Ty(C);
|
||||
|
||||
/* iterate over all functions, bbs and instruction and add
|
||||
* all signed compares to icomps vector */
|
||||
for (auto &F : M) {
|
||||
|
||||
for (auto &BB : F) {
|
||||
for(auto &IN: BB) {
|
||||
CmpInst* selectcmpInst = nullptr;
|
||||
|
||||
for (auto &IN : BB) {
|
||||
|
||||
CmpInst *selectcmpInst = nullptr;
|
||||
|
||||
if ((selectcmpInst = dyn_cast<CmpInst>(&IN))) {
|
||||
|
||||
if (selectcmpInst->getPredicate() != CmpInst::ICMP_SGT &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_SLT
|
||||
) {
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_SLT) {
|
||||
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
auto op0 = selectcmpInst->getOperand(0);
|
||||
auto op1 = selectcmpInst->getOperand(1);
|
||||
|
||||
IntegerType* intTyOp0 = dyn_cast<IntegerType>(op0->getType());
|
||||
IntegerType* intTyOp1 = dyn_cast<IntegerType>(op1->getType());
|
||||
IntegerType *intTyOp0 = dyn_cast<IntegerType>(op0->getType());
|
||||
IntegerType *intTyOp1 = dyn_cast<IntegerType>(op1->getType());
|
||||
|
||||
/* see above */
|
||||
if (!intTyOp0 || !intTyOp1) {
|
||||
continue;
|
||||
}
|
||||
if (!intTyOp0 || !intTyOp1) { continue; }
|
||||
|
||||
/* i think this is not possible but to lazy to look it up */
|
||||
if (intTyOp0->getBitWidth() != intTyOp1->getBitWidth()) {
|
||||
continue;
|
||||
}
|
||||
if (intTyOp0->getBitWidth() != intTyOp1->getBitWidth()) { continue; }
|
||||
|
||||
icomps.push_back(selectcmpInst);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (!icomps.size()) {
|
||||
return false;
|
||||
}
|
||||
if (!icomps.size()) { return false; }
|
||||
|
||||
for (auto &IcmpInst: icomps) {
|
||||
BasicBlock* bb = IcmpInst->getParent();
|
||||
for (auto &IcmpInst : icomps) {
|
||||
|
||||
BasicBlock *bb = IcmpInst->getParent();
|
||||
|
||||
auto op0 = IcmpInst->getOperand(0);
|
||||
auto op1 = IcmpInst->getOperand(1);
|
||||
|
||||
IntegerType* intTyOp0 = dyn_cast<IntegerType>(op0->getType());
|
||||
unsigned bitw = intTyOp0->getBitWidth();
|
||||
IntegerType *intTyOp0 = dyn_cast<IntegerType>(op0->getType());
|
||||
unsigned bitw = intTyOp0->getBitWidth();
|
||||
IntegerType *IntType = IntegerType::get(C, bitw);
|
||||
|
||||
|
||||
/* get the new predicate */
|
||||
auto pred = dyn_cast<CmpInst>(IcmpInst)->getPredicate();
|
||||
auto pred = dyn_cast<CmpInst>(IcmpInst)->getPredicate();
|
||||
CmpInst::Predicate new_pred;
|
||||
if (pred == CmpInst::ICMP_SGT) {
|
||||
|
||||
new_pred = CmpInst::ICMP_UGT;
|
||||
|
||||
} else {
|
||||
|
||||
new_pred = CmpInst::ICMP_ULT;
|
||||
|
||||
}
|
||||
|
||||
BasicBlock* end_bb = bb->splitBasicBlock(BasicBlock::iterator(IcmpInst));
|
||||
BasicBlock *end_bb = bb->splitBasicBlock(BasicBlock::iterator(IcmpInst));
|
||||
|
||||
/* create a 1 bit compare for the sign bit. to do this shift and trunc
|
||||
* the original operands so only the first bit remains.*/
|
||||
Instruction *s_op0, *t_op0, *s_op1, *t_op1, *icmp_sign_bit;
|
||||
|
||||
s_op0 = BinaryOperator::Create(Instruction::LShr, op0, ConstantInt::get(IntType, bitw - 1));
|
||||
s_op0 = BinaryOperator::Create(Instruction::LShr, op0,
|
||||
ConstantInt::get(IntType, bitw - 1));
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), s_op0);
|
||||
t_op0 = new TruncInst(s_op0, Int1Ty);
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), t_op0);
|
||||
|
||||
s_op1 = BinaryOperator::Create(Instruction::LShr, op1, ConstantInt::get(IntType, bitw - 1));
|
||||
s_op1 = BinaryOperator::Create(Instruction::LShr, op1,
|
||||
ConstantInt::get(IntType, bitw - 1));
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), s_op1);
|
||||
t_op1 = new TruncInst(s_op1, Int1Ty);
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), t_op1);
|
||||
|
||||
/* compare of the sign bits */
|
||||
icmp_sign_bit = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_EQ, t_op0, t_op1);
|
||||
icmp_sign_bit =
|
||||
CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_EQ, t_op0, t_op1);
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), icmp_sign_bit);
|
||||
|
||||
/* create a new basic block which is executed if the signedness bit is
|
||||
* different */
|
||||
* different */
|
||||
Instruction *icmp_inv_sig_cmp;
|
||||
BasicBlock* sign_bb = BasicBlock::Create(C, "sign", end_bb->getParent(), end_bb);
|
||||
BasicBlock * sign_bb =
|
||||
BasicBlock::Create(C, "sign", end_bb->getParent(), end_bb);
|
||||
if (pred == CmpInst::ICMP_SGT) {
|
||||
/* if we check for > and the op0 positiv and op1 negative then the final
|
||||
|
||||
/* if we check for > and the op0 positive and op1 negative then the final
|
||||
* result is true. if op0 negative and op1 pos, the cmp must result
|
||||
* in false
|
||||
*/
|
||||
icmp_inv_sig_cmp = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_ULT, t_op0, t_op1);
|
||||
icmp_inv_sig_cmp =
|
||||
CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_ULT, t_op0, t_op1);
|
||||
|
||||
} else {
|
||||
|
||||
/* just the inverse of the above statement */
|
||||
icmp_inv_sig_cmp = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_UGT, t_op0, t_op1);
|
||||
icmp_inv_sig_cmp =
|
||||
CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_UGT, t_op0, t_op1);
|
||||
|
||||
}
|
||||
|
||||
sign_bb->getInstList().push_back(icmp_inv_sig_cmp);
|
||||
BranchInst::Create(end_bb, sign_bb);
|
||||
|
||||
/* create a new bb which is executed if signedness is equal */
|
||||
Instruction *icmp_usign_cmp;
|
||||
BasicBlock* middle_bb = BasicBlock::Create(C, "injected", end_bb->getParent(), end_bb);
|
||||
BasicBlock * middle_bb =
|
||||
BasicBlock::Create(C, "injected", end_bb->getParent(), end_bb);
|
||||
/* we can do a normal unsigned compare now */
|
||||
icmp_usign_cmp = CmpInst::Create(Instruction::ICmp, new_pred, op0, op1);
|
||||
middle_bb->getInstList().push_back(icmp_usign_cmp);
|
||||
@ -285,7 +314,6 @@ bool SplitComparesTransform::simplifySignedness(Module &M) {
|
||||
BranchInst::Create(middle_bb, sign_bb, icmp_sign_bit, bb);
|
||||
term->eraseFromParent();
|
||||
|
||||
|
||||
PHINode *PN = PHINode::Create(Int1Ty, 2, "");
|
||||
|
||||
PN->addIncoming(icmp_usign_cmp, middle_bb);
|
||||
@ -293,91 +321,100 @@ bool SplitComparesTransform::simplifySignedness(Module &M) {
|
||||
|
||||
BasicBlock::iterator ii(IcmpInst);
|
||||
ReplaceInstWithInst(IcmpInst->getParent()->getInstList(), ii, PN);
|
||||
|
||||
}
|
||||
|
||||
return true;
|
||||
|
||||
}
|
||||
|
||||
/* splits icmps of size bitw into two nested icmps with bitw/2 size each */
|
||||
bool SplitComparesTransform::splitCompares(Module &M, unsigned bitw) {
|
||||
|
||||
LLVMContext &C = M.getContext();
|
||||
|
||||
IntegerType *Int1Ty = IntegerType::getInt1Ty(C);
|
||||
IntegerType *OldIntType = IntegerType::get(C, bitw);
|
||||
IntegerType *NewIntType = IntegerType::get(C, bitw / 2);
|
||||
|
||||
std::vector<Instruction*> icomps;
|
||||
std::vector<Instruction *> icomps;
|
||||
|
||||
if (bitw % 2) {
|
||||
return false;
|
||||
}
|
||||
if (bitw % 2) { return false; }
|
||||
|
||||
/* not supported yet */
|
||||
if (bitw > 64) {
|
||||
return false;
|
||||
}
|
||||
if (bitw > 64) { return false; }
|
||||
|
||||
/* get all EQ, NE, UGT, and ULT icmps of width bitw. if the other two
|
||||
/* get all EQ, NE, UGT, and ULT icmps of width bitw. if the other two
|
||||
* unctions were executed only these four predicates should exist */
|
||||
for (auto &F : M) {
|
||||
|
||||
for (auto &BB : F) {
|
||||
for(auto &IN: BB) {
|
||||
CmpInst* selectcmpInst = nullptr;
|
||||
|
||||
for (auto &IN : BB) {
|
||||
|
||||
CmpInst *selectcmpInst = nullptr;
|
||||
|
||||
if ((selectcmpInst = dyn_cast<CmpInst>(&IN))) {
|
||||
|
||||
if(selectcmpInst->getPredicate() != CmpInst::ICMP_EQ &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_NE &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_UGT &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_ULT
|
||||
) {
|
||||
if (selectcmpInst->getPredicate() != CmpInst::ICMP_EQ &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_NE &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_UGT &&
|
||||
selectcmpInst->getPredicate() != CmpInst::ICMP_ULT) {
|
||||
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
auto op0 = selectcmpInst->getOperand(0);
|
||||
auto op1 = selectcmpInst->getOperand(1);
|
||||
|
||||
IntegerType* intTyOp0 = dyn_cast<IntegerType>(op0->getType());
|
||||
IntegerType* intTyOp1 = dyn_cast<IntegerType>(op1->getType());
|
||||
IntegerType *intTyOp0 = dyn_cast<IntegerType>(op0->getType());
|
||||
IntegerType *intTyOp1 = dyn_cast<IntegerType>(op1->getType());
|
||||
|
||||
if (!intTyOp0 || !intTyOp1) {
|
||||
continue;
|
||||
}
|
||||
if (!intTyOp0 || !intTyOp1) { continue; }
|
||||
|
||||
/* check if the bitwidths are the one we are looking for */
|
||||
if (intTyOp0->getBitWidth() != bitw || intTyOp1->getBitWidth() != bitw) {
|
||||
if (intTyOp0->getBitWidth() != bitw ||
|
||||
intTyOp1->getBitWidth() != bitw) {
|
||||
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
icomps.push_back(selectcmpInst);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (!icomps.size()) {
|
||||
return false;
|
||||
}
|
||||
if (!icomps.size()) { return false; }
|
||||
|
||||
for (auto &IcmpInst: icomps) {
|
||||
BasicBlock* bb = IcmpInst->getParent();
|
||||
for (auto &IcmpInst : icomps) {
|
||||
|
||||
BasicBlock *bb = IcmpInst->getParent();
|
||||
|
||||
auto op0 = IcmpInst->getOperand(0);
|
||||
auto op1 = IcmpInst->getOperand(1);
|
||||
|
||||
auto pred = dyn_cast<CmpInst>(IcmpInst)->getPredicate();
|
||||
|
||||
BasicBlock* end_bb = bb->splitBasicBlock(BasicBlock::iterator(IcmpInst));
|
||||
BasicBlock *end_bb = bb->splitBasicBlock(BasicBlock::iterator(IcmpInst));
|
||||
|
||||
/* create the comparison of the top halfs of the original operands */
|
||||
/* create the comparison of the top halves of the original operands */
|
||||
Instruction *s_op0, *op0_high, *s_op1, *op1_high, *icmp_high;
|
||||
|
||||
s_op0 = BinaryOperator::Create(Instruction::LShr, op0, ConstantInt::get(OldIntType, bitw / 2));
|
||||
s_op0 = BinaryOperator::Create(Instruction::LShr, op0,
|
||||
ConstantInt::get(OldIntType, bitw / 2));
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), s_op0);
|
||||
op0_high = new TruncInst(s_op0, NewIntType);
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), op0_high);
|
||||
|
||||
s_op1 = BinaryOperator::Create(Instruction::LShr, op1, ConstantInt::get(OldIntType, bitw / 2));
|
||||
s_op1 = BinaryOperator::Create(Instruction::LShr, op1,
|
||||
ConstantInt::get(OldIntType, bitw / 2));
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), s_op1);
|
||||
op1_high = new TruncInst(s_op1, NewIntType);
|
||||
bb->getInstList().insert(bb->getTerminator()->getIterator(), op1_high);
|
||||
@ -387,11 +424,13 @@ bool SplitComparesTransform::splitCompares(Module &M, unsigned bitw) {
|
||||
|
||||
/* now we have to destinguish between == != and > < */
|
||||
if (pred == CmpInst::ICMP_EQ || pred == CmpInst::ICMP_NE) {
|
||||
|
||||
/* transformation for == and != icmps */
|
||||
|
||||
/* create a compare for the lower half of the original operands */
|
||||
Instruction *op0_low, *op1_low, *icmp_low;
|
||||
BasicBlock* cmp_low_bb = BasicBlock::Create(C, "injected", end_bb->getParent(), end_bb);
|
||||
BasicBlock * cmp_low_bb =
|
||||
BasicBlock::Create(C, "injected", end_bb->getParent(), end_bb);
|
||||
|
||||
op0_low = new TruncInst(op0, NewIntType);
|
||||
cmp_low_bb->getInstList().push_back(op0_low);
|
||||
@ -403,25 +442,34 @@ bool SplitComparesTransform::splitCompares(Module &M, unsigned bitw) {
|
||||
cmp_low_bb->getInstList().push_back(icmp_low);
|
||||
BranchInst::Create(end_bb, cmp_low_bb);
|
||||
|
||||
/* dependant on the cmp of the high parts go to the end or go on with
|
||||
/* dependent on the cmp of the high parts go to the end or go on with
|
||||
* the comparison */
|
||||
auto term = bb->getTerminator();
|
||||
if (pred == CmpInst::ICMP_EQ) {
|
||||
|
||||
BranchInst::Create(cmp_low_bb, end_bb, icmp_high, bb);
|
||||
|
||||
} else {
|
||||
|
||||
/* CmpInst::ICMP_NE */
|
||||
BranchInst::Create(end_bb, cmp_low_bb, icmp_high, bb);
|
||||
|
||||
}
|
||||
|
||||
term->eraseFromParent();
|
||||
|
||||
/* create the PHI and connect the edges accordingly */
|
||||
PHINode *PN = PHINode::Create(Int1Ty, 2, "");
|
||||
PN->addIncoming(icmp_low, cmp_low_bb);
|
||||
if (pred == CmpInst::ICMP_EQ) {
|
||||
|
||||
PN->addIncoming(ConstantInt::get(Int1Ty, 0), bb);
|
||||
|
||||
} else {
|
||||
|
||||
/* CmpInst::ICMP_NE */
|
||||
PN->addIncoming(ConstantInt::get(Int1Ty, 1), bb);
|
||||
|
||||
}
|
||||
|
||||
/* replace the old icmp with the new PHI */
|
||||
@ -429,27 +477,37 @@ bool SplitComparesTransform::splitCompares(Module &M, unsigned bitw) {
|
||||
ReplaceInstWithInst(IcmpInst->getParent()->getInstList(), ii, PN);
|
||||
|
||||
} else {
|
||||
|
||||
/* CmpInst::ICMP_UGT and CmpInst::ICMP_ULT */
|
||||
/* transformations for < and > */
|
||||
|
||||
/* create a basic block which checks for the inverse predicate.
|
||||
/* create a basic block which checks for the inverse predicate.
|
||||
* if this is true we can go to the end if not we have to got to the
|
||||
* bb which checks the lower half of the operands */
|
||||
Instruction *icmp_inv_cmp, *op0_low, *op1_low, *icmp_low;
|
||||
BasicBlock* inv_cmp_bb = BasicBlock::Create(C, "inv_cmp", end_bb->getParent(), end_bb);
|
||||
BasicBlock * inv_cmp_bb =
|
||||
BasicBlock::Create(C, "inv_cmp", end_bb->getParent(), end_bb);
|
||||
if (pred == CmpInst::ICMP_UGT) {
|
||||
icmp_inv_cmp = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_ULT, op0_high, op1_high);
|
||||
|
||||
icmp_inv_cmp = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_ULT,
|
||||
op0_high, op1_high);
|
||||
|
||||
} else {
|
||||
icmp_inv_cmp = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_UGT, op0_high, op1_high);
|
||||
|
||||
icmp_inv_cmp = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_UGT,
|
||||
op0_high, op1_high);
|
||||
|
||||
}
|
||||
|
||||
inv_cmp_bb->getInstList().push_back(icmp_inv_cmp);
|
||||
|
||||
auto term = bb->getTerminator();
|
||||
term->eraseFromParent();
|
||||
BranchInst::Create(end_bb, inv_cmp_bb, icmp_high, bb);
|
||||
|
||||
/* create a bb which handles the cmp of the lower halfs */
|
||||
BasicBlock* cmp_low_bb = BasicBlock::Create(C, "injected", end_bb->getParent(), end_bb);
|
||||
/* create a bb which handles the cmp of the lower halves */
|
||||
BasicBlock *cmp_low_bb =
|
||||
BasicBlock::Create(C, "injected", end_bb->getParent(), end_bb);
|
||||
op0_low = new TruncInst(op0, NewIntType);
|
||||
cmp_low_bb->getInstList().push_back(op0_low);
|
||||
op1_low = new TruncInst(op1, NewIntType);
|
||||
@ -468,56 +526,64 @@ bool SplitComparesTransform::splitCompares(Module &M, unsigned bitw) {
|
||||
|
||||
BasicBlock::iterator ii(IcmpInst);
|
||||
ReplaceInstWithInst(IcmpInst->getParent()->getInstList(), ii, PN);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
return true;
|
||||
|
||||
return true;
|
||||
|
||||
}
|
||||
|
||||
bool SplitComparesTransform::runOnModule(Module &M) {
|
||||
|
||||
int bitw = 64;
|
||||
|
||||
char* bitw_env = getenv("LAF_SPLIT_COMPARES_BITW");
|
||||
if (bitw_env) {
|
||||
bitw = atoi(bitw_env);
|
||||
}
|
||||
char *bitw_env = getenv("LAF_SPLIT_COMPARES_BITW");
|
||||
if (!bitw_env) bitw_env = getenv("AFL_LLVM_LAF_SPLIT_COMPARES_BITW");
|
||||
if (bitw_env) { bitw = atoi(bitw_env); }
|
||||
|
||||
simplifyCompares(M);
|
||||
|
||||
simplifySignedness(M);
|
||||
|
||||
errs() << "Split-compare-pass by laf.intel@gmail.com\n";
|
||||
if (getenv("AFL_QUIET") == NULL)
|
||||
errs() << "Split-compare-pass by laf.intel@gmail.com\n";
|
||||
|
||||
switch (bitw) {
|
||||
|
||||
case 64:
|
||||
errs() << "Running split-compare-pass " << 64 << "\n";
|
||||
errs() << "Running split-compare-pass " << 64 << "\n";
|
||||
splitCompares(M, 64);
|
||||
|
||||
[[clang::fallthrough]];
|
||||
/* fallthrough */
|
||||
[[clang::fallthrough]]; /*FALLTHRU*/ /* FALLTHROUGH */
|
||||
case 32:
|
||||
errs() << "Running split-compare-pass " << 32 << "\n";
|
||||
errs() << "Running split-compare-pass " << 32 << "\n";
|
||||
splitCompares(M, 32);
|
||||
|
||||
[[clang::fallthrough]];
|
||||
/* fallthrough */
|
||||
[[clang::fallthrough]]; /*FALLTHRU*/ /* FALLTHROUGH */
|
||||
case 16:
|
||||
errs() << "Running split-compare-pass " << 16 << "\n";
|
||||
errs() << "Running split-compare-pass " << 16 << "\n";
|
||||
splitCompares(M, 16);
|
||||
break;
|
||||
|
||||
default:
|
||||
errs() << "NOT Running split-compare-pass \n";
|
||||
errs() << "NOT Running split-compare-pass \n";
|
||||
return false;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
verifyModule(M);
|
||||
return true;
|
||||
|
||||
}
|
||||
|
||||
static void registerSplitComparesPass(const PassManagerBuilder &,
|
||||
legacy::PassManagerBase &PM) {
|
||||
legacy::PassManagerBase &PM) {
|
||||
|
||||
PM.add(new SplitComparesTransform());
|
||||
|
||||
}
|
||||
|
||||
static RegisterStandardPasses RegisterSplitComparesPass(
|
||||
@ -525,3 +591,4 @@ static RegisterStandardPasses RegisterSplitComparesPass(
|
||||
|
||||
static RegisterStandardPasses RegisterSplitComparesTransPass0(
|
||||
PassManagerBuilder::EP_EnabledOnOptLevel0, registerSplitComparesPass);
|
||||
|
||||
|
||||
@ -36,95 +36,120 @@ using namespace llvm;
|
||||
|
||||
namespace {
|
||||
|
||||
class SplitSwitchesTransform : public ModulePass {
|
||||
class SplitSwitchesTransform : public ModulePass {
|
||||
|
||||
public:
|
||||
static char ID;
|
||||
SplitSwitchesTransform() : ModulePass(ID) {
|
||||
}
|
||||
public:
|
||||
static char ID;
|
||||
SplitSwitchesTransform() : ModulePass(ID) {
|
||||
|
||||
bool runOnModule(Module &M) override;
|
||||
}
|
||||
|
||||
bool runOnModule(Module &M) override;
|
||||
|
||||
#if LLVM_VERSION_MAJOR >= 4
|
||||
StringRef getPassName() const override {
|
||||
StringRef getPassName() const override {
|
||||
|
||||
#else
|
||||
const char * getPassName() const override {
|
||||
const char *getPassName() const override {
|
||||
|
||||
#endif
|
||||
return "splits switch constructs";
|
||||
}
|
||||
struct CaseExpr {
|
||||
ConstantInt* Val;
|
||||
BasicBlock* BB;
|
||||
return "splits switch constructs";
|
||||
|
||||
CaseExpr(ConstantInt *val = nullptr, BasicBlock *bb = nullptr) :
|
||||
Val(val), BB(bb) { }
|
||||
};
|
||||
}
|
||||
|
||||
typedef std::vector<CaseExpr> CaseVector;
|
||||
struct CaseExpr {
|
||||
|
||||
ConstantInt *Val;
|
||||
BasicBlock * BB;
|
||||
|
||||
CaseExpr(ConstantInt *val = nullptr, BasicBlock *bb = nullptr)
|
||||
: Val(val), BB(bb) {
|
||||
|
||||
}
|
||||
|
||||
private:
|
||||
bool splitSwitches(Module &M);
|
||||
bool transformCmps(Module &M, const bool processStrcmp, const bool processMemcmp);
|
||||
BasicBlock* switchConvert(CaseVector Cases, std::vector<bool> bytesChecked,
|
||||
BasicBlock* OrigBlock, BasicBlock* NewDefault,
|
||||
Value* Val, unsigned level);
|
||||
};
|
||||
|
||||
}
|
||||
typedef std::vector<CaseExpr> CaseVector;
|
||||
|
||||
private:
|
||||
bool splitSwitches(Module &M);
|
||||
bool transformCmps(Module &M, const bool processStrcmp,
|
||||
const bool processMemcmp);
|
||||
BasicBlock *switchConvert(CaseVector Cases, std::vector<bool> bytesChecked,
|
||||
BasicBlock *OrigBlock, BasicBlock *NewDefault,
|
||||
Value *Val, unsigned level);
|
||||
|
||||
};
|
||||
|
||||
} // namespace
|
||||
|
||||
char SplitSwitchesTransform::ID = 0;
|
||||
|
||||
|
||||
/* switchConvert - Transform simple list of Cases into list of CaseRange's */
|
||||
BasicBlock* SplitSwitchesTransform::switchConvert(CaseVector Cases, std::vector<bool> bytesChecked,
|
||||
BasicBlock* OrigBlock, BasicBlock* NewDefault,
|
||||
Value* Val, unsigned level) {
|
||||
BasicBlock *SplitSwitchesTransform::switchConvert(
|
||||
CaseVector Cases, std::vector<bool> bytesChecked, BasicBlock *OrigBlock,
|
||||
BasicBlock *NewDefault, Value *Val, unsigned level) {
|
||||
|
||||
unsigned ValTypeBitWidth = Cases[0].Val->getBitWidth();
|
||||
IntegerType *ValType = IntegerType::get(OrigBlock->getContext(), ValTypeBitWidth);
|
||||
IntegerType *ByteType = IntegerType::get(OrigBlock->getContext(), 8);
|
||||
unsigned BytesInValue = bytesChecked.size();
|
||||
unsigned ValTypeBitWidth = Cases[0].Val->getBitWidth();
|
||||
IntegerType *ValType =
|
||||
IntegerType::get(OrigBlock->getContext(), ValTypeBitWidth);
|
||||
IntegerType * ByteType = IntegerType::get(OrigBlock->getContext(), 8);
|
||||
unsigned BytesInValue = bytesChecked.size();
|
||||
std::vector<uint8_t> setSizes;
|
||||
std::vector<std::set<uint8_t>> byteSets(BytesInValue, std::set<uint8_t>());
|
||||
|
||||
assert(ValTypeBitWidth >= 8 && ValTypeBitWidth <= 64);
|
||||
|
||||
/* for each of the possible cases we iterate over all bytes of the values
|
||||
* build a set of possible values at each byte position in byteSets */
|
||||
for (CaseExpr& Case: Cases) {
|
||||
for (CaseExpr &Case : Cases) {
|
||||
|
||||
for (unsigned i = 0; i < BytesInValue; i++) {
|
||||
|
||||
uint8_t byte = (Case.Val->getZExtValue() >> (i*8)) & 0xFF;
|
||||
uint8_t byte = (Case.Val->getZExtValue() >> (i * 8)) & 0xFF;
|
||||
byteSets[i].insert(byte);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* find the index of the first byte position that was not yet checked. then
|
||||
* save the number of possible values at that byte position */
|
||||
unsigned smallestIndex = 0;
|
||||
unsigned smallestSize = 257;
|
||||
for(unsigned i = 0; i < byteSets.size(); i++) {
|
||||
if (bytesChecked[i])
|
||||
continue;
|
||||
for (unsigned i = 0; i < byteSets.size(); i++) {
|
||||
|
||||
if (bytesChecked[i]) continue;
|
||||
if (byteSets[i].size() < smallestSize) {
|
||||
|
||||
smallestIndex = i;
|
||||
smallestSize = byteSets[i].size();
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
assert(bytesChecked[smallestIndex] == false);
|
||||
|
||||
/* there are only smallestSize different bytes at index smallestIndex */
|
||||
|
||||
|
||||
Instruction *Shift, *Trunc;
|
||||
Function* F = OrigBlock->getParent();
|
||||
BasicBlock* NewNode = BasicBlock::Create(Val->getContext(), "NodeBlock", F);
|
||||
Shift = BinaryOperator::Create(Instruction::LShr, Val, ConstantInt::get(ValType, smallestIndex * 8));
|
||||
Function * F = OrigBlock->getParent();
|
||||
BasicBlock * NewNode = BasicBlock::Create(Val->getContext(), "NodeBlock", F);
|
||||
Shift = BinaryOperator::Create(Instruction::LShr, Val,
|
||||
ConstantInt::get(ValType, smallestIndex * 8));
|
||||
NewNode->getInstList().push_back(Shift);
|
||||
|
||||
if (ValTypeBitWidth > 8) {
|
||||
|
||||
Trunc = new TruncInst(Shift, ByteType);
|
||||
NewNode->getInstList().push_back(Trunc);
|
||||
}
|
||||
else {
|
||||
|
||||
} else {
|
||||
|
||||
/* not necessary to trunc */
|
||||
Trunc = Shift;
|
||||
|
||||
}
|
||||
|
||||
/* this is a trivial case, we can directly check for the byte,
|
||||
@ -132,113 +157,155 @@ BasicBlock* SplitSwitchesTransform::switchConvert(CaseVector Cases, std::vector<
|
||||
* mark the byte as checked. if this was the last byte to check
|
||||
* we can finally execute the block belonging to this case */
|
||||
|
||||
|
||||
if (smallestSize == 1) {
|
||||
|
||||
uint8_t byte = *(byteSets[smallestIndex].begin());
|
||||
|
||||
/* insert instructions to check whether the value we are switching on is equal to byte */
|
||||
ICmpInst* Comp = new ICmpInst(ICmpInst::ICMP_EQ, Trunc, ConstantInt::get(ByteType, byte), "byteMatch");
|
||||
/* insert instructions to check whether the value we are switching on is
|
||||
* equal to byte */
|
||||
ICmpInst *Comp =
|
||||
new ICmpInst(ICmpInst::ICMP_EQ, Trunc, ConstantInt::get(ByteType, byte),
|
||||
"byteMatch");
|
||||
NewNode->getInstList().push_back(Comp);
|
||||
|
||||
bytesChecked[smallestIndex] = true;
|
||||
if (std::all_of(bytesChecked.begin(), bytesChecked.end(), [](bool b){return b;} )) {
|
||||
if (std::all_of(bytesChecked.begin(), bytesChecked.end(),
|
||||
[](bool b) { return b; })) {
|
||||
|
||||
assert(Cases.size() == 1);
|
||||
BranchInst::Create(Cases[0].BB, NewDefault, Comp, NewNode);
|
||||
|
||||
/* we have to update the phi nodes! */
|
||||
for (BasicBlock::iterator I = Cases[0].BB->begin(); I != Cases[0].BB->end(); ++I) {
|
||||
if (!isa<PHINode>(&*I)) {
|
||||
continue;
|
||||
}
|
||||
for (BasicBlock::iterator I = Cases[0].BB->begin();
|
||||
I != Cases[0].BB->end(); ++I) {
|
||||
|
||||
if (!isa<PHINode>(&*I)) { continue; }
|
||||
PHINode *PN = cast<PHINode>(I);
|
||||
|
||||
/* Only update the first occurence. */
|
||||
/* Only update the first occurrence. */
|
||||
unsigned Idx = 0, E = PN->getNumIncomingValues();
|
||||
for (; Idx != E; ++Idx) {
|
||||
|
||||
if (PN->getIncomingBlock(Idx) == OrigBlock) {
|
||||
|
||||
PN->setIncomingBlock(Idx, NewNode);
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
else {
|
||||
BasicBlock* BB = switchConvert(Cases, bytesChecked, OrigBlock, NewDefault, Val, level + 1);
|
||||
|
||||
} else {
|
||||
|
||||
BasicBlock *BB = switchConvert(Cases, bytesChecked, OrigBlock, NewDefault,
|
||||
Val, level + 1);
|
||||
BranchInst::Create(BB, NewDefault, Comp, NewNode);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* there is no byte which we can directly check on, split the tree */
|
||||
else {
|
||||
|
||||
std::vector<uint8_t> byteVector;
|
||||
std::copy(byteSets[smallestIndex].begin(), byteSets[smallestIndex].end(), std::back_inserter(byteVector));
|
||||
std::copy(byteSets[smallestIndex].begin(), byteSets[smallestIndex].end(),
|
||||
std::back_inserter(byteVector));
|
||||
std::sort(byteVector.begin(), byteVector.end());
|
||||
uint8_t pivot = byteVector[byteVector.size() / 2];
|
||||
|
||||
/* we already chose to divide the cases based on the value of byte at index smallestIndex
|
||||
* the pivot value determines the threshold for the decicion; if a case value
|
||||
* is smaller at this byte index move it to the LHS vector, otherwise to the RHS vector */
|
||||
/* we already chose to divide the cases based on the value of byte at index
|
||||
* smallestIndex the pivot value determines the threshold for the decicion;
|
||||
* if a case value
|
||||
* is smaller at this byte index move it to the LHS vector, otherwise to the
|
||||
* RHS vector */
|
||||
|
||||
CaseVector LHSCases, RHSCases;
|
||||
|
||||
for (CaseExpr& Case: Cases) {
|
||||
uint8_t byte = (Case.Val->getZExtValue() >> (smallestIndex*8)) & 0xFF;
|
||||
for (CaseExpr &Case : Cases) {
|
||||
|
||||
uint8_t byte = (Case.Val->getZExtValue() >> (smallestIndex * 8)) & 0xFF;
|
||||
|
||||
if (byte < pivot) {
|
||||
LHSCases.push_back(Case);
|
||||
}
|
||||
else {
|
||||
RHSCases.push_back(Case);
|
||||
}
|
||||
}
|
||||
BasicBlock *LBB, *RBB;
|
||||
LBB = switchConvert(LHSCases, bytesChecked, OrigBlock, NewDefault, Val, level + 1);
|
||||
RBB = switchConvert(RHSCases, bytesChecked, OrigBlock, NewDefault, Val, level + 1);
|
||||
|
||||
/* insert instructions to check whether the value we are switching on is equal to byte */
|
||||
ICmpInst* Comp = new ICmpInst(ICmpInst::ICMP_ULT, Trunc, ConstantInt::get(ByteType, pivot), "byteMatch");
|
||||
LHSCases.push_back(Case);
|
||||
|
||||
} else {
|
||||
|
||||
RHSCases.push_back(Case);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
BasicBlock *LBB, *RBB;
|
||||
LBB = switchConvert(LHSCases, bytesChecked, OrigBlock, NewDefault, Val,
|
||||
level + 1);
|
||||
RBB = switchConvert(RHSCases, bytesChecked, OrigBlock, NewDefault, Val,
|
||||
level + 1);
|
||||
|
||||
/* insert instructions to check whether the value we are switching on is
|
||||
* equal to byte */
|
||||
ICmpInst *Comp =
|
||||
new ICmpInst(ICmpInst::ICMP_ULT, Trunc,
|
||||
ConstantInt::get(ByteType, pivot), "byteMatch");
|
||||
NewNode->getInstList().push_back(Comp);
|
||||
BranchInst::Create(LBB, RBB, Comp, NewNode);
|
||||
|
||||
}
|
||||
|
||||
return NewNode;
|
||||
|
||||
}
|
||||
|
||||
bool SplitSwitchesTransform::splitSwitches(Module &M) {
|
||||
|
||||
std::vector<SwitchInst*> switches;
|
||||
std::vector<SwitchInst *> switches;
|
||||
|
||||
/* iterate over all functions, bbs and instruction and add
|
||||
* all switches to switches vector for later processing */
|
||||
for (auto &F : M) {
|
||||
|
||||
for (auto &BB : F) {
|
||||
SwitchInst* switchInst = nullptr;
|
||||
|
||||
SwitchInst *switchInst = nullptr;
|
||||
|
||||
if ((switchInst = dyn_cast<SwitchInst>(BB.getTerminator()))) {
|
||||
if (switchInst->getNumCases() < 1)
|
||||
continue;
|
||||
switches.push_back(switchInst);
|
||||
|
||||
if (switchInst->getNumCases() < 1) continue;
|
||||
switches.push_back(switchInst);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (!switches.size())
|
||||
return false;
|
||||
errs() << "Rewriting " << switches.size() << " switch statements " << "\n";
|
||||
if (!switches.size()) return false;
|
||||
errs() << "Rewriting " << switches.size() << " switch statements "
|
||||
<< "\n";
|
||||
|
||||
for (auto &SI: switches) {
|
||||
for (auto &SI : switches) {
|
||||
|
||||
BasicBlock *CurBlock = SI->getParent();
|
||||
BasicBlock *OrigBlock = CurBlock;
|
||||
Function *F = CurBlock->getParent();
|
||||
Function * F = CurBlock->getParent();
|
||||
/* this is the value we are switching on */
|
||||
Value *Val = SI->getCondition();
|
||||
BasicBlock* Default = SI->getDefaultDest();
|
||||
Value * Val = SI->getCondition();
|
||||
BasicBlock *Default = SI->getDefaultDest();
|
||||
unsigned bitw = Val->getType()->getIntegerBitWidth();
|
||||
|
||||
/* If there is only the default destination, don't bother with the code below. */
|
||||
if (!SI->getNumCases()) {
|
||||
errs() << "switch: " << SI->getNumCases() << " cases " << bitw << " bit\n";
|
||||
|
||||
/* If there is only the default destination or the condition checks 8 bit or
|
||||
* less, don't bother with the code below. */
|
||||
if (!SI->getNumCases() || bitw <= 8) {
|
||||
|
||||
if (getenv("AFL_QUIET") == NULL) errs() << "skip trivial switch..\n";
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
/* Create a new, empty default block so that the new hierarchy of
|
||||
@ -250,17 +317,21 @@ bool SplitSwitchesTransform::splitSwitches(Module &M) {
|
||||
NewDefault->insertInto(F, Default);
|
||||
BranchInst::Create(Default, NewDefault);
|
||||
|
||||
|
||||
/* Prepare cases vector. */
|
||||
CaseVector Cases;
|
||||
for (SwitchInst::CaseIt i = SI->case_begin(), e = SI->case_end(); i != e; ++i)
|
||||
for (SwitchInst::CaseIt i = SI->case_begin(), e = SI->case_end(); i != e;
|
||||
++i)
|
||||
#if LLVM_VERSION_MAJOR < 5
|
||||
Cases.push_back(CaseExpr(i.getCaseValue(), i.getCaseSuccessor()));
|
||||
#else
|
||||
Cases.push_back(CaseExpr(i->getCaseValue(), i->getCaseSuccessor()));
|
||||
#endif
|
||||
std::vector<bool> bytesChecked(Cases[0].Val->getBitWidth() / 8, false);
|
||||
BasicBlock* SwitchBlock = switchConvert(Cases, bytesChecked, OrigBlock, NewDefault, Val, 0);
|
||||
/* bugfix thanks to pbst
|
||||
* round up bytesChecked (in case getBitWidth() % 8 != 0) */
|
||||
std::vector<bool> bytesChecked((7 + Cases[0].Val->getBitWidth()) / 8,
|
||||
false);
|
||||
BasicBlock * SwitchBlock =
|
||||
switchConvert(Cases, bytesChecked, OrigBlock, NewDefault, Val, 0);
|
||||
|
||||
/* Branch to our shiny new if-then stuff... */
|
||||
BranchInst::Create(SwitchBlock, OrigBlock);
|
||||
@ -268,40 +339,47 @@ bool SplitSwitchesTransform::splitSwitches(Module &M) {
|
||||
/* We are now done with the switch instruction, delete it. */
|
||||
CurBlock->getInstList().erase(SI);
|
||||
|
||||
/* we have to update the phi nodes! */
|
||||
for (BasicBlock::iterator I = Default->begin(); I != Default->end(); ++I) {
|
||||
|
||||
/* we have to update the phi nodes! */
|
||||
for (BasicBlock::iterator I = Default->begin(); I != Default->end(); ++I) {
|
||||
if (!isa<PHINode>(&*I)) {
|
||||
continue;
|
||||
}
|
||||
PHINode *PN = cast<PHINode>(I);
|
||||
if (!isa<PHINode>(&*I)) { continue; }
|
||||
PHINode *PN = cast<PHINode>(I);
|
||||
|
||||
/* Only update the first occurence. */
|
||||
unsigned Idx = 0, E = PN->getNumIncomingValues();
|
||||
for (; Idx != E; ++Idx) {
|
||||
if (PN->getIncomingBlock(Idx) == OrigBlock) {
|
||||
PN->setIncomingBlock(Idx, NewDefault);
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
/* Only update the first occurrence. */
|
||||
unsigned Idx = 0, E = PN->getNumIncomingValues();
|
||||
for (; Idx != E; ++Idx) {
|
||||
|
||||
if (PN->getIncomingBlock(Idx) == OrigBlock) {
|
||||
|
||||
PN->setIncomingBlock(Idx, NewDefault);
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
verifyModule(M);
|
||||
return true;
|
||||
|
||||
verifyModule(M);
|
||||
return true;
|
||||
}
|
||||
|
||||
bool SplitSwitchesTransform::runOnModule(Module &M) {
|
||||
|
||||
llvm::errs() << "Running split-switches-pass by laf.intel@gmail.com\n";
|
||||
if (getenv("AFL_QUIET") == NULL)
|
||||
llvm::errs() << "Running split-switches-pass by laf.intel@gmail.com\n";
|
||||
splitSwitches(M);
|
||||
verifyModule(M);
|
||||
|
||||
return true;
|
||||
|
||||
}
|
||||
|
||||
static void registerSplitSwitchesTransPass(const PassManagerBuilder &,
|
||||
legacy::PassManagerBase &PM) {
|
||||
legacy::PassManagerBase &PM) {
|
||||
|
||||
auto p = new SplitSwitchesTransform();
|
||||
PM.add(p);
|
||||
@ -313,3 +391,4 @@ static RegisterStandardPasses RegisterSplitSwitchesTransPass(
|
||||
|
||||
static RegisterStandardPasses RegisterSplitSwitchesTransPass0(
|
||||
PassManagerBuilder::EP_EnabledOnOptLevel0, registerSplitSwitchesTransPass);
|
||||
|
||||
|
||||
15
python_mutators/README
Normal file
15
python_mutators/README
Normal file
@ -0,0 +1,15 @@
|
||||
These are example and helper files for the AFL_PYTHON_MODULE feature.
|
||||
See docs/python_mutators.txt for more information
|
||||
|
||||
|
||||
example.py - this is the template you can use, the functions are there
|
||||
but they are empty
|
||||
|
||||
simple-chunk-replace.py - this is a simple example where chunks are replaced
|
||||
|
||||
common.py - this can be used for common functions and helpers.
|
||||
the examples do not use this though. But you can :)
|
||||
|
||||
wrapper_afl_min.py - mutation of XML documents, loads XmlMutatorMin.py
|
||||
|
||||
XmlMutatorMin.py - module for XML mutation
|
||||
331
python_mutators/XmlMutatorMin.py
Normal file
331
python_mutators/XmlMutatorMin.py
Normal file
@ -0,0 +1,331 @@
|
||||
#!/usr/bin/python
|
||||
|
||||
""" Mutation of XML documents, should be called from one of its wrappers (CLI, AFL, ...) """
|
||||
|
||||
from __future__ import print_function
|
||||
from copy import deepcopy
|
||||
from lxml import etree as ET
|
||||
import random, re, io
|
||||
|
||||
###########################
|
||||
# The XmlMutatorMin class #
|
||||
###########################
|
||||
|
||||
class XmlMutatorMin:
|
||||
|
||||
"""
|
||||
Optionals parameters:
|
||||
seed Seed used by the PRNG (default: "RANDOM")
|
||||
verbose Verbosity (default: False)
|
||||
"""
|
||||
|
||||
def __init__(self, seed="RANDOM", verbose=False):
|
||||
|
||||
""" Initialize seed, database and mutators """
|
||||
|
||||
# Verbosity
|
||||
self.verbose = verbose
|
||||
|
||||
# Initialize PRNG
|
||||
self.seed = str(seed)
|
||||
if self.seed == "RANDOM":
|
||||
random.seed()
|
||||
else:
|
||||
if self.verbose:
|
||||
print("Static seed '%s'" % self.seed)
|
||||
random.seed(self.seed)
|
||||
|
||||
# Initialize input and output documents
|
||||
self.input_tree = None
|
||||
self.tree = None
|
||||
|
||||
# High-level mutators (no database needed)
|
||||
hl_mutators_delete = [ "del_node_and_children", "del_node_but_children", "del_attribute", "del_content" ] # Delete items
|
||||
hl_mutators_fuzz = ["fuzz_attribute"] # Randomly change attribute values
|
||||
|
||||
# Exposed mutators
|
||||
self.hl_mutators_all = hl_mutators_fuzz + hl_mutators_delete
|
||||
|
||||
def __parse_xml (self, xml):
|
||||
|
||||
""" Parse an XML string. Basic wrapper around lxml.parse() """
|
||||
|
||||
try:
|
||||
# Function parse() takes care of comments / DTD / processing instructions / ...
|
||||
tree = ET.parse(io.BytesIO(xml))
|
||||
except ET.ParseError:
|
||||
raise RuntimeError("XML isn't well-formed!")
|
||||
except LookupError as e:
|
||||
raise RuntimeError(e)
|
||||
|
||||
# Return a document wrapper
|
||||
return tree
|
||||
|
||||
def __exec_among (self, module, functions, min_times, max_times):
|
||||
|
||||
""" Randomly execute $functions between $min and $max times """
|
||||
|
||||
for i in xrange (random.randint (min_times, max_times)):
|
||||
# Function names are mangled because they are "private"
|
||||
getattr (module, "_XmlMutatorMin__" + random.choice(functions)) ()
|
||||
|
||||
def __serialize_xml (self, tree):
|
||||
|
||||
""" Serialize a XML document. Basic wrapper around lxml.tostring() """
|
||||
|
||||
return ET.tostring(tree, with_tail=False, xml_declaration=True, encoding=tree.docinfo.encoding)
|
||||
|
||||
def __ver (self, version):
|
||||
|
||||
""" Helper for displaying lxml version numbers """
|
||||
|
||||
return ".".join(map(str, version))
|
||||
|
||||
def reset (self):
|
||||
|
||||
""" Reset the mutator """
|
||||
|
||||
self.tree = deepcopy(self.input_tree)
|
||||
|
||||
def init_from_string (self, input_string):
|
||||
|
||||
""" Initialize the mutator from a XML string """
|
||||
|
||||
# Get a pointer to the top-element
|
||||
self.input_tree = self.__parse_xml(input_string)
|
||||
|
||||
# Get a working copy
|
||||
self.tree = deepcopy(self.input_tree)
|
||||
|
||||
def save_to_string (self):
|
||||
|
||||
""" Return the current XML document as UTF-8 string """
|
||||
|
||||
# Return a text version of the tree
|
||||
return self.__serialize_xml(self.tree)
|
||||
|
||||
def __pick_element (self, exclude_root_node = False):
|
||||
|
||||
""" Pick a random element from the current document """
|
||||
|
||||
# Get a list of all elements, but nodes like PI and comments
|
||||
elems = list(self.tree.getroot().iter(tag=ET.Element))
|
||||
|
||||
# Is the root node excluded?
|
||||
if exclude_root_node:
|
||||
start = 1
|
||||
else:
|
||||
start = 0
|
||||
|
||||
# Pick a random element
|
||||
try:
|
||||
elem_id = random.randint (start, len(elems) - 1)
|
||||
elem = elems[elem_id]
|
||||
except ValueError:
|
||||
# Should only occurs if "exclude_root_node = True"
|
||||
return (None, None)
|
||||
|
||||
return (elem_id, elem)
|
||||
|
||||
def __fuzz_attribute (self):
|
||||
|
||||
""" Fuzz (part of) an attribute value """
|
||||
|
||||
# Select a node to modify
|
||||
(rand_elem_id, rand_elem) = self.__pick_element()
|
||||
|
||||
# Get all the attributes
|
||||
attribs = rand_elem.keys()
|
||||
|
||||
# Is there attributes?
|
||||
if len(attribs) < 1:
|
||||
if self.verbose:
|
||||
print("No attribute: can't replace!")
|
||||
return
|
||||
|
||||
# Pick a random attribute
|
||||
rand_attrib_id = random.randint (0, len(attribs) - 1)
|
||||
rand_attrib = attribs[rand_attrib_id]
|
||||
|
||||
# We have the attribute to modify
|
||||
# Get its value
|
||||
attrib_value = rand_elem.get(rand_attrib);
|
||||
# print("- Value: " + attrib_value)
|
||||
|
||||
# Should we work on the whole value?
|
||||
func_call = "(?P<func>[a-zA-Z:\-]+)\((?P<args>.*?)\)"
|
||||
p = re.compile(func_call)
|
||||
l = p.findall(attrib_value)
|
||||
if random.choice((True,False)) and l:
|
||||
# Randomly pick one the function calls
|
||||
(func, args) = random.choice(l)
|
||||
# Split by "," and randomly pick one of the arguments
|
||||
value = random.choice(args.split(','))
|
||||
# Remove superfluous characters
|
||||
unclean_value = value
|
||||
value = value.strip(" ").strip("'")
|
||||
# print("Selected argument: [%s]" % value)
|
||||
else:
|
||||
value = attrib_value
|
||||
|
||||
# For each type, define some possible replacement values
|
||||
choices_number = ( \
|
||||
"0", \
|
||||
"11111", \
|
||||
"-128", \
|
||||
"2", \
|
||||
"-1", \
|
||||
"1/3", \
|
||||
"42/0", \
|
||||
"1094861636 idiv 1.0", \
|
||||
"-1123329771506872 idiv 3.8", \
|
||||
"17=$numericRTF", \
|
||||
str(3 + random.randrange(0, 100)), \
|
||||
)
|
||||
|
||||
choices_letter = ( \
|
||||
"P" * (25 * random.randrange(1, 100)), \
|
||||
"%s%s%s%s%s%s", \
|
||||
"foobar", \
|
||||
)
|
||||
|
||||
choices_alnum = ( \
|
||||
"Abc123", \
|
||||
"020F0302020204030204", \
|
||||
"020F0302020204030204" * (random.randrange(5, 20)), \
|
||||
)
|
||||
|
||||
# Fuzz the value
|
||||
if random.choice((True,False)) and value == "":
|
||||
|
||||
# Empty
|
||||
new_value = value
|
||||
|
||||
elif random.choice((True,False)) and value.isdigit():
|
||||
|
||||
# Numbers
|
||||
new_value = random.choice(choices_number)
|
||||
|
||||
elif random.choice((True,False)) and value.isalpha():
|
||||
|
||||
# Letters
|
||||
new_value = random.choice(choices_letter)
|
||||
|
||||
elif random.choice((True,False)) and value.isalnum():
|
||||
|
||||
# Alphanumeric
|
||||
new_value = random.choice(choices_alnum)
|
||||
|
||||
else:
|
||||
|
||||
# Default type
|
||||
new_value = random.choice(choices_alnum + choices_letter + choices_number)
|
||||
|
||||
# If we worked on a substring, apply changes to the whole string
|
||||
if value != attrib_value:
|
||||
# No ' around empty values
|
||||
if new_value != "" and value != "":
|
||||
new_value = "'" + new_value + "'"
|
||||
# Apply changes
|
||||
new_value = attrib_value.replace(unclean_value, new_value)
|
||||
|
||||
# Log something
|
||||
if self.verbose:
|
||||
print("Fuzzing attribute #%i '%s' of tag #%i '%s'" % (rand_attrib_id, rand_attrib, rand_elem_id, rand_elem.tag))
|
||||
|
||||
# Modify the attribute
|
||||
rand_elem.set(rand_attrib, new_value.decode("utf-8"))
|
||||
|
||||
def __del_node_and_children (self):
|
||||
|
||||
""" High-level minimizing mutator
|
||||
Delete a random node and its children (i.e. delete a random tree) """
|
||||
|
||||
self.__del_node(True)
|
||||
|
||||
def __del_node_but_children (self):
|
||||
|
||||
""" High-level minimizing mutator
|
||||
Delete a random node but its children (i.e. link them to the parent of the deleted node) """
|
||||
|
||||
self.__del_node(False)
|
||||
|
||||
def __del_node (self, delete_children):
|
||||
|
||||
""" Called by the __del_node_* mutators """
|
||||
|
||||
# Select a node to modify (but the root one)
|
||||
(rand_elem_id, rand_elem) = self.__pick_element (exclude_root_node = True)
|
||||
|
||||
# If the document includes only a top-level element
|
||||
# Then we can't pick a element (given that "exclude_root_node = True")
|
||||
|
||||
# Is the document deep enough?
|
||||
if rand_elem is None:
|
||||
if self.verbose:
|
||||
print("Can't delete a node: document not deep enough!")
|
||||
return
|
||||
|
||||
# Log something
|
||||
if self.verbose:
|
||||
but_or_and = "and" if delete_children else "but"
|
||||
print("Deleting tag #%i '%s' %s its children" % (rand_elem_id, rand_elem.tag, but_or_and))
|
||||
|
||||
if delete_children is False:
|
||||
# Link children of the random (soon to be deleted) node to its parent
|
||||
for child in rand_elem:
|
||||
rand_elem.getparent().append(child)
|
||||
|
||||
# Remove the node
|
||||
rand_elem.getparent().remove(rand_elem)
|
||||
|
||||
def __del_content (self):
|
||||
|
||||
""" High-level minimizing mutator
|
||||
Delete the attributes and children of a random node """
|
||||
|
||||
# Select a node to modify
|
||||
(rand_elem_id, rand_elem) = self.__pick_element()
|
||||
|
||||
# Log something
|
||||
if self.verbose:
|
||||
print("Reseting tag #%i '%s'" % (rand_elem_id, rand_elem.tag))
|
||||
|
||||
# Reset the node
|
||||
rand_elem.clear()
|
||||
|
||||
def __del_attribute (self):
|
||||
|
||||
""" High-level minimizing mutator
|
||||
Delete a random attribute from a random node """
|
||||
|
||||
# Select a node to modify
|
||||
(rand_elem_id, rand_elem) = self.__pick_element()
|
||||
|
||||
# Get all the attributes
|
||||
attribs = rand_elem.keys()
|
||||
|
||||
# Is there attributes?
|
||||
if len(attribs) < 1:
|
||||
if self.verbose:
|
||||
print("No attribute: can't delete!")
|
||||
return
|
||||
|
||||
# Pick a random attribute
|
||||
rand_attrib_id = random.randint (0, len(attribs) - 1)
|
||||
rand_attrib = attribs[rand_attrib_id]
|
||||
|
||||
# Log something
|
||||
if self.verbose:
|
||||
print("Deleting attribute #%i '%s' of tag #%i '%s'" % (rand_attrib_id, rand_attrib, rand_elem_id, rand_elem.tag))
|
||||
|
||||
# Delete the attribute
|
||||
rand_elem.attrib.pop(rand_attrib)
|
||||
|
||||
def mutate (self, min=1, max=5):
|
||||
|
||||
""" Execute some high-level mutators between $min and $max times, then some medium-level ones """
|
||||
|
||||
# High-level mutation
|
||||
self.__exec_among(self, self.hl_mutators_all, min, max)
|
||||
|
||||
37
python_mutators/common.py
Normal file
37
python_mutators/common.py
Normal file
@ -0,0 +1,37 @@
|
||||
#!/usr/bin/env python
|
||||
# encoding: utf-8
|
||||
'''
|
||||
Module containing functions shared between multiple AFL modules
|
||||
|
||||
@author: Christian Holler (:decoder)
|
||||
|
||||
@license:
|
||||
|
||||
This Source Code Form is subject to the terms of the Mozilla Public
|
||||
License, v. 2.0. If a copy of the MPL was not distributed with this
|
||||
file, You can obtain one at http://mozilla.org/MPL/2.0/.
|
||||
|
||||
@contact: choller@mozilla.com
|
||||
'''
|
||||
|
||||
from __future__ import print_function
|
||||
import random
|
||||
import os
|
||||
import re
|
||||
|
||||
def randel(l):
|
||||
if not l:
|
||||
return None
|
||||
return l[random.randint(0,len(l)-1)]
|
||||
|
||||
def randel_pop(l):
|
||||
if not l:
|
||||
return None
|
||||
return l.pop(random.randint(0,len(l)-1))
|
||||
|
||||
def write_exc_example(data, exc):
|
||||
exc_name = re.sub(r'[^a-zA-Z0-9]', '_', repr(exc))
|
||||
|
||||
if not os.path.exists(exc_name):
|
||||
with open(exc_name, 'w') as f:
|
||||
f.write(data)
|
||||
103
python_mutators/example.py
Normal file
103
python_mutators/example.py
Normal file
@ -0,0 +1,103 @@
|
||||
#!/usr/bin/env python
|
||||
# encoding: utf-8
|
||||
'''
|
||||
Example Python Module for AFLFuzz
|
||||
|
||||
@author: Christian Holler (:decoder)
|
||||
|
||||
@license:
|
||||
|
||||
This Source Code Form is subject to the terms of the Mozilla Public
|
||||
License, v. 2.0. If a copy of the MPL was not distributed with this
|
||||
file, You can obtain one at http://mozilla.org/MPL/2.0/.
|
||||
|
||||
@contact: choller@mozilla.com
|
||||
'''
|
||||
|
||||
import random
|
||||
|
||||
def init(seed):
|
||||
'''
|
||||
Called once when AFLFuzz starts up. Used to seed our RNG.
|
||||
|
||||
@type seed: int
|
||||
@param seed: A 32-bit random value
|
||||
'''
|
||||
random.seed(seed)
|
||||
return 0
|
||||
|
||||
def fuzz(buf, add_buf):
|
||||
'''
|
||||
Called per fuzzing iteration.
|
||||
|
||||
@type buf: bytearray
|
||||
@param buf: The buffer that should be mutated.
|
||||
|
||||
@type add_buf: bytearray
|
||||
@param add_buf: A second buffer that can be used as mutation source.
|
||||
|
||||
@rtype: bytearray
|
||||
@return: A new bytearray containing the mutated data
|
||||
'''
|
||||
ret = bytearray(buf)
|
||||
# Do something interesting with ret
|
||||
|
||||
return ret
|
||||
|
||||
# Uncomment and implement the following methods if you want to use a custom
|
||||
# trimming algorithm. See also the documentation for a better API description.
|
||||
|
||||
# def init_trim(buf):
|
||||
# '''
|
||||
# Called per trimming iteration.
|
||||
#
|
||||
# @type buf: bytearray
|
||||
# @param buf: The buffer that should be trimmed.
|
||||
#
|
||||
# @rtype: int
|
||||
# @return: The maximum number of trimming steps.
|
||||
# '''
|
||||
# global ...
|
||||
#
|
||||
# # Initialize global variables
|
||||
#
|
||||
# # Figure out how many trimming steps are possible.
|
||||
# # If this is not possible for your trimming, you can
|
||||
# # return 1 instead and always return 0 in post_trim
|
||||
# # until you are done (then you return 1).
|
||||
#
|
||||
# return steps
|
||||
#
|
||||
# def trim():
|
||||
# '''
|
||||
# Called per trimming iteration.
|
||||
#
|
||||
# @rtype: bytearray
|
||||
# @return: A new bytearray containing the trimmed data.
|
||||
# '''
|
||||
# global ...
|
||||
#
|
||||
# # Implement the actual trimming here
|
||||
#
|
||||
# return bytearray(...)
|
||||
#
|
||||
# def post_trim(success):
|
||||
# '''
|
||||
# Called after each trimming operation.
|
||||
#
|
||||
# @type success: bool
|
||||
# @param success: Indicates if the last trim operation was successful.
|
||||
#
|
||||
# @rtype: int
|
||||
# @return: The next trim index (0 to max number of steps) where max
|
||||
# number of steps indicates the trimming is done.
|
||||
# '''
|
||||
# global ...
|
||||
#
|
||||
# if not success:
|
||||
# # Restore last known successful input, determine next index
|
||||
# else:
|
||||
# # Just determine the next index, based on what was successfully
|
||||
# # removed in the last step
|
||||
#
|
||||
# return next_index
|
||||
59
python_mutators/simple-chunk-replace.py
Normal file
59
python_mutators/simple-chunk-replace.py
Normal file
@ -0,0 +1,59 @@
|
||||
#!/usr/bin/env python
|
||||
# encoding: utf-8
|
||||
'''
|
||||
Simple Chunk Cross-Over Replacement Module for AFLFuzz
|
||||
|
||||
@author: Christian Holler (:decoder)
|
||||
|
||||
@license:
|
||||
|
||||
This Source Code Form is subject to the terms of the Mozilla Public
|
||||
License, v. 2.0. If a copy of the MPL was not distributed with this
|
||||
file, You can obtain one at http://mozilla.org/MPL/2.0/.
|
||||
|
||||
@contact: choller@mozilla.com
|
||||
'''
|
||||
|
||||
import random
|
||||
|
||||
def init(seed):
|
||||
'''
|
||||
Called once when AFLFuzz starts up. Used to seed our RNG.
|
||||
|
||||
@type seed: int
|
||||
@param seed: A 32-bit random value
|
||||
'''
|
||||
# Seed our RNG
|
||||
random.seed(seed)
|
||||
return 0
|
||||
|
||||
def fuzz(buf, add_buf):
|
||||
'''
|
||||
Called per fuzzing iteration.
|
||||
|
||||
@type buf: bytearray
|
||||
@param buf: The buffer that should be mutated.
|
||||
|
||||
@type add_buf: bytearray
|
||||
@param add_buf: A second buffer that can be used as mutation source.
|
||||
|
||||
@rtype: bytearray
|
||||
@return: A new bytearray containing the mutated data
|
||||
'''
|
||||
# Make a copy of our input buffer for returning
|
||||
ret = bytearray(buf)
|
||||
|
||||
# Take a random fragment length between 2 and 32 (or less if add_buf is shorter)
|
||||
fragment_len = random.randint(1, min(len(add_buf), 32))
|
||||
|
||||
# Determine a random source index where to take the data chunk from
|
||||
rand_src_idx = random.randint(0, len(add_buf) - fragment_len)
|
||||
|
||||
# Determine a random destination index where to put the data chunk
|
||||
rand_dst_idx = random.randint(0, len(buf))
|
||||
|
||||
# Make the chunk replacement
|
||||
ret[rand_dst_idx:rand_dst_idx + fragment_len] = add_buf[rand_src_idx:rand_src_idx + fragment_len]
|
||||
|
||||
# Return data
|
||||
return ret
|
||||
117
python_mutators/wrapper_afl_min.py
Normal file
117
python_mutators/wrapper_afl_min.py
Normal file
@ -0,0 +1,117 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
from XmlMutatorMin import XmlMutatorMin
|
||||
|
||||
# Default settings (production mode)
|
||||
|
||||
__mutator__ = None
|
||||
__seed__ = "RANDOM"
|
||||
__log__ = False
|
||||
__log_file__ = "wrapper.log"
|
||||
|
||||
# AFL functions
|
||||
|
||||
def log(text):
|
||||
"""
|
||||
Logger
|
||||
"""
|
||||
|
||||
global __seed__
|
||||
global __log__
|
||||
global __log_file__
|
||||
|
||||
if __log__:
|
||||
with open(__log_file__, "a") as logf:
|
||||
logf.write("[%s] %s\n" % (__seed__, text))
|
||||
|
||||
def init(seed):
|
||||
"""
|
||||
Called once when AFL starts up. Seed is used to identify the AFL instance in log files
|
||||
"""
|
||||
|
||||
global __mutator__
|
||||
global __seed__
|
||||
|
||||
# Get the seed
|
||||
__seed__ = seed
|
||||
|
||||
# Create a global mutation class
|
||||
try:
|
||||
__mutator__ = XmlMutatorMin(__seed__, verbose=__log__)
|
||||
log("init(): Mutator created")
|
||||
except RuntimeError as e:
|
||||
log("init(): Can't create mutator: %s" % e.message)
|
||||
|
||||
def fuzz(buf, add_buf):
|
||||
"""
|
||||
Called for each fuzzing iteration.
|
||||
"""
|
||||
|
||||
global __mutator__
|
||||
|
||||
# Do we have a working mutator object?
|
||||
if __mutator__ is None:
|
||||
log("fuzz(): Can't fuzz, no mutator available")
|
||||
return buf
|
||||
|
||||
# Try to use the AFL buffer
|
||||
via_buffer = True
|
||||
|
||||
# Interpret the AFL buffer (an array of bytes) as a string
|
||||
if via_buffer:
|
||||
try:
|
||||
buf_str = str(buf)
|
||||
log("fuzz(): AFL buffer converted to a string")
|
||||
except:
|
||||
via_buffer = False
|
||||
log("fuzz(): Can't convert AFL buffer to a string")
|
||||
|
||||
# Load XML from the AFL string
|
||||
if via_buffer:
|
||||
try:
|
||||
__mutator__.init_from_string(buf_str)
|
||||
log("fuzz(): Mutator successfully initialized with AFL buffer (%d bytes)" % len(buf_str))
|
||||
except:
|
||||
via_buffer = False
|
||||
log("fuzz(): Can't initialize mutator with AFL buffer")
|
||||
|
||||
# If init from AFL buffer wasn't succesful
|
||||
if not via_buffer:
|
||||
log("fuzz(): Returning unmodified AFL buffer")
|
||||
return buf
|
||||
|
||||
# Sucessful initialization -> mutate
|
||||
try:
|
||||
__mutator__.mutate(max=5)
|
||||
log("fuzz(): Input mutated")
|
||||
except:
|
||||
log("fuzz(): Can't mutate input => returning buf")
|
||||
return buf
|
||||
|
||||
# Convert mutated data to a array of bytes
|
||||
try:
|
||||
data = bytearray(__mutator__.save_to_string())
|
||||
log("fuzz(): Mutated data converted as bytes")
|
||||
except:
|
||||
log("fuzz(): Can't convert mutated data to bytes => returning buf")
|
||||
return buf
|
||||
|
||||
# Everything went fine, returning mutated content
|
||||
log("fuzz(): Returning %d bytes" % len(data))
|
||||
return data
|
||||
|
||||
# Main (for debug)
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
__log__ = True
|
||||
__log_file__ = "/dev/stdout"
|
||||
__seed__ = "RANDOM"
|
||||
|
||||
init(__seed__)
|
||||
|
||||
in_1 = bytearray("<foo ddd='eeee'>ffff<a b='c' d='456' eee='ffffff'>zzzzzzzzzzzz</a><b yyy='YYY' zzz='ZZZ'></b></foo>")
|
||||
in_2 = bytearray("<abc abc123='456' abcCBA='ppppppppppppppppppppppppppppp'/>")
|
||||
out = fuzz(in_1, in_2)
|
||||
print(out)
|
||||
|
||||
@ -1,11 +1,8 @@
|
||||
=========================================================
|
||||
High-performance binary-only instrumentation for afl-fuzz
|
||||
=========================================================
|
||||
# High-performance binary-only instrumentation for afl-fuzz
|
||||
|
||||
(See ../docs/README for the general instruction manual.)
|
||||
|
||||
1) Introduction
|
||||
---------------
|
||||
## 1) Introduction
|
||||
|
||||
The code in this directory allows you to build a standalone feature that
|
||||
leverages the QEMU "user emulation" mode and allows callers to obtain
|
||||
@ -16,14 +13,15 @@ with afl-gcc.
|
||||
The usual performance cost is 2-5x, which is considerably better than
|
||||
seen so far in experiments with tools such as DynamoRIO and PIN.
|
||||
|
||||
The idea and much of the implementation comes from Andrew Griffiths.
|
||||
The idea and much of the initial implementation comes from Andrew Griffiths.
|
||||
The actual implementation on QEMU 3 (shipped with afl++) is from
|
||||
Andrea Fioraldi. Special thanks to abiondo that re-enabled TCG chaining.
|
||||
|
||||
2) How to use
|
||||
-------------
|
||||
## 2) How to use
|
||||
|
||||
The feature is implemented with a fairly simple patch to QEMU 2.10.0. The
|
||||
simplest way to build it is to run ./build_qemu_support.sh. The script will
|
||||
download, configure, and compile the QEMU binary for you.
|
||||
The feature is implemented with a patch to QEMU 3.1.0. The simplest way
|
||||
to build it is to run ./build_qemu_support.sh. The script will download,
|
||||
configure, and compile the QEMU binary for you.
|
||||
|
||||
QEMU is a big project, so this will take a while, and you may have to
|
||||
resolve a couple of dependencies (most notably, you will definitely need
|
||||
@ -46,8 +44,26 @@ Note: if you want the QEMU helper to be installed on your system for all
|
||||
users, you need to build it before issuing 'make install' in the parent
|
||||
directory.
|
||||
|
||||
3) Notes on linking
|
||||
-------------------
|
||||
## 3) Options
|
||||
|
||||
There is ./libcompcov/ which implements laf-intel (splitting memcmp,
|
||||
strncmp, etc. to make these conditions easier solvable by afl-fuzz).
|
||||
Highly recommended.
|
||||
|
||||
The option that enables QEMU CompareCoverage is AFL_COMPCOV_LEVEL.
|
||||
AFL_COMPCOV_LEVEL=1 is to instrument comparisons with only immediate
|
||||
values / read-only memory. AFL_COMPCOV_LEVEL=2 instruments all
|
||||
comparison instructions and memory comparison functions when libcompcov
|
||||
is preloaded. Comparison instructions are currently instrumented only
|
||||
on the x86 and x86_64 targets.
|
||||
|
||||
Another option is the environment variable AFL_ENTRYPOINT which allows
|
||||
move the forkserver to a different part, e.g. just before the file is
|
||||
opened (e.g. way after command line parsing and config file loading, etc)
|
||||
which can be a huge speed improvement. Note that the specified address
|
||||
must be an address of a basic block.
|
||||
|
||||
## 4) Notes on linking
|
||||
|
||||
The feature is supported only on Linux. Supporting BSD may amount to porting
|
||||
the changes made to linux-user/elfload.c and applying them to
|
||||
@ -68,8 +84,7 @@ practice, this means two things:
|
||||
Setting AFL_INST_LIBS=1 can be used to circumvent the .text detection logic
|
||||
and instrument every basic block encountered.
|
||||
|
||||
4) Benchmarking
|
||||
---------------
|
||||
## 5) Benchmarking
|
||||
|
||||
If you want to compare the performance of the QEMU instrumentation with that of
|
||||
afl-gcc compiled code against the same target, you need to build the
|
||||
@ -84,8 +99,7 @@ Comparative measurements of execution speed or instrumentation coverage will be
|
||||
fairly meaningless if the optimization levels or instrumentation scopes don't
|
||||
match.
|
||||
|
||||
5) Gotchas, feedback, bugs
|
||||
--------------------------
|
||||
## 6) Gotchas, feedback, bugs
|
||||
|
||||
If you need to fix up checksums or do other cleanup on mutated test cases, see
|
||||
experimental/post_library/ for a viable solution.
|
||||
@ -106,20 +120,18 @@ with -march=core2, can help.
|
||||
Beyond that, this is an early-stage mechanism, so fields reports are welcome.
|
||||
You can send them to <afl-users@googlegroups.com>.
|
||||
|
||||
6) Alternatives: static rewriting
|
||||
---------------------------------
|
||||
## 7) Alternatives: static rewriting
|
||||
|
||||
Statically rewriting binaries just once, instead of attempting to translate
|
||||
them at run time, can be a faster alternative. That said, static rewriting is
|
||||
fraught with peril, because it depends on being able to properly and fully model
|
||||
program control flow without actually executing each and every code path.
|
||||
|
||||
If you want to experiment with this mode of operation, there is a module
|
||||
contributed by Aleksandar Nikolich:
|
||||
The best implementation is this one:
|
||||
|
||||
https://github.com/vrtadmin/moflow/tree/master/afl-dyninst
|
||||
https://groups.google.com/forum/#!topic/afl-users/HlSQdbOTlpg
|
||||
https://github.com/vanhauser-thc/afl-dyninst
|
||||
|
||||
At this point, the author reports the possibility of hiccups with stripped
|
||||
binaries. That said, if we can get it to be comparably reliable to QEMU, we may
|
||||
decide to switch to this mode, but I had no time to play with it yet.
|
||||
The issue however is Dyninst which is not rewriting the binaries so that
|
||||
they run stable. a lot of crashes happen, especially in C++ programs that
|
||||
use throw/catch. Try it first, and if it works for you be happy as it is
|
||||
2-3x as fast as qemu_mode.
|
||||
@ -3,10 +3,17 @@
|
||||
# american fuzzy lop - QEMU build script
|
||||
# --------------------------------------
|
||||
#
|
||||
# Written by Andrew Griffiths <agriffiths@google.com> and
|
||||
# Michal Zalewski <lcamtuf@google.com>
|
||||
# Originally written by Andrew Griffiths <agriffiths@google.com> and
|
||||
# Michal Zalewski <lcamtuf@google.com>
|
||||
#
|
||||
# TCG instrumentation and block chaining support by Andrea Biondo
|
||||
# <andrea.biondo965@gmail.com>
|
||||
#
|
||||
# QEMU 3.1.0 port, TCG thread-safety, CompareCoverage and NeverZero
|
||||
# counters by Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
#
|
||||
# Copyright 2015, 2016, 2017 Google Inc. All rights reserved.
|
||||
# Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -105,7 +112,8 @@ if [ "$CKSUM" = "$QEMU_SHA384" ]; then
|
||||
|
||||
else
|
||||
|
||||
echo "[-] Error: signature mismatch on $ARCHIVE (perhaps download error?)."
|
||||
echo "[-] Error: signature mismatch on $ARCHIVE (perhaps download error?), removing archive ..."
|
||||
rm -f "$ARCHIVE"
|
||||
exit 1
|
||||
|
||||
fi
|
||||
@ -133,7 +141,7 @@ patch -p1 <../patches/cpu-exec.diff || exit 1
|
||||
patch -p1 <../patches/syscall.diff || exit 1
|
||||
patch -p1 <../patches/translate-all.diff || exit 1
|
||||
patch -p1 <../patches/tcg.diff || exit 1
|
||||
patch -p1 <../patches/elfload2.diff || exit 1
|
||||
patch -p1 <../patches/i386-translate.diff || exit 1
|
||||
|
||||
echo "[+] Patching done."
|
||||
|
||||
@ -193,6 +201,8 @@ if [ "$ORIG_CPU_TARGET" = "" ]; then
|
||||
echo "[+] Instrumentation tests passed. "
|
||||
echo "[+] All set, you can now use the -Q mode in afl-fuzz!"
|
||||
|
||||
cd qemu_mode || exit 1
|
||||
|
||||
else
|
||||
|
||||
echo "[!] Note: can't test instrumentation when CPU_TARGET set."
|
||||
@ -200,4 +210,9 @@ else
|
||||
|
||||
fi
|
||||
|
||||
echo "[+] Building libcompcov ..."
|
||||
make -C libcompcov
|
||||
echo "[+] libcompcov ready"
|
||||
echo "[+] All done for qemu_mode, enjoy!"
|
||||
|
||||
exit 0
|
||||
|
||||
42
qemu_mode/libcompcov/Makefile
Normal file
42
qemu_mode/libcompcov/Makefile
Normal file
@ -0,0 +1,42 @@
|
||||
#
|
||||
# american fuzzy lop - libcompcov
|
||||
# --------------------------------
|
||||
#
|
||||
# Written by Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
#
|
||||
# Copyright 2019 Andrea Fioraldi. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at:
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
|
||||
PREFIX ?= /usr/local
|
||||
HELPER_PATH = $(PREFIX)/lib/afl
|
||||
|
||||
VERSION = $(shell grep '^\#define VERSION ' ../config.h | cut -d '"' -f2)
|
||||
|
||||
CFLAGS ?= -O3 -funroll-loops -I ../../include/
|
||||
CFLAGS += -Wall -Wno-unused-result -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign
|
||||
LDFLAGS += -ldl
|
||||
|
||||
all: libcompcov.so compcovtest
|
||||
|
||||
libcompcov.so: libcompcov.so.c ../../config.h
|
||||
$(CC) $(CFLAGS) -shared -fPIC $< -o ../../$@ $(LDFLAGS)
|
||||
|
||||
.NOTPARALLEL: clean
|
||||
|
||||
clean:
|
||||
rm -f *.o *.so *~ a.out core core.[1-9][0-9]*
|
||||
rm -f ../../libcompcov.so compcovtest
|
||||
|
||||
compcovtest: compcovtest.cc
|
||||
$(CXX) $< -o $@
|
||||
|
||||
install: all
|
||||
install -m 755 ../../libcompcov.so $${DESTDIR}$(HELPER_PATH)
|
||||
install -m 644 README.compcov $${DESTDIR}$(HELPER_PATH)
|
||||
|
||||
37
qemu_mode/libcompcov/README.md
Normal file
37
qemu_mode/libcompcov/README.md
Normal file
@ -0,0 +1,37 @@
|
||||
# strcmp() / memcmp() CompareCoverage library for afl++ QEMU
|
||||
|
||||
Written by Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
This Linux-only companion library allows you to instrument `strcmp()`, `memcmp()`,
|
||||
and related functions to log the CompareCoverage of these libcalls.
|
||||
|
||||
Use this with caution. While this can speedup a lot the bypass of hard
|
||||
branch conditions it can also waste a lot of time and take up unnecessary space
|
||||
in the shared memory when logging the coverage related to functions that
|
||||
doesn't process input-related data.
|
||||
|
||||
To use the library, you *need* to make sure that your fuzzing target is linked
|
||||
dynamically and make use of strcmp(), memcmp(), and related functions.
|
||||
For optimized binaries this is an issue, those functions are often inlined
|
||||
and this module is not capable to log the coverage in this case.
|
||||
|
||||
If you have the source code of the fuzzing target you should nto use this
|
||||
library and QEMU but build it with afl-clang-fast and the laf-intel options.
|
||||
|
||||
To use this library make sure to preload it with AFL_PRELOAD.
|
||||
|
||||
```
|
||||
export AFL_PRELOAD=/path/to/libcompcov.so
|
||||
export AFL_COMPCOV_LEVEL=1
|
||||
|
||||
afl-fuzz -Q -i input -o output <your options> -- <target args>
|
||||
```
|
||||
|
||||
The AFL_COMPCOV_LEVEL tells to QEMU and libcompcov how to log comaprisons.
|
||||
Level 1 logs just comparison with immediates / read-only memory and level 2
|
||||
logs all the comparisons.
|
||||
|
||||
The library make use of https://github.com/ouadev/proc_maps_parser and so it is
|
||||
Linux specific. However this is not a strict dependency, other UNIX operating
|
||||
systems can be supported simply replacing the code related to the
|
||||
/proc/self/maps parsing.
|
||||
65
qemu_mode/libcompcov/compcovtest.cc
Normal file
65
qemu_mode/libcompcov/compcovtest.cc
Normal file
@ -0,0 +1,65 @@
|
||||
/////////////////////////////////////////////////////////////////////////
|
||||
//
|
||||
// Author: Mateusz Jurczyk (mjurczyk@google.com)
|
||||
//
|
||||
// Copyright 2019 Google LLC
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// https://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
//
|
||||
|
||||
// solution: echo -ne 'The quick brown fox jumps over the lazy
|
||||
// dog\xbe\xba\xfe\xca\xbe\xba\xfe\xca\xde\xc0\xad\xde\xef\xbe' | ./compcovtest
|
||||
|
||||
#include <cstdint>
|
||||
#include <cstdio>
|
||||
#include <cstdlib>
|
||||
#include <cstring>
|
||||
|
||||
int main() {
|
||||
|
||||
char buffer[44] = {/* zero padding */};
|
||||
fread(buffer, 1, sizeof(buffer) - 1, stdin);
|
||||
|
||||
if (memcmp(&buffer[0], "The quick brown fox ", 20) != 0 ||
|
||||
strncmp(&buffer[20], "jumps over ", 11) != 0 ||
|
||||
strcmp(&buffer[31], "the lazy dog") != 0) {
|
||||
|
||||
return 1;
|
||||
|
||||
}
|
||||
|
||||
uint64_t x = 0;
|
||||
fread(&x, sizeof(x), 1, stdin);
|
||||
if (x != 0xCAFEBABECAFEBABE) { return 2; }
|
||||
|
||||
uint32_t y = 0;
|
||||
fread(&y, sizeof(y), 1, stdin);
|
||||
if (y != 0xDEADC0DE) { return 3; }
|
||||
|
||||
uint16_t z = 0;
|
||||
fread(&z, sizeof(z), 1, stdin);
|
||||
|
||||
switch (z) {
|
||||
|
||||
case 0xBEEF: break;
|
||||
|
||||
default: return 4;
|
||||
|
||||
}
|
||||
|
||||
printf("Puzzle solved, congrats!\n");
|
||||
abort();
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
348
qemu_mode/libcompcov/libcompcov.so.c
Normal file
348
qemu_mode/libcompcov/libcompcov.so.c
Normal file
@ -0,0 +1,348 @@
|
||||
/*
|
||||
|
||||
american fuzzy lop++ - strcmp() / memcmp() CompareCoverage library
|
||||
------------------------------------------------------------------
|
||||
|
||||
Written and maintained by Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This Linux-only companion library allows you to instrument strcmp(),
|
||||
memcmp(), and related functions to get compare coverage.
|
||||
See README.compcov for more info.
|
||||
|
||||
*/
|
||||
|
||||
#define _GNU_SOURCE
|
||||
#include <dlfcn.h>
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
#include <ctype.h>
|
||||
#include <sys/types.h>
|
||||
#include <sys/shm.h>
|
||||
|
||||
#include "types.h"
|
||||
#include "config.h"
|
||||
|
||||
#include "pmparser.h"
|
||||
|
||||
#ifndef __linux__
|
||||
#error "Sorry, this library is Linux-specific for now!"
|
||||
#endif /* !__linux__ */
|
||||
|
||||
/* Change this value to tune the compare coverage */
|
||||
|
||||
#define MAX_CMP_LENGTH 32
|
||||
|
||||
static void *__compcov_code_start, *__compcov_code_end;
|
||||
|
||||
static u8* __compcov_afl_map;
|
||||
|
||||
static u32 __compcov_level;
|
||||
|
||||
static int (*__libc_strcmp)(const char*, const char*);
|
||||
static int (*__libc_strncmp)(const char*, const char*, size_t);
|
||||
static int (*__libc_strcasecmp)(const char*, const char*);
|
||||
static int (*__libc_strncasecmp)(const char*, const char*, size_t);
|
||||
static int (*__libc_memcmp)(const void*, const void*, size_t);
|
||||
|
||||
static int debug_fd = -1;
|
||||
|
||||
#define MAX_MAPPINGS 1024
|
||||
|
||||
static struct mapping { void *st, *en; } __compcov_ro[MAX_MAPPINGS];
|
||||
|
||||
static u32 __compcov_ro_cnt;
|
||||
|
||||
/* Check an address against the list of read-only mappings. */
|
||||
|
||||
static u8 __compcov_is_ro(const void* ptr) {
|
||||
|
||||
u32 i;
|
||||
|
||||
for (i = 0; i < __compcov_ro_cnt; i++)
|
||||
if (ptr >= __compcov_ro[i].st && ptr <= __compcov_ro[i].en) return 1;
|
||||
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
static size_t __strlen2(const char* s1, const char* s2, size_t max_length) {
|
||||
|
||||
// from https://github.com/googleprojectzero/CompareCoverage
|
||||
|
||||
size_t len = 0;
|
||||
for (; len < max_length && s1[len] != '\0' && s2[len] != '\0'; len++) {}
|
||||
return len;
|
||||
|
||||
}
|
||||
|
||||
/* Identify the binary boundaries in the memory mapping */
|
||||
|
||||
static void __compcov_load(void) {
|
||||
|
||||
__libc_strcmp = dlsym(RTLD_NEXT, "strcmp");
|
||||
__libc_strncmp = dlsym(RTLD_NEXT, "strncmp");
|
||||
__libc_strcasecmp = dlsym(RTLD_NEXT, "strcasecmp");
|
||||
__libc_strncasecmp = dlsym(RTLD_NEXT, "strncasecmp");
|
||||
__libc_memcmp = dlsym(RTLD_NEXT, "memcmp");
|
||||
|
||||
if (getenv("AFL_QEMU_COMPCOV")) { __compcov_level = 1; }
|
||||
if (getenv("AFL_COMPCOV_LEVEL")) {
|
||||
|
||||
__compcov_level = atoi(getenv("AFL_COMPCOV_LEVEL"));
|
||||
|
||||
}
|
||||
|
||||
char* id_str = getenv(SHM_ENV_VAR);
|
||||
int shm_id;
|
||||
|
||||
if (id_str) {
|
||||
|
||||
shm_id = atoi(id_str);
|
||||
__compcov_afl_map = shmat(shm_id, NULL, 0);
|
||||
|
||||
if (__compcov_afl_map == (void*)-1) exit(1);
|
||||
|
||||
} else {
|
||||
|
||||
__compcov_afl_map = calloc(1, MAP_SIZE);
|
||||
|
||||
}
|
||||
|
||||
if (getenv("AFL_INST_LIBS")) {
|
||||
|
||||
__compcov_code_start = (void*)0;
|
||||
__compcov_code_end = (void*)-1;
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
char* bin_name = getenv("AFL_COMPCOV_BINNAME");
|
||||
|
||||
procmaps_iterator* maps = pmparser_parse(-1);
|
||||
procmaps_struct* maps_tmp = NULL;
|
||||
|
||||
while ((maps_tmp = pmparser_next(maps)) != NULL) {
|
||||
|
||||
/* If AFL_COMPCOV_BINNAME is not set pick the first executable segment */
|
||||
if (!bin_name || strstr(maps_tmp->pathname, bin_name) != NULL) {
|
||||
|
||||
if (maps_tmp->is_x) {
|
||||
|
||||
if (!__compcov_code_start) __compcov_code_start = maps_tmp->addr_start;
|
||||
if (!__compcov_code_end) __compcov_code_end = maps_tmp->addr_end;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if ((maps_tmp->is_w && !maps_tmp->is_r) || __compcov_ro_cnt == MAX_MAPPINGS)
|
||||
continue;
|
||||
|
||||
__compcov_ro[__compcov_ro_cnt].st = maps_tmp->addr_start;
|
||||
__compcov_ro[__compcov_ro_cnt].en = maps_tmp->addr_end;
|
||||
|
||||
}
|
||||
|
||||
pmparser_free(maps);
|
||||
|
||||
}
|
||||
|
||||
static void __compcov_trace(u64 cur_loc, const u8* v0, const u8* v1, size_t n) {
|
||||
|
||||
size_t i;
|
||||
|
||||
if (debug_fd != 1) {
|
||||
|
||||
char debugbuf[4096];
|
||||
snprintf(debugbuf, sizeof(debugbuf), "0x%llx %s %s %lu\n", cur_loc,
|
||||
v0 == NULL ? "(null)" : (char*)v0,
|
||||
v1 == NULL ? "(null)" : (char*)v1, n);
|
||||
write(debug_fd, debugbuf, strlen(debugbuf));
|
||||
|
||||
}
|
||||
|
||||
for (i = 0; i < n && v0[i] == v1[i]; ++i) {
|
||||
|
||||
__compcov_afl_map[cur_loc + i]++;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* Check an address against the list of read-only mappings. */
|
||||
|
||||
static u8 __compcov_is_in_bound(const void* ptr) {
|
||||
|
||||
return ptr >= __compcov_code_start && ptr < __compcov_code_end;
|
||||
|
||||
}
|
||||
|
||||
/* Replacements for strcmp(), memcmp(), and so on. Note that these will be used
|
||||
only if the target is compiled with -fno-builtins and linked dynamically. */
|
||||
|
||||
#undef strcmp
|
||||
|
||||
int strcmp(const char* str1, const char* str2) {
|
||||
|
||||
void* retaddr = __builtin_return_address(0);
|
||||
|
||||
if (__compcov_is_in_bound(retaddr) &&
|
||||
!(__compcov_level < 2 && !__compcov_is_ro(str1) &&
|
||||
!__compcov_is_ro(str2))) {
|
||||
|
||||
size_t n = __strlen2(str1, str2, MAX_CMP_LENGTH + 1);
|
||||
|
||||
if (n <= MAX_CMP_LENGTH) {
|
||||
|
||||
u64 cur_loc = (u64)retaddr;
|
||||
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
|
||||
cur_loc &= MAP_SIZE - 1;
|
||||
|
||||
__compcov_trace(cur_loc, str1, str2, n);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
return __libc_strcmp(str1, str2);
|
||||
|
||||
}
|
||||
|
||||
#undef strncmp
|
||||
|
||||
int strncmp(const char* str1, const char* str2, size_t len) {
|
||||
|
||||
void* retaddr = __builtin_return_address(0);
|
||||
|
||||
if (__compcov_is_in_bound(retaddr) &&
|
||||
!(__compcov_level < 2 && !__compcov_is_ro(str1) &&
|
||||
!__compcov_is_ro(str2))) {
|
||||
|
||||
size_t n = __strlen2(str1, str2, MAX_CMP_LENGTH + 1);
|
||||
n = MIN(n, len);
|
||||
|
||||
if (n <= MAX_CMP_LENGTH) {
|
||||
|
||||
u64 cur_loc = (u64)retaddr;
|
||||
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
|
||||
cur_loc &= MAP_SIZE - 1;
|
||||
|
||||
__compcov_trace(cur_loc, str1, str2, n);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
return __libc_strncmp(str1, str2, len);
|
||||
|
||||
}
|
||||
|
||||
#undef strcasecmp
|
||||
|
||||
int strcasecmp(const char* str1, const char* str2) {
|
||||
|
||||
void* retaddr = __builtin_return_address(0);
|
||||
|
||||
if (__compcov_is_in_bound(retaddr) &&
|
||||
!(__compcov_level < 2 && !__compcov_is_ro(str1) &&
|
||||
!__compcov_is_ro(str2))) {
|
||||
|
||||
/* Fallback to strcmp, maybe improve in future */
|
||||
|
||||
size_t n = __strlen2(str1, str2, MAX_CMP_LENGTH + 1);
|
||||
|
||||
if (n <= MAX_CMP_LENGTH) {
|
||||
|
||||
u64 cur_loc = (u64)retaddr;
|
||||
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
|
||||
cur_loc &= MAP_SIZE - 1;
|
||||
|
||||
__compcov_trace(cur_loc, str1, str2, n);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
return __libc_strcasecmp(str1, str2);
|
||||
|
||||
}
|
||||
|
||||
#undef strncasecmp
|
||||
|
||||
int strncasecmp(const char* str1, const char* str2, size_t len) {
|
||||
|
||||
void* retaddr = __builtin_return_address(0);
|
||||
|
||||
if (__compcov_is_in_bound(retaddr) &&
|
||||
!(__compcov_level < 2 && !__compcov_is_ro(str1) &&
|
||||
!__compcov_is_ro(str2))) {
|
||||
|
||||
/* Fallback to strncmp, maybe improve in future */
|
||||
|
||||
size_t n = __strlen2(str1, str2, MAX_CMP_LENGTH + 1);
|
||||
n = MIN(n, len);
|
||||
|
||||
if (n <= MAX_CMP_LENGTH) {
|
||||
|
||||
u64 cur_loc = (u64)retaddr;
|
||||
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
|
||||
cur_loc &= MAP_SIZE - 1;
|
||||
|
||||
__compcov_trace(cur_loc, str1, str2, n);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
return __libc_strncasecmp(str1, str2, len);
|
||||
|
||||
}
|
||||
|
||||
#undef memcmp
|
||||
|
||||
int memcmp(const void* mem1, const void* mem2, size_t len) {
|
||||
|
||||
void* retaddr = __builtin_return_address(0);
|
||||
|
||||
if (__compcov_is_in_bound(retaddr) &&
|
||||
!(__compcov_level < 2 && !__compcov_is_ro(mem1) &&
|
||||
!__compcov_is_ro(mem2))) {
|
||||
|
||||
size_t n = len;
|
||||
|
||||
if (n <= MAX_CMP_LENGTH) {
|
||||
|
||||
u64 cur_loc = (u64)retaddr;
|
||||
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
|
||||
cur_loc &= MAP_SIZE - 1;
|
||||
|
||||
__compcov_trace(cur_loc, mem1, mem2, n);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
return __libc_memcmp(mem1, mem2, len);
|
||||
|
||||
}
|
||||
|
||||
/* Init code to open init the library. */
|
||||
|
||||
__attribute__((constructor)) void __compcov_init(void) {
|
||||
|
||||
if (getenv("AFL_QEMU_COMPCOV_DEBUG") != NULL)
|
||||
debug_fd =
|
||||
open("compcov.debug", O_WRONLY | O_CREAT | O_TRUNC | O_SYNC, 0644);
|
||||
|
||||
__compcov_load();
|
||||
|
||||
}
|
||||
|
||||
326
qemu_mode/libcompcov/pmparser.h
Normal file
326
qemu_mode/libcompcov/pmparser.h
Normal file
@ -0,0 +1,326 @@
|
||||
/*
|
||||
@Author : ouadimjamal@gmail.com
|
||||
@date : December 2015
|
||||
|
||||
Permission to use, copy, modify, distribute, and sell this software and its
|
||||
documentation for any purpose is hereby granted without fee, provided that
|
||||
the above copyright notice appear in all copies and that both that
|
||||
copyright notice and this permission notice appear in supporting
|
||||
documentation. No representations are made about the suitability of this
|
||||
software for any purpose. It is provided "as is" without express or
|
||||
implied warranty.
|
||||
|
||||
*/
|
||||
|
||||
#ifndef H_PMPARSER
|
||||
#define H_PMPARSER
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <unistd.h>
|
||||
#include <string.h>
|
||||
#include <sys/types.h>
|
||||
#include <sys/stat.h>
|
||||
#include <fcntl.h>
|
||||
#include <errno.h>
|
||||
#include <linux/limits.h>
|
||||
|
||||
// maximum line length in a procmaps file
|
||||
#define PROCMAPS_LINE_MAX_LENGTH (PATH_MAX + 100)
|
||||
/**
|
||||
* procmaps_struct
|
||||
* @desc hold all the information about an area in the process's VM
|
||||
*/
|
||||
typedef struct procmaps_struct {
|
||||
|
||||
void* addr_start; //< start address of the area
|
||||
void* addr_end; //< end address
|
||||
unsigned long length; //< size of the range
|
||||
|
||||
char perm[5]; //< permissions rwxp
|
||||
short is_r; //< rewrote of perm with short flags
|
||||
short is_w;
|
||||
short is_x;
|
||||
short is_p;
|
||||
|
||||
long offset; //< offset
|
||||
char dev[12]; //< dev major:minor
|
||||
int inode; //< inode of the file that backs the area
|
||||
|
||||
char pathname[600]; //< the path of the file that backs the area
|
||||
// chained list
|
||||
struct procmaps_struct* next; //<handler of the chinaed list
|
||||
|
||||
} procmaps_struct;
|
||||
|
||||
/**
|
||||
* procmaps_iterator
|
||||
* @desc holds iterating information
|
||||
*/
|
||||
typedef struct procmaps_iterator {
|
||||
|
||||
procmaps_struct* head;
|
||||
procmaps_struct* current;
|
||||
|
||||
} procmaps_iterator;
|
||||
|
||||
/**
|
||||
* pmparser_parse
|
||||
* @param pid the process id whose memory map to be parser. the current process
|
||||
* if pid<0
|
||||
* @return an iterator over all the nodes
|
||||
*/
|
||||
procmaps_iterator* pmparser_parse(int pid);
|
||||
|
||||
/**
|
||||
* pmparser_next
|
||||
* @description move between areas
|
||||
* @param p_procmaps_it the iterator to move on step in the chained list
|
||||
* @return a procmaps structure filled with information about this VM area
|
||||
*/
|
||||
procmaps_struct* pmparser_next(procmaps_iterator* p_procmaps_it);
|
||||
/**
|
||||
* pmparser_free
|
||||
* @description should be called at the end to free the resources
|
||||
* @param p_procmaps_it the iterator structure returned by pmparser_parse
|
||||
*/
|
||||
void pmparser_free(procmaps_iterator* p_procmaps_it);
|
||||
|
||||
/**
|
||||
* _pmparser_split_line
|
||||
* @description internal usage
|
||||
*/
|
||||
void _pmparser_split_line(char* buf, char* addr1, char* addr2, char* perm,
|
||||
char* offset, char* device, char* inode,
|
||||
char* pathname);
|
||||
|
||||
/**
|
||||
* pmparser_print
|
||||
* @param map the head of the list
|
||||
* @order the order of the area to print, -1 to print everything
|
||||
*/
|
||||
void pmparser_print(procmaps_struct* map, int order);
|
||||
|
||||
/**
|
||||
* gobal variables
|
||||
*/
|
||||
// procmaps_struct* g_last_head=NULL;
|
||||
// procmaps_struct* g_current=NULL;
|
||||
|
||||
procmaps_iterator* pmparser_parse(int pid) {
|
||||
|
||||
procmaps_iterator* maps_it = malloc(sizeof(procmaps_iterator));
|
||||
char maps_path[500];
|
||||
if (pid >= 0) {
|
||||
|
||||
sprintf(maps_path, "/proc/%d/maps", pid);
|
||||
|
||||
} else {
|
||||
|
||||
sprintf(maps_path, "/proc/self/maps");
|
||||
|
||||
}
|
||||
|
||||
FILE* file = fopen(maps_path, "r");
|
||||
if (!file) {
|
||||
|
||||
fprintf(stderr, "pmparser : cannot open the memory maps, %s\n",
|
||||
strerror(errno));
|
||||
return NULL;
|
||||
|
||||
}
|
||||
|
||||
int ind = 0;
|
||||
char buf[PROCMAPS_LINE_MAX_LENGTH];
|
||||
// int c;
|
||||
procmaps_struct* list_maps = NULL;
|
||||
procmaps_struct* tmp;
|
||||
procmaps_struct* current_node = list_maps;
|
||||
char addr1[20], addr2[20], perm[8], offset[20], dev[10], inode[30],
|
||||
pathname[PATH_MAX];
|
||||
while (!feof(file)) {
|
||||
|
||||
fgets(buf, PROCMAPS_LINE_MAX_LENGTH, file);
|
||||
// allocate a node
|
||||
tmp = (procmaps_struct*)malloc(sizeof(procmaps_struct));
|
||||
// fill the node
|
||||
_pmparser_split_line(buf, addr1, addr2, perm, offset, dev, inode, pathname);
|
||||
// printf("#%s",buf);
|
||||
// printf("%s-%s %s %s %s
|
||||
// %s\t%s\n",addr1,addr2,perm,offset,dev,inode,pathname); addr_start &
|
||||
// addr_end unsigned long l_addr_start;
|
||||
sscanf(addr1, "%lx", (long unsigned*)&tmp->addr_start);
|
||||
sscanf(addr2, "%lx", (long unsigned*)&tmp->addr_end);
|
||||
// size
|
||||
tmp->length = (unsigned long)(tmp->addr_end - tmp->addr_start);
|
||||
// perm
|
||||
strcpy(tmp->perm, perm);
|
||||
tmp->is_r = (perm[0] == 'r');
|
||||
tmp->is_w = (perm[1] == 'w');
|
||||
tmp->is_x = (perm[2] == 'x');
|
||||
tmp->is_p = (perm[3] == 'p');
|
||||
|
||||
// offset
|
||||
sscanf(offset, "%lx", &tmp->offset);
|
||||
// device
|
||||
strcpy(tmp->dev, dev);
|
||||
// inode
|
||||
tmp->inode = atoi(inode);
|
||||
// pathname
|
||||
strcpy(tmp->pathname, pathname);
|
||||
tmp->next = NULL;
|
||||
// attach the node
|
||||
if (ind == 0) {
|
||||
|
||||
list_maps = tmp;
|
||||
list_maps->next = NULL;
|
||||
current_node = list_maps;
|
||||
|
||||
}
|
||||
|
||||
current_node->next = tmp;
|
||||
current_node = tmp;
|
||||
ind++;
|
||||
// printf("%s",buf);
|
||||
|
||||
}
|
||||
|
||||
// close file
|
||||
fclose(file);
|
||||
|
||||
// g_last_head=list_maps;
|
||||
maps_it->head = list_maps;
|
||||
maps_it->current = list_maps;
|
||||
return maps_it;
|
||||
|
||||
}
|
||||
|
||||
procmaps_struct* pmparser_next(procmaps_iterator* p_procmaps_it) {
|
||||
|
||||
if (p_procmaps_it->current == NULL) return NULL;
|
||||
procmaps_struct* p_current = p_procmaps_it->current;
|
||||
p_procmaps_it->current = p_procmaps_it->current->next;
|
||||
return p_current;
|
||||
/*
|
||||
if(g_current==NULL){
|
||||
|
||||
g_current=g_last_head;
|
||||
|
||||
}else
|
||||
|
||||
g_current=g_current->next;
|
||||
|
||||
return g_current;
|
||||
*/
|
||||
|
||||
}
|
||||
|
||||
void pmparser_free(procmaps_iterator* p_procmaps_it) {
|
||||
|
||||
procmaps_struct* maps_list = p_procmaps_it->head;
|
||||
if (maps_list == NULL) return;
|
||||
procmaps_struct* act = maps_list;
|
||||
procmaps_struct* nxt = act->next;
|
||||
while (act != NULL) {
|
||||
|
||||
free(act);
|
||||
act = nxt;
|
||||
if (nxt != NULL) nxt = nxt->next;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void _pmparser_split_line(char* buf, char* addr1, char* addr2, char* perm,
|
||||
char* offset, char* device, char* inode,
|
||||
char* pathname) {
|
||||
|
||||
//
|
||||
int orig = 0;
|
||||
int i = 0;
|
||||
// addr1
|
||||
while (buf[i] != '-') {
|
||||
|
||||
addr1[i - orig] = buf[i];
|
||||
i++;
|
||||
|
||||
}
|
||||
|
||||
addr1[i] = '\0';
|
||||
i++;
|
||||
// addr2
|
||||
orig = i;
|
||||
while (buf[i] != '\t' && buf[i] != ' ') {
|
||||
|
||||
addr2[i - orig] = buf[i];
|
||||
i++;
|
||||
|
||||
}
|
||||
|
||||
addr2[i - orig] = '\0';
|
||||
|
||||
// perm
|
||||
while (buf[i] == '\t' || buf[i] == ' ')
|
||||
i++;
|
||||
orig = i;
|
||||
while (buf[i] != '\t' && buf[i] != ' ') {
|
||||
|
||||
perm[i - orig] = buf[i];
|
||||
i++;
|
||||
|
||||
}
|
||||
|
||||
perm[i - orig] = '\0';
|
||||
// offset
|
||||
while (buf[i] == '\t' || buf[i] == ' ')
|
||||
i++;
|
||||
orig = i;
|
||||
while (buf[i] != '\t' && buf[i] != ' ') {
|
||||
|
||||
offset[i - orig] = buf[i];
|
||||
i++;
|
||||
|
||||
}
|
||||
|
||||
offset[i - orig] = '\0';
|
||||
// dev
|
||||
while (buf[i] == '\t' || buf[i] == ' ')
|
||||
i++;
|
||||
orig = i;
|
||||
while (buf[i] != '\t' && buf[i] != ' ') {
|
||||
|
||||
device[i - orig] = buf[i];
|
||||
i++;
|
||||
|
||||
}
|
||||
|
||||
device[i - orig] = '\0';
|
||||
// inode
|
||||
while (buf[i] == '\t' || buf[i] == ' ')
|
||||
i++;
|
||||
orig = i;
|
||||
while (buf[i] != '\t' && buf[i] != ' ') {
|
||||
|
||||
inode[i - orig] = buf[i];
|
||||
i++;
|
||||
|
||||
}
|
||||
|
||||
inode[i - orig] = '\0';
|
||||
// pathname
|
||||
pathname[0] = '\0';
|
||||
while (buf[i] == '\t' || buf[i] == ' ')
|
||||
i++;
|
||||
orig = i;
|
||||
while (buf[i] != '\t' && buf[i] != ' ' && buf[i] != '\n') {
|
||||
|
||||
pathname[i - orig] = buf[i];
|
||||
i++;
|
||||
|
||||
}
|
||||
|
||||
pathname[i - orig] = '\0';
|
||||
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
49
qemu_mode/patches/afl-qemu-common.h
Normal file
49
qemu_mode/patches/afl-qemu-common.h
Normal file
@ -0,0 +1,49 @@
|
||||
/*
|
||||
american fuzzy lop++ - high-performance binary-only instrumentation
|
||||
-------------------------------------------------------------------
|
||||
|
||||
Originally written by Andrew Griffiths <agriffiths@google.com> and
|
||||
Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
TCG instrumentation and block chaining support by Andrea Biondo
|
||||
<andrea.biondo965@gmail.com>
|
||||
|
||||
QEMU 3.1.0 port, TCG thread-safety, CompareCoverage and NeverZero
|
||||
counters by Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2015, 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This code is a shim patched into the separately-distributed source
|
||||
code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality
|
||||
to implement AFL-style instrumentation and to take care of the remaining
|
||||
parts of the AFL fork server logic.
|
||||
|
||||
The resulting QEMU binary is essentially a standalone instrumentation
|
||||
tool; for an example of how to leverage it for other purposes, you can
|
||||
have a look at afl-showmap.c.
|
||||
|
||||
*/
|
||||
|
||||
#include "../../config.h"
|
||||
|
||||
/* NeverZero */
|
||||
|
||||
#if (defined(__x86_64__) || defined(__i386__)) && defined(AFL_QEMU_NOT_ZERO)
|
||||
#define INC_AFL_AREA(loc) \
|
||||
asm volatile( \
|
||||
"incb (%0, %1, 1)\n" \
|
||||
"adcb $0, (%0, %1, 1)\n" \
|
||||
: /* no out */ \
|
||||
: "r"(afl_area_ptr), "r"(loc) \
|
||||
: "memory", "eax")
|
||||
#else
|
||||
#define INC_AFL_AREA(loc) afl_area_ptr[loc]++
|
||||
#endif
|
||||
|
||||
@ -1,16 +1,18 @@
|
||||
/*
|
||||
american fuzzy lop - high-performance binary-only instrumentation
|
||||
-----------------------------------------------------------------
|
||||
american fuzzy lop++ - high-performance binary-only instrumentation
|
||||
-------------------------------------------------------------------
|
||||
|
||||
Written by Andrew Griffiths <agriffiths@google.com> and
|
||||
Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Idea & design very much by Andrew Griffiths.
|
||||
Originally written by Andrew Griffiths <agriffiths@google.com> and
|
||||
Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
TCG instrumentation and block chaining support by Andrea Biondo
|
||||
<andrea.biondo965@gmail.com>
|
||||
|
||||
QEMU 3.1.0 port, TCG thread-safety, CompareCoverage and NeverZero
|
||||
counters by Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2015, 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
@ -19,7 +21,7 @@
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This code is a shim patched into the separately-distributed source
|
||||
code of QEMU 2.10.0. It leverages the built-in QEMU tracing functionality
|
||||
code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality
|
||||
to implement AFL-style instrumentation and to take care of the remaining
|
||||
parts of the AFL fork server logic.
|
||||
|
||||
@ -40,11 +42,16 @@
|
||||
_start and does the usual forkserver stuff, not very different from
|
||||
regular instrumentation injected via afl-as.h. */
|
||||
|
||||
#define AFL_QEMU_CPU_SNIPPET2 do { \
|
||||
if(itb->pc == afl_entry_point) { \
|
||||
afl_setup(); \
|
||||
afl_forkserver(cpu); \
|
||||
} \
|
||||
#define AFL_QEMU_CPU_SNIPPET2 \
|
||||
do { \
|
||||
\
|
||||
if (itb->pc == afl_entry_point) { \
|
||||
\
|
||||
afl_setup(); \
|
||||
afl_forkserver(cpu); \
|
||||
\
|
||||
} \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* We use one additional file descriptor to relay "needs translation"
|
||||
@ -54,58 +61,71 @@
|
||||
|
||||
/* This is equivalent to afl-as.h: */
|
||||
|
||||
static unsigned char dummy[65536]; /* costs 64kb but saves a few instructions */
|
||||
unsigned char *afl_area_ptr = dummy; /* Exported for afl_gen_trace */
|
||||
static unsigned char
|
||||
dummy[MAP_SIZE]; /* costs MAP_SIZE but saves a few instructions */
|
||||
unsigned char *afl_area_ptr = dummy; /* Exported for afl_gen_trace */
|
||||
|
||||
/* Exported variables populated by the code patched into elfload.c: */
|
||||
|
||||
abi_ulong afl_entry_point, /* ELF entry point (_start) */
|
||||
afl_start_code, /* .text start pointer */
|
||||
afl_end_code; /* .text end pointer */
|
||||
abi_ulong afl_entry_point, /* ELF entry point (_start) */
|
||||
afl_start_code, /* .text start pointer */
|
||||
afl_end_code; /* .text end pointer */
|
||||
|
||||
u8 afl_compcov_level;
|
||||
|
||||
/* Set in the child process in forkserver mode: */
|
||||
|
||||
static int forkserver_installed = 0;
|
||||
static int forkserver_installed = 0;
|
||||
static unsigned char afl_fork_child;
|
||||
unsigned int afl_forksrv_pid;
|
||||
unsigned int afl_forksrv_pid;
|
||||
|
||||
/* Instrumentation ratio: */
|
||||
|
||||
unsigned int afl_inst_rms = MAP_SIZE; /* Exported for afl_gen_trace */
|
||||
unsigned int afl_inst_rms = MAP_SIZE; /* Exported for afl_gen_trace */
|
||||
|
||||
/* Function declarations. */
|
||||
|
||||
static void afl_setup(void);
|
||||
static void afl_forkserver(CPUState*);
|
||||
static void afl_forkserver(CPUState *);
|
||||
|
||||
static void afl_wait_tsl(CPUState*, int);
|
||||
static void afl_request_tsl(target_ulong, target_ulong, uint32_t, uint32_t, TranslationBlock*, int);
|
||||
static void afl_wait_tsl(CPUState *, int);
|
||||
static void afl_request_tsl(target_ulong, target_ulong, uint32_t, uint32_t,
|
||||
TranslationBlock *, int);
|
||||
|
||||
/* Data structures passed around by the translate handlers: */
|
||||
|
||||
struct afl_tb {
|
||||
|
||||
target_ulong pc;
|
||||
target_ulong cs_base;
|
||||
uint32_t flags;
|
||||
uint32_t cf_mask;
|
||||
uint32_t flags;
|
||||
uint32_t cf_mask;
|
||||
|
||||
};
|
||||
|
||||
struct afl_tsl {
|
||||
|
||||
struct afl_tb tb;
|
||||
char is_chain;
|
||||
char is_chain;
|
||||
|
||||
};
|
||||
|
||||
struct afl_chain {
|
||||
|
||||
struct afl_tb last_tb;
|
||||
uint32_t cf_mask;
|
||||
int tb_exit;
|
||||
uint32_t cf_mask;
|
||||
int tb_exit;
|
||||
|
||||
};
|
||||
|
||||
/* Some forward decls: */
|
||||
|
||||
TranslationBlock *tb_htable_lookup(CPUState*, target_ulong, target_ulong, uint32_t, uint32_t);
|
||||
static inline TranslationBlock *tb_find(CPUState*, TranslationBlock*, int, uint32_t);
|
||||
static inline void tb_add_jump(TranslationBlock *tb, int n, TranslationBlock *tb_next);
|
||||
TranslationBlock *tb_htable_lookup(CPUState *, target_ulong, target_ulong,
|
||||
uint32_t, uint32_t);
|
||||
static inline TranslationBlock *tb_find(CPUState *, TranslationBlock *, int,
|
||||
uint32_t);
|
||||
static inline void tb_add_jump(TranslationBlock *tb, int n,
|
||||
TranslationBlock *tb_next);
|
||||
|
||||
/*************************
|
||||
* ACTUAL IMPLEMENTATION *
|
||||
@ -115,8 +135,7 @@ static inline void tb_add_jump(TranslationBlock *tb, int n, TranslationBlock *tb
|
||||
|
||||
static void afl_setup(void) {
|
||||
|
||||
char *id_str = getenv(SHM_ENV_VAR),
|
||||
*inst_r = getenv("AFL_INST_RATIO");
|
||||
char *id_str = getenv(SHM_ENV_VAR), *inst_r = getenv("AFL_INST_RATIO");
|
||||
|
||||
int shm_id;
|
||||
|
||||
@ -138,20 +157,27 @@ static void afl_setup(void) {
|
||||
shm_id = atoi(id_str);
|
||||
afl_area_ptr = shmat(shm_id, NULL, 0);
|
||||
|
||||
if (afl_area_ptr == (void*)-1) exit(1);
|
||||
if (afl_area_ptr == (void *)-1) exit(1);
|
||||
|
||||
/* With AFL_INST_RATIO set to a low value, we want to touch the bitmap
|
||||
so that the parent doesn't give up on us. */
|
||||
|
||||
if (inst_r) afl_area_ptr[0] = 1;
|
||||
|
||||
|
||||
}
|
||||
|
||||
if (getenv("AFL_INST_LIBS")) {
|
||||
|
||||
afl_start_code = 0;
|
||||
afl_end_code = (abi_ulong)-1;
|
||||
afl_end_code = (abi_ulong)-1;
|
||||
|
||||
}
|
||||
|
||||
/* Maintain for compatibility */
|
||||
if (getenv("AFL_QEMU_COMPCOV")) { afl_compcov_level = 1; }
|
||||
if (getenv("AFL_COMPCOV_LEVEL")) {
|
||||
|
||||
afl_compcov_level = atoi(getenv("AFL_COMPCOV_LEVEL"));
|
||||
|
||||
}
|
||||
|
||||
@ -163,17 +189,15 @@ static void afl_setup(void) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Fork server logic, invoked once we hit _start. */
|
||||
|
||||
static void afl_forkserver(CPUState *cpu) {
|
||||
|
||||
static unsigned char tmp[4];
|
||||
|
||||
if (forkserver_installed == 1)
|
||||
return;
|
||||
if (forkserver_installed == 1) return;
|
||||
forkserver_installed = 1;
|
||||
//if (!afl_area_ptr) return; // not necessary because of fixed dummy buffer
|
||||
// if (!afl_area_ptr) return; // not necessary because of fixed dummy buffer
|
||||
|
||||
/* Tell the parent that we're alive. If the parent doesn't want
|
||||
to talk, assume that we're not running in forkserver mode. */
|
||||
@ -187,7 +211,7 @@ static void afl_forkserver(CPUState *cpu) {
|
||||
while (1) {
|
||||
|
||||
pid_t child_pid;
|
||||
int status, t_fd[2];
|
||||
int status, t_fd[2];
|
||||
|
||||
/* Whoops, parent dead? */
|
||||
|
||||
@ -233,75 +257,115 @@ static void afl_forkserver(CPUState *cpu) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* This code is invoked whenever QEMU decides that it doesn't have a
|
||||
translation of a particular block and needs to compute it, or when it
|
||||
decides to chain two TBs together. When this happens, we tell the parent to
|
||||
mirror the operation, so that the next fork() has a cached copy. */
|
||||
|
||||
static void afl_request_tsl(target_ulong pc, target_ulong cb, uint32_t flags, uint32_t cf_mask,
|
||||
TranslationBlock *last_tb, int tb_exit) {
|
||||
static void afl_request_tsl(target_ulong pc, target_ulong cb, uint32_t flags,
|
||||
uint32_t cf_mask, TranslationBlock *last_tb,
|
||||
int tb_exit) {
|
||||
|
||||
struct afl_tsl t;
|
||||
struct afl_tsl t;
|
||||
struct afl_chain c;
|
||||
|
||||
if (!afl_fork_child) return;
|
||||
|
||||
t.tb.pc = pc;
|
||||
t.tb.pc = pc;
|
||||
t.tb.cs_base = cb;
|
||||
t.tb.flags = flags;
|
||||
t.tb.flags = flags;
|
||||
t.tb.cf_mask = cf_mask;
|
||||
t.is_chain = (last_tb != NULL);
|
||||
t.is_chain = (last_tb != NULL);
|
||||
|
||||
if (write(TSL_FD, &t, sizeof(struct afl_tsl)) != sizeof(struct afl_tsl))
|
||||
return;
|
||||
|
||||
if (t.is_chain) {
|
||||
c.last_tb.pc = last_tb->pc;
|
||||
|
||||
c.last_tb.pc = last_tb->pc;
|
||||
c.last_tb.cs_base = last_tb->cs_base;
|
||||
c.last_tb.flags = last_tb->flags;
|
||||
c.cf_mask = cf_mask;
|
||||
c.tb_exit = tb_exit;
|
||||
c.last_tb.flags = last_tb->flags;
|
||||
c.cf_mask = cf_mask;
|
||||
c.tb_exit = tb_exit;
|
||||
|
||||
if (write(TSL_FD, &c, sizeof(struct afl_chain)) != sizeof(struct afl_chain))
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* Check if an address is valid in the current mapping */
|
||||
|
||||
static inline int is_valid_addr(target_ulong addr) {
|
||||
|
||||
int l, flags;
|
||||
target_ulong page;
|
||||
void * p;
|
||||
|
||||
page = addr & TARGET_PAGE_MASK;
|
||||
l = (page + TARGET_PAGE_SIZE) - addr;
|
||||
|
||||
flags = page_get_flags(page);
|
||||
if (!(flags & PAGE_VALID) || !(flags & PAGE_READ)) return 0;
|
||||
|
||||
return 1;
|
||||
|
||||
}
|
||||
|
||||
/* This is the other side of the same channel. Since timeouts are handled by
|
||||
afl-fuzz simply killing the child, we can just wait until the pipe breaks. */
|
||||
|
||||
static void afl_wait_tsl(CPUState *cpu, int fd) {
|
||||
|
||||
struct afl_tsl t;
|
||||
struct afl_chain c;
|
||||
struct afl_tsl t;
|
||||
struct afl_chain c;
|
||||
TranslationBlock *tb, *last_tb;
|
||||
|
||||
while (1) {
|
||||
|
||||
u8 invalid_pc = 0;
|
||||
|
||||
/* Broken pipe means it's time to return to the fork server routine. */
|
||||
|
||||
if (read(fd, &t, sizeof(struct afl_tsl)) != sizeof(struct afl_tsl))
|
||||
break;
|
||||
if (read(fd, &t, sizeof(struct afl_tsl)) != sizeof(struct afl_tsl)) break;
|
||||
|
||||
tb = tb_htable_lookup(cpu, t.tb.pc, t.tb.cs_base, t.tb.flags, t.tb.cf_mask);
|
||||
|
||||
if(!tb) {
|
||||
mmap_lock();
|
||||
tb = tb_gen_code(cpu, t.tb.pc, t.tb.cs_base, t.tb.flags, 0);
|
||||
mmap_unlock();
|
||||
if (!tb) {
|
||||
|
||||
/* The child may request to transate a block of memory that is not
|
||||
mapped in the parent (e.g. jitted code or dlopened code).
|
||||
This causes a SIGSEV in gen_intermediate_code() and associated
|
||||
subroutines. We simply avoid caching of such blocks. */
|
||||
|
||||
if (is_valid_addr(t.tb.pc)) {
|
||||
|
||||
mmap_lock();
|
||||
tb = tb_gen_code(cpu, t.tb.pc, t.tb.cs_base, t.tb.flags, t.tb.cf_mask);
|
||||
mmap_unlock();
|
||||
|
||||
} else {
|
||||
|
||||
invalid_pc = 1;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (t.is_chain) {
|
||||
|
||||
if (read(fd, &c, sizeof(struct afl_chain)) != sizeof(struct afl_chain))
|
||||
break;
|
||||
|
||||
last_tb = tb_htable_lookup(cpu, c.last_tb.pc, c.last_tb.cs_base,
|
||||
c.last_tb.flags, c.cf_mask);
|
||||
if (last_tb) {
|
||||
tb_add_jump(last_tb, c.tb_exit, tb);
|
||||
if (!invalid_pc) {
|
||||
|
||||
last_tb = tb_htable_lookup(cpu, c.last_tb.pc, c.last_tb.cs_base,
|
||||
c.last_tb.flags, c.cf_mask);
|
||||
if (last_tb) { tb_add_jump(last_tb, c.tb_exit, tb); }
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
@ -309,3 +373,4 @@ static void afl_wait_tsl(CPUState *cpu, int fd) {
|
||||
close(fd);
|
||||
|
||||
}
|
||||
|
||||
|
||||
139
qemu_mode/patches/afl-qemu-cpu-translate-inl.h
Normal file
139
qemu_mode/patches/afl-qemu-cpu-translate-inl.h
Normal file
@ -0,0 +1,139 @@
|
||||
/*
|
||||
american fuzzy lop++ - high-performance binary-only instrumentation
|
||||
-------------------------------------------------------------------
|
||||
|
||||
Originally written by Andrew Griffiths <agriffiths@google.com> and
|
||||
Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
TCG instrumentation and block chaining support by Andrea Biondo
|
||||
<andrea.biondo965@gmail.com>
|
||||
|
||||
QEMU 3.1.0 port, TCG thread-safety, CompareCoverage and NeverZero
|
||||
counters by Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2015, 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This code is a shim patched into the separately-distributed source
|
||||
code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality
|
||||
to implement AFL-style instrumentation and to take care of the remaining
|
||||
parts of the AFL fork server logic.
|
||||
|
||||
The resulting QEMU binary is essentially a standalone instrumentation
|
||||
tool; for an example of how to leverage it for other purposes, you can
|
||||
have a look at afl-showmap.c.
|
||||
|
||||
*/
|
||||
|
||||
#include "afl-qemu-common.h"
|
||||
#include "tcg.h"
|
||||
#include "tcg-op.h"
|
||||
|
||||
/* Declared in afl-qemu-cpu-inl.h */
|
||||
extern unsigned char *afl_area_ptr;
|
||||
extern unsigned int afl_inst_rms;
|
||||
extern abi_ulong afl_start_code, afl_end_code;
|
||||
extern u8 afl_compcov_level;
|
||||
|
||||
void tcg_gen_afl_compcov_log_call(void *func, target_ulong cur_loc,
|
||||
TCGv_i64 arg1, TCGv_i64 arg2);
|
||||
|
||||
static void afl_compcov_log_16(target_ulong cur_loc, target_ulong arg1,
|
||||
target_ulong arg2) {
|
||||
|
||||
if ((arg1 & 0xff) == (arg2 & 0xff)) { INC_AFL_AREA(cur_loc); }
|
||||
|
||||
}
|
||||
|
||||
static void afl_compcov_log_32(target_ulong cur_loc, target_ulong arg1,
|
||||
target_ulong arg2) {
|
||||
|
||||
if ((arg1 & 0xff) == (arg2 & 0xff)) {
|
||||
|
||||
INC_AFL_AREA(cur_loc);
|
||||
if ((arg1 & 0xffff) == (arg2 & 0xffff)) {
|
||||
|
||||
INC_AFL_AREA(cur_loc + 1);
|
||||
if ((arg1 & 0xffffff) == (arg2 & 0xffffff)) { INC_AFL_AREA(cur_loc + 2); }
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
static void afl_compcov_log_64(target_ulong cur_loc, target_ulong arg1,
|
||||
target_ulong arg2) {
|
||||
|
||||
if ((arg1 & 0xff) == (arg2 & 0xff)) {
|
||||
|
||||
INC_AFL_AREA(cur_loc);
|
||||
if ((arg1 & 0xffff) == (arg2 & 0xffff)) {
|
||||
|
||||
INC_AFL_AREA(cur_loc + 1);
|
||||
if ((arg1 & 0xffffff) == (arg2 & 0xffffff)) {
|
||||
|
||||
INC_AFL_AREA(cur_loc + 2);
|
||||
if ((arg1 & 0xffffffff) == (arg2 & 0xffffffff)) {
|
||||
|
||||
INC_AFL_AREA(cur_loc + 3);
|
||||
if ((arg1 & 0xffffffffff) == (arg2 & 0xffffffffff)) {
|
||||
|
||||
INC_AFL_AREA(cur_loc + 4);
|
||||
if ((arg1 & 0xffffffffffff) == (arg2 & 0xffffffffffff)) {
|
||||
|
||||
INC_AFL_AREA(cur_loc + 5);
|
||||
if ((arg1 & 0xffffffffffffff) == (arg2 & 0xffffffffffffff)) {
|
||||
|
||||
INC_AFL_AREA(cur_loc + 6);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
static void afl_gen_compcov(target_ulong cur_loc, TCGv_i64 arg1, TCGv_i64 arg2,
|
||||
TCGMemOp ot, int is_imm) {
|
||||
|
||||
void *func;
|
||||
|
||||
if (!afl_compcov_level || cur_loc > afl_end_code || cur_loc < afl_start_code)
|
||||
return;
|
||||
|
||||
if (!is_imm && afl_compcov_level < 2) return;
|
||||
|
||||
switch (ot) {
|
||||
|
||||
case MO_64: func = &afl_compcov_log_64; break;
|
||||
case MO_32: func = &afl_compcov_log_32; break;
|
||||
case MO_16: func = &afl_compcov_log_16; break;
|
||||
default: return;
|
||||
|
||||
}
|
||||
|
||||
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
|
||||
cur_loc &= MAP_SIZE - 7;
|
||||
|
||||
if (cur_loc >= afl_inst_rms) return;
|
||||
|
||||
tcg_gen_afl_compcov_log_call(func, cur_loc, arg1, arg2);
|
||||
|
||||
}
|
||||
|
||||
373
qemu_mode/patches/afl-qemu-tcg-inl.h
Normal file
373
qemu_mode/patches/afl-qemu-tcg-inl.h
Normal file
@ -0,0 +1,373 @@
|
||||
/*
|
||||
american fuzzy lop++ - high-performance binary-only instrumentation
|
||||
-------------------------------------------------------------------
|
||||
|
||||
Originally written by Andrew Griffiths <agriffiths@google.com> and
|
||||
Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
TCG instrumentation and block chaining support by Andrea Biondo
|
||||
<andrea.biondo965@gmail.com>
|
||||
|
||||
QEMU 3.1.0 port, TCG thread-safety, CompareCoverage and NeverZero
|
||||
counters by Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2015, 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This code is a shim patched into the separately-distributed source
|
||||
code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality
|
||||
to implement AFL-style instrumentation and to take care of the remaining
|
||||
parts of the AFL fork server logic.
|
||||
|
||||
The resulting QEMU binary is essentially a standalone instrumentation
|
||||
tool; for an example of how to leverage it for other purposes, you can
|
||||
have a look at afl-showmap.c.
|
||||
|
||||
*/
|
||||
|
||||
void afl_maybe_log(void *cur_loc);
|
||||
|
||||
/* Note: we convert the 64 bit args to 32 bit and do some alignment
|
||||
and endian swap. Maybe it would be better to do the alignment
|
||||
and endian swap in tcg_reg_alloc_call(). */
|
||||
void tcg_gen_afl_maybe_log_call(target_ulong cur_loc) {
|
||||
|
||||
int real_args, pi;
|
||||
unsigned sizemask, flags;
|
||||
TCGOp * op;
|
||||
|
||||
TCGTemp *arg = tcgv_i64_temp(tcg_const_tl(cur_loc));
|
||||
|
||||
flags = 0;
|
||||
sizemask = dh_sizemask(void, 0) | dh_sizemask(i64, 1);
|
||||
|
||||
#if defined(__sparc__) && !defined(__arch64__) && \
|
||||
!defined(CONFIG_TCG_INTERPRETER)
|
||||
/* We have 64-bit values in one register, but need to pass as two
|
||||
separate parameters. Split them. */
|
||||
int orig_sizemask = sizemask;
|
||||
TCGv_i64 retl, reth;
|
||||
TCGTemp *split_args[MAX_OPC_PARAM];
|
||||
|
||||
retl = NULL;
|
||||
reth = NULL;
|
||||
if (sizemask != 0) {
|
||||
|
||||
real_args = 0;
|
||||
int is_64bit = sizemask & (1 << 2);
|
||||
if (is_64bit) {
|
||||
|
||||
TCGv_i64 orig = temp_tcgv_i64(arg);
|
||||
TCGv_i32 h = tcg_temp_new_i32();
|
||||
TCGv_i32 l = tcg_temp_new_i32();
|
||||
tcg_gen_extr_i64_i32(l, h, orig);
|
||||
split_args[real_args++] = tcgv_i32_temp(h);
|
||||
split_args[real_args++] = tcgv_i32_temp(l);
|
||||
|
||||
} else {
|
||||
|
||||
split_args[real_args++] = arg;
|
||||
|
||||
}
|
||||
|
||||
nargs = real_args;
|
||||
args = split_args;
|
||||
sizemask = 0;
|
||||
|
||||
}
|
||||
|
||||
#elif defined(TCG_TARGET_EXTEND_ARGS) && TCG_TARGET_REG_BITS == 64
|
||||
int is_64bit = sizemask & (1 << 2);
|
||||
int is_signed = sizemask & (2 << 2);
|
||||
if (!is_64bit) {
|
||||
|
||||
TCGv_i64 temp = tcg_temp_new_i64();
|
||||
TCGv_i64 orig = temp_tcgv_i64(arg);
|
||||
if (is_signed) {
|
||||
|
||||
tcg_gen_ext32s_i64(temp, orig);
|
||||
|
||||
} else {
|
||||
|
||||
tcg_gen_ext32u_i64(temp, orig);
|
||||
|
||||
}
|
||||
|
||||
arg = tcgv_i64_temp(temp);
|
||||
|
||||
}
|
||||
|
||||
#endif /* TCG_TARGET_EXTEND_ARGS */
|
||||
|
||||
op = tcg_emit_op(INDEX_op_call);
|
||||
|
||||
pi = 0;
|
||||
|
||||
TCGOP_CALLO(op) = 0;
|
||||
|
||||
real_args = 0;
|
||||
int is_64bit = sizemask & (1 << 2);
|
||||
if (TCG_TARGET_REG_BITS < 64 && is_64bit) {
|
||||
|
||||
#ifdef TCG_TARGET_CALL_ALIGN_ARGS
|
||||
/* some targets want aligned 64 bit args */
|
||||
if (real_args & 1) {
|
||||
|
||||
op->args[pi++] = TCG_CALL_DUMMY_ARG;
|
||||
real_args++;
|
||||
|
||||
}
|
||||
|
||||
#endif
|
||||
/* If stack grows up, then we will be placing successive
|
||||
arguments at lower addresses, which means we need to
|
||||
reverse the order compared to how we would normally
|
||||
treat either big or little-endian. For those arguments
|
||||
that will wind up in registers, this still works for
|
||||
HPPA (the only current STACK_GROWSUP target) since the
|
||||
argument registers are *also* allocated in decreasing
|
||||
order. If another such target is added, this logic may
|
||||
have to get more complicated to differentiate between
|
||||
stack arguments and register arguments. */
|
||||
#if defined(HOST_WORDS_BIGENDIAN) != defined(TCG_TARGET_STACK_GROWSUP)
|
||||
op->args[pi++] = temp_arg(arg + 1);
|
||||
op->args[pi++] = temp_arg(arg);
|
||||
#else
|
||||
op->args[pi++] = temp_arg(arg);
|
||||
op->args[pi++] = temp_arg(arg + 1);
|
||||
#endif
|
||||
real_args += 2;
|
||||
|
||||
}
|
||||
|
||||
op->args[pi++] = temp_arg(arg);
|
||||
real_args++;
|
||||
|
||||
op->args[pi++] = (uintptr_t)&afl_maybe_log;
|
||||
op->args[pi++] = flags;
|
||||
TCGOP_CALLI(op) = real_args;
|
||||
|
||||
/* Make sure the fields didn't overflow. */
|
||||
tcg_debug_assert(TCGOP_CALLI(op) == real_args);
|
||||
tcg_debug_assert(pi <= ARRAY_SIZE(op->args));
|
||||
|
||||
#if defined(__sparc__) && !defined(__arch64__) && \
|
||||
!defined(CONFIG_TCG_INTERPRETER)
|
||||
/* Free all of the parts we allocated above. */
|
||||
real_args = 0;
|
||||
int is_64bit = orig_sizemask & (1 << 2);
|
||||
if (is_64bit) {
|
||||
|
||||
tcg_temp_free_internal(args[real_args++]);
|
||||
tcg_temp_free_internal(args[real_args++]);
|
||||
|
||||
} else {
|
||||
|
||||
real_args++;
|
||||
|
||||
}
|
||||
|
||||
if (orig_sizemask & 1) {
|
||||
|
||||
/* The 32-bit ABI returned two 32-bit pieces. Re-assemble them.
|
||||
Note that describing these as TCGv_i64 eliminates an unnecessary
|
||||
zero-extension that tcg_gen_concat_i32_i64 would create. */
|
||||
tcg_gen_concat32_i64(temp_tcgv_i64(NULL), retl, reth);
|
||||
tcg_temp_free_i64(retl);
|
||||
tcg_temp_free_i64(reth);
|
||||
|
||||
}
|
||||
|
||||
#elif defined(TCG_TARGET_EXTEND_ARGS) && TCG_TARGET_REG_BITS == 64
|
||||
int is_64bit = sizemask & (1 << 2);
|
||||
if (!is_64bit) { tcg_temp_free_internal(arg); }
|
||||
#endif /* TCG_TARGET_EXTEND_ARGS */
|
||||
|
||||
}
|
||||
|
||||
void tcg_gen_afl_compcov_log_call(void *func, target_ulong cur_loc,
|
||||
TCGv_i64 arg1, TCGv_i64 arg2) {
|
||||
|
||||
int i, real_args, nb_rets, pi;
|
||||
unsigned sizemask, flags;
|
||||
TCGOp * op;
|
||||
|
||||
const int nargs = 3;
|
||||
TCGTemp *args[3] = {tcgv_i64_temp(tcg_const_tl(cur_loc)), tcgv_i64_temp(arg1),
|
||||
tcgv_i64_temp(arg2)};
|
||||
|
||||
flags = 0;
|
||||
sizemask = dh_sizemask(void, 0) | dh_sizemask(i64, 1) | dh_sizemask(i64, 2) |
|
||||
dh_sizemask(i64, 3);
|
||||
|
||||
#if defined(__sparc__) && !defined(__arch64__) && \
|
||||
!defined(CONFIG_TCG_INTERPRETER)
|
||||
/* We have 64-bit values in one register, but need to pass as two
|
||||
separate parameters. Split them. */
|
||||
int orig_sizemask = sizemask;
|
||||
int orig_nargs = nargs;
|
||||
TCGv_i64 retl, reth;
|
||||
TCGTemp *split_args[MAX_OPC_PARAM];
|
||||
|
||||
retl = NULL;
|
||||
reth = NULL;
|
||||
if (sizemask != 0) {
|
||||
|
||||
for (i = real_args = 0; i < nargs; ++i) {
|
||||
|
||||
int is_64bit = sizemask & (1 << (i + 1) * 2);
|
||||
if (is_64bit) {
|
||||
|
||||
TCGv_i64 orig = temp_tcgv_i64(args[i]);
|
||||
TCGv_i32 h = tcg_temp_new_i32();
|
||||
TCGv_i32 l = tcg_temp_new_i32();
|
||||
tcg_gen_extr_i64_i32(l, h, orig);
|
||||
split_args[real_args++] = tcgv_i32_temp(h);
|
||||
split_args[real_args++] = tcgv_i32_temp(l);
|
||||
|
||||
} else {
|
||||
|
||||
split_args[real_args++] = args[i];
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
nargs = real_args;
|
||||
args = split_args;
|
||||
sizemask = 0;
|
||||
|
||||
}
|
||||
|
||||
#elif defined(TCG_TARGET_EXTEND_ARGS) && TCG_TARGET_REG_BITS == 64
|
||||
for (i = 0; i < nargs; ++i) {
|
||||
|
||||
int is_64bit = sizemask & (1 << (i + 1) * 2);
|
||||
int is_signed = sizemask & (2 << (i + 1) * 2);
|
||||
if (!is_64bit) {
|
||||
|
||||
TCGv_i64 temp = tcg_temp_new_i64();
|
||||
TCGv_i64 orig = temp_tcgv_i64(args[i]);
|
||||
if (is_signed) {
|
||||
|
||||
tcg_gen_ext32s_i64(temp, orig);
|
||||
|
||||
} else {
|
||||
|
||||
tcg_gen_ext32u_i64(temp, orig);
|
||||
|
||||
}
|
||||
|
||||
args[i] = tcgv_i64_temp(temp);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
#endif /* TCG_TARGET_EXTEND_ARGS */
|
||||
|
||||
op = tcg_emit_op(INDEX_op_call);
|
||||
|
||||
pi = 0;
|
||||
nb_rets = 0;
|
||||
TCGOP_CALLO(op) = nb_rets;
|
||||
|
||||
real_args = 0;
|
||||
for (i = 0; i < nargs; i++) {
|
||||
|
||||
int is_64bit = sizemask & (1 << (i + 1) * 2);
|
||||
if (TCG_TARGET_REG_BITS < 64 && is_64bit) {
|
||||
|
||||
#ifdef TCG_TARGET_CALL_ALIGN_ARGS
|
||||
/* some targets want aligned 64 bit args */
|
||||
if (real_args & 1) {
|
||||
|
||||
op->args[pi++] = TCG_CALL_DUMMY_ARG;
|
||||
real_args++;
|
||||
|
||||
}
|
||||
|
||||
#endif
|
||||
/* If stack grows up, then we will be placing successive
|
||||
arguments at lower addresses, which means we need to
|
||||
reverse the order compared to how we would normally
|
||||
treat either big or little-endian. For those arguments
|
||||
that will wind up in registers, this still works for
|
||||
HPPA (the only current STACK_GROWSUP target) since the
|
||||
argument registers are *also* allocated in decreasing
|
||||
order. If another such target is added, this logic may
|
||||
have to get more complicated to differentiate between
|
||||
stack arguments and register arguments. */
|
||||
#if defined(HOST_WORDS_BIGENDIAN) != defined(TCG_TARGET_STACK_GROWSUP)
|
||||
op->args[pi++] = temp_arg(args[i] + 1);
|
||||
op->args[pi++] = temp_arg(args[i]);
|
||||
#else
|
||||
op->args[pi++] = temp_arg(args[i]);
|
||||
op->args[pi++] = temp_arg(args[i] + 1);
|
||||
#endif
|
||||
real_args += 2;
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
op->args[pi++] = temp_arg(args[i]);
|
||||
real_args++;
|
||||
|
||||
}
|
||||
|
||||
op->args[pi++] = (uintptr_t)func;
|
||||
op->args[pi++] = flags;
|
||||
TCGOP_CALLI(op) = real_args;
|
||||
|
||||
/* Make sure the fields didn't overflow. */
|
||||
tcg_debug_assert(TCGOP_CALLI(op) == real_args);
|
||||
tcg_debug_assert(pi <= ARRAY_SIZE(op->args));
|
||||
|
||||
#if defined(__sparc__) && !defined(__arch64__) && \
|
||||
!defined(CONFIG_TCG_INTERPRETER)
|
||||
/* Free all of the parts we allocated above. */
|
||||
for (i = real_args = 0; i < orig_nargs; ++i) {
|
||||
|
||||
int is_64bit = orig_sizemask & (1 << (i + 1) * 2);
|
||||
if (is_64bit) {
|
||||
|
||||
tcg_temp_free_internal(args[real_args++]);
|
||||
tcg_temp_free_internal(args[real_args++]);
|
||||
|
||||
} else {
|
||||
|
||||
real_args++;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (orig_sizemask & 1) {
|
||||
|
||||
/* The 32-bit ABI returned two 32-bit pieces. Re-assemble them.
|
||||
Note that describing these as TCGv_i64 eliminates an unnecessary
|
||||
zero-extension that tcg_gen_concat_i32_i64 would create. */
|
||||
tcg_gen_concat32_i64(temp_tcgv_i64(NULL), retl, reth);
|
||||
tcg_temp_free_i64(retl);
|
||||
tcg_temp_free_i64(reth);
|
||||
|
||||
}
|
||||
|
||||
#elif defined(TCG_TARGET_EXTEND_ARGS) && TCG_TARGET_REG_BITS == 64
|
||||
for (i = 0; i < nargs; ++i) {
|
||||
|
||||
int is_64bit = sizemask & (1 << (i + 1) * 2);
|
||||
if (!is_64bit) { tcg_temp_free_internal(args[i]); }
|
||||
|
||||
}
|
||||
|
||||
#endif /* TCG_TARGET_EXTEND_ARGS */
|
||||
|
||||
}
|
||||
|
||||
@ -1,16 +1,18 @@
|
||||
/*
|
||||
american fuzzy lop - high-performance binary-only instrumentation
|
||||
-----------------------------------------------------------------
|
||||
american fuzzy lop++ - high-performance binary-only instrumentation
|
||||
-------------------------------------------------------------------
|
||||
|
||||
Written by Andrew Griffiths <agriffiths@google.com> and
|
||||
Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Idea & design very much by Andrew Griffiths.
|
||||
Originally written by Andrew Griffiths <agriffiths@google.com> and
|
||||
Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
TCG instrumentation and block chaining support by Andrea Biondo
|
||||
<andrea.biondo965@gmail.com>
|
||||
|
||||
QEMU 3.1.0 port, TCG thread-safety, CompareCoverage and NeverZero
|
||||
counters by Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2015, 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
@ -19,7 +21,7 @@
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This code is a shim patched into the separately-distributed source
|
||||
code of QEMU 2.10.0. It leverages the built-in QEMU tracing functionality
|
||||
code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality
|
||||
to implement AFL-style instrumentation and to take care of the remaining
|
||||
parts of the AFL fork server logic.
|
||||
|
||||
@ -29,41 +31,44 @@
|
||||
|
||||
*/
|
||||
|
||||
#include "../../config.h"
|
||||
#include "afl-qemu-common.h"
|
||||
#include "tcg-op.h"
|
||||
|
||||
/* Declared in afl-qemu-cpu-inl.h */
|
||||
extern unsigned char *afl_area_ptr;
|
||||
extern unsigned int afl_inst_rms;
|
||||
extern abi_ulong afl_start_code, afl_end_code;
|
||||
extern unsigned int afl_inst_rms;
|
||||
extern abi_ulong afl_start_code, afl_end_code;
|
||||
|
||||
void tcg_gen_afl_callN(void *func, TCGTemp *ret, int nargs, TCGTemp **args);
|
||||
void tcg_gen_afl_maybe_log_call(target_ulong cur_loc);
|
||||
|
||||
|
||||
void afl_maybe_log(abi_ulong cur_loc) {
|
||||
void afl_maybe_log(target_ulong cur_loc) {
|
||||
|
||||
static __thread abi_ulong prev_loc;
|
||||
|
||||
afl_area_ptr[cur_loc ^ prev_loc]++;
|
||||
register uintptr_t afl_idx = cur_loc ^ prev_loc;
|
||||
|
||||
INC_AFL_AREA(afl_idx);
|
||||
|
||||
prev_loc = cur_loc >> 1;
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Generates TCG code for AFL's tracing instrumentation. */
|
||||
static void afl_gen_trace(target_ulong cur_loc) {
|
||||
|
||||
/* Optimize for cur_loc > afl_end_code, which is the most likely case on
|
||||
Linux systems. */
|
||||
|
||||
if (cur_loc > afl_end_code || cur_loc < afl_start_code /*|| !afl_area_ptr*/) // not needed because of static dummy buffer
|
||||
if (cur_loc > afl_end_code ||
|
||||
cur_loc < afl_start_code /*|| !afl_area_ptr*/) // not needed because of
|
||||
// static dummy buffer
|
||||
return;
|
||||
|
||||
/* Looks like QEMU always maps to fixed locations, so ASAN is not a
|
||||
/* Looks like QEMU always maps to fixed locations, so ASLR is not a
|
||||
concern. Phew. But instruction addresses may be aligned. Let's mangle
|
||||
the value to get something quasi-uniform. */
|
||||
|
||||
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
|
||||
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
|
||||
cur_loc &= MAP_SIZE - 1;
|
||||
|
||||
/* Implement probabilistic instrumentation by looking at scrambled block
|
||||
@ -71,7 +76,7 @@ static void afl_gen_trace(target_ulong cur_loc) {
|
||||
|
||||
if (cur_loc >= afl_inst_rms) return;
|
||||
|
||||
TCGTemp *args[1] = { tcgv_i64_temp( tcg_const_tl(cur_loc) ) };
|
||||
tcg_gen_afl_callN(afl_maybe_log, NULL, 1, args);
|
||||
|
||||
tcg_gen_afl_maybe_log_call(cur_loc);
|
||||
|
||||
}
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
diff --git a/linux-user/elfload.c b/linux-user/elfload.c
|
||||
index 5bccd2e2..94e928a4 100644
|
||||
index 5bccd2e2..fd7460b3 100644
|
||||
--- a/linux-user/elfload.c
|
||||
+++ b/linux-user/elfload.c
|
||||
@@ -20,6 +20,8 @@
|
||||
@ -11,16 +11,29 @@ index 5bccd2e2..94e928a4 100644
|
||||
/* from personality.h */
|
||||
|
||||
/*
|
||||
@@ -2301,6 +2303,8 @@ static void load_elf_image(const char *image_name, int image_fd,
|
||||
@@ -2301,6 +2303,21 @@ static void load_elf_image(const char *image_name, int image_fd,
|
||||
info->brk = 0;
|
||||
info->elf_flags = ehdr->e_flags;
|
||||
|
||||
+ if (!afl_entry_point) afl_entry_point = info->entry;
|
||||
+ if (!afl_entry_point) {
|
||||
+ char *ptr;
|
||||
+ if ((ptr = getenv("AFL_ENTRYPOINT")) != NULL) {
|
||||
+ afl_entry_point = strtoul(ptr, NULL, 16);
|
||||
+ } else {
|
||||
+ afl_entry_point = info->entry;
|
||||
+ }
|
||||
+#ifdef TARGET_ARM
|
||||
+ /* The least significant bit indicates Thumb mode. */
|
||||
+ afl_entry_point = afl_entry_point & ~(target_ulong)1;
|
||||
+#endif
|
||||
+ }
|
||||
+ if (getenv("AFL_DEBUG") != NULL)
|
||||
+ fprintf(stderr, "AFL forkserver entrypoint: %p\n", (void*)afl_entry_point);
|
||||
+
|
||||
for (i = 0; i < ehdr->e_phnum; i++) {
|
||||
struct elf_phdr *eppnt = phdr + i;
|
||||
if (eppnt->p_type == PT_LOAD) {
|
||||
@@ -2335,9 +2339,11 @@ static void load_elf_image(const char *image_name, int image_fd,
|
||||
@@ -2335,9 +2352,11 @@ static void load_elf_image(const char *image_name, int image_fd,
|
||||
if (elf_prot & PROT_EXEC) {
|
||||
if (vaddr < info->start_code) {
|
||||
info->start_code = vaddr;
|
||||
@ -32,3 +45,26 @@ index 5bccd2e2..94e928a4 100644
|
||||
}
|
||||
}
|
||||
if (elf_prot & PROT_WRITE) {
|
||||
@@ -2662,6 +2681,22 @@ int load_elf_binary(struct linux_binprm *bprm, struct image_info *info)
|
||||
change some of these later */
|
||||
bprm->p = setup_arg_pages(bprm, info);
|
||||
|
||||
+ // On PowerPC64 the entry point is the _function descriptor_
|
||||
+ // of the entry function. For AFL to properly initialize,
|
||||
+ // afl_entry_point needs to be set to the actual first instruction
|
||||
+ // as opposed executed by the target program. This as opposed to
|
||||
+ // where the function's descriptor sits in memory.
|
||||
+ // copied from PPC init_thread
|
||||
+#if defined(TARGET_PPC64) && !defined(TARGET_ABI32)
|
||||
+ if (get_ppc64_abi(infop) < 2) {
|
||||
+ uint64_t val;
|
||||
+ get_user_u64(val, infop->entry + 8);
|
||||
+ _regs->gpr[2] = val + infop->load_bias;
|
||||
+ get_user_u64(val, infop->entry);
|
||||
+ infop->entry = val + infop->load_bias;
|
||||
+ }
|
||||
+#endif
|
||||
+
|
||||
scratch = g_new0(char, TARGET_PAGE_SIZE);
|
||||
if (STACK_GROWS_DOWN) {
|
||||
bprm->p = copy_elf_strings(1, &bprm->filename, scratch,
|
||||
|
||||
@ -1,47 +0,0 @@
|
||||
--- a/linux-user/elfload.c 2019-06-03 13:06:40.755755923 +0200
|
||||
+++ b/linux-user/elfload.c 2019-06-03 13:33:01.315709801 +0200
|
||||
@@ -2303,7 +2303,20 @@
|
||||
info->brk = 0;
|
||||
info->elf_flags = ehdr->e_flags;
|
||||
|
||||
- if (!afl_entry_point) afl_entry_point = info->entry;
|
||||
+ if (!afl_entry_point) {
|
||||
+ char *ptr;
|
||||
+ if ((ptr = getenv("AFL_ENTRYPOINT")) != NULL) {
|
||||
+ afl_entry_point = strtoul(ptr, NULL, 16);
|
||||
+ } else {
|
||||
+ afl_entry_point = info->entry;
|
||||
+ }
|
||||
+#ifdef TARGET_ARM
|
||||
+ /* The least significant bit indicates Thumb mode. */
|
||||
+ afl_entry_point = afl_entry_point & ~(target_ulong)1;
|
||||
+#endif
|
||||
+ }
|
||||
+ if (getenv("AFL_DEBUG") != NULL)
|
||||
+ fprintf(stderr, "AFL forkserver entrypoint: %p\n", (void*)afl_entry_point);
|
||||
|
||||
for (i = 0; i < ehdr->e_phnum; i++) {
|
||||
struct elf_phdr *eppnt = phdr + i;
|
||||
@@ -2668,6 +2681,22 @@
|
||||
change some of these later */
|
||||
bprm->p = setup_arg_pages(bprm, info);
|
||||
|
||||
+ // On PowerPC64 the entry point is the _function descriptor_
|
||||
+ // of the entry function. For AFL to properly initialize,
|
||||
+ // afl_entry_point needs to be set to the actual first instruction
|
||||
+ // as opposed executed by the target program. This as opposed to
|
||||
+ // where the function's descriptor sits in memory.
|
||||
+ // copied from PPC init_thread
|
||||
+#if defined(TARGET_PPC64) && !defined(TARGET_ABI32)
|
||||
+ if (get_ppc64_abi(infop) < 2) {
|
||||
+ uint64_t val;
|
||||
+ get_user_u64(val, infop->entry + 8);
|
||||
+ _regs->gpr[2] = val + infop->load_bias;
|
||||
+ get_user_u64(val, infop->entry);
|
||||
+ infop->entry = val + infop->load_bias;
|
||||
+ }
|
||||
+#endif
|
||||
+
|
||||
scratch = g_new0(char, TARGET_PAGE_SIZE);
|
||||
if (STACK_GROWS_DOWN) {
|
||||
bprm->p = copy_elf_strings(1, &bprm->filename, scratch,
|
||||
33
qemu_mode/patches/i386-translate.diff
Normal file
33
qemu_mode/patches/i386-translate.diff
Normal file
@ -0,0 +1,33 @@
|
||||
diff --git a/target/i386/translate.c b/target/i386/translate.c
|
||||
index 0dd5fbe4..b95d341e 100644
|
||||
--- a/target/i386/translate.c
|
||||
+++ b/target/i386/translate.c
|
||||
@@ -32,6 +32,8 @@
|
||||
#include "trace-tcg.h"
|
||||
#include "exec/log.h"
|
||||
|
||||
+#include "../patches/afl-qemu-cpu-translate-inl.h"
|
||||
+
|
||||
#define PREFIX_REPZ 0x01
|
||||
#define PREFIX_REPNZ 0x02
|
||||
#define PREFIX_LOCK 0x04
|
||||
@@ -1343,9 +1345,11 @@ static void gen_op(DisasContext *s1, int op, TCGMemOp ot, int d)
|
||||
tcg_gen_atomic_fetch_add_tl(s1->cc_srcT, s1->A0, s1->T0,
|
||||
s1->mem_index, ot | MO_LE);
|
||||
tcg_gen_sub_tl(s1->T0, s1->cc_srcT, s1->T1);
|
||||
+ afl_gen_compcov(s1->pc, s1->cc_srcT, s1->T1, ot, d == OR_EAX);
|
||||
} else {
|
||||
tcg_gen_mov_tl(s1->cc_srcT, s1->T0);
|
||||
tcg_gen_sub_tl(s1->T0, s1->T0, s1->T1);
|
||||
+ afl_gen_compcov(s1->pc, s1->T0, s1->T1, ot, d == OR_EAX);
|
||||
gen_op_st_rm_T0_A0(s1, ot, d);
|
||||
}
|
||||
gen_op_update2_cc(s1);
|
||||
@@ -1389,6 +1393,7 @@ static void gen_op(DisasContext *s1, int op, TCGMemOp ot, int d)
|
||||
tcg_gen_mov_tl(cpu_cc_src, s1->T1);
|
||||
tcg_gen_mov_tl(s1->cc_srcT, s1->T0);
|
||||
tcg_gen_sub_tl(cpu_cc_dst, s1->T0, s1->T1);
|
||||
+ afl_gen_compcov(s1->pc, s1->T0, s1->T1, ot, d == OR_EAX);
|
||||
set_cc_op(s1, CC_OP_SUBB + ot);
|
||||
break;
|
||||
}
|
||||
@ -2,9 +2,10 @@ diff --git a/linux-user/syscall.c b/linux-user/syscall.c
|
||||
index 280137da..8c0e749f 100644
|
||||
--- a/linux-user/syscall.c
|
||||
+++ b/linux-user/syscall.c
|
||||
@@ -112,6 +112,8 @@
|
||||
@@ -112,6 +112,9 @@
|
||||
#include "qemu.h"
|
||||
#include "fd-trans.h"
|
||||
+#include <linux/sockios.h>
|
||||
|
||||
+extern unsigned int afl_forksrv_pid;
|
||||
+
|
||||
@ -32,4 +33,4 @@ index 280137da..8c0e749f 100644
|
||||
+ }
|
||||
|
||||
#ifdef TARGET_NR_set_robust_list
|
||||
case TARGET_NR_set_robust_list:
|
||||
case TARGET_NR_set_robust_list:
|
||||
@ -2,179 +2,12 @@ diff --git a/tcg/tcg.c b/tcg/tcg.c
|
||||
index e85133ef..54b9b390 100644
|
||||
--- a/tcg/tcg.c
|
||||
+++ b/tcg/tcg.c
|
||||
@@ -1612,6 +1612,176 @@ bool tcg_op_supported(TCGOpcode op)
|
||||
@@ -1612,6 +1612,9 @@ bool tcg_op_supported(TCGOpcode op)
|
||||
}
|
||||
}
|
||||
|
||||
+
|
||||
+/* Call the instrumentation function from the TCG IR */
|
||||
+void tcg_gen_afl_callN(void *func, TCGTemp *ret, int nargs, TCGTemp **args)
|
||||
+{
|
||||
+ int i, real_args, nb_rets, pi;
|
||||
+ unsigned sizemask, flags;
|
||||
+ TCGOp *op;
|
||||
+
|
||||
+ flags = 0;
|
||||
+ sizemask = 0;
|
||||
+
|
||||
+#if defined(__sparc__) && !defined(__arch64__) \
|
||||
+ && !defined(CONFIG_TCG_INTERPRETER)
|
||||
+ /* We have 64-bit values in one register, but need to pass as two
|
||||
+ separate parameters. Split them. */
|
||||
+ int orig_sizemask = sizemask;
|
||||
+ int orig_nargs = nargs;
|
||||
+ TCGv_i64 retl, reth;
|
||||
+ TCGTemp *split_args[MAX_OPC_PARAM];
|
||||
+
|
||||
+ retl = NULL;
|
||||
+ reth = NULL;
|
||||
+ if (sizemask != 0) {
|
||||
+ for (i = real_args = 0; i < nargs; ++i) {
|
||||
+ int is_64bit = sizemask & (1 << (i+1)*2);
|
||||
+ if (is_64bit) {
|
||||
+ TCGv_i64 orig = temp_tcgv_i64(args[i]);
|
||||
+ TCGv_i32 h = tcg_temp_new_i32();
|
||||
+ TCGv_i32 l = tcg_temp_new_i32();
|
||||
+ tcg_gen_extr_i64_i32(l, h, orig);
|
||||
+ split_args[real_args++] = tcgv_i32_temp(h);
|
||||
+ split_args[real_args++] = tcgv_i32_temp(l);
|
||||
+ } else {
|
||||
+ split_args[real_args++] = args[i];
|
||||
+ }
|
||||
+ }
|
||||
+ nargs = real_args;
|
||||
+ args = split_args;
|
||||
+ sizemask = 0;
|
||||
+ }
|
||||
+#elif defined(TCG_TARGET_EXTEND_ARGS) && TCG_TARGET_REG_BITS == 64
|
||||
+ for (i = 0; i < nargs; ++i) {
|
||||
+ int is_64bit = sizemask & (1 << (i+1)*2);
|
||||
+ int is_signed = sizemask & (2 << (i+1)*2);
|
||||
+ if (!is_64bit) {
|
||||
+ TCGv_i64 temp = tcg_temp_new_i64();
|
||||
+ TCGv_i64 orig = temp_tcgv_i64(args[i]);
|
||||
+ if (is_signed) {
|
||||
+ tcg_gen_ext32s_i64(temp, orig);
|
||||
+ } else {
|
||||
+ tcg_gen_ext32u_i64(temp, orig);
|
||||
+ }
|
||||
+ args[i] = tcgv_i64_temp(temp);
|
||||
+ }
|
||||
+ }
|
||||
+#endif /* TCG_TARGET_EXTEND_ARGS */
|
||||
+
|
||||
+ op = tcg_emit_op(INDEX_op_call);
|
||||
+
|
||||
+ pi = 0;
|
||||
+ if (ret != NULL) {
|
||||
+#if defined(__sparc__) && !defined(__arch64__) \
|
||||
+ && !defined(CONFIG_TCG_INTERPRETER)
|
||||
+ if (orig_sizemask & 1) {
|
||||
+ /* The 32-bit ABI is going to return the 64-bit value in
|
||||
+ the %o0/%o1 register pair. Prepare for this by using
|
||||
+ two return temporaries, and reassemble below. */
|
||||
+ retl = tcg_temp_new_i64();
|
||||
+ reth = tcg_temp_new_i64();
|
||||
+ op->args[pi++] = tcgv_i64_arg(reth);
|
||||
+ op->args[pi++] = tcgv_i64_arg(retl);
|
||||
+ nb_rets = 2;
|
||||
+ } else {
|
||||
+ op->args[pi++] = temp_arg(ret);
|
||||
+ nb_rets = 1;
|
||||
+ }
|
||||
+#else
|
||||
+ if (TCG_TARGET_REG_BITS < 64 && (sizemask & 1)) {
|
||||
+#ifdef HOST_WORDS_BIGENDIAN
|
||||
+ op->args[pi++] = temp_arg(ret + 1);
|
||||
+ op->args[pi++] = temp_arg(ret);
|
||||
+#else
|
||||
+ op->args[pi++] = temp_arg(ret);
|
||||
+ op->args[pi++] = temp_arg(ret + 1);
|
||||
+#endif
|
||||
+ nb_rets = 2;
|
||||
+ } else {
|
||||
+ op->args[pi++] = temp_arg(ret);
|
||||
+ nb_rets = 1;
|
||||
+ }
|
||||
+#endif
|
||||
+ } else {
|
||||
+ nb_rets = 0;
|
||||
+ }
|
||||
+ TCGOP_CALLO(op) = nb_rets;
|
||||
+
|
||||
+ real_args = 0;
|
||||
+ for (i = 0; i < nargs; i++) {
|
||||
+ int is_64bit = sizemask & (1 << (i+1)*2);
|
||||
+ if (TCG_TARGET_REG_BITS < 64 && is_64bit) {
|
||||
+#ifdef TCG_TARGET_CALL_ALIGN_ARGS
|
||||
+ /* some targets want aligned 64 bit args */
|
||||
+ if (real_args & 1) {
|
||||
+ op->args[pi++] = TCG_CALL_DUMMY_ARG;
|
||||
+ real_args++;
|
||||
+ }
|
||||
+#endif
|
||||
+ /* If stack grows up, then we will be placing successive
|
||||
+ arguments at lower addresses, which means we need to
|
||||
+ reverse the order compared to how we would normally
|
||||
+ treat either big or little-endian. For those arguments
|
||||
+ that will wind up in registers, this still works for
|
||||
+ HPPA (the only current STACK_GROWSUP target) since the
|
||||
+ argument registers are *also* allocated in decreasing
|
||||
+ order. If another such target is added, this logic may
|
||||
+ have to get more complicated to differentiate between
|
||||
+ stack arguments and register arguments. */
|
||||
+#if defined(HOST_WORDS_BIGENDIAN) != defined(TCG_TARGET_STACK_GROWSUP)
|
||||
+ op->args[pi++] = temp_arg(args[i] + 1);
|
||||
+ op->args[pi++] = temp_arg(args[i]);
|
||||
+#else
|
||||
+ op->args[pi++] = temp_arg(args[i]);
|
||||
+ op->args[pi++] = temp_arg(args[i] + 1);
|
||||
+#endif
|
||||
+ real_args += 2;
|
||||
+ continue;
|
||||
+ }
|
||||
+
|
||||
+ op->args[pi++] = temp_arg(args[i]);
|
||||
+ real_args++;
|
||||
+ }
|
||||
+ op->args[pi++] = (uintptr_t)func;
|
||||
+ op->args[pi++] = flags;
|
||||
+ TCGOP_CALLI(op) = real_args;
|
||||
+
|
||||
+ /* Make sure the fields didn't overflow. */
|
||||
+ tcg_debug_assert(TCGOP_CALLI(op) == real_args);
|
||||
+ tcg_debug_assert(pi <= ARRAY_SIZE(op->args));
|
||||
+
|
||||
+#if defined(__sparc__) && !defined(__arch64__) \
|
||||
+ && !defined(CONFIG_TCG_INTERPRETER)
|
||||
+ /* Free all of the parts we allocated above. */
|
||||
+ for (i = real_args = 0; i < orig_nargs; ++i) {
|
||||
+ int is_64bit = orig_sizemask & (1 << (i+1)*2);
|
||||
+ if (is_64bit) {
|
||||
+ tcg_temp_free_internal(args[real_args++]);
|
||||
+ tcg_temp_free_internal(args[real_args++]);
|
||||
+ } else {
|
||||
+ real_args++;
|
||||
+ }
|
||||
+ }
|
||||
+ if (orig_sizemask & 1) {
|
||||
+ /* The 32-bit ABI returned two 32-bit pieces. Re-assemble them.
|
||||
+ Note that describing these as TCGv_i64 eliminates an unnecessary
|
||||
+ zero-extension that tcg_gen_concat_i32_i64 would create. */
|
||||
+ tcg_gen_concat32_i64(temp_tcgv_i64(ret), retl, reth);
|
||||
+ tcg_temp_free_i64(retl);
|
||||
+ tcg_temp_free_i64(reth);
|
||||
+ }
|
||||
+#elif defined(TCG_TARGET_EXTEND_ARGS) && TCG_TARGET_REG_BITS == 64
|
||||
+ for (i = 0; i < nargs; ++i) {
|
||||
+ int is_64bit = sizemask & (1 << (i+1)*2);
|
||||
+ if (!is_64bit) {
|
||||
+ tcg_temp_free_internal(args[i]);
|
||||
+ }
|
||||
+ }
|
||||
+#endif /* TCG_TARGET_EXTEND_ARGS */
|
||||
+}
|
||||
+
|
||||
+#include "../../patches/afl-qemu-tcg-inl.h"
|
||||
+
|
||||
/* Note: we convert the 64 bit args to 32 bit and do some alignment
|
||||
and endian swap. Maybe it would be better to do the alignment
|
||||
|
||||
22
src/README.src
Normal file
22
src/README.src
Normal file
@ -0,0 +1,22 @@
|
||||
Quick explanation about the files here:
|
||||
|
||||
afl-analyze.c - afl-analyze binary tool
|
||||
afl-as.c - afl-as binary tool
|
||||
afl-gotcpu.c - afl-gotcpu binary tool
|
||||
afl-showmap.c - afl-showmap binary tool
|
||||
afl-tmin.c - afl-tmin binary tool
|
||||
afl-fuzz.c - afl-fuzz binary tool (just main() and usage())
|
||||
afl-fuzz-bitmap.c - afl-fuzz bitmap handling
|
||||
afl-fuzz-extras.c - afl-fuzz the *extra* function calls
|
||||
afl-fuzz-globals.c - afl-fuzz global variables
|
||||
afl-fuzz-init.c - afl-fuzz initialization
|
||||
afl-fuzz-misc.c - afl-fuzz misc functions
|
||||
afl-fuzz-one.c - afl-fuzz fuzzer_one big loop, this is where the mutation is happening
|
||||
afl-fuzz-python.c - afl-fuzz the python mutator extension
|
||||
afl-fuzz-queue.c - afl-fuzz handling the queue
|
||||
afl-fuzz-run.c - afl-fuzz running the target
|
||||
afl-fuzz-stats.c - afl-fuzz writing the statistics file
|
||||
afl-gcc.c - afl-gcc binary tool (deprecated)
|
||||
afl-common.c - common functions, used by afl-analyze, afl-fuzz, afl-showmap and afl-tmin
|
||||
afl-forkserver.c - forkserver implementation, used by afl-fuzz and afl-tmin
|
||||
afl-sharedmem.c - sharedmem implementation, used by afl-fuzz and afl-tmin
|
||||
@ -1,10 +1,15 @@
|
||||
/*
|
||||
american fuzzy lop - file format analyzer
|
||||
-----------------------------------------
|
||||
american fuzzy lop++ - file format analyzer
|
||||
-------------------------------------------
|
||||
|
||||
Written and maintained by Michal Zalewski <lcamtuf@google.com>
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
@ -21,11 +26,16 @@
|
||||
|
||||
#define AFL_MAIN
|
||||
|
||||
#ifdef __ANDROID__
|
||||
#include "android-ashmem.h"
|
||||
#endif
|
||||
#include "config.h"
|
||||
#include "types.h"
|
||||
#include "debug.h"
|
||||
#include "alloc-inl.h"
|
||||
#include "hash.h"
|
||||
#include "sharedmem.h"
|
||||
#include "common.h"
|
||||
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
@ -45,62 +55,59 @@
|
||||
#include <sys/types.h>
|
||||
#include <sys/resource.h>
|
||||
|
||||
static s32 child_pid; /* PID of the tested program */
|
||||
static s32 child_pid; /* PID of the tested program */
|
||||
|
||||
static u8* trace_bits; /* SHM with instrumentation bitmap */
|
||||
u8* trace_bits; /* SHM with instrumentation bitmap */
|
||||
|
||||
static u8 *in_file, /* Analyzer input test case */
|
||||
*prog_in, /* Targeted program input file */
|
||||
*target_path, /* Path to target binary */
|
||||
*doc_path; /* Path to docs */
|
||||
static u8 *in_file, /* Analyzer input test case */
|
||||
*prog_in, /* Targeted program input file */
|
||||
*target_path, /* Path to target binary */
|
||||
*doc_path; /* Path to docs */
|
||||
|
||||
static u8 *in_data; /* Input data for analysis */
|
||||
static u8* in_data; /* Input data for analysis */
|
||||
|
||||
static u32 in_len, /* Input data length */
|
||||
orig_cksum, /* Original checksum */
|
||||
total_execs, /* Total number of execs */
|
||||
exec_hangs, /* Total number of hangs */
|
||||
exec_tmout = EXEC_TIMEOUT; /* Exec timeout (ms) */
|
||||
static u32 in_len, /* Input data length */
|
||||
orig_cksum, /* Original checksum */
|
||||
total_execs, /* Total number of execs */
|
||||
exec_hangs, /* Total number of hangs */
|
||||
exec_tmout = EXEC_TIMEOUT; /* Exec timeout (ms) */
|
||||
|
||||
static u64 mem_limit = MEM_LIMIT; /* Memory limit (MB) */
|
||||
static u64 mem_limit = MEM_LIMIT; /* Memory limit (MB) */
|
||||
|
||||
static s32 shm_id, /* ID of the SHM region */
|
||||
dev_null_fd = -1; /* FD to /dev/null */
|
||||
static s32 dev_null_fd = -1; /* FD to /dev/null */
|
||||
|
||||
static u8 edges_only, /* Ignore hit counts? */
|
||||
use_hex_offsets, /* Show hex offsets? */
|
||||
use_stdin = 1; /* Use stdin for program input? */
|
||||
|
||||
static volatile u8
|
||||
stop_soon, /* Ctrl-C pressed? */
|
||||
child_timed_out; /* Child timed out? */
|
||||
static u8 edges_only, /* Ignore hit counts? */
|
||||
use_hex_offsets, /* Show hex offsets? */
|
||||
use_stdin = 1; /* Use stdin for program input? */
|
||||
|
||||
static volatile u8 stop_soon, /* Ctrl-C pressed? */
|
||||
child_timed_out; /* Child timed out? */
|
||||
|
||||
/* Constants used for describing byte behavior. */
|
||||
|
||||
#define RESP_NONE 0x00 /* Changing byte is a no-op. */
|
||||
#define RESP_MINOR 0x01 /* Some changes have no effect. */
|
||||
#define RESP_VARIABLE 0x02 /* Changes produce variable paths. */
|
||||
#define RESP_FIXED 0x03 /* Changes produce fixed patterns. */
|
||||
#define RESP_NONE 0x00 /* Changing byte is a no-op. */
|
||||
#define RESP_MINOR 0x01 /* Some changes have no effect. */
|
||||
#define RESP_VARIABLE 0x02 /* Changes produce variable paths. */
|
||||
#define RESP_FIXED 0x03 /* Changes produce fixed patterns. */
|
||||
|
||||
#define RESP_LEN 0x04 /* Potential length field */
|
||||
#define RESP_CKSUM 0x05 /* Potential checksum */
|
||||
#define RESP_SUSPECT 0x06 /* Potential "suspect" blob */
|
||||
#define RESP_LEN 0x04 /* Potential length field */
|
||||
#define RESP_CKSUM 0x05 /* Potential checksum */
|
||||
#define RESP_SUSPECT 0x06 /* Potential "suspect" blob */
|
||||
|
||||
|
||||
/* Classify tuple counts. This is a slow & naive version, but good enough here. */
|
||||
/* Classify tuple counts. This is a slow & naive version, but good enough here.
|
||||
*/
|
||||
|
||||
static u8 count_class_lookup[256] = {
|
||||
|
||||
[0] = 0,
|
||||
[1] = 1,
|
||||
[2] = 2,
|
||||
[3] = 4,
|
||||
[4 ... 7] = 8,
|
||||
[8 ... 15] = 16,
|
||||
[16 ... 31] = 32,
|
||||
[32 ... 127] = 64,
|
||||
[128 ... 255] = 128
|
||||
[0] = 0,
|
||||
[1] = 1,
|
||||
[2] = 2,
|
||||
[3] = 4,
|
||||
[4 ... 7] = 8,
|
||||
[8 ... 15] = 16,
|
||||
[16 ... 31] = 32,
|
||||
[32 ... 127] = 64,
|
||||
[128 ... 255] = 128
|
||||
|
||||
};
|
||||
|
||||
@ -111,87 +118,62 @@ static void classify_counts(u8* mem) {
|
||||
if (edges_only) {
|
||||
|
||||
while (i--) {
|
||||
|
||||
if (*mem) *mem = 1;
|
||||
mem++;
|
||||
|
||||
}
|
||||
|
||||
} else {
|
||||
|
||||
while (i--) {
|
||||
|
||||
*mem = count_class_lookup[*mem];
|
||||
mem++;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* See if any bytes are set in the bitmap. */
|
||||
|
||||
static inline u8 anything_set(void) {
|
||||
|
||||
u32* ptr = (u32*)trace_bits;
|
||||
u32 i = (MAP_SIZE >> 2);
|
||||
u32 i = (MAP_SIZE >> 2);
|
||||
|
||||
while (i--) if (*(ptr++)) return 1;
|
||||
while (i--)
|
||||
if (*(ptr++)) return 1;
|
||||
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
/* Get rid of temp files (atexit handler). */
|
||||
|
||||
/* Get rid of shared memory and temp files (atexit handler). */
|
||||
static void at_exit_handler(void) {
|
||||
|
||||
static void remove_shm(void) {
|
||||
|
||||
unlink(prog_in); /* Ignore errors */
|
||||
shmctl(shm_id, IPC_RMID, NULL);
|
||||
unlink(prog_in); /* Ignore errors */
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Configure shared memory. */
|
||||
|
||||
static void setup_shm(void) {
|
||||
|
||||
u8* shm_str;
|
||||
|
||||
shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600);
|
||||
|
||||
if (shm_id < 0) PFATAL("shmget() failed");
|
||||
|
||||
atexit(remove_shm);
|
||||
|
||||
shm_str = alloc_printf("%d", shm_id);
|
||||
|
||||
setenv(SHM_ENV_VAR, shm_str, 1);
|
||||
|
||||
ck_free(shm_str);
|
||||
|
||||
trace_bits = shmat(shm_id, NULL, 0);
|
||||
|
||||
if (!trace_bits) PFATAL("shmat() failed");
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Read initial file. */
|
||||
|
||||
static void read_initial_file(void) {
|
||||
|
||||
struct stat st;
|
||||
s32 fd = open(in_file, O_RDONLY);
|
||||
s32 fd = open(in_file, O_RDONLY);
|
||||
|
||||
if (fd < 0) PFATAL("Unable to open '%s'", in_file);
|
||||
|
||||
if (fstat(fd, &st) || !st.st_size)
|
||||
FATAL("Zero-sized input file.");
|
||||
if (fstat(fd, &st) || !st.st_size) FATAL("Zero-sized input file.");
|
||||
|
||||
if (st.st_size >= TMIN_MAX_FILE)
|
||||
FATAL("Input file is too large (%u MB max)", TMIN_MAX_FILE / 1024 / 1024);
|
||||
|
||||
in_len = st.st_size;
|
||||
in_len = st.st_size;
|
||||
in_data = ck_alloc_nozero(in_len);
|
||||
|
||||
ck_read(fd, in_data, in_len, in_file);
|
||||
@ -202,14 +184,13 @@ static void read_initial_file(void) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Write output file. */
|
||||
|
||||
static s32 write_to_file(u8* path, u8* mem, u32 len) {
|
||||
|
||||
s32 ret;
|
||||
|
||||
unlink(path); /* Ignore errors */
|
||||
unlink(path); /* Ignore errors */
|
||||
|
||||
ret = open(path, O_RDWR | O_CREAT | O_EXCL, 0600);
|
||||
|
||||
@ -223,7 +204,6 @@ static s32 write_to_file(u8* path, u8* mem, u32 len) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Handle timeout signal. */
|
||||
|
||||
static void handle_timeout(int sig) {
|
||||
@ -233,14 +213,13 @@ static void handle_timeout(int sig) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Execute target application. Returns exec checksum, or 0 if program
|
||||
times out. */
|
||||
|
||||
static u32 run_target(char** argv, u8* mem, u32 len, u8 first_run) {
|
||||
|
||||
static struct itimerval it;
|
||||
int status = 0;
|
||||
int status = 0;
|
||||
|
||||
s32 prog_in_fd;
|
||||
u32 cksum;
|
||||
@ -259,8 +238,7 @@ static u32 run_target(char** argv, u8* mem, u32 len, u8 first_run) {
|
||||
struct rlimit r;
|
||||
|
||||
if (dup2(use_stdin ? prog_in_fd : dev_null_fd, 0) < 0 ||
|
||||
dup2(dev_null_fd, 1) < 0 ||
|
||||
dup2(dev_null_fd, 2) < 0) {
|
||||
dup2(dev_null_fd, 1) < 0 || dup2(dev_null_fd, 2) < 0) {
|
||||
|
||||
*(u32*)trace_bits = EXEC_FAIL_SIG;
|
||||
PFATAL("dup2() failed");
|
||||
@ -276,18 +254,18 @@ static u32 run_target(char** argv, u8* mem, u32 len, u8 first_run) {
|
||||
|
||||
#ifdef RLIMIT_AS
|
||||
|
||||
setrlimit(RLIMIT_AS, &r); /* Ignore errors */
|
||||
setrlimit(RLIMIT_AS, &r); /* Ignore errors */
|
||||
|
||||
#else
|
||||
|
||||
setrlimit(RLIMIT_DATA, &r); /* Ignore errors */
|
||||
setrlimit(RLIMIT_DATA, &r); /* Ignore errors */
|
||||
|
||||
#endif /* ^RLIMIT_AS */
|
||||
#endif /* ^RLIMIT_AS */
|
||||
|
||||
}
|
||||
|
||||
r.rlim_max = r.rlim_cur = 0;
|
||||
setrlimit(RLIMIT_CORE, &r); /* Ignore errors */
|
||||
setrlimit(RLIMIT_CORE, &r); /* Ignore errors */
|
||||
|
||||
execv(target_path, argv);
|
||||
|
||||
@ -325,8 +303,10 @@ static u32 run_target(char** argv, u8* mem, u32 len, u8 first_run) {
|
||||
total_execs++;
|
||||
|
||||
if (stop_soon) {
|
||||
|
||||
SAYF(cRST cLRD "\n+++ Analysis aborted by user +++\n" cRST);
|
||||
exit(1);
|
||||
|
||||
}
|
||||
|
||||
/* Always discard inputs that time out. */
|
||||
@ -357,7 +337,6 @@ static u32 run_target(char** argv, u8* mem, u32 len, u8 first_run) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
#ifdef USE_COLOR
|
||||
|
||||
/* Helper function to display a human-readable character. */
|
||||
@ -375,23 +354,24 @@ static void show_char(u8 val) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Show the legend */
|
||||
|
||||
static void show_legend(void) {
|
||||
|
||||
SAYF(" " cLGR bgGRA " 01 " cRST " - no-op block "
|
||||
cBLK bgLGN " 01 " cRST " - suspected length field\n"
|
||||
" " cBRI bgGRA " 01 " cRST " - superficial content "
|
||||
cBLK bgYEL " 01 " cRST " - suspected cksum or magic int\n"
|
||||
" " cBLK bgCYA " 01 " cRST " - critical stream "
|
||||
cBLK bgLRD " 01 " cRST " - suspected checksummed block\n"
|
||||
SAYF(" " cLGR bgGRA " 01 " cRST " - no-op block " cBLK bgLGN
|
||||
" 01 " cRST
|
||||
" - suspected length field\n"
|
||||
" " cBRI bgGRA " 01 " cRST " - superficial content " cBLK bgYEL
|
||||
" 01 " cRST
|
||||
" - suspected cksum or magic int\n"
|
||||
" " cBLK bgCYA " 01 " cRST " - critical stream " cBLK bgLRD
|
||||
" 01 " cRST
|
||||
" - suspected checksummed block\n"
|
||||
" " cBLK bgMGN " 01 " cRST " - \"magic value\" section\n\n");
|
||||
|
||||
}
|
||||
|
||||
#endif /* USE_COLOR */
|
||||
|
||||
#endif /* USE_COLOR */
|
||||
|
||||
/* Interpret and report a pattern in the input file. */
|
||||
|
||||
@ -405,9 +385,9 @@ static void dump_hex(u8* buf, u32 len, u8* b_data) {
|
||||
u32 rlen = 1, off;
|
||||
#else
|
||||
u32 rlen = 1;
|
||||
#endif /* ^USE_COLOR */
|
||||
#endif /* ^USE_COLOR */
|
||||
|
||||
u8 rtype = b_data[i] & 0x0f;
|
||||
u8 rtype = b_data[i] & 0x0f;
|
||||
|
||||
/* Look ahead to determine the length of run. */
|
||||
|
||||
@ -426,51 +406,61 @@ static void dump_hex(u8* buf, u32 len, u8* b_data) {
|
||||
|
||||
case 2: {
|
||||
|
||||
u16 val = *(u16*)(in_data + i);
|
||||
u16 val = *(u16*)(in_data + i);
|
||||
|
||||
/* Small integers may be length fields. */
|
||||
/* Small integers may be length fields. */
|
||||
|
||||
if (val && (val <= in_len || SWAP16(val) <= in_len)) {
|
||||
rtype = RESP_LEN;
|
||||
break;
|
||||
}
|
||||
|
||||
/* Uniform integers may be checksums. */
|
||||
|
||||
if (val && abs(in_data[i] - in_data[i + 1]) > 32) {
|
||||
rtype = RESP_CKSUM;
|
||||
break;
|
||||
}
|
||||
if (val && (val <= in_len || SWAP16(val) <= in_len)) {
|
||||
|
||||
rtype = RESP_LEN;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
/* Uniform integers may be checksums. */
|
||||
|
||||
if (val && abs(in_data[i] - in_data[i + 1]) > 32) {
|
||||
|
||||
rtype = RESP_CKSUM;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 4: {
|
||||
|
||||
u32 val = *(u32*)(in_data + i);
|
||||
u32 val = *(u32*)(in_data + i);
|
||||
|
||||
/* Small integers may be length fields. */
|
||||
/* Small integers may be length fields. */
|
||||
|
||||
if (val && (val <= in_len || SWAP32(val) <= in_len)) {
|
||||
rtype = RESP_LEN;
|
||||
break;
|
||||
}
|
||||
|
||||
/* Uniform integers may be checksums. */
|
||||
|
||||
if (val && (in_data[i] >> 7 != in_data[i + 1] >> 7 ||
|
||||
in_data[i] >> 7 != in_data[i + 2] >> 7 ||
|
||||
in_data[i] >> 7 != in_data[i + 3] >> 7)) {
|
||||
rtype = RESP_CKSUM;
|
||||
break;
|
||||
}
|
||||
if (val && (val <= in_len || SWAP32(val) <= in_len)) {
|
||||
|
||||
rtype = RESP_LEN;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 1: case 3: case 5 ... MAX_AUTO_EXTRA - 1: break;
|
||||
/* Uniform integers may be checksums. */
|
||||
|
||||
if (val && (in_data[i] >> 7 != in_data[i + 1] >> 7 ||
|
||||
in_data[i] >> 7 != in_data[i + 2] >> 7 ||
|
||||
in_data[i] >> 7 != in_data[i + 3] >> 7)) {
|
||||
|
||||
rtype = RESP_CKSUM;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 1:
|
||||
case 3:
|
||||
case 5 ... MAX_AUTO_EXTRA - 1: break;
|
||||
|
||||
default: rtype = RESP_SUSPECT;
|
||||
|
||||
@ -499,19 +489,22 @@ static void dump_hex(u8* buf, u32 len, u8* b_data) {
|
||||
|
||||
switch (rtype) {
|
||||
|
||||
case RESP_NONE: SAYF(cLGR bgGRA); break;
|
||||
case RESP_MINOR: SAYF(cBRI bgGRA); break;
|
||||
case RESP_NONE: SAYF(cLGR bgGRA); break;
|
||||
case RESP_MINOR: SAYF(cBRI bgGRA); break;
|
||||
case RESP_VARIABLE: SAYF(cBLK bgCYA); break;
|
||||
case RESP_FIXED: SAYF(cBLK bgMGN); break;
|
||||
case RESP_LEN: SAYF(cBLK bgLGN); break;
|
||||
case RESP_CKSUM: SAYF(cBLK bgYEL); break;
|
||||
case RESP_SUSPECT: SAYF(cBLK bgLRD); break;
|
||||
case RESP_FIXED: SAYF(cBLK bgMGN); break;
|
||||
case RESP_LEN: SAYF(cBLK bgLGN); break;
|
||||
case RESP_CKSUM: SAYF(cBLK bgYEL); break;
|
||||
case RESP_SUSPECT: SAYF(cBLK bgLRD); break;
|
||||
|
||||
}
|
||||
|
||||
show_char(in_data[i + off]);
|
||||
|
||||
if (off != rlen - 1 && (i + off + 1) % 16) SAYF(" "); else SAYF(cRST " ");
|
||||
if (off != rlen - 1 && (i + off + 1) % 16)
|
||||
SAYF(" ");
|
||||
else
|
||||
SAYF(cRST " ");
|
||||
|
||||
}
|
||||
|
||||
@ -524,17 +517,17 @@ static void dump_hex(u8* buf, u32 len, u8* b_data) {
|
||||
|
||||
switch (rtype) {
|
||||
|
||||
case RESP_NONE: SAYF("no-op block\n"); break;
|
||||
case RESP_MINOR: SAYF("superficial content\n"); break;
|
||||
case RESP_NONE: SAYF("no-op block\n"); break;
|
||||
case RESP_MINOR: SAYF("superficial content\n"); break;
|
||||
case RESP_VARIABLE: SAYF("critical stream\n"); break;
|
||||
case RESP_FIXED: SAYF("\"magic value\" section\n"); break;
|
||||
case RESP_LEN: SAYF("suspected length field\n"); break;
|
||||
case RESP_CKSUM: SAYF("suspected cksum or magic int\n"); break;
|
||||
case RESP_SUSPECT: SAYF("suspected checksummed block\n"); break;
|
||||
case RESP_FIXED: SAYF("\"magic value\" section\n"); break;
|
||||
case RESP_LEN: SAYF("suspected length field\n"); break;
|
||||
case RESP_CKSUM: SAYF("suspected cksum or magic int\n"); break;
|
||||
case RESP_SUSPECT: SAYF("suspected checksummed block\n"); break;
|
||||
|
||||
}
|
||||
|
||||
#endif /* ^USE_COLOR */
|
||||
#endif /* ^USE_COLOR */
|
||||
|
||||
i += rlen - 1;
|
||||
|
||||
@ -542,12 +535,10 @@ static void dump_hex(u8* buf, u32 len, u8* b_data) {
|
||||
|
||||
#ifdef USE_COLOR
|
||||
SAYF(cRST "\n");
|
||||
#endif /* USE_COLOR */
|
||||
#endif /* USE_COLOR */
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
/* Actually analyze! */
|
||||
|
||||
static void analyze(char** argv) {
|
||||
@ -558,13 +549,13 @@ static void analyze(char** argv) {
|
||||
u8* b_data = ck_alloc(in_len + 1);
|
||||
u8 seq_byte = 0;
|
||||
|
||||
b_data[in_len] = 0xff; /* Intentional terminator. */
|
||||
b_data[in_len] = 0xff; /* Intentional terminator. */
|
||||
|
||||
ACTF("Analyzing input file (this may take a while)...\n");
|
||||
|
||||
#ifdef USE_COLOR
|
||||
show_legend();
|
||||
#endif /* USE_COLOR */
|
||||
#endif /* USE_COLOR */
|
||||
|
||||
for (i = 0; i < in_len; i++) {
|
||||
|
||||
@ -609,12 +600,15 @@ static void analyze(char** argv) {
|
||||
|
||||
b_data[i] = RESP_FIXED;
|
||||
|
||||
} else b_data[i] = RESP_VARIABLE;
|
||||
} else
|
||||
|
||||
b_data[i] = RESP_VARIABLE;
|
||||
|
||||
/* When all checksums change, flip most significant bit of b_data. */
|
||||
|
||||
if (prev_xff != xor_ff && prev_x01 != xor_01 &&
|
||||
prev_s10 != sub_10 && prev_a10 != add_10) seq_byte ^= 0x80;
|
||||
if (prev_xff != xor_ff && prev_x01 != xor_01 && prev_s10 != sub_10 &&
|
||||
prev_a10 != add_10)
|
||||
seq_byte ^= 0x80;
|
||||
|
||||
b_data[i] |= seq_byte;
|
||||
|
||||
@ -623,7 +617,7 @@ static void analyze(char** argv) {
|
||||
prev_s10 = sub_10;
|
||||
prev_a10 = add_10;
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
dump_hex(in_data, in_len, b_data);
|
||||
|
||||
@ -640,8 +634,6 @@ static void analyze(char** argv) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
/* Handle Ctrl-C and the like. */
|
||||
|
||||
static void handle_stop_sig(int sig) {
|
||||
@ -652,7 +644,6 @@ static void handle_stop_sig(int sig) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Do basic preparations - persistent fds, filenames, etc. */
|
||||
|
||||
static void set_up_environment(void) {
|
||||
@ -696,18 +687,20 @@ static void set_up_environment(void) {
|
||||
if (x) {
|
||||
|
||||
if (!strstr(x, "exit_code=" STRINGIFY(MSAN_ERROR)))
|
||||
FATAL("Custom MSAN_OPTIONS set without exit_code="
|
||||
STRINGIFY(MSAN_ERROR) " - please fix!");
|
||||
FATAL("Custom MSAN_OPTIONS set without exit_code=" STRINGIFY(
|
||||
MSAN_ERROR) " - please fix!");
|
||||
|
||||
if (!strstr(x, "symbolize=0"))
|
||||
FATAL("Custom MSAN_OPTIONS set without symbolize=0 - please fix!");
|
||||
|
||||
}
|
||||
|
||||
setenv("ASAN_OPTIONS", "abort_on_error=1:"
|
||||
"detect_leaks=0:"
|
||||
"symbolize=0:"
|
||||
"allocator_may_return_null=1", 0);
|
||||
setenv("ASAN_OPTIONS",
|
||||
"abort_on_error=1:"
|
||||
"detect_leaks=0:"
|
||||
"symbolize=0:"
|
||||
"allocator_may_return_null=1",
|
||||
0);
|
||||
|
||||
setenv("MSAN_OPTIONS", "exit_code=" STRINGIFY(MSAN_ERROR) ":"
|
||||
"symbolize=0:"
|
||||
@ -716,21 +709,22 @@ static void set_up_environment(void) {
|
||||
"msan_track_origins=0", 0);
|
||||
|
||||
if (getenv("AFL_PRELOAD")) {
|
||||
|
||||
setenv("LD_PRELOAD", getenv("AFL_PRELOAD"), 1);
|
||||
setenv("DYLD_INSERT_LIBRARIES", getenv("AFL_PRELOAD"), 1);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Setup signal handlers, duh. */
|
||||
|
||||
static void setup_signal_handlers(void) {
|
||||
|
||||
struct sigaction sa;
|
||||
|
||||
sa.sa_handler = NULL;
|
||||
sa.sa_flags = SA_RESTART;
|
||||
sa.sa_handler = NULL;
|
||||
sa.sa_flags = SA_RESTART;
|
||||
sa.sa_sigaction = NULL;
|
||||
|
||||
sigemptyset(&sa.sa_mask);
|
||||
@ -749,84 +743,42 @@ static void setup_signal_handlers(void) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Detect @@ in args. */
|
||||
|
||||
static void detect_file_args(char** argv) {
|
||||
|
||||
u32 i = 0;
|
||||
u8* cwd = getcwd(NULL, 0);
|
||||
|
||||
if (!cwd) PFATAL("getcwd() failed");
|
||||
|
||||
while (argv[i]) {
|
||||
|
||||
u8* aa_loc = strstr(argv[i], "@@");
|
||||
|
||||
if (aa_loc) {
|
||||
|
||||
u8 *aa_subst, *n_arg;
|
||||
|
||||
/* Be sure that we're always using fully-qualified paths. */
|
||||
|
||||
if (prog_in[0] == '/') aa_subst = prog_in;
|
||||
else aa_subst = alloc_printf("%s/%s", cwd, prog_in);
|
||||
|
||||
/* Construct a replacement argv value. */
|
||||
|
||||
*aa_loc = 0;
|
||||
n_arg = alloc_printf("%s%s%s", argv[i], aa_subst, aa_loc + 2);
|
||||
argv[i] = n_arg;
|
||||
*aa_loc = '@';
|
||||
|
||||
if (prog_in[0] != '/') ck_free(aa_subst);
|
||||
|
||||
}
|
||||
|
||||
i++;
|
||||
|
||||
}
|
||||
|
||||
free(cwd); /* not tracked */
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Display usage hints. */
|
||||
|
||||
static void usage(u8* argv0) {
|
||||
|
||||
SAYF("\n%s [ options ] -- /path/to/target_app [ ... ]\n\n"
|
||||
SAYF(
|
||||
"\n%s [ options ] -- /path/to/target_app [ ... ]\n\n"
|
||||
|
||||
"Required parameters:\n\n"
|
||||
"Required parameters:\n\n"
|
||||
|
||||
" -i file - input test case to be analyzed by the tool\n"
|
||||
" -i file - input test case to be analyzed by the tool\n"
|
||||
|
||||
"Execution control settings:\n\n"
|
||||
"Execution control settings:\n\n"
|
||||
|
||||
" -f file - input file read by the tested program (stdin)\n"
|
||||
" -t msec - timeout for each run (%u ms)\n"
|
||||
" -m megs - memory limit for child process (%u MB)\n"
|
||||
" -Q - use binary-only instrumentation (QEMU mode)\n\n"
|
||||
" -f file - input file read by the tested program (stdin)\n"
|
||||
" -t msec - timeout for each run (%d ms)\n"
|
||||
" -m megs - memory limit for child process (%d MB)\n"
|
||||
" -Q - use binary-only instrumentation (QEMU mode)\n"
|
||||
" -U - use unicorn-based instrumentation (Unicorn mode)\n\n"
|
||||
|
||||
"Analysis settings:\n\n"
|
||||
"Analysis settings:\n\n"
|
||||
|
||||
" -e - look for edge coverage only, ignore hit counts\n\n"
|
||||
" -e - look for edge coverage only, ignore hit counts\n\n"
|
||||
|
||||
"For additional tips, please consult %s/README.\n\n",
|
||||
"For additional tips, please consult %s/README.\n\n",
|
||||
|
||||
argv0, EXEC_TIMEOUT, MEM_LIMIT, doc_path);
|
||||
argv0, EXEC_TIMEOUT, MEM_LIMIT, doc_path);
|
||||
|
||||
exit(1);
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Find binary. */
|
||||
|
||||
static void find_binary(u8* fname) {
|
||||
|
||||
u8* env_path = 0;
|
||||
u8* env_path = 0;
|
||||
struct stat st;
|
||||
|
||||
if (strchr(fname, '/') || !(env_path = getenv("PATH"))) {
|
||||
@ -849,7 +801,9 @@ static void find_binary(u8* fname) {
|
||||
memcpy(cur_elem, env_path, delim - env_path);
|
||||
delim++;
|
||||
|
||||
} else cur_elem = ck_strdup(env_path);
|
||||
} else
|
||||
|
||||
cur_elem = ck_strdup(env_path);
|
||||
|
||||
env_path = delim;
|
||||
|
||||
@ -861,7 +815,8 @@ static void find_binary(u8* fname) {
|
||||
ck_free(cur_elem);
|
||||
|
||||
if (!stat(target_path, &st) && S_ISREG(st.st_mode) &&
|
||||
(st.st_mode & 0111) && st.st_size >= 4) break;
|
||||
(st.st_mode & 0111) && st.st_size >= 4)
|
||||
break;
|
||||
|
||||
ck_free(target_path);
|
||||
target_path = 0;
|
||||
@ -874,13 +829,12 @@ static void find_binary(u8* fname) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Fix up argv for QEMU. */
|
||||
|
||||
static char** get_qemu_argv(u8* own_loc, char** argv, int argc) {
|
||||
|
||||
char** new_argv = ck_alloc(sizeof(char*) * (argc + 4));
|
||||
u8 *tmp, *cp, *rsl, *own_copy;
|
||||
u8 * tmp, *cp, *rsl, *own_copy;
|
||||
|
||||
memcpy(new_argv + 3, argv + 1, sizeof(char*) * argc);
|
||||
|
||||
@ -895,8 +849,7 @@ static char** get_qemu_argv(u8* own_loc, char** argv, int argc) {
|
||||
|
||||
cp = alloc_printf("%s/afl-qemu-trace", tmp);
|
||||
|
||||
if (access(cp, X_OK))
|
||||
FATAL("Unable to find '%s'", tmp);
|
||||
if (access(cp, X_OK)) FATAL("Unable to find '%s'", tmp);
|
||||
|
||||
target_path = new_argv[0] = cp;
|
||||
return new_argv;
|
||||
@ -920,7 +873,9 @@ static char** get_qemu_argv(u8* own_loc, char** argv, int argc) {
|
||||
|
||||
}
|
||||
|
||||
} else ck_free(own_copy);
|
||||
} else
|
||||
|
||||
ck_free(own_copy);
|
||||
|
||||
if (!access(BIN_PATH "/afl-qemu-trace", X_OK)) {
|
||||
|
||||
@ -933,20 +888,19 @@ static char** get_qemu_argv(u8* own_loc, char** argv, int argc) {
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Main entry point */
|
||||
|
||||
int main(int argc, char** argv) {
|
||||
|
||||
s32 opt;
|
||||
u8 mem_limit_given = 0, timeout_given = 0, qemu_mode = 0;
|
||||
u8 mem_limit_given = 0, timeout_given = 0, qemu_mode = 0, unicorn_mode = 0;
|
||||
char** use_argv;
|
||||
|
||||
doc_path = access(DOC_PATH, F_OK) ? "docs" : DOC_PATH;
|
||||
|
||||
SAYF(cCYA "afl-analyze" VERSION cRST " by <lcamtuf@google.com>\n");
|
||||
|
||||
while ((opt = getopt(argc,argv,"+i:f:m:t:eQ")) > 0)
|
||||
while ((opt = getopt(argc, argv, "+i:f:m:t:eQUh")) > 0)
|
||||
|
||||
switch (opt) {
|
||||
|
||||
@ -960,7 +914,7 @@ int main(int argc, char** argv) {
|
||||
|
||||
if (prog_in) FATAL("Multiple -f options not supported");
|
||||
use_stdin = 0;
|
||||
prog_in = optarg;
|
||||
prog_in = optarg;
|
||||
break;
|
||||
|
||||
case 'e':
|
||||
@ -971,40 +925,41 @@ int main(int argc, char** argv) {
|
||||
|
||||
case 'm': {
|
||||
|
||||
u8 suffix = 'M';
|
||||
u8 suffix = 'M';
|
||||
|
||||
if (mem_limit_given) FATAL("Multiple -m options not supported");
|
||||
mem_limit_given = 1;
|
||||
if (mem_limit_given) FATAL("Multiple -m options not supported");
|
||||
mem_limit_given = 1;
|
||||
|
||||
if (!strcmp(optarg, "none")) {
|
||||
if (!strcmp(optarg, "none")) {
|
||||
|
||||
mem_limit = 0;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
if (sscanf(optarg, "%llu%c", &mem_limit, &suffix) < 1 ||
|
||||
optarg[0] == '-') FATAL("Bad syntax used for -m");
|
||||
|
||||
switch (suffix) {
|
||||
|
||||
case 'T': mem_limit *= 1024 * 1024; break;
|
||||
case 'G': mem_limit *= 1024; break;
|
||||
case 'k': mem_limit /= 1024; break;
|
||||
case 'M': break;
|
||||
|
||||
default: FATAL("Unsupported suffix or bad syntax for -m");
|
||||
|
||||
}
|
||||
|
||||
if (mem_limit < 5) FATAL("Dangerously low value of -m");
|
||||
|
||||
if (sizeof(rlim_t) == 4 && mem_limit > 2000)
|
||||
FATAL("Value of -m out of range on 32-bit systems");
|
||||
mem_limit = 0;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
if (sscanf(optarg, "%llu%c", &mem_limit, &suffix) < 1 ||
|
||||
optarg[0] == '-')
|
||||
FATAL("Bad syntax used for -m");
|
||||
|
||||
switch (suffix) {
|
||||
|
||||
case 'T': mem_limit *= 1024 * 1024; break;
|
||||
case 'G': mem_limit *= 1024; break;
|
||||
case 'k': mem_limit /= 1024; break;
|
||||
case 'M': break;
|
||||
|
||||
default: FATAL("Unsupported suffix or bad syntax for -m");
|
||||
|
||||
}
|
||||
|
||||
if (mem_limit < 5) FATAL("Dangerously low value of -m");
|
||||
|
||||
if (sizeof(rlim_t) == 4 && mem_limit > 2000)
|
||||
FATAL("Value of -m out of range on 32-bit systems");
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
case 't':
|
||||
|
||||
@ -1026,9 +981,20 @@ int main(int argc, char** argv) {
|
||||
qemu_mode = 1;
|
||||
break;
|
||||
|
||||
default:
|
||||
case 'U':
|
||||
|
||||
if (unicorn_mode) FATAL("Multiple -U options not supported");
|
||||
if (!mem_limit_given) mem_limit = MEM_LIMIT_UNICORN;
|
||||
|
||||
unicorn_mode = 1;
|
||||
break;
|
||||
|
||||
case 'h':
|
||||
usage(argv[0]);
|
||||
return -1;
|
||||
break;
|
||||
|
||||
default: usage(argv[0]);
|
||||
|
||||
}
|
||||
|
||||
@ -1036,13 +1002,14 @@ int main(int argc, char** argv) {
|
||||
|
||||
use_hex_offsets = !!getenv("AFL_ANALYZE_HEX");
|
||||
|
||||
setup_shm();
|
||||
setup_shm(0);
|
||||
atexit(at_exit_handler);
|
||||
setup_signal_handlers();
|
||||
|
||||
set_up_environment();
|
||||
|
||||
find_binary(argv[optind]);
|
||||
detect_file_args(argv + optind);
|
||||
detect_file_args(argv + optind, prog_in);
|
||||
|
||||
if (qemu_mode)
|
||||
use_argv = get_qemu_argv(argv[0], argv + optind, argc - optind);
|
||||
@ -1,10 +1,15 @@
|
||||
/*
|
||||
american fuzzy lop - wrapper for GNU as
|
||||
---------------------------------------
|
||||
american fuzzy lop++ - wrapper for GNU as
|
||||
-----------------------------------------
|
||||
|
||||
Written and maintained by Michal Zalewski <lcamtuf@google.com>
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Copyright 2013, 2014, 2015 Google Inc. All rights reserved.
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
@ -48,38 +53,37 @@
|
||||
#include <sys/wait.h>
|
||||
#include <sys/time.h>
|
||||
|
||||
static u8** as_params; /* Parameters passed to the real 'as' */
|
||||
static u8** as_params; /* Parameters passed to the real 'as' */
|
||||
|
||||
static u8* input_file; /* Originally specified input file */
|
||||
static u8* modified_file; /* Instrumented file for the real 'as' */
|
||||
static u8* input_file; /* Originally specified input file */
|
||||
static u8* modified_file; /* Instrumented file for the real 'as' */
|
||||
|
||||
static u8 be_quiet, /* Quiet mode (no stderr output) */
|
||||
clang_mode, /* Running in clang mode? */
|
||||
pass_thru, /* Just pass data through? */
|
||||
just_version, /* Just show version? */
|
||||
sanitizer; /* Using ASAN / MSAN */
|
||||
static u8 be_quiet, /* Quiet mode (no stderr output) */
|
||||
clang_mode, /* Running in clang mode? */
|
||||
pass_thru, /* Just pass data through? */
|
||||
just_version, /* Just show version? */
|
||||
sanitizer; /* Using ASAN / MSAN */
|
||||
|
||||
static u32 inst_ratio = 100, /* Instrumentation probability (%) */
|
||||
as_par_cnt = 1; /* Number of params to 'as' */
|
||||
static u32 inst_ratio = 100, /* Instrumentation probability (%) */
|
||||
as_par_cnt = 1; /* Number of params to 'as' */
|
||||
|
||||
/* If we don't find --32 or --64 in the command line, default to
|
||||
/* If we don't find --32 or --64 in the command line, default to
|
||||
instrumentation for whichever mode we were compiled with. This is not
|
||||
perfect, but should do the trick for almost all use cases. */
|
||||
|
||||
#ifdef __x86_64__
|
||||
|
||||
static u8 use_64bit = 1;
|
||||
static u8 use_64bit = 1;
|
||||
|
||||
#else
|
||||
|
||||
static u8 use_64bit = 0;
|
||||
static u8 use_64bit = 0;
|
||||
|
||||
#ifdef __APPLE__
|
||||
# error "Sorry, 32-bit Apple platforms are not supported."
|
||||
#endif /* __APPLE__ */
|
||||
|
||||
#endif /* ^__x86_64__ */
|
||||
#error "Sorry, 32-bit Apple platforms are not supported."
|
||||
#endif /* __APPLE__ */
|
||||
|
||||
#endif /* ^__x86_64__ */
|
||||
|
||||
/* Examine and modify parameters to pass to 'as'. Note that the file name
|
||||
is always the last parameter passed by GCC, so we exploit this property
|
||||
@ -116,7 +120,7 @@ static void edit_params(int argc, char** argv) {
|
||||
|
||||
}
|
||||
|
||||
#endif /* __APPLE__ */
|
||||
#endif /* __APPLE__ */
|
||||
|
||||
/* Although this is not documented, GCC also uses TEMP and TMP when TMPDIR
|
||||
is not set. We need to check these non-standard variables to properly
|
||||
@ -134,8 +138,10 @@ static void edit_params(int argc, char** argv) {
|
||||
|
||||
for (i = 1; i < argc - 1; i++) {
|
||||
|
||||
if (!strcmp(argv[i], "--64")) use_64bit = 1;
|
||||
else if (!strcmp(argv[i], "--32")) use_64bit = 0;
|
||||
if (!strcmp(argv[i], "--64"))
|
||||
use_64bit = 1;
|
||||
else if (!strcmp(argv[i], "--32"))
|
||||
use_64bit = 0;
|
||||
|
||||
#ifdef __APPLE__
|
||||
|
||||
@ -143,7 +149,8 @@ static void edit_params(int argc, char** argv) {
|
||||
|
||||
if (!strcmp(argv[i], "-arch") && i + 1 < argc) {
|
||||
|
||||
if (!strcmp(argv[i + 1], "x86_64")) use_64bit = 1;
|
||||
if (!strcmp(argv[i + 1], "x86_64"))
|
||||
use_64bit = 1;
|
||||
else if (!strcmp(argv[i + 1], "i386"))
|
||||
FATAL("Sorry, 32-bit Apple platforms are not supported.");
|
||||
|
||||
@ -155,7 +162,7 @@ static void edit_params(int argc, char** argv) {
|
||||
if (clang_mode && (!strcmp(argv[i], "-q") || !strcmp(argv[i], "-Q")))
|
||||
continue;
|
||||
|
||||
#endif /* __APPLE__ */
|
||||
#endif /* __APPLE__ */
|
||||
|
||||
as_params[as_par_cnt++] = argv[i];
|
||||
|
||||
@ -174,20 +181,24 @@ static void edit_params(int argc, char** argv) {
|
||||
|
||||
}
|
||||
|
||||
#endif /* __APPLE__ */
|
||||
#endif /* __APPLE__ */
|
||||
|
||||
input_file = argv[argc - 1];
|
||||
|
||||
if (input_file[0] == '-') {
|
||||
|
||||
if (!strcmp(input_file + 1, "-version")) {
|
||||
|
||||
just_version = 1;
|
||||
modified_file = input_file;
|
||||
goto wrap_things_up;
|
||||
|
||||
}
|
||||
|
||||
if (input_file[1]) FATAL("Incorrect use (not called through afl-gcc?)");
|
||||
else input_file = NULL;
|
||||
if (input_file[1])
|
||||
FATAL("Incorrect use (not called through afl-gcc?)");
|
||||
else
|
||||
input_file = NULL;
|
||||
|
||||
} else {
|
||||
|
||||
@ -197,22 +208,21 @@ static void edit_params(int argc, char** argv) {
|
||||
NSS. */
|
||||
|
||||
if (strncmp(input_file, tmp_dir, strlen(tmp_dir)) &&
|
||||
strncmp(input_file, "/var/tmp/", 9) &&
|
||||
strncmp(input_file, "/tmp/", 5)) pass_thru = 1;
|
||||
strncmp(input_file, "/var/tmp/", 9) && strncmp(input_file, "/tmp/", 5))
|
||||
pass_thru = 1;
|
||||
|
||||
}
|
||||
|
||||
modified_file = alloc_printf("%s/.afl-%u-%u.s", tmp_dir, getpid(),
|
||||
(u32)time(NULL));
|
||||
modified_file =
|
||||
alloc_printf("%s/.afl-%u-%u.s", tmp_dir, getpid(), (u32)time(NULL));
|
||||
|
||||
wrap_things_up:
|
||||
|
||||
as_params[as_par_cnt++] = modified_file;
|
||||
as_params[as_par_cnt] = NULL;
|
||||
as_params[as_par_cnt] = NULL;
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Process input file, generate modified_file. Insert instrumentation in all
|
||||
the appropriate places. */
|
||||
|
||||
@ -222,24 +232,26 @@ static void add_instrumentation(void) {
|
||||
|
||||
FILE* inf;
|
||||
FILE* outf;
|
||||
s32 outfd;
|
||||
u32 ins_lines = 0;
|
||||
s32 outfd;
|
||||
u32 ins_lines = 0;
|
||||
|
||||
u8 instr_ok = 0, skip_csect = 0, skip_next_label = 0,
|
||||
skip_intel = 0, skip_app = 0, instrument_next = 0;
|
||||
u8 instr_ok = 0, skip_csect = 0, skip_next_label = 0, skip_intel = 0,
|
||||
skip_app = 0, instrument_next = 0;
|
||||
|
||||
#ifdef __APPLE__
|
||||
|
||||
u8* colon_pos;
|
||||
|
||||
#endif /* __APPLE__ */
|
||||
#endif /* __APPLE__ */
|
||||
|
||||
if (input_file) {
|
||||
|
||||
inf = fopen(input_file, "r");
|
||||
if (!inf) PFATAL("Unable to read '%s'", input_file);
|
||||
|
||||
} else inf = stdin;
|
||||
} else
|
||||
|
||||
inf = stdin;
|
||||
|
||||
outfd = open(modified_file, O_WRONLY | O_EXCL | O_CREAT, 0600);
|
||||
|
||||
@ -247,7 +259,7 @@ static void add_instrumentation(void) {
|
||||
|
||||
outf = fdopen(outfd, "w");
|
||||
|
||||
if (!outf) PFATAL("fdopen() failed");
|
||||
if (!outf) PFATAL("fdopen() failed");
|
||||
|
||||
while (fgets(line, MAX_LINE, inf)) {
|
||||
|
||||
@ -284,22 +296,26 @@ static void add_instrumentation(void) {
|
||||
around them, so we use that as a signal. */
|
||||
|
||||
if (!clang_mode && instr_ok && !strncmp(line + 2, "p2align ", 8) &&
|
||||
isdigit(line[10]) && line[11] == '\n') skip_next_label = 1;
|
||||
isdigit(line[10]) && line[11] == '\n')
|
||||
skip_next_label = 1;
|
||||
|
||||
if (!strncmp(line + 2, "text\n", 5) ||
|
||||
!strncmp(line + 2, "section\t.text", 13) ||
|
||||
!strncmp(line + 2, "section\t__TEXT,__text", 21) ||
|
||||
!strncmp(line + 2, "section __TEXT,__text", 21)) {
|
||||
|
||||
instr_ok = 1;
|
||||
continue;
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
if (!strncmp(line + 2, "section\t", 8) ||
|
||||
!strncmp(line + 2, "section ", 8) ||
|
||||
!strncmp(line + 2, "bss\n", 4) ||
|
||||
!strncmp(line + 2, "section ", 8) || !strncmp(line + 2, "bss\n", 4) ||
|
||||
!strncmp(line + 2, "data\n", 5)) {
|
||||
|
||||
instr_ok = 0;
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
@ -354,8 +370,9 @@ static void add_instrumentation(void) {
|
||||
|
||||
*/
|
||||
|
||||
if (skip_intel || skip_app || skip_csect || !instr_ok ||
|
||||
line[0] == '#' || line[0] == ' ') continue;
|
||||
if (skip_intel || skip_app || skip_csect || !instr_ok || line[0] == '#' ||
|
||||
line[0] == ' ')
|
||||
continue;
|
||||
|
||||
/* Conditional branch instruction (jnz, etc). We append the instrumentation
|
||||
right after the branch (to instrument the not-taken path) and at the
|
||||
@ -377,7 +394,7 @@ static void add_instrumentation(void) {
|
||||
}
|
||||
|
||||
/* Label of some sort. This may be a branch destination, but we need to
|
||||
tread carefully and account for several different formatting
|
||||
read carefully and account for several different formatting
|
||||
conventions. */
|
||||
|
||||
#ifdef __APPLE__
|
||||
@ -396,7 +413,7 @@ static void add_instrumentation(void) {
|
||||
|
||||
if (line[0] == '.') {
|
||||
|
||||
#endif /* __APPLE__ */
|
||||
#endif /* __APPLE__ */
|
||||
|
||||
/* .L0: or LBB0_0: style jump destination */
|
||||
|
||||
@ -404,17 +421,18 @@ static void add_instrumentation(void) {
|
||||
|
||||
/* Apple: L<num> / LBB<num> */
|
||||
|
||||
if ((isdigit(line[1]) || (clang_mode && !strncmp(line, "LBB", 3)))
|
||||
&& R(100) < inst_ratio) {
|
||||
if ((isdigit(line[1]) || (clang_mode && !strncmp(line, "LBB", 3))) &&
|
||||
R(100) < inst_ratio) {
|
||||
|
||||
#else
|
||||
|
||||
/* Apple: .L<num> / .LBB<num> */
|
||||
|
||||
if ((isdigit(line[2]) || (clang_mode && !strncmp(line + 1, "LBB", 3)))
|
||||
&& R(100) < inst_ratio) {
|
||||
if ((isdigit(line[2]) ||
|
||||
(clang_mode && !strncmp(line + 1, "LBB", 3))) &&
|
||||
R(100) < inst_ratio) {
|
||||
|
||||
#endif /* __APPLE__ */
|
||||
#endif /* __APPLE__ */
|
||||
|
||||
/* An optimization is possible here by adding the code only if the
|
||||
label is mentioned in the code in contexts other than call / jmp.
|
||||
@ -427,7 +445,10 @@ static void add_instrumentation(void) {
|
||||
.Lfunc_begin0-style exception handling calculations (a problem on
|
||||
MacOS X). */
|
||||
|
||||
if (!skip_next_label) instrument_next = 1; else skip_next_label = 0;
|
||||
if (!skip_next_label)
|
||||
instrument_next = 1;
|
||||
else
|
||||
skip_next_label = 0;
|
||||
|
||||
}
|
||||
|
||||
@ -436,34 +457,34 @@ static void add_instrumentation(void) {
|
||||
/* Function label (always instrumented, deferred mode). */
|
||||
|
||||
instrument_next = 1;
|
||||
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (ins_lines)
|
||||
fputs(use_64bit ? main_payload_64 : main_payload_32, outf);
|
||||
if (ins_lines) fputs(use_64bit ? main_payload_64 : main_payload_32, outf);
|
||||
|
||||
if (input_file) fclose(inf);
|
||||
fclose(outf);
|
||||
|
||||
if (!be_quiet) {
|
||||
|
||||
if (!ins_lines) WARNF("No instrumentation targets found%s.",
|
||||
pass_thru ? " (pass-thru mode)" : "");
|
||||
else OKF("Instrumented %u locations (%s-bit, %s mode, ratio %u%%).",
|
||||
ins_lines, use_64bit ? "64" : "32",
|
||||
getenv("AFL_HARDEN") ? "hardened" :
|
||||
(sanitizer ? "ASAN/MSAN" : "non-hardened"),
|
||||
inst_ratio);
|
||||
|
||||
if (!ins_lines)
|
||||
WARNF("No instrumentation targets found%s.",
|
||||
pass_thru ? " (pass-thru mode)" : "");
|
||||
else
|
||||
OKF("Instrumented %u locations (%s-bit, %s mode, ratio %u%%).", ins_lines,
|
||||
use_64bit ? "64" : "32",
|
||||
getenv("AFL_HARDEN") ? "hardened"
|
||||
: (sanitizer ? "ASAN/MSAN" : "non-hardened"),
|
||||
inst_ratio);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
/* Main entry point */
|
||||
|
||||
int main(int argc, char** argv) {
|
||||
@ -473,7 +494,7 @@ int main(int argc, char** argv) {
|
||||
int status;
|
||||
u8* inst_ratio_str = getenv("AFL_INST_RATIO");
|
||||
|
||||
struct timeval tv;
|
||||
struct timeval tv;
|
||||
struct timezone tz;
|
||||
|
||||
clang_mode = !!getenv(CLANG_ENV_VAR);
|
||||
@ -481,19 +502,26 @@ int main(int argc, char** argv) {
|
||||
if (isatty(2) && !getenv("AFL_QUIET")) {
|
||||
|
||||
SAYF(cCYA "afl-as" VERSION cRST " by <lcamtuf@google.com>\n");
|
||||
|
||||
} else be_quiet = 1;
|
||||
|
||||
} else
|
||||
|
||||
be_quiet = 1;
|
||||
|
||||
if (argc < 2) {
|
||||
|
||||
SAYF("\n"
|
||||
"This is a helper application for afl-fuzz. It is a wrapper around GNU 'as',\n"
|
||||
"executed by the toolchain whenever using afl-gcc or afl-clang. You probably\n"
|
||||
"don't want to run this program directly.\n\n"
|
||||
SAYF(
|
||||
"\n"
|
||||
"This is a helper application for afl-fuzz. It is a wrapper around GNU "
|
||||
"'as',\n"
|
||||
"executed by the toolchain whenever using afl-gcc or afl-clang. You "
|
||||
"probably\n"
|
||||
"don't want to run this program directly.\n\n"
|
||||
|
||||
"Rarely, when dealing with extremely complex projects, it may be advisable to\n"
|
||||
"set AFL_INST_RATIO to a value less than 100 in order to reduce the odds of\n"
|
||||
"instrumenting every discovered branch.\n\n");
|
||||
"Rarely, when dealing with extremely complex projects, it may be "
|
||||
"advisable to\n"
|
||||
"set AFL_INST_RATIO to a value less than 100 in order to reduce the "
|
||||
"odds of\n"
|
||||
"instrumenting every discovered branch.\n\n");
|
||||
|
||||
exit(1);
|
||||
|
||||
@ -509,7 +537,7 @@ int main(int argc, char** argv) {
|
||||
|
||||
if (inst_ratio_str) {
|
||||
|
||||
if (sscanf(inst_ratio_str, "%u", &inst_ratio) != 1 || inst_ratio > 100)
|
||||
if (sscanf(inst_ratio_str, "%u", &inst_ratio) != 1 || inst_ratio > 100)
|
||||
FATAL("Bad value of AFL_INST_RATIO (must be between 0 and 100)");
|
||||
|
||||
}
|
||||
@ -524,9 +552,10 @@ int main(int argc, char** argv) {
|
||||
that... */
|
||||
|
||||
if (getenv("AFL_USE_ASAN") || getenv("AFL_USE_MSAN")) {
|
||||
|
||||
sanitizer = 1;
|
||||
if (!getenv("AFL_INST_RATIO"))
|
||||
inst_ratio /= 3;
|
||||
if (!getenv("AFL_INST_RATIO")) inst_ratio /= 3;
|
||||
|
||||
}
|
||||
|
||||
if (!just_version) add_instrumentation();
|
||||
97
src/afl-common.c
Normal file
97
src/afl-common.c
Normal file
@ -0,0 +1,97 @@
|
||||
/*
|
||||
american fuzzy lop++ - common routines
|
||||
--------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Gather some functions common to multiple executables
|
||||
|
||||
- detect_file_args
|
||||
|
||||
*/
|
||||
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
#include <strings.h>
|
||||
|
||||
#include "debug.h"
|
||||
#include "alloc-inl.h"
|
||||
|
||||
/* Detect @@ in args. */
|
||||
#ifndef __glibc__
|
||||
#include <unistd.h>
|
||||
#endif
|
||||
|
||||
void detect_file_args(char** argv, u8* prog_in) {
|
||||
|
||||
u32 i = 0;
|
||||
#ifdef __GLIBC__
|
||||
u8* cwd = getcwd(NULL, 0); /* non portable glibc extension */
|
||||
#else
|
||||
u8* cwd;
|
||||
char* buf;
|
||||
long size = pathconf(".", _PC_PATH_MAX);
|
||||
if ((buf = (char*)malloc((size_t)size)) != NULL) {
|
||||
|
||||
cwd = getcwd(buf, (size_t)size); /* portable version */
|
||||
|
||||
} else {
|
||||
|
||||
PFATAL("getcwd() failed");
|
||||
cwd = 0; /* for dumb compilers */
|
||||
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
if (!cwd) PFATAL("getcwd() failed");
|
||||
|
||||
while (argv[i]) {
|
||||
|
||||
u8* aa_loc = strstr(argv[i], "@@");
|
||||
|
||||
if (aa_loc) {
|
||||
|
||||
u8 *aa_subst, *n_arg;
|
||||
|
||||
if (!prog_in) FATAL("@@ syntax is not supported by this tool.");
|
||||
|
||||
/* Be sure that we're always using fully-qualified paths. */
|
||||
|
||||
if (prog_in[0] == '/')
|
||||
aa_subst = prog_in;
|
||||
else
|
||||
aa_subst = alloc_printf("%s/%s", cwd, prog_in);
|
||||
|
||||
/* Construct a replacement argv value. */
|
||||
|
||||
*aa_loc = 0;
|
||||
n_arg = alloc_printf("%s%s%s", argv[i], aa_subst, aa_loc + 2);
|
||||
argv[i] = n_arg;
|
||||
*aa_loc = '@';
|
||||
|
||||
if (prog_in[0] != '/') ck_free(aa_subst);
|
||||
|
||||
}
|
||||
|
||||
i++;
|
||||
|
||||
}
|
||||
|
||||
free(cwd); /* not tracked */
|
||||
|
||||
}
|
||||
|
||||
456
src/afl-forkserver.c
Normal file
456
src/afl-forkserver.c
Normal file
@ -0,0 +1,456 @@
|
||||
/*
|
||||
american fuzzy lop++ - forkserver code
|
||||
--------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Forkserver design by Jann Horn <jannhorn@googlemail.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Shared code that implements a forkserver. This is used by the fuzzer
|
||||
as well the other components like afl-tmin.
|
||||
|
||||
*/
|
||||
|
||||
#include "config.h"
|
||||
#include "types.h"
|
||||
#include "debug.h"
|
||||
#include "forkserver.h"
|
||||
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
#include <time.h>
|
||||
#include <errno.h>
|
||||
#include <signal.h>
|
||||
#include <sys/time.h>
|
||||
#include <sys/wait.h>
|
||||
#include <sys/resource.h>
|
||||
|
||||
/* a program that includes afl-forkserver needs to define these */
|
||||
extern u8 uses_asan;
|
||||
extern u8 *trace_bits;
|
||||
extern s32 forksrv_pid, child_pid, fsrv_ctl_fd, fsrv_st_fd;
|
||||
extern s32 out_fd, out_dir_fd, dev_urandom_fd,
|
||||
dev_null_fd; /* initialize these with -1 */
|
||||
extern u32 exec_tmout;
|
||||
extern u64 mem_limit;
|
||||
extern u8 * out_file, *target_path, *doc_path;
|
||||
extern FILE *plot_file;
|
||||
|
||||
/* we need this internally but can be defined and read extern in the main source
|
||||
*/
|
||||
u8 child_timed_out;
|
||||
|
||||
/* Describe integer as memory size. */
|
||||
|
||||
u8 *forkserver_DMS(u64 val) {
|
||||
|
||||
static u8 tmp[12][16];
|
||||
static u8 cur;
|
||||
|
||||
#define CHK_FORMAT(_divisor, _limit_mult, _fmt, _cast) \
|
||||
do { \
|
||||
\
|
||||
if (val < (_divisor) * (_limit_mult)) { \
|
||||
\
|
||||
sprintf(tmp[cur], _fmt, ((_cast)val) / (_divisor)); \
|
||||
return tmp[cur]; \
|
||||
\
|
||||
} \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
cur = (cur + 1) % 12;
|
||||
|
||||
/* 0-9999 */
|
||||
CHK_FORMAT(1, 10000, "%llu B", u64);
|
||||
|
||||
/* 10.0k - 99.9k */
|
||||
CHK_FORMAT(1024, 99.95, "%0.01f kB", double);
|
||||
|
||||
/* 100k - 999k */
|
||||
CHK_FORMAT(1024, 1000, "%llu kB", u64);
|
||||
|
||||
/* 1.00M - 9.99M */
|
||||
CHK_FORMAT(1024 * 1024, 9.995, "%0.02f MB", double);
|
||||
|
||||
/* 10.0M - 99.9M */
|
||||
CHK_FORMAT(1024 * 1024, 99.95, "%0.01f MB", double);
|
||||
|
||||
/* 100M - 999M */
|
||||
CHK_FORMAT(1024 * 1024, 1000, "%llu MB", u64);
|
||||
|
||||
/* 1.00G - 9.99G */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024, 9.995, "%0.02f GB", double);
|
||||
|
||||
/* 10.0G - 99.9G */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024, 99.95, "%0.01f GB", double);
|
||||
|
||||
/* 100G - 999G */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024, 1000, "%llu GB", u64);
|
||||
|
||||
/* 1.00T - 9.99G */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024 * 1024, 9.995, "%0.02f TB", double);
|
||||
|
||||
/* 10.0T - 99.9T */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024 * 1024, 99.95, "%0.01f TB", double);
|
||||
|
||||
#undef CHK_FORMAT
|
||||
|
||||
/* 100T+ */
|
||||
strcpy(tmp[cur], "infty");
|
||||
return tmp[cur];
|
||||
|
||||
}
|
||||
|
||||
/* the timeout handler */
|
||||
|
||||
void handle_timeout(int sig) {
|
||||
|
||||
if (child_pid > 0) {
|
||||
|
||||
child_timed_out = 1;
|
||||
kill(child_pid, SIGKILL);
|
||||
|
||||
} else if (child_pid == -1 && forksrv_pid > 0) {
|
||||
|
||||
child_timed_out = 1;
|
||||
kill(forksrv_pid, SIGKILL);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* Spin up fork server (instrumented mode only). The idea is explained here:
|
||||
|
||||
http://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html
|
||||
|
||||
In essence, the instrumentation allows us to skip execve(), and just keep
|
||||
cloning a stopped child. So, we just execute once, and then send commands
|
||||
through a pipe. The other part of this logic is in afl-as.h / llvm_mode */
|
||||
|
||||
void init_forkserver(char **argv) {
|
||||
|
||||
static struct itimerval it;
|
||||
int st_pipe[2], ctl_pipe[2];
|
||||
int status;
|
||||
s32 rlen;
|
||||
|
||||
ACTF("Spinning up the fork server...");
|
||||
|
||||
if (pipe(st_pipe) || pipe(ctl_pipe)) PFATAL("pipe() failed");
|
||||
|
||||
child_timed_out = 0;
|
||||
forksrv_pid = fork();
|
||||
|
||||
if (forksrv_pid < 0) PFATAL("fork() failed");
|
||||
|
||||
if (!forksrv_pid) {
|
||||
|
||||
/* CHILD PROCESS */
|
||||
|
||||
struct rlimit r;
|
||||
|
||||
/* Umpf. On OpenBSD, the default fd limit for root users is set to
|
||||
soft 128. Let's try to fix that... */
|
||||
|
||||
if (!getrlimit(RLIMIT_NOFILE, &r) && r.rlim_cur < FORKSRV_FD + 2) {
|
||||
|
||||
r.rlim_cur = FORKSRV_FD + 2;
|
||||
setrlimit(RLIMIT_NOFILE, &r); /* Ignore errors */
|
||||
|
||||
}
|
||||
|
||||
if (mem_limit) {
|
||||
|
||||
r.rlim_max = r.rlim_cur = ((rlim_t)mem_limit) << 20;
|
||||
|
||||
#ifdef RLIMIT_AS
|
||||
setrlimit(RLIMIT_AS, &r); /* Ignore errors */
|
||||
#else
|
||||
/* This takes care of OpenBSD, which doesn't have RLIMIT_AS, but
|
||||
according to reliable sources, RLIMIT_DATA covers anonymous
|
||||
maps - so we should be getting good protection against OOM bugs. */
|
||||
|
||||
setrlimit(RLIMIT_DATA, &r); /* Ignore errors */
|
||||
#endif /* ^RLIMIT_AS */
|
||||
|
||||
}
|
||||
|
||||
/* Dumping cores is slow and can lead to anomalies if SIGKILL is delivered
|
||||
before the dump is complete. */
|
||||
|
||||
// r.rlim_max = r.rlim_cur = 0;
|
||||
// setrlimit(RLIMIT_CORE, &r); /* Ignore errors */
|
||||
|
||||
/* Isolate the process and configure standard descriptors. If out_file is
|
||||
specified, stdin is /dev/null; otherwise, out_fd is cloned instead. */
|
||||
|
||||
setsid();
|
||||
|
||||
if (!getenv("AFL_DEBUG_CHILD_OUTPUT")) {
|
||||
|
||||
dup2(dev_null_fd, 1);
|
||||
dup2(dev_null_fd, 2);
|
||||
|
||||
}
|
||||
|
||||
if (out_file) {
|
||||
|
||||
dup2(dev_null_fd, 0);
|
||||
|
||||
} else {
|
||||
|
||||
dup2(out_fd, 0);
|
||||
close(out_fd);
|
||||
|
||||
}
|
||||
|
||||
/* Set up control and status pipes, close the unneeded original fds. */
|
||||
|
||||
if (dup2(ctl_pipe[0], FORKSRV_FD) < 0) PFATAL("dup2() failed");
|
||||
if (dup2(st_pipe[1], FORKSRV_FD + 1) < 0) PFATAL("dup2() failed");
|
||||
|
||||
close(ctl_pipe[0]);
|
||||
close(ctl_pipe[1]);
|
||||
close(st_pipe[0]);
|
||||
close(st_pipe[1]);
|
||||
|
||||
close(out_dir_fd);
|
||||
close(dev_null_fd);
|
||||
close(dev_urandom_fd);
|
||||
close(plot_file == NULL ? -1 : fileno(plot_file));
|
||||
|
||||
/* This should improve performance a bit, since it stops the linker from
|
||||
doing extra work post-fork(). */
|
||||
|
||||
if (!getenv("LD_BIND_LAZY")) setenv("LD_BIND_NOW", "1", 0);
|
||||
|
||||
/* Set sane defaults for ASAN if nothing else specified. */
|
||||
|
||||
setenv("ASAN_OPTIONS",
|
||||
"abort_on_error=1:"
|
||||
"detect_leaks=0:"
|
||||
"symbolize=0:"
|
||||
"allocator_may_return_null=1",
|
||||
0);
|
||||
|
||||
/* MSAN is tricky, because it doesn't support abort_on_error=1 at this
|
||||
point. So, we do this in a very hacky way. */
|
||||
|
||||
setenv("MSAN_OPTIONS",
|
||||
"exit_code=" STRINGIFY(MSAN_ERROR) ":"
|
||||
"symbolize=0:"
|
||||
"abort_on_error=1:"
|
||||
"allocator_may_return_null=1:"
|
||||
"msan_track_origins=0",
|
||||
0);
|
||||
|
||||
execv(target_path, argv);
|
||||
|
||||
/* Use a distinctive bitmap signature to tell the parent about execv()
|
||||
falling through. */
|
||||
|
||||
*(u32 *)trace_bits = EXEC_FAIL_SIG;
|
||||
exit(0);
|
||||
|
||||
}
|
||||
|
||||
/* PARENT PROCESS */
|
||||
|
||||
/* Close the unneeded endpoints. */
|
||||
|
||||
close(ctl_pipe[0]);
|
||||
close(st_pipe[1]);
|
||||
|
||||
fsrv_ctl_fd = ctl_pipe[1];
|
||||
fsrv_st_fd = st_pipe[0];
|
||||
|
||||
/* Wait for the fork server to come up, but don't wait too long. */
|
||||
|
||||
if (exec_tmout) {
|
||||
|
||||
it.it_value.tv_sec = ((exec_tmout * FORK_WAIT_MULT) / 1000);
|
||||
it.it_value.tv_usec = ((exec_tmout * FORK_WAIT_MULT) % 1000) * 1000;
|
||||
|
||||
}
|
||||
|
||||
setitimer(ITIMER_REAL, &it, NULL);
|
||||
|
||||
rlen = read(fsrv_st_fd, &status, 4);
|
||||
|
||||
it.it_value.tv_sec = 0;
|
||||
it.it_value.tv_usec = 0;
|
||||
|
||||
setitimer(ITIMER_REAL, &it, NULL);
|
||||
|
||||
/* If we have a four-byte "hello" message from the server, we're all set.
|
||||
Otherwise, try to figure out what went wrong. */
|
||||
|
||||
if (rlen == 4) {
|
||||
|
||||
OKF("All right - fork server is up.");
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
if (child_timed_out)
|
||||
FATAL("Timeout while initializing fork server (adjusting -t may help)");
|
||||
|
||||
if (waitpid(forksrv_pid, &status, 0) <= 0) PFATAL("waitpid() failed");
|
||||
|
||||
if (WIFSIGNALED(status)) {
|
||||
|
||||
if (mem_limit && mem_limit < 500 && uses_asan) {
|
||||
|
||||
SAYF("\n" cLRD "[-] " cRST
|
||||
"Whoops, the target binary crashed suddenly, "
|
||||
"before receiving any input\n"
|
||||
" from the fuzzer! Since it seems to be built with ASAN and you "
|
||||
"have a\n"
|
||||
" restrictive memory limit configured, this is expected; please "
|
||||
"read\n"
|
||||
" %s/notes_for_asan.txt for help.\n",
|
||||
doc_path);
|
||||
|
||||
} else if (!mem_limit) {
|
||||
|
||||
SAYF("\n" cLRD "[-] " cRST
|
||||
"Whoops, the target binary crashed suddenly, "
|
||||
"before receiving any input\n"
|
||||
" from the fuzzer! There are several probable explanations:\n\n"
|
||||
|
||||
" - The binary is just buggy and explodes entirely on its own. "
|
||||
"If so, you\n"
|
||||
" need to fix the underlying problem or find a better "
|
||||
"replacement.\n\n"
|
||||
|
||||
MSG_FORK_ON_APPLE
|
||||
|
||||
" - Less likely, there is a horrible bug in the fuzzer. If other "
|
||||
"options\n"
|
||||
" fail, poke <afl-users@googlegroups.com> for troubleshooting "
|
||||
"tips.\n");
|
||||
|
||||
} else {
|
||||
|
||||
SAYF("\n" cLRD "[-] " cRST
|
||||
"Whoops, the target binary crashed suddenly, "
|
||||
"before receiving any input\n"
|
||||
" from the fuzzer! There are several probable explanations:\n\n"
|
||||
|
||||
" - The current memory limit (%s) is too restrictive, causing "
|
||||
"the\n"
|
||||
" target to hit an OOM condition in the dynamic linker. Try "
|
||||
"bumping up\n"
|
||||
" the limit with the -m setting in the command line. A simple "
|
||||
"way confirm\n"
|
||||
" this diagnosis would be:\n\n"
|
||||
|
||||
MSG_ULIMIT_USAGE
|
||||
" /path/to/fuzzed_app )\n\n"
|
||||
|
||||
" Tip: you can use http://jwilk.net/software/recidivm to "
|
||||
"quickly\n"
|
||||
" estimate the required amount of virtual memory for the "
|
||||
"binary.\n\n"
|
||||
|
||||
" - The binary is just buggy and explodes entirely on its own. "
|
||||
"If so, you\n"
|
||||
" need to fix the underlying problem or find a better "
|
||||
"replacement.\n\n"
|
||||
|
||||
MSG_FORK_ON_APPLE
|
||||
|
||||
" - Less likely, there is a horrible bug in the fuzzer. If other "
|
||||
"options\n"
|
||||
" fail, poke <afl-users@googlegroups.com> for troubleshooting "
|
||||
"tips.\n",
|
||||
forkserver_DMS(mem_limit << 20), mem_limit - 1);
|
||||
|
||||
}
|
||||
|
||||
FATAL("Fork server crashed with signal %d", WTERMSIG(status));
|
||||
|
||||
}
|
||||
|
||||
if (*(u32 *)trace_bits == EXEC_FAIL_SIG)
|
||||
FATAL("Unable to execute target application ('%s')", argv[0]);
|
||||
|
||||
if (mem_limit && mem_limit < 500 && uses_asan) {
|
||||
|
||||
SAYF("\n" cLRD "[-] " cRST
|
||||
"Hmm, looks like the target binary terminated "
|
||||
"before we could complete a\n"
|
||||
" handshake with the injected code. Since it seems to be built "
|
||||
"with ASAN and\n"
|
||||
" you have a restrictive memory limit configured, this is "
|
||||
"expected; please\n"
|
||||
" read %s/notes_for_asan.txt for help.\n",
|
||||
doc_path);
|
||||
|
||||
} else if (!mem_limit) {
|
||||
|
||||
SAYF("\n" cLRD "[-] " cRST
|
||||
"Hmm, looks like the target binary terminated "
|
||||
"before we could complete a\n"
|
||||
" handshake with the injected code. Perhaps there is a horrible "
|
||||
"bug in the\n"
|
||||
" fuzzer. Poke <afl-users@googlegroups.com> for troubleshooting "
|
||||
"tips.\n");
|
||||
|
||||
} else {
|
||||
|
||||
SAYF(
|
||||
"\n" cLRD "[-] " cRST
|
||||
"Hmm, looks like the target binary terminated "
|
||||
"before we could complete a\n"
|
||||
" handshake with the injected code. There are %s probable "
|
||||
"explanations:\n\n"
|
||||
|
||||
"%s"
|
||||
" - The current memory limit (%s) is too restrictive, causing an "
|
||||
"OOM\n"
|
||||
" fault in the dynamic linker. This can be fixed with the -m "
|
||||
"option. A\n"
|
||||
" simple way to confirm the diagnosis may be:\n\n"
|
||||
|
||||
MSG_ULIMIT_USAGE
|
||||
" /path/to/fuzzed_app )\n\n"
|
||||
|
||||
" Tip: you can use http://jwilk.net/software/recidivm to quickly\n"
|
||||
" estimate the required amount of virtual memory for the "
|
||||
"binary.\n\n"
|
||||
|
||||
" - Less likely, there is a horrible bug in the fuzzer. If other "
|
||||
"options\n"
|
||||
" fail, poke <afl-users@googlegroups.com> for troubleshooting "
|
||||
"tips.\n",
|
||||
getenv(DEFER_ENV_VAR) ? "three" : "two",
|
||||
getenv(DEFER_ENV_VAR)
|
||||
? " - You are using deferred forkserver, but __AFL_INIT() is "
|
||||
"never\n"
|
||||
" reached before the program terminates.\n\n"
|
||||
: "",
|
||||
forkserver_DMS(mem_limit << 20), mem_limit - 1);
|
||||
|
||||
}
|
||||
|
||||
FATAL("Fork server handshake failed");
|
||||
|
||||
}
|
||||
|
||||
711
src/afl-fuzz-bitmap.c
Normal file
711
src/afl-fuzz-bitmap.c
Normal file
@ -0,0 +1,711 @@
|
||||
/*
|
||||
american fuzzy lop++ - bitmap related routines
|
||||
----------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This is the real deal: the program takes an instrumented binary and
|
||||
attempts a variety of basic fuzzing tricks, paying close attention to
|
||||
how they affect the execution path.
|
||||
|
||||
*/
|
||||
|
||||
#include "afl-fuzz.h"
|
||||
|
||||
/* Write bitmap to file. The bitmap is useful mostly for the secret
|
||||
-B option, to focus a separate fuzzing session on a particular
|
||||
interesting input without rediscovering all the others. */
|
||||
|
||||
void write_bitmap(void) {
|
||||
|
||||
u8* fname;
|
||||
s32 fd;
|
||||
|
||||
if (!bitmap_changed) return;
|
||||
bitmap_changed = 0;
|
||||
|
||||
fname = alloc_printf("%s/fuzz_bitmap", out_dir);
|
||||
fd = open(fname, O_WRONLY | O_CREAT | O_TRUNC, 0600);
|
||||
|
||||
if (fd < 0) PFATAL("Unable to open '%s'", fname);
|
||||
|
||||
ck_write(fd, virgin_bits, MAP_SIZE, fname);
|
||||
|
||||
close(fd);
|
||||
ck_free(fname);
|
||||
|
||||
}
|
||||
|
||||
/* Read bitmap from file. This is for the -B option again. */
|
||||
|
||||
void read_bitmap(u8* fname) {
|
||||
|
||||
s32 fd = open(fname, O_RDONLY);
|
||||
|
||||
if (fd < 0) PFATAL("Unable to open '%s'", fname);
|
||||
|
||||
ck_read(fd, virgin_bits, MAP_SIZE, fname);
|
||||
|
||||
close(fd);
|
||||
|
||||
}
|
||||
|
||||
/* Check if the current execution path brings anything new to the table.
|
||||
Update virgin bits to reflect the finds. Returns 1 if the only change is
|
||||
the hit-count for a particular tuple; 2 if there are new tuples seen.
|
||||
Updates the map, so subsequent calls will always return 0.
|
||||
|
||||
This function is called after every exec() on a fairly large buffer, so
|
||||
it needs to be fast. We do this in 32-bit and 64-bit flavors. */
|
||||
|
||||
u8 has_new_bits(u8* virgin_map) {
|
||||
|
||||
#ifdef __x86_64__
|
||||
|
||||
u64* current = (u64*)trace_bits;
|
||||
u64* virgin = (u64*)virgin_map;
|
||||
|
||||
u32 i = (MAP_SIZE >> 3);
|
||||
|
||||
#else
|
||||
|
||||
u32* current = (u32*)trace_bits;
|
||||
u32* virgin = (u32*)virgin_map;
|
||||
|
||||
u32 i = (MAP_SIZE >> 2);
|
||||
|
||||
#endif /* ^__x86_64__ */
|
||||
|
||||
u8 ret = 0;
|
||||
|
||||
while (i--) {
|
||||
|
||||
/* Optimize for (*current & *virgin) == 0 - i.e., no bits in current bitmap
|
||||
that have not been already cleared from the virgin map - since this will
|
||||
almost always be the case. */
|
||||
|
||||
if (unlikely(*current) && unlikely(*current & *virgin)) {
|
||||
|
||||
if (likely(ret < 2)) {
|
||||
|
||||
u8* cur = (u8*)current;
|
||||
u8* vir = (u8*)virgin;
|
||||
|
||||
/* Looks like we have not found any new bytes yet; see if any non-zero
|
||||
bytes in current[] are pristine in virgin[]. */
|
||||
|
||||
#ifdef __x86_64__
|
||||
|
||||
if ((cur[0] && vir[0] == 0xff) || (cur[1] && vir[1] == 0xff) ||
|
||||
(cur[2] && vir[2] == 0xff) || (cur[3] && vir[3] == 0xff) ||
|
||||
(cur[4] && vir[4] == 0xff) || (cur[5] && vir[5] == 0xff) ||
|
||||
(cur[6] && vir[6] == 0xff) || (cur[7] && vir[7] == 0xff))
|
||||
ret = 2;
|
||||
else
|
||||
ret = 1;
|
||||
|
||||
#else
|
||||
|
||||
if ((cur[0] && vir[0] == 0xff) || (cur[1] && vir[1] == 0xff) ||
|
||||
(cur[2] && vir[2] == 0xff) || (cur[3] && vir[3] == 0xff))
|
||||
ret = 2;
|
||||
else
|
||||
ret = 1;
|
||||
|
||||
#endif /* ^__x86_64__ */
|
||||
|
||||
}
|
||||
|
||||
*virgin &= ~*current;
|
||||
|
||||
}
|
||||
|
||||
++current;
|
||||
++virgin;
|
||||
|
||||
}
|
||||
|
||||
if (ret && virgin_map == virgin_bits) bitmap_changed = 1;
|
||||
|
||||
return ret;
|
||||
|
||||
}
|
||||
|
||||
/* Count the number of bits set in the provided bitmap. Used for the status
|
||||
screen several times every second, does not have to be fast. */
|
||||
|
||||
u32 count_bits(u8* mem) {
|
||||
|
||||
u32* ptr = (u32*)mem;
|
||||
u32 i = (MAP_SIZE >> 2);
|
||||
u32 ret = 0;
|
||||
|
||||
while (i--) {
|
||||
|
||||
u32 v = *(ptr++);
|
||||
|
||||
/* This gets called on the inverse, virgin bitmap; optimize for sparse
|
||||
data. */
|
||||
|
||||
if (v == 0xffffffff) {
|
||||
|
||||
ret += 32;
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
v -= ((v >> 1) & 0x55555555);
|
||||
v = (v & 0x33333333) + ((v >> 2) & 0x33333333);
|
||||
ret += (((v + (v >> 4)) & 0xF0F0F0F) * 0x01010101) >> 24;
|
||||
|
||||
}
|
||||
|
||||
return ret;
|
||||
|
||||
}
|
||||
|
||||
#define FF(_b) (0xff << ((_b) << 3))
|
||||
|
||||
/* Count the number of bytes set in the bitmap. Called fairly sporadically,
|
||||
mostly to update the status screen or calibrate and examine confirmed
|
||||
new paths. */
|
||||
|
||||
u32 count_bytes(u8* mem) {
|
||||
|
||||
u32* ptr = (u32*)mem;
|
||||
u32 i = (MAP_SIZE >> 2);
|
||||
u32 ret = 0;
|
||||
|
||||
while (i--) {
|
||||
|
||||
u32 v = *(ptr++);
|
||||
|
||||
if (!v) continue;
|
||||
if (v & FF(0)) ++ret;
|
||||
if (v & FF(1)) ++ret;
|
||||
if (v & FF(2)) ++ret;
|
||||
if (v & FF(3)) ++ret;
|
||||
|
||||
}
|
||||
|
||||
return ret;
|
||||
|
||||
}
|
||||
|
||||
/* Count the number of non-255 bytes set in the bitmap. Used strictly for the
|
||||
status screen, several calls per second or so. */
|
||||
|
||||
u32 count_non_255_bytes(u8* mem) {
|
||||
|
||||
u32* ptr = (u32*)mem;
|
||||
u32 i = (MAP_SIZE >> 2);
|
||||
u32 ret = 0;
|
||||
|
||||
while (i--) {
|
||||
|
||||
u32 v = *(ptr++);
|
||||
|
||||
/* This is called on the virgin bitmap, so optimize for the most likely
|
||||
case. */
|
||||
|
||||
if (v == 0xffffffff) continue;
|
||||
if ((v & FF(0)) != FF(0)) ++ret;
|
||||
if ((v & FF(1)) != FF(1)) ++ret;
|
||||
if ((v & FF(2)) != FF(2)) ++ret;
|
||||
if ((v & FF(3)) != FF(3)) ++ret;
|
||||
|
||||
}
|
||||
|
||||
return ret;
|
||||
|
||||
}
|
||||
|
||||
/* Destructively simplify trace by eliminating hit count information
|
||||
and replacing it with 0x80 or 0x01 depending on whether the tuple
|
||||
is hit or not. Called on every new crash or timeout, should be
|
||||
reasonably fast. */
|
||||
|
||||
const u8 simplify_lookup[256] = {
|
||||
|
||||
[0] = 1, [1 ... 255] = 128
|
||||
|
||||
};
|
||||
|
||||
#ifdef __x86_64__
|
||||
|
||||
void simplify_trace(u64* mem) {
|
||||
|
||||
u32 i = MAP_SIZE >> 3;
|
||||
|
||||
while (i--) {
|
||||
|
||||
/* Optimize for sparse bitmaps. */
|
||||
|
||||
if (unlikely(*mem)) {
|
||||
|
||||
u8* mem8 = (u8*)mem;
|
||||
|
||||
mem8[0] = simplify_lookup[mem8[0]];
|
||||
mem8[1] = simplify_lookup[mem8[1]];
|
||||
mem8[2] = simplify_lookup[mem8[2]];
|
||||
mem8[3] = simplify_lookup[mem8[3]];
|
||||
mem8[4] = simplify_lookup[mem8[4]];
|
||||
mem8[5] = simplify_lookup[mem8[5]];
|
||||
mem8[6] = simplify_lookup[mem8[6]];
|
||||
mem8[7] = simplify_lookup[mem8[7]];
|
||||
|
||||
} else
|
||||
|
||||
*mem = 0x0101010101010101ULL;
|
||||
|
||||
++mem;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
#else
|
||||
|
||||
void simplify_trace(u32* mem) {
|
||||
|
||||
u32 i = MAP_SIZE >> 2;
|
||||
|
||||
while (i--) {
|
||||
|
||||
/* Optimize for sparse bitmaps. */
|
||||
|
||||
if (unlikely(*mem)) {
|
||||
|
||||
u8* mem8 = (u8*)mem;
|
||||
|
||||
mem8[0] = simplify_lookup[mem8[0]];
|
||||
mem8[1] = simplify_lookup[mem8[1]];
|
||||
mem8[2] = simplify_lookup[mem8[2]];
|
||||
mem8[3] = simplify_lookup[mem8[3]];
|
||||
|
||||
} else
|
||||
|
||||
*mem = 0x01010101;
|
||||
|
||||
++mem;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
#endif /* ^__x86_64__ */
|
||||
|
||||
/* Destructively classify execution counts in a trace. This is used as a
|
||||
preprocessing step for any newly acquired traces. Called on every exec,
|
||||
must be fast. */
|
||||
|
||||
static const u8 count_class_lookup8[256] = {
|
||||
|
||||
[0] = 0,
|
||||
[1] = 1,
|
||||
[2] = 2,
|
||||
[3] = 4,
|
||||
[4 ... 7] = 8,
|
||||
[8 ... 15] = 16,
|
||||
[16 ... 31] = 32,
|
||||
[32 ... 127] = 64,
|
||||
[128 ... 255] = 128
|
||||
|
||||
};
|
||||
|
||||
static u16 count_class_lookup16[65536];
|
||||
|
||||
void init_count_class16(void) {
|
||||
|
||||
u32 b1, b2;
|
||||
|
||||
for (b1 = 0; b1 < 256; b1++)
|
||||
for (b2 = 0; b2 < 256; b2++)
|
||||
count_class_lookup16[(b1 << 8) + b2] =
|
||||
(count_class_lookup8[b1] << 8) | count_class_lookup8[b2];
|
||||
|
||||
}
|
||||
|
||||
#ifdef __x86_64__
|
||||
|
||||
void classify_counts(u64* mem) {
|
||||
|
||||
u32 i = MAP_SIZE >> 3;
|
||||
|
||||
while (i--) {
|
||||
|
||||
/* Optimize for sparse bitmaps. */
|
||||
|
||||
if (unlikely(*mem)) {
|
||||
|
||||
u16* mem16 = (u16*)mem;
|
||||
|
||||
mem16[0] = count_class_lookup16[mem16[0]];
|
||||
mem16[1] = count_class_lookup16[mem16[1]];
|
||||
mem16[2] = count_class_lookup16[mem16[2]];
|
||||
mem16[3] = count_class_lookup16[mem16[3]];
|
||||
|
||||
}
|
||||
|
||||
++mem;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
#else
|
||||
|
||||
void classify_counts(u32* mem) {
|
||||
|
||||
u32 i = MAP_SIZE >> 2;
|
||||
|
||||
while (i--) {
|
||||
|
||||
/* Optimize for sparse bitmaps. */
|
||||
|
||||
if (unlikely(*mem)) {
|
||||
|
||||
u16* mem16 = (u16*)mem;
|
||||
|
||||
mem16[0] = count_class_lookup16[mem16[0]];
|
||||
mem16[1] = count_class_lookup16[mem16[1]];
|
||||
|
||||
}
|
||||
|
||||
++mem;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
#endif /* ^__x86_64__ */
|
||||
|
||||
/* Compact trace bytes into a smaller bitmap. We effectively just drop the
|
||||
count information here. This is called only sporadically, for some
|
||||
new paths. */
|
||||
|
||||
void minimize_bits(u8* dst, u8* src) {
|
||||
|
||||
u32 i = 0;
|
||||
|
||||
while (i < MAP_SIZE) {
|
||||
|
||||
if (*(src++)) dst[i >> 3] |= 1 << (i & 7);
|
||||
++i;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
#ifndef SIMPLE_FILES
|
||||
|
||||
/* Construct a file name for a new test case, capturing the operation
|
||||
that led to its discovery. Uses a static buffer. */
|
||||
|
||||
u8* describe_op(u8 hnb) {
|
||||
|
||||
static u8 ret[256];
|
||||
|
||||
if (syncing_party) {
|
||||
|
||||
sprintf(ret, "sync:%s,src:%06u", syncing_party, syncing_case);
|
||||
|
||||
} else {
|
||||
|
||||
sprintf(ret, "src:%06u", current_entry);
|
||||
|
||||
sprintf(ret + strlen(ret), ",time:%llu", get_cur_time() - start_time);
|
||||
|
||||
if (splicing_with >= 0) sprintf(ret + strlen(ret), "+%06d", splicing_with);
|
||||
|
||||
sprintf(ret + strlen(ret), ",op:%s", stage_short);
|
||||
|
||||
if (stage_cur_byte >= 0) {
|
||||
|
||||
sprintf(ret + strlen(ret), ",pos:%d", stage_cur_byte);
|
||||
|
||||
if (stage_val_type != STAGE_VAL_NONE)
|
||||
sprintf(ret + strlen(ret), ",val:%s%+d",
|
||||
(stage_val_type == STAGE_VAL_BE) ? "be:" : "", stage_cur_val);
|
||||
|
||||
} else
|
||||
|
||||
sprintf(ret + strlen(ret), ",rep:%d", stage_cur_val);
|
||||
|
||||
}
|
||||
|
||||
if (hnb == 2) strcat(ret, ",+cov");
|
||||
|
||||
return ret;
|
||||
|
||||
}
|
||||
|
||||
#endif /* !SIMPLE_FILES */
|
||||
|
||||
/* Write a message accompanying the crash directory :-) */
|
||||
|
||||
static void write_crash_readme(void) {
|
||||
|
||||
u8* fn = alloc_printf("%s/crashes/README.txt", out_dir);
|
||||
s32 fd;
|
||||
FILE* f;
|
||||
|
||||
fd = open(fn, O_WRONLY | O_CREAT | O_EXCL, 0600);
|
||||
ck_free(fn);
|
||||
|
||||
/* Do not die on errors here - that would be impolite. */
|
||||
|
||||
if (fd < 0) return;
|
||||
|
||||
f = fdopen(fd, "w");
|
||||
|
||||
if (!f) {
|
||||
|
||||
close(fd);
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
fprintf(
|
||||
f,
|
||||
"Command line used to find this crash:\n\n"
|
||||
|
||||
"%s\n\n"
|
||||
|
||||
"If you can't reproduce a bug outside of afl-fuzz, be sure to set the "
|
||||
"same\n"
|
||||
"memory limit. The limit used for this fuzzing session was %s.\n\n"
|
||||
|
||||
"Need a tool to minimize test cases before investigating the crashes or "
|
||||
"sending\n"
|
||||
"them to a vendor? Check out the afl-tmin that comes with the fuzzer!\n\n"
|
||||
|
||||
"Found any cool bugs in open-source tools using afl-fuzz? If yes, please "
|
||||
"drop\n"
|
||||
"an mail at <afl-users@googlegroups.com> once the issues are fixed\n\n"
|
||||
|
||||
" https://github.com/vanhauser-thc/AFLplusplus\n\n",
|
||||
|
||||
orig_cmdline, DMS(mem_limit << 20)); /* ignore errors */
|
||||
|
||||
fclose(f);
|
||||
|
||||
}
|
||||
|
||||
/* Check if the result of an execve() during routine fuzzing is interesting,
|
||||
save or queue the input test case for further analysis if so. Returns 1 if
|
||||
entry is saved, 0 otherwise. */
|
||||
|
||||
u8 save_if_interesting(char** argv, void* mem, u32 len, u8 fault) {
|
||||
|
||||
if (len == 0) return 0;
|
||||
|
||||
u8* fn = "";
|
||||
u8 hnb;
|
||||
s32 fd;
|
||||
u8 keeping = 0, res;
|
||||
|
||||
/* Update path frequency. */
|
||||
u32 cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST);
|
||||
|
||||
struct queue_entry* q = queue;
|
||||
while (q) {
|
||||
|
||||
if (q->exec_cksum == cksum) q->n_fuzz = q->n_fuzz + 1;
|
||||
|
||||
q = q->next;
|
||||
|
||||
}
|
||||
|
||||
if (fault == crash_mode) {
|
||||
|
||||
/* Keep only if there are new bits in the map, add to queue for
|
||||
future fuzzing, etc. */
|
||||
|
||||
if (!(hnb = has_new_bits(virgin_bits))) {
|
||||
|
||||
if (crash_mode) ++total_crashes;
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
#ifndef SIMPLE_FILES
|
||||
|
||||
fn = alloc_printf("%s/queue/id:%06u,%s", out_dir, queued_paths,
|
||||
describe_op(hnb));
|
||||
|
||||
#else
|
||||
|
||||
fn = alloc_printf("%s/queue/id_%06u", out_dir, queued_paths);
|
||||
|
||||
#endif /* ^!SIMPLE_FILES */
|
||||
|
||||
add_to_queue(fn, len, 0);
|
||||
|
||||
if (hnb == 2) {
|
||||
|
||||
queue_top->has_new_cov = 1;
|
||||
++queued_with_cov;
|
||||
|
||||
}
|
||||
|
||||
queue_top->exec_cksum = cksum;
|
||||
|
||||
/* Try to calibrate inline; this also calls update_bitmap_score() when
|
||||
successful. */
|
||||
|
||||
res = calibrate_case(argv, queue_top, mem, queue_cycle - 1, 0);
|
||||
|
||||
if (res == FAULT_ERROR) FATAL("Unable to execute target application");
|
||||
|
||||
fd = open(fn, O_WRONLY | O_CREAT | O_EXCL, 0600);
|
||||
if (fd < 0) PFATAL("Unable to create '%s'", fn);
|
||||
ck_write(fd, mem, len, fn);
|
||||
close(fd);
|
||||
|
||||
keeping = 1;
|
||||
|
||||
}
|
||||
|
||||
switch (fault) {
|
||||
|
||||
case FAULT_TMOUT:
|
||||
|
||||
/* Timeouts are not very interesting, but we're still obliged to keep
|
||||
a handful of samples. We use the presence of new bits in the
|
||||
hang-specific bitmap as a signal of uniqueness. In "dumb" mode, we
|
||||
just keep everything. */
|
||||
|
||||
++total_tmouts;
|
||||
|
||||
if (unique_hangs >= KEEP_UNIQUE_HANG) return keeping;
|
||||
|
||||
if (!dumb_mode) {
|
||||
|
||||
#ifdef __x86_64__
|
||||
simplify_trace((u64*)trace_bits);
|
||||
#else
|
||||
simplify_trace((u32*)trace_bits);
|
||||
#endif /* ^__x86_64__ */
|
||||
|
||||
if (!has_new_bits(virgin_tmout)) return keeping;
|
||||
|
||||
}
|
||||
|
||||
++unique_tmouts;
|
||||
|
||||
/* Before saving, we make sure that it's a genuine hang by re-running
|
||||
the target with a more generous timeout (unless the default timeout
|
||||
is already generous). */
|
||||
|
||||
if (exec_tmout < hang_tmout) {
|
||||
|
||||
u8 new_fault;
|
||||
write_to_testcase(mem, len);
|
||||
new_fault = run_target(argv, hang_tmout);
|
||||
|
||||
/* A corner case that one user reported bumping into: increasing the
|
||||
timeout actually uncovers a crash. Make sure we don't discard it if
|
||||
so. */
|
||||
|
||||
if (!stop_soon && new_fault == FAULT_CRASH) goto keep_as_crash;
|
||||
|
||||
if (stop_soon || new_fault != FAULT_TMOUT) return keeping;
|
||||
|
||||
}
|
||||
|
||||
#ifndef SIMPLE_FILES
|
||||
|
||||
fn = alloc_printf("%s/hangs/id:%06llu,%s", out_dir, unique_hangs,
|
||||
describe_op(0));
|
||||
|
||||
#else
|
||||
|
||||
fn = alloc_printf("%s/hangs/id_%06llu", out_dir, unique_hangs);
|
||||
|
||||
#endif /* ^!SIMPLE_FILES */
|
||||
|
||||
++unique_hangs;
|
||||
|
||||
last_hang_time = get_cur_time();
|
||||
|
||||
break;
|
||||
|
||||
case FAULT_CRASH:
|
||||
|
||||
keep_as_crash:
|
||||
|
||||
/* This is handled in a manner roughly similar to timeouts,
|
||||
except for slightly different limits and no need to re-run test
|
||||
cases. */
|
||||
|
||||
++total_crashes;
|
||||
|
||||
if (unique_crashes >= KEEP_UNIQUE_CRASH) return keeping;
|
||||
|
||||
if (!dumb_mode) {
|
||||
|
||||
#ifdef __x86_64__
|
||||
simplify_trace((u64*)trace_bits);
|
||||
#else
|
||||
simplify_trace((u32*)trace_bits);
|
||||
#endif /* ^__x86_64__ */
|
||||
|
||||
if (!has_new_bits(virgin_crash)) return keeping;
|
||||
|
||||
}
|
||||
|
||||
if (!unique_crashes) write_crash_readme();
|
||||
|
||||
#ifndef SIMPLE_FILES
|
||||
|
||||
fn = alloc_printf("%s/crashes/id:%06llu,sig:%02u,%s", out_dir,
|
||||
unique_crashes, kill_signal, describe_op(0));
|
||||
|
||||
#else
|
||||
|
||||
fn = alloc_printf("%s/crashes/id_%06llu_%02u", out_dir, unique_crashes,
|
||||
kill_signal);
|
||||
|
||||
#endif /* ^!SIMPLE_FILES */
|
||||
|
||||
++unique_crashes;
|
||||
|
||||
last_crash_time = get_cur_time();
|
||||
last_crash_execs = total_execs;
|
||||
|
||||
break;
|
||||
|
||||
case FAULT_ERROR: FATAL("Unable to execute target application");
|
||||
|
||||
default: return keeping;
|
||||
|
||||
}
|
||||
|
||||
/* If we're here, we apparently want to save the crash or hang
|
||||
test case, too. */
|
||||
|
||||
fd = open(fn, O_WRONLY | O_CREAT | O_EXCL, 0600);
|
||||
if (fd < 0) PFATAL("Unable to create '%s'", fn);
|
||||
ck_write(fd, mem, len, fn);
|
||||
close(fd);
|
||||
|
||||
ck_free(fn);
|
||||
|
||||
return keeping;
|
||||
|
||||
}
|
||||
|
||||
488
src/afl-fuzz-extras.c
Normal file
488
src/afl-fuzz-extras.c
Normal file
@ -0,0 +1,488 @@
|
||||
/*
|
||||
american fuzzy lop++ - extras relates routines
|
||||
----------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This is the real deal: the program takes an instrumented binary and
|
||||
attempts a variety of basic fuzzing tricks, paying close attention to
|
||||
how they affect the execution path.
|
||||
|
||||
*/
|
||||
|
||||
#include "afl-fuzz.h"
|
||||
|
||||
/* Helper function for load_extras. */
|
||||
|
||||
static int compare_extras_len(const void* p1, const void* p2) {
|
||||
|
||||
struct extra_data *e1 = (struct extra_data*)p1, *e2 = (struct extra_data*)p2;
|
||||
|
||||
return e1->len - e2->len;
|
||||
|
||||
}
|
||||
|
||||
static int compare_extras_use_d(const void* p1, const void* p2) {
|
||||
|
||||
struct extra_data *e1 = (struct extra_data*)p1, *e2 = (struct extra_data*)p2;
|
||||
|
||||
return e2->hit_cnt - e1->hit_cnt;
|
||||
|
||||
}
|
||||
|
||||
/* Read extras from a file, sort by size. */
|
||||
|
||||
void load_extras_file(u8* fname, u32* min_len, u32* max_len, u32 dict_level) {
|
||||
|
||||
FILE* f;
|
||||
u8 buf[MAX_LINE];
|
||||
u8* lptr;
|
||||
u32 cur_line = 0;
|
||||
|
||||
f = fopen(fname, "r");
|
||||
|
||||
if (!f) PFATAL("Unable to open '%s'", fname);
|
||||
|
||||
while ((lptr = fgets(buf, MAX_LINE, f))) {
|
||||
|
||||
u8 *rptr, *wptr;
|
||||
u32 klen = 0;
|
||||
|
||||
++cur_line;
|
||||
|
||||
/* Trim on left and right. */
|
||||
|
||||
while (isspace(*lptr))
|
||||
++lptr;
|
||||
|
||||
rptr = lptr + strlen(lptr) - 1;
|
||||
while (rptr >= lptr && isspace(*rptr))
|
||||
--rptr;
|
||||
++rptr;
|
||||
*rptr = 0;
|
||||
|
||||
/* Skip empty lines and comments. */
|
||||
|
||||
if (!*lptr || *lptr == '#') continue;
|
||||
|
||||
/* All other lines must end with '"', which we can consume. */
|
||||
|
||||
--rptr;
|
||||
|
||||
if (rptr < lptr || *rptr != '"')
|
||||
FATAL("Malformed name=\"value\" pair in line %u.", cur_line);
|
||||
|
||||
*rptr = 0;
|
||||
|
||||
/* Skip alphanumerics and dashes (label). */
|
||||
|
||||
while (isalnum(*lptr) || *lptr == '_')
|
||||
++lptr;
|
||||
|
||||
/* If @number follows, parse that. */
|
||||
|
||||
if (*lptr == '@') {
|
||||
|
||||
++lptr;
|
||||
if (atoi(lptr) > dict_level) continue;
|
||||
while (isdigit(*lptr))
|
||||
++lptr;
|
||||
|
||||
}
|
||||
|
||||
/* Skip whitespace and = signs. */
|
||||
|
||||
while (isspace(*lptr) || *lptr == '=')
|
||||
++lptr;
|
||||
|
||||
/* Consume opening '"'. */
|
||||
|
||||
if (*lptr != '"')
|
||||
FATAL("Malformed name=\"keyword\" pair in line %u.", cur_line);
|
||||
|
||||
++lptr;
|
||||
|
||||
if (!*lptr) FATAL("Empty keyword in line %u.", cur_line);
|
||||
|
||||
/* Okay, let's allocate memory and copy data between "...", handling
|
||||
\xNN escaping, \\, and \". */
|
||||
|
||||
extras =
|
||||
ck_realloc_block(extras, (extras_cnt + 1) * sizeof(struct extra_data));
|
||||
|
||||
wptr = extras[extras_cnt].data = ck_alloc(rptr - lptr);
|
||||
|
||||
while (*lptr) {
|
||||
|
||||
char* hexdigits = "0123456789abcdef";
|
||||
|
||||
switch (*lptr) {
|
||||
|
||||
case 1 ... 31:
|
||||
case 128 ... 255:
|
||||
FATAL("Non-printable characters in line %u.", cur_line);
|
||||
|
||||
case '\\':
|
||||
|
||||
++lptr;
|
||||
|
||||
if (*lptr == '\\' || *lptr == '"') {
|
||||
|
||||
*(wptr++) = *(lptr++);
|
||||
klen++;
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
if (*lptr != 'x' || !isxdigit(lptr[1]) || !isxdigit(lptr[2]))
|
||||
FATAL("Invalid escaping (not \\xNN) in line %u.", cur_line);
|
||||
|
||||
*(wptr++) = ((strchr(hexdigits, tolower(lptr[1])) - hexdigits) << 4) |
|
||||
(strchr(hexdigits, tolower(lptr[2])) - hexdigits);
|
||||
|
||||
lptr += 3;
|
||||
++klen;
|
||||
|
||||
break;
|
||||
|
||||
default: *(wptr++) = *(lptr++); ++klen;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
extras[extras_cnt].len = klen;
|
||||
|
||||
if (extras[extras_cnt].len > MAX_DICT_FILE)
|
||||
FATAL("Keyword too big in line %u (%s, limit is %s)", cur_line, DMS(klen),
|
||||
DMS(MAX_DICT_FILE));
|
||||
|
||||
if (*min_len > klen) *min_len = klen;
|
||||
if (*max_len < klen) *max_len = klen;
|
||||
|
||||
++extras_cnt;
|
||||
|
||||
}
|
||||
|
||||
fclose(f);
|
||||
|
||||
}
|
||||
|
||||
/* Read extras from the extras directory and sort them by size. */
|
||||
|
||||
void load_extras(u8* dir) {
|
||||
|
||||
DIR* d;
|
||||
struct dirent* de;
|
||||
u32 min_len = MAX_DICT_FILE, max_len = 0, dict_level = 0;
|
||||
u8* x;
|
||||
|
||||
/* If the name ends with @, extract level and continue. */
|
||||
|
||||
if ((x = strchr(dir, '@'))) {
|
||||
|
||||
*x = 0;
|
||||
dict_level = atoi(x + 1);
|
||||
|
||||
}
|
||||
|
||||
ACTF("Loading extra dictionary from '%s' (level %u)...", dir, dict_level);
|
||||
|
||||
d = opendir(dir);
|
||||
|
||||
if (!d) {
|
||||
|
||||
if (errno == ENOTDIR) {
|
||||
|
||||
load_extras_file(dir, &min_len, &max_len, dict_level);
|
||||
goto check_and_sort;
|
||||
|
||||
}
|
||||
|
||||
PFATAL("Unable to open '%s'", dir);
|
||||
|
||||
}
|
||||
|
||||
if (x) FATAL("Dictionary levels not supported for directories.");
|
||||
|
||||
while ((de = readdir(d))) {
|
||||
|
||||
struct stat st;
|
||||
u8* fn = alloc_printf("%s/%s", dir, de->d_name);
|
||||
s32 fd;
|
||||
|
||||
if (lstat(fn, &st) || access(fn, R_OK)) PFATAL("Unable to access '%s'", fn);
|
||||
|
||||
/* This also takes care of . and .. */
|
||||
if (!S_ISREG(st.st_mode) || !st.st_size) {
|
||||
|
||||
ck_free(fn);
|
||||
continue;
|
||||
|
||||
}
|
||||
|
||||
if (st.st_size > MAX_DICT_FILE)
|
||||
FATAL("Extra '%s' is too big (%s, limit is %s)", fn, DMS(st.st_size),
|
||||
DMS(MAX_DICT_FILE));
|
||||
|
||||
if (min_len > st.st_size) min_len = st.st_size;
|
||||
if (max_len < st.st_size) max_len = st.st_size;
|
||||
|
||||
extras =
|
||||
ck_realloc_block(extras, (extras_cnt + 1) * sizeof(struct extra_data));
|
||||
|
||||
extras[extras_cnt].data = ck_alloc(st.st_size);
|
||||
extras[extras_cnt].len = st.st_size;
|
||||
|
||||
fd = open(fn, O_RDONLY);
|
||||
|
||||
if (fd < 0) PFATAL("Unable to open '%s'", fn);
|
||||
|
||||
ck_read(fd, extras[extras_cnt].data, st.st_size, fn);
|
||||
|
||||
close(fd);
|
||||
ck_free(fn);
|
||||
|
||||
++extras_cnt;
|
||||
|
||||
}
|
||||
|
||||
closedir(d);
|
||||
|
||||
check_and_sort:
|
||||
|
||||
if (!extras_cnt) FATAL("No usable files in '%s'", dir);
|
||||
|
||||
qsort(extras, extras_cnt, sizeof(struct extra_data), compare_extras_len);
|
||||
|
||||
OKF("Loaded %u extra tokens, size range %s to %s.", extras_cnt, DMS(min_len),
|
||||
DMS(max_len));
|
||||
|
||||
if (max_len > 32)
|
||||
WARNF("Some tokens are relatively large (%s) - consider trimming.",
|
||||
DMS(max_len));
|
||||
|
||||
if (extras_cnt > MAX_DET_EXTRAS)
|
||||
WARNF("More than %d tokens - will use them probabilistically.",
|
||||
MAX_DET_EXTRAS);
|
||||
|
||||
}
|
||||
|
||||
/* Helper function for maybe_add_auto() */
|
||||
|
||||
static inline u8 memcmp_nocase(u8* m1, u8* m2, u32 len) {
|
||||
|
||||
while (len--)
|
||||
if (tolower(*(m1++)) ^ tolower(*(m2++))) return 1;
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
/* Maybe add automatic extra. */
|
||||
|
||||
void maybe_add_auto(u8* mem, u32 len) {
|
||||
|
||||
u32 i;
|
||||
|
||||
/* Allow users to specify that they don't want auto dictionaries. */
|
||||
|
||||
if (!MAX_AUTO_EXTRAS || !USE_AUTO_EXTRAS) return;
|
||||
|
||||
/* Skip runs of identical bytes. */
|
||||
|
||||
for (i = 1; i < len; ++i)
|
||||
if (mem[0] ^ mem[i]) break;
|
||||
|
||||
if (i == len) return;
|
||||
|
||||
/* Reject builtin interesting values. */
|
||||
|
||||
if (len == 2) {
|
||||
|
||||
i = sizeof(interesting_16) >> 1;
|
||||
|
||||
while (i--)
|
||||
if (*((u16*)mem) == interesting_16[i] ||
|
||||
*((u16*)mem) == SWAP16(interesting_16[i]))
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
if (len == 4) {
|
||||
|
||||
i = sizeof(interesting_32) >> 2;
|
||||
|
||||
while (i--)
|
||||
if (*((u32*)mem) == interesting_32[i] ||
|
||||
*((u32*)mem) == SWAP32(interesting_32[i]))
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
/* Reject anything that matches existing extras. Do a case-insensitive
|
||||
match. We optimize by exploiting the fact that extras[] are sorted
|
||||
by size. */
|
||||
|
||||
for (i = 0; i < extras_cnt; ++i)
|
||||
if (extras[i].len >= len) break;
|
||||
|
||||
for (; i < extras_cnt && extras[i].len == len; ++i)
|
||||
if (!memcmp_nocase(extras[i].data, mem, len)) return;
|
||||
|
||||
/* Last but not least, check a_extras[] for matches. There are no
|
||||
guarantees of a particular sort order. */
|
||||
|
||||
auto_changed = 1;
|
||||
|
||||
for (i = 0; i < a_extras_cnt; ++i) {
|
||||
|
||||
if (a_extras[i].len == len && !memcmp_nocase(a_extras[i].data, mem, len)) {
|
||||
|
||||
a_extras[i].hit_cnt++;
|
||||
goto sort_a_extras;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* At this point, looks like we're dealing with a new entry. So, let's
|
||||
append it if we have room. Otherwise, let's randomly evict some other
|
||||
entry from the bottom half of the list. */
|
||||
|
||||
if (a_extras_cnt < MAX_AUTO_EXTRAS) {
|
||||
|
||||
a_extras = ck_realloc_block(a_extras,
|
||||
(a_extras_cnt + 1) * sizeof(struct extra_data));
|
||||
|
||||
a_extras[a_extras_cnt].data = ck_memdup(mem, len);
|
||||
a_extras[a_extras_cnt].len = len;
|
||||
++a_extras_cnt;
|
||||
|
||||
} else {
|
||||
|
||||
i = MAX_AUTO_EXTRAS / 2 + UR((MAX_AUTO_EXTRAS + 1) / 2);
|
||||
|
||||
ck_free(a_extras[i].data);
|
||||
|
||||
a_extras[i].data = ck_memdup(mem, len);
|
||||
a_extras[i].len = len;
|
||||
a_extras[i].hit_cnt = 0;
|
||||
|
||||
}
|
||||
|
||||
sort_a_extras:
|
||||
|
||||
/* First, sort all auto extras by use count, descending order. */
|
||||
|
||||
qsort(a_extras, a_extras_cnt, sizeof(struct extra_data),
|
||||
compare_extras_use_d);
|
||||
|
||||
/* Then, sort the top USE_AUTO_EXTRAS entries by size. */
|
||||
|
||||
qsort(a_extras, MIN(USE_AUTO_EXTRAS, a_extras_cnt), sizeof(struct extra_data),
|
||||
compare_extras_len);
|
||||
|
||||
}
|
||||
|
||||
/* Save automatically generated extras. */
|
||||
|
||||
void save_auto(void) {
|
||||
|
||||
u32 i;
|
||||
|
||||
if (!auto_changed) return;
|
||||
auto_changed = 0;
|
||||
|
||||
for (i = 0; i < MIN(USE_AUTO_EXTRAS, a_extras_cnt); ++i) {
|
||||
|
||||
u8* fn = alloc_printf("%s/queue/.state/auto_extras/auto_%06u", out_dir, i);
|
||||
s32 fd;
|
||||
|
||||
fd = open(fn, O_WRONLY | O_CREAT | O_TRUNC, 0600);
|
||||
|
||||
if (fd < 0) PFATAL("Unable to create '%s'", fn);
|
||||
|
||||
ck_write(fd, a_extras[i].data, a_extras[i].len, fn);
|
||||
|
||||
close(fd);
|
||||
ck_free(fn);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* Load automatically generated extras. */
|
||||
|
||||
void load_auto(void) {
|
||||
|
||||
u32 i;
|
||||
|
||||
for (i = 0; i < USE_AUTO_EXTRAS; ++i) {
|
||||
|
||||
u8 tmp[MAX_AUTO_EXTRA + 1];
|
||||
u8* fn = alloc_printf("%s/.state/auto_extras/auto_%06u", in_dir, i);
|
||||
s32 fd, len;
|
||||
|
||||
fd = open(fn, O_RDONLY, 0600);
|
||||
|
||||
if (fd < 0) {
|
||||
|
||||
if (errno != ENOENT) PFATAL("Unable to open '%s'", fn);
|
||||
ck_free(fn);
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
/* We read one byte more to cheaply detect tokens that are too
|
||||
long (and skip them). */
|
||||
|
||||
len = read(fd, tmp, MAX_AUTO_EXTRA + 1);
|
||||
|
||||
if (len < 0) PFATAL("Unable to read from '%s'", fn);
|
||||
|
||||
if (len >= MIN_AUTO_EXTRA && len <= MAX_AUTO_EXTRA)
|
||||
maybe_add_auto(tmp, len);
|
||||
|
||||
close(fd);
|
||||
ck_free(fn);
|
||||
|
||||
}
|
||||
|
||||
if (i)
|
||||
OKF("Loaded %u auto-discovered dictionary tokens.", i);
|
||||
else
|
||||
OKF("No auto-generated dictionary tokens to reuse.");
|
||||
|
||||
}
|
||||
|
||||
/* Destroy extras. */
|
||||
|
||||
void destroy_extras(void) {
|
||||
|
||||
u32 i;
|
||||
|
||||
for (i = 0; i < extras_cnt; ++i)
|
||||
ck_free(extras[i].data);
|
||||
|
||||
ck_free(extras);
|
||||
|
||||
for (i = 0; i < a_extras_cnt; ++i)
|
||||
ck_free(a_extras[i].data);
|
||||
|
||||
ck_free(a_extras);
|
||||
|
||||
}
|
||||
|
||||
260
src/afl-fuzz-globals.c
Normal file
260
src/afl-fuzz-globals.c
Normal file
@ -0,0 +1,260 @@
|
||||
/*
|
||||
american fuzzy lop++ - globals declarations
|
||||
-------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This is the real deal: the program takes an instrumented binary and
|
||||
attempts a variety of basic fuzzing tricks, paying close attention to
|
||||
how they affect the execution path.
|
||||
|
||||
*/
|
||||
|
||||
#include "afl-fuzz.h"
|
||||
|
||||
/* MOpt:
|
||||
Lots of globals, but mostly for the status UI and other things where it
|
||||
really makes no sense to haul them around as function parameters. */
|
||||
u64 limit_time_puppet, orig_hit_cnt_puppet, last_limit_time_start,
|
||||
tmp_pilot_time, total_pacemaker_time, total_puppet_find, temp_puppet_find,
|
||||
most_time_key, most_time, most_execs_key, most_execs, old_hit_count;
|
||||
|
||||
s32 SPLICE_CYCLES_puppet, limit_time_sig, key_puppet, key_module;
|
||||
|
||||
double w_init = 0.9, w_end = 0.3, w_now;
|
||||
|
||||
s32 g_now;
|
||||
s32 g_max = 5000;
|
||||
|
||||
u64 tmp_core_time;
|
||||
s32 swarm_now;
|
||||
|
||||
double x_now[swarm_num][operator_num], L_best[swarm_num][operator_num],
|
||||
eff_best[swarm_num][operator_num], G_best[operator_num],
|
||||
v_now[swarm_num][operator_num], probability_now[swarm_num][operator_num],
|
||||
swarm_fitness[swarm_num];
|
||||
|
||||
u64 stage_finds_puppet[swarm_num]
|
||||
[operator_num], /* Patterns found per fuzz stage */
|
||||
stage_finds_puppet_v2[swarm_num][operator_num],
|
||||
stage_cycles_puppet_v2[swarm_num][operator_num],
|
||||
stage_cycles_puppet_v3[swarm_num][operator_num],
|
||||
stage_cycles_puppet[swarm_num][operator_num],
|
||||
operator_finds_puppet[operator_num],
|
||||
core_operator_finds_puppet[operator_num],
|
||||
core_operator_finds_puppet_v2[operator_num],
|
||||
core_operator_cycles_puppet[operator_num],
|
||||
core_operator_cycles_puppet_v2[operator_num],
|
||||
core_operator_cycles_puppet_v3[operator_num]; /* Execs per fuzz stage */
|
||||
|
||||
double period_pilot_tmp = 5000.0;
|
||||
s32 key_lv;
|
||||
|
||||
u8 *in_dir, /* Input directory with test cases */
|
||||
*out_dir, /* Working & output directory */
|
||||
*tmp_dir, /* Temporary directory for input */
|
||||
*sync_dir, /* Synchronization directory */
|
||||
*sync_id, /* Fuzzer ID */
|
||||
*power_name, /* Power schedule name */
|
||||
*use_banner, /* Display banner */
|
||||
*in_bitmap, /* Input bitmap */
|
||||
*file_extension, /* File extension */
|
||||
*orig_cmdline; /* Original command line */
|
||||
u8 *doc_path, /* Path to documentation dir */
|
||||
*target_path, /* Path to target binary */
|
||||
*out_file; /* File to fuzz, if any */
|
||||
|
||||
u32 exec_tmout = EXEC_TIMEOUT; /* Configurable exec timeout (ms) */
|
||||
u32 hang_tmout = EXEC_TIMEOUT; /* Timeout used for hang det (ms) */
|
||||
|
||||
u64 mem_limit = MEM_LIMIT; /* Memory cap for child (MB) */
|
||||
|
||||
u8 cal_cycles = CAL_CYCLES, /* Calibration cycles defaults */
|
||||
cal_cycles_long = CAL_CYCLES_LONG, debug, /* Debug mode */
|
||||
python_only; /* Python-only mode */
|
||||
|
||||
u32 stats_update_freq = 1; /* Stats update frequency (execs) */
|
||||
|
||||
char *power_names[POWER_SCHEDULES_NUM] = {"explore", "fast", "coe",
|
||||
"lin", "quad", "exploit"};
|
||||
|
||||
u8 schedule = EXPLORE; /* Power schedule (default: EXPLORE)*/
|
||||
u8 havoc_max_mult = HAVOC_MAX_MULT;
|
||||
|
||||
u8 skip_deterministic, /* Skip deterministic stages? */
|
||||
force_deterministic, /* Force deterministic stages? */
|
||||
use_splicing, /* Recombine input files? */
|
||||
dumb_mode, /* Run in non-instrumented mode? */
|
||||
score_changed, /* Scoring for favorites changed? */
|
||||
kill_signal, /* Signal that killed the child */
|
||||
resuming_fuzz, /* Resuming an older fuzzing job? */
|
||||
timeout_given, /* Specific timeout given? */
|
||||
not_on_tty, /* stdout is not a tty */
|
||||
term_too_small, /* terminal dimensions too small */
|
||||
no_forkserver, /* Disable forkserver? */
|
||||
crash_mode, /* Crash mode! Yeah! */
|
||||
in_place_resume, /* Attempt in-place resume? */
|
||||
auto_changed, /* Auto-generated tokens changed? */
|
||||
no_cpu_meter_red, /* Feng shui on the status screen */
|
||||
no_arith, /* Skip most arithmetic ops */
|
||||
shuffle_queue, /* Shuffle input queue? */
|
||||
bitmap_changed = 1, /* Time to update bitmap? */
|
||||
qemu_mode, /* Running in QEMU mode? */
|
||||
unicorn_mode, /* Running in Unicorn mode? */
|
||||
skip_requested, /* Skip request, via SIGUSR1 */
|
||||
run_over10m, /* Run time over 10 minutes? */
|
||||
persistent_mode, /* Running in persistent mode? */
|
||||
deferred_mode, /* Deferred forkserver mode? */
|
||||
fixed_seed, /* do not reseed */
|
||||
fast_cal, /* Try to calibrate faster? */
|
||||
uses_asan; /* Target uses ASAN? */
|
||||
|
||||
s32 out_fd, /* Persistent fd for out_file */
|
||||
#ifndef HAVE_ARC4RANDOM
|
||||
dev_urandom_fd = -1, /* Persistent fd for /dev/urandom */
|
||||
#endif
|
||||
dev_null_fd = -1, /* Persistent fd for /dev/null */
|
||||
fsrv_ctl_fd, /* Fork server control pipe (write) */
|
||||
fsrv_st_fd; /* Fork server status pipe (read) */
|
||||
|
||||
s32 forksrv_pid, /* PID of the fork server */
|
||||
child_pid = -1, /* PID of the fuzzed program */
|
||||
out_dir_fd = -1; /* FD of the lock file */
|
||||
|
||||
u8 *trace_bits; /* SHM with instrumentation bitmap */
|
||||
|
||||
u8 virgin_bits[MAP_SIZE], /* Regions yet untouched by fuzzing */
|
||||
virgin_tmout[MAP_SIZE], /* Bits we haven't seen in tmouts */
|
||||
virgin_crash[MAP_SIZE]; /* Bits we haven't seen in crashes */
|
||||
|
||||
u8 var_bytes[MAP_SIZE]; /* Bytes that appear to be variable */
|
||||
|
||||
volatile u8 stop_soon, /* Ctrl-C pressed? */
|
||||
clear_screen = 1, /* Window resized? */
|
||||
child_timed_out; /* Traced process timed out? */
|
||||
|
||||
u32 queued_paths, /* Total number of queued testcases */
|
||||
queued_variable, /* Testcases with variable behavior */
|
||||
queued_at_start, /* Total number of initial inputs */
|
||||
queued_discovered, /* Items discovered during this run */
|
||||
queued_imported, /* Items imported via -S */
|
||||
queued_favored, /* Paths deemed favorable */
|
||||
queued_with_cov, /* Paths with new coverage bytes */
|
||||
pending_not_fuzzed, /* Queued but not done yet */
|
||||
pending_favored, /* Pending favored paths */
|
||||
cur_skipped_paths, /* Abandoned inputs in cur cycle */
|
||||
cur_depth, /* Current path depth */
|
||||
max_depth, /* Max path depth */
|
||||
useless_at_start, /* Number of useless starting paths */
|
||||
var_byte_count, /* Bitmap bytes with var behavior */
|
||||
current_entry, /* Current queue entry ID */
|
||||
havoc_div = 1; /* Cycle count divisor for havoc */
|
||||
|
||||
u64 total_crashes, /* Total number of crashes */
|
||||
unique_crashes, /* Crashes with unique signatures */
|
||||
total_tmouts, /* Total number of timeouts */
|
||||
unique_tmouts, /* Timeouts with unique signatures */
|
||||
unique_hangs, /* Hangs with unique signatures */
|
||||
total_execs, /* Total execve() calls */
|
||||
slowest_exec_ms, /* Slowest testcase non hang in ms */
|
||||
start_time, /* Unix start time (ms) */
|
||||
last_path_time, /* Time for most recent path (ms) */
|
||||
last_crash_time, /* Time for most recent crash (ms) */
|
||||
last_hang_time, /* Time for most recent hang (ms) */
|
||||
last_crash_execs, /* Exec counter at last crash */
|
||||
queue_cycle, /* Queue round counter */
|
||||
cycles_wo_finds, /* Cycles without any new paths */
|
||||
trim_execs, /* Execs done to trim input files */
|
||||
bytes_trim_in, /* Bytes coming into the trimmer */
|
||||
bytes_trim_out, /* Bytes coming outa the trimmer */
|
||||
blocks_eff_total, /* Blocks subject to effector maps */
|
||||
blocks_eff_select; /* Blocks selected as fuzzable */
|
||||
|
||||
u32 subseq_tmouts; /* Number of timeouts in a row */
|
||||
|
||||
u8 *stage_name = "init", /* Name of the current fuzz stage */
|
||||
*stage_short, /* Short stage name */
|
||||
*syncing_party; /* Currently syncing with... */
|
||||
|
||||
s32 stage_cur, stage_max; /* Stage progression */
|
||||
s32 splicing_with = -1; /* Splicing with which test case? */
|
||||
|
||||
u32 master_id, master_max; /* Master instance job splitting */
|
||||
|
||||
u32 syncing_case; /* Syncing with case #... */
|
||||
|
||||
s32 stage_cur_byte, /* Byte offset of current stage op */
|
||||
stage_cur_val; /* Value used for stage op */
|
||||
|
||||
u8 stage_val_type; /* Value type (STAGE_VAL_*) */
|
||||
|
||||
u64 stage_finds[32], /* Patterns found per fuzz stage */
|
||||
stage_cycles[32]; /* Execs per fuzz stage */
|
||||
|
||||
#ifndef HAVE_ARC4RANDOM
|
||||
u32 rand_cnt; /* Random number counter */
|
||||
#endif
|
||||
|
||||
u64 total_cal_us, /* Total calibration time (us) */
|
||||
total_cal_cycles; /* Total calibration cycles */
|
||||
|
||||
u64 total_bitmap_size, /* Total bit count for all bitmaps */
|
||||
total_bitmap_entries; /* Number of bitmaps counted */
|
||||
|
||||
s32 cpu_core_count; /* CPU core count */
|
||||
|
||||
#ifdef HAVE_AFFINITY
|
||||
|
||||
s32 cpu_aff = -1; /* Selected CPU core */
|
||||
|
||||
#endif /* HAVE_AFFINITY */
|
||||
|
||||
FILE *plot_file; /* Gnuplot output file */
|
||||
|
||||
struct queue_entry *queue, /* Fuzzing queue (linked list) */
|
||||
*queue_cur, /* Current offset within the queue */
|
||||
*queue_top, /* Top of the list */
|
||||
*q_prev100; /* Previous 100 marker */
|
||||
|
||||
struct queue_entry *top_rated[MAP_SIZE]; /* Top entries for bitmap bytes */
|
||||
|
||||
struct extra_data *extras; /* Extra tokens to fuzz with */
|
||||
u32 extras_cnt; /* Total number of tokens read */
|
||||
|
||||
struct extra_data *a_extras; /* Automatically selected extras */
|
||||
u32 a_extras_cnt; /* Total number of tokens available */
|
||||
|
||||
u8 *(*post_handler)(u8 *buf, u32 *len);
|
||||
|
||||
/* hooks for the custom mutator function */
|
||||
size_t (*custom_mutator)(u8 *data, size_t size, u8 *mutated_out,
|
||||
size_t max_size, unsigned int seed);
|
||||
size_t (*pre_save_handler)(u8 *data, size_t size, u8 **new_data);
|
||||
|
||||
/* Interesting values, as per config.h */
|
||||
|
||||
s8 interesting_8[] = {INTERESTING_8};
|
||||
s16 interesting_16[] = {INTERESTING_8, INTERESTING_16};
|
||||
s32 interesting_32[] = {INTERESTING_8, INTERESTING_16, INTERESTING_32};
|
||||
|
||||
/* Python stuff */
|
||||
#ifdef USE_PYTHON
|
||||
|
||||
PyObject *py_module;
|
||||
PyObject *py_functions[PY_FUNC_COUNT];
|
||||
|
||||
#endif
|
||||
|
||||
2067
src/afl-fuzz-init.c
Normal file
2067
src/afl-fuzz-init.c
Normal file
File diff suppressed because it is too large
Load Diff
186
src/afl-fuzz-misc.c
Normal file
186
src/afl-fuzz-misc.c
Normal file
@ -0,0 +1,186 @@
|
||||
/*
|
||||
american fuzzy lop++ - misc stuffs from Mordor
|
||||
----------------------------------------------
|
||||
|
||||
Originally written by Michal Zalewski <lcamtuf@google.com>
|
||||
|
||||
Now maintained by by Marc Heuse <mh@mh-sec.de>,
|
||||
Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and
|
||||
Andrea Fioraldi <andreafioraldi@gmail.com>
|
||||
|
||||
Copyright 2016, 2017 Google Inc. All rights reserved.
|
||||
Copyright 2019 AFLplusplus Project. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
This is the real deal: the program takes an instrumented binary and
|
||||
attempts a variety of basic fuzzing tricks, paying close attention to
|
||||
how they affect the execution path.
|
||||
|
||||
*/
|
||||
|
||||
#include "afl-fuzz.h"
|
||||
|
||||
/* Describe integer. Uses 12 cyclic static buffers for return values. The value
|
||||
returned should be five characters or less for all the integers we reasonably
|
||||
expect to see. */
|
||||
|
||||
u8* DI(u64 val) {
|
||||
|
||||
static u8 tmp[12][16];
|
||||
static u8 cur;
|
||||
|
||||
cur = (cur + 1) % 12;
|
||||
|
||||
#define CHK_FORMAT(_divisor, _limit_mult, _fmt, _cast) \
|
||||
do { \
|
||||
\
|
||||
if (val < (_divisor) * (_limit_mult)) { \
|
||||
\
|
||||
sprintf(tmp[cur], _fmt, ((_cast)val) / (_divisor)); \
|
||||
return tmp[cur]; \
|
||||
\
|
||||
} \
|
||||
\
|
||||
} while (0)
|
||||
|
||||
/* 0-9999 */
|
||||
CHK_FORMAT(1, 10000, "%llu", u64);
|
||||
|
||||
/* 10.0k - 99.9k */
|
||||
CHK_FORMAT(1000, 99.95, "%0.01fk", double);
|
||||
|
||||
/* 100k - 999k */
|
||||
CHK_FORMAT(1000, 1000, "%lluk", u64);
|
||||
|
||||
/* 1.00M - 9.99M */
|
||||
CHK_FORMAT(1000 * 1000, 9.995, "%0.02fM", double);
|
||||
|
||||
/* 10.0M - 99.9M */
|
||||
CHK_FORMAT(1000 * 1000, 99.95, "%0.01fM", double);
|
||||
|
||||
/* 100M - 999M */
|
||||
CHK_FORMAT(1000 * 1000, 1000, "%lluM", u64);
|
||||
|
||||
/* 1.00G - 9.99G */
|
||||
CHK_FORMAT(1000LL * 1000 * 1000, 9.995, "%0.02fG", double);
|
||||
|
||||
/* 10.0G - 99.9G */
|
||||
CHK_FORMAT(1000LL * 1000 * 1000, 99.95, "%0.01fG", double);
|
||||
|
||||
/* 100G - 999G */
|
||||
CHK_FORMAT(1000LL * 1000 * 1000, 1000, "%lluG", u64);
|
||||
|
||||
/* 1.00T - 9.99G */
|
||||
CHK_FORMAT(1000LL * 1000 * 1000 * 1000, 9.995, "%0.02fT", double);
|
||||
|
||||
/* 10.0T - 99.9T */
|
||||
CHK_FORMAT(1000LL * 1000 * 1000 * 1000, 99.95, "%0.01fT", double);
|
||||
|
||||
/* 100T+ */
|
||||
strcpy(tmp[cur], "infty");
|
||||
return tmp[cur];
|
||||
|
||||
}
|
||||
|
||||
/* Describe float. Similar to the above, except with a single
|
||||
static buffer. */
|
||||
|
||||
u8* DF(double val) {
|
||||
|
||||
static u8 tmp[16];
|
||||
|
||||
if (val < 99.995) {
|
||||
|
||||
sprintf(tmp, "%0.02f", val);
|
||||
return tmp;
|
||||
|
||||
}
|
||||
|
||||
if (val < 999.95) {
|
||||
|
||||
sprintf(tmp, "%0.01f", val);
|
||||
return tmp;
|
||||
|
||||
}
|
||||
|
||||
return DI((u64)val);
|
||||
|
||||
}
|
||||
|
||||
/* Describe integer as memory size. */
|
||||
|
||||
u8* DMS(u64 val) {
|
||||
|
||||
static u8 tmp[12][16];
|
||||
static u8 cur;
|
||||
|
||||
cur = (cur + 1) % 12;
|
||||
|
||||
/* 0-9999 */
|
||||
CHK_FORMAT(1, 10000, "%llu B", u64);
|
||||
|
||||
/* 10.0k - 99.9k */
|
||||
CHK_FORMAT(1024, 99.95, "%0.01f kB", double);
|
||||
|
||||
/* 100k - 999k */
|
||||
CHK_FORMAT(1024, 1000, "%llu kB", u64);
|
||||
|
||||
/* 1.00M - 9.99M */
|
||||
CHK_FORMAT(1024 * 1024, 9.995, "%0.02f MB", double);
|
||||
|
||||
/* 10.0M - 99.9M */
|
||||
CHK_FORMAT(1024 * 1024, 99.95, "%0.01f MB", double);
|
||||
|
||||
/* 100M - 999M */
|
||||
CHK_FORMAT(1024 * 1024, 1000, "%llu MB", u64);
|
||||
|
||||
/* 1.00G - 9.99G */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024, 9.995, "%0.02f GB", double);
|
||||
|
||||
/* 10.0G - 99.9G */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024, 99.95, "%0.01f GB", double);
|
||||
|
||||
/* 100G - 999G */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024, 1000, "%llu GB", u64);
|
||||
|
||||
/* 1.00T - 9.99G */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024 * 1024, 9.995, "%0.02f TB", double);
|
||||
|
||||
/* 10.0T - 99.9T */
|
||||
CHK_FORMAT(1024LL * 1024 * 1024 * 1024, 99.95, "%0.01f TB", double);
|
||||
|
||||
#undef CHK_FORMAT
|
||||
|
||||
/* 100T+ */
|
||||
strcpy(tmp[cur], "infty");
|
||||
return tmp[cur];
|
||||
|
||||
}
|
||||
|
||||
/* Describe time delta. Returns one static buffer, 34 chars of less. */
|
||||
|
||||
u8* DTD(u64 cur_ms, u64 event_ms) {
|
||||
|
||||
static u8 tmp[64];
|
||||
u64 delta;
|
||||
s32 t_d, t_h, t_m, t_s;
|
||||
|
||||
if (!event_ms) return "none seen yet";
|
||||
|
||||
delta = cur_ms - event_ms;
|
||||
|
||||
t_d = delta / 1000 / 60 / 60 / 24;
|
||||
t_h = (delta / 1000 / 60 / 60) % 24;
|
||||
t_m = (delta / 1000 / 60) % 60;
|
||||
t_s = (delta / 1000) % 60;
|
||||
|
||||
sprintf(tmp, "%s days, %d hrs, %d min, %d sec", DI(t_d), t_h, t_m, t_s);
|
||||
return tmp;
|
||||
|
||||
}
|
||||
|
||||
6027
src/afl-fuzz-one.c
Normal file
6027
src/afl-fuzz-one.c
Normal file
File diff suppressed because it is too large
Load Diff
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user