mirror of
https://github.com/AFLplusplus/AFLplusplus.git
synced 2025-06-24 22:53:24 +00:00
Compare commits
14 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| c89946fc19 | |||
| 3136ad5bca | |||
| 50311d5a6a | |||
| 748da4ee16 | |||
| 6d5e5484b6 | |||
| 37de3ba212 | |||
| 2a13c8b497 | |||
| 87be884221 | |||
| ff168fe3eb | |||
| dce29b1e7d | |||
| 518b13827b | |||
| b7a2999c03 | |||
| a86659f834 | |||
| 917c0bf1d7 |
@ -33,13 +33,13 @@ if CLANG_FORMAT_BIN is None:
|
||||
o, _ = p.communicate()
|
||||
o = str(o, "utf-8")
|
||||
o = re.sub(r".*ersion ", "", o)
|
||||
# o = o[len("clang-format version "):].strip()
|
||||
o = o[: o.find(".")]
|
||||
#o = o[len("clang-format version "):].strip()
|
||||
o = o[:o.find(".")]
|
||||
o = int(o)
|
||||
except:
|
||||
print("clang-format-11 is needed. Aborted.")
|
||||
print ("clang-format-11 is needed. Aborted.")
|
||||
exit(1)
|
||||
# if o < 7:
|
||||
#if o < 7:
|
||||
# if subprocess.call(['which', 'clang-format-7'], stdout=subprocess.PIPE) == 0:
|
||||
# CLANG_FORMAT_BIN = 'clang-format-7'
|
||||
# elif subprocess.call(['which', 'clang-format-8'], stdout=subprocess.PIPE) == 0:
|
||||
@ -52,8 +52,8 @@ if CLANG_FORMAT_BIN is None:
|
||||
# print ("clang-format 7 or above is needed. Aborted.")
|
||||
# exit(1)
|
||||
else:
|
||||
CLANG_FORMAT_BIN = "clang-format-11"
|
||||
|
||||
CLANG_FORMAT_BIN = 'clang-format-11'
|
||||
|
||||
COLUMN_LIMIT = 80
|
||||
for line in fmt.split("\n"):
|
||||
line = line.split(":")
|
||||
@ -69,47 +69,26 @@ def custom_format(filename):
|
||||
in_define = False
|
||||
last_line = None
|
||||
out = ""
|
||||
|
||||
|
||||
for line in src.split("\n"):
|
||||
if line.lstrip().startswith("#"):
|
||||
if line[line.find("#") + 1 :].lstrip().startswith("define"):
|
||||
if line[line.find("#")+1:].lstrip().startswith("define"):
|
||||
in_define = True
|
||||
|
||||
if (
|
||||
"/*" in line
|
||||
and not line.strip().startswith("/*")
|
||||
and line.endswith("*/")
|
||||
and len(line) < (COLUMN_LIMIT - 2)
|
||||
):
|
||||
|
||||
if "/*" in line and not line.strip().startswith("/*") and line.endswith("*/") and len(line) < (COLUMN_LIMIT-2):
|
||||
cmt_start = line.rfind("/*")
|
||||
line = (
|
||||
line[:cmt_start]
|
||||
+ " " * (COLUMN_LIMIT - 2 - len(line))
|
||||
+ line[cmt_start:]
|
||||
)
|
||||
line = line[:cmt_start] + " " * (COLUMN_LIMIT-2 - len(line)) + line[cmt_start:]
|
||||
|
||||
define_padding = 0
|
||||
if last_line is not None and in_define and last_line.endswith("\\"):
|
||||
last_line = last_line[:-1]
|
||||
define_padding = max(0, len(last_line[last_line.rfind("\n") + 1 :]))
|
||||
define_padding = max(0, len(last_line[last_line.rfind("\n")+1:]))
|
||||
|
||||
if (
|
||||
last_line is not None
|
||||
and last_line.strip().endswith("{")
|
||||
and line.strip() != ""
|
||||
):
|
||||
if last_line is not None and last_line.strip().endswith("{") and line.strip() != "":
|
||||
line = (" " * define_padding + "\\" if in_define else "") + "\n" + line
|
||||
elif (
|
||||
last_line is not None
|
||||
and last_line.strip().startswith("}")
|
||||
and line.strip() != ""
|
||||
):
|
||||
elif last_line is not None and last_line.strip().startswith("}") and line.strip() != "":
|
||||
line = (" " * define_padding + "\\" if in_define else "") + "\n" + line
|
||||
elif (
|
||||
line.strip().startswith("}")
|
||||
and last_line is not None
|
||||
and last_line.strip() != ""
|
||||
):
|
||||
elif line.strip().startswith("}") and last_line is not None and last_line.strip() != "":
|
||||
line = (" " * define_padding + "\\" if in_define else "") + "\n" + line
|
||||
|
||||
if not line.endswith("\\"):
|
||||
@ -118,15 +97,14 @@ def custom_format(filename):
|
||||
out += line + "\n"
|
||||
last_line = line
|
||||
|
||||
return out
|
||||
|
||||
return (out)
|
||||
|
||||
args = sys.argv[1:]
|
||||
if len(args) == 0:
|
||||
print("Usage: ./format.py [-i] <filename>")
|
||||
print()
|
||||
print(" The -i option, if specified, let the script to modify in-place")
|
||||
print(" the source files. By default the results are written to stdout.")
|
||||
print ("Usage: ./format.py [-i] <filename>")
|
||||
print ()
|
||||
print (" The -i option, if specified, let the script to modify in-place")
|
||||
print (" the source files. By default the results are written to stdout.")
|
||||
print()
|
||||
exit(1)
|
||||
|
||||
@ -142,3 +120,4 @@ for filename in args:
|
||||
f.write(code)
|
||||
else:
|
||||
print(code)
|
||||
|
||||
|
||||
13
.github/FUNDING.yml
vendored
13
.github/FUNDING.yml
vendored
@ -1,13 +0,0 @@
|
||||
# These are supported funding model platforms
|
||||
|
||||
# Replace with up to 4 GitHub Sponsors-enabled usernames e.g., [user1, user2]
|
||||
github: AFLplusplus
|
||||
patreon: # Replace with a single Patreon username
|
||||
open_collective: AFLplusplusEU
|
||||
ko_fi: # Replace with a single Ko-fi username
|
||||
tidelift: # Replace with a single Tidelift platform-name/package-name e.g., npm/babel
|
||||
community_bridge: # Replace with a single Community Bridge project-name e.g., cloud-foundry
|
||||
liberapay: # Replace with a single Liberapay username
|
||||
issuehunt: # Replace with a single IssueHunt username
|
||||
otechie: # Replace with a single Otechie username
|
||||
custom: # Replace with up to 4 custom sponsorship URLs e.g., ['link1', 'link2']
|
||||
25
.github/workflows/build_aflplusplus_docker.yaml
vendored
25
.github/workflows/build_aflplusplus_docker.yaml
vendored
@ -1,25 +0,0 @@
|
||||
name: Publish Docker Images
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ stable ]
|
||||
# paths:
|
||||
# - Dockerfile
|
||||
|
||||
jobs:
|
||||
push_to_registry:
|
||||
name: Push Docker images to Dockerhub
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@master
|
||||
- name: Login to Dockerhub
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
username: ${{ secrets.DOCKER_USERNAME }}
|
||||
password: ${{ secrets.DOCKER_TOKEN }}
|
||||
- name: Publish aflpp to Registry
|
||||
uses: docker/build-push-action@v2
|
||||
with:
|
||||
context: .
|
||||
push: true
|
||||
tags: aflplusplus/aflplusplus:latest
|
||||
4
.github/workflows/ci.yml
vendored
4
.github/workflows/ci.yml
vendored
@ -16,10 +16,8 @@ jobs:
|
||||
- uses: actions/checkout@v2
|
||||
- name: debug
|
||||
run: apt-cache search plugin-dev | grep gcc- ; echo ; apt-cache search clang-format- | grep clang-format-
|
||||
- name: update
|
||||
run: sudo apt-get update && sudo apt-get upgrade -y
|
||||
- name: install packages
|
||||
run: sudo apt-get install -y -m -f --install-suggests build-essential git libtool libtool-bin automake bison libglib2.0-0 clang llvm-dev libc++-dev findutils libcmocka-dev python3-dev python3-setuptools ninja-build
|
||||
run: sudo apt-get install -y -m -f --install-suggests build-essential git libtool libtool-bin automake bison libglib2.0-0 clang llvm-dev libc++-dev findutils libcmocka-dev python3-dev python3-setuptools
|
||||
- name: compiler installed
|
||||
run: gcc -v ; echo ; clang -v
|
||||
- name: install gcc plugin
|
||||
|
||||
30
.github/workflows/rust_custom_mutator.yml
vendored
30
.github/workflows/rust_custom_mutator.yml
vendored
@ -1,30 +0,0 @@
|
||||
name: Rust Custom Mutators
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ stable, dev ]
|
||||
pull_request:
|
||||
branches: [ stable, dev ]
|
||||
|
||||
jobs:
|
||||
test:
|
||||
name: Test Rust Custom Mutator Support
|
||||
runs-on: '${{ matrix.os }}'
|
||||
defaults:
|
||||
run:
|
||||
working-directory: custom_mutators/rust
|
||||
strategy:
|
||||
matrix:
|
||||
os: [ubuntu-20.04]
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Install Rust Toolchain
|
||||
uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
toolchain: stable
|
||||
- name: Check Code Compiles
|
||||
run: cargo check
|
||||
- name: Run General Tests
|
||||
run: cargo test
|
||||
- name: Run Tests for afl_internals feature flag
|
||||
run: cd custom_mutator && cargo test --features=afl_internals
|
||||
5
.gitignore
vendored
5
.gitignore
vendored
@ -65,6 +65,7 @@ qemu_mode/qemu-*
|
||||
qemu_mode/qemuafl
|
||||
unicorn_mode/samples/*/\.test-*
|
||||
unicorn_mode/samples/*/output/
|
||||
unicorn_mode/unicornafl
|
||||
test/unittests/unit_maybe_alloc
|
||||
test/unittests/unit_preallocable
|
||||
test/unittests/unit_list
|
||||
@ -82,7 +83,3 @@ libAFLDriver.a
|
||||
libAFLQemuDriver.a
|
||||
test/.afl_performance
|
||||
gmon.out
|
||||
afl-frida-trace.so
|
||||
utils/afl_network_proxy/afl-network-client
|
||||
utils/afl_network_proxy/afl-network-server
|
||||
*.o.tmp
|
||||
|
||||
143
Android.bp
143
Android.bp
@ -1,5 +1,8 @@
|
||||
cc_defaults {
|
||||
name: "afl-defaults",
|
||||
sanitize: {
|
||||
never: true,
|
||||
},
|
||||
|
||||
local_include_dirs: [
|
||||
"include",
|
||||
@ -20,44 +23,18 @@ cc_defaults {
|
||||
"-DBIN_PATH=\"out/host/linux-x86/bin\"",
|
||||
"-DDOC_PATH=\"out/host/linux-x86/shared/doc/afl\"",
|
||||
"-D__USE_GNU",
|
||||
"-D__aarch64__",
|
||||
"-DDEBUG_BUILD",
|
||||
"-U_FORTIFY_SOURCE",
|
||||
"-ggdb3",
|
||||
"-g",
|
||||
"-O0",
|
||||
"-fno-omit-frame-pointer",
|
||||
"-fPIC",
|
||||
],
|
||||
|
||||
target: {
|
||||
android_arm64: {
|
||||
cflags: [
|
||||
"-D__ANDROID__",
|
||||
],
|
||||
},
|
||||
android_arm: {
|
||||
cflags: [
|
||||
"-D__ANDROID__",
|
||||
],
|
||||
},
|
||||
android_x86_64: {
|
||||
cflags: [
|
||||
"-D__ANDROID__",
|
||||
],
|
||||
},
|
||||
android_x86: {
|
||||
cflags: [
|
||||
"-D__ANDROID__",
|
||||
],
|
||||
},
|
||||
},
|
||||
}
|
||||
|
||||
cc_binary {
|
||||
name: "afl-fuzz",
|
||||
sanitize: {
|
||||
never: true,
|
||||
},
|
||||
host_supported: true,
|
||||
compile_multilib: "64",
|
||||
|
||||
@ -151,6 +128,7 @@ cc_binary_host {
|
||||
],
|
||||
|
||||
cflags: [
|
||||
"-D__ANDROID__",
|
||||
"-DAFL_PATH=\"out/host/linux-x86/lib64\"",
|
||||
"-DAFL_CLANG_FLTO=\"-flto=full\"",
|
||||
"-DUSE_BINDIR=1",
|
||||
@ -221,7 +199,6 @@ cc_library_headers {
|
||||
|
||||
export_include_dirs: [
|
||||
"include",
|
||||
"instrumentation",
|
||||
],
|
||||
}
|
||||
|
||||
@ -291,116 +268,6 @@ cc_binary {
|
||||
],
|
||||
}
|
||||
|
||||
cc_binary {
|
||||
name: "afl-fuzz-32",
|
||||
sanitize: {
|
||||
never: true,
|
||||
},
|
||||
host_supported: true,
|
||||
compile_multilib: "32",
|
||||
|
||||
defaults: [
|
||||
"afl-defaults",
|
||||
],
|
||||
|
||||
srcs: [
|
||||
"src/afl-fuzz*.c",
|
||||
"src/afl-common.c",
|
||||
"src/afl-sharedmem.c",
|
||||
"src/afl-forkserver.c",
|
||||
"src/afl-performance.c",
|
||||
],
|
||||
}
|
||||
|
||||
cc_binary_host {
|
||||
name: "afl-cc-32",
|
||||
compile_multilib: "32",
|
||||
static_executable: true,
|
||||
|
||||
defaults: [
|
||||
"afl-defaults",
|
||||
],
|
||||
|
||||
cflags: [
|
||||
"-DAFL_PATH=\"out/host/linux-x86/lib64\"",
|
||||
"-DAFL_CLANG_FLTO=\"-flto=full\"",
|
||||
"-DUSE_BINDIR=1",
|
||||
"-DLLVM_BINDIR=\"prebuilts/clang/host/linux-x86/clang-r383902b/bin\"",
|
||||
"-DLLVM_LIBDIR=\"prebuilts/clang/host/linux-x86/clang-r383902b/lib64\"",
|
||||
"-DCLANGPP_BIN=\"prebuilts/clang/host/linux-x86/clang-r383902b/bin/clang++\"",
|
||||
"-DAFL_REAL_LD=\"prebuilts/clang/host/linux-x86/clang-r383902b/bin/ld.lld\"",
|
||||
"-DLLVM_LTO=1",
|
||||
"-DLLVM_MAJOR=11",
|
||||
"-DLLVM_MINOR=2",
|
||||
],
|
||||
|
||||
srcs: [
|
||||
"src/afl-cc.c",
|
||||
"src/afl-common.c",
|
||||
],
|
||||
|
||||
symlinks: [
|
||||
"afl-clang-fast-32",
|
||||
"afl-clang-fast++-32",
|
||||
],
|
||||
}
|
||||
|
||||
cc_library_static {
|
||||
name: "afl-llvm-rt-32",
|
||||
compile_multilib: "32",
|
||||
vendor_available: true,
|
||||
host_supported: true,
|
||||
recovery_available: true,
|
||||
sdk_version: "9",
|
||||
|
||||
apex_available: [
|
||||
"com.android.adbd",
|
||||
"com.android.appsearch",
|
||||
"com.android.art",
|
||||
"com.android.bluetooth.updatable",
|
||||
"com.android.cellbroadcast",
|
||||
"com.android.conscrypt",
|
||||
"com.android.extservices",
|
||||
"com.android.cronet",
|
||||
"com.android.neuralnetworks",
|
||||
"com.android.media",
|
||||
"com.android.media.swcodec",
|
||||
"com.android.mediaprovider",
|
||||
"com.android.permission",
|
||||
"com.android.runtime",
|
||||
"com.android.resolv",
|
||||
"com.android.tethering",
|
||||
"com.android.wifi",
|
||||
"com.android.sdkext",
|
||||
"com.android.os.statsd",
|
||||
"//any",
|
||||
],
|
||||
|
||||
defaults: [
|
||||
"afl-defaults",
|
||||
],
|
||||
|
||||
srcs: [
|
||||
"instrumentation/afl-compiler-rt.o.c",
|
||||
],
|
||||
}
|
||||
|
||||
cc_prebuilt_library_static {
|
||||
name: "libfrida-gum-32",
|
||||
compile_multilib: "32",
|
||||
strip: {
|
||||
none: true,
|
||||
},
|
||||
|
||||
srcs: [
|
||||
"utils/afl_frida/android/arm/libfrida-gum.a",
|
||||
],
|
||||
|
||||
export_include_dirs: [
|
||||
"utils/afl_frida/android/arm",
|
||||
],
|
||||
}
|
||||
|
||||
subdirs = [
|
||||
"custom_mutators",
|
||||
]
|
||||
|
||||
19
Dockerfile
19
Dockerfile
@ -11,8 +11,6 @@ LABEL "about"="AFLplusplus docker image"
|
||||
|
||||
ARG DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
env NO_ARCH_OPT 1
|
||||
|
||||
RUN apt-get update && \
|
||||
apt-get -y install --no-install-suggests --no-install-recommends \
|
||||
automake \
|
||||
@ -37,7 +35,7 @@ RUN echo "deb http://ppa.launchpad.net/ubuntu-toolchain-r/test/ubuntu focal main
|
||||
|
||||
RUN apt-get update && apt-get full-upgrade -y && \
|
||||
apt-get -y install --no-install-suggests --no-install-recommends \
|
||||
gcc-10 g++-10 gcc-10-plugin-dev gcc-10-multilib gcc-multilib gdb lcov \
|
||||
gcc-10 g++-10 gcc-10-plugin-dev gcc-10-multilib gdb lcov \
|
||||
clang-12 clang-tools-12 libc++1-12 libc++-12-dev \
|
||||
libc++abi1-12 libc++abi-12-dev libclang1-12 libclang-12-dev \
|
||||
libclang-common-12-dev libclang-cpp12 libclang-cpp12-dev liblld-12 \
|
||||
@ -50,22 +48,19 @@ RUN update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-10 0
|
||||
|
||||
ENV LLVM_CONFIG=llvm-config-12
|
||||
ENV AFL_SKIP_CPUFREQ=1
|
||||
ENV AFL_TRY_AFFINITY=1
|
||||
ENV AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=1
|
||||
|
||||
RUN git clone --depth=1 https://github.com/vanhauser-thc/afl-cov /afl-cov
|
||||
RUN git clone https://github.com/vanhauser-thc/afl-cov /afl-cov
|
||||
RUN cd /afl-cov && make install && cd ..
|
||||
|
||||
COPY . /AFLplusplus
|
||||
WORKDIR /AFLplusplus
|
||||
|
||||
RUN export CC=gcc-10 && export CXX=g++-10 && make clean && \
|
||||
make distrib && make install && make clean
|
||||
RUN export REAL_CXX=g++-10 && export CC=gcc-10 && \
|
||||
export CXX=g++-10 && make clean && \
|
||||
make distrib CFLAGS="-O3 -funroll-loops -D_FORTIFY_SOURCE=2" && make install && make clean
|
||||
|
||||
RUN sh -c 'echo set encoding=utf-8 > /root/.vimrc'
|
||||
RUN echo '. /etc/bash_completion' >> ~/.bashrc
|
||||
RUN echo 'alias joe="joe --wordwrap --joe_state -nobackup"' >> ~/.bashrc
|
||||
RUN echo "export PS1='"'[afl++ \h] \w$(__git_ps1) \$ '"'" >> ~/.bashrc
|
||||
RUN echo 'alias joe="jupp --wordwrap"' >> ~/.bashrc
|
||||
RUN echo 'export PS1="[afl++]$PS1"' >> ~/.bashrc
|
||||
ENV IS_DOCKER="1"
|
||||
|
||||
# Disabled until we have the container ready
|
||||
|
||||
93
GNUmakefile
93
GNUmakefile
@ -24,7 +24,7 @@ BIN_PATH = $(PREFIX)/bin
|
||||
HELPER_PATH = $(PREFIX)/lib/afl
|
||||
DOC_PATH = $(PREFIX)/share/doc/afl
|
||||
MISC_PATH = $(PREFIX)/share/afl
|
||||
MAN_PATH = $(PREFIX)/share/man/man8
|
||||
MAN_PATH = $(PREFIX)/man/man8
|
||||
|
||||
PROGNAME = afl
|
||||
VERSION = $(shell grep '^$(HASH)define VERSION ' ../config.h | cut -d '"' -f2)
|
||||
@ -36,11 +36,6 @@ SH_PROGS = afl-plot afl-cmin afl-cmin.bash afl-whatsup afl-system-config
|
||||
MANPAGES=$(foreach p, $(PROGS) $(SH_PROGS), $(p).8) afl-as.8
|
||||
ASAN_OPTIONS=detect_leaks=0
|
||||
|
||||
SYS = $(shell uname -s)
|
||||
ARCH = $(shell uname -m)
|
||||
|
||||
$(info [*] Compiling afl++ for OS $(SYS) on ARCH $(ARCH))
|
||||
|
||||
ifdef NO_SPLICING
|
||||
override CFLAGS += -DNO_SPLICING
|
||||
endif
|
||||
@ -62,6 +57,8 @@ ifdef MSAN_BUILD
|
||||
override LDFLAGS += -fsanitize=memory
|
||||
endif
|
||||
|
||||
|
||||
|
||||
ifeq "$(findstring android, $(shell $(CC) --version 2>/dev/null))" ""
|
||||
ifeq "$(shell echo 'int main() {return 0; }' | $(CC) $(CFLAGS) -Werror -x c - -flto=full -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1"
|
||||
CFLAGS_FLTO ?= -flto=full
|
||||
@ -80,24 +77,24 @@ ifeq "$(shell echo 'int main() {return 0; }' | $(CC) -fno-move-loop-invariants -
|
||||
SPECIAL_PERFORMANCE += -fno-move-loop-invariants -fdisable-tree-cunrolli
|
||||
endif
|
||||
|
||||
#ifeq "$(shell echo 'int main() {return 0; }' | $(CC) $(CFLAGS) -Werror -x c - -march=native -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1"
|
||||
# ifndef SOURCE_DATE_EPOCH
|
||||
# HAVE_MARCHNATIVE = 1
|
||||
# CFLAGS_OPT += -march=native
|
||||
# endif
|
||||
#endif
|
||||
ifeq "$(shell echo 'int main() {return 0; }' | $(CC) $(CFLAGS) -Werror -x c - -march=native -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1"
|
||||
ifndef SOURCE_DATE_EPOCH
|
||||
HAVE_MARCHNATIVE = 1
|
||||
CFLAGS_OPT += -march=native
|
||||
endif
|
||||
endif
|
||||
|
||||
ifneq "$(SYS)" "Darwin"
|
||||
#ifeq "$(HAVE_MARCHNATIVE)" "1"
|
||||
# SPECIAL_PERFORMANCE += -march=native
|
||||
#endif
|
||||
ifneq "$(shell uname)" "Darwin"
|
||||
ifeq "$(HAVE_MARCHNATIVE)" "1"
|
||||
SPECIAL_PERFORMANCE += -march=native
|
||||
endif
|
||||
# OS X does not like _FORTIFY_SOURCE=2
|
||||
ifndef DEBUG
|
||||
CFLAGS_OPT += -D_FORTIFY_SOURCE=2
|
||||
endif
|
||||
endif
|
||||
|
||||
ifeq "$(SYS)" "SunOS"
|
||||
ifeq "$(shell uname)" "SunOS"
|
||||
CFLAGS_OPT += -Wno-format-truncation
|
||||
LDFLAGS = -lkstat -lrt
|
||||
endif
|
||||
@ -124,10 +121,11 @@ ifdef INTROSPECTION
|
||||
CFLAGS_OPT += -DINTROSPECTION=1
|
||||
endif
|
||||
|
||||
ifneq "$(ARCH)" "x86_64"
|
||||
ifneq "$(patsubst i%86,i386,$(ARCH))" "i386"
|
||||
ifneq "$(ARCH)" "amd64"
|
||||
ifneq "$(ARCH)" "i86pc"
|
||||
|
||||
ifneq "$(shell uname -m)" "x86_64"
|
||||
ifneq "$(patsubst i%86,i386,$(shell uname -m))" "i386"
|
||||
ifneq "$(shell uname -m)" "amd64"
|
||||
ifneq "$(shell uname -m)" "i86pc"
|
||||
AFL_NO_X86=1
|
||||
endif
|
||||
endif
|
||||
@ -145,30 +143,30 @@ override CFLAGS += -g -Wno-pointer-sign -Wno-variadic-macros -Wall -Wextra -Wpoi
|
||||
-I include/ -DAFL_PATH=\"$(HELPER_PATH)\" \
|
||||
-DBIN_PATH=\"$(BIN_PATH)\" -DDOC_PATH=\"$(DOC_PATH)\"
|
||||
|
||||
ifeq "$(SYS)" "FreeBSD"
|
||||
ifeq "$(shell uname -s)" "FreeBSD"
|
||||
override CFLAGS += -I /usr/local/include/
|
||||
LDFLAGS += -L /usr/local/lib/
|
||||
endif
|
||||
|
||||
ifeq "$(SYS)" "DragonFly"
|
||||
ifeq "$(shell uname -s)" "DragonFly"
|
||||
override CFLAGS += -I /usr/local/include/
|
||||
LDFLAGS += -L /usr/local/lib/
|
||||
endif
|
||||
|
||||
ifeq "$(SYS)" "OpenBSD"
|
||||
ifeq "$(shell uname -s)" "OpenBSD"
|
||||
override CFLAGS += -I /usr/local/include/ -mno-retpoline
|
||||
LDFLAGS += -Wl,-z,notext -L /usr/local/lib/
|
||||
endif
|
||||
|
||||
ifeq "$(SYS)" "NetBSD"
|
||||
ifeq "$(shell uname -s)" "NetBSD"
|
||||
override CFLAGS += -I /usr/pkg/include/
|
||||
LDFLAGS += -L /usr/pkg/lib/
|
||||
endif
|
||||
|
||||
ifeq "$(SYS)" "Haiku"
|
||||
ifeq "$(shell uname -s)" "Haiku"
|
||||
SHMAT_OK=0
|
||||
override CFLAGS += -DUSEMMAP=1 -Wno-error=format -fPIC
|
||||
LDFLAGS += -Wno-deprecated-declarations -lgnu -lnetwork
|
||||
LDFLAGS += -Wno-deprecated-declarations -lgnu
|
||||
SPECIAL_PERFORMANCE += -DUSEMMAP=1
|
||||
endif
|
||||
|
||||
@ -240,24 +238,24 @@ else
|
||||
BUILD_DATE ?= $(shell date "+%Y-%m-%d")
|
||||
endif
|
||||
|
||||
ifneq "$(filter Linux GNU%,$(SYS))" ""
|
||||
ifneq "$(filter Linux GNU%,$(shell uname))" ""
|
||||
ifndef DEBUG
|
||||
override CFLAGS += -D_FORTIFY_SOURCE=2
|
||||
endif
|
||||
LDFLAGS += -ldl -lrt -lm
|
||||
endif
|
||||
|
||||
ifneq "$(findstring FreeBSD, $(SYS))" ""
|
||||
ifneq "$(findstring FreeBSD, $(shell uname))" ""
|
||||
override CFLAGS += -pthread
|
||||
LDFLAGS += -lpthread
|
||||
endif
|
||||
|
||||
ifneq "$(findstring NetBSD, $(SYS))" ""
|
||||
ifneq "$(findstring NetBSD, $(shell uname))" ""
|
||||
override CFLAGS += -pthread
|
||||
LDFLAGS += -lpthread
|
||||
endif
|
||||
|
||||
ifneq "$(findstring OpenBSD, $(SYS))" ""
|
||||
ifneq "$(findstring OpenBSD, $(shell uname))" ""
|
||||
override CFLAGS += -pthread
|
||||
LDFLAGS += -lpthread
|
||||
endif
|
||||
@ -306,7 +304,6 @@ endif
|
||||
|
||||
.PHONY: all
|
||||
all: test_x86 test_shm test_python ready $(PROGS) afl-as llvm gcc_plugin test_build all_done
|
||||
-$(MAKE) -C utils/aflpp_driver
|
||||
|
||||
.PHONY: llvm
|
||||
llvm:
|
||||
@ -437,8 +434,8 @@ afl-showmap: src/afl-showmap.c src/afl-common.o src/afl-sharedmem.o src/afl-fork
|
||||
afl-tmin: src/afl-tmin.c src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o src/afl-performance.o $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) src/$@.c src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o src/afl-performance.o -o $@ $(LDFLAGS)
|
||||
|
||||
afl-analyze: src/afl-analyze.c src/afl-common.o src/afl-sharedmem.o src/afl-performance.o src/afl-forkserver.o $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) src/$@.c src/afl-common.o src/afl-sharedmem.o src/afl-performance.o src/afl-forkserver.o -o $@ $(LDFLAGS)
|
||||
afl-analyze: src/afl-analyze.c src/afl-common.o src/afl-sharedmem.o src/afl-performance.o $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) src/$@.c src/afl-common.o src/afl-sharedmem.o src/afl-performance.o -o $@ $(LDFLAGS)
|
||||
|
||||
afl-gotcpu: src/afl-gotcpu.c src/afl-common.o $(COMM_HDR) | test_x86
|
||||
$(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) src/$@.c src/afl-common.o -o $@ $(LDFLAGS)
|
||||
@ -490,7 +487,7 @@ unit_clean:
|
||||
@rm -f ./test/unittests/unit_preallocable ./test/unittests/unit_list ./test/unittests/unit_maybe_alloc test/unittests/*.o
|
||||
|
||||
.PHONY: unit
|
||||
ifneq "$(SYS)" "Darwin"
|
||||
ifneq "$(shell uname)" "Darwin"
|
||||
unit: unit_maybe_alloc unit_preallocable unit_list unit_clean unit_rand unit_hash
|
||||
else
|
||||
unit:
|
||||
@ -504,28 +501,25 @@ code-format:
|
||||
./.custom-format.py -i instrumentation/*.h
|
||||
./.custom-format.py -i instrumentation/*.cc
|
||||
./.custom-format.py -i instrumentation/*.c
|
||||
./.custom-format.py -i *.h
|
||||
./.custom-format.py -i *.c
|
||||
@#./.custom-format.py -i custom_mutators/*/*.c* # destroys libfuzzer :-(
|
||||
@#./.custom-format.py -i custom_mutators/*/*.h # destroys honggfuzz :-(
|
||||
./.custom-format.py -i utils/*/*.c*
|
||||
./.custom-format.py -i utils/*/*.h
|
||||
./.custom-format.py -i test/*.c
|
||||
./.custom-format.py -i frida_mode/src/*.c
|
||||
./.custom-format.py -i frida_mode/include/*.h
|
||||
-./.custom-format.py -i frida_mode/src/*/*.c
|
||||
./.custom-format.py -i qemu_mode/libcompcov/*.c
|
||||
./.custom-format.py -i qemu_mode/libcompcov/*.cc
|
||||
./.custom-format.py -i qemu_mode/libcompcov/*.h
|
||||
./.custom-format.py -i qemu_mode/libqasan/*.c
|
||||
./.custom-format.py -i qemu_mode/libqasan/*.h
|
||||
./.custom-format.py -i *.h
|
||||
./.custom-format.py -i *.c
|
||||
|
||||
|
||||
.PHONY: test_build
|
||||
ifndef AFL_NO_X86
|
||||
test_build: afl-cc afl-gcc afl-as afl-showmap
|
||||
@echo "[*] Testing the CC wrapper afl-cc and its instrumentation output..."
|
||||
@unset AFL_MAP_SIZE AFL_USE_UBSAN AFL_USE_CFISAN AFL_USE_LSAN AFL_USE_ASAN AFL_USE_MSAN; ASAN_OPTIONS=detect_leaks=0 AFL_INST_RATIO=100 AFL_PATH=. ./afl-cc test-instr.c -o test-instr 2>&1 || (echo "Oops, afl-cc failed"; exit 1 )
|
||||
@unset AFL_MAP_SIZE AFL_USE_UBSAN AFL_USE_CFISAN AFL_USE_ASAN AFL_USE_MSAN; ASAN_OPTIONS=detect_leaks=0 AFL_INST_RATIO=100 AFL_PATH=. ./afl-cc test-instr.c -o test-instr 2>&1 || (echo "Oops, afl-cc failed"; exit 1 )
|
||||
ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr0 ./test-instr < /dev/null
|
||||
echo 1 | ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr1 ./test-instr
|
||||
@rm -f test-instr
|
||||
@ -533,7 +527,7 @@ test_build: afl-cc afl-gcc afl-as afl-showmap
|
||||
@echo
|
||||
@echo "[+] All right, the instrumentation of afl-cc seems to be working!"
|
||||
# @echo "[*] Testing the CC wrapper afl-gcc and its instrumentation output..."
|
||||
# @unset AFL_MAP_SIZE AFL_USE_UBSAN AFL_USE_CFISAN AFL_USE_LSAN AFL_USE_ASAN AFL_USE_MSAN; AFL_CC=$(CC) ASAN_OPTIONS=detect_leaks=0 AFL_INST_RATIO=100 AFL_PATH=. ./afl-gcc test-instr.c -o test-instr 2>&1 || (echo "Oops, afl-gcc failed"; exit 1 )
|
||||
# @unset AFL_MAP_SIZE AFL_USE_UBSAN AFL_USE_CFISAN AFL_USE_ASAN AFL_USE_MSAN; AFL_CC=$(CC) ASAN_OPTIONS=detect_leaks=0 AFL_INST_RATIO=100 AFL_PATH=. ./afl-gcc test-instr.c -o test-instr 2>&1 || (echo "Oops, afl-gcc failed"; exit 1 )
|
||||
# ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr0 ./test-instr < /dev/null
|
||||
# echo 1 | ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr1 ./test-instr
|
||||
# @rm -f test-instr
|
||||
@ -554,7 +548,7 @@ all_done: test_build
|
||||
@test -e SanitizerCoverageLTO.so && echo "[+] LLVM LTO mode for 'afl-cc' successfully built!" || echo "[-] LLVM LTO mode for 'afl-cc' failed to build, this would need LLVM 11+, see instrumentation/README.lto.md how to build it"
|
||||
@test -e afl-gcc-pass.so && echo "[+] gcc_plugin for 'afl-cc' successfully built!" || echo "[-] gcc_plugin for 'afl-cc' failed to build, unless you really need it that is fine - or read instrumentation/README.gcc_plugin.md how to build it"
|
||||
@echo "[+] All done! Be sure to review the README.md - it's pretty short and useful."
|
||||
@if [ "$(SYS)" = "Darwin" ]; then printf "\nWARNING: Fuzzing on MacOS X is slow because of the unusually high overhead of\nfork() on this OS. Consider using Linux or *BSD for fuzzing software not\nspecifically for MacOS.\n\n"; fi
|
||||
@if [ "`uname`" = "Darwin" ]; then printf "\nWARNING: Fuzzing on MacOS X is slow because of the unusually high overhead of\nfork() on this OS. Consider using Linux or *BSD. You can also use VirtualBox\n(virtualbox.org) to put AFL inside a Linux or *BSD VM.\n\n"; fi
|
||||
@! tty <&1 >/dev/null || printf "\033[0;30mNOTE: If you can read this, your terminal probably uses white background.\nThis will make the UI hard to read. See docs/status_screen.md for advice.\033[0m\n" 2>/dev/null
|
||||
|
||||
.NOTPARALLEL: clean all
|
||||
@ -566,16 +560,14 @@ clean:
|
||||
-$(MAKE) -f GNUmakefile.gcc_plugin clean
|
||||
$(MAKE) -C utils/libdislocator clean
|
||||
$(MAKE) -C utils/libtokencap clean
|
||||
$(MAKE) -C utils/aflpp_driver clean
|
||||
$(MAKE) -C utils/afl_network_proxy clean
|
||||
$(MAKE) -C utils/socket_fuzzing clean
|
||||
$(MAKE) -C utils/argv_fuzzing clean
|
||||
$(MAKE) -C qemu_mode/unsigaction clean
|
||||
$(MAKE) -C qemu_mode/libcompcov clean
|
||||
$(MAKE) -C qemu_mode/libqasan clean
|
||||
-$(MAKE) -C frida_mode clean
|
||||
ifeq "$(IN_REPO)" "1"
|
||||
-test -e qemu_mode/qemuafl/Makefile && $(MAKE) -C qemu_mode/qemuafl clean || true
|
||||
test -e qemu_mode/qemuafl/Makefile && $(MAKE) -C qemu_mode/qemuafl clean || true
|
||||
test -e unicorn_mode/unicornafl/Makefile && $(MAKE) -C unicorn_mode/unicornafl clean || true
|
||||
else
|
||||
rm -rf qemu_mode/qemuafl
|
||||
@ -586,11 +578,7 @@ endif
|
||||
deepclean: clean
|
||||
rm -rf unicorn_mode/unicornafl
|
||||
rm -rf qemu_mode/qemuafl
|
||||
ifeq "$(IN_REPO)" "1"
|
||||
# NEVER EVER ACTIVATE THAT!!!!! git reset --hard >/dev/null 2>&1 || true
|
||||
git checkout unicorn_mode/unicornafl
|
||||
git checkout qemu_mode/qemuafl
|
||||
endif
|
||||
|
||||
.PHONY: distrib
|
||||
distrib: all
|
||||
@ -598,10 +586,10 @@ distrib: all
|
||||
-$(MAKE) -f GNUmakefile.gcc_plugin
|
||||
$(MAKE) -C utils/libdislocator
|
||||
$(MAKE) -C utils/libtokencap
|
||||
-$(MAKE) -C utils/aflpp_driver
|
||||
$(MAKE) -C utils/afl_network_proxy
|
||||
$(MAKE) -C utils/socket_fuzzing
|
||||
$(MAKE) -C utils/argv_fuzzing
|
||||
-$(MAKE) -C frida_mode
|
||||
-cd qemu_mode && sh ./build_qemu_support.sh
|
||||
-cd unicorn_mode && unset CFLAGS && sh ./build_unicorn_support.sh
|
||||
|
||||
@ -612,7 +600,6 @@ binary-only: test_shm test_python ready $(PROGS)
|
||||
$(MAKE) -C utils/afl_network_proxy
|
||||
$(MAKE) -C utils/socket_fuzzing
|
||||
$(MAKE) -C utils/argv_fuzzing
|
||||
-$(MAKE) -C frida_mode
|
||||
-cd qemu_mode && sh ./build_qemu_support.sh
|
||||
-cd unicorn_mode && unset CFLAGS && sh ./build_unicorn_support.sh
|
||||
|
||||
@ -622,6 +609,7 @@ source-only: all
|
||||
-$(MAKE) -f GNUmakefile.gcc_plugin
|
||||
$(MAKE) -C utils/libdislocator
|
||||
$(MAKE) -C utils/libtokencap
|
||||
-$(MAKE) -C utils/aflpp_driver
|
||||
|
||||
%.8: %
|
||||
@echo .TH $* 8 $(BUILD_DATE) "afl++" > $@
|
||||
@ -657,7 +645,6 @@ install: all $(MANPAGES)
|
||||
@if [ -f afl-fuzz-document ]; then set -e; install -m 755 afl-fuzz-document $${DESTDIR}$(BIN_PATH); fi
|
||||
@if [ -f socketfuzz32.so -o -f socketfuzz64.so ]; then $(MAKE) -C utils/socket_fuzzing install; fi
|
||||
@if [ -f argvfuzz32.so -o -f argvfuzz64.so ]; then $(MAKE) -C utils/argv_fuzzing install; fi
|
||||
@if [ -f afl-frida-trace.so ]; then install -m 755 afl-frida-trace.so $${DESTDIR}$(HELPER_PATH); fi
|
||||
@if [ -f utils/afl_network_proxy/afl-network-server ]; then $(MAKE) -C utils/afl_network_proxy install; fi
|
||||
@if [ -f utils/aflpp_driver/libAFLDriver.a ]; then set -e; install -m 644 utils/aflpp_driver/libAFLDriver.a $${DESTDIR}$(HELPER_PATH); fi
|
||||
@if [ -f utils/aflpp_driver/libAFLQemuDriver.a ]; then set -e; install -m 644 utils/aflpp_driver/libAFLQemuDriver.a $${DESTDIR}$(HELPER_PATH); fi
|
||||
|
||||
@ -41,8 +41,6 @@ CXXEFLAGS := $(CXXFLAGS) -Wall -std=c++11
|
||||
CC ?= gcc
|
||||
CXX ?= g++
|
||||
|
||||
SYS = $(shell uname -s)
|
||||
|
||||
ifeq "clang" "$(CC)"
|
||||
CC = gcc
|
||||
CXX = g++
|
||||
@ -77,30 +75,30 @@ ifeq "$(TEST_MMAP)" "1"
|
||||
override CFLAGS_SAFE += -DUSEMMAP=1
|
||||
endif
|
||||
|
||||
ifneq "$(SYS)" "Haiku"
|
||||
ifneq "$(SYS)" "OpenBSD"
|
||||
ifneq "$(shell uname -s)" "Haiku"
|
||||
ifneq "$(shell uname -s)" "OpenBSD"
|
||||
LDFLAGS += -lrt
|
||||
endif
|
||||
else
|
||||
CFLAGS_SAFE += -DUSEMMAP=1
|
||||
endif
|
||||
|
||||
ifeq "$(SYS)" "OpenBSD"
|
||||
ifeq "$(shell uname -s)" "OpenBSD"
|
||||
CC = egcc
|
||||
CXX = eg++
|
||||
PLUGIN_FLAGS += -I/usr/local/include
|
||||
endif
|
||||
|
||||
ifeq "$(SYS)" "DragonFly"
|
||||
ifeq "$(shell uname -s)" "DragonFly"
|
||||
PLUGIN_FLAGS += -I/usr/local/include
|
||||
endif
|
||||
|
||||
ifeq "$(SYS)" "SunOS"
|
||||
ifeq "$(shell uname -s)" "SunOS"
|
||||
PLUGIN_FLAGS += -I/usr/include/gmp
|
||||
endif
|
||||
|
||||
|
||||
PROGS = ./afl-gcc-pass.so ./afl-compiler-rt.o ./afl-compiler-rt-32.o ./afl-compiler-rt-64.o
|
||||
PROGS = ./afl-gcc-pass.so
|
||||
|
||||
.PHONY: all
|
||||
all: test_shm test_deps $(PROGS) test_build all_done
|
||||
@ -130,17 +128,6 @@ test_deps:
|
||||
afl-common.o: ./src/afl-common.c
|
||||
$(CC) $(CFLAGS) $(CPPFLAGS) -c $< -o $@ $(LDFLAGS)
|
||||
|
||||
./afl-compiler-rt.o: instrumentation/afl-compiler-rt.o.c
|
||||
$(CC) $(CFLAGS_SAFE) $(CPPFLAGS) -O3 -Wno-unused-result -fPIC -c $< -o $@
|
||||
|
||||
./afl-compiler-rt-32.o: instrumentation/afl-compiler-rt.o.c
|
||||
@printf "[*] Building 32-bit variant of the runtime (-m32)... "
|
||||
@$(CC) $(CFLAGS_SAFE) $(CPPFLAGS) -O3 -Wno-unused-result -m32 -fPIC -c $< -o $@ 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; ln -sf afl-compiler-rt-32.o afl-llvm-rt-32.o; else echo "failed (that's fine)"; fi
|
||||
|
||||
./afl-compiler-rt-64.o: instrumentation/afl-compiler-rt.o.c
|
||||
@printf "[*] Building 64-bit variant of the runtime (-m64)... "
|
||||
@$(CC) $(CFLAGS_SAFE) $(CPPFLAGS) -O3 -Wno-unused-result -m64 -fPIC -c $< -o $@ 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; ln -sf afl-compiler-rt-64.o afl-llvm-rt-64.o; else echo "failed (that's fine)"; fi
|
||||
|
||||
./afl-gcc-pass.so: instrumentation/afl-gcc-pass.so.cc | test_deps
|
||||
$(CXX) $(CXXEFLAGS) $(PLUGIN_FLAGS) -shared $< -o $@
|
||||
ln -sf afl-cc afl-gcc-fast
|
||||
|
||||
@ -30,13 +30,11 @@ BUILD_DATE ?= $(shell date -u -d "@$(SOURCE_DATE_EPOCH)" "+%Y-%m-%d" 2>/dev/nul
|
||||
|
||||
VERSION = $(shell grep '^$(HASH)define VERSION ' ./config.h | cut -d '"' -f2)
|
||||
|
||||
SYS = $(shell uname -s)
|
||||
|
||||
ifeq "$(SYS)" "OpenBSD"
|
||||
ifeq "$(shell uname)" "OpenBSD"
|
||||
LLVM_CONFIG ?= $(BIN_PATH)/llvm-config
|
||||
HAS_OPT = $(shell test -x $(BIN_PATH)/opt && echo 0 || echo 1)
|
||||
ifeq "$(HAS_OPT)" "1"
|
||||
$(warning llvm_mode needs a complete llvm installation (versions 6.0 up to 12) -> e.g. "pkg_add llvm-7.0.1p9")
|
||||
$(warning llvm_mode needs a complete llvm installation (versions 3.4 up to 12) -> e.g. "pkg_add llvm-7.0.1p9")
|
||||
endif
|
||||
else
|
||||
LLVM_CONFIG ?= llvm-config
|
||||
@ -45,8 +43,7 @@ endif
|
||||
LLVMVER = $(shell $(LLVM_CONFIG) --version 2>/dev/null | sed 's/git//' | sed 's/svn//' )
|
||||
LLVM_MAJOR = $(shell $(LLVM_CONFIG) --version 2>/dev/null | sed 's/\..*//' )
|
||||
LLVM_MINOR = $(shell $(LLVM_CONFIG) --version 2>/dev/null | sed 's/.*\.//' | sed 's/git//' | sed 's/svn//' | sed 's/ .*//' )
|
||||
LLVM_UNSUPPORTED = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^[0-2]\.|^3.[0-7]\.' && echo 1 || echo 0 )
|
||||
LLVM_TOO_NEW = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[3-9]' && echo 1 || echo 0 )
|
||||
LLVM_UNSUPPORTED = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^3\.[0-3]|^1[3-9]' && echo 1 || echo 0 )
|
||||
LLVM_NEW_API = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[0-9]' && echo 1 || echo 0 )
|
||||
LLVM_10_OK = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[1-9]|^10\.[1-9]|^10\.0.[1-9]' && echo 1 || echo 0 )
|
||||
LLVM_HAVE_LTO = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[1-9]' && echo 1 || echo 0 )
|
||||
@ -57,15 +54,11 @@ LLVM_APPLE_XCODE = $(shell clang -v 2>&1 | grep -q Apple && echo 1 || echo 0)
|
||||
LLVM_LTO = 0
|
||||
|
||||
ifeq "$(LLVMVER)" ""
|
||||
$(warning [!] llvm_mode needs llvm-config, which was not found. Set LLVM_CONFIG to its path and retry.)
|
||||
$(warning [!] llvm_mode needs llvm-config, which was not found)
|
||||
endif
|
||||
|
||||
ifeq "$(LLVM_UNSUPPORTED)" "1"
|
||||
$(error llvm_mode only supports llvm from version 3.8 onwards)
|
||||
endif
|
||||
|
||||
ifeq "$(LLVM_TOO_NEW)" "1"
|
||||
$(warning you are using an in-development llvm version - this might break llvm_mode!)
|
||||
$(warning llvm_mode only supports llvm versions 3.4 up to 12)
|
||||
endif
|
||||
|
||||
LLVM_TOO_OLD=1
|
||||
@ -277,13 +270,13 @@ CLANG_LFL = `$(LLVM_CONFIG) --ldflags` $(LDFLAGS)
|
||||
|
||||
|
||||
# User teor2345 reports that this is required to make things work on MacOS X.
|
||||
ifeq "$(SYS)" "Darwin"
|
||||
ifeq "$(shell uname)" "Darwin"
|
||||
CLANG_LFL += -Wl,-flat_namespace -Wl,-undefined,suppress
|
||||
else
|
||||
CLANG_CPPFL += -Wl,-znodelete
|
||||
endif
|
||||
|
||||
ifeq "$(SYS)" "OpenBSD"
|
||||
ifeq "$(shell uname)" "OpenBSD"
|
||||
CLANG_LFL += `$(LLVM_CONFIG) --libdir`/libLLVM.so
|
||||
CLANG_CPPFL += -mno-retpoline
|
||||
CFLAGS += -mno-retpoline
|
||||
@ -306,7 +299,7 @@ ifeq "$(TEST_MMAP)" "1"
|
||||
endif
|
||||
|
||||
PROGS_ALWAYS = ./afl-cc ./afl-compiler-rt.o ./afl-compiler-rt-32.o ./afl-compiler-rt-64.o
|
||||
PROGS = $(PROGS_ALWAYS) ./afl-llvm-pass.so ./SanitizerCoveragePCGUARD.so ./split-compares-pass.so ./split-switches-pass.so ./cmplog-routines-pass.so ./cmplog-instructions-pass.so ./cmplog-switches-pass.so ./afl-llvm-dict2file.so ./compare-transform-pass.so ./afl-ld-lto ./afl-llvm-lto-instrumentlist.so ./afl-llvm-lto-instrumentation.so ./SanitizerCoverageLTO.so
|
||||
PROGS = $(PROGS_ALWAYS) ./afl-llvm-pass.so ./SanitizerCoveragePCGUARD.so ./split-compares-pass.so ./split-switches-pass.so ./cmplog-routines-pass.so ./cmplog-instructions-pass.so ./afl-llvm-dict2file.so ./compare-transform-pass.so ./libLLVMInsTrim.so ./afl-ld-lto ./afl-llvm-lto-instrumentlist.so ./afl-llvm-lto-instrumentation.so ./SanitizerCoverageLTO.so ./afl-llvm-unreachable.so
|
||||
|
||||
# If prerequisites are not given, warn, do not build anything, and exit with code 0
|
||||
ifeq "$(LLVMVER)" ""
|
||||
@ -346,7 +339,7 @@ no_build:
|
||||
test_deps:
|
||||
@echo "[*] Checking for working 'llvm-config'..."
|
||||
ifneq "$(LLVM_APPLE_XCODE)" "1"
|
||||
@type $(LLVM_CONFIG) >/dev/null 2>&1 || ( echo "[-] Oops, can't find 'llvm-config'. Install clang or set \$$LLVM_CONFIG or \$$PATH beforehand."; echo " (Sometimes, the binary will be named llvm-config-11 or something like that.)"; exit 1 )
|
||||
@type $(LLVM_CONFIG) >/dev/null 2>&1 || ( echo "[-] Oops, can't find 'llvm-config'. Install clang or set \$$LLVM_CONFIG or \$$PATH beforehand."; echo " (Sometimes, the binary will be named llvm-config-3.5 or something like that.)"; exit 1 )
|
||||
endif
|
||||
@echo "[*] Checking for working '$(CC)'..."
|
||||
@type $(CC) >/dev/null 2>&1 || ( echo "[-] Oops, can't find '$(CC)'. Make sure that it's in your \$$PATH (or set \$$CC and \$$CXX)."; exit 1 )
|
||||
@ -384,6 +377,9 @@ endif
|
||||
instrumentation/afl-llvm-common.o: instrumentation/afl-llvm-common.cc instrumentation/afl-llvm-common.h
|
||||
$(CXX) $(CFLAGS) $(CPPFLAGS) `$(LLVM_CONFIG) --cxxflags` -fno-rtti -fPIC -std=$(LLVM_STDCXX) -c $< -o $@
|
||||
|
||||
./libLLVMInsTrim.so: instrumentation/LLVMInsTrim.so.cc instrumentation/MarkNodes.cc instrumentation/afl-llvm-common.o | test_deps
|
||||
-$(CXX) $(CLANG_CPPFL) -DLLVMInsTrim_EXPORTS -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< instrumentation/MarkNodes.cc -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o
|
||||
|
||||
./afl-llvm-pass.so: instrumentation/afl-llvm-pass.so.cc instrumentation/afl-llvm-common.o | test_deps
|
||||
ifeq "$(LLVM_MIN_4_0_1)" "0"
|
||||
$(info [!] N-gram branch coverage instrumentation is not available for llvm version $(LLVMVER))
|
||||
@ -433,10 +429,10 @@ endif
|
||||
./cmplog-instructions-pass.so: instrumentation/cmplog-instructions-pass.cc instrumentation/afl-llvm-common.o | test_deps
|
||||
$(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o
|
||||
|
||||
./cmplog-switches-pass.so: instrumentation/cmplog-switches-pass.cc instrumentation/afl-llvm-common.o | test_deps
|
||||
./afl-llvm-unreachable.so: instrumentation/afl-llvm-unreachable.cc instrumentation/afl-llvm-common.o | test_deps
|
||||
$(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o
|
||||
|
||||
afl-llvm-dict2file.so: instrumentation/afl-llvm-dict2file.so.cc instrumentation/afl-llvm-common.o | test_deps
|
||||
./afl-llvm-dict2file.so: instrumentation/afl-llvm-dict2file.so.cc instrumentation/afl-llvm-common.o | test_deps
|
||||
$(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o
|
||||
|
||||
.PHONY: document
|
||||
@ -509,8 +505,6 @@ install: all
|
||||
@echo .SH LICENSE >> ./$@
|
||||
@echo Apache License Version 2.0, January 2004 >> ./$@
|
||||
@ln -sf afl-cc.8 ./afl-c++.8
|
||||
@ln -sf afl-cc.8 ./afl-clang-fast.8
|
||||
@ln -sf afl-cc.8 ./afl-clang-fast++.8
|
||||
ifneq "$(AFL_CLANG_FLTO)" ""
|
||||
ifeq "$(LLVM_LTO)" "1"
|
||||
@ln -sf afl-cc.8 ./afl-clang-lto.8
|
||||
|
||||
406
README.md
406
README.md
@ -2,9 +2,11 @@
|
||||
|
||||
<img align="right" src="https://raw.githubusercontent.com/andreafioraldi/AFLplusplus-website/master/static/logo_256x256.png" alt="AFL++ Logo">
|
||||
|
||||
Release Version: [3.14c](https://github.com/AFLplusplus/AFLplusplus/releases)
|
||||

|
||||
|
||||
Github Version: 3.15a
|
||||
Release Version: [3.00c](https://github.com/AFLplusplus/AFLplusplus/releases)
|
||||
|
||||
Github Version: 3.01a
|
||||
|
||||
Repository: [https://github.com/AFLplusplus/AFLplusplus](https://github.com/AFLplusplus/AFLplusplus)
|
||||
|
||||
@ -21,33 +23,13 @@
|
||||
mutations, more and better instrumentation, custom module support, etc.
|
||||
|
||||
If you want to use afl++ for your academic work, check the [papers page](https://aflplus.plus/papers/)
|
||||
on the website. To cite our work, look at the [Cite](#cite) section.
|
||||
For comparisons use the fuzzbench `aflplusplus` setup, or use `afl-clang-fast`
|
||||
with `AFL_LLVM_CMPLOG=1`.
|
||||
on the website.
|
||||
|
||||
## Major behaviour changes in afl++ 3.00 onwards:
|
||||
## Major changes in afl++ 3.0
|
||||
|
||||
With afl++ 3.13-3.20 we introduce frida_mode (-O) to have an alternative for
|
||||
binary-only fuzzing. It is slower than Qemu mode but works on MacOS, Android,
|
||||
iOS etc.
|
||||
|
||||
With afl++ 3.15 we introduced the following changes from previous behaviours:
|
||||
* Also -M main mode does not do deterministic fuzzing by default anymore
|
||||
* afl-cmin and afl-showmap -Ci now descent into subdirectories like
|
||||
afl-fuzz -i does (but note that afl-cmin.bash does not)
|
||||
|
||||
With afl++ 3.14 we introduced the following changes from previous behaviours:
|
||||
* afl-fuzz: deterministic fuzzing it not a default for -M main anymore
|
||||
* afl-cmin/afl-showmap -i now descends into subdirectories (afl-cmin.bash
|
||||
however does not)
|
||||
|
||||
With afl++ 3.10 we introduced the following changes from previous behaviours:
|
||||
* The '+' feature of the '-t' option now means to auto-calculate the timeout
|
||||
with the value given being the maximum timeout. The original meaning of
|
||||
"skipping timeouts instead of abort" is now inherent to the -t option.
|
||||
|
||||
With afl++ 3.00 we introduced changes that break some previous afl and afl++
|
||||
With afl++ 3.0 we introduced changes that break some previous afl and afl++
|
||||
behaviours and defaults:
|
||||
|
||||
* There are no llvm_mode and gcc_plugin subdirectories anymore and there is
|
||||
only one compiler: afl-cc. All previous compilers now symlink to this one.
|
||||
All instrumentation source code is now in the `instrumentation/` folder.
|
||||
@ -59,8 +41,8 @@ behaviours and defaults:
|
||||
shared libraries, etc. Additionally QEMU 5.1 supports more CPU targets so
|
||||
this is really worth it.
|
||||
* When instrumenting targets, afl-cc will not supersede optimizations anymore
|
||||
if any were given. This allows to fuzz targets build regularly like those
|
||||
for debug or release versions.
|
||||
if any were given. This allows to fuzz targets as same as they are built
|
||||
for debug or release.
|
||||
* afl-fuzz:
|
||||
* if neither -M or -S is specified, `-S default` is assumed, so more
|
||||
fuzzers can easily be added later
|
||||
@ -93,32 +75,30 @@ behaviours and defaults:
|
||||
|
||||
## Important features of afl++
|
||||
|
||||
afl++ supports llvm from 3.8 up to version 12, very fast binary fuzzing with QEMU 5.1
|
||||
with laf-intel and redqueen, frida mode, unicorn mode, gcc plugin, full *BSD,
|
||||
Mac OS, Solaris and Android support and much, much, much more.
|
||||
afl++ supports llvm up to version 12, very fast binary fuzzing with QEMU 5.1
|
||||
with laf-intel and redqueen, unicorn mode, gcc plugin, full *BSD, Solaris and
|
||||
Android support and much, much, much more.
|
||||
|
||||
| Feature/Instrumentation | afl-gcc | llvm | gcc_plugin | frida_mode | qemu_mode |unicorn_mode |
|
||||
| -------------------------|:-------:|:---------:|:----------:|:----------------:|:----------------:|:----------------:|
|
||||
| Threadsafe counters | | x(3) | | | | |
|
||||
| NeverZero | x86[_64]| x(1) | x | x | x | x |
|
||||
| Persistent Mode | | x | x | x86[_64]/arm64 | x86[_64]/arm[64] | x |
|
||||
| LAF-Intel / CompCov | | x | | | x86[_64]/arm[64] | x86[_64]/arm[64] |
|
||||
| CmpLog | | x | | x86[_64]/arm64 | x86[_64]/arm[64] | |
|
||||
| Selective Instrumentation| | x | x | x | x | |
|
||||
| Non-Colliding Coverage | | x(4) | | | (x)(5) | |
|
||||
| Ngram prev_loc Coverage | | x(6) | | | | |
|
||||
| Context Coverage | | x(6) | | | | |
|
||||
| Auto Dictionary | | x(7) | | | | |
|
||||
| Snapshot LKM Support | | (x)(8) | (x)(8) | | (x)(5) | |
|
||||
| Shared Memory Testcases | | x | x | x86[_64]/arm64 | x | x |
|
||||
| Feature/Instrumentation | afl-gcc | llvm | gcc_plugin | qemu_mode | unicorn_mode |
|
||||
| -------------------------|:-------:|:---------:|:----------:|:----------------:|:------------:|
|
||||
| NeverZero | x86[_64]| x(1) | x | x | x |
|
||||
| Persistent Mode | | x | x | x86[_64]/arm[64] | x |
|
||||
| LAF-Intel / CompCov | | x | | x86[_64]/arm[64] | x86[_64]/arm |
|
||||
| CmpLog | | x | | x86[_64]/arm[64] | |
|
||||
| Selective Instrumentation| | x | x | x | |
|
||||
| Non-Colliding Coverage | | x(4) | | (x)(5) | |
|
||||
| Ngram prev_loc Coverage | | x(6) | | | |
|
||||
| Context Coverage | | x(6) | | | |
|
||||
| Auto Dictionary | | x(7) | | | |
|
||||
| Snapshot LKM Support | | x(8) | x(8) | (x)(5) | |
|
||||
|
||||
1. default for LLVM >= 9.0, env var for older version due an efficiency bug in previous llvm versions
|
||||
1. default for LLVM >= 9.0, env var for older version due an efficiency bug in llvm <= 8
|
||||
2. GCC creates non-performant code, hence it is disabled in gcc_plugin
|
||||
3. with `AFL_LLVM_THREADSAFE_INST`, disables NeverZero
|
||||
4. with pcguard mode and LTO mode for LLVM 11 and newer
|
||||
3. (currently unassigned)
|
||||
4. with pcguard mode and LTO mode for LLVM >= 11
|
||||
5. upcoming, development in the branch
|
||||
6. not compatible with LTO instrumentation and needs at least LLVM v4.1
|
||||
7. automatic in LTO mode with LLVM 11 and newer, an extra pass for all LLVM versions that write to a file to use with afl-fuzz' `-x`
|
||||
6. not compatible with LTO instrumentation and needs at least LLVM >= 4.1
|
||||
7. automatic in LTO mode with LLVM >= 11, an extra pass for all LLVM version that writes to a file to use with afl-fuzz' `-x`
|
||||
8. the snapshot LKM is currently unmaintained due to too many kernel changes coming too fast :-(
|
||||
|
||||
Among others, the following features and patches have been integrated:
|
||||
@ -155,7 +135,6 @@ behaviours and defaults:
|
||||
time when we are satisfied with its stability
|
||||
* [dev](https://github.com/AFLplusplus/AFLplusplus/tree/dev) : development state of afl++ - bleeding edge and you might catch a
|
||||
checkout which does not compile or has a bug. *We only accept PRs in dev!!*
|
||||
* [release](https://github.com/AFLplusplus/AFLplusplus/tree/release) : the latest release
|
||||
* (any other) : experimental branches to work on specific features or testing
|
||||
new functionality or changes.
|
||||
|
||||
@ -191,13 +170,7 @@ If you want to build afl++ yourself you have many options.
|
||||
The easiest choice is to build and install everything:
|
||||
|
||||
```shell
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y build-essential python3-dev automake git flex bison libglib2.0-dev libpixman-1-dev python3-setuptools
|
||||
# try to install llvm 11 and install the distro default if that fails
|
||||
sudo apt-get install -y lld-11 llvm-11 llvm-11-dev clang-11 || sudo apt-get install -y lld llvm llvm-dev clang
|
||||
sudo apt-get install -y gcc-$(gcc --version|head -n1|sed 's/.* //'|sed 's/\..*//')-plugin-dev libstdc++-$(gcc --version|head -n1|sed 's/.* //'|sed 's/\..*//')-dev
|
||||
git clone https://github.com/AFLplusplus/AFLplusplus
|
||||
cd AFLplusplus
|
||||
sudo apt install build-essential python3-dev automake flex bison libglib2.0-dev libpixman-1-dev clang python3-setuptools clang llvm llvm-dev libstdc++-dev
|
||||
make distrib
|
||||
sudo make install
|
||||
```
|
||||
@ -248,7 +221,7 @@ These build options exist:
|
||||
* AFL_NO_X86 - if compiling on non-intel/amd platforms
|
||||
* LLVM_CONFIG - if your distro doesn't use the standard name for llvm-config (e.g. Debian)
|
||||
|
||||
e.g.: `make ASAN_BUILD=1`
|
||||
e.g.: make ASAN_BUILD=1
|
||||
|
||||
## Good examples and writeups
|
||||
|
||||
@ -260,12 +233,10 @@ Here are some good writeups to show how to effectively use AFL++:
|
||||
* [https://securitylab.github.com/research/fuzzing-software-2](https://securitylab.github.com/research/fuzzing-software-2)
|
||||
* [https://securitylab.github.com/research/fuzzing-sockets-FTP](https://securitylab.github.com/research/fuzzing-sockets-FTP)
|
||||
* [https://securitylab.github.com/research/fuzzing-sockets-FreeRDP](https://securitylab.github.com/research/fuzzing-sockets-FreeRDP)
|
||||
* [https://securitylab.github.com/research/fuzzing-apache-1](https://securitylab.github.com/research/fuzzing-apache-1)
|
||||
|
||||
If you are interested in fuzzing structured data (where you define what the
|
||||
structure is), these links have you covered:
|
||||
* Superion for afl++: [https://github.com/adrian-rt/superion-mutator](https://github.com/adrian-rt/superion-mutator)
|
||||
* libprotobuf for afl++: [https://github.com/P1umer/AFLplusplus-protobuf-mutator](https://github.com/P1umer/AFLplusplus-protobuf-mutator)
|
||||
* libprotobuf raw: [https://github.com/bruce30262/libprotobuf-mutator_fuzzing_learning/tree/master/4_libprotobuf_aflpp_custom_mutator](https://github.com/bruce30262/libprotobuf-mutator_fuzzing_learning/tree/master/4_libprotobuf_aflpp_custom_mutator)
|
||||
* libprotobuf for old afl++ API: [https://github.com/thebabush/afl-libprotobuf-mutator](https://github.com/thebabush/afl-libprotobuf-mutator)
|
||||
|
||||
@ -305,7 +276,7 @@ anything below 9 is not recommended.
|
||||
|
|
||||
v
|
||||
+---------------------------------+
|
||||
| clang/clang++ 3.8+ is available | --> use LLVM mode (afl-clang-fast/afl-clang-fast++)
|
||||
| clang/clang++ 3.3+ is available | --> use LLVM mode (afl-clang-fast/afl-clang-fast++)
|
||||
+---------------------------------+ see [instrumentation/README.llvm.md](instrumentation/README.llvm.md)
|
||||
|
|
||||
| if not, or if the target fails with LLVM afl-clang-fast/++
|
||||
@ -327,7 +298,7 @@ Clickable README links for the chosen compiler:
|
||||
* [LTO mode - afl-clang-lto](instrumentation/README.lto.md)
|
||||
* [LLVM mode - afl-clang-fast](instrumentation/README.llvm.md)
|
||||
* [GCC_PLUGIN mode - afl-gcc-fast](instrumentation/README.gcc_plugin.md)
|
||||
* GCC/CLANG modes (afl-gcc/afl-clang) have no README as they have no own features
|
||||
* GCC/CLANG mode (afl-gcc/afl-clang) have no README as they have no own features
|
||||
|
||||
You can select the mode for the afl-cc compiler by:
|
||||
1. use a symlink to afl-cc: afl-gcc, afl-g++, afl-clang, afl-clang++,
|
||||
@ -387,67 +358,19 @@ There are many more options and modes available however these are most of the
|
||||
time less effective. See:
|
||||
* [instrumentation/README.ctx.md](instrumentation/README.ctx.md)
|
||||
* [instrumentation/README.ngram.md](instrumentation/README.ngram.md)
|
||||
* [instrumentation/README.instrim.md](instrumentation/README.instrim.md)
|
||||
|
||||
afl++ performs "never zero" counting in its bitmap. You can read more about this
|
||||
here:
|
||||
* [instrumentation/README.neverzero.md](instrumentation/README.neverzero.md)
|
||||
|
||||
#### c) Sanitizers
|
||||
|
||||
It is possible to use sanitizers when instrumenting targets for fuzzing,
|
||||
which allows you to find bugs that would not necessarily result in a crash.
|
||||
|
||||
Note that sanitizers have a huge impact on CPU (= less executions per second)
|
||||
and RAM usage. Also you should only run one afl-fuzz instance per sanitizer type.
|
||||
This is enough because a use-after-free bug will be picked up, e.g. by
|
||||
ASAN (address sanitizer) anyway when syncing to other fuzzing instances,
|
||||
so not all fuzzing instances need to be instrumented with ASAN.
|
||||
|
||||
The following sanitizers have built-in support in afl++:
|
||||
* ASAN = Address SANitizer, finds memory corruption vulnerabilities like
|
||||
use-after-free, NULL pointer dereference, buffer overruns, etc.
|
||||
Enabled with `export AFL_USE_ASAN=1` before compiling.
|
||||
* MSAN = Memory SANitizer, finds read access to uninitialized memory, eg.
|
||||
a local variable that is defined and read before it is even set.
|
||||
Enabled with `export AFL_USE_MSAN=1` before compiling.
|
||||
* UBSAN = Undefined Behaviour SANitizer, finds instances where - by the
|
||||
C and C++ standards - undefined behaviour happens, e.g. adding two
|
||||
signed integers together where the result is larger than a signed integer
|
||||
can hold.
|
||||
Enabled with `export AFL_USE_UBSAN=1` before compiling.
|
||||
* CFISAN = Control Flow Integrity SANitizer, finds instances where the
|
||||
control flow is found to be illegal. Originally this was rather to
|
||||
prevent return oriented programming exploit chains from functioning,
|
||||
in fuzzing this is mostly reduced to detecting type confusion
|
||||
vulnerabilities - which is however one of the most important and dangerous
|
||||
C++ memory corruption classes!
|
||||
Enabled with `export AFL_USE_CFISAN=1` before compiling.
|
||||
* LSAN = Leak SANitizer, finds memory leaks in a program. This is not really
|
||||
a security issue, but for developers this can be very valuable.
|
||||
Note that unlike the other sanitizers above this needs
|
||||
`__AFL_LEAK_CHECK();` added to all areas of the target source code where you
|
||||
find a leak check necessary!
|
||||
Enabled with `export AFL_USE_LSAN=1` before compiling.
|
||||
|
||||
It is possible to further modify the behaviour of the sanitizers at run-time
|
||||
by setting `ASAN_OPTIONS=...`, `LSAN_OPTIONS` etc. - the available parameters
|
||||
can be looked up in the sanitizer documentation of llvm/clang.
|
||||
afl-fuzz however requires some specific parameters important for fuzzing to be
|
||||
set. If you want to set your own, it might bail and report what it is missing.
|
||||
|
||||
Note that some sanitizers cannot be used together, e.g. ASAN and MSAN, and
|
||||
others often cannot work together because of target weirdness, e.g. ASAN and
|
||||
CFISAN. You might need to experiment which sanitizers you can combine in a
|
||||
target (which means more instances can be run without a sanitized target,
|
||||
which is more effective).
|
||||
|
||||
#### d) Modify the target
|
||||
#### c) Modify the target
|
||||
|
||||
If the target has features that make fuzzing more difficult, e.g.
|
||||
checksums, HMAC, etc. then modify the source code so that checks for these
|
||||
values are removed.
|
||||
This can even be done safely for source code used in operational products
|
||||
by eliminating these checks within these AFL specific blocks:
|
||||
checksums, HMAC, etc. then modify the source code so that this is
|
||||
removed.
|
||||
This can even be done for operational source code by eliminating
|
||||
these checks within this specific defines:
|
||||
|
||||
```
|
||||
#ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION
|
||||
@ -459,7 +382,7 @@ by eliminating these checks within these AFL specific blocks:
|
||||
|
||||
All afl++ compilers will set this preprocessor definition automatically.
|
||||
|
||||
#### e) Instrument the target
|
||||
#### d) Instrument the target
|
||||
|
||||
In this step the target source code is compiled so that it can be fuzzed.
|
||||
|
||||
@ -470,19 +393,10 @@ How to do this is described below.
|
||||
|
||||
Then build the target. (Usually with `make`)
|
||||
|
||||
**NOTES**
|
||||
|
||||
1. sometimes configure and build systems are fickle and do not like
|
||||
stderr output (and think this means a test failure) - which is something
|
||||
afl++ likes to do to show statistics. It is recommended to disable afl++
|
||||
instrumentation reporting via `export AFL_QUIET=1`.
|
||||
|
||||
2. sometimes configure and build systems error on warnings - these should be
|
||||
disabled (e.g. `--disable-werror` for some configure scripts).
|
||||
|
||||
3. in case the configure/build system complains about afl++'s compiler and
|
||||
aborts then set `export AFL_NOOPT=1` which will then just behave like the
|
||||
real compiler. This option has to be unset again before building the target!
|
||||
**NOTE**: sometimes configure and build systems are fickle and do not like
|
||||
stderr output (and think this means a test failure) - which is something
|
||||
afl++ like to do to show statistics. It is recommended to disable them via
|
||||
`export AFL_QUIET=1`.
|
||||
|
||||
##### configure
|
||||
|
||||
@ -496,7 +410,7 @@ described in [instrumentation/README.lto.md](instrumentation/README.lto.md).
|
||||
##### cmake
|
||||
|
||||
For `cmake` build systems this is usually done by:
|
||||
`mkdir build; cd build; cmake -DCMAKE_C_COMPILER=afl-cc -DCMAKE_CXX_COMPILER=afl-c++ ..`
|
||||
`mkdir build; cmake -DCMAKE_C_COMPILERC=afl-cc -DCMAKE_CXX_COMPILER=afl-c++ ..`
|
||||
|
||||
Note that if you are using the (better) afl-clang-lto compiler you also have to
|
||||
set AR to llvm-ar[-VERSION] and RANLIB to llvm-ranlib[-VERSION] - as is
|
||||
@ -516,38 +430,20 @@ non-standard way to set this, otherwise set up the build normally and edit the
|
||||
generated build environment afterwards manually to point it to the right compiler
|
||||
(and/or ranlib and ar).
|
||||
|
||||
#### f) Better instrumentation
|
||||
#### d) Better instrumentation
|
||||
|
||||
If you just fuzz a target program as-is you are wasting a great opportunity for
|
||||
much more fuzzing speed.
|
||||
|
||||
This variant requires the usage of afl-clang-lto, afl-clang-fast or afl-gcc-fast.
|
||||
This requires the usage of afl-clang-lto or afl-clang-fast.
|
||||
|
||||
It is the so-called `persistent mode`, which is much, much faster but
|
||||
This is the so-called `persistent mode`, which is much, much faster but
|
||||
requires that you code a source file that is specifically calling the target
|
||||
functions that you want to fuzz, plus a few specific afl++ functions around
|
||||
it. See [instrumentation/README.persistent_mode.md](instrumentation/README.persistent_mode.md) for details.
|
||||
|
||||
Basically if you do not fuzz a target in persistent mode then you are just
|
||||
doing it for a hobby and not professionally :-).
|
||||
|
||||
#### g) libfuzzer fuzzer harnesses with LLVMFuzzerTestOneInput()
|
||||
|
||||
libfuzzer `LLVMFuzzerTestOneInput()` harnesses are the defacto standard
|
||||
for fuzzing, and they can be used with afl++ (and honggfuzz) as well!
|
||||
Compiling them is as simple as:
|
||||
```
|
||||
afl-clang-fast++ -fsanitize=fuzzer -o harness harness.cpp targetlib.a
|
||||
```
|
||||
You can even use advanced libfuzzer features like `FuzzedDataProvider`,
|
||||
`LLVMFuzzerMutate()` etc. and they will work!
|
||||
|
||||
The generated binary is fuzzed with afl-fuzz like any other fuzz target.
|
||||
|
||||
Bonus: the target is already optimized for fuzzing due to persistent mode and
|
||||
shared-memory testcases and hence gives you the fastest speed possible.
|
||||
|
||||
For more information see [utils/aflpp_driver/README.md](utils/aflpp_driver/README.md)
|
||||
doing it for a hobby and not professionally :-)
|
||||
|
||||
### 2. Preparing the fuzzing campaign
|
||||
|
||||
@ -579,14 +475,11 @@ Note that the INPUTFILE argument that the target program would read from has to
|
||||
If the target reads from stdin instead, just omit the `@@` as this is the
|
||||
default.
|
||||
|
||||
This step is highly recommended!
|
||||
|
||||
#### c) Minimizing all corpus files
|
||||
|
||||
The shorter the input files that still traverse the same path
|
||||
within the target, the better the fuzzing will be. This minimization
|
||||
is done with `afl-tmin` however it is a long process as this has to
|
||||
be done for every file:
|
||||
within the target, the better the fuzzing will be. This is done with `afl-tmin`
|
||||
however it is a long process as this has to be done for every file:
|
||||
|
||||
```
|
||||
mkdir input
|
||||
@ -596,8 +489,7 @@ for i in *; do
|
||||
done
|
||||
```
|
||||
|
||||
This step can also be parallelized, e.g. with `parallel`.
|
||||
Note that this step is rather optional though.
|
||||
This step can also be parallelized, e.g. with `parallel`
|
||||
|
||||
#### Done!
|
||||
|
||||
@ -633,25 +525,17 @@ step [2a. Collect inputs](#a-collect-inputs):
|
||||
`afl-fuzz -i input -o output -- bin/target -d @@`
|
||||
Note that the directory specified with -o will be created if it does not exist.
|
||||
|
||||
It can be valuable to run afl-fuzz in a screen or tmux shell so you can log off,
|
||||
or afl-fuzz is not aborted if you are running it in a remote ssh session where
|
||||
the connection fails in between.
|
||||
Only do that though once you have verified that your fuzzing setup works!
|
||||
Simply run it like `screen -dmS afl-main -- afl-fuzz -M main-$HOSTNAME -i ...`
|
||||
and it will start away in a screen session. To enter this session simply type
|
||||
`screen -r afl-main`. You see - it makes sense to name the screen session
|
||||
same as the afl-fuzz -M/-S naming :-)
|
||||
For more information on screen or tmux please check their documentation.
|
||||
|
||||
If you need to stop and re-start the fuzzing, use the same command line options
|
||||
(or even change them by selecting a different power schedule or another
|
||||
mutation mode!) and switch the input directory with a dash (`-`):
|
||||
`afl-fuzz -i - -o output -- bin/target -d @@`
|
||||
|
||||
Memory limits are not enforced by afl-fuzz by default and the system may run
|
||||
out of memory. You can decrease the memory with the `-m` option, the value is
|
||||
in MB. If this is too small for the target, you can usually see this by
|
||||
afl-fuzz bailing with the message that it could not connect to the forkserver.
|
||||
Note that afl-fuzz enforces memory limits to prevent the system to run out
|
||||
of memory. By default this is 50MB for a process. If this is too little for
|
||||
the target (which you can usually see by afl-fuzz bailing with the message
|
||||
that it could not connect to the forkserver), then you can increase this
|
||||
with the `-m` option, the value is in MB. To disable any memory limits
|
||||
(beware!) set `-m none` - which is usually required for ASAN compiled targets.
|
||||
|
||||
Adding a dictionary is helpful. See the directory [dictionaries/](dictionaries/) if
|
||||
something is already included for your data format, and tell afl-fuzz to load
|
||||
@ -661,19 +545,10 @@ to use afl-clang-lto as the compiler. You also have the option to generate
|
||||
a dictionary yourself, see [utils/libtokencap/README.md](utils/libtokencap/README.md).
|
||||
|
||||
afl-fuzz has a variety of options that help to workaround target quirks like
|
||||
specific locations for the input file (`-f`), performing deterministic
|
||||
fuzzing (`-D`) and many more. Check out `afl-fuzz -h`.
|
||||
specific locations for the input file (`-f`), not performing deterministic
|
||||
fuzzing (`-d`) and many more. Check out `afl-fuzz -h`.
|
||||
|
||||
We highly recommend that you set a memory limit for running the target with `-m`
|
||||
which defines the maximum memory in MB. This prevents a potential
|
||||
out-of-memory problem for your system plus helps you detect missing `malloc()`
|
||||
failure handling in the target.
|
||||
Play around with various -m values until you find one that safely works for all
|
||||
your input seeds (if you have good ones and then double or quadrouple that.
|
||||
|
||||
By default afl-fuzz never stops fuzzing. To terminate afl++ simply press Control-C
|
||||
or send a signal SIGINT. You can limit the number of executions or approximate runtime
|
||||
in seconds with options also.
|
||||
afl-fuzz never stops fuzzing. To terminate afl++ simply press Control-C.
|
||||
|
||||
When you start afl-fuzz you will see a user interface that shows what the status
|
||||
is:
|
||||
@ -696,7 +571,7 @@ of the testcases. Depending on the average testcase size (and those found
|
||||
during fuzzing) and their number, a value between 50-500MB is recommended.
|
||||
You can set the cache size (in MB) by setting the environment variable `AFL_TESTCACHE_SIZE`.
|
||||
|
||||
There should be one main fuzzer (`-M main-$HOSTNAME` option) and as many secondary
|
||||
There should be one main fuzzer (`-M main` option) and as many secondary
|
||||
fuzzers (eg `-S variant1`) as you have cores that you use.
|
||||
Every -M/-S entry needs a unique name (that can be whatever), however the same
|
||||
-o output directory location has to be used for all instances.
|
||||
@ -704,35 +579,28 @@ Every -M/-S entry needs a unique name (that can be whatever), however the same
|
||||
For every secondary fuzzer there should be a variation, e.g.:
|
||||
* one should fuzz the target that was compiled differently: with sanitizers
|
||||
activated (`export AFL_USE_ASAN=1 ; export AFL_USE_UBSAN=1 ;
|
||||
export AFL_USE_CFISAN=1`)
|
||||
* one or two should fuzz the target with CMPLOG/redqueen (see above), at
|
||||
least one cmplog instance should follow transformations (`-l AT`)
|
||||
export AFL_USE_CFISAN=1 ; `
|
||||
* one should fuzz the target with CMPLOG/redqueen (see above)
|
||||
* one to three fuzzers should fuzz a target compiled with laf-intel/COMPCOV
|
||||
(see above). Important note: If you run more than one laf-intel/COMPCOV
|
||||
fuzzer and you want them to share their intermediate results, the main
|
||||
fuzzer (`-M`) must be one of the them! (Although this is not really
|
||||
recommended.)
|
||||
fuzzer (`-M`) must be one of the them!
|
||||
|
||||
All other secondaries should be used like this:
|
||||
* A quarter to a third with the MOpt mutator enabled: `-L 0`
|
||||
* run with a different power schedule, recommended are:
|
||||
`fast (default), explore, coe, lin, quad, exploit and rare`
|
||||
which you can set with e.g. `-p explore`
|
||||
* a few instances should use the old queue cycling with `-Z`
|
||||
* A third to a half with the MOpt mutator enabled: `-L 0`
|
||||
* run with a different power schedule, available are:
|
||||
`fast (default), explore, coe, lin, quad, exploit, mmopt, rare, seek`
|
||||
which you can set with e.g. `-p seek`
|
||||
|
||||
Also it is recommended to set `export AFL_IMPORT_FIRST=1` to load testcases
|
||||
from other fuzzers in the campaign first.
|
||||
|
||||
If you have a large corpus, a corpus from a previous run or are fuzzing in
|
||||
a CI, then also set `export AFL_CMPLOG_ONLY_NEW=1` and `export AFL_FAST_CAL=1`.
|
||||
|
||||
You can also use different fuzzers.
|
||||
If you are using afl spinoffs or afl conforming fuzzers, then just use the
|
||||
same -o directory and give it a unique `-S` name.
|
||||
Examples are:
|
||||
* [Fuzzolic](https://github.com/season-lab/fuzzolic)
|
||||
* [symcc](https://github.com/eurecom-s/symcc/)
|
||||
* [Eclipser](https://github.com/SoftSec-KAIST/Eclipser/)
|
||||
* [Untracer](https://github.com/FoRTE-Research/UnTracer-AFL)
|
||||
* [AFLsmart](https://github.com/aflsmart/aflsmart)
|
||||
* [FairFuzz](https://github.com/carolemieux/afl-rb)
|
||||
* [Neuzz](https://github.com/Dongdongshe/neuzz)
|
||||
@ -740,52 +608,11 @@ Examples are:
|
||||
|
||||
A long list can be found at [https://github.com/Microsvuln/Awesome-AFL](https://github.com/Microsvuln/Awesome-AFL)
|
||||
|
||||
However you can also sync afl++ with honggfuzz, libfuzzer with `-entropic=1`, etc.
|
||||
However you can also sync afl++ with honggfuzz, libfuzzer with -entropic, etc.
|
||||
Just show the main fuzzer (-M) with the `-F` option where the queue/work
|
||||
directory of a different fuzzer is, e.g. `-F /src/target/honggfuzz`.
|
||||
Using honggfuzz (with `-n 1` or `-n 2`) and libfuzzer in parallel is highly
|
||||
recommended!
|
||||
|
||||
#### c) Using multiple machines for fuzzing
|
||||
|
||||
Maybe you have more than one machine you want to fuzz the same target on.
|
||||
Simply start the `afl-fuzz` (and perhaps libfuzzer, honggfuzz, ...)
|
||||
orchestra as you like, just ensure that your have one and only one `-M`
|
||||
instance per server, and that its name is unique, hence the recommendation
|
||||
for `-M main-$HOSTNAME`.
|
||||
|
||||
Now there are three strategies on how you can sync between the servers:
|
||||
* never: sounds weird, but this makes every server an island and has the
|
||||
chance the each follow different paths into the target. You can make
|
||||
this even more interesting by even giving different seeds to each server.
|
||||
* regularly (~4h): this ensures that all fuzzing campaigns on the servers
|
||||
"see" the same thing. It is like fuzzing on a huge server.
|
||||
* in intervals of 1/10th of the overall expected runtime of the fuzzing you
|
||||
sync. This tries a bit to combine both. have some individuality of the
|
||||
paths each campaign on a server explores, on the other hand if one
|
||||
gets stuck where another found progress this is handed over making it
|
||||
unstuck.
|
||||
|
||||
The syncing process itself is very simple.
|
||||
As the `-M main-$HOSTNAME` instance syncs to all `-S` secondaries as well
|
||||
as to other fuzzers, you have to copy only this directory to the other
|
||||
machines.
|
||||
|
||||
Lets say all servers have the `-o out` directory in /target/foo/out, and
|
||||
you created a file `servers.txt` which contains the hostnames of all
|
||||
participating servers, plus you have an ssh key deployed to all of them,
|
||||
then run:
|
||||
```bash
|
||||
for FROM in `cat servers.txt`; do
|
||||
for TO in `cat servers.txt`; do
|
||||
rsync -rlpogtz --rsh=ssh $FROM:/target/foo/out/main-$FROM $TO:target/foo/out/
|
||||
done
|
||||
done
|
||||
```
|
||||
You can run this manually, per cron job - as you need it.
|
||||
There is a more complex and configurable script in `utils/distributed_fuzzing`.
|
||||
|
||||
#### d) The status of the fuzz campaign
|
||||
#### c) The status of the fuzz campaign
|
||||
|
||||
afl++ comes with the `afl-whatsup` script to show the status of the fuzzing
|
||||
campaign.
|
||||
@ -794,14 +621,11 @@ Just supply the directory that afl-fuzz is given with the -o option and
|
||||
you will see a detailed status of every fuzzer in that campaign plus
|
||||
a summary.
|
||||
|
||||
To have only the summary use the `-s` switch e.g.: `afl-whatsup -s out/`
|
||||
To have only the summary use the `-s` switch e.g.: `afl-whatsup -s output/`
|
||||
|
||||
If you have multiple servers then use the command after a sync, or you have
|
||||
to execute this script per server.
|
||||
#### d) Checking the coverage of the fuzzing
|
||||
|
||||
#### e) Checking the coverage of the fuzzing
|
||||
|
||||
The `paths found` value is a bad indicator for checking how good the coverage is.
|
||||
The `paths found` value is a bad indicator how good the coverage is.
|
||||
|
||||
A better indicator - if you use default llvm instrumentation with at least
|
||||
version 9 - is to use `afl-showmap` with the collect coverage option `-C` on
|
||||
@ -826,16 +650,15 @@ If you see that an important area or a feature has not been covered so far then
|
||||
try to find an input that is able to reach that and start a new secondary in
|
||||
that fuzzing campaign with that seed as input, let it run for a few minutes,
|
||||
then terminate it. The main node will pick it up and make it available to the
|
||||
other secondary nodes over time. Set `export AFL_NO_AFFINITY=1` or
|
||||
`export AFL_TRY_AFFINITY=1` if you have no free core.
|
||||
other secondary nodes over time. Set `export AFL_NO_AFFINITY=1` if you have no
|
||||
free core.
|
||||
|
||||
Note that in nearly all cases you can never reach full coverage. A lot of
|
||||
functionality is usually dependent on exclusive options that would need individual
|
||||
fuzzing campaigns each with one of these options set. E.g. if you fuzz a library to
|
||||
convert image formats and your target is the png to tiff API then you will not
|
||||
touch any of the other library APIs and features.
|
||||
Note that you in nearly all cases can never reach full coverage. A lot of
|
||||
functionality is usually behind options that were not activated or fuzz e.g.
|
||||
if you fuzz a library to convert image formats and your target is the png to
|
||||
tiff API then you will not touch any of the other library APIs and features.
|
||||
|
||||
#### f) How long to fuzz a target?
|
||||
#### e) How long to fuzz a target?
|
||||
|
||||
This is a difficult question.
|
||||
Basically if no new path is found for a long time (e.g. for a day or a week)
|
||||
@ -847,7 +670,7 @@ Keep the queue/ directory (for future fuzzings of the same or similar targets)
|
||||
and use them to seed other good fuzzers like libfuzzer with the -entropic
|
||||
switch or honggfuzz.
|
||||
|
||||
#### g) Improve the speed!
|
||||
#### f) Improve the speed!
|
||||
|
||||
* Use [persistent mode](instrumentation/README.persistent_mode.md) (x2-x20 speed increase)
|
||||
* If you do not use shmem persistent mode, use `AFL_TMPDIR` to point the input file on a tempfs location, see [docs/env_variables.md](docs/env_variables.md)
|
||||
@ -914,45 +737,37 @@ campaigns as these are much shorter runnings.
|
||||
corpus needs to be loaded.
|
||||
* `AFL_CMPLOG_ONLY_NEW` - only perform cmplog on new found paths, not the
|
||||
initial corpus as this very likely has been done for them already.
|
||||
* Keep the generated corpus, use afl-cmin and reuse it every time!
|
||||
* Keep the generated corpus, use afl-cmin and reuse it everytime!
|
||||
|
||||
2. Additionally randomize the afl++ compilation options, e.g.
|
||||
* 40% for `AFL_LLVM_CMPLOG`
|
||||
* 10% for `AFL_LLVM_LAF_ALL`
|
||||
|
||||
3. Also randomize the afl-fuzz runtime options, e.g.
|
||||
* 65% for `AFL_DISABLE_TRIM`
|
||||
* 60% for `AFL_DISABLE_TRIM`
|
||||
* 50% use a dictionary generated by `AFL_LLVM_DICT2FILE`
|
||||
* 40% use MOpt (`-L 0`)
|
||||
* 50% use MOpt (`-L 0`)
|
||||
* 40% for `AFL_EXPAND_HAVOC_NOW`
|
||||
* 20% for old queue processing (`-Z`)
|
||||
* 30% for old queue processing (`-Z`)
|
||||
* for CMPLOG targets, 60% for `-l 2`, 40% for `-l 3`
|
||||
|
||||
4. Do *not* run any `-M` modes, just running `-S` modes is better for CI fuzzing.
|
||||
`-M` enables old queue handling etc. which is good for a fuzzing campaign but
|
||||
not good for short CI runs.
|
||||
|
||||
How this can look like can e.g. be seen at afl++'s setup in Google's [oss-fuzz](https://github.com/google/oss-fuzz/blob/master/infra/base-images/base-builder/compile_afl)
|
||||
and [clusterfuzz](https://github.com/google/clusterfuzz/blob/master/src/python/bot/fuzzers/afl/launcher.py).
|
||||
|
||||
## Fuzzing binary-only targets
|
||||
|
||||
When source code is *NOT* available, afl++ offers various support for fast,
|
||||
on-the-fly instrumentation of black-box binaries.
|
||||
|
||||
If you do not have to use Unicorn the following setup is recommended to use
|
||||
qemu_mode:
|
||||
If you do not have to use Unicorn the following setup is recommended:
|
||||
* run 1 afl-fuzz -Q instance with CMPLOG (`-c 0` + `AFL_COMPCOV_LEVEL=2`)
|
||||
* run 1 afl-fuzz -Q instance with QASAN (`AFL_USE_QASAN=1`)
|
||||
* run 1 afl-fuzz -Q instance with LAF (`AFL_PRELOAD=libcmpcov.so` + `AFL_COMPCOV_LEVEL=2`)
|
||||
Alternatively you can use frida_mode, just switch `-Q` with `-O` and remove the
|
||||
LAF instance.
|
||||
* run 1 afl-fuzz -Q instance with LAF (``AFL_PRELOAD=libcmpcov.so` + `AFL_COMPCOV_LEVEL=2`)
|
||||
|
||||
Then run as many instances as you have cores left with either -Q mode or - better -
|
||||
use a binary rewriter like afl-dyninst, retrowrite, zafl, etc.
|
||||
use a binary rewriter like afl-dyninst, retrowrite, zipr, fibre, etc.
|
||||
|
||||
For Qemu and Frida mode, check out the persistent mode, it gives a huge speed
|
||||
improvement if it is possible to use.
|
||||
For Qemu mode, check out the persistent mode and snapshot features, they give
|
||||
a huge speed improvement!
|
||||
|
||||
### QEMU
|
||||
|
||||
@ -964,30 +779,18 @@ feature by doing:
|
||||
cd qemu_mode
|
||||
./build_qemu_support.sh
|
||||
```
|
||||
For additional instructions and caveats, see [qemu_mode/README.md](qemu_mode/README.md).
|
||||
For additional instructions and caveats, see [qemu_mode/README.md](qemu_mode/README.md) -
|
||||
check out the snapshot feature! :-)
|
||||
If possible you should use the persistent mode, see [qemu_mode/README.persistent.md](qemu_mode/README.persistent.md).
|
||||
The mode is approximately 2-5x slower than compile-time instrumentation, and is
|
||||
less conducive to parallelization.
|
||||
|
||||
If [afl-dyninst](https://github.com/vanhauser-thc/afl-dyninst) works for
|
||||
your binary, then you can use afl-fuzz normally and it will have twice
|
||||
the speed compared to qemu_mode (but slower than qemu persistent mode).
|
||||
the speed compared to qemu_mode (but slower than persistent mode).
|
||||
Note that several other binary rewriters exist, all with their advantages and
|
||||
caveats.
|
||||
|
||||
### Frida
|
||||
|
||||
Frida mode is sometimes faster and sometimes slower than Qemu mode.
|
||||
It is also newer, lacks COMPCOV, but supports MacOS.
|
||||
|
||||
```shell
|
||||
cd frida_mode
|
||||
make
|
||||
```
|
||||
For additional instructions and caveats, see [frida_mode/README.md](frida_mode/README.md).
|
||||
If possible you should use the persistent mode, see [qemu_frida/README.persistent.md](qemu_frida/README.persistent.md).
|
||||
The mode is approximately 2-5x slower than compile-time instrumentation, and is
|
||||
less conducive to parallelization.
|
||||
caveats. As rewriting a binary is much faster than Qemu this is a highly
|
||||
recommended approach!
|
||||
|
||||
### Unicorn
|
||||
|
||||
@ -1356,7 +1159,6 @@ without feedback, bug reports, or patches from:
|
||||
Josephine Calliotte Konrad Welc
|
||||
Thomas Rooijakkers David Carlier
|
||||
Ruben ten Hove Joey Jiao
|
||||
fuzzah
|
||||
```
|
||||
|
||||
Thank you!
|
||||
@ -1364,18 +1166,8 @@ Thank you!
|
||||
|
||||
## Cite
|
||||
|
||||
If you use AFLpluplus to compare to your work, please use either `afl-clang-lto`
|
||||
or `afl-clang-fast` with `AFL_LLVM_CMPLOG=1` for building targets and
|
||||
`afl-fuzz` with the command line option `-l 2` for fuzzing.
|
||||
The most effective setup is the `aflplusplus` default configuration on Google's [fuzzbench](https://github.com/google/fuzzbench/tree/master/fuzzers/aflplusplus).
|
||||
|
||||
If you use AFLplusplus in scientific work, consider citing [our paper](https://www.usenix.org/conference/woot20/presentation/fioraldi) presented at WOOT'20:
|
||||
|
||||
+ Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. “AFL++: Combining incremental steps of fuzzing research”. In 14th USENIX Workshop on Offensive Technologies (WOOT 20). USENIX Association, Aug. 2020.
|
||||
|
||||
Bibtex:
|
||||
|
||||
```bibtex
|
||||
```
|
||||
@inproceedings {AFLplusplus-Woot20,
|
||||
author = {Andrea Fioraldi and Dominik Maier and Heiko Ei{\ss}feldt and Marc Heuse},
|
||||
title = {{AFL++}: Combining Incremental Steps of Fuzzing Research},
|
||||
|
||||
18
TODO.md
18
TODO.md
@ -2,20 +2,20 @@
|
||||
|
||||
## Roadmap 3.00+
|
||||
|
||||
- Update afl->pending_not_fuzzed for MOpt
|
||||
- put fuzz target in top line of UI
|
||||
- AFL_MAP_SIZE for qemu_mode and unicorn_mode
|
||||
- CPU affinity for many cores? There seems to be an issue > 96 cores
|
||||
- afl-plot to support multiple plot_data
|
||||
- afl_custom_fuzz_splice_optin()
|
||||
- afl_custom_splice()
|
||||
- better autodetection of shifting runtime timeout values
|
||||
- cmplog: use colorization input for havoc?
|
||||
- parallel builds for source-only targets
|
||||
|
||||
- intel-pt tracer
|
||||
|
||||
## Further down the road
|
||||
|
||||
afl-fuzz:
|
||||
- setting min_len/max_len/start_offset/end_offset limits for mutation output
|
||||
- add __sanitizer_cov_trace_cmp* support via shmem
|
||||
|
||||
llvm_mode:
|
||||
- add __sanitizer_cov_trace_cmp* support
|
||||
|
||||
qemu_mode:
|
||||
- non colliding instrumentation
|
||||
@ -26,13 +26,9 @@ qemu_mode:
|
||||
- add/implement AFL_QEMU_INST_LIBLIST and AFL_QEMU_NOINST_PROGRAM
|
||||
- add/implement AFL_QEMU_INST_REGIONS as a list of _START/_END addresses
|
||||
|
||||
|
||||
## Ideas
|
||||
|
||||
- LTO/sancov: write current edge to prev_loc and use that information when
|
||||
using cmplog or __sanitizer_cov_trace_cmp*. maybe we can deduct by follow
|
||||
up edge numbers that both following cmp paths have been found and then
|
||||
disable working on this edge id -> cmplog_intelligence branch
|
||||
- use cmplog colorization taint result for havoc locations?
|
||||
- new instrumentation option for a thread-safe variant of feedback to shared mem.
|
||||
The user decides, if this is needed (eg the target is multithreaded).
|
||||
|
||||
72
afl-cmin
72
afl-cmin
@ -106,7 +106,6 @@ function usage() {
|
||||
" -f file - location read by the fuzzed program (stdin)\n" \
|
||||
" -m megs - memory limit for child process ("mem_limit" MB)\n" \
|
||||
" -t msec - run time limit for child process (none)\n" \
|
||||
" -O - use binary-only instrumentation (FRIDA mode)\n" \
|
||||
" -Q - use binary-only instrumentation (QEMU mode)\n" \
|
||||
" -U - use unicorn-based instrumentation (unicorn mode)\n" \
|
||||
"\n" \
|
||||
@ -119,14 +118,11 @@ function usage() {
|
||||
"Environment variables used:\n" \
|
||||
"AFL_ALLOW_TMP: allow unsafe use of input/output directories under {/var}/tmp\n" \
|
||||
"AFL_CRASH_EXITCODE: optional child exit code to be interpreted as crash\n" \
|
||||
"AFL_FORKSRV_INIT_TMOUT: time the fuzzer waits for the forkserver to come up\n" \
|
||||
"AFL_FORKSRV_INIT_TMOUT: time the fuzzer waits for the target to come up, initially\n" \
|
||||
"AFL_KEEP_TRACES: leave the temporary <out_dir>/.traces directory\n" \
|
||||
"AFL_KILL_SIGNAL: Signal delivered to child processes on timeout (default: SIGKILL)\n" \
|
||||
"AFL_NO_FORKSRV: run target via execve instead of using the forkserver\n" \
|
||||
"AFL_PATH: path for the afl-showmap binary if not found anywhere in PATH\n" \
|
||||
"AFL_PRINT_FILENAMES: If set, the filename currently processed will be " \
|
||||
"printed to stdout\n" \
|
||||
"AFL_SKIP_BIN_CHECK: skip afl instrumentation checks for target binary\n"
|
||||
"AFL_KILL_SIGNAL: Signal ID delivered to child processes on timeout, etc. (default: SIGKILL)\n"
|
||||
"AFL_PATH: path for the afl-showmap binary if not found anywhere else\n" \
|
||||
"AFL_SKIP_BIN_CHECK: skip check for target binary\n"
|
||||
exit 1
|
||||
}
|
||||
|
||||
@ -144,7 +140,7 @@ BEGIN {
|
||||
# process options
|
||||
Opterr = 1 # default is to diagnose
|
||||
Optind = 1 # skip ARGV[0]
|
||||
while ((_go_c = getopt(ARGC, ARGV, "hi:o:f:m:t:eCOQU?")) != -1) {
|
||||
while ((_go_c = getopt(ARGC, ARGV, "hi:o:f:m:t:eCQU?")) != -1) {
|
||||
if (_go_c == "i") {
|
||||
if (!Optarg) usage()
|
||||
if (in_dir) { print "Option "_go_c" is only allowed once" > "/dev/stderr"}
|
||||
@ -184,12 +180,6 @@ BEGIN {
|
||||
extra_par = extra_par " -e"
|
||||
continue
|
||||
} else
|
||||
if (_go_c == "O") {
|
||||
if (frida_mode) { print "Option "_go_c" is only allowed once" > "/dev/stderr"}
|
||||
extra_par = extra_par " -O"
|
||||
frida_mode = 1
|
||||
continue
|
||||
} else
|
||||
if (_go_c == "Q") {
|
||||
if (qemu_mode) { print "Option "_go_c" is only allowed once" > "/dev/stderr"}
|
||||
extra_par = extra_par " -Q"
|
||||
@ -253,7 +243,7 @@ BEGIN {
|
||||
if (!stdin_file) {
|
||||
found_atat = 0
|
||||
for (prog_args_ind in prog_args) {
|
||||
if (match(prog_args[prog_args_ind], "@@") != 0) {
|
||||
if ("@@" == prog_args[prog_args_ind]) {
|
||||
found_atat = 1
|
||||
break
|
||||
}
|
||||
@ -285,7 +275,7 @@ BEGIN {
|
||||
target_bin = tnew
|
||||
}
|
||||
|
||||
if (!ENVIRON["AFL_SKIP_BIN_CHECK"] && !qemu_mode && !frida_mode && !unicorn_mode) {
|
||||
if (!ENVIRON["AFL_SKIP_BIN_CHECK"] && !qemu_mode && !unicorn_mode) {
|
||||
if (0 != system( "grep -q __AFL_SHM_ID "target_bin )) {
|
||||
print "[-] Error: binary '"target_bin"' doesn't appear to be instrumented." > "/dev/stderr"
|
||||
exit 1
|
||||
@ -297,13 +287,9 @@ BEGIN {
|
||||
exit 1
|
||||
}
|
||||
|
||||
#if (0 == system( "test -d "in_dir"/default" )) {
|
||||
# in_dir = in_dir "/default"
|
||||
#}
|
||||
#
|
||||
#if (0 == system( "test -d "in_dir"/queue" )) {
|
||||
# in_dir = in_dir "/queue"
|
||||
#}
|
||||
if (0 == system( "test -d "in_dir"/queue" )) {
|
||||
in_dir = in_dir "/queue"
|
||||
}
|
||||
|
||||
system("rm -rf "trace_dir" 2>/dev/null");
|
||||
system("rm "out_dir"/id[:_]* 2>/dev/null")
|
||||
@ -356,35 +342,28 @@ BEGIN {
|
||||
} else {
|
||||
stat_format = "-f '%z %N'" # *BSD, MacOS
|
||||
}
|
||||
cmdline = "(cd "in_dir" && find . \\( ! -name \".*\" -a -type d \\) -o -type f -exec stat "stat_format" \\{\\} + | sort -k1n -k2r)"
|
||||
#cmdline = "ls "in_dir" | (cd "in_dir" && xargs stat "stat_format" 2>/dev/null) | sort -k1n -k2r"
|
||||
#cmdline = "(cd "in_dir" && stat "stat_format" *) | sort -k1n -k2r"
|
||||
#cmdline = "(cd "in_dir" && ls | xargs stat "stat_format" ) | sort -k1n -k2r"
|
||||
cmdline = "cd "in_dir" && find . \\( ! -name . -a -type d -prune \\) -o -type f -exec stat "stat_format" \\{\\} \\; | sort -k1n -k2r"
|
||||
cmdline = "ls "in_dir" | (cd "in_dir" && xargs stat "stat_format" 2>/dev/null) | sort -k1n -k2r"
|
||||
while (cmdline | getline) {
|
||||
sub(/^[0-9]+ (\.\/)?/,"",$0)
|
||||
infilesSmallToBigFull[i] = $0
|
||||
sub(/.*\//, "", $0)
|
||||
infilesSmallToBig[i] = $0
|
||||
infilesSmallToBigMap[infilesSmallToBig[i]] = infilesSmallToBigFull[i]
|
||||
infilesSmallToBigFullMap[infilesSmallToBigFull[i]] = infilesSmallToBig[i]
|
||||
i++
|
||||
infilesSmallToBig[i++] = $0
|
||||
}
|
||||
in_count = i
|
||||
|
||||
first_file = infilesSmallToBigFull[0]
|
||||
first_file = infilesSmallToBig[0]
|
||||
|
||||
#if (0 == system("test -d ""\""in_dir"/"first_file"\"")) {
|
||||
# print "[-] Error: The input directory is empty or contains subdirectories - please fix." > "/dev/stderr"
|
||||
# exit 1
|
||||
#}
|
||||
# Make sure that we're not dealing with a directory.
|
||||
|
||||
system(">\""in_dir"/.afl-cmin.test\"")
|
||||
if (0 == system("ln \""in_dir"/.afl-cmin.test\" "trace_dir"/.link_test")) {
|
||||
if (0 == system("test -d "in_dir"/"first_file)) {
|
||||
print "[-] Error: The input directory is empty or contains subdirectories - please fix." > "/dev/stderr"
|
||||
exit 1
|
||||
}
|
||||
|
||||
if (0 == system("ln "in_dir"/"first_file" "trace_dir"/.link_test")) {
|
||||
cp_tool = "ln"
|
||||
} else {
|
||||
cp_tool = "cp"
|
||||
}
|
||||
system("rm -f \""in_dir"/.afl-cmin.test\"")
|
||||
|
||||
if (!ENVIRON["AFL_SKIP_BIN_CHECK"]) {
|
||||
# Make sure that we can actually get anything out of afl-showmap before we
|
||||
@ -395,7 +374,7 @@ BEGIN {
|
||||
if (!stdin_file) {
|
||||
system( "AFL_CMIN_ALLOW_ANY=1 "AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"/.run_test\" -Z "extra_par" -- \""target_bin"\" "prog_args_string" <\""in_dir"/"first_file"\"")
|
||||
} else {
|
||||
system("cp \""in_dir"/"first_file"\" "stdin_file)
|
||||
system("cp "in_dir"/"first_file" "stdin_file)
|
||||
system( "AFL_CMIN_ALLOW_ANY=1 "AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"/.run_test\" -Z "extra_par" -A \""stdin_file"\" -- \""target_bin"\" "prog_args_string" </dev/null")
|
||||
}
|
||||
|
||||
@ -432,8 +411,8 @@ BEGIN {
|
||||
retval = system( AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -- \""target_bin"\" "prog_args_string)
|
||||
} else {
|
||||
print " Processing "in_count" files (forkserver mode)..."
|
||||
# print AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -A \""stdin_file"\" -- \""target_bin"\" "prog_args_string" </dev/null"
|
||||
retval = system( AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -A \""stdin_file"\" -- \""target_bin"\" "prog_args_string" </dev/null")
|
||||
# print AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -- \""target_bin"\" "prog_args_string" </dev/null"
|
||||
retval = system( AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -- \""target_bin"\" "prog_args_string" </dev/null")
|
||||
}
|
||||
|
||||
if (retval && !AFL_CMIN_CRASHES_ONLY) {
|
||||
@ -517,8 +496,7 @@ BEGIN {
|
||||
|
||||
# copy file unless already done
|
||||
if (! (fn in file_already_copied)) {
|
||||
realfile = infilesSmallToBigMap[fn]
|
||||
system(cp_tool" \""in_dir"/"realfile"\" \""out_dir"/"fn"\"")
|
||||
system(cp_tool" "in_dir"/"fn" "out_dir"/"fn)
|
||||
file_already_copied[fn] = ""
|
||||
++out_count
|
||||
#printf "tuple nr %d (%d cnt=%d) -> %s\n",tcnt,key,key_count[key],fn > trace_dir"/.log"
|
||||
|
||||
@ -53,7 +53,7 @@ unset IN_DIR OUT_DIR STDIN_FILE EXTRA_PAR MEM_LIMIT_GIVEN \
|
||||
|
||||
export AFL_QUIET=1
|
||||
|
||||
while getopts "+i:o:f:m:t:eOQUCh" opt; do
|
||||
while getopts "+i:o:f:m:t:eQUCh" opt; do
|
||||
|
||||
case "$opt" in
|
||||
|
||||
@ -83,10 +83,6 @@ while getopts "+i:o:f:m:t:eOQUCh" opt; do
|
||||
"C")
|
||||
export AFL_CMIN_CRASHES_ONLY=1
|
||||
;;
|
||||
"O")
|
||||
EXTRA_PAR="$EXTRA_PAR -O"
|
||||
FRIDA_MODE=1
|
||||
;;
|
||||
"Q")
|
||||
EXTRA_PAR="$EXTRA_PAR -Q"
|
||||
QEMU_MODE=1
|
||||
@ -122,7 +118,6 @@ Execution control settings:
|
||||
-f file - location read by the fuzzed program (stdin)
|
||||
-m megs - memory limit for child process ($MEM_LIMIT MB)
|
||||
-t msec - run time limit for child process (none)
|
||||
-O - use binary-only instrumentation (FRIDA mode)
|
||||
-Q - use binary-only instrumentation (QEMU mode)
|
||||
-U - use unicorn-based instrumentation (Unicorn mode)
|
||||
|
||||
@ -135,7 +130,6 @@ For additional tips, please consult README.md.
|
||||
|
||||
Environment variables used:
|
||||
AFL_KEEP_TRACES: leave the temporary <out_dir>\.traces directory
|
||||
AFL_NO_FORKSRV: run target via execve instead of using the forkserver
|
||||
AFL_PATH: last resort location to find the afl-showmap binary
|
||||
AFL_SKIP_BIN_CHECK: skip check for target binary
|
||||
_EOF_
|
||||
@ -215,7 +209,7 @@ if [ ! -f "$TARGET_BIN" -o ! -x "$TARGET_BIN" ]; then
|
||||
|
||||
fi
|
||||
|
||||
if [ "$AFL_SKIP_BIN_CHECK" = "" -a "$QEMU_MODE" = "" -a "$FRIDA_MODE" = "" -a "$UNICORN_MODE" = "" ]; then
|
||||
if [ "$AFL_SKIP_BIN_CHECK" = "" -a "$QEMU_MODE" = "" -a "$UNICORN_MODE" = "" ]; then
|
||||
|
||||
if ! grep -qF "__AFL_SHM_ID" "$TARGET_BIN"; then
|
||||
echo "[-] Error: binary '$TARGET_BIN' doesn't appear to be instrumented." 1>&2
|
||||
@ -229,7 +223,6 @@ if [ ! -d "$IN_DIR" ]; then
|
||||
exit 1
|
||||
fi
|
||||
|
||||
test -d "$IN_DIR/default" && IN_DIR="$IN_DIR/default"
|
||||
test -d "$IN_DIR/queue" && IN_DIR="$IN_DIR/queue"
|
||||
|
||||
find "$OUT_DIR" -name 'id[:_]*' -maxdepth 1 -exec rm -- {} \; 2>/dev/null
|
||||
|
||||
21
afl-plot
21
afl-plot
@ -99,7 +99,7 @@ if [ ! -d "$outputdir" ]; then
|
||||
|
||||
fi
|
||||
|
||||
rm -f "$outputdir/high_freq.png" "$outputdir/low_freq.png" "$outputdir/exec_speed.png" "$outputdir/edges.png"
|
||||
rm -f "$outputdir/high_freq.png" "$outputdir/low_freq.png" "$outputdir/exec_speed.png"
|
||||
mv -f "$outputdir/index.html" "$outputdir/index.html.orig" 2>/dev/null
|
||||
|
||||
echo "[*] Generating plots..."
|
||||
@ -111,9 +111,9 @@ set terminal png truecolor enhanced size 1000,300 butt
|
||||
|
||||
set output '$outputdir/high_freq.png'
|
||||
|
||||
#set xdata time
|
||||
#set timefmt '%s'
|
||||
#set format x "%b %d\n%H:%M"
|
||||
set xdata time
|
||||
set timefmt '%s'
|
||||
set format x "%b %d\n%H:%M"
|
||||
set tics font 'small'
|
||||
unset mxtics
|
||||
unset mytics
|
||||
@ -127,8 +127,9 @@ set key outside
|
||||
set autoscale xfixmin
|
||||
set autoscale xfixmax
|
||||
|
||||
set xlabel "relative time in seconds" font "small"
|
||||
set xlabel "all times in UTC" font "small"
|
||||
|
||||
set ytics auto
|
||||
plot '$inputdir/plot_data' using 1:4 with filledcurve x1 title 'total paths' linecolor rgb '#000000' fillstyle transparent solid 0.2 noborder, \\
|
||||
'' using 1:3 with filledcurve x1 title 'current path' linecolor rgb '#f0f0f0' fillstyle transparent solid 0.5 noborder, \\
|
||||
'' using 1:5 with lines title 'pending paths' linecolor rgb '#0090ff' linewidth 3, \\
|
||||
@ -138,6 +139,7 @@ plot '$inputdir/plot_data' using 1:4 with filledcurve x1 title 'total paths' lin
|
||||
set terminal png truecolor enhanced size 1000,200 butt
|
||||
set output '$outputdir/low_freq.png'
|
||||
|
||||
set ytics 1
|
||||
plot '$inputdir/plot_data' using 1:8 with filledcurve x1 title '' linecolor rgb '#c00080' fillstyle transparent solid 0.2 noborder, \\
|
||||
'' using 1:8 with lines title ' uniq crashes' linecolor rgb '#c00080' linewidth 3, \\
|
||||
'' using 1:9 with lines title 'uniq hangs' linecolor rgb '#c000f0' linewidth 3, \\
|
||||
@ -146,14 +148,10 @@ plot '$inputdir/plot_data' using 1:8 with filledcurve x1 title '' linecolor rgb
|
||||
set terminal png truecolor enhanced size 1000,200 butt
|
||||
set output '$outputdir/exec_speed.png'
|
||||
|
||||
set ytics auto
|
||||
plot '$inputdir/plot_data' using 1:11 with filledcurve x1 title '' linecolor rgb '#0090ff' fillstyle transparent solid 0.2 noborder, \\
|
||||
'$inputdir/plot_data' using 1:11 with lines title ' execs/sec' linecolor rgb '#0090ff' linewidth 3 smooth bezier;
|
||||
|
||||
set terminal png truecolor enhanced size 1000,300 butt
|
||||
set output '$outputdir/edges.png'
|
||||
|
||||
plot '$inputdir/plot_data' using 1:13 with lines title ' edges' linecolor rgb '#0090ff' linewidth 3
|
||||
|
||||
_EOF_
|
||||
|
||||
) | gnuplot
|
||||
@ -174,7 +172,6 @@ cat >"$outputdir/index.html" <<_EOF_
|
||||
<tr><td><b>Generated on:</b></td><td>`date`</td></tr>
|
||||
</table>
|
||||
<p>
|
||||
<img src="edges.png" width=1000 height=300>
|
||||
<img src="high_freq.png" width=1000 height=300><p>
|
||||
<img src="low_freq.png" width=1000 height=200><p>
|
||||
<img src="exec_speed.png" width=1000 height=200>
|
||||
@ -186,7 +183,7 @@ _EOF_
|
||||
# sensitive, this seems like a reasonable trade-off.
|
||||
|
||||
chmod 755 "$outputdir"
|
||||
chmod 644 "$outputdir/high_freq.png" "$outputdir/low_freq.png" "$outputdir/exec_speed.png" "$outputdir/edges.png" "$outputdir/index.html"
|
||||
chmod 644 "$outputdir/high_freq.png" "$outputdir/low_freq.png" "$outputdir/exec_speed.png" "$outputdir/index.html"
|
||||
|
||||
echo "[+] All done - enjoy your charts!"
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@ test "$1" = "-h" -o "$1" = "-hh" && {
|
||||
echo afl-system-config has no command line options
|
||||
echo
|
||||
echo afl-system reconfigures the system to a high performance fuzzing state
|
||||
echo "WARNING: this reduces the security of the system!"
|
||||
echo WARNING: this reduces the security of the system
|
||||
echo
|
||||
exit 1
|
||||
}
|
||||
@ -15,20 +15,14 @@ test "$1" = "-h" -o "$1" = "-hh" && {
|
||||
DONE=
|
||||
PLATFORM=`uname -s`
|
||||
echo This reconfigures the system to have a better fuzzing performance.
|
||||
echo "WARNING: this reduces the security of the system!"
|
||||
echo
|
||||
if [ '!' "$EUID" = 0 ] && [ '!' `id -u` = 0 ] ; then
|
||||
echo "Warning: you need to be root to run this!"
|
||||
# we do not exit as other mechanisms exist that allows to do this than
|
||||
# being root. let the errors speak for themselves.
|
||||
fi
|
||||
sleep 1
|
||||
if [ "$PLATFORM" = "Linux" ] ; then
|
||||
{
|
||||
sysctl -w kernel.core_uses_pid=0
|
||||
# Arch Linux requires core_pattern to be empty :(
|
||||
test -e /etc/arch-release && sysctl -w kernel.core_pattern=
|
||||
test -e /etc/arch-release || sysctl -w kernel.core_pattern=core
|
||||
sysctl -w kernel.core_pattern=core
|
||||
sysctl -w kernel.randomize_va_space=0
|
||||
sysctl -w kernel.sched_child_runs_first=1
|
||||
sysctl -w kernel.sched_autogroup_enabled=1
|
||||
@ -41,17 +35,12 @@ if [ "$PLATFORM" = "Linux" ] ; then
|
||||
test -e /sys/devices/system/cpu/intel_pstate/no_turbo && echo 0 > /sys/devices/system/cpu/intel_pstate/no_turbo
|
||||
test -e /sys/devices/system/cpu/cpufreq/boost && echo 1 > /sys/devices/system/cpu/cpufreq/boost
|
||||
test -e /sys/devices/system/cpu/intel_pstate/max_perf_pct && echo 100 > /sys/devices/system/cpu/intel_pstate/max_perf_pct
|
||||
test -n "$(which auditctl)" && auditctl -a never,task >/dev/null 2>&1
|
||||
} > /dev/null
|
||||
echo Settings applied.
|
||||
echo
|
||||
dmesg | egrep -q 'nospectre_v2|spectre_v2=off' || {
|
||||
echo It is recommended to boot the kernel with lots of security off - if you are running a machine that is in a secured network - so set this:
|
||||
echo ' /etc/default/grub:GRUB_CMDLINE_LINUX_DEFAULT="ibpb=off ibrs=off kpti=0 l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off srbds=off noexec=off noexec32=off tsx=on tsx_async_abort=off arm64.nopauth audit=0 hardened_usercopy=off ssbd=force-off"'
|
||||
echo
|
||||
echo ' /etc/default/grub:GRUB_CMDLINE_LINUX_DEFAULT="ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off"'
|
||||
}
|
||||
echo If you run fuzzing instances in docker, run them with \"--security-opt seccomp=unconfined\" for more speed
|
||||
echo
|
||||
DONE=1
|
||||
fi
|
||||
if [ "$PLATFORM" = "FreeBSD" ] ; then
|
||||
@ -60,70 +49,48 @@ if [ "$PLATFORM" = "FreeBSD" ] ; then
|
||||
sysctl kern.elf64.aslr.enable=0
|
||||
} > /dev/null
|
||||
echo Settings applied.
|
||||
echo
|
||||
cat <<EOF
|
||||
In order to suppress core file generation during fuzzing it is recommended to set
|
||||
me:\\
|
||||
:coredumpsize=0:
|
||||
in the ~/.login_conf file for the user used for fuzzing.
|
||||
EOF
|
||||
echo It is recommended to boot the kernel with lots of security off - if you are running a machine that is in a secured network - so set this:
|
||||
echo ' sysctl hw.ibrs_disable=1'
|
||||
echo 'Setting kern.pmap.pg_ps_enabled=0 into /boot/loader.conf might be helpful too.'
|
||||
echo
|
||||
DONE=1
|
||||
fi
|
||||
if [ "$PLATFORM" = "OpenBSD" ] ; then
|
||||
echo 'System security features cannot be disabled on OpenBSD.'
|
||||
echo
|
||||
echo 'System security features cannot be disabled on OpenBSD.'
|
||||
DONE=1
|
||||
fi
|
||||
if [ "$PLATFORM" = "DragonFly" ] ; then
|
||||
#/sbin/sysctl kern.corefile=/dev/null
|
||||
#echo Settings applied.
|
||||
cat <<EOF
|
||||
In order to suppress core file generation during fuzzing it is recommended to set
|
||||
me:\\
|
||||
:coredumpsize=0:
|
||||
in the ~/.login_conf file for the user used for fuzzing.
|
||||
EOF
|
||||
echo
|
||||
echo 'System security features cannot be disabled on DragonFly.'
|
||||
DONE=1
|
||||
fi
|
||||
if [ "$PLATFORM" = "NetBSD" ] ; then
|
||||
{
|
||||
#echo It is recommended to enable unprivileged users to set cpu affinity
|
||||
#echo to be able to use afl-gotcpu meaningfully.
|
||||
/sbin/sysctl -w security.models.extensions.user_set_cpu_affinity=1
|
||||
} > /dev/null
|
||||
echo Settings applied.
|
||||
echo
|
||||
DONE=1
|
||||
fi
|
||||
if [ "$PLATFORM" = "Darwin" ] ; then
|
||||
sysctl kern.sysv.shmmax=8388608
|
||||
sysctl kern.sysv.shmseg=48
|
||||
sysctl kern.sysv.shmall=98304
|
||||
echo Settings applied.
|
||||
echo
|
||||
if [ $(launchctl list 2>/dev/null | grep -q '\.ReportCrash$') ] ; then
|
||||
echo
|
||||
echo Unloading the default crash reporter
|
||||
echo We unload the default crash reporter here
|
||||
SL=/System/Library; PL=com.apple.ReportCrash
|
||||
launchctl unload -w ${SL}/LaunchAgents/${PL}.plist >/dev/null 2>&1
|
||||
sudo launchctl unload -w ${SL}/LaunchDaemons/${PL}.Root.plist >/dev/null 2>&1
|
||||
echo
|
||||
launchctl unload -w ${SL}/LaunchAgents/${PL}.plist
|
||||
sudo launchctl unload -w ${SL}/LaunchDaemons/${PL}.Root.plist
|
||||
echo Settings applied.
|
||||
else
|
||||
echo Nothing to do.
|
||||
fi
|
||||
echo It is recommended to disable System Integration Protection for increased performance.
|
||||
echo
|
||||
DONE=1
|
||||
fi
|
||||
if [ "$PLATFORM" = "Haiku" ] ; then
|
||||
DEBUG_SERVER_DIR=~/config/settings/system/debug_server
|
||||
[ ! -d ${DEBUG_SERVER_DIR} ] && mkdir -p ${DEBUG_SERVER_DIR}
|
||||
SETTINGS=${DEBUG_SERVER_DIR}/settings
|
||||
SETTINGS=~/config/settings/system/debug_server/settings
|
||||
[ -r ${SETTINGS} ] && grep -qE "default_action\s+kill" ${SETTINGS} && { echo "Nothing to do"; } || { \
|
||||
echo We change the debug_server default_action from user to silently kill; \
|
||||
echo We change the debug_server default_action from user to silenty kill; \
|
||||
[ ! -r ${SETTINGS} ] && echo "default_action kill" >${SETTINGS} || { mv ${SETTINGS} s.tmp; sed -e "s/default_action\s\s*user/default_action kill/" s.tmp > ${SETTINGS}; rm s.tmp; }; \
|
||||
echo Settings applied.; echo; \
|
||||
echo Settings applied.; \
|
||||
}
|
||||
DONE=1
|
||||
fi
|
||||
|
||||
56
afl-whatsup
56
afl-whatsup
@ -21,41 +21,32 @@
|
||||
echo "$0 status check tool for afl-fuzz by Michal Zalewski"
|
||||
echo
|
||||
test "$1" = "-h" -o "$1" = "-hh" && {
|
||||
echo "Usage: $0 [-s] [-d] afl_output_directory"
|
||||
echo $0 [-s] output_directory
|
||||
echo
|
||||
echo Options:
|
||||
echo " -s - skip details and output summary results only"
|
||||
echo " -d - include dead fuzzer stats"
|
||||
echo -s - skip details and output summary results only
|
||||
echo
|
||||
exit 1
|
||||
}
|
||||
|
||||
unset SUMMARY_ONLY
|
||||
unset PROCESS_DEAD
|
||||
if [ "$1" = "-s" ]; then
|
||||
|
||||
while [ "$1" = "-s" -o "$1" = "-d" ]; do
|
||||
SUMMARY_ONLY=1
|
||||
DIR="$2"
|
||||
|
||||
if [ "$1" = "-s" ]; then
|
||||
SUMMARY_ONLY=1
|
||||
fi
|
||||
else
|
||||
|
||||
if [ "$1" = "-d" ]; then
|
||||
PROCESS_DEAD=1
|
||||
fi
|
||||
|
||||
shift
|
||||
unset SUMMARY_ONLY
|
||||
DIR="$1"
|
||||
|
||||
done
|
||||
|
||||
DIR="$1"
|
||||
fi
|
||||
|
||||
if [ "$DIR" = "" ]; then
|
||||
|
||||
echo "Usage: $0 [-s] [-d] afl_output_directory" 1>&2
|
||||
echo "Usage: $0 [ -s ] afl_sync_dir" 1>&2
|
||||
echo 1>&2
|
||||
echo Options: 1>&2
|
||||
echo " -s - skip details and output summary results only" 1>&2
|
||||
echo " -d - include dead fuzzer stats" 1>&2
|
||||
echo "The -s option causes the tool to skip all the per-fuzzer trivia and show" 1>&2
|
||||
echo "just the summary results. See docs/parallel_fuzzing.md for additional tips." 1>&2
|
||||
echo 1>&2
|
||||
exit 1
|
||||
|
||||
@ -142,7 +133,7 @@ for i in `find . -maxdepth 2 -iname fuzzer_stats | sort`; do
|
||||
sed 's/^command_line.*$/_skip:1/;s/[ ]*:[ ]*/="/;s/$/"/' "$i" >"$TMP"
|
||||
. "$TMP"
|
||||
|
||||
RUN_UNIX=$run_time
|
||||
RUN_UNIX=$((CUR_TIME - start_time))
|
||||
RUN_DAYS=$((RUN_UNIX / 60 / 60 / 24))
|
||||
RUN_HRS=$(((RUN_UNIX / 60 / 60) % 24))
|
||||
|
||||
@ -169,13 +160,7 @@ for i in `find . -maxdepth 2 -iname fuzzer_stats | sort`; do
|
||||
fi
|
||||
|
||||
DEAD_CNT=$((DEAD_CNT + 1))
|
||||
last_path=0
|
||||
|
||||
if [ "$PROCESS_DEAD" = "" ]; then
|
||||
|
||||
continue
|
||||
|
||||
fi
|
||||
continue
|
||||
|
||||
fi
|
||||
|
||||
@ -267,24 +252,13 @@ fmt_duration $TOTAL_LAST_PATH && TOTAL_LAST_PATH=$DUR_STRING
|
||||
|
||||
test "$TOTAL_TIME" = "0" && TOTAL_TIME=1
|
||||
|
||||
if [ "$PROCESS_DEAD" = "" ]; then
|
||||
|
||||
TXT="excluded from stats"
|
||||
|
||||
else
|
||||
|
||||
TXT="included in stats"
|
||||
ALIVE_CNT=$(($ALIVE_CNT - $DEAD_CNT))
|
||||
|
||||
fi
|
||||
|
||||
echo "Summary stats"
|
||||
echo "============="
|
||||
echo
|
||||
echo " Fuzzers alive : $ALIVE_CNT"
|
||||
|
||||
if [ ! "$DEAD_CNT" = "0" ]; then
|
||||
echo " Dead or remote : $DEAD_CNT ($TXT)"
|
||||
echo " Dead or remote : $DEAD_CNT (excluded from stats)"
|
||||
fi
|
||||
|
||||
echo " Total run time : $FMT_TIME"
|
||||
|
||||
@ -10,8 +10,6 @@ cc_library_shared {
|
||||
"-fPIC",
|
||||
"-fpermissive",
|
||||
"-std=c++11",
|
||||
"-Wno-unused-parameter",
|
||||
"-Wno-unused-variable",
|
||||
],
|
||||
|
||||
srcs: [
|
||||
@ -79,8 +77,6 @@ cc_library_shared {
|
||||
"-O0",
|
||||
"-funroll-loops",
|
||||
"-fPIC",
|
||||
"-Wno-unused-parameter",
|
||||
"-Wno-unused-function",
|
||||
],
|
||||
|
||||
srcs: [
|
||||
@ -103,8 +99,6 @@ cc_library_shared {
|
||||
"-O0",
|
||||
"-funroll-loops",
|
||||
"-fPIC",
|
||||
"-Wno-unused-parameter",
|
||||
"-Wno-pointer-sign",
|
||||
],
|
||||
|
||||
srcs: [
|
||||
|
||||
@ -3,14 +3,6 @@
|
||||
Custom mutators enhance and alter the mutation strategies of afl++.
|
||||
For further information and documentation on how to write your own, read [the docs](../docs/custom_mutators.md).
|
||||
|
||||
## Examples
|
||||
|
||||
The `./examples` folder contains examples for custom mutators in python and C.
|
||||
|
||||
## Rust
|
||||
|
||||
In `./rust`, you will find rust bindings, including a simple example in `./rust/example` and an example for structured fuzzing, based on lain, in`./rust/example_lain`.
|
||||
|
||||
## The afl++ Grammar Mutator
|
||||
|
||||
If you use git to clone afl++, then the following will incorporate our
|
||||
@ -54,6 +46,3 @@ https://github.com/bruce30262/libprotobuf-mutator_fuzzing_learning/tree/master/4
|
||||
has a transform function you need to fill for your protobuf format, however
|
||||
needs to be ported to the updated afl++ custom mutator API (not much work):
|
||||
https://github.com/thebabush/afl-libprotobuf-mutator
|
||||
|
||||
same as above but is for current afl++:
|
||||
https://github.com/P1umer/AFLplusplus-protobuf-mutator
|
||||
|
||||
@ -1 +1 @@
|
||||
b79d51a
|
||||
b3c4fcf
|
||||
|
||||
@ -106,23 +106,23 @@ git status 1>/dev/null 2>/dev/null
|
||||
if [ $? -eq 0 ]; then
|
||||
echo "[*] initializing grammar mutator submodule"
|
||||
git submodule init || exit 1
|
||||
git submodule update ./grammar_mutator 2>/dev/null # ignore errors
|
||||
git submodule update ./grammar-mutator 2>/dev/null # ignore errors
|
||||
else
|
||||
echo "[*] cloning grammar mutator"
|
||||
test -d grammar_mutator || {
|
||||
test -d grammar-mutator || {
|
||||
CNT=1
|
||||
while [ '!' -d grammar_mutator -a "$CNT" -lt 4 ]; do
|
||||
echo "Trying to clone grammar_mutator (attempt $CNT/3)"
|
||||
while [ '!' -d grammar-mutator -a "$CNT" -lt 4 ]; do
|
||||
echo "Trying to clone grammar-mutator (attempt $CNT/3)"
|
||||
git clone "$GRAMMAR_REPO"
|
||||
CNT=`expr "$CNT" + 1`
|
||||
done
|
||||
}
|
||||
fi
|
||||
|
||||
test -d grammar_mutator || { echo "[-] not checked out, please install git or check your internet connection." ; exit 1 ; }
|
||||
test -d grammar-mutator || { echo "[-] not checked out, please install git or check your internet connection." ; exit 1 ; }
|
||||
echo "[+] Got grammar mutator."
|
||||
|
||||
cd "grammar_mutator" || exit 1
|
||||
cd "grammar-mutator" || exit 1
|
||||
echo "[*] Checking out $GRAMMAR_VERSION"
|
||||
sh -c 'git stash && git stash drop' 1>/dev/null 2>/dev/null
|
||||
git checkout "$GRAMMAR_VERSION" || exit 1
|
||||
@ -134,7 +134,7 @@ echo
|
||||
echo
|
||||
echo "[+] All successfully prepared!"
|
||||
echo "[!] To build for your grammar just do:"
|
||||
echo " cd grammar_mutator"
|
||||
echo " cd grammar-mutator"
|
||||
echo " make GRAMMAR_FILE=/path/to/your/grammar"
|
||||
echo "[+] You will find a JSON and RUBY grammar in grammar_mutator/grammars to play with."
|
||||
echo "[+] You will find a JSON and RUBY grammar in grammar-mutator/grammars to play with."
|
||||
echo
|
||||
|
||||
Submodule custom_mutators/grammar_mutator/grammar_mutator updated: b79d51a8da...b3c4fcfa6a
0
custom_mutators/honggfuzz/common.h
Normal file
0
custom_mutators/honggfuzz/common.h
Normal file
@ -39,7 +39,7 @@
|
||||
#include "libhfcommon/util.h"
|
||||
|
||||
#define PROG_NAME "honggfuzz"
|
||||
#define PROG_VERSION "2.4"
|
||||
#define PROG_VERSION "2.3"
|
||||
|
||||
/* Name of the template which will be replaced with the proper name of the file */
|
||||
#define _HF_FILE_PLACEHOLDER "___FILE___"
|
||||
@ -208,7 +208,6 @@ typedef struct {
|
||||
const char* crashDir;
|
||||
const char* covDirNew;
|
||||
bool saveUnique;
|
||||
bool saveSmaller;
|
||||
size_t dynfileqMaxSz;
|
||||
size_t dynfileqCnt;
|
||||
dynfile_t* dynfileqCurrent;
|
||||
@ -246,9 +245,9 @@ typedef struct {
|
||||
} timing;
|
||||
struct {
|
||||
struct {
|
||||
uint8_t val[512];
|
||||
uint8_t val[256];
|
||||
size_t len;
|
||||
} dictionary[8192];
|
||||
} dictionary[1024];
|
||||
size_t dictionaryCnt;
|
||||
const char* dictionaryFile;
|
||||
size_t mutationsMax;
|
||||
@ -263,7 +262,6 @@ typedef struct {
|
||||
struct {
|
||||
bool useVerifier;
|
||||
bool exitUponCrash;
|
||||
uint8_t exitCodeUponCrash;
|
||||
const char* reportFile;
|
||||
size_t dynFileIterExpire;
|
||||
bool only_printable;
|
||||
@ -281,9 +279,9 @@ typedef struct {
|
||||
cmpfeedback_t* cmpFeedbackMap;
|
||||
int cmpFeedbackFd;
|
||||
bool cmpFeedback;
|
||||
const char* blocklistFile;
|
||||
uint64_t* blocklist;
|
||||
size_t blocklistCnt;
|
||||
const char* blacklistFile;
|
||||
uint64_t* blacklist;
|
||||
size_t blacklistCnt;
|
||||
bool skipFeedbackOnTimeout;
|
||||
uint64_t maxCov[4];
|
||||
dynFileMethod_t dynFileMethod;
|
||||
|
||||
@ -77,11 +77,11 @@ static inline uint64_t util_rndGet(uint64_t min, uint64_t max) {
|
||||
}
|
||||
static inline uint64_t util_rnd64() { return rand_below(afl_struct, 1 << 30); }
|
||||
|
||||
static inline const uint8_t* input_getRandomInputAsBuf(run_t* run, size_t* len) {
|
||||
*len = queue_input_size;
|
||||
static inline size_t input_getRandomInputAsBuf(run_t *run, const uint8_t **buf) {
|
||||
*buf = queue_input;
|
||||
run->dynfile->data = queue_input;
|
||||
run->dynfile->size = queue_input_size;
|
||||
return queue_input;
|
||||
return queue_input_size;
|
||||
}
|
||||
static inline void input_setSize(run_t* run, size_t sz) {
|
||||
run->dynfile->size = sz;
|
||||
|
||||
1
custom_mutators/honggfuzz/libhfcommon
Symbolic link
1
custom_mutators/honggfuzz/libhfcommon
Symbolic link
@ -0,0 +1 @@
|
||||
.
|
||||
@ -1,3 +0,0 @@
|
||||
#ifndef LOG_E
|
||||
#define LOG_E LOG_F
|
||||
#endif
|
||||
File diff suppressed because it is too large
Load Diff
@ -8,7 +8,6 @@ cc_library_shared {
|
||||
"-O0",
|
||||
"-fPIC",
|
||||
"-Wall",
|
||||
"-Wno-unused-parameter",
|
||||
],
|
||||
|
||||
srcs: [
|
||||
@ -30,9 +29,4 @@ cc_binary {
|
||||
srcs: [
|
||||
"vuln.c",
|
||||
],
|
||||
|
||||
cflags: [
|
||||
"-Wno-unused-result",
|
||||
"-Wno-unused-parameter",
|
||||
],
|
||||
}
|
||||
|
||||
@ -1 +0,0 @@
|
||||
../examples/custom_mutator_helpers.h
|
||||
342
custom_mutators/radamsa/custom_mutator_helpers.h
Normal file
342
custom_mutators/radamsa/custom_mutator_helpers.h
Normal file
@ -0,0 +1,342 @@
|
||||
#ifndef CUSTOM_MUTATOR_HELPERS
|
||||
#define CUSTOM_MUTATOR_HELPERS
|
||||
|
||||
#include "config.h"
|
||||
#include "types.h"
|
||||
#include <stdlib.h>
|
||||
|
||||
#define INITIAL_GROWTH_SIZE (64)
|
||||
|
||||
#define RAND_BELOW(limit) (rand() % (limit))
|
||||
|
||||
/* Use in a struct: creates a name_buf and a name_size variable. */
|
||||
#define BUF_VAR(type, name) \
|
||||
type * name##_buf; \
|
||||
size_t name##_size;
|
||||
/* this filles in `&structptr->something_buf, &structptr->something_size`. */
|
||||
#define BUF_PARAMS(struct, name) \
|
||||
(void **)&struct->name##_buf, &struct->name##_size
|
||||
|
||||
typedef struct {
|
||||
|
||||
} afl_t;
|
||||
|
||||
static void surgical_havoc_mutate(u8 *out_buf, s32 begin, s32 end) {
|
||||
|
||||
static s8 interesting_8[] = {INTERESTING_8};
|
||||
static s16 interesting_16[] = {INTERESTING_8, INTERESTING_16};
|
||||
static s32 interesting_32[] = {INTERESTING_8, INTERESTING_16, INTERESTING_32};
|
||||
|
||||
switch (RAND_BELOW(12)) {
|
||||
|
||||
case 0: {
|
||||
|
||||
/* Flip a single bit somewhere. Spooky! */
|
||||
|
||||
s32 bit_idx = ((RAND_BELOW(end - begin) + begin) << 3) + RAND_BELOW(8);
|
||||
|
||||
out_buf[bit_idx >> 3] ^= 128 >> (bit_idx & 7);
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 1: {
|
||||
|
||||
/* Set byte to interesting value. */
|
||||
|
||||
u8 val = interesting_8[RAND_BELOW(sizeof(interesting_8))];
|
||||
out_buf[(RAND_BELOW(end - begin) + begin)] = val;
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 2: {
|
||||
|
||||
/* Set word to interesting value, randomly choosing endian. */
|
||||
|
||||
if (end - begin < 2) break;
|
||||
|
||||
s32 byte_idx = (RAND_BELOW(end - begin) + begin);
|
||||
|
||||
if (byte_idx >= end - 1) break;
|
||||
|
||||
switch (RAND_BELOW(2)) {
|
||||
|
||||
case 0:
|
||||
*(u16 *)(out_buf + byte_idx) =
|
||||
interesting_16[RAND_BELOW(sizeof(interesting_16) >> 1)];
|
||||
break;
|
||||
case 1:
|
||||
*(u16 *)(out_buf + byte_idx) =
|
||||
SWAP16(interesting_16[RAND_BELOW(sizeof(interesting_16) >> 1)]);
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 3: {
|
||||
|
||||
/* Set dword to interesting value, randomly choosing endian. */
|
||||
|
||||
if (end - begin < 4) break;
|
||||
|
||||
s32 byte_idx = (RAND_BELOW(end - begin) + begin);
|
||||
|
||||
if (byte_idx >= end - 3) break;
|
||||
|
||||
switch (RAND_BELOW(2)) {
|
||||
|
||||
case 0:
|
||||
*(u32 *)(out_buf + byte_idx) =
|
||||
interesting_32[RAND_BELOW(sizeof(interesting_32) >> 2)];
|
||||
break;
|
||||
case 1:
|
||||
*(u32 *)(out_buf + byte_idx) =
|
||||
SWAP32(interesting_32[RAND_BELOW(sizeof(interesting_32) >> 2)]);
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 4: {
|
||||
|
||||
/* Set qword to interesting value, randomly choosing endian. */
|
||||
|
||||
if (end - begin < 8) break;
|
||||
|
||||
s32 byte_idx = (RAND_BELOW(end - begin) + begin);
|
||||
|
||||
if (byte_idx >= end - 7) break;
|
||||
|
||||
switch (RAND_BELOW(2)) {
|
||||
|
||||
case 0:
|
||||
*(u64 *)(out_buf + byte_idx) =
|
||||
(s64)interesting_32[RAND_BELOW(sizeof(interesting_32) >> 2)];
|
||||
break;
|
||||
case 1:
|
||||
*(u64 *)(out_buf + byte_idx) = SWAP64(
|
||||
(s64)interesting_32[RAND_BELOW(sizeof(interesting_32) >> 2)]);
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 5: {
|
||||
|
||||
/* Randomly subtract from byte. */
|
||||
|
||||
out_buf[(RAND_BELOW(end - begin) + begin)] -= 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 6: {
|
||||
|
||||
/* Randomly add to byte. */
|
||||
|
||||
out_buf[(RAND_BELOW(end - begin) + begin)] += 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 7: {
|
||||
|
||||
/* Randomly subtract from word, random endian. */
|
||||
|
||||
if (end - begin < 2) break;
|
||||
|
||||
s32 byte_idx = (RAND_BELOW(end - begin) + begin);
|
||||
|
||||
if (byte_idx >= end - 1) break;
|
||||
|
||||
if (RAND_BELOW(2)) {
|
||||
|
||||
*(u16 *)(out_buf + byte_idx) -= 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
} else {
|
||||
|
||||
u16 num = 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
*(u16 *)(out_buf + byte_idx) =
|
||||
SWAP16(SWAP16(*(u16 *)(out_buf + byte_idx)) - num);
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 8: {
|
||||
|
||||
/* Randomly add to word, random endian. */
|
||||
|
||||
if (end - begin < 2) break;
|
||||
|
||||
s32 byte_idx = (RAND_BELOW(end - begin) + begin);
|
||||
|
||||
if (byte_idx >= end - 1) break;
|
||||
|
||||
if (RAND_BELOW(2)) {
|
||||
|
||||
*(u16 *)(out_buf + byte_idx) += 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
} else {
|
||||
|
||||
u16 num = 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
*(u16 *)(out_buf + byte_idx) =
|
||||
SWAP16(SWAP16(*(u16 *)(out_buf + byte_idx)) + num);
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 9: {
|
||||
|
||||
/* Randomly subtract from dword, random endian. */
|
||||
|
||||
if (end - begin < 4) break;
|
||||
|
||||
s32 byte_idx = (RAND_BELOW(end - begin) + begin);
|
||||
|
||||
if (byte_idx >= end - 3) break;
|
||||
|
||||
if (RAND_BELOW(2)) {
|
||||
|
||||
*(u32 *)(out_buf + byte_idx) -= 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
} else {
|
||||
|
||||
u32 num = 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
*(u32 *)(out_buf + byte_idx) =
|
||||
SWAP32(SWAP32(*(u32 *)(out_buf + byte_idx)) - num);
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 10: {
|
||||
|
||||
/* Randomly add to dword, random endian. */
|
||||
|
||||
if (end - begin < 4) break;
|
||||
|
||||
s32 byte_idx = (RAND_BELOW(end - begin) + begin);
|
||||
|
||||
if (byte_idx >= end - 3) break;
|
||||
|
||||
if (RAND_BELOW(2)) {
|
||||
|
||||
*(u32 *)(out_buf + byte_idx) += 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
} else {
|
||||
|
||||
u32 num = 1 + RAND_BELOW(ARITH_MAX);
|
||||
|
||||
*(u32 *)(out_buf + byte_idx) =
|
||||
SWAP32(SWAP32(*(u32 *)(out_buf + byte_idx)) + num);
|
||||
|
||||
}
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
case 11: {
|
||||
|
||||
/* Just set a random byte to a random value. Because,
|
||||
why not. We use XOR with 1-255 to eliminate the
|
||||
possibility of a no-op. */
|
||||
|
||||
out_buf[(RAND_BELOW(end - begin) + begin)] ^= 1 + RAND_BELOW(255);
|
||||
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
/* This function calculates the next power of 2 greater or equal its argument.
|
||||
@return The rounded up power of 2 (if no overflow) or 0 on overflow.
|
||||
*/
|
||||
static inline size_t next_pow2(size_t in) {
|
||||
|
||||
if (in == 0 || in > (size_t)-1)
|
||||
return 0; /* avoid undefined behaviour under-/overflow */
|
||||
size_t out = in - 1;
|
||||
out |= out >> 1;
|
||||
out |= out >> 2;
|
||||
out |= out >> 4;
|
||||
out |= out >> 8;
|
||||
out |= out >> 16;
|
||||
return out + 1;
|
||||
|
||||
}
|
||||
|
||||
/* This function makes sure *size is > size_needed after call.
|
||||
It will realloc *buf otherwise.
|
||||
*size will grow exponentially as per:
|
||||
https://blog.mozilla.org/nnethercote/2014/11/04/please-grow-your-buffers-exponentially/
|
||||
Will return NULL and free *buf if size_needed is <1 or realloc failed.
|
||||
@return For convenience, this function returns *buf.
|
||||
*/
|
||||
static inline void *maybe_grow(void **buf, size_t *size, size_t size_needed) {
|
||||
|
||||
/* No need to realloc */
|
||||
if (likely(size_needed && *size >= size_needed)) return *buf;
|
||||
|
||||
/* No initial size was set */
|
||||
if (size_needed < INITIAL_GROWTH_SIZE) size_needed = INITIAL_GROWTH_SIZE;
|
||||
|
||||
/* grow exponentially */
|
||||
size_t next_size = next_pow2(size_needed);
|
||||
|
||||
/* handle overflow */
|
||||
if (!next_size) { next_size = size_needed; }
|
||||
|
||||
/* alloc */
|
||||
*buf = realloc(*buf, next_size);
|
||||
*size = *buf ? next_size : 0;
|
||||
|
||||
return *buf;
|
||||
|
||||
}
|
||||
|
||||
/* Swaps buf1 ptr and buf2 ptr, as well as their sizes */
|
||||
static inline void afl_swap_bufs(void **buf1, size_t *size1, void **buf2,
|
||||
size_t *size2) {
|
||||
|
||||
void * scratch_buf = *buf1;
|
||||
size_t scratch_size = *size1;
|
||||
*buf1 = *buf2;
|
||||
*size1 = *size2;
|
||||
*buf2 = scratch_buf;
|
||||
*size2 = scratch_size;
|
||||
|
||||
}
|
||||
|
||||
#undef INITIAL_GROWTH_SIZE
|
||||
|
||||
#endif
|
||||
|
||||
10
custom_mutators/rust/.gitignore
vendored
10
custom_mutators/rust/.gitignore
vendored
@ -1,10 +0,0 @@
|
||||
# Generated by Cargo
|
||||
# will have compiled files and executables
|
||||
/target/
|
||||
|
||||
# Remove Cargo.lock from gitignore if creating an executable, leave it for libraries
|
||||
# More information here https://doc.rust-lang.org/cargo/guide/cargo-toml-vs-cargo-lock.html
|
||||
Cargo.lock
|
||||
|
||||
# These are backup files generated by rustfmt
|
||||
**/*.rs.bk
|
||||
@ -1,8 +0,0 @@
|
||||
[workspace]
|
||||
members = [
|
||||
"custom_mutator-sys",
|
||||
"custom_mutator",
|
||||
"example",
|
||||
# Lain needs a nightly toolchain
|
||||
# "example_lain",
|
||||
]
|
||||
@ -1,11 +0,0 @@
|
||||
# Rust Custom Mutators
|
||||
|
||||
Bindings to create custom mutators in Rust.
|
||||
|
||||
These bindings are documented with rustdoc. To view the documentation run
|
||||
```cargo doc -p custom_mutator --open```.
|
||||
|
||||
A minimal example can be found in `example`. Build it using `cargo build --example example_mutator`.
|
||||
|
||||
An example using [lain](https://github.com/microsoft/lain) for structured fuzzing can be found in `example_lain`.
|
||||
Since lain requires a nightly rust toolchain, you need to set one up before you can play with it.
|
||||
@ -1,12 +0,0 @@
|
||||
[package]
|
||||
name = "custom_mutator-sys"
|
||||
version = "0.1.0"
|
||||
authors = ["Julius Hohnerlein <julihoh@users.noreply.github.com>"]
|
||||
edition = "2018"
|
||||
|
||||
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
||||
|
||||
[dependencies]
|
||||
|
||||
[build-dependencies]
|
||||
bindgen = "0.56"
|
||||
@ -1,42 +0,0 @@
|
||||
extern crate bindgen;
|
||||
|
||||
use std::env;
|
||||
use std::path::PathBuf;
|
||||
|
||||
// this code is largely taken straight from the handbook: https://github.com/fitzgen/bindgen-tutorial-bzip2-sys
|
||||
fn main() {
|
||||
// Tell cargo to invalidate the built crate whenever the wrapper changes
|
||||
println!("cargo:rerun-if-changed=wrapper.h");
|
||||
|
||||
// The bindgen::Builder is the main entry point
|
||||
// to bindgen, and lets you build up options for
|
||||
// the resulting bindings.
|
||||
let bindings = bindgen::Builder::default()
|
||||
// The input header we would like to generate
|
||||
// bindings for.
|
||||
.header("wrapper.h")
|
||||
.whitelist_type("afl_state_t")
|
||||
.blacklist_type(r"u\d+")
|
||||
.opaque_type(r"_.*")
|
||||
.opaque_type("FILE")
|
||||
.opaque_type("in_addr(_t)?")
|
||||
.opaque_type("in_port(_t)?")
|
||||
.opaque_type("sa_family(_t)?")
|
||||
.opaque_type("sockaddr_in(_t)?")
|
||||
.opaque_type("time_t")
|
||||
.rustfmt_bindings(true)
|
||||
.size_t_is_usize(true)
|
||||
// Tell cargo to invalidate the built crate whenever any of the
|
||||
// included header files changed.
|
||||
.parse_callbacks(Box::new(bindgen::CargoCallbacks))
|
||||
// Finish the builder and generate the bindings.
|
||||
.generate()
|
||||
// Unwrap the Result and panic on failure.
|
||||
.expect("Unable to generate bindings");
|
||||
|
||||
// Write the bindings to the $OUT_DIR/bindings.rs file.
|
||||
let out_path = PathBuf::from(env::var("OUT_DIR").unwrap());
|
||||
bindings
|
||||
.write_to_file(out_path.join("bindings.rs"))
|
||||
.expect("Couldn't write bindings!");
|
||||
}
|
||||
@ -1,5 +0,0 @@
|
||||
#![allow(non_upper_case_globals)]
|
||||
#![allow(non_camel_case_types)]
|
||||
#![allow(non_snake_case)]
|
||||
|
||||
include!(concat!(env!("OUT_DIR"), "/bindings.rs"));
|
||||
@ -1,4 +0,0 @@
|
||||
#include "../../../include/afl-fuzz.h"
|
||||
#include "../../../include/common.h"
|
||||
#include "../../../include/config.h"
|
||||
#include "../../../include/debug.h"
|
||||
@ -1,13 +0,0 @@
|
||||
[package]
|
||||
name = "custom_mutator"
|
||||
version = "0.1.0"
|
||||
authors = ["Julius Hohnerlein <julihoh@users.noreply.github.com>"]
|
||||
edition = "2018"
|
||||
|
||||
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
||||
|
||||
[features]
|
||||
afl_internals = ["custom_mutator-sys"]
|
||||
|
||||
[dependencies]
|
||||
custom_mutator-sys = { path = "../custom_mutator-sys", optional=true }
|
||||
@ -1,740 +0,0 @@
|
||||
#![cfg(unix)]
|
||||
//! Somewhat safe and somewhat ergonomic bindings for creating [AFL++](https://github.com/AFLplusplus/AFLplusplus) [custom mutators](https://github.com/AFLplusplus/AFLplusplus/blob/stable/docs/custom_mutators.md) in Rust.
|
||||
//!
|
||||
//! # Usage
|
||||
//! AFL++ custom mutators are expected to be dynamic libraries which expose a set of symbols.
|
||||
//! Check out [`CustomMutator`] to see which functions of the API are supported.
|
||||
//! Then use [`export_mutator`] to export the correct symbols for your mutator.
|
||||
//! In order to use the mutator, your crate needs to be a library crate and have a `crate-type` of `cdylib`.
|
||||
//! Putting
|
||||
//! ```yaml
|
||||
//! [lib]
|
||||
//! crate-type = ["cdylib"]
|
||||
//! ```
|
||||
//! into your `Cargo.toml` should do the trick.
|
||||
//! The final executable can be found in `target/(debug|release)/your_crate_name.so`.
|
||||
//! # Example
|
||||
//! See [`export_mutator`] for an example.
|
||||
//!
|
||||
//! # On `panic`s
|
||||
//! This binding is panic-safe in that it will prevent panics from unwinding into AFL++. Any panic will `abort` at the boundary between the custom mutator and AFL++.
|
||||
//!
|
||||
//! # Access to AFL++ internals
|
||||
//! This crate has an optional feature "afl_internals", which gives access to AFL++'s internal state.
|
||||
//! The state is passed to [`CustomMutator::init`], when the feature is activated.
|
||||
//!
|
||||
//! _This is completely unsafe and uses automatically generated types extracted from the AFL++ source._
|
||||
use std::{fmt::Debug, path::Path};
|
||||
|
||||
#[cfg(feature = "afl_internals")]
|
||||
#[doc(hidden)]
|
||||
pub use custom_mutator_sys::afl_state;
|
||||
|
||||
#[allow(unused_variables)]
|
||||
#[doc(hidden)]
|
||||
pub trait RawCustomMutator {
|
||||
#[cfg(feature = "afl_internals")]
|
||||
fn init(afl: &'static afl_state, seed: u32) -> Self
|
||||
where
|
||||
Self: Sized;
|
||||
#[cfg(not(feature = "afl_internals"))]
|
||||
fn init(seed: u32) -> Self
|
||||
where
|
||||
Self: Sized;
|
||||
|
||||
fn fuzz<'b, 's: 'b>(
|
||||
&'s mut self,
|
||||
buffer: &'b mut [u8],
|
||||
add_buff: Option<&[u8]>,
|
||||
max_size: usize,
|
||||
) -> Option<&'b [u8]>;
|
||||
|
||||
fn fuzz_count(&mut self, buffer: &[u8]) -> u32 {
|
||||
1
|
||||
}
|
||||
|
||||
fn queue_new_entry(&mut self, filename_new_queue: &Path, _filename_orig_queue: Option<&Path>) {}
|
||||
|
||||
fn queue_get(&mut self, filename: &Path) -> bool {
|
||||
true
|
||||
}
|
||||
|
||||
fn describe(&mut self, max_description: usize) -> Option<&str> {
|
||||
Some(default_mutator_describe::<Self>(max_description))
|
||||
}
|
||||
|
||||
fn introspection(&mut self) -> Option<&str> {
|
||||
None
|
||||
}
|
||||
|
||||
/*fn post_process(&self, buffer: &[u8], unsigned char **out_buf)-> usize;
|
||||
int afl_custom_init_trim(&self, buffer: &[u8]);
|
||||
size_t afl_custom_trim(&self, unsigned char **out_buf);
|
||||
int afl_custom_post_trim(&self, unsigned char success);
|
||||
size_t afl_custom_havoc_mutation(&self, buffer: &[u8], unsigned char **out_buf, size_t max_size);
|
||||
unsigned char afl_custom_havoc_mutation_probability(&self);*/
|
||||
}
|
||||
|
||||
/// Wrappers for the custom mutator which provide the bridging between the C API and CustomMutator.
|
||||
/// These wrappers are not intended to be used directly, rather export_mutator will use them to publish the custom mutator C API.
|
||||
#[doc(hidden)]
|
||||
pub mod wrappers {
|
||||
#[cfg(feature = "afl_internals")]
|
||||
use custom_mutator_sys::afl_state;
|
||||
|
||||
use std::{
|
||||
any::Any,
|
||||
convert::TryInto,
|
||||
ffi::{c_void, CStr, OsStr},
|
||||
mem::ManuallyDrop,
|
||||
os::{raw::c_char, unix::ffi::OsStrExt},
|
||||
panic::catch_unwind,
|
||||
path::Path,
|
||||
process::abort,
|
||||
ptr::null,
|
||||
slice,
|
||||
};
|
||||
|
||||
use crate::RawCustomMutator;
|
||||
|
||||
/// A structure to be used as the data pointer for our custom mutator. This was used as additional storage and is kept for now in case its needed later.
|
||||
/// Also has some convenience functions for FFI conversions (from and to ptr) and tries to make misuse hard (see [`FFIContext::from`]).
|
||||
struct FFIContext<M: RawCustomMutator> {
|
||||
mutator: M,
|
||||
/// buffer for storing the description returned by [`RawCustomMutator::describe`] as a CString
|
||||
description_buffer: Vec<u8>,
|
||||
/// buffer for storing the introspection returned by [`RawCustomMutator::introspect`] as a CString
|
||||
introspection_buffer: Vec<u8>,
|
||||
}
|
||||
|
||||
impl<M: RawCustomMutator> FFIContext<M> {
|
||||
fn from(ptr: *mut c_void) -> ManuallyDrop<Box<Self>> {
|
||||
assert!(!ptr.is_null());
|
||||
ManuallyDrop::new(unsafe { Box::from_raw(ptr as *mut Self) })
|
||||
}
|
||||
|
||||
fn into_ptr(self: Box<Self>) -> *const c_void {
|
||||
Box::into_raw(self) as *const c_void
|
||||
}
|
||||
|
||||
#[cfg(feature = "afl_internals")]
|
||||
fn new(afl: &'static afl_state, seed: u32) -> Box<Self> {
|
||||
Box::new(Self {
|
||||
mutator: M::init(afl, seed),
|
||||
description_buffer: Vec::new(),
|
||||
introspection_buffer: Vec::new(),
|
||||
})
|
||||
}
|
||||
#[cfg(not(feature = "afl_internals"))]
|
||||
fn new(seed: u32) -> Box<Self> {
|
||||
Box::new(Self {
|
||||
mutator: M::init(seed),
|
||||
description_buffer: Vec::new(),
|
||||
introspection_buffer: Vec::new(),
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
/// panic handler called for every panic
|
||||
fn panic_handler(method: &str, panic_info: Box<dyn Any + Send + 'static>) -> ! {
|
||||
use std::ops::Deref;
|
||||
let cause = panic_info
|
||||
.downcast_ref::<String>()
|
||||
.map(String::deref)
|
||||
.unwrap_or_else(|| {
|
||||
panic_info
|
||||
.downcast_ref::<&str>()
|
||||
.copied()
|
||||
.unwrap_or("<cause unknown>")
|
||||
});
|
||||
eprintln!("A panic occurred at {}: {}", method, cause);
|
||||
abort()
|
||||
}
|
||||
|
||||
/// Internal function used in the macro
|
||||
#[cfg(not(feature = "afl_internals"))]
|
||||
pub fn afl_custom_init_<M: RawCustomMutator>(seed: u32) -> *const c_void {
|
||||
match catch_unwind(|| FFIContext::<M>::new(seed).into_ptr()) {
|
||||
Ok(ret) => ret,
|
||||
Err(err) => panic_handler("afl_custom_init", err),
|
||||
}
|
||||
}
|
||||
|
||||
/// Internal function used in the macro
|
||||
#[cfg(feature = "afl_internals")]
|
||||
pub fn afl_custom_init_<M: RawCustomMutator>(
|
||||
afl: Option<&'static afl_state>,
|
||||
seed: u32,
|
||||
) -> *const c_void {
|
||||
match catch_unwind(|| {
|
||||
let afl = afl.expect("mutator func called with NULL afl");
|
||||
FFIContext::<M>::new(afl, seed).into_ptr()
|
||||
}) {
|
||||
Ok(ret) => ret,
|
||||
Err(err) => panic_handler("afl_custom_init", err),
|
||||
}
|
||||
}
|
||||
|
||||
/// Internal function used in the macro
|
||||
pub unsafe fn afl_custom_fuzz_<M: RawCustomMutator>(
|
||||
data: *mut c_void,
|
||||
buf: *mut u8,
|
||||
buf_size: usize,
|
||||
out_buf: *mut *const u8,
|
||||
add_buf: *mut u8,
|
||||
add_buf_size: usize,
|
||||
max_size: usize,
|
||||
) -> usize {
|
||||
match catch_unwind(|| {
|
||||
let mut context = FFIContext::<M>::from(data);
|
||||
if buf.is_null() {
|
||||
panic!("null buf passed to afl_custom_fuzz")
|
||||
}
|
||||
if out_buf.is_null() {
|
||||
panic!("null out_buf passed to afl_custom_fuzz")
|
||||
}
|
||||
let buff_slice = slice::from_raw_parts_mut(buf, buf_size);
|
||||
let add_buff_slice = if add_buf.is_null() {
|
||||
None
|
||||
} else {
|
||||
Some(slice::from_raw_parts(add_buf, add_buf_size))
|
||||
};
|
||||
match context
|
||||
.mutator
|
||||
.fuzz(buff_slice, add_buff_slice, max_size.try_into().unwrap())
|
||||
{
|
||||
Some(buffer) => {
|
||||
*out_buf = buffer.as_ptr();
|
||||
buffer.len().try_into().unwrap()
|
||||
}
|
||||
None => {
|
||||
// return the input buffer with 0-length to let AFL skip this mutation attempt
|
||||
*out_buf = buf;
|
||||
0
|
||||
}
|
||||
}
|
||||
}) {
|
||||
Ok(ret) => ret,
|
||||
Err(err) => panic_handler("afl_custom_fuzz", err),
|
||||
}
|
||||
}
|
||||
|
||||
/// Internal function used in the macro
|
||||
pub unsafe fn afl_custom_fuzz_count_<M: RawCustomMutator>(
|
||||
data: *mut c_void,
|
||||
buf: *const u8,
|
||||
buf_size: usize,
|
||||
) -> u32 {
|
||||
match catch_unwind(|| {
|
||||
let mut context = FFIContext::<M>::from(data);
|
||||
if buf.is_null() {
|
||||
panic!("null buf passed to afl_custom_fuzz")
|
||||
}
|
||||
let buf_slice = slice::from_raw_parts(buf, buf_size);
|
||||
// see https://doc.rust-lang.org/nomicon/borrow-splitting.html
|
||||
let ctx = &mut **context;
|
||||
let mutator = &mut ctx.mutator;
|
||||
mutator.fuzz_count(buf_slice)
|
||||
}) {
|
||||
Ok(ret) => ret,
|
||||
Err(err) => panic_handler("afl_custom_fuzz_count", err),
|
||||
}
|
||||
}
|
||||
|
||||
/// Internal function used in the macro
|
||||
pub fn afl_custom_queue_new_entry_<M: RawCustomMutator>(
|
||||
data: *mut c_void,
|
||||
filename_new_queue: *const c_char,
|
||||
filename_orig_queue: *const c_char,
|
||||
) {
|
||||
match catch_unwind(|| {
|
||||
let mut context = FFIContext::<M>::from(data);
|
||||
if filename_new_queue.is_null() {
|
||||
panic!("received null filename_new_queue in afl_custom_queue_new_entry");
|
||||
}
|
||||
let filename_new_queue = Path::new(OsStr::from_bytes(
|
||||
unsafe { CStr::from_ptr(filename_new_queue) }.to_bytes(),
|
||||
));
|
||||
let filename_orig_queue = if !filename_orig_queue.is_null() {
|
||||
Some(Path::new(OsStr::from_bytes(
|
||||
unsafe { CStr::from_ptr(filename_orig_queue) }.to_bytes(),
|
||||
)))
|
||||
} else {
|
||||
None
|
||||
};
|
||||
context
|
||||
.mutator
|
||||
.queue_new_entry(filename_new_queue, filename_orig_queue);
|
||||
}) {
|
||||
Ok(ret) => ret,
|
||||
Err(err) => panic_handler("afl_custom_queue_new_entry", err),
|
||||
}
|
||||
}
|
||||
|
||||
/// Internal function used in the macro
|
||||
pub unsafe fn afl_custom_deinit_<M: RawCustomMutator>(data: *mut c_void) {
|
||||
match catch_unwind(|| {
|
||||
// drop the context
|
||||
ManuallyDrop::into_inner(FFIContext::<M>::from(data));
|
||||
}) {
|
||||
Ok(ret) => ret,
|
||||
Err(err) => panic_handler("afl_custom_deinit", err),
|
||||
}
|
||||
}
|
||||
|
||||
/// Internal function used in the macro
|
||||
pub fn afl_custom_introspection_<M: RawCustomMutator>(data: *mut c_void) -> *const c_char {
|
||||
match catch_unwind(|| {
|
||||
let context = &mut *FFIContext::<M>::from(data);
|
||||
if let Some(res) = context.mutator.introspection() {
|
||||
let buf = &mut context.introspection_buffer;
|
||||
buf.clear();
|
||||
buf.extend_from_slice(res.as_bytes());
|
||||
buf.push(0);
|
||||
// unwrapping here, as the error case should be extremely rare
|
||||
CStr::from_bytes_with_nul(&buf).unwrap().as_ptr()
|
||||
} else {
|
||||
null()
|
||||
}
|
||||
}) {
|
||||
Ok(ret) => ret,
|
||||
Err(err) => panic_handler("afl_custom_introspection", err),
|
||||
}
|
||||
}
|
||||
|
||||
/// Internal function used in the macro
|
||||
pub fn afl_custom_describe_<M: RawCustomMutator>(
|
||||
data: *mut c_void,
|
||||
max_description_len: usize,
|
||||
) -> *const c_char {
|
||||
match catch_unwind(|| {
|
||||
let context = &mut *FFIContext::<M>::from(data);
|
||||
if let Some(res) = context.mutator.describe(max_description_len) {
|
||||
let buf = &mut context.description_buffer;
|
||||
buf.clear();
|
||||
buf.extend_from_slice(res.as_bytes());
|
||||
buf.push(0);
|
||||
// unwrapping here, as the error case should be extremely rare
|
||||
CStr::from_bytes_with_nul(&buf).unwrap().as_ptr()
|
||||
} else {
|
||||
null()
|
||||
}
|
||||
}) {
|
||||
Ok(ret) => ret,
|
||||
Err(err) => panic_handler("afl_custom_describe", err),
|
||||
}
|
||||
}
|
||||
|
||||
/// Internal function used in the macro
|
||||
pub fn afl_custom_queue_get_<M: RawCustomMutator>(
|
||||
data: *mut c_void,
|
||||
filename: *const c_char,
|
||||
) -> u8 {
|
||||
match catch_unwind(|| {
|
||||
let mut context = FFIContext::<M>::from(data);
|
||||
assert!(!filename.is_null());
|
||||
|
||||
context.mutator.queue_get(Path::new(OsStr::from_bytes(
|
||||
unsafe { CStr::from_ptr(filename) }.to_bytes(),
|
||||
))) as u8
|
||||
}) {
|
||||
Ok(ret) => ret,
|
||||
Err(err) => panic_handler("afl_custom_queue_get", err),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/// exports the given Mutator as a custom mutator as the C interface that AFL++ expects.
|
||||
/// It is not possible to call this macro multiple times, because it would define the custom mutator symbols multiple times.
|
||||
/// # Example
|
||||
/// ```
|
||||
/// # #[macro_use] extern crate custom_mutator;
|
||||
/// # #[cfg(feature = "afl_internals")]
|
||||
/// # use custom_mutator::afl_state;
|
||||
/// # use custom_mutator::CustomMutator;
|
||||
/// struct MyMutator;
|
||||
/// impl CustomMutator for MyMutator {
|
||||
/// /// ...
|
||||
/// # type Error = ();
|
||||
/// # #[cfg(feature = "afl_internals")]
|
||||
/// # fn init(_afl_state: &afl_state, _seed: u32) -> Result<Self,()> {unimplemented!()}
|
||||
/// # #[cfg(not(feature = "afl_internals"))]
|
||||
/// # fn init(_seed: u32) -> Result<Self, Self::Error> {unimplemented!()}
|
||||
/// # fn fuzz<'b,'s:'b>(&'s mut self, _buffer: &'b mut [u8], _add_buff: Option<&[u8]>, _max_size: usize) -> Result<Option<&'b [u8]>, Self::Error> {unimplemented!()}
|
||||
/// }
|
||||
/// export_mutator!(MyMutator);
|
||||
/// ```
|
||||
#[macro_export]
|
||||
macro_rules! export_mutator {
|
||||
($mutator_type:ty) => {
|
||||
#[cfg(feature = "afl_internals")]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn afl_custom_init(
|
||||
afl: ::std::option::Option<&'static $crate::afl_state>,
|
||||
seed: ::std::os::raw::c_uint,
|
||||
) -> *const ::std::os::raw::c_void {
|
||||
$crate::wrappers::afl_custom_init_::<$mutator_type>(afl, seed as u32)
|
||||
}
|
||||
|
||||
#[cfg(not(feature = "afl_internals"))]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn afl_custom_init(
|
||||
_afl: *const ::std::os::raw::c_void,
|
||||
seed: ::std::os::raw::c_uint,
|
||||
) -> *const ::std::os::raw::c_void {
|
||||
$crate::wrappers::afl_custom_init_::<$mutator_type>(seed as u32)
|
||||
}
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn afl_custom_fuzz_count(
|
||||
data: *mut ::std::os::raw::c_void,
|
||||
buf: *const u8,
|
||||
buf_size: usize,
|
||||
) -> u32 {
|
||||
unsafe {
|
||||
$crate::wrappers::afl_custom_fuzz_count_::<$mutator_type>(data, buf, buf_size)
|
||||
}
|
||||
}
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn afl_custom_fuzz(
|
||||
data: *mut ::std::os::raw::c_void,
|
||||
buf: *mut u8,
|
||||
buf_size: usize,
|
||||
out_buf: *mut *const u8,
|
||||
add_buf: *mut u8,
|
||||
add_buf_size: usize,
|
||||
max_size: usize,
|
||||
) -> usize {
|
||||
unsafe {
|
||||
$crate::wrappers::afl_custom_fuzz_::<$mutator_type>(
|
||||
data,
|
||||
buf,
|
||||
buf_size,
|
||||
out_buf,
|
||||
add_buf,
|
||||
add_buf_size,
|
||||
max_size,
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn afl_custom_queue_new_entry(
|
||||
data: *mut ::std::os::raw::c_void,
|
||||
filename_new_queue: *const ::std::os::raw::c_char,
|
||||
filename_orig_queue: *const ::std::os::raw::c_char,
|
||||
) {
|
||||
$crate::wrappers::afl_custom_queue_new_entry_::<$mutator_type>(
|
||||
data,
|
||||
filename_new_queue,
|
||||
filename_orig_queue,
|
||||
)
|
||||
}
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn afl_custom_queue_get(
|
||||
data: *mut ::std::os::raw::c_void,
|
||||
filename: *const ::std::os::raw::c_char,
|
||||
) -> u8 {
|
||||
$crate::wrappers::afl_custom_queue_get_::<$mutator_type>(data, filename)
|
||||
}
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn afl_custom_introspection(
|
||||
data: *mut ::std::os::raw::c_void,
|
||||
) -> *const ::std::os::raw::c_char {
|
||||
$crate::wrappers::afl_custom_introspection_::<$mutator_type>(data)
|
||||
}
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn afl_custom_describe(
|
||||
data: *mut ::std::os::raw::c_void,
|
||||
max_description_len: usize,
|
||||
) -> *const ::std::os::raw::c_char {
|
||||
$crate::wrappers::afl_custom_describe_::<$mutator_type>(data, max_description_len)
|
||||
}
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn afl_custom_deinit(data: *mut ::std::os::raw::c_void) {
|
||||
unsafe { $crate::wrappers::afl_custom_deinit_::<$mutator_type>(data) }
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
/// this sanity test is supposed to just find out whether an empty mutator being exported by the macro compiles
|
||||
mod sanity_test {
|
||||
#[cfg(feature = "afl_internals")]
|
||||
use super::afl_state;
|
||||
|
||||
use super::{export_mutator, RawCustomMutator};
|
||||
|
||||
struct ExampleMutator;
|
||||
|
||||
impl RawCustomMutator for ExampleMutator {
|
||||
#[cfg(feature = "afl_internals")]
|
||||
fn init(_afl: &afl_state, _seed: u32) -> Self {
|
||||
unimplemented!()
|
||||
}
|
||||
|
||||
#[cfg(not(feature = "afl_internals"))]
|
||||
fn init(_seed: u32) -> Self {
|
||||
unimplemented!()
|
||||
}
|
||||
|
||||
fn fuzz<'b, 's: 'b>(
|
||||
&'s mut self,
|
||||
_buffer: &'b mut [u8],
|
||||
_add_buff: Option<&[u8]>,
|
||||
_max_size: usize,
|
||||
) -> Option<&'b [u8]> {
|
||||
unimplemented!()
|
||||
}
|
||||
}
|
||||
|
||||
export_mutator!(ExampleMutator);
|
||||
}
|
||||
|
||||
#[allow(unused_variables)]
|
||||
/// A custom mutator.
|
||||
/// [`CustomMutator::handle_error`] will be called in case any method returns an [`Result::Err`].
|
||||
pub trait CustomMutator {
|
||||
/// The error type. All methods must return the same error type.
|
||||
type Error: Debug;
|
||||
|
||||
/// The method which handles errors.
|
||||
/// By default, this method will log the error to stderr if the environment variable "`AFL_CUSTOM_MUTATOR_DEBUG`" is set and non-empty.
|
||||
/// After logging the error, execution will continue on a best-effort basis.
|
||||
///
|
||||
/// This default behaviour can be customized by implementing this method.
|
||||
fn handle_error(err: Self::Error) {
|
||||
if std::env::var("AFL_CUSTOM_MUTATOR_DEBUG")
|
||||
.map(|v| !v.is_empty())
|
||||
.unwrap_or(false)
|
||||
{
|
||||
eprintln!("Error in custom mutator: {:?}", err)
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(feature = "afl_internals")]
|
||||
fn init(afl: &'static afl_state, seed: u32) -> Result<Self, Self::Error>
|
||||
where
|
||||
Self: Sized;
|
||||
|
||||
#[cfg(not(feature = "afl_internals"))]
|
||||
fn init(seed: u32) -> Result<Self, Self::Error>
|
||||
where
|
||||
Self: Sized;
|
||||
|
||||
fn fuzz_count(&mut self, buffer: &[u8]) -> Result<u32, Self::Error> {
|
||||
Ok(1)
|
||||
}
|
||||
|
||||
fn fuzz<'b, 's: 'b>(
|
||||
&'s mut self,
|
||||
buffer: &'b mut [u8],
|
||||
add_buff: Option<&[u8]>,
|
||||
max_size: usize,
|
||||
) -> Result<Option<&'b [u8]>, Self::Error>;
|
||||
|
||||
fn queue_new_entry(
|
||||
&mut self,
|
||||
filename_new_queue: &Path,
|
||||
filename_orig_queue: Option<&Path>,
|
||||
) -> Result<(), Self::Error> {
|
||||
Ok(())
|
||||
}
|
||||
|
||||
fn queue_get(&mut self, filename: &Path) -> Result<bool, Self::Error> {
|
||||
Ok(true)
|
||||
}
|
||||
|
||||
fn describe(&mut self, max_description: usize) -> Result<Option<&str>, Self::Error> {
|
||||
Ok(Some(default_mutator_describe::<Self>(max_description)))
|
||||
}
|
||||
|
||||
fn introspection(&mut self) -> Result<Option<&str>, Self::Error> {
|
||||
Ok(None)
|
||||
}
|
||||
}
|
||||
|
||||
impl<M> RawCustomMutator for M
|
||||
where
|
||||
M: CustomMutator,
|
||||
M::Error: Debug,
|
||||
{
|
||||
#[cfg(feature = "afl_internals")]
|
||||
fn init(afl: &'static afl_state, seed: u32) -> Self
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
match Self::init(afl, seed) {
|
||||
Ok(r) => r,
|
||||
Err(e) => {
|
||||
Self::handle_error(e);
|
||||
panic!("Error in afl_custom_init")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(not(feature = "afl_internals"))]
|
||||
fn init(seed: u32) -> Self
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
match Self::init(seed) {
|
||||
Ok(r) => r,
|
||||
Err(e) => {
|
||||
Self::handle_error(e);
|
||||
panic!("Error in afl_custom_init")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn fuzz_count(&mut self, buffer: &[u8]) -> u32 {
|
||||
match self.fuzz_count(buffer) {
|
||||
Ok(r) => r,
|
||||
Err(e) => {
|
||||
Self::handle_error(e);
|
||||
0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn fuzz<'b, 's: 'b>(
|
||||
&'s mut self,
|
||||
buffer: &'b mut [u8],
|
||||
add_buff: Option<&[u8]>,
|
||||
max_size: usize,
|
||||
) -> Option<&'b [u8]> {
|
||||
match self.fuzz(buffer, add_buff, max_size) {
|
||||
Ok(r) => r,
|
||||
Err(e) => {
|
||||
Self::handle_error(e);
|
||||
None
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn queue_new_entry(&mut self, filename_new_queue: &Path, filename_orig_queue: Option<&Path>) {
|
||||
match self.queue_new_entry(filename_new_queue, filename_orig_queue) {
|
||||
Ok(r) => r,
|
||||
Err(e) => {
|
||||
Self::handle_error(e);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn queue_get(&mut self, filename: &Path) -> bool {
|
||||
match self.queue_get(filename) {
|
||||
Ok(r) => r,
|
||||
Err(e) => {
|
||||
Self::handle_error(e);
|
||||
false
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn describe(&mut self, max_description: usize) -> Option<&str> {
|
||||
match self.describe(max_description) {
|
||||
Ok(r) => r,
|
||||
Err(e) => {
|
||||
Self::handle_error(e);
|
||||
None
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn introspection(&mut self) -> Option<&str> {
|
||||
match self.introspection() {
|
||||
Ok(r) => r,
|
||||
Err(e) => {
|
||||
Self::handle_error(e);
|
||||
None
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/// the default value to return from [`CustomMutator::describe`].
|
||||
fn default_mutator_describe<T: ?Sized>(max_len: usize) -> &'static str {
|
||||
truncate_str_unicode_safe(std::any::type_name::<T>(), max_len)
|
||||
}
|
||||
|
||||
#[cfg(all(test, not(feature = "afl_internals")))]
|
||||
mod default_mutator_describe {
|
||||
struct MyMutator;
|
||||
use super::CustomMutator;
|
||||
impl CustomMutator for MyMutator {
|
||||
type Error = ();
|
||||
|
||||
fn init(_: u32) -> Result<Self, Self::Error> {
|
||||
Ok(Self)
|
||||
}
|
||||
|
||||
fn fuzz<'b, 's: 'b>(
|
||||
&'s mut self,
|
||||
_: &'b mut [u8],
|
||||
_: Option<&[u8]>,
|
||||
_: usize,
|
||||
) -> Result<Option<&'b [u8]>, Self::Error> {
|
||||
unimplemented!()
|
||||
}
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_default_describe() {
|
||||
assert_eq!(
|
||||
MyMutator::init(0).unwrap().describe(64).unwrap().unwrap(),
|
||||
"custom_mutator::default_mutator_describe::MyMutator"
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
/// little helper function to truncate a `str` to a maximum of bytes while retaining unicode safety
|
||||
fn truncate_str_unicode_safe(s: &str, max_len: usize) -> &str {
|
||||
if s.len() <= max_len {
|
||||
s
|
||||
} else {
|
||||
if let Some((last_index, _)) = s
|
||||
.char_indices()
|
||||
.take_while(|(index, _)| *index <= max_len)
|
||||
.last()
|
||||
{
|
||||
&s[..last_index]
|
||||
} else {
|
||||
""
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod truncate_test {
|
||||
use super::truncate_str_unicode_safe;
|
||||
|
||||
#[test]
|
||||
fn test_truncate() {
|
||||
for (max_len, input, expected_output) in &[
|
||||
(0usize, "a", ""),
|
||||
(1, "a", "a"),
|
||||
(1, "ä", ""),
|
||||
(2, "ä", "ä"),
|
||||
(3, "äa", "äa"),
|
||||
(4, "äa", "äa"),
|
||||
(1, "👎", ""),
|
||||
(2, "👎", ""),
|
||||
(3, "👎", ""),
|
||||
(4, "👎", "👎"),
|
||||
(1, "abc", "a"),
|
||||
(2, "abc", "ab"),
|
||||
] {
|
||||
let actual_output = truncate_str_unicode_safe(input, *max_len);
|
||||
assert_eq!(
|
||||
&actual_output, expected_output,
|
||||
"{:#?} truncated to {} bytes should be {:#?}, but is {:#?}",
|
||||
input, max_len, expected_output, actual_output
|
||||
);
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -1,15 +0,0 @@
|
||||
[package]
|
||||
name = "example_mutator"
|
||||
version = "0.1.0"
|
||||
authors = ["Julius Hohnerlein <julihoh@users.noreply.github.com>"]
|
||||
edition = "2018"
|
||||
|
||||
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
||||
|
||||
[dependencies]
|
||||
custom_mutator = { path = "../custom_mutator" }
|
||||
|
||||
[[example]]
|
||||
name = "example_mutator"
|
||||
path = "./src/example_mutator.rs"
|
||||
crate-type = ["cdylib"]
|
||||
@ -1,50 +0,0 @@
|
||||
#![cfg(unix)]
|
||||
#![allow(unused_variables)]
|
||||
|
||||
use custom_mutator::{export_mutator, CustomMutator};
|
||||
|
||||
struct ExampleMutator;
|
||||
|
||||
impl CustomMutator for ExampleMutator {
|
||||
type Error = ();
|
||||
|
||||
fn init(seed: u32) -> Result<Self, Self::Error> {
|
||||
Ok(Self)
|
||||
}
|
||||
|
||||
fn fuzz<'b, 's: 'b>(
|
||||
&'s mut self,
|
||||
buffer: &'b mut [u8],
|
||||
add_buff: Option<&[u8]>,
|
||||
max_size: usize,
|
||||
) -> Result<Option<&'b [u8]>, Self::Error> {
|
||||
buffer.reverse();
|
||||
Ok(Some(buffer))
|
||||
}
|
||||
}
|
||||
|
||||
struct OwnBufferExampleMutator {
|
||||
own_buffer: Vec<u8>,
|
||||
}
|
||||
|
||||
impl CustomMutator for OwnBufferExampleMutator {
|
||||
type Error = ();
|
||||
|
||||
fn init(seed: u32) -> Result<Self, Self::Error> {
|
||||
Ok(Self {
|
||||
own_buffer: Vec::new(),
|
||||
})
|
||||
}
|
||||
|
||||
fn fuzz<'b, 's: 'b>(
|
||||
&'s mut self,
|
||||
buffer: &'b mut [u8],
|
||||
add_buff: Option<&[u8]>,
|
||||
max_size: usize,
|
||||
) -> Result<Option<&'b [u8]>, ()> {
|
||||
self.own_buffer.reverse();
|
||||
Ok(Some(self.own_buffer.as_slice()))
|
||||
}
|
||||
}
|
||||
|
||||
export_mutator!(ExampleMutator);
|
||||
@ -1,16 +0,0 @@
|
||||
[package]
|
||||
name = "example_lain"
|
||||
version = "0.1.0"
|
||||
authors = ["Julius Hohnerlein <julihoh@users.noreply.github.com>"]
|
||||
edition = "2018"
|
||||
|
||||
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
||||
|
||||
[dependencies]
|
||||
custom_mutator = { path = "../custom_mutator" }
|
||||
lain="0.5"
|
||||
|
||||
[[example]]
|
||||
name = "example_lain"
|
||||
path = "./src/lain_mutator.rs"
|
||||
crate-type = ["cdylib"]
|
||||
@ -1 +0,0 @@
|
||||
nightly
|
||||
@ -1,61 +0,0 @@
|
||||
#![cfg(unix)]
|
||||
|
||||
use custom_mutator::{export_mutator, CustomMutator};
|
||||
use lain::{
|
||||
mutator::Mutator,
|
||||
prelude::*,
|
||||
rand::{rngs::StdRng, SeedableRng},
|
||||
};
|
||||
|
||||
#[derive(Debug, Mutatable, NewFuzzed, BinarySerialize)]
|
||||
struct MyStruct {
|
||||
field_1: u8,
|
||||
|
||||
#[lain(bits = 3)]
|
||||
field_2: u8,
|
||||
|
||||
#[lain(bits = 5)]
|
||||
field_3: u8,
|
||||
|
||||
#[lain(min = 5, max = 10000)]
|
||||
field_4: u32,
|
||||
|
||||
#[lain(ignore)]
|
||||
ignored_field: u64,
|
||||
}
|
||||
|
||||
struct LainMutator {
|
||||
mutator: Mutator<StdRng>,
|
||||
buffer: Vec<u8>,
|
||||
}
|
||||
|
||||
impl CustomMutator for LainMutator {
|
||||
type Error = ();
|
||||
|
||||
fn init(seed: u32) -> Result<Self, ()> {
|
||||
Ok(Self {
|
||||
mutator: Mutator::new(StdRng::seed_from_u64(seed as u64)),
|
||||
buffer: Vec::new(),
|
||||
})
|
||||
}
|
||||
|
||||
fn fuzz<'b, 's: 'b>(
|
||||
&'s mut self,
|
||||
_buffer: &'b mut [u8],
|
||||
_add_buff: Option<&[u8]>,
|
||||
max_size: usize,
|
||||
) -> Result<Option<&'b [u8]>, ()> {
|
||||
// we just sample an instance of MyStruct, ignoring the current input
|
||||
let instance = MyStruct::new_fuzzed(&mut self.mutator, None);
|
||||
let size = instance.serialized_size();
|
||||
if size > max_size {
|
||||
return Err(());
|
||||
}
|
||||
self.buffer.clear();
|
||||
self.buffer.reserve(size);
|
||||
instance.binary_serialize::<_, BigEndian>(&mut self.buffer);
|
||||
Ok(Some(self.buffer.as_slice()))
|
||||
}
|
||||
}
|
||||
|
||||
export_mutator!(LainMutator);
|
||||
@ -8,203 +8,46 @@
|
||||
Want to stay in the loop on major new features? Join our mailing list by
|
||||
sending a mail to <afl-users+subscribe@googlegroups.com>.
|
||||
|
||||
### Version ++3.14c (release)
|
||||
- afl-fuzz:
|
||||
- fix -F when a '/' was part of the parameter
|
||||
- fixed a crash for cmplog for very slow inputs
|
||||
- fix for AFLfast schedule counting
|
||||
- removed implied -D determinstic from -M main
|
||||
- if the target becomes unavailable check out out/default/error.txt
|
||||
for an indicator why
|
||||
- AFL_CAL_FAST was a dead env, now does the same as AFL_FAST_CAL
|
||||
- reverse read the queue on resumes (more effective)
|
||||
- fix custom mutator trimming
|
||||
- afl-cc:
|
||||
- Update to COMPCOV/laf-intel that speeds up the instrumentation
|
||||
process a lot - thanks to Michael Rodler/f0rki for the PR!
|
||||
- Fix for failures for some sized string instrumentations
|
||||
- Fix to instrument global namespace functions in c++
|
||||
- Fix for llvm 13
|
||||
- support partial linking
|
||||
- do honor AFL_LLVM_{ALLOW/DENY}LIST for LTO autodictionary and DICT2FILE
|
||||
- We do support llvm versions from 3.8 to 5.0 again
|
||||
- frida_mode:
|
||||
- several fixes for cmplog
|
||||
- remove need for AFL_FRIDA_PERSISTENT_RETADDR_OFFSET
|
||||
- less coverage collision
|
||||
- feature parity of aarch64 with intel now (persistent, cmplog,
|
||||
in-memory testcases, asan)
|
||||
- afl-cmin and afl-showmap -i do now descend into subdirectories
|
||||
(like afl-fuzz does) - note that afl-cmin.bash does not!
|
||||
- afl_analyze:
|
||||
- fix timeout handling
|
||||
- add forkserver support for better performance
|
||||
- ensure afl-compiler-rt is built for gcc_module
|
||||
- always build aflpp_driver for libfuzzer harnesses
|
||||
- added `AFL_NO_FORKSRV` env variable support to
|
||||
afl-cmin, afl-tmin, and afl-showmap, by @jhertz
|
||||
- removed outdated documents, improved existing documentation
|
||||
|
||||
### Version ++3.13c (release)
|
||||
- Note: plot_data switched to relative time from unix time in 3.10
|
||||
- frida_mode - new mode that uses frida to fuzz binary-only targets,
|
||||
it currently supports persistent mode and cmplog.
|
||||
thanks to @WorksButNotTested!
|
||||
- create a fuzzing dictionary with the help of CodeQL thanks to
|
||||
@microsvuln! see utils/autodict_ql
|
||||
- afl-fuzz:
|
||||
- added patch by @realmadsci to support @@ as part of command line
|
||||
options, e.g. `afl-fuzz ... -- ./target --infile=@@`
|
||||
- add recording of previous fuzz attempts for persistent mode
|
||||
to allow replay of non-reproducable crashes, see
|
||||
AFL_PERSISTENT_RECORD in config.h and docs/envs.h
|
||||
- fixed a bug when trimming for stdin targets
|
||||
- cmplog -l: default cmplog level is now 2, better efficiency.
|
||||
level 3 now performs redqueen on everything. use with care.
|
||||
- better fuzzing strategy yield display for enabled options
|
||||
- ensure one fuzzer sync per cycle
|
||||
- fix afl_custom_queue_new_entry original file name when syncing
|
||||
from fuzzers
|
||||
- fixed a crash when more than one custom mutator was used together
|
||||
with afl_custom_post_process
|
||||
- on a crashing seed potentially the wrong input was disabled
|
||||
- added AFL_EXIT_ON_SEED_ISSUES env that will exit if a seed in
|
||||
-i dir crashes the target or results in a timeout. By default
|
||||
afl++ ignores these and uses them for splicing instead.
|
||||
- added AFL_EXIT_ON_TIME env that will make afl-fuzz exit fuzzing
|
||||
after no new paths have been found for n seconds
|
||||
- when AFL_FAST_CAL is set a variable path will now be calibrated
|
||||
8 times instead of originally 40. Long calibration is now 20.
|
||||
- added AFL_TRY_AFFINITY to try to bind to CPUs but don't error if
|
||||
it fails
|
||||
- afl-cc:
|
||||
- We do not support llvm versions prior 6.0 anymore
|
||||
- added thread safe counters to all modes (`AFL_LLVM_THREADSAFE_INST`),
|
||||
note that this disables NeverZero counters.
|
||||
- Fix for -pie compiled binaries with default afl-clang-fast PCGUARD
|
||||
- Leak Sanitizer (AFL_USE_LSAN) added by Joshua Rogers, thanks!
|
||||
- Removed InsTrim instrumentation as it is not as good as PCGUARD
|
||||
- Removed automatic linking with -lc++ for LTO mode
|
||||
- Fixed a crash in llvm dict2file when a strncmp length was -1
|
||||
- added --afl-noopt support
|
||||
- utils/aflpp_driver:
|
||||
- aflpp_qemu_driver_hook fixed to work with qemu_mode
|
||||
- aflpp_driver now compiled with -fPIC
|
||||
- unicornafl:
|
||||
- fix MIPS delay slot caching, thanks @JackGrence
|
||||
- fixed aarch64 exit address
|
||||
- execution no longer stops at address 0x0
|
||||
- updated afl-system-config to support Arch Linux weirdness and increase
|
||||
MacOS shared memory
|
||||
- updated the grammar custom mutator to the newest version
|
||||
- add -d (add dead fuzzer stats) to afl-whatsup
|
||||
- added AFL_PRINT_FILENAMES to afl-showmap/cmin to print the
|
||||
current filename
|
||||
- afl-showmap/cmin will now process queue items in alphabetical order
|
||||
|
||||
### Version ++3.12c (release)
|
||||
- afl-fuzz:
|
||||
- added AFL_TARGET_ENV variable to pass extra env vars to the target
|
||||
(for things like LD_LIBRARY_PATH)
|
||||
- fix map detection, AFL_MAP_SIZE not needed anymore for most cases
|
||||
- fix counting favorites (just a display thing)
|
||||
- afl-cc:
|
||||
- fix cmplog rtn (rare crash and not being able to gather ptr data)
|
||||
- fix our own PCGUARD implementation to compile with llvm 10.0.1
|
||||
- link runtime not to shared libs
|
||||
- ensure shared libraries are properly built and instrumented
|
||||
- AFL_LLVM_INSTRUMENT_ALLOW/DENY were not implemented for LTO, added
|
||||
- show correct LLVM PCGUARD NATIVE mode when auto switching to it
|
||||
and keep fsanitize-coverage-*list=...
|
||||
Short mnemnonic NATIVE is now also accepted.
|
||||
- qemu_mode (thanks @realmadsci):
|
||||
- move AFL_PRELOAD and AFL_USE_QASAN logic inside afl-qemu-trace
|
||||
- add AFL_QEMU_CUSTOM_BIN
|
||||
- unicorn_mode
|
||||
- accidently removed the subfolder from github, re-added
|
||||
- added DEFAULT_PERMISSION to config.h for all files created, default
|
||||
to 0600
|
||||
|
||||
### Version ++3.11c (release)
|
||||
- afl-fuzz:
|
||||
- better auto detection of map size
|
||||
- fix sanitizer settings (bug since 3.10c)
|
||||
- fix an off-by-one overwrite in cmplog
|
||||
- add non-unicode variants from unicode-looking dictionary entries
|
||||
- Rust custom mutator API improvements
|
||||
- Imported crash stats painted yellow on resume (only new ones are red)
|
||||
- afl-cc:
|
||||
- added AFL_NOOPT that will just pass everything to the normal
|
||||
gcc/clang compiler without any changes - to pass weird configure
|
||||
scripts
|
||||
- fixed a crash that can occur with ASAN + CMPLOG together plus
|
||||
better support for unicode (thanks to @stbergmann for reporting!)
|
||||
- fixed a crash in LAF transform for empty strings
|
||||
- handle erroneous setups in which multiple afl-compiler-rt are
|
||||
compiled into the target. This now also supports dlopen()
|
||||
instrumented libs loaded before the forkserver and even after the
|
||||
forkserver is started (then with collisions though)
|
||||
- the compiler rt was added also in object building (-c) which
|
||||
should have been fixed years ago but somewhere got lost :(
|
||||
- Renamed CTX to CALLER, added correct/real CTX implementation to
|
||||
CLASSIC
|
||||
- qemu_mode:
|
||||
- added AFL_QEMU_EXCLUDE_RANGES env by @realmadsci, thanks!
|
||||
- if no new/updated checkout is wanted, build with:
|
||||
NO_CHECKOUT=1 ./build_qemu_support.sh
|
||||
- we no longer perform a "git drop"
|
||||
- afl-cmin: support filenames with spaces
|
||||
|
||||
### Version ++3.10c (release)
|
||||
### Version ++3.01a (dev)
|
||||
- Mac OS ARM64 support
|
||||
- Android support fixed and updated by Joey Jiaojg - thanks!
|
||||
- New selective instrumentation option with __AFL_COVERAGE_* commands
|
||||
to be placed in the source code.
|
||||
Check out instrumentation/README.instrument_list.md
|
||||
- afl-fuzz
|
||||
- Making AFL_MAP_SIZE (mostly) obsolete - afl-fuzz now learns on
|
||||
start the target map size
|
||||
- Making AFL_MAP_SIZE (mostly) obsolete - afl-fuzz now learns on start
|
||||
the target map size
|
||||
- upgraded cmplog/redqueen: solving for floating point, solving
|
||||
transformations (e.g. toupper, tolower, to/from hex, xor,
|
||||
arithmetics, etc.). This is costly hence new command line option
|
||||
`-l` that sets the intensity (values 1 to 3). Recommended is 2.
|
||||
- added `AFL_CMPLOG_ONLY_NEW` to not use cmplog on initial seeds
|
||||
from `-i` or resumes (these have most likely already been done)
|
||||
arithmetics, etc.). this is costly hence new command line option
|
||||
-l that sets the intensity (values 1 to 3). recommended is 1 or 2.
|
||||
- added `AFL_CMPLOG_ONLY_NEW` to not use cmplog on initial testcases from
|
||||
`-i` or resumes (as these have most likely already been done)
|
||||
- fix crash for very, very fast targets+systems (thanks to mhlakhani
|
||||
for reporting)
|
||||
- on restarts (`-i`)/autoresume (AFL_AUTORESUME) the stats are now
|
||||
- on restarts (-i)/autoresume (AFL_AUTORESUME) the stats are now
|
||||
reloaded and used, thanks to Vimal Joseph for this patch!
|
||||
- changed the meaning of '+' of the '-t' option, it now means to
|
||||
auto-calculate the timeout with the value given being the max
|
||||
timeout. The original meaning of skipping timeouts instead of
|
||||
abort is now inherent to the -t option.
|
||||
- if deterministic mode is active (`-D`, or `-M` without `-d`) then
|
||||
we sync after every queue entry as this can take very long time
|
||||
otherwise
|
||||
- added minimum SYNC_TIME to include/config.h (30 minutes default)
|
||||
- if determinstic mode is active (-D, or -M without -d) then we sync
|
||||
after every queue entry as this can take very long time otherwise
|
||||
- better detection if a target needs a large shared map
|
||||
- fix for `-Z`
|
||||
- fixed a few crashes
|
||||
- fix for -Z
|
||||
- switched to an even faster RNG
|
||||
- added hghwng's patch for faster trace map analysis
|
||||
- printing suggestions for mistyped `AFL_` env variables
|
||||
- added Rust bindings for custom mutators (thanks @julihoh)
|
||||
- afl-cc
|
||||
- allow instrumenting LLVMFuzzerTestOneInput
|
||||
- fixed endless loop for allow/blocklist lines starting with a
|
||||
comment (thanks to Zherya for reporting)
|
||||
- cmplog/redqueen now also tracks floating point, _ExtInt() + 128bit
|
||||
- cmplog/redqueen can now process basic libc++ and libstdc++
|
||||
std::string comparisons (no position or length type variants)
|
||||
- added support for __afl_coverage_interesting() for LTO and our
|
||||
own PCGUARD (llvm 10.0.1+), read more about this function and
|
||||
selective coverage in instrumentation/README.instrument_list.md
|
||||
std::string comparisons (though no position or length type variants)
|
||||
- added support for __afl_coverage_interesting() for LTO and
|
||||
and our own PCGUARD (llvm 10.0.1+), read more about this function
|
||||
and selective coverage in instrumentation/README.instrument_list.md
|
||||
- added AFL_LLVM_INSTRUMENT option NATIVE for native clang pc-guard
|
||||
support (less performant than our own), GCC for old afl-gcc and
|
||||
CLANG for old afl-clang
|
||||
- fixed a potential crash in the LAF feature
|
||||
- workaround for llvm bitcast lto bug
|
||||
- workaround for llvm 13
|
||||
- qemuafl
|
||||
- QASan (address sanitizer for Qemu) ported to qemuafl!
|
||||
See qemu_mode/libqasan/README.md
|
||||
@ -212,17 +55,14 @@ sending a mail to <afl-users+subscribe@googlegroups.com>.
|
||||
- solved an issue when dumping the memory maps (thanks wizche)
|
||||
- Android support for QASan
|
||||
- unicornafl
|
||||
- Substantial speed gains in python bindings for certain use cases
|
||||
- Substential speed gains in python bindings for certain use cases
|
||||
- Improved rust bindings
|
||||
- Added a new example harness to compare python, c and rust bindings
|
||||
- afl-cmin and afl-showmap now support the -f option
|
||||
- afl_plot now also generates a graph on the discovered edges
|
||||
- Added a new example harness to compare python, c, and rust bindings
|
||||
- changed default: no memory limit for afl-cmin and afl-cmin.bash
|
||||
- warn on any _AFL and __AFL env vars.
|
||||
- set AFL_IGNORE_UNKNOWN_ENVS to not warn on unknown AFL_... env vars
|
||||
- warn on any _AFL and __AFL env vars
|
||||
- added dummy Makefile to instrumentation/
|
||||
- Updated utils/afl_frida to be 5% faster, 7% on x86_x64
|
||||
- Added `AFL_KILL_SIGNAL` env variable (thanks @v-p-b)
|
||||
- Added AFL_KILL_SIGNAL env variable (thanks @v-p-b)
|
||||
- @Edznux added a nice documentation on how to use rpc.statsd with
|
||||
afl++ in docs/rpc_statsd.md, thanks!
|
||||
|
||||
|
||||
37
docs/FAQ.md
37
docs/FAQ.md
@ -3,7 +3,6 @@
|
||||
## Contents
|
||||
|
||||
* [What is the difference between afl and afl++?](#what-is-the-difference-between-afl-and-afl)
|
||||
* [I got a weird compile error from clang](#i-got-a-weird-compile-error-from-clang)
|
||||
* [How to improve the fuzzing speed?](#how-to-improve-the-fuzzing-speed)
|
||||
* [How do I fuzz a network service?](#how-do-i-fuzz-a-network-service)
|
||||
* [How do I fuzz a GUI program?](#how-do-i-fuzz-a-gui-program)
|
||||
@ -36,26 +35,6 @@ flexible and feature rich guided fuzzer available as open source.
|
||||
And in independent fuzzing benchmarks it is one of the best fuzzers available,
|
||||
e.g. [Fuzzbench Report](https://www.fuzzbench.com/reports/2020-08-03/index.html)
|
||||
|
||||
## I got a weird compile error from clang
|
||||
|
||||
If you see this kind of error when trying to instrument a target with afl-cc/
|
||||
afl-clang-fast/afl-clang-lto:
|
||||
```
|
||||
/prg/tmp/llvm-project/build/bin/clang-13: symbol lookup error: /usr/local/bin/../lib/afl//cmplog-instructions-pass.so: undefined symbol: _ZNK4llvm8TypeSizecvmEv
|
||||
clang-13: error: unable to execute command: No such file or directory
|
||||
clang-13: error: clang frontend command failed due to signal (use -v to see invocation)
|
||||
clang version 13.0.0 (https://github.com/llvm/llvm-project 1d7cf550721c51030144f3cd295c5789d51c4aad)
|
||||
Target: x86_64-unknown-linux-gnu
|
||||
Thread model: posix
|
||||
InstalledDir: /prg/tmp/llvm-project/build/bin
|
||||
clang-13: note: diagnostic msg:
|
||||
********************
|
||||
```
|
||||
Then this means that your OS updated the clang installation from an upgrade
|
||||
package and because of that the afl++ llvm plugins do not match anymore.
|
||||
|
||||
Solution: `git pull ; make clean install` of afl++
|
||||
|
||||
## How to improve the fuzzing speed?
|
||||
|
||||
1. Use [llvm_mode](docs/llvm_mode/README.md): afl-clang-lto (llvm >= 11) or afl-clang-fast (llvm >= 9 recommended)
|
||||
@ -188,7 +167,13 @@ Four steps are required to do this and it also requires quite some knowledge
|
||||
of coding and/or disassembly and is effectively possible only with
|
||||
afl-clang-fast PCGUARD and afl-clang-lto LTO instrumentation.
|
||||
|
||||
1. First step: Instrument to be able to find the responsible function(s).
|
||||
1. First step: Identify which edge ID numbers are unstable
|
||||
|
||||
run the target with `export AFL_DEBUG=1` for a few minutes then terminate.
|
||||
The out/fuzzer_stats file will then show the edge IDs that were identified
|
||||
as unstable.
|
||||
|
||||
2. Second step: Find the responsible function(s).
|
||||
|
||||
a) For LTO instrumented binaries this can be documented during compile
|
||||
time, just set `export AFL_LLVM_DOCUMENT_IDS=/path/to/a/file`.
|
||||
@ -211,14 +196,6 @@ afl-clang-fast PCGUARD and afl-clang-lto LTO instrumentation.
|
||||
recompile with the two mentioned above. This is just for
|
||||
identifying the functions that have unstable edges.
|
||||
|
||||
2. Second step: Identify which edge ID numbers are unstable
|
||||
|
||||
run the target with `export AFL_DEBUG=1` for a few minutes then terminate.
|
||||
The out/fuzzer_stats file will then show the edge IDs that were identified
|
||||
as unstable in the `var_bytes` entry. You can match these numbers
|
||||
directly to the data you created in the first step.
|
||||
Now you know which functions are responsible for the instability
|
||||
|
||||
3. Third step: create a text file with the filenames/functions
|
||||
|
||||
Identify which source code files contain the functions that you need to
|
||||
|
||||
@ -65,17 +65,22 @@ The QEMU mode is currently supported only on Linux. I think it's just a QEMU
|
||||
problem, I couldn't get a vanilla copy of user-mode emulation support working
|
||||
correctly on BSD at all.
|
||||
|
||||
## 3. MacOS X on x86 and arm64 (M1)
|
||||
## 3. MacOS X on x86
|
||||
|
||||
MacOS X should work, but there are some gotchas due to the idiosyncrasies of
|
||||
the platform. On top of this, I have limited release testing capabilities
|
||||
and depend mostly on user feedback.
|
||||
|
||||
To build AFL, install llvm (and perhaps gcc) from brew and follow the general
|
||||
instructions for Linux. If possible avoid Xcode at all cost.
|
||||
To build AFL, install Xcode and follow the general instructions for Linux.
|
||||
|
||||
afl-gcc will fail unless you have GCC installed, but that is using outdated
|
||||
instrumentation anyway. You don't want that.
|
||||
The Xcode 'gcc' tool is just a wrapper for clang, so be sure to use afl-clang
|
||||
to compile any instrumented binaries; afl-gcc will fail unless you have GCC
|
||||
installed from another source (in which case, please specify `AFL_CC` and
|
||||
`AFL_CXX` to point to the "real" GCC binaries).
|
||||
|
||||
Only 64-bit compilation will work on the platform; porting the 32-bit
|
||||
instrumentation would require a fair amount of work due to the way OS X
|
||||
handles relocations, and today, virtually all MacOS X boxes are 64-bit.
|
||||
|
||||
The crash reporting daemon that comes by default with MacOS X will cause
|
||||
problems with fuzzing. You need to turn it off by following the instructions
|
||||
@ -93,42 +98,10 @@ and definitely don't look POSIX-compliant. This means two things:
|
||||
|
||||
User emulation mode of QEMU does not appear to be supported on MacOS X, so
|
||||
black-box instrumentation mode (`-Q`) will not work.
|
||||
However Frida mode (`-O`) should work on x86 and arm64 MacOS boxes.
|
||||
|
||||
MacOS X supports SYSV shared memory used by AFL's instrumentation, but the
|
||||
default settings aren't usable with AFL++. The default settings on 10.14 seem
|
||||
to be:
|
||||
|
||||
```bash
|
||||
$ ipcs -M
|
||||
IPC status from <running system> as of XXX
|
||||
shminfo:
|
||||
shmmax: 4194304 (max shared memory segment size)
|
||||
shmmin: 1 (min shared memory segment size)
|
||||
shmmni: 32 (max number of shared memory identifiers)
|
||||
shmseg: 8 (max shared memory segments per process)
|
||||
shmall: 1024 (max amount of shared memory in pages)
|
||||
```
|
||||
|
||||
To temporarily change your settings to something minimally usable with AFL++,
|
||||
run these commands as root:
|
||||
|
||||
```bash
|
||||
sysctl kern.sysv.shmmax=8388608
|
||||
sysctl kern.sysv.shmall=4096
|
||||
```
|
||||
|
||||
If you're running more than one instance of AFL you likely want to make `shmall`
|
||||
bigger and increase `shmseg` as well:
|
||||
|
||||
```bash
|
||||
sysctl kern.sysv.shmmax=8388608
|
||||
sysctl kern.sysv.shmseg=48
|
||||
sysctl kern.sysv.shmall=98304
|
||||
```
|
||||
|
||||
See http://www.spy-hill.com/help/apple/SharedMemory.html for documentation for
|
||||
these settings and how to make them permanent.
|
||||
The llvm instrumentation requires a fully-operational installation of clang. The one that
|
||||
comes with Xcode is missing some of the essential headers and helper tools.
|
||||
See README.llvm.md for advice on how to build the compiler from scratch.
|
||||
|
||||
## 4. Linux or *BSD on non-x86 systems
|
||||
|
||||
|
||||
43
docs/PATCHES.md
Normal file
43
docs/PATCHES.md
Normal file
@ -0,0 +1,43 @@
|
||||
# Applied Patches
|
||||
|
||||
The following patches from https://github.com/vanhauser-thc/afl-patches
|
||||
have been installed or not installed:
|
||||
|
||||
|
||||
## INSTALLED
|
||||
```
|
||||
afl-llvm-fix.diff by kcwu(at)csie(dot)org
|
||||
afl-sort-all_uniq-fix.diff by legarrec(dot)vincent(at)gmail(dot)com
|
||||
laf-intel.diff by heiko(dot)eissfeldt(at)hexco(dot)de
|
||||
afl-llvm-optimize.diff by mh(at)mh-sec(dot)de
|
||||
afl-fuzz-tmpdir.diff by mh(at)mh-sec(dot)de
|
||||
afl-fuzz-79x24.diff by heiko(dot)eissfeldt(at)hexco(dot)de
|
||||
afl-fuzz-fileextensionopt.diff tbd
|
||||
afl-as-AFL_INST_RATIO.diff by legarrec(dot)vincent(at)gmail(dot)com
|
||||
afl-qemu-ppc64.diff by william(dot)barsse(at)airbus(dot)com
|
||||
afl-qemu-optimize-entrypoint.diff by mh(at)mh-sec(dot)de
|
||||
afl-qemu-speed.diff by abiondo on github
|
||||
afl-qemu-optimize-map.diff by mh(at)mh-sec(dot)de
|
||||
```
|
||||
|
||||
+ llvm_mode ngram prev_loc coverage (github.com/adrianherrera/afl-ngram-pass)
|
||||
+ Custom mutator (native library) (by kyakdan)
|
||||
+ unicorn_mode (modernized and updated by domenukk)
|
||||
+ instrim (https://github.com/csienslab/instrim) was integrated
|
||||
+ MOpt (github.com/puppet-meteor/MOpt-AFL) was imported
|
||||
+ AFLfast additions (github.com/mboehme/aflfast) were incorporated.
|
||||
+ Qemu 3.1 upgrade with enhancement patches (github.com/andreafioraldi/afl)
|
||||
+ Python mutator modules support (github.com/choller/afl)
|
||||
+ Instrument file list in LLVM mode (github.com/choller/afl)
|
||||
+ forkserver patch for afl-tmin (github.com/nccgroup/TriforceAFL)
|
||||
|
||||
|
||||
## NOT INSTALLED
|
||||
|
||||
```
|
||||
afl-fuzz-context_sensitive.diff - changes too much of the behaviour
|
||||
afl-tmpfs.diff - same as afl-fuzz-tmpdir.diff but more complex
|
||||
afl-cmin-reduce-dataset.diff - unsure of the impact
|
||||
afl-llvm-fix2.diff - not needed with the other patches
|
||||
```
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# AFL quick start guide
|
||||
|
||||
You should read [README.md](../README.md) - it's pretty short. If you really can't, here's
|
||||
You should read [README.md](README.md) - it's pretty short. If you really can't, here's
|
||||
how to hit the ground running:
|
||||
|
||||
1) Compile AFL with 'make'. If build fails, see [INSTALL.md](INSTALL.md) for tips.
|
||||
@ -18,12 +18,14 @@ how to hit the ground running:
|
||||
custom SIGSEGV or SIGABRT handlers and background processes. For tips on
|
||||
detecting non-crashing flaws, see section 11 in [README.md](README.md) .
|
||||
|
||||
3) Compile the program / library to be fuzzed using afl-cc. A common way to
|
||||
3) Compile the program / library to be fuzzed using afl-gcc. A common way to
|
||||
do this would be:
|
||||
|
||||
CC=/path/to/afl-cc CXX=/path/to/afl-c++ ./configure --disable-shared
|
||||
CC=/path/to/afl-gcc CXX=/path/to/afl-g++ ./configure --disable-shared
|
||||
make clean all
|
||||
|
||||
If program build fails, ping <afl-users@googlegroups.com>.
|
||||
|
||||
4) Get a small but valid input file that makes sense to the program. When
|
||||
fuzzing verbose syntax (SQL, HTTP, etc), create a dictionary as described in
|
||||
dictionaries/README.md, too.
|
||||
@ -39,6 +41,9 @@ how to hit the ground running:
|
||||
6) Investigate anything shown in red in the fuzzer UI by promptly consulting
|
||||
[status_screen.md](status_screen.md).
|
||||
|
||||
7) compile and use llvm_mode (afl-clang-fast/afl-clang-fast++) as it is way
|
||||
faster and has a few cool features
|
||||
|
||||
8) There is a basic docker build with 'docker build -t aflplusplus .'
|
||||
|
||||
That's it. Sit back, relax, and - time permitting - try to skim through the
|
||||
|
||||
54
docs/README.MOpt.md
Normal file
54
docs/README.MOpt.md
Normal file
@ -0,0 +1,54 @@
|
||||
# MOpt(imized) AFL by <puppet@zju.edu.cn>
|
||||
|
||||
### 1. Description
|
||||
MOpt-AFL is a AFL-based fuzzer that utilizes a customized Particle Swarm
|
||||
Optimization (PSO) algorithm to find the optimal selection probability
|
||||
distribution of operators with respect to fuzzing effectiveness.
|
||||
More details can be found in the technical report.
|
||||
|
||||
### 2. Cite Information
|
||||
Chenyang Lyu, Shouling Ji, Chao Zhang, Yuwei Li, Wei-Han Lee, Yu Song and
|
||||
Raheem Beyah, MOPT: Optimized Mutation Scheduling for Fuzzers,
|
||||
USENIX Security 2019.
|
||||
|
||||
### 3. Seed Sets
|
||||
We open source all the seed sets used in the paper
|
||||
"MOPT: Optimized Mutation Scheduling for Fuzzers".
|
||||
|
||||
### 4. Experiment Results
|
||||
The experiment results can be found in
|
||||
https://drive.google.com/drive/folders/184GOzkZGls1H2NuLuUfSp9gfqp1E2-lL?usp=sharing.
|
||||
We only open source the crash files since the space is limited.
|
||||
|
||||
### 5. Technical Report
|
||||
MOpt_TechReport.pdf is the technical report of the paper
|
||||
"MOPT: Optimized Mutation Scheduling for Fuzzers", which contains more deatails.
|
||||
|
||||
### 6. Parameter Introduction
|
||||
Most important, you must add the parameter `-L` (e.g., `-L 0`) to launch the
|
||||
MOpt scheme.
|
||||
|
||||
Option '-L' controls the time to move on to the pacemaker fuzzing mode.
|
||||
'-L t': when MOpt-AFL finishes the mutation of one input, if it has not
|
||||
discovered any new unique crash or path for more than t minutes, MOpt-AFL will
|
||||
enter the pacemaker fuzzing mode.
|
||||
|
||||
Setting 0 will enter the pacemaker fuzzing mode at first, which is
|
||||
recommended in a short time-scale evaluation.
|
||||
|
||||
Setting -1 will enable both pacemaker mode and normal aflmutation fuzzing in
|
||||
parallel.
|
||||
|
||||
Other important parameters can be found in afl-fuzz.c, for instance,
|
||||
|
||||
'swarm_num': the number of the PSO swarms used in the fuzzing process.
|
||||
'period_pilot': how many times MOpt-AFL will execute the target program
|
||||
in the pilot fuzzing module, then it will enter the core fuzzing module.
|
||||
'period_core': how many times MOpt-AFL will execute the target program in the
|
||||
core fuzzing module, then it will enter the PSO updating module.
|
||||
'limit_time_bound': control how many interesting test cases need to be found
|
||||
before MOpt-AFL quits the pacemaker fuzzing mode and reuses the deterministic stage.
|
||||
0 < 'limit_time_bound' < 1, MOpt-AFL-tmp.
|
||||
'limit_time_bound' >= 1, MOpt-AFL-ever.
|
||||
|
||||
Have fun with MOpt in AFL!
|
||||
@ -41,33 +41,6 @@
|
||||
|
||||
As it is included in afl++ this needs no URL.
|
||||
|
||||
If you like to code a customized fuzzer without much work, we highly
|
||||
recommend to check out our sister project libafl which will support QEMU
|
||||
too:
|
||||
[https://github.com/AFLplusplus/LibAFL](https://github.com/AFLplusplus/LibAFL)
|
||||
|
||||
|
||||
## AFL FRIDA
|
||||
|
||||
In frida_mode you can fuzz binary-only targets easily like with QEMU,
|
||||
with the advantage that frida_mode also works on MacOS (both intel and M1).
|
||||
|
||||
If you want to fuzz a binary-only library then you can fuzz it with
|
||||
frida-gum via utils/afl_frida/, you will have to write a harness to
|
||||
call the target function in the library, use afl-frida.c as a template.
|
||||
|
||||
Both come with afl++ so this needs no URL.
|
||||
|
||||
You can also perform remote fuzzing with frida, e.g. if you want to fuzz
|
||||
on iPhone or Android devices, for this you can use
|
||||
[https://github.com/ttdennis/fpicker/](https://github.com/ttdennis/fpicker/)
|
||||
as an intermediate that uses afl++ for fuzzing.
|
||||
|
||||
If you like to code a customized fuzzer without much work, we highly
|
||||
recommend to check out our sister project libafl which supports Frida too:
|
||||
[https://github.com/AFLplusplus/LibAFL](https://github.com/AFLplusplus/LibAFL)
|
||||
Working examples already exist :-)
|
||||
|
||||
|
||||
## WINE+QEMU
|
||||
|
||||
@ -89,6 +62,13 @@
|
||||
As it is included in afl++ this needs no URL.
|
||||
|
||||
|
||||
## AFL FRIDA
|
||||
|
||||
If you want to fuzz a binary-only shared library then you can fuzz it with
|
||||
frida-gum via utils/afl_frida/, you will have to write a harness to
|
||||
call the target function in the library, use afl-frida.c as a template.
|
||||
|
||||
|
||||
## AFL UNTRACER
|
||||
|
||||
If you want to fuzz a binary-only shared library then you can fuzz it with
|
||||
@ -122,7 +102,7 @@
|
||||
[https://github.com/vanhauser-thc/afl-dyninst](https://github.com/vanhauser-thc/afl-dyninst)
|
||||
|
||||
|
||||
## RETROWRITE, ZAFL, ... other binary rewriter
|
||||
## RETROWRITE
|
||||
|
||||
If you have an x86/x86_64 binary that still has its symbols, is compiled
|
||||
with position independant code (PIC/PIE) and does not use most of the C++
|
||||
@ -131,7 +111,6 @@
|
||||
|
||||
It is at about 80-85% performance.
|
||||
|
||||
[https://git.zephyr-software.com/opensrc/zafl](https://git.zephyr-software.com/opensrc/zafl)
|
||||
[https://github.com/HexHive/retrowrite](https://github.com/HexHive/retrowrite)
|
||||
|
||||
|
||||
@ -178,6 +157,19 @@
|
||||
If anyone finds any coresight implementation for afl please ping me: vh@thc.org
|
||||
|
||||
|
||||
## FRIDA
|
||||
|
||||
Frida is a dynamic instrumentation engine like Pintool, Dyninst and Dynamorio.
|
||||
What is special is that it is written Python, and scripted with Javascript.
|
||||
It is mostly used to reverse binaries on mobile phones however can be used
|
||||
everywhere.
|
||||
|
||||
There is a WIP fuzzer available at [https://github.com/andreafioraldi/frida-fuzzer](https://github.com/andreafioraldi/frida-fuzzer)
|
||||
|
||||
There is also an early implementation in an AFL++ test branch:
|
||||
[https://github.com/AFLplusplus/AFLplusplus/tree/frida](https://github.com/AFLplusplus/AFLplusplus/tree/frida)
|
||||
|
||||
|
||||
## PIN & DYNAMORIO
|
||||
|
||||
Pintool and Dynamorio are dynamic instrumentation engines, and they can be
|
||||
@ -213,8 +205,7 @@
|
||||
* QSYM: [https://github.com/sslab-gatech/qsym](https://github.com/sslab-gatech/qsym)
|
||||
* Manticore: [https://github.com/trailofbits/manticore](https://github.com/trailofbits/manticore)
|
||||
* S2E: [https://github.com/S2E](https://github.com/S2E)
|
||||
* Tinyinst: [https://github.com/googleprojectzero/TinyInst](https://github.com/googleprojectzero/TinyInst) (Mac/Windows only)
|
||||
* Jackalope: [https://github.com/googleprojectzero/Jackalope](https://github.com/googleprojectzero/Jackalope)
|
||||
* Tinyinst [https://github.com/googleprojectzero/TinyInst](https://github.com/googleprojectzero/TinyInst) (Mac/Windows only)
|
||||
* ... please send me any missing that are good
|
||||
|
||||
|
||||
|
||||
@ -4,11 +4,6 @@ This file describes how you can implement custom mutations to be used in AFL.
|
||||
For now, we support C/C++ library and Python module, collectivelly named as the
|
||||
custom mutator.
|
||||
|
||||
There is also experimental support for Rust in `custom_mutators/rust`.
|
||||
Please refer to that directory for documentation.
|
||||
Run ```cargo doc -p custom_mutator --open``` in that directory to view the
|
||||
documentation in your web browser.
|
||||
|
||||
Implemented by
|
||||
- C/C++ library (`*.so`): Khaled Yakdan from Code Intelligence (<yakdan@code-intelligence.de>)
|
||||
- Python module: Christian Holler from Mozilla (<choller@mozilla.com>)
|
||||
@ -89,14 +84,11 @@ def queue_get(filename):
|
||||
|
||||
def queue_new_entry(filename_new_queue, filename_orig_queue):
|
||||
pass
|
||||
```
|
||||
|
||||
def introspection():
|
||||
return string
|
||||
|
||||
def deinit(): # optional for Python
|
||||
pass
|
||||
```
|
||||
|
||||
### Custom Mutation
|
||||
|
||||
- `init`:
|
||||
@ -123,7 +115,6 @@ def deinit(): # optional for Python
|
||||
Note that this function is optional - but it makes sense to use it.
|
||||
You would only skip this if `post_process` is used to fix checksums etc.
|
||||
so if you are using it e.g. as a post processing library.
|
||||
Note that a length > 0 *must* be returned!
|
||||
|
||||
- `describe` (optional):
|
||||
|
||||
@ -204,7 +195,9 @@ trimmed input. Here's a quick API description:
|
||||
arguments because we already have the initial buffer from `init_trim` and we
|
||||
can memorize the current state in the data variables. This can also save
|
||||
reparsing steps for each iteration. It should return the trimmed input
|
||||
buffer.
|
||||
buffer, where the returned data must not exceed the initial input data in
|
||||
length. Returning anything that is larger than the original data (passed to
|
||||
`init_trim`) will result in a fatal abort of AFL++.
|
||||
|
||||
- `post_trim` (optional)
|
||||
|
||||
@ -287,8 +280,8 @@ afl-fuzz /path/to/program
|
||||
|
||||
## 4) Example
|
||||
|
||||
Please see [example.c](../custom_mutators/examples/example.c) and
|
||||
[example.py](../custom_mutators/examples/example.py)
|
||||
Please see [example.c](../utils/custom_mutators/example.c) and
|
||||
[example.py](../utils/custom_mutators/example.py)
|
||||
|
||||
## 5) Other Resources
|
||||
|
||||
|
||||
122
docs/docs.md
122
docs/docs.md
@ -1,122 +0,0 @@
|
||||
# Restructure afl++'s documentation
|
||||
|
||||
## About us
|
||||
|
||||
We are dedicated to everything around fuzzing, our main and most well known
|
||||
contribution is the fuzzer `afl++` which is part of all major Unix
|
||||
distributions (e.g. Debian, Arch, FreeBSD, etc.) and is deployed on Google's
|
||||
oss-fuzz and clusterfuzz. It is rated the top fuzzer on Google's fuzzbench.
|
||||
|
||||
We are four individuals from Europe supported by a large community.
|
||||
|
||||
All our tools are open source.
|
||||
|
||||
## About the afl++ fuzzer project
|
||||
|
||||
afl++ inherited it's documentation from the original Google afl project.
|
||||
Since then it has been massively improved - feature and performance wise -
|
||||
and although the documenation has likewise been continued it has grown out
|
||||
of proportion.
|
||||
The documentation is done by non-natives to the English language, plus
|
||||
none of us has a writer background.
|
||||
|
||||
We see questions on afl++ usage on mailing lists (e.g. afl-users), discord
|
||||
channels, web forums and as issues in our repository.
|
||||
|
||||
This only increases as afl++ has been on the top of Google's fuzzbench
|
||||
statistics (which measures the performance of fuzzers) and is now being
|
||||
integrated in Google's oss-fuzz and clusterfuzz - and is in many Unix
|
||||
packaging repositories, e.g. Debian, FreeBSD, etc.
|
||||
|
||||
afl++ now has 44 (!) documentation files with 13k total lines of content.
|
||||
This is way too much.
|
||||
|
||||
Hence afl++ needs a complete overhaul of it's documentation, both on a
|
||||
organisation/structural level as well as the content.
|
||||
|
||||
Overall the following actions have to be performed:
|
||||
* Create a better structure of documentation so it is easier to find the
|
||||
information that is being looked for, combining and/or splitting up the
|
||||
existing documents as needed.
|
||||
* Rewrite some documentation to remove duplication. Several information is
|
||||
present several times in the documentation. These should be removed to
|
||||
where needed so that we have as little bloat as possible.
|
||||
* The documents have been written and modified by a lot of different people,
|
||||
most of them non-native English speaker. Hence an overall review where
|
||||
parts should be rewritten has to be performed and then the rewrite done.
|
||||
* Create a cheat-sheet for a very short best-setup build and run of afl++
|
||||
* Pictures explain more than 1000 words. We need at least 4 images that
|
||||
explain the workflow with afl++:
|
||||
- the build workflow
|
||||
- the fuzzing workflow
|
||||
- the fuzzing campaign management workflow
|
||||
- the overall workflow that is an overview of the above
|
||||
- maybe more? where the technical writes seems it necessary for
|
||||
understanding.
|
||||
|
||||
Requirements:
|
||||
* Documentation has to be in Markdown format
|
||||
* Images have to be either in SVG or PNG format.
|
||||
* All documentation should be (moved) in(to) docs/
|
||||
|
||||
The project does not require writing new documentation or tutorials beside the
|
||||
cheat sheet. The technical information for the cheat sheet will be provided by
|
||||
us.
|
||||
|
||||
## Metrics
|
||||
|
||||
afl++ is a the highest performant fuzzer publicly available - but is also the
|
||||
most feature rich and complex. With the publicity of afl++' success and
|
||||
deployment in Google projects internally and externally and availability as
|
||||
a package on most Linux distributions we see more and more issues being
|
||||
created and help requests on our Discord channel that would not be
|
||||
necessary if people would have read through all our documentation - which
|
||||
is unrealistic.
|
||||
|
||||
We expect the the new documenation after this project to be cleaner, easier
|
||||
accessible and lighter to digest by our users, resulting in much less
|
||||
help requests. On the other hand the amount of users using afl++ should
|
||||
increase as well as it will be more accessible which would also increase
|
||||
questions again - but overall resulting in a reduction of help requests.
|
||||
|
||||
In numbers: we currently have per week on average 5 issues on Github,
|
||||
10 questions on discord and 1 on mailing lists that would not be necessary
|
||||
with perfect documentation and perfect people.
|
||||
|
||||
We would consider this project a success if afterwards we only have
|
||||
2 issues on Github and 3 questions on discord anymore that would be answered
|
||||
by reading the documentation. The mailing list is usually used by the most
|
||||
novice users and we don't expect any less questions there.
|
||||
|
||||
## Project Budget
|
||||
|
||||
We have zero experience with technical writers, so this is very hard for us
|
||||
to calculate. We expect it to be a lot of work though because of the amount
|
||||
of documentation we have that needs to be restructured and partially rewritten
|
||||
(44 documents with 13k total lines of content).
|
||||
|
||||
We assume the daily rate of a very good and experienced technical writer in
|
||||
times of a pandemic to be ~500$ (according to web research), and calculate
|
||||
the overall amout of work to be around 20 days for everything incl. the
|
||||
graphics (but again - this is basically just guessing).
|
||||
|
||||
Technical Writer 10000$
|
||||
Volunteer stipends 0$ (waved)
|
||||
T-Shirts for the top 10 contributors and helpers to this documentation project:
|
||||
10 afl++ logo t-shirts 20$ each 200$
|
||||
10 shipping cost of t-shirts 10$ each 100$
|
||||
|
||||
Total: 10.300$
|
||||
(in the submission form 10.280$ was entered)
|
||||
|
||||
## Additional Information
|
||||
|
||||
We have participated in Google Summer of Code in 2020 and hope to be selected
|
||||
again in 2021.
|
||||
|
||||
We have no experience with a technical writer, but we will support that person
|
||||
with video calls, chats, emails and messaging, provide all necessary information
|
||||
and write technical contents that is required for the success of this project.
|
||||
It is clear to us that a technical writer knows how to write, but cannot know
|
||||
the technical details in a complex tooling like in afl++. This guidance, input,
|
||||
etc. has to come from us.
|
||||
@ -5,10 +5,6 @@
|
||||
users or for some types of custom fuzzing setups. See [README.md](README.md) for the general
|
||||
instruction manual.
|
||||
|
||||
Note that most tools will warn on any unknown AFL environment variables.
|
||||
This is for warning on typos that can happen. If you want to disable this
|
||||
check then set the `AFL_IGNORE_UNKNOWN_ENVS` environment variable.
|
||||
|
||||
## 1) Settings for all compilers
|
||||
|
||||
Starting with afl++ 3.0 there is only one compiler: afl-cc
|
||||
@ -22,21 +18,11 @@ To select the different instrumentation modes this can be done by
|
||||
`MODE` can be one of `LTO` (afl-clang-lto*), `LLVM` (afl-clang-fast*), `GCC_PLUGIN`
|
||||
(afl-g*-fast) or `GCC` (afl-gcc/afl-g++).
|
||||
|
||||
|
||||
Because (with the exception of the --afl-MODE command line option) the
|
||||
compile-time tools do not accept afl specific command-line options, they
|
||||
make fairly broad use of environmental variables instead:
|
||||
|
||||
- Some build/configure scripts break with afl++ compilers. To be able to
|
||||
pass them, do:
|
||||
```
|
||||
export CC=afl-cc
|
||||
export CXX=afl-c++
|
||||
export AFL_NOOPT=1
|
||||
./configure --disable-shared --disabler-werror
|
||||
unset AFL_NOOPT
|
||||
make
|
||||
```
|
||||
|
||||
- Most afl tools do not print any output if stdout/stderr are redirected.
|
||||
If you want to get the output into a file then set the `AFL_DEBUG`
|
||||
environment variable.
|
||||
@ -55,7 +41,7 @@ make fairly broad use of environmental variables instead:
|
||||
overridden.
|
||||
|
||||
- Setting `AFL_USE_ASAN` automatically enables ASAN, provided that your
|
||||
compiler supports it. Note that fuzzing with ASAN is mildly challenging
|
||||
compiler supports that. Note that fuzzing with ASAN is mildly challenging
|
||||
- see [notes_for_asan.md](notes_for_asan.md).
|
||||
|
||||
(You can also enable MSAN via `AFL_USE_MSAN`; ASAN and MSAN come with the
|
||||
@ -64,13 +50,6 @@ make fairly broad use of environmental variables instead:
|
||||
there is the Control Flow Integrity sanitizer that can be activated by
|
||||
`AFL_USE_CFISAN=1`)
|
||||
|
||||
- Setting `AFL_USE_LSAN` automatically enables Leak-Sanitizer, provided
|
||||
that your compiler supports it. To perform a leak check within your
|
||||
program at a certain point (such as at the end of an __AFL_LOOP),
|
||||
you can run the macro __AFL_LEAK_CHECK(); which will cause
|
||||
an abort if any memory is leaked (you can combine this with the
|
||||
LSAN_OPTIONS=suppressions option to supress some known leaks).
|
||||
|
||||
- Setting `AFL_CC`, `AFL_CXX`, and `AFL_AS` lets you use alternate downstream
|
||||
compilation tools, rather than the default 'clang', 'gcc', or 'as' binaries
|
||||
in your `$PATH`.
|
||||
@ -108,6 +87,9 @@ make fairly broad use of environmental variables instead:
|
||||
- Setting `AFL_QUIET` will prevent afl-cc and afl-as banners from being
|
||||
displayed during compilation, in case you find them distracting.
|
||||
|
||||
- Setting `AFL_CAL_FAST` will speed up the initial calibration, if the
|
||||
application is very slow.
|
||||
|
||||
## 2) Settings for LLVM and LTO: afl-clang-fast / afl-clang-fast++ / afl-clang-lto / afl-clang-lto++
|
||||
|
||||
The native instrumentation helpers (instrumentation and gcc_plugin) accept a subset
|
||||
@ -134,15 +116,16 @@ Then there are a few specific features that are only available in instrumentatio
|
||||
PCGUARD - our own pcgard based instrumentation (default)
|
||||
NATIVE - clang's original pcguard based instrumentation
|
||||
CLASSIC - classic AFL (map[cur_loc ^ prev_loc >> 1]++) (default)
|
||||
CFG - InsTrim instrumentation (see below)
|
||||
LTO - LTO instrumentation (see below)
|
||||
CTX - context sensitive instrumentation (see below)
|
||||
NGRAM-x - deeper previous location coverage (from NGRAM-2 up to NGRAM-16)
|
||||
GCC - outdated gcc instrumentation
|
||||
CLANG - outdated clang instrumentation
|
||||
In CLASSIC you can also specify CTX and/or NGRAM, seperate the options
|
||||
with a comma "," then, e.g.:
|
||||
`AFL_LLVM_INSTRUMENT=CLASSIC,CTX,NGRAM-4`
|
||||
Note that this is actually not a good idea to use both CTX and NGRAM :)
|
||||
In CLASSIC (default) and CFG/INSTRIM you can also specify CTX and/or
|
||||
NGRAM, seperate the options with a comma "," then, e.g.:
|
||||
`AFL_LLVM_INSTRUMENT=CFG,CTX,NGRAM-4`
|
||||
Not that this is a good idea to use both CTX and NGRAM :)
|
||||
|
||||
### LTO
|
||||
|
||||
@ -173,9 +156,29 @@ Then there are a few specific features that are only available in instrumentatio
|
||||
This defaults to 1
|
||||
- `AFL_LLVM_LTO_DONTWRITEID` prevents that the highest location ID written
|
||||
into the instrumentation is set in a global variable
|
||||
- `AFL_LLVM_LTO_UNREACHABLE` will *not* instrument the binary for fuzzing but
|
||||
instead perform an analysis on unreachable functions
|
||||
|
||||
See [instrumentation/README.lto.md](../instrumentation/README.lto.md) for more information.
|
||||
|
||||
### INSTRIM
|
||||
|
||||
This feature increases the speed by ~15% without any disadvantages to the
|
||||
classic instrumentation.
|
||||
|
||||
Note that there is also an LTO version (if you have llvm 11 or higher) -
|
||||
that is the best instrumentation we have. Use `afl-clang-lto` to activate.
|
||||
The InsTrim LTO version additionally has all the options and features of
|
||||
LTO (see above).
|
||||
|
||||
- Setting `AFL_LLVM_INSTRIM` or `AFL_LLVM_INSTRUMENT=CFG` activates this mode
|
||||
|
||||
- Setting `AFL_LLVM_INSTRIM_LOOPHEAD=1` expands on INSTRIM to optimize loops.
|
||||
afl-fuzz will only be able to see the path the loop took, but not how
|
||||
many times it was called (unless it is a complex loop).
|
||||
|
||||
See [instrumentation/README.instrim.md](../instrumentation/README.instrim.md)
|
||||
|
||||
### NGRAM
|
||||
|
||||
- Setting `AFL_LLVM_NGRAM_SIZE` or `AFL_LLVM_INSTRUMENT=NGRAM-{value}`
|
||||
@ -228,12 +231,6 @@ Then there are a few specific features that are only available in instrumentatio
|
||||
|
||||
See [instrumentation/README.instrument_list.md](../instrumentation/README.instrument_list.md) for more information.
|
||||
|
||||
### Thread safe instrumentation counters (in all modes)
|
||||
|
||||
- Setting `AFL_LLVM_THREADSAFE_INST` will inject code that implements thread
|
||||
safe counters. The overhead is a little bit higher compared to the older
|
||||
non-thread safe case. Note that this disables neverzero (see below).
|
||||
|
||||
### NOT_ZERO
|
||||
|
||||
- Setting `AFL_LLVM_NOT_ZERO=1` during compilation will use counters
|
||||
@ -287,13 +284,6 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
normally indicated by the cycle counter in the UI turning green. May be
|
||||
convenient for some types of automated jobs.
|
||||
|
||||
- `AFL_EXIT_ON_TIME` Causes afl-fuzz to terminate if no new paths were
|
||||
found within a specified period of time (in seconds). May be convenient
|
||||
for some types of automated jobs.
|
||||
|
||||
- `AFL_EXIT_ON_SEED_ISSUES` will restore the vanilla afl-fuzz behaviour
|
||||
which does not allow crashes or timeout seeds in the initial -i corpus.
|
||||
|
||||
- `AFL_MAP_SIZE` sets the size of the shared map that afl-fuzz, afl-showmap,
|
||||
afl-tmin and afl-analyze create to gather instrumentation data from
|
||||
the target. This must be equal or larger than the size the target was
|
||||
@ -315,12 +305,14 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
on Linux systems. This slows things down, but lets you run more instances
|
||||
of afl-fuzz than would be prudent (if you really want to).
|
||||
|
||||
- Setting `AFL_TRY_AFFINITY` tries to attempt binding to a specific CPU core
|
||||
on Linux systems, but will not terminate if that fails.
|
||||
|
||||
- Setting `AFL_NO_AUTODICT` will not load an LTO generated auto dictionary
|
||||
that is compiled into the target.
|
||||
|
||||
- `AFL_SKIP_CRASHES` causes AFL++ to tolerate crashing files in the input
|
||||
queue. This can help with rare situations where a program crashes only
|
||||
intermittently, but it's not really recommended under normal operating
|
||||
conditions.
|
||||
|
||||
- Setting `AFL_HANG_TMOUT` allows you to specify a different timeout for
|
||||
deciding if a particular test case is a "hang". The default is 1 second
|
||||
or the value of the `-t` parameter, whichever is larger. Dialing the value
|
||||
@ -356,7 +348,6 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
and shell scripts; and `AFL_DUMB_FORKSRV` in conjunction with the `-n`
|
||||
setting to instruct afl-fuzz to still follow the fork server protocol
|
||||
without expecting any instrumentation data in return.
|
||||
Note that this also turns off auto map size detection.
|
||||
|
||||
- When running in the `-M` or `-S` mode, setting `AFL_IMPORT_FIRST` causes the
|
||||
fuzzer to import test cases from other instances before doing anything
|
||||
@ -383,18 +374,12 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
|
||||
- `AFL_FAST_CAL` keeps the calibration stage about 2.5x faster (albeit less
|
||||
precise), which can help when starting a session against a slow target.
|
||||
`AFL_CAL_FAST` works too.
|
||||
|
||||
- The CPU widget shown at the bottom of the screen is fairly simplistic and
|
||||
may complain of high load prematurely, especially on systems with low core
|
||||
counts. To avoid the alarming red color, you can set `AFL_NO_CPU_RED`.
|
||||
|
||||
- In QEMU mode (-Q) and Frida mode (-O), `AFL_PATH` will
|
||||
be searched for afl-qemu-trace and afl-frida-trace.so.
|
||||
|
||||
- In QEMU mode (-Q), setting `AFL_QEMU_CUSTOM_BIN` cause afl-fuzz to skip
|
||||
prepending `afl-qemu-trace` to your command line. Use this if you wish to use a
|
||||
custom afl-qemu-trace or if you need to modify the afl-qemu-trace arguments.
|
||||
- In QEMU mode (-Q), `AFL_PATH` will be searched for afl-qemu-trace.
|
||||
|
||||
- Setting `AFL_CYCLE_SCHEDULES` will switch to a different schedule everytime
|
||||
a cycle is finished.
|
||||
@ -407,12 +392,6 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
without disrupting the afl-fuzz process itself. This is useful, among other
|
||||
things, for bootstrapping libdislocator.so.
|
||||
|
||||
- Setting `AFL_TARGET_ENV` causes AFL++ to set extra environment variables
|
||||
for the target binary. Example: `AFL_TARGET_ENV="VAR1=1 VAR2='a b c'" afl-fuzz ... `
|
||||
This exists mostly for things like `LD_LIBRARY_PATH` but it would theoretically
|
||||
allow fuzzing of AFL++ itself (with 'target' AFL++ using some AFL_ vars that
|
||||
would disrupt work of 'fuzzer' AFL++).
|
||||
|
||||
- Setting `AFL_NO_UI` inhibits the UI altogether, and just periodically prints
|
||||
some basic stats. This behavior is also automatically triggered when the
|
||||
output from afl-fuzz is redirected to a file or to a pipe.
|
||||
@ -423,19 +402,8 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
- Setting `AFL_FORCE_UI` will force painting the UI on the screen even if
|
||||
no valid terminal was detected (for virtual consoles)
|
||||
|
||||
- If you are using persistent mode (you should, see [instrumentation/README.persistent_mode.md](instrumentation/README.persistent_mode.md))
|
||||
some targets keep inherent state due which a detected crash testcase does
|
||||
not crash the target again when the testcase is given. To be able to still
|
||||
re-trigger these crashes you can use the `AFL_PERSISTENT_RECORD` variable
|
||||
with a value of how many previous fuzz cases to keep prio a crash.
|
||||
if set to e.g. 10, then the 9 previous inputs are written to
|
||||
out/default/crashes as RECORD:000000,cnt:000000 to RECORD:000000,cnt:000008
|
||||
and RECORD:000000,cnt:000009 being the crash case.
|
||||
NOTE: This option needs to be enabled in config.h first!
|
||||
|
||||
- If you are Jakub, you may need `AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES`.
|
||||
Others need not apply, unless they also want to disable the
|
||||
`/proc/sys/kernel/core_pattern` check.
|
||||
Others need not apply.
|
||||
|
||||
- Benchmarking only: `AFL_BENCH_JUST_ONE` causes the fuzzer to exit after
|
||||
processing the first queue entry; and `AFL_BENCH_UNTIL_CRASH` causes it to
|
||||
@ -482,7 +450,6 @@ checks or alter some of the more exotic semantics of the tool:
|
||||
`banner` corresponds to the name of the fuzzer provided through `-M/-S`.
|
||||
`afl_version` corresponds to the currently running afl version (e.g `++3.0c`).
|
||||
Default (empty/non present) will add no tags to the metrics.
|
||||
See [rpc_statsd.md](rpc_statsd.md) for more information.
|
||||
|
||||
- Setting `AFL_CRASH_EXITCODE` sets the exit code afl treats as crash.
|
||||
For example, if `AFL_CRASH_EXITCODE='-1'` is set, each input resulting
|
||||
@ -552,7 +519,7 @@ The QEMU wrapper used to instrument binary-only code supports several settings:
|
||||
- With `AFL_USE_QASAN` you can enable QEMU AddressSanitizer for dynamically
|
||||
linked binaries.
|
||||
|
||||
- With `AFL_QEMU_FORCE_DFL` you force QEMU to ignore the registered signal
|
||||
- With `AFL_QEMU_FORCE_DFL` you force QEMU to ignore the registered singal
|
||||
handlers of the target.
|
||||
|
||||
## 6) Settings for afl-cmin
|
||||
@ -570,9 +537,6 @@ The corpus minimization script offers very little customization:
|
||||
a modest security risk on multi-user systems with rogue users, but should
|
||||
be safe on dedicated fuzzing boxes.
|
||||
|
||||
- `AFL_PRINT_FILENAMES` prints each filename to stdout, as it gets processed.
|
||||
This can help when embedding `afl-cmin` or `afl-showmap` in other scripts scripting.
|
||||
|
||||
## 7) Settings for afl-tmin
|
||||
|
||||
Virtually nothing to play with. Well, in QEMU mode (`-Q`), `AFL_PATH` will be
|
||||
@ -626,7 +590,7 @@ optimal values if not already present in the environment:
|
||||
override this by setting `LD_BIND_LAZY` beforehand, but it is almost
|
||||
certainly pointless.
|
||||
|
||||
- By default, `ASAN_OPTIONS` are set to (among others):
|
||||
- By default, `ASAN_OPTIONS` are set to:
|
||||
```
|
||||
abort_on_error=1
|
||||
detect_leaks=0
|
||||
@ -647,14 +611,7 @@ optimal values if not already present in the environment:
|
||||
msan_track_origins=0
|
||||
allocator_may_return_null=1
|
||||
```
|
||||
- Similarly, the default `LSAN_OPTIONS` are set to:
|
||||
```
|
||||
exit_code=23
|
||||
fast_unwind_on_malloc=0
|
||||
symbolize=0
|
||||
print_suppressions=0
|
||||
```
|
||||
Be sure to include the first ones for LSAN and MSAN when customizing
|
||||
anything, since some MSAN and LSAN versions don't call `abort()` on
|
||||
error, and we need a way to detect faults.
|
||||
Be sure to include the first one when customizing anything, since some
|
||||
MSAN versions don't call `abort()` on error, and we need a way to detect
|
||||
faults.
|
||||
|
||||
|
||||
143
docs/historical_notes.md
Normal file
143
docs/historical_notes.md
Normal file
@ -0,0 +1,143 @@
|
||||
# Historical notes
|
||||
|
||||
This doc talks about the rationale of some of the high-level design decisions
|
||||
for American Fuzzy Lop. It's adopted from a discussion with Rob Graham.
|
||||
See README.md for the general instruction manual, and technical_details.md for
|
||||
additional implementation-level insights.
|
||||
|
||||
## 1) Influences
|
||||
|
||||
In short, `afl-fuzz` is inspired chiefly by the work done by Tavis Ormandy back
|
||||
in 2007. Tavis did some very persuasive experiments using `gcov` block coverage
|
||||
to select optimal test cases out of a large corpus of data, and then using
|
||||
them as a starting point for traditional fuzzing workflows.
|
||||
|
||||
(By "persuasive", I mean: netting a significant number of interesting
|
||||
vulnerabilities.)
|
||||
|
||||
In parallel to this, both Tavis and I were interested in evolutionary fuzzing.
|
||||
Tavis had his experiments, and I was working on a tool called bunny-the-fuzzer,
|
||||
released somewhere in 2007.
|
||||
|
||||
Bunny used a generational algorithm not much different from `afl-fuzz`, but
|
||||
also tried to reason about the relationship between various input bits and
|
||||
the internal state of the program, with hopes of deriving some additional value
|
||||
from that. The reasoning / correlation part was probably in part inspired by
|
||||
other projects done around the same time by Will Drewry and Chris Evans.
|
||||
|
||||
The state correlation approach sounded very sexy on paper, but ultimately, made
|
||||
the fuzzer complicated, brittle, and cumbersome to use; every other target
|
||||
program would require a tweak or two. Because Bunny didn't fare a whole lot
|
||||
better than less sophisticated brute-force tools, I eventually decided to write
|
||||
it off. You can still find its original documentation at:
|
||||
|
||||
https://code.google.com/p/bunny-the-fuzzer/wiki/BunnyDoc
|
||||
|
||||
There has been a fair amount of independent work, too. Most notably, a few
|
||||
weeks earlier that year, Jared DeMott had a Defcon presentation about a
|
||||
coverage-driven fuzzer that relied on coverage as a fitness function.
|
||||
|
||||
Jared's approach was by no means identical to what afl-fuzz does, but it was in
|
||||
the same ballpark. His fuzzer tried to explicitly solve for the maximum coverage
|
||||
with a single input file; in comparison, afl simply selects for cases that do
|
||||
something new (which yields better results - see [technical_details.md](technical_details.md)).
|
||||
|
||||
A few years later, Gabriel Campana released fuzzgrind, a tool that relied purely
|
||||
on Valgrind and a constraint solver to maximize coverage without any brute-force
|
||||
bits; and Microsoft Research folks talked extensively about their still
|
||||
non-public, solver-based SAGE framework.
|
||||
|
||||
In the past six years or so, I've also seen a fair number of academic papers
|
||||
that dealt with smart fuzzing (focusing chiefly on symbolic execution) and a
|
||||
couple papers that discussed proof-of-concept applications of genetic
|
||||
algorithms with the same goals in mind. I'm unconvinced how practical most of
|
||||
these experiments were; I suspect that many of them suffer from the
|
||||
bunny-the-fuzzer's curse of being cool on paper and in carefully designed
|
||||
experiments, but failing the ultimate test of being able to find new,
|
||||
worthwhile security bugs in otherwise well-fuzzed, real-world software.
|
||||
|
||||
In some ways, the baseline that the "cool" solutions have to compete against is
|
||||
a lot more impressive than it may seem, making it difficult for competitors to
|
||||
stand out. For a singular example, check out the work by Gynvael and Mateusz
|
||||
Jurczyk, applying "dumb" fuzzing to ffmpeg, a prominent and security-critical
|
||||
component of modern browsers and media players:
|
||||
|
||||
http://googleonlinesecurity.blogspot.com/2014/01/ffmpeg-and-thousand-fixes.html
|
||||
|
||||
Effortlessly getting comparable results with state-of-the-art symbolic execution
|
||||
in equally complex software still seems fairly unlikely, and hasn't been
|
||||
demonstrated in practice so far.
|
||||
|
||||
But I digress; ultimately, attribution is hard, and glorying the fundamental
|
||||
concepts behind AFL is probably a waste of time. The devil is very much in the
|
||||
often-overlooked details, which brings us to...
|
||||
|
||||
## 2. Design goals for afl-fuzz
|
||||
|
||||
In short, I believe that the current implementation of afl-fuzz takes care of
|
||||
several itches that seemed impossible to scratch with other tools:
|
||||
|
||||
1) Speed. It's genuinely hard to compete with brute force when your "smart"
|
||||
approach is resource-intensive. If your instrumentation makes it 10x more
|
||||
likely to find a bug, but runs 100x slower, your users are getting a bad
|
||||
deal.
|
||||
|
||||
To avoid starting with a handicap, `afl-fuzz` is meant to let you fuzz most of
|
||||
the intended targets at roughly their native speed - so even if it doesn't
|
||||
add value, you do not lose much.
|
||||
|
||||
On top of this, the tool leverages instrumentation to actually reduce the
|
||||
amount of work in a couple of ways: for example, by carefully trimming the
|
||||
corpus or skipping non-functional but non-trimmable regions in the input
|
||||
files.
|
||||
|
||||
2) Rock-solid reliability. It's hard to compete with brute force if your
|
||||
approach is brittle and fails unexpectedly. Automated testing is attractive
|
||||
because it's simple to use and scalable; anything that goes against these
|
||||
principles is an unwelcome trade-off and means that your tool will be used
|
||||
less often and with less consistent results.
|
||||
|
||||
Most of the approaches based on symbolic execution, taint tracking, or
|
||||
complex syntax-aware instrumentation are currently fairly unreliable with
|
||||
real-world targets. Perhaps more importantly, their failure modes can render
|
||||
them strictly worse than "dumb" tools, and such degradation can be difficult
|
||||
for less experienced users to notice and correct.
|
||||
|
||||
In contrast, `afl-fuzz` is designed to be rock solid, chiefly by keeping it
|
||||
simple. In fact, at its core, it's designed to be just a very good
|
||||
traditional fuzzer with a wide range of interesting, well-researched
|
||||
strategies to go by. The fancy parts just help it focus the effort in
|
||||
places where it matters the most.
|
||||
|
||||
3) Simplicity. The author of a testing framework is probably the only person
|
||||
who truly understands the impact of all the settings offered by the tool -
|
||||
and who can dial them in just right. Yet, even the most rudimentary fuzzer
|
||||
frameworks often come with countless knobs and fuzzing ratios that need to
|
||||
be guessed by the operator ahead of the time. This can do more harm than
|
||||
good.
|
||||
|
||||
AFL is designed to avoid this as much as possible. The three knobs you
|
||||
can play with are the output file, the memory limit, and the ability to
|
||||
override the default, auto-calibrated timeout. The rest is just supposed to
|
||||
work. When it doesn't, user-friendly error messages outline the probable
|
||||
causes and workarounds, and get you back on track right away.
|
||||
|
||||
4) Chainability. Most general-purpose fuzzers can't be easily employed
|
||||
against resource-hungry or interaction-heavy tools, necessitating the
|
||||
creation of custom in-process fuzzers or the investment of massive CPU
|
||||
power (most of which is wasted on tasks not directly related to the code
|
||||
we actually want to test).
|
||||
|
||||
AFL tries to scratch this itch by allowing users to use more lightweight
|
||||
targets (e.g., standalone image parsing libraries) to create small
|
||||
corpora of interesting test cases that can be fed into a manual testing
|
||||
process or a UI harness later on.
|
||||
|
||||
As mentioned in [technical_details.md](technical_details.md), AFL does all this not by systematically
|
||||
applying a single overarching CS concept, but by experimenting with a variety
|
||||
of small, complementary methods that were shown to reliably yields results
|
||||
better than chance. The use of instrumentation is a part of that toolkit, but is
|
||||
far from being the most important one.
|
||||
|
||||
Ultimately, what matters is that `afl-fuzz` is designed to find cool bugs - and
|
||||
has a pretty robust track record of doing just that.
|
||||
@ -3,6 +3,40 @@
|
||||
In the following, we describe a variety of ideas that could be implemented
|
||||
for future AFL++ versions.
|
||||
|
||||
# GSoC 2021
|
||||
|
||||
All GSoC 2021 projects will be in the Rust development language!
|
||||
|
||||
## UI for libaflrs
|
||||
|
||||
Write a user interface to libaflrs, the upcoming backend of afl++.
|
||||
This might look like the afl-fuzz UI, but you can improve on it - and should!
|
||||
|
||||
## Schedulers for libaflrs
|
||||
|
||||
Schedulers is a mechanism that selects items from the fuzzing corpus based
|
||||
on strategy and randomness. One scheduler might focus on long paths,
|
||||
another on rarity of edges disocvered, still another on a combination on
|
||||
things. Some of the schedulers in afl++ have to be ported, but you are free
|
||||
to come up with your own if you want to - and see how it performs.
|
||||
|
||||
## Forkserver support for libaflrs
|
||||
|
||||
The current libaflrs implementation fuzzes in-memory, however obviously we
|
||||
want to support afl instrumented binaries as well.
|
||||
Hence a forkserver support needs to be implemented - forking off the target
|
||||
and talking to the target via a socketpair and the communication protocol
|
||||
within.
|
||||
|
||||
## More Observers for libaflrs
|
||||
|
||||
An observer is measuring functionality that looks at the target being fuzzed
|
||||
and documents something about it. In traditional fuzzing this is the coverage
|
||||
in the target, however we want to add various more observers, e.g. stack depth,
|
||||
heap usage, etc. - this is a topic for an experienced Rust developer.
|
||||
|
||||
# Generic ideas and wishlist
|
||||
|
||||
## Analysis software
|
||||
|
||||
Currently analysis is done by using afl-plot, which is rather outdated.
|
||||
@ -29,19 +63,6 @@ the current Unicorn instrumentation.
|
||||
|
||||
Mentor: any
|
||||
|
||||
## Support other programming languages
|
||||
|
||||
Other programming languages also use llvm hence they could (easily?) supported
|
||||
for fuzzing, e.g. mono, swift, go, kotlin native, fortran, ...
|
||||
|
||||
GCC also supports: Objective-C, Fortran, Ada, Go, and D
|
||||
(according to [Gcc homepage](https://gcc.gnu.org/))
|
||||
|
||||
LLVM is also used by: Rust, LLGo (Go), kaleidoscope (Haskell), flang (Fortran), emscripten (JavaScript, WASM), ilwasm (CIL (C#))
|
||||
(according to [LLVM frontends](https://gist.github.com/axic/62d66fb9d8bccca6cc48fa9841db9241))
|
||||
|
||||
Mentor: vanhauser-thc
|
||||
|
||||
## Machine Learning
|
||||
|
||||
Something with machine learning, better than [NEUZZ](https://github.com/dongdongshe/neuzz) :-)
|
||||
|
||||
@ -83,5 +83,5 @@ You can find a simple solution in utils/argv_fuzzing.
|
||||
## Attacking a format that uses checksums?
|
||||
|
||||
Remove the checksum-checking code or use a postprocessor!
|
||||
See `afl_custom_post_process` in custom_mutators/examples/example.c for more.
|
||||
See utils/custom_mutators/ for more.
|
||||
|
||||
|
||||
150
docs/notes_for_asan.md
Normal file
150
docs/notes_for_asan.md
Normal file
@ -0,0 +1,150 @@
|
||||
# Notes for using ASAN with afl-fuzz
|
||||
|
||||
This file discusses some of the caveats for fuzzing under ASAN, and suggests
|
||||
a handful of alternatives. See README.md for the general instruction manual.
|
||||
|
||||
## 1) Short version
|
||||
|
||||
ASAN on 64-bit systems requests a lot of memory in a way that can't be easily
|
||||
distinguished from a misbehaving program bent on crashing your system.
|
||||
|
||||
Because of this, fuzzing with ASAN is recommended only in four scenarios:
|
||||
|
||||
- On 32-bit systems, where we can always enforce a reasonable memory limit
|
||||
(-m 800 or so is a good starting point),
|
||||
|
||||
- On 64-bit systems only if you can do one of the following:
|
||||
|
||||
- Compile the binary in 32-bit mode (gcc -m32),
|
||||
|
||||
- Precisely gauge memory needs using http://jwilk.net/software/recidivm .
|
||||
|
||||
- Limit the memory available to process using cgroups on Linux (see
|
||||
utils/asan_cgroups).
|
||||
|
||||
To compile with ASAN, set AFL_USE_ASAN=1 before calling 'make clean all'. The
|
||||
afl-gcc / afl-clang wrappers will pick that up and add the appropriate flags.
|
||||
Note that ASAN is incompatible with -static, so be mindful of that.
|
||||
|
||||
(You can also use AFL_USE_MSAN=1 to enable MSAN instead.)
|
||||
|
||||
NOTE: if you run several secondary instances, only one should run the target
|
||||
compiled with ASAN (and UBSAN, CFISAN), the others should run the target with
|
||||
no sanitizers compiled in.
|
||||
|
||||
There is also the option of generating a corpus using a non-ASAN binary, and
|
||||
then feeding it to an ASAN-instrumented one to check for bugs. This is faster,
|
||||
and can give you somewhat comparable results. You can also try using
|
||||
libdislocator (see [utils/libdislocator/README.dislocator.md](../utils/libdislocator/README.dislocator.md) in the parent directory) as a
|
||||
lightweight and hassle-free (but less thorough) alternative.
|
||||
|
||||
## 2) Long version
|
||||
|
||||
ASAN allocates a huge region of virtual address space for bookkeeping purposes.
|
||||
Most of this is never actually accessed, so the OS never has to allocate any
|
||||
real pages of memory for the process, and the VM grabbed by ASAN is essentially
|
||||
"free" - but the mapping counts against the standard OS-enforced limit
|
||||
(RLIMIT_AS, aka ulimit -v).
|
||||
|
||||
On our end, afl-fuzz tries to protect you from processes that go off-rails
|
||||
and start consuming all the available memory in a vain attempt to parse a
|
||||
malformed input file. This happens surprisingly often, so enforcing such a limit
|
||||
is important for almost any fuzzer: the alternative is for the kernel OOM
|
||||
handler to step in and start killing random processes to free up resources.
|
||||
Needless to say, that's not a very nice prospect to live with.
|
||||
|
||||
Unfortunately, un*x systems offer no portable way to limit the amount of
|
||||
pages actually given to a process in a way that distinguishes between that
|
||||
and the harmless "land grab" done by ASAN. In principle, there are three standard
|
||||
ways to limit the size of the heap:
|
||||
|
||||
- The RLIMIT_AS mechanism (ulimit -v) caps the size of the virtual space -
|
||||
but as noted, this pays no attention to the number of pages actually
|
||||
in use by the process, and doesn't help us here.
|
||||
|
||||
- The RLIMIT_DATA mechanism (ulimit -d) seems like a good fit, but it applies
|
||||
only to the traditional sbrk() / brk() methods of requesting heap space;
|
||||
modern allocators, including the one in glibc, routinely rely on mmap()
|
||||
instead, and circumvent this limit completely.
|
||||
|
||||
- Finally, the RLIMIT_RSS limit (ulimit -m) sounds like what we need, but
|
||||
doesn't work on Linux - mostly because nobody felt like implementing it.
|
||||
|
||||
There are also cgroups, but they are Linux-specific, not universally available
|
||||
even on Linux systems, and they require root permissions to set up; I'm a bit
|
||||
hesitant to make afl-fuzz require root permissions just for that. That said,
|
||||
if you are on Linux and want to use cgroups, check out the contributed script
|
||||
that ships in utils/asan_cgroups/.
|
||||
|
||||
In settings where cgroups aren't available, we have no nice, portable way to
|
||||
avoid counting the ASAN allocation toward the limit. On 32-bit systems, or for
|
||||
binaries compiled in 32-bit mode (-m32), this is not a big deal: ASAN needs
|
||||
around 600-800 MB or so, depending on the compiler - so all you need to do is
|
||||
to specify -m that is a bit higher than that.
|
||||
|
||||
On 64-bit systems, the situation is more murky, because the ASAN allocation
|
||||
is completely outlandish - around 17.5 TB in older versions, and closer to
|
||||
20 TB with newest ones. The actual amount of memory on your system is
|
||||
(probably!) just a tiny fraction of that - so unless you dial the limit
|
||||
with surgical precision, you will get no protection from OOM bugs.
|
||||
|
||||
On my system, the amount of memory grabbed by ASAN with a slightly older
|
||||
version of gcc is around 17,825,850 MB; for newest clang, it's 20,971,600.
|
||||
But there is no guarantee that these numbers are stable, and if you get them
|
||||
wrong by "just" a couple gigs or so, you will be at risk.
|
||||
|
||||
To get the precise number, you can use the recidivm tool developed by Jakub
|
||||
Wilk (http://jwilk.net/software/recidivm). In absence of this, ASAN is *not*
|
||||
recommended when fuzzing 64-bit binaries, unless you are confident that they
|
||||
are robust and enforce reasonable memory limits (in which case, you can
|
||||
specify '-m none' when calling afl-fuzz).
|
||||
|
||||
Using recidivm or running with no limits aside, there are two other decent
|
||||
alternatives: build a corpus of test cases using a non-ASAN binary, and then
|
||||
examine them with ASAN, Valgrind, or other heavy-duty tools in a more
|
||||
controlled setting; or compile the target program with -m32 (32-bit mode)
|
||||
if your system supports that.
|
||||
|
||||
## 3) Interactions with the QEMU mode
|
||||
|
||||
ASAN, MSAN, and other sanitizers appear to be incompatible with QEMU user
|
||||
emulation, so please do not try to use them with the -Q option; QEMU doesn't
|
||||
seem to appreciate the shadow VM trick used by these tools, and will likely
|
||||
just allocate all your physical memory, then crash.
|
||||
|
||||
You can, however, use QASan to run binaries that are not instrumented with ASan
|
||||
under QEMU with the AFL++ instrumentation.
|
||||
|
||||
https://github.com/andreafioraldi/qasan
|
||||
|
||||
## 4) ASAN and OOM crashes
|
||||
|
||||
By default, ASAN treats memory allocation failures as fatal errors, immediately
|
||||
causing the program to crash. Since this is a departure from normal POSIX
|
||||
semantics (and creates the appearance of security issues in otherwise
|
||||
properly-behaving programs), we try to disable this by specifying
|
||||
allocator_may_return_null=1 in ASAN_OPTIONS.
|
||||
|
||||
Unfortunately, it's been reported that this setting still causes ASAN to
|
||||
trigger phantom crashes in situations where the standard allocator would
|
||||
simply return NULL. If this is interfering with your fuzzing jobs, you may
|
||||
want to cc: yourself on this bug:
|
||||
|
||||
https://bugs.llvm.org/show_bug.cgi?id=22026
|
||||
|
||||
## 5) What about UBSAN?
|
||||
|
||||
New versions of UndefinedBehaviorSanitizer offers the
|
||||
-fsanitize=undefined-trap-on-error compiler flag that tells UBSan to insert an
|
||||
istruction that will cause SIGILL (ud2 on x86) when an undefined behaviour
|
||||
is detected. This is the option that you want to use when combining AFL++
|
||||
and UBSan.
|
||||
|
||||
AFL_USE_UBSAN=1 env var will add this compiler flag to afl-clang-fast,
|
||||
afl-gcc-fast and afl-gcc for you.
|
||||
|
||||
Old versions of UBSAN don't offer a consistent way
|
||||
to abort() on fault conditions or to terminate with a distinctive exit code
|
||||
but there are some versions of the library can be binary-patched to address this
|
||||
issue. You can also preload a shared library that substitute all the UBSan
|
||||
routines used to report errors with abort().
|
||||
@ -1,11 +1,7 @@
|
||||
# Tips for parallel fuzzing
|
||||
|
||||
This document talks about synchronizing afl-fuzz jobs on a single machine
|
||||
or across a fleet of systems. See README.md for the general instruction manual.
|
||||
|
||||
Note that this document is rather outdated. please refer to the main document
|
||||
section on multiple core usage [../README.md#Using multiple cores](../README.md#b-using-multiple-coresthreads)
|
||||
for up to date strategies!
|
||||
This document talks about synchronizing afl-fuzz jobs on a single machine
|
||||
or across a fleet of systems. See README.md for the general instruction manual.
|
||||
|
||||
## 1) Introduction
|
||||
|
||||
|
||||
@ -48,9 +48,13 @@ be then manually fed to a more resource-hungry program later on.
|
||||
Also note that reading the fuzzing input via stdin is faster than reading from
|
||||
a file.
|
||||
|
||||
## 3. Use LLVM persistent instrumentation
|
||||
## 3. Use LLVM instrumentation
|
||||
|
||||
The LLVM mode offers a "persistent", in-process fuzzing mode that can
|
||||
When fuzzing slow targets, you can gain 20-100% performance improvement by
|
||||
using the LLVM-based instrumentation mode described in [the instrumentation README](../instrumentation/README.llvm.md).
|
||||
Note that this mode requires the use of clang and will not work with GCC.
|
||||
|
||||
The LLVM mode also offers a "persistent", in-process fuzzing mode that can
|
||||
work well for certain types of self-contained libraries, and for fast targets,
|
||||
can offer performance gains up to 5-10x; and a "deferred fork server" mode
|
||||
that can offer huge benefits for programs with high startup overhead. Both
|
||||
@ -65,6 +69,9 @@ If you are only interested in specific parts of the code being fuzzed, you can
|
||||
instrument_files the files that are actually relevant. This improves the speed and
|
||||
accuracy of afl. See instrumentation/README.instrument_list.md
|
||||
|
||||
Also use the InsTrim mode on larger binaries, this improves performance and
|
||||
coverage a lot.
|
||||
|
||||
## 4. Profile and optimize the binary
|
||||
|
||||
Check for any parameters or settings that obviously improve performance. For
|
||||
@ -134,7 +141,8 @@ misses, or similar factors, but they are less likely to be a concern.)
|
||||
|
||||
## 7. Keep memory use and timeouts in check
|
||||
|
||||
Consider setting low values for `-m` and `-t`.
|
||||
If you have increased the `-m` or `-t` limits more than truly necessary, consider
|
||||
dialing them back down.
|
||||
|
||||
For programs that are nominally very fast, but get sluggish for some inputs,
|
||||
you can also try setting `-t` values that are more punishing than what `afl-fuzz`
|
||||
@ -159,20 +167,6 @@ There are several OS-level factors that may affect fuzzing speed:
|
||||
- Network filesystems, either used for fuzzer input / output, or accessed by
|
||||
the fuzzed binary to read configuration files (pay special attention to the
|
||||
home directory - many programs search it for dot-files).
|
||||
- Disable all the spectre, meltdown etc. security countermeasures in the
|
||||
kernel if your machine is properly separated:
|
||||
|
||||
```
|
||||
ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off
|
||||
no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable
|
||||
nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off
|
||||
spectre_v2=off stf_barrier=off
|
||||
```
|
||||
In most Linux distributions you can put this into a `/etc/default/grub`
|
||||
variable.
|
||||
|
||||
The following list of changes are made when executing `afl-system-config`:
|
||||
|
||||
- On-demand CPU scaling. The Linux `ondemand` governor performs its analysis
|
||||
on a particular schedule and is known to underestimate the needs of
|
||||
short-lived processes spawned by `afl-fuzz` (or any other fuzzer). On Linux,
|
||||
@ -205,4 +199,26 @@ The following list of changes are made when executing `afl-system-config`:
|
||||
Setting a different scheduling policy for the fuzzer process - say
|
||||
`SCHED_RR` - can usually speed things up, too, but needs to be done with
|
||||
care.
|
||||
- Use the `afl-system-config` script to set all proc/sys settings above in one go.
|
||||
- Disable all the spectre, meltdown etc. security countermeasures in the
|
||||
kernel if your machine is properly separated:
|
||||
|
||||
```
|
||||
ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off
|
||||
no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable
|
||||
nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off
|
||||
spectre_v2=off stf_barrier=off
|
||||
```
|
||||
In most Linux distributions you can put this into a `/etc/default/grub`
|
||||
variable.
|
||||
|
||||
## 9. If all other options fail, use `-d`
|
||||
|
||||
For programs that are genuinely slow, in cases where you really can't escape
|
||||
using huge input files, or when you simply want to get quick and dirty results
|
||||
early on, you can always resort to the `-d` mode.
|
||||
|
||||
The mode causes `afl-fuzz` to skip all the deterministic fuzzing steps, which
|
||||
makes output a lot less neat and can ultimately make the testing a bit less
|
||||
in-depth, but it will give you an experience more familiar from other fuzzing
|
||||
tools.
|
||||
|
||||
32
docs/power_schedules.md
Normal file
32
docs/power_schedules.md
Normal file
@ -0,0 +1,32 @@
|
||||
# afl++'s power schedules based on AFLfast
|
||||
|
||||
<a href="https://mboehme.github.io/paper/CCS16.pdf"><img src="https://mboehme.github.io/paper/CCS16.png" align="right" width="250"></a>
|
||||
Power schedules implemented by Marcel Böhme \<marcel.boehme@acm.org\>.
|
||||
AFLFast is an extension of AFL which is written and maintained by
|
||||
Michal Zalewski \<lcamtuf@google.com\>.
|
||||
|
||||
AFLfast has helped in the success of Team Codejitsu at the finals of the DARPA Cyber Grand Challenge where their bot Galactica took **2nd place** in terms of #POVs proven (see red bar at https://www.cybergrandchallenge.com/event#results). AFLFast exposed several previously unreported CVEs that could not be exposed by AFL in 24 hours and otherwise exposed vulnerabilities significantly faster than AFL while generating orders of magnitude more unique crashes.
|
||||
|
||||
Essentially, we observed that most generated inputs exercise the same few "high-frequency" paths and developed strategies to gravitate towards low-frequency paths, to stress significantly more program behavior in the same amount of time. We devised several **search strategies** that decide in which order the seeds should be fuzzed and **power schedules** that smartly regulate the number of inputs generated from a seed (i.e., the time spent fuzzing a seed). We call the number of inputs generated from a seed, the seed's **energy**.
|
||||
|
||||
We find that AFL's exploitation-based constant schedule assigns **too much energy to seeds exercising high-frequency paths** (e.g., paths that reject invalid inputs) and not enough energy to seeds exercising low-frequency paths (e.g., paths that stress interesting behaviors). Technically, we modified the computation of a seed's performance score (`calculate_score`), which seed is marked as favourite (`update_bitmap_score`), and which seed is chosen next from the circular queue (`main`). We implemented the following schedules (in the order of their effectiveness, best first):
|
||||
|
||||
| AFL flag | Power Schedule |
|
||||
| ------------- | -------------------------- |
|
||||
| `-p explore` | 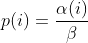 |
|
||||
| `-p fast` (default)| 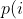=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) |
|
||||
| `-p coe` |  |
|
||||
| `-p quad` |  |
|
||||
| `-p lin` |  |
|
||||
| `-p exploit` (AFL) |  |
|
||||
| `-p mmopt` | Experimental: `explore` with no weighting to runtime and increased weighting on the last 5 queue entries |
|
||||
| `-p rare` | Experimental: `rare` puts focus on queue entries that hit rare edges |
|
||||
| `-p seek` | Experimental: `seek` is EXPLORE but ignoring the runtime of the queue input and less focus on the size |
|
||||
where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path.
|
||||
|
||||
More details can be found in the paper that was accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/).
|
||||
|
||||
PS: In parallel mode (several instances with shared queue), we suggest to run the main node using the exploit schedule (-p exploit) and the secondary nodes with a combination of cut-off-exponential (-p coe), exponential (-p fast; default), and explore (-p explore) schedules. In single mode, the default settings will do. **EDIT:** In parallel mode, AFLFast seems to perform poorly because the path probability estimates are incorrect for the imported seeds. Pull requests to fix this issue by syncing the estimates across instances are appreciated :)
|
||||
|
||||
Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved.
|
||||
Released under terms and conditions of Apache License, Version 2.0.
|
||||
@ -1,6 +1,6 @@
|
||||
# Remote monitoring with StatsD
|
||||
|
||||
StatsD allows you to receive and aggregate metrics from a wide range of applications and retransmit them to the backend of your choice.
|
||||
StatsD allows you to receive and aggregate metrics from a wide range of application and retransmit them to the backend of your choice.
|
||||
This enables you to create nice and readable dashboards containing all the information you need on your fuzzer instances.
|
||||
No need to write your own statistics parsing system, deploy and maintain it to all your instances, sync with your graph rendering system...
|
||||
|
||||
@ -45,7 +45,7 @@ For more information on these env vars, check out `docs/env_variables.md`.
|
||||
|
||||
The simplest way of using this feature is to use any metric provider and change the host/port of your StatsD daemon,
|
||||
with `AFL_STATSD_HOST` and `AFL_STATSD_PORT`, if required (defaults are `localhost` and port `8125`).
|
||||
To get started, here are some instructions with free and open source tools.
|
||||
To get started, here are some instruction with free and open source tools.
|
||||
The following setup is based on Prometheus, statsd_exporter and Grafana.
|
||||
Grafana here is not mandatory, but gives you some nice graphs and features.
|
||||
|
||||
@ -131,7 +131,7 @@ mappings:
|
||||
|
||||
Run `docker-compose up -d`.
|
||||
|
||||
Everything should now be setup, you are now able to run your fuzzers with
|
||||
Everything should be now setup, you are now able to run your fuzzers with
|
||||
|
||||
```
|
||||
AFL_STATSD_TAGS_FLAVOR=dogstatsd AFL_STATSD=1 afl-fuzz -M test-fuzzer-1 -i i -o o ./bin/my-application @@
|
||||
@ -139,5 +139,5 @@ AFL_STATSD_TAGS_FLAVOR=dogstatsd AFL_STATSD=1 afl-fuzz -S test-fuzzer-2 -i i -o
|
||||
...
|
||||
```
|
||||
|
||||
This setup may be modified before use in a production environment. Depending on your needs: adding passwords, creating volumes for storage,
|
||||
This setup may be modified before use in production environment. Depending on your needs: addind passwords, creating volumes for storage,
|
||||
tweaking the metrics gathering to get host metrics (CPU, RAM ...).
|
||||
|
||||
@ -251,9 +251,8 @@ exceed it by a margin sufficient to be classified as hangs.
|
||||
| arithmetics : 53/2.54M, 0/537k, 0/55.2k |
|
||||
| known ints : 8/322k, 12/1.32M, 10/1.70M |
|
||||
| dictionary : 9/52k, 1/53k, 1/24k |
|
||||
|havoc/splice : 1903/20.0M, 0/0 |
|
||||
|py/custom/rq : unused, 53/2.54M, unused |
|
||||
| trim/eff : 20.31%/9201, 17.05% |
|
||||
| havoc : 1903/20.0M, 0/0 |
|
||||
| trim : 20.31%/9201, 17.05% |
|
||||
+-----------------------------------------------------+
|
||||
```
|
||||
|
||||
@ -269,12 +268,6 @@ goal. Finally, the third number shows the proportion of bytes that, although
|
||||
not possible to remove, were deemed to have no effect and were excluded from
|
||||
some of the more expensive deterministic fuzzing steps.
|
||||
|
||||
Note that when deterministic mutation mode is off (which is the default
|
||||
because it is not very efficient) the first five lines display
|
||||
"disabled (default, enable with -D)".
|
||||
|
||||
Only what is activated will have counter shown.
|
||||
|
||||
### Path geometry
|
||||
|
||||
```
|
||||
|
||||
@ -1,9 +1,5 @@
|
||||
# Technical "whitepaper" for afl-fuzz
|
||||
|
||||
|
||||
NOTE: this document is rather outdated!
|
||||
|
||||
|
||||
This document provides a quick overview of the guts of American Fuzzy Lop.
|
||||
See README.md for the general instruction manual; and for a discussion of
|
||||
motivations and design goals behind AFL, see historical_notes.md.
|
||||
|
||||
@ -1,56 +1,10 @@
|
||||
{
|
||||
"__afl_already_initialized_first";
|
||||
"__afl_already_initialized_forkserver";
|
||||
"__afl_already_initialized_second";
|
||||
"__afl_already_initialized_shm";
|
||||
"__afl_area_ptr";
|
||||
"__afl_auto_early";
|
||||
"__afl_auto_first";
|
||||
"__afl_auto_init";
|
||||
"__afl_auto_second";
|
||||
"__afl_coverage_discard";
|
||||
"__afl_coverage_interesting";
|
||||
"__afl_coverage_off";
|
||||
"__afl_coverage_on";
|
||||
"__afl_coverage_skip";
|
||||
"__afl_dictionary";
|
||||
"__afl_dictionary_len";
|
||||
"__afl_final_loc";
|
||||
"__afl_fuzz_len";
|
||||
"__afl_fuzz_ptr";
|
||||
"__afl_manual_init";
|
||||
"__afl_map_addr";
|
||||
"__afl_persistent_loop";
|
||||
"__afl_prev_caller";
|
||||
"__afl_prev_ctx";
|
||||
"__afl_auto_init";
|
||||
"__afl_area_initial";
|
||||
"__afl_prev_loc";
|
||||
"__afl_selective_coverage";
|
||||
"__afl_selective_coverage_start_off";
|
||||
"__afl_selective_coverage_temp";
|
||||
"__afl_sharedmem_fuzzing";
|
||||
"__afl_trace";
|
||||
"__cmplog_ins_hook1";
|
||||
"__cmplog_ins_hook16";
|
||||
"__cmplog_ins_hook2";
|
||||
"__cmplog_ins_hook4";
|
||||
"__cmplog_ins_hook8";
|
||||
"__cmplog_ins_hookN";
|
||||
"__cmplog_rtn_gcc_stdstring_cstring";
|
||||
"__cmplog_rtn_gcc_stdstring_stdstring";
|
||||
"__cmplog_rtn_hook";
|
||||
"__cmplog_rtn_llvm_stdstring_cstring";
|
||||
"__cmplog_rtn_llvm_stdstring_stdstring";
|
||||
"__sanitizer_cov_trace_cmp1";
|
||||
"__sanitizer_cov_trace_cmp16";
|
||||
"__sanitizer_cov_trace_cmp2";
|
||||
"__sanitizer_cov_trace_cmp4";
|
||||
"__sanitizer_cov_trace_cmp8";
|
||||
"__sanitizer_cov_trace_const_cmp1";
|
||||
"__sanitizer_cov_trace_const_cmp16";
|
||||
"__sanitizer_cov_trace_const_cmp2";
|
||||
"__sanitizer_cov_trace_const_cmp4";
|
||||
"__sanitizer_cov_trace_const_cmp8";
|
||||
"__sanitizer_cov_trace_pc_guard";
|
||||
"__sanitizer_cov_trace_pc_guard_init";
|
||||
"__sanitizer_cov_trace_switch";
|
||||
};
|
||||
|
||||
7
frida_mode/.gitignore
vendored
7
frida_mode/.gitignore
vendored
@ -1,7 +0,0 @@
|
||||
build/
|
||||
frida_test.dat
|
||||
qemu_test.dat
|
||||
frida_out/**
|
||||
qemu_out/**
|
||||
ts/dist/
|
||||
ts/node_modules/
|
||||
@ -1,263 +0,0 @@
|
||||
PWD:=$(shell pwd)/
|
||||
ROOT:=$(shell realpath $(PWD)..)/
|
||||
INC_DIR:=$(PWD)include/
|
||||
SRC_DIR:=$(PWD)src/
|
||||
INCLUDES:=$(wildcard $(INC_DIR)*.h)
|
||||
BUILD_DIR:=$(PWD)build/
|
||||
OBJ_DIR:=$(BUILD_DIR)obj/
|
||||
|
||||
JS_DIR:=$(SRC_DIR)js/
|
||||
JS_NAME:=api.js
|
||||
JS:=$(JS_DIR)$(JS_NAME)
|
||||
JS_SRC:=$(BUILD_DIR)api.c
|
||||
JS_OBJ:=$(BUILD_DIR)api.o
|
||||
SOURCES:=$(wildcard $(SRC_DIR)**/*.c) $(wildcard $(SRC_DIR)*.c)
|
||||
OBJS:=$(foreach src,$(SOURCES),$(OBJ_DIR)$(notdir $(patsubst %.c, %.o, $(src))))
|
||||
CFLAGS+=-fPIC \
|
||||
-D_GNU_SOURCE \
|
||||
-D_FORTIFY_SOURCE=2 \
|
||||
-g \
|
||||
-O3 \
|
||||
-funroll-loops \
|
||||
-ffunction-sections \
|
||||
|
||||
AFL_CFLAGS:=-Wno-unused-parameter \
|
||||
-Wno-sign-compare \
|
||||
-Wno-unused-function \
|
||||
-Wno-unused-result \
|
||||
-Wno-int-to-pointer-cast \
|
||||
-Wno-pointer-sign
|
||||
|
||||
LDFLAGS+=-shared \
|
||||
-lpthread \
|
||||
-lresolv \
|
||||
-ldl
|
||||
|
||||
ifdef DEBUG
|
||||
CFLAGS+=-Werror \
|
||||
-Wall \
|
||||
-Wextra \
|
||||
-Wpointer-arith
|
||||
else
|
||||
CFLAGS+=-Wno-pointer-arith
|
||||
endif
|
||||
|
||||
FRIDA_BUILD_DIR:=$(BUILD_DIR)frida/
|
||||
FRIDA_TRACE:=$(BUILD_DIR)afl-frida-trace.so
|
||||
FRIDA_TRACE_EMBEDDED:=$(BUILD_DIR)afl-frida-trace-embedded
|
||||
|
||||
ifndef ARCH
|
||||
|
||||
ARCH=$(shell uname -m)
|
||||
ifeq "$(ARCH)" "aarch64"
|
||||
ARCH:=arm64
|
||||
endif
|
||||
|
||||
ifeq "$(ARCH)" "armv7l"
|
||||
ARCH:=armhf
|
||||
endif
|
||||
|
||||
ifeq "$(ARCH)" "i686"
|
||||
ARCH:=x86
|
||||
endif
|
||||
endif
|
||||
|
||||
ifeq "$(shell uname)" "Darwin"
|
||||
OS:=macos
|
||||
AFL_CFLAGS:=$(AFL_CFLAGS) -Wno-deprecated-declarations
|
||||
else
|
||||
ifdef DEBUG
|
||||
AFL_CFLAGS:=$(AFL_CFLAGS) -Wno-prio-ctor-dtor
|
||||
endif
|
||||
LDFLAGS+= -z noexecstack \
|
||||
-Wl,--gc-sections \
|
||||
-Wl,--exclude-libs,ALL
|
||||
LDSCRIPT:=-Wl,--version-script=$(PWD)frida.map
|
||||
endif
|
||||
|
||||
ifeq "$(shell uname)" "Linux"
|
||||
OS:=linux
|
||||
endif
|
||||
|
||||
ifndef OS
|
||||
$(error "Operating system unsupported")
|
||||
endif
|
||||
|
||||
ifeq "$(ARCH)" "arm64"
|
||||
# 15.0.0 Not released for aarch64 yet
|
||||
GUM_DEVKIT_VERSION=14.2.18
|
||||
else
|
||||
ifeq "$(ARCH)" "armhf"
|
||||
GUM_DEVKIT_VERSION=14.2.18
|
||||
else
|
||||
GUM_DEVKIT_VERSION=15.0.0
|
||||
endif
|
||||
endif
|
||||
GUM_DEVKIT_FILENAME=frida-gumjs-devkit-$(GUM_DEVKIT_VERSION)-$(OS)-$(ARCH).tar.xz
|
||||
GUM_DEVKIT_URL="https://github.com/frida/frida/releases/download/$(GUM_DEVKIT_VERSION)/$(GUM_DEVKIT_FILENAME)"
|
||||
|
||||
GUM_DEVKIT_TARBALL:=$(FRIDA_BUILD_DIR)$(GUM_DEVKIT_FILENAME)
|
||||
GUM_DEVIT_LIBRARY=$(FRIDA_BUILD_DIR)libfrida-gumjs.a
|
||||
GUM_DEVIT_HEADER=$(FRIDA_BUILD_DIR)frida-gumjs.h
|
||||
|
||||
FRIDA_DIR:=$(PWD)build/frida-source/
|
||||
FRIDA_MAKEFILE:=$(FRIDA_DIR)Makefile
|
||||
FRIDA_GUM:=$(FRIDA_DIR)build/frida-linux-x86_64/lib/libfrida-gumjs-1.0.a
|
||||
FRIDA_GUM_DEVKIT_DIR:=$(FRIDA_DIR)build/gum-devkit/
|
||||
FRIDA_GUM_DEVKIT_HEADER:=$(FRIDA_GUM_DEVKIT_DIR)frida-gumjs.h
|
||||
FRIDA_GUM_DEVKIT_TARBALL:=$(FRIDA_DIR)build/frida-gumjs-devkit-$(GUM_DEVKIT_VERSION)-$(OS)-$(ARCH).tar
|
||||
FRIDA_GUM_DEVKIT_COMPRESSED_TARBALL:=$(FRIDA_DIR)build/$(GUM_DEVKIT_FILENAME)
|
||||
|
||||
AFL_COMPILER_RT_SRC:=$(ROOT)instrumentation/afl-compiler-rt.o.c
|
||||
AFL_COMPILER_RT_OBJ:=$(OBJ_DIR)afl-compiler-rt.o
|
||||
|
||||
AFL_PERFORMANCE_SRC:=$(ROOT)src/afl-performance.c
|
||||
AFL_PERFORMANCE_OBJ:=$(OBJ_DIR)afl-performance.o
|
||||
|
||||
HOOK_DIR:=$(PWD)hook/
|
||||
AFLPP_FRIDA_DRIVER_HOOK_SRC=$(HOOK_DIR)frida_hook.c
|
||||
AFLPP_FRIDA_DRIVER_HOOK_OBJ=$(BUILD_DIR)frida_hook.so
|
||||
|
||||
AFLPP_QEMU_DRIVER_HOOK_SRC:=$(HOOK_DIR)qemu_hook.c
|
||||
AFLPP_QEMU_DRIVER_HOOK_OBJ:=$(BUILD_DIR)qemu_hook.so
|
||||
|
||||
BIN2C:=$(BUILD_DIR)bin2c
|
||||
BIN2C_SRC:=$(PWD)util/bin2c.c
|
||||
|
||||
.PHONY: all 32 clean format hook $(FRIDA_GUM)
|
||||
|
||||
############################## ALL #############################################
|
||||
|
||||
all: $(FRIDA_TRACE) $(AFLPP_FRIDA_DRIVER_HOOK_OBJ) $(AFLPP_QEMU_DRIVER_HOOK_OBJ)
|
||||
|
||||
32:
|
||||
CFLAGS="-m32" LDFLAGS="-m32" ARCH="x86" make all
|
||||
|
||||
$(BUILD_DIR):
|
||||
mkdir -p $(BUILD_DIR)
|
||||
|
||||
$(OBJ_DIR): | $(BUILD_DIR)
|
||||
mkdir -p $@
|
||||
|
||||
############################# FRIDA ############################################
|
||||
|
||||
$(FRIDA_MAKEFILE): | $(BUILD_DIR)
|
||||
git clone --recursive https://github.com/frida/frida.git $(FRIDA_DIR)
|
||||
|
||||
$(FRIDA_GUM): $(FRIDA_MAKEFILE)
|
||||
cd $(FRIDA_DIR) && make gum-linux-$(ARCH)
|
||||
|
||||
$(FRIDA_GUM_DEVKIT_HEADER): $(FRIDA_GUM)
|
||||
$(FRIDA_DIR)releng/devkit.py frida-gumjs linux-$(ARCH) $(FRIDA_DIR)build/gum-devkit/
|
||||
|
||||
$(FRIDA_GUM_DEVKIT_TARBALL): $(FRIDA_GUM_DEVKIT_HEADER)
|
||||
cd $(FRIDA_GUM_DEVKIT_DIR) && tar cvf $(FRIDA_GUM_DEVKIT_TARBALL) .
|
||||
|
||||
$(FRIDA_GUM_DEVKIT_COMPRESSED_TARBALL): $(FRIDA_GUM_DEVKIT_TARBALL)
|
||||
xz -k -f -0 $(FRIDA_GUM_DEVKIT_TARBALL)
|
||||
|
||||
############################# DEVKIT ###########################################
|
||||
|
||||
$(FRIDA_BUILD_DIR): | $(BUILD_DIR)
|
||||
mkdir -p $@
|
||||
|
||||
ifdef FRIDA_SOURCE
|
||||
$(GUM_DEVKIT_TARBALL): $(FRIDA_GUM_DEVKIT_COMPRESSED_TARBALL)| $(FRIDA_BUILD_DIR)
|
||||
cp -v $< $@
|
||||
else
|
||||
$(GUM_DEVKIT_TARBALL): | $(FRIDA_BUILD_DIR)
|
||||
wget -O $@ $(GUM_DEVKIT_URL)
|
||||
endif
|
||||
|
||||
$(GUM_DEVIT_LIBRARY): $(GUM_DEVKIT_TARBALL)
|
||||
tar Jxvfm $(GUM_DEVKIT_TARBALL) -C $(FRIDA_BUILD_DIR)
|
||||
|
||||
$(GUM_DEVIT_HEADER): $(GUM_DEVKIT_TARBALL)
|
||||
tar Jxvfm $(GUM_DEVKIT_TARBALL) -C $(FRIDA_BUILD_DIR)
|
||||
|
||||
############################## AFL #############################################
|
||||
$(AFL_COMPILER_RT_OBJ): $(AFL_COMPILER_RT_SRC)
|
||||
$(CC) \
|
||||
$(CFLAGS) \
|
||||
$(AFL_CFLAGS) \
|
||||
-I $(ROOT) \
|
||||
-I $(ROOT)include \
|
||||
-o $@ \
|
||||
-c $<
|
||||
|
||||
$(AFL_PERFORMANCE_OBJ): $(AFL_PERFORMANCE_SRC)
|
||||
$(CC) \
|
||||
$(CFLAGS) \
|
||||
$(AFL_CFLAGS) \
|
||||
-I $(ROOT) \
|
||||
-I $(ROOT)include \
|
||||
-o $@ \
|
||||
-c $<
|
||||
|
||||
############################### JS #############################################
|
||||
|
||||
$(BIN2C): $(BIN2C_SRC)
|
||||
$(CC) -D_GNU_SOURCE -o $@ $<
|
||||
|
||||
$(JS_SRC): $(JS) $(BIN2C)| $(BUILD_DIR)
|
||||
cd $(JS_DIR) && $(BIN2C) api_js $(JS) $@
|
||||
|
||||
$(JS_OBJ): $(JS_SRC) GNUmakefile
|
||||
$(CC) \
|
||||
$(CFLAGS) \
|
||||
-I $(ROOT)include \
|
||||
-I $(FRIDA_BUILD_DIR) \
|
||||
-I $(INC_DIR) \
|
||||
-c $< \
|
||||
-o $@
|
||||
|
||||
############################# SOURCE ###########################################
|
||||
|
||||
define BUILD_SOURCE
|
||||
$(2): $(1) $(INCLUDES) GNUmakefile | $(OBJ_DIR)
|
||||
$(CC) \
|
||||
$(CFLAGS) \
|
||||
-I $(ROOT)include \
|
||||
-I $(FRIDA_BUILD_DIR) \
|
||||
-I $(INC_DIR) \
|
||||
-c $1 \
|
||||
-o $2
|
||||
endef
|
||||
|
||||
$(foreach src,$(SOURCES),$(eval $(call BUILD_SOURCE,$(src),$(OBJ_DIR)$(notdir $(patsubst %.c, %.o, $(src))))))
|
||||
|
||||
######################## AFL-FRIDA-TRACE #######################################
|
||||
|
||||
$(FRIDA_TRACE): $(GUM_DEVIT_LIBRARY) $(GUM_DEVIT_HEADER) $(OBJS) $(JS_OBJ) $(AFL_COMPILER_RT_OBJ) $(AFL_PERFORMANCE_OBJ) GNUmakefile | $(BUILD_DIR)
|
||||
$(CXX) \
|
||||
$(OBJS) \
|
||||
$(JS_OBJ) \
|
||||
$(GUM_DEVIT_LIBRARY) \
|
||||
$(AFL_COMPILER_RT_OBJ) \
|
||||
$(AFL_PERFORMANCE_OBJ) \
|
||||
$(LDFLAGS) \
|
||||
$(LDSCRIPT) \
|
||||
-o $@ \
|
||||
|
||||
cp -v $(FRIDA_TRACE) $(ROOT)
|
||||
|
||||
############################# HOOK #############################################
|
||||
|
||||
$(AFLPP_FRIDA_DRIVER_HOOK_OBJ): $(AFLPP_FRIDA_DRIVER_HOOK_SRC) $(GUM_DEVIT_HEADER) | $(BUILD_DIR)
|
||||
$(CC) $(CFLAGS) $(LDFLAGS) -I $(FRIDA_BUILD_DIR) $< -o $@
|
||||
|
||||
$(AFLPP_QEMU_DRIVER_HOOK_OBJ): $(AFLPP_QEMU_DRIVER_HOOK_SRC) | $(BUILD_DIR)
|
||||
$(CC) $(CFLAGS) $(LDFLAGS) $< -o $@
|
||||
|
||||
hook: $(AFLPP_FRIDA_DRIVER_HOOK_OBJ) $(AFLPP_QEMU_DRIVER_HOOK_OBJ)
|
||||
|
||||
############################# CLEAN ############################################
|
||||
clean:
|
||||
rm -rf $(BUILD_DIR)
|
||||
|
||||
############################# FORMAT ###########################################
|
||||
format:
|
||||
cd $(ROOT) && echo $(SOURCES) $(AFLPP_FRIDA_DRIVER_HOOK_SRC) $(BIN2C_SRC) | xargs -L1 ./.custom-format.py -i
|
||||
cd $(ROOT) && echo $(INCLUDES) | xargs -L1 ./.custom-format.py -i
|
||||
|
||||
############################# RUN #############################################
|
||||
@ -1,16 +0,0 @@
|
||||
all:
|
||||
@echo trying to use GNU make...
|
||||
@gmake all || echo please install GNUmake
|
||||
|
||||
32:
|
||||
@echo trying to use GNU make...
|
||||
@gmake 32 || echo please install GNUmake
|
||||
|
||||
clean:
|
||||
@gmake clean
|
||||
|
||||
format:
|
||||
@gmake format
|
||||
|
||||
hook:
|
||||
@gmake hook
|
||||
@ -1,147 +0,0 @@
|
||||
# Map Density
|
||||
|
||||
# How Coverage Works
|
||||
The coverage in AFL++ works by assigning each basic block of code a unique ID
|
||||
and during execution when transitioning between blocks (e.g. by calls or jumps)
|
||||
assigning each of these edges an ID based upon the source and destination block
|
||||
ID.
|
||||
|
||||
For each individual execution of the target, a single dimensional byte array
|
||||
indexed by the edge ID is used to count how many times each edge is traversed.
|
||||
|
||||
A single dimensional cumulative byte array is also constructed where each byte
|
||||
again represents an individual edge ID, but this time, the value of the byte
|
||||
represents a range of how many times that edge has been traversed.
|
||||
|
||||
```1, 2, 3, 4-7, 8-15, 16-31, 32-127, 128+```
|
||||
|
||||
The theory is that a new path isn't particularly interesting if an edge has been
|
||||
traversed `23` instead of `24` times for example, but is interesting if an edge
|
||||
has been traversed for the very first time, or the number of times fits within a different bucket.
|
||||
|
||||
After each run, the count of times each edge is hit is compared to the values in
|
||||
the cumulative map and if it is different, then the input is kept as a new seed
|
||||
and the cumulative map is updated.
|
||||
|
||||
This mechanism is described in greater detail in the seminal
|
||||
[paper](https://lcamtuf.coredump.cx/afl/technical_details.txt) on AFL by
|
||||
[lcamtuf](https://github.com/lcamtuf).
|
||||
|
||||
# Collisions
|
||||
In black-box fuzzing, we must assume that control may flow from any block to any
|
||||
other block, since we don't know any better. Thus for a target with `n` basic
|
||||
blocks of code, there are `n * n` potential edges. As we can see, even with a
|
||||
small number of edges, a very large map will be required so that we have space
|
||||
to fit them all. Even if our target only had `1024` blocks, this would require a
|
||||
map containing `1048576` entries (or 1Mb in size).
|
||||
|
||||
Whilst this may not seem like a lot of memory, it causes problems for two reasons. Firstly, the processing step after each execution must now process much more
|
||||
data, and secondly a map this size is unlikely to fit within the L2 cache of the processor. Since this is a very hot code path, we are likely to pay a very heavy
|
||||
performance cost.
|
||||
|
||||
Therefore, we must accept that not all edges can have a unique and that
|
||||
therefore there will be collisions. This means that if the fuzzer finds a new
|
||||
path by uncovering an edge which was not previously found, but that the same
|
||||
edge ID is used by another edge, then it may go completely unnoticed. This is
|
||||
obviously undesirable, but equally if our map is too large, then we will not be
|
||||
able to process as many potential inputs in the same time and hence not uncover
|
||||
edges for that reason. Thus a careful trade-off of map size must be made.
|
||||
|
||||
# Block & Edge Numbering
|
||||
Since the original AFL, blocks and edges have always been numbered in the same
|
||||
way as we can see from the following C snippet from the whitepaper.
|
||||
|
||||
```c
|
||||
cur_location = (block_address >> 4) ^ (block_address << 8);
|
||||
shared_mem[cur_location ^ prev_location]++;
|
||||
prev_location = cur_location >> 1;
|
||||
|
||||
```
|
||||
|
||||
Each block ID is generated by performing a shift and XOR on its address. Then
|
||||
the edge ID is calculated as `E = B ^ (B' >> 1)`. Here, we can make two
|
||||
observations. In fact, the edge ID is also masked to ensure it is less than the
|
||||
size of the map being used.
|
||||
|
||||
## Block IDs
|
||||
Firstly, the block ID doesn't have very good entropy. If we consider the address
|
||||
of the block, then whilst each block has a unique ID, it isn't necessarily very
|
||||
evenly distributed.
|
||||
|
||||
We start with a large address, and need to discard a large number of the bits to
|
||||
generate a block ID which is within range. But how do we choose the unique bits
|
||||
of the address verus those which are the same for every block? The high bits of
|
||||
the address may simply be all `0s` or all `1s` to make the address cannonical,
|
||||
the middle portion of the address may be the same for all blocks (since if they
|
||||
are all within the same binary, then they will all be adjacent in memory), and
|
||||
on some systems, even the low bits may have poor entropy as some use fixed
|
||||
length aligned instructions. Then we need to consider that a portion of each
|
||||
binary may contain the `.data` or `.bss` sections and so may not contain any
|
||||
blocks of code at all.
|
||||
|
||||
## Edge IDs
|
||||
Secondly, we can observe that when we generate an edge ID from the source and
|
||||
destination block IDs, we perform a right shift on the source block ID. Whilst
|
||||
there are good reasons as set out in the whitepaper why such a transform is
|
||||
applied, in so doing, we dispose of `1` bit of precious entropy in our source
|
||||
block ID.
|
||||
|
||||
All together, this means that some edge IDs may be more popular than others.
|
||||
This means that some portions of the map may be very densly populated with large
|
||||
numbers of edges, whilst others may be very sparsely populated, or not populated
|
||||
at all.
|
||||
|
||||
# Improvements
|
||||
One of the main reaons why this algorithm selected, is performance. All of the
|
||||
operations are very quick to perform and given we may be carrying this out for
|
||||
every block of code we execute, performance is critical.
|
||||
|
||||
However, the design of the binary instrumentation modes of AFL++ has moved on.
|
||||
Both QEMU and FRIDA modes use a two stage process when executing a target
|
||||
application. Each block is first compiled or instrumented, and then it is
|
||||
executed. The compiled blocks can be re-used each time the target executes them.
|
||||
|
||||
Since a blocks ID is based on its address, and this is known at compile time, we
|
||||
only need to generate this ID once per block and so this ID generation no longer
|
||||
needs to be as performant. We can therefore use a hash algorithm to generate
|
||||
this ID and therefore ensure that the block IDs are more evenly distributed.
|
||||
|
||||
Edge IDs however, can only be determined at run-time. Since we don't know which
|
||||
blocks a given input will traverse until we run it. However, given our block IDs
|
||||
are now evenly distributed, generating an evenly distributed edge ID becomes
|
||||
simple. Here, the only change we make is to use a rotate operation rather than
|
||||
a shift operation so we don't lose a bit of entropy from the source ID.
|
||||
|
||||
So our new algorithm becomes:
|
||||
```c
|
||||
cur_location = hash(block_address)
|
||||
shared_mem[cur_location ^ prev_location]++;
|
||||
prev_location = rotate(cur_location, 1);
|
||||
```
|
||||
|
||||
Lastly, in the original design, the `cur_location` was always set to `0`, at the
|
||||
beginning of a run, we instead set the value of `cur_location` to `hash(0)`.
|
||||
|
||||
# Parallel Fuzzing
|
||||
Another sub-optimal aspect of the original design is that no matter how many
|
||||
instances of the fuzzer you ran in parallel, each instance numbered each block
|
||||
and so each edge with the same ID. Each instance would therefore find the same
|
||||
subset of edges collide with each other. In the event of a collision, all
|
||||
instances will hit the same road block.
|
||||
|
||||
However, if we instead use a different seed for our hashing function for each
|
||||
instance, then each will ascribe each block a different ID and hence each edge
|
||||
will be given a different edge ID. This means that whilst one instance of the
|
||||
fuzzer may find a given pair of edges collide, it is very unlikely that another
|
||||
instance will find the same pair also collide.
|
||||
|
||||
Due to the collaborative nature of parallel fuzzing, this means that whilst one
|
||||
instance may struggle to find a particular new path because the new edge
|
||||
collides, another instance will likely not encounter the same collision and thus
|
||||
be able to differentiate this new path and share it with the other instances.
|
||||
|
||||
If only a single new edge is found, and the new path is shared with an instance
|
||||
for which that edge collides, that instance may disregard it as irrelevant. In
|
||||
practice, however, the discovery of a single new edge, likely leads to several
|
||||
more edges beneath it also being found and therefore the likelihood of all of
|
||||
these being collisions is very slim.
|
||||
@ -1,308 +0,0 @@
|
||||
# FRIDA MODE
|
||||
|
||||
The purpose of FRIDA mode is to provide an alternative binary only fuzzer for
|
||||
AFL just like that provided by QEMU mode. The intention is to provide a very
|
||||
similar user experience, right down to the options provided through environment
|
||||
variables.
|
||||
|
||||
Whilst AFLplusplus already has some support for running on FRIDA [here](https://github.com/AFLplusplus/AFLplusplus/tree/stable/utils/afl_frida)
|
||||
this requires the code to be fuzzed to be provided as a shared library, it
|
||||
cannot be used to fuzz executables. Additionally, it requires the user to write
|
||||
a small harness around their target code of interest.
|
||||
FRIDA mode instead takes a different approach to avoid these limitations.
|
||||
In Frida mode binary programs are instrumented, similarly to QEMU mode.
|
||||
|
||||
## Current Progress
|
||||
|
||||
As FRIDA mode is new, it is missing a lot of features. The design is such that it
|
||||
should be possible to add these features in a similar manner to QEMU mode and
|
||||
perhaps leverage some of its design and implementation.
|
||||
|
||||
| Feature/Instrumentation | frida-mode | Notes |
|
||||
| -------------------------|:----------:|:--------------------------------------------:|
|
||||
| NeverZero | x | |
|
||||
| Persistent Mode | x | (x86/x64/aarch64 only) |
|
||||
| LAF-Intel / CompCov | - | (CMPLOG is better 90% of the time) |
|
||||
| CMPLOG | x | (x86/x64/aarch64 only) |
|
||||
| Selective Instrumentation| x | |
|
||||
| Non-Colliding Coverage | - | (Not possible in binary-only instrumentation |
|
||||
| Ngram prev_loc Coverage | - | |
|
||||
| Context Coverage | - | |
|
||||
| Auto Dictionary | - | |
|
||||
| Snapshot LKM Support | - | |
|
||||
| In-Memory Test Cases | x | (x86/x64/aarch64 only) |
|
||||
|
||||
## Compatibility
|
||||
Currently FRIDA mode supports Linux and macOS targets on both x86/x64
|
||||
architecture and aarch64. Later releases may add support for aarch32 and Windows
|
||||
targets as well as embedded linux environments.
|
||||
|
||||
FRIDA has been used on various embedded targets using both uClibc and musl C
|
||||
runtime libraries, so porting should be possible. However, the current build
|
||||
system does not support cross compilation.
|
||||
|
||||
## Getting Started
|
||||
|
||||
To build everything run `make`. To build for x86 run `make 32`. Note that in
|
||||
x86 bit mode, it is not necessary for afl-fuzz to be built for 32-bit. However,
|
||||
the shared library for frida_mode must be since it is injected into the target
|
||||
process.
|
||||
|
||||
Various tests can be found in subfolders within the `test/` directory. To use
|
||||
these, first run `make` to build any dependencies. Then run `make qemu` or
|
||||
`make frida` to run on either QEMU of FRIDA mode respectively. To run frida
|
||||
tests in 32-bit mode, run `make ARCH=x86 frida`. When switching between
|
||||
architectures it may be necessary to run `make clean` first for a given build
|
||||
target to remove previously generated binaries for a different architecture.
|
||||
|
||||
## Usage
|
||||
|
||||
FRIDA mode added some small modifications to `afl-fuzz` and similar tools
|
||||
in AFLplusplus. The intention was that it behaves identically to QEMU, but it uses
|
||||
the 'O' switch rather than 'Q'. Whilst the options 'f', 'F', 's' or 'S' may have
|
||||
made more sense for a mode powered by FRIDA Stalker, they were all taken, so
|
||||
instead we use 'O' in hommage to the [author](https://github.com/oleavr) of
|
||||
FRIDA.
|
||||
|
||||
Similarly, the intention is to mimic the use of environment variables used by
|
||||
QEMU where possible (by replacing `s/QEMU/FRIDA/g`). Accordingly, the
|
||||
following options are currently supported:
|
||||
|
||||
* `AFL_FRIDA_DEBUG_MAPS` - See `AFL_QEMU_DEBUG_MAPS`
|
||||
* `AFL_FRIDA_EXCLUDE_RANGES` - See `AFL_QEMU_EXCLUDE_RANGES`
|
||||
* `AFL_FRIDA_INST_RANGES` - See `AFL_QEMU_INST_RANGES`
|
||||
* `AFL_FRIDA_PERSISTENT_ADDR` - See `AFL_QEMU_PERSISTENT_ADDR`
|
||||
* `AFL_FRIDA_PERSISTENT_CNT` - See `AFL_QEMU_PERSISTENT_CNT`
|
||||
* `AFL_FRIDA_PERSISTENT_HOOK` - See `AFL_QEMU_PERSISTENT_HOOK`
|
||||
* `AFL_FRIDA_PERSISTENT_RET` - See `AFL_QEMU_PERSISTENT_RET`
|
||||
|
||||
To enable the powerful CMPLOG mechanism, set `-c 0` for `afl-fuzz`.
|
||||
|
||||
## Scripting
|
||||
|
||||
One of the more powerful features of FRIDA mode is it's support for configuration by JavaScript, rather than using environment variables. For details of how this works see [here](Scripting.md).
|
||||
|
||||
## Performance
|
||||
|
||||
Additionally, the intention is to be able to make a direct performance
|
||||
comparison between the two approaches. Accordingly, FRIDA mode includes various
|
||||
test targets based on the [libpng](https://libpng.sourceforge.io/) benchmark
|
||||
used by [fuzzbench](https://google.github.io/fuzzbench/) and integrated with the
|
||||
[StandaloneFuzzTargetMain](https://raw.githubusercontent.com/llvm/llvm-project/main/compiler-rt/lib/fuzzer/standalone/StandaloneFuzzTargetMain.c)
|
||||
from the llvm project. These tests include basic fork-server support, persistent
|
||||
mode and persistent mode with in-memory test-cases. These are built and linked
|
||||
without any special modifications to suit FRIDA or QEMU. The test data provided
|
||||
with libpng is used as the corpus.
|
||||
|
||||
The intention is to add support for FRIDA mode to the FuzzBench project and
|
||||
perform a like-for-like comparison with QEMU mode to get an accurate
|
||||
appreciation of its performance.
|
||||
|
||||
## Design
|
||||
|
||||
FRIDA mode is supported by using `LD_PRELOAD` (`DYLD_INSERT_LIBRARIES` on macOS)
|
||||
to inject a shared library (`afl-frida-trace.so`) into the target. This shared
|
||||
library is built using the [frida-gum](https://github.com/frida/frida-gum)
|
||||
devkit from the [FRIDA](https://github.com/frida/frida) project. One of the
|
||||
components of frida-gum is [Stalker](https://medium.com/@oleavr/anatomy-of-a-code-tracer-b081aadb0df8),
|
||||
this allows the dynamic instrumentation of running code for AARCH32, AARCH64,
|
||||
x86 and x64 architectures. Implementation details can be found
|
||||
[here](https://frida.re/docs/stalker/).
|
||||
|
||||
Dynamic instrumentation is used to augment the target application with similar
|
||||
coverage information to that inserted by `afl-gcc` or `afl-clang`. The shared
|
||||
library is also linked to the `compiler-rt` component of AFLplusplus to feedback
|
||||
this coverage information to AFL++ and also provide a fork server. It also makes
|
||||
use of the FRIDA [prefetch](https://github.com/frida/frida-gum/blob/56dd9ba3ee9a5511b4b0c629394bf122775f1ab7/gum/gumstalker.h#L115)
|
||||
support to feedback instrumented blocks from the child to the parent using a
|
||||
shared memory region to avoid the need to regenerate instrumented blocks on each
|
||||
fork.
|
||||
|
||||
Whilst FRIDA allows for a normal C function to be used to augment instrumented
|
||||
code, FRIDA mode instead makes use of optimized assembly instead on AARCH64 and
|
||||
x86/64 targets. By injecting these small snippets of assembly, we avoid having
|
||||
to push and pop the full register context. Note that since this instrumentation
|
||||
is used on every basic block to generate coverage, it has a large impact on
|
||||
performance.
|
||||
|
||||
CMPLOG support also adds code to the assembly, however, at present this code
|
||||
makes use of a basic C function and is yet to be optimized. Since not all
|
||||
instances run CMPLOG mode and instrumentation of the binary is less frequent
|
||||
(only on CMP, SUB and CALL instructions) performance is not quite so critical.
|
||||
|
||||
## Advanced configuration options
|
||||
|
||||
* `AFL_FRIDA_INST_DEBUG_FILE` - File to write raw assembly of original blocks
|
||||
and their instrumented counterparts during block compilation.
|
||||
```
|
||||
***
|
||||
|
||||
Creating block for 0x7ffff7953313:
|
||||
0x7ffff7953313 mov qword ptr [rax], 0
|
||||
0x7ffff795331a add rsp, 8
|
||||
0x7ffff795331e ret
|
||||
|
||||
Generated block 0x7ffff75e98e2
|
||||
0x7ffff75e98e2 mov qword ptr [rax], 0
|
||||
0x7ffff75e98e9 add rsp, 8
|
||||
0x7ffff75e98ed lea rsp, [rsp - 0x80]
|
||||
0x7ffff75e98f5 push rcx
|
||||
0x7ffff75e98f6 movabs rcx, 0x7ffff795331e
|
||||
0x7ffff75e9900 jmp 0x7ffff75e9384
|
||||
|
||||
|
||||
***
|
||||
```
|
||||
* `AFL_FRIDA_INST_JIT` - Enable the instrumentation of Just-In-Time compiled
|
||||
code. Code is considered to be JIT if the executable segment is not backed by a
|
||||
file.
|
||||
* `AFL_FRIDA_INST_NO_OPTIMIZE` - Don't use optimized inline assembly coverage
|
||||
instrumentation (the default where available). Required to use
|
||||
`AFL_FRIDA_INST_TRACE`.
|
||||
* `AFL_FRIDA_INST_NO_PREFETCH` - Disable prefetching. By default the child will
|
||||
report instrumented blocks back to the parent so that it can also instrument
|
||||
them and they be inherited by the next child on fork.
|
||||
* `AFL_FRIDA_INST_SEED` - Sets the initial seed for the hash function used to
|
||||
generate block (and hence edge) IDs. Setting this to a constant value may be
|
||||
useful for debugging purposes, e.g. investigating unstable edges.
|
||||
* `AFL_FRIDA_INST_TRACE` - Log to stdout the address of executed blocks,
|
||||
implies `AFL_FRIDA_INST_NO_OPTIMIZE`.
|
||||
* `AFL_FRIDA_INST_TRACE_UNIQUE` - As per `AFL_FRIDA_INST_TRACE`, but each edge
|
||||
is logged only once, requires `AFL_FRIDA_INST_NO_OPTIMIZE`.
|
||||
* `AFL_FRIDA_OUTPUT_STDOUT` - Redirect the standard output of the target
|
||||
application to the named file (supersedes the setting of `AFL_DEBUG_CHILD`)
|
||||
* `AFL_FRIDA_OUTPUT_STDERR` - Redirect the standard error of the target
|
||||
application to the named file (supersedes the setting of `AFL_DEBUG_CHILD`)
|
||||
* `AFL_FRIDA_PERSISTENT_DEBUG` - Insert a Breakpoint into the instrumented code
|
||||
at `AFL_FRIDA_PERSISTENT_HOOK` and `AFL_FRIDA_PERSISTENT_RET` to allow the user
|
||||
to detect issues in the persistent loop using a debugger.
|
||||
|
||||
```
|
||||
|
||||
gdb \
|
||||
--ex 'set environment AFL_FRIDA_PERSISTENT_ADDR=XXXXXXXXXX' \
|
||||
--ex 'set environment AFL_FRIDA_PERSISTENT_RET=XXXXXXXXXX' \
|
||||
--ex 'set environment AFL_FRIDA_PERSISTENT_DEBUG=1' \
|
||||
--ex 'set environment AFL_DEBUG_CHILD=1' \
|
||||
--ex 'set environment LD_PRELOAD=afl-frida-trace.so' \
|
||||
--args <my-executable> [my arguments]
|
||||
|
||||
```
|
||||
* `AFL_FRIDA_STATS_FILE` - Write statistics information about the code being
|
||||
instrumented to the given file name. The statistics are written only for the
|
||||
child process when new block is instrumented (when the
|
||||
`AFL_FRIDA_STATS_INTERVAL` has expired). Note that simply because a new path is
|
||||
found does not mean a new block needs to be compiled. It could simply be that
|
||||
the existing blocks instrumented have been executed in a different order.
|
||||
```
|
||||
stats
|
||||
-----
|
||||
Index: 2
|
||||
Pid: 1815944
|
||||
Time: 2021-05-28 15:26:41
|
||||
Blocks: 1985
|
||||
Instructions: 9192
|
||||
Avg Instructions / Block: 4
|
||||
|
||||
Call Immediates: 391 (4.25%)
|
||||
Call Immediates Excluded: 65 (0.71%)
|
||||
Call Register: 0 (0.00%)
|
||||
Call Memory: 0 (0.00%)
|
||||
|
||||
Jump Immediates: 202 (2.20%)
|
||||
Jump Register: 10 (0.11%)
|
||||
Jump Memory: 12 (0.13%)
|
||||
|
||||
Conditional Jump Immediates: 1210 (13.16%)
|
||||
Conditional Jump CX Immediate: 0 (0.00%)
|
||||
Conditional Jump Register: 0 (0.00%)
|
||||
Conditional Jump Memory: 0 (0.00%)
|
||||
|
||||
Returns: 159 (0.00%)
|
||||
|
||||
Rip Relative: 247 (0.00%)
|
||||
|
||||
```
|
||||
* `AFL_FRIDA_STATS_INTERVAL` - The maximum frequency to output statistics
|
||||
information. Stats will be written whenever they are updated if the given
|
||||
interval has elapsed since last time they were written.
|
||||
* `AFL_FRIDA_STATS_TRANSITIONS` - Also dump the internal stalker counters to
|
||||
stderr when the regular stats are written. Note that these stats are reset in
|
||||
the child each time a new fork occurs since they are not stored in shared
|
||||
memory. Unfortunately, these stats are internal to stalker, so this is the best
|
||||
we can do for now.
|
||||
```
|
||||
stats
|
||||
-----
|
||||
Index: 2
|
||||
Pid: 1816794
|
||||
Time: 2021-05-28 15:26:41
|
||||
|
||||
|
||||
total_transitions: 786
|
||||
call_imms: 97
|
||||
call_regs: 0
|
||||
call_mems: 0
|
||||
post_call_invokes: 86
|
||||
excluded_call_imms: 29
|
||||
ret_slow_paths: 23
|
||||
|
||||
jmp_imms: 58
|
||||
jmp_mems: 7
|
||||
jmp_regs: 26
|
||||
|
||||
jmp_cond_imms: 460
|
||||
jmp_cond_mems: 0
|
||||
jmp_cond_regs: 0
|
||||
jmp_cond_jcxzs: 0
|
||||
|
||||
jmp_continuations: 0
|
||||
```
|
||||
## FASAN - Frida Address Sanitizer Mode
|
||||
Frida mode also supports FASAN. The design of this is actually quite simple and
|
||||
very similar to that used when instrumenting applications compiled from source.
|
||||
|
||||
### Address Sanitizer Basics
|
||||
|
||||
When Address Sanitizer is used to instrument programs built from source, the
|
||||
compiler first adds a dependency (`DT_NEEDED` entry) for the Address Sanitizer
|
||||
dynamic shared object (DSO). This shared object contains the main logic for Address
|
||||
Sanitizer, including setting and managing up the shadow memory. It also provides
|
||||
replacement implementations for a number of functions in standard libraries.
|
||||
|
||||
These replacements include things like `malloc` and `free` which allows for those
|
||||
allocations to be marked in the shadow memory, but also a number of other fuctions.
|
||||
Consider `memcpy` for example, this is instrumented to validate the paramters
|
||||
(test the source and destination buffers against the shadow memory. This is much
|
||||
easier than instrumenting those standard libraries since, first it would require
|
||||
you to re-compile them and secondly it would mean that the instrumentation would
|
||||
be applied at a more expensive granular level. Lastly, load-widening (typically
|
||||
found in highy optimized code) can also make this instrumentation more difficult.
|
||||
|
||||
Since the DSO is loaded before all of the standard libraries (in fact it insists
|
||||
on being first), the dynamic loader will use it to resolve imports from other
|
||||
modules which depend on it.
|
||||
|
||||
### FASAN Implementation
|
||||
|
||||
FASAN takes a similar approach. It requires the user to add the Address Sanitizer
|
||||
DSO to the `AFL_PRELOAD` environment variable such that it is loaded into the target.
|
||||
Again, it must be first in the list. This means that it is not necessary to
|
||||
instrument the standard libraries to detect when an application has provided an
|
||||
incorrect argument to `memcpy` for example. This avoids issues with load-widening
|
||||
and should also mean a huge improvement in performance.
|
||||
|
||||
FASAN then adds instrumentation for any instrucutions which use memory operands and
|
||||
then calls into the `__asan_loadN` and `__asan_storeN` functions provided by the DSO
|
||||
to validate memory accesses against the shadow memory.
|
||||
|
||||
# Collisions
|
||||
FRIDA mode has also introduced some improvements to reduce collisions in the map.
|
||||
See [here](MapDensity.md) for details.
|
||||
|
||||
## TODO
|
||||
|
||||
The next features to be added are Aarch32 support as well as looking at
|
||||
potential performance improvements. The intention is to achieve feature parity with
|
||||
QEMU mode in due course. Contributions are welcome, but please get in touch to
|
||||
ensure that efforts are deconflicted.
|
||||
@ -1,863 +0,0 @@
|
||||
# Scripting
|
||||
FRIDA now supports the ability to configure itself using JavaScript. This allows
|
||||
the user to make use of the convenience of FRIDA's scripting engine (along with
|
||||
it's support for debug symbols and exports) to configure all of the things which
|
||||
were traditionally configured using environment variables.
|
||||
|
||||
By default FRIDA mode will look for the file `afl.js` in the current working
|
||||
directory of the target. Alternatively, a script file can be configured using
|
||||
the environment variable `AFL_FRIDA_JS_SCRIPT`.
|
||||
|
||||
This script can make use of all of the standard [frida api functions](https://frida.re/docs/javascript-api/), but FRIDA mode adds some additional functions to allow
|
||||
you to interact with FRIDA mode itself. These can all be accessed via the global
|
||||
`Afl` parameter. e.g. `Afl.print("HELLO WORLD");`,
|
||||
|
||||
If you encounter a problem with your script, then you should set the environment
|
||||
variable `AFL_DEBUG_CHILD=1` to view any diagnostic information.
|
||||
|
||||
|
||||
# Example
|
||||
Most of the time, users will likely be wanting to call the functions which configure an address (e.g. for the entry point, or the persistent address).
|
||||
|
||||
The example below uses the API [`DebugSymbol.fromName()`](https://frida.re/docs/javascript-api/#debugsymbol). Another use API is [`Module.getExportByName()`](https://frida.re/docs/javascript-api/#module).
|
||||
|
||||
```js
|
||||
/* Use Afl.print instead of console.log */
|
||||
Afl.print('******************');
|
||||
Afl.print('* AFL FRIDA MODE *');
|
||||
Afl.print('******************');
|
||||
Afl.print('');
|
||||
|
||||
/* Print some useful diagnostics stuff */
|
||||
Afl.print(`PID: ${Process.id}`);
|
||||
|
||||
new ModuleMap().values().forEach(m => {
|
||||
Afl.print(`${m.base}-${m.base.add(m.size)} ${m.name}`);
|
||||
});
|
||||
|
||||
/*
|
||||
* Configure entry-point, persistence etc. This will be what most
|
||||
* people want to do.
|
||||
*/
|
||||
const persistent_addr = DebugSymbol.fromName('main');
|
||||
Afl.print(`persistent_addr: ${persistent_addr.address}`);
|
||||
|
||||
if (persistent_addr.address.equals(ptr(0))) {
|
||||
Afl.error('Cannot find symbol main');
|
||||
}
|
||||
|
||||
const persistent_ret = DebugSymbol.fromName('slow');
|
||||
Afl.print(`persistent_ret: ${persistent_ret.address}`);
|
||||
|
||||
if (persistent_ret.address.equals(ptr(0))) {
|
||||
Afl.error('Cannot find symbol slow');
|
||||
}
|
||||
|
||||
Afl.setPersistentAddress(persistent_addr.address);
|
||||
Afl.setPersistentReturn(persistent_ret.address);
|
||||
Afl.setPersistentCount(1000000);
|
||||
|
||||
/* Control instrumentation, you may want to do this too */
|
||||
Afl.setInstrumentLibraries();
|
||||
const mod = Process.findModuleByName("libc-2.31.so")
|
||||
Afl.addExcludedRange(mod.base, mod.size);
|
||||
|
||||
/* Some useful options to configure logging */
|
||||
Afl.setStdOut("/tmp/stdout.txt");
|
||||
Afl.setStdErr("/tmp/stderr.txt");
|
||||
|
||||
/* Show the address layout. Sometimes helpful */
|
||||
Afl.setDebugMaps();
|
||||
|
||||
/*
|
||||
* If you are using these options, then things aren't going
|
||||
* very well for you.
|
||||
*/
|
||||
Afl.setInstrumentDebugFile("/tmp/instr.log");
|
||||
Afl.setPrefetchDisable();
|
||||
Afl.setInstrumentNoOptimize();
|
||||
Afl.setInstrumentEnableTracing();
|
||||
Afl.setInstrumentTracingUnique();
|
||||
Afl.setStatsFile("/tmp/stats.txt");
|
||||
Afl.setStatsInterval(1);
|
||||
Afl.setStatsTransitions();
|
||||
|
||||
/* *ALWAYS* call this when you have finished all your configuration */
|
||||
Afl.done();
|
||||
Afl.print("done");
|
||||
```
|
||||
|
||||
# Stripped Binaries
|
||||
|
||||
Lastly, if the binary you attempting to fuzz has no symbol information, and no
|
||||
exports, then the following approach can be used.
|
||||
|
||||
```js
|
||||
const module = Process.getModuleByName('target.exe');
|
||||
/* Hardcoded offset within the target image */
|
||||
const address = module.base.add(0xdeadface);
|
||||
Afl.setPersistentAddress(address);
|
||||
```
|
||||
|
||||
# Persisent Hook
|
||||
A persistent hook can be implemented using a conventional shared object, sample
|
||||
source code for a hook suitable for the prototype of `LLVMFuzzerTestOneInput`
|
||||
can be found [here](hook/hook.c). This can be configured using code similar to
|
||||
the following.
|
||||
|
||||
```js
|
||||
const path = Afl.module.path;
|
||||
const dir = path.substring(0, path.lastIndexOf("/"));
|
||||
const mod = Module.load(`${dir}/frida_mode/build/hook.so`);
|
||||
const hook = mod.getExportByName('afl_persistent_hook');
|
||||
Afl.setPersistentHook(hook);
|
||||
```
|
||||
|
||||
Alternatively, the hook can be provided by using FRIDAs built in support for `CModule`, powered by TinyCC.
|
||||
|
||||
```js
|
||||
const cm = new CModule(`
|
||||
|
||||
#include <string.h>
|
||||
#include <gum/gumdefs.h>
|
||||
|
||||
void afl_persistent_hook(GumCpuContext *regs, uint8_t *input_buf,
|
||||
uint32_t input_buf_len) {
|
||||
|
||||
memcpy((void *)regs->rdi, input_buf, input_buf_len);
|
||||
regs->rsi = input_buf_len;
|
||||
|
||||
}
|
||||
`,
|
||||
{
|
||||
memcpy: Module.getExportByName(null, 'memcpy')
|
||||
});
|
||||
Afl.setPersistentHook(cm.afl_persistent_hook);
|
||||
```
|
||||
|
||||
# Advanced Persistence
|
||||
Consider the following target code...
|
||||
```c
|
||||
|
||||
#include <fcntl.h>
|
||||
#include <stdbool.h>
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <unistd.h>
|
||||
|
||||
void LLVMFuzzerTestOneInput(char *buf, int len) {
|
||||
|
||||
if (len < 1) return;
|
||||
buf[len] = 0;
|
||||
|
||||
// we support three input cases
|
||||
if (buf[0] == '0')
|
||||
printf("Looks like a zero to me!\n");
|
||||
else if (buf[0] == '1')
|
||||
printf("Pretty sure that is a one!\n");
|
||||
else
|
||||
printf("Neither one or zero? How quaint!\n");
|
||||
|
||||
}
|
||||
|
||||
int run(char *file) {
|
||||
|
||||
int fd = -1;
|
||||
off_t len;
|
||||
char * buf = NULL;
|
||||
size_t n_read;
|
||||
int result = -1;
|
||||
|
||||
do {
|
||||
|
||||
dprintf(STDERR_FILENO, "Running: %s\n", file);
|
||||
|
||||
fd = open(file, O_RDONLY);
|
||||
if (fd < 0) {
|
||||
|
||||
perror("open");
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
len = lseek(fd, 0, SEEK_END);
|
||||
if (len < 0) {
|
||||
|
||||
perror("lseek (SEEK_END)");
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
if (lseek(fd, 0, SEEK_SET) != 0) {
|
||||
|
||||
perror("lseek (SEEK_SET)");
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
buf = malloc(len);
|
||||
if (buf == NULL) {
|
||||
|
||||
perror("malloc");
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
n_read = read(fd, buf, len);
|
||||
if (n_read != len) {
|
||||
|
||||
perror("read");
|
||||
break;
|
||||
|
||||
}
|
||||
|
||||
dprintf(STDERR_FILENO, "Running: %s: (%zd bytes)\n", file, n_read);
|
||||
|
||||
LLVMFuzzerTestOneInput(buf, len);
|
||||
dprintf(STDERR_FILENO, "Done: %s: (%zd bytes)\n", file, n_read);
|
||||
|
||||
result = 0;
|
||||
|
||||
} while (false);
|
||||
|
||||
if (buf != NULL) { free(buf); }
|
||||
|
||||
if (fd != -1) { close(fd); }
|
||||
|
||||
return result;
|
||||
|
||||
}
|
||||
|
||||
void slow() {
|
||||
|
||||
usleep(100000);
|
||||
|
||||
}
|
||||
|
||||
int main(int argc, char **argv) {
|
||||
|
||||
if (argc != 2) { return 1; }
|
||||
slow();
|
||||
return run(argv[1]);
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
FRIDA mode supports the replacement of any function, with an implementation
|
||||
generated by CModule. This allows for a bespoke harness to be written as
|
||||
follows:
|
||||
|
||||
```
|
||||
const slow = DebugSymbol.fromName('slow').address;
|
||||
Afl.print(`slow: ${slow}`);
|
||||
|
||||
const LLVMFuzzerTestOneInput = DebugSymbol.fromName('LLVMFuzzerTestOneInput').address;
|
||||
Afl.print(`LLVMFuzzerTestOneInput: ${LLVMFuzzerTestOneInput}`);
|
||||
|
||||
const cm = new CModule(`
|
||||
|
||||
extern unsigned char * __afl_fuzz_ptr;
|
||||
extern unsigned int * __afl_fuzz_len;
|
||||
extern void LLVMFuzzerTestOneInput(char *buf, int len);
|
||||
|
||||
void slow(void) {
|
||||
|
||||
LLVMFuzzerTestOneInput(__afl_fuzz_ptr, *__afl_fuzz_len);
|
||||
}
|
||||
`,
|
||||
{
|
||||
LLVMFuzzerTestOneInput: LLVMFuzzerTestOneInput,
|
||||
__afl_fuzz_ptr: Afl.getAflFuzzPtr(),
|
||||
__afl_fuzz_len: Afl.getAflFuzzLen()
|
||||
});
|
||||
|
||||
Afl.setEntryPoint(cm.slow);
|
||||
Afl.setPersistentAddress(cm.slow);
|
||||
Afl.setInMemoryFuzzing();
|
||||
Interceptor.replace(slow, cm.slow);
|
||||
Afl.print("done");
|
||||
Afl.done();
|
||||
```
|
||||
|
||||
Here, we replace the function `slow` with our own code. This code is then
|
||||
selected as the entry point as well as the persistent loop address.
|
||||
|
||||
**WARNING** There are two key limitations in replacing a function in this way:
|
||||
- The function which is to be replaced must not be `main` this is because this
|
||||
is the point at which FRIDA mode is initialized and at the point the the JS has
|
||||
been run, the start of the `main` function has already been instrumented and
|
||||
cached.
|
||||
- The replacement function must not call itself. e.g. in this example we
|
||||
couldn't replace `LLVMFuzzerTestOneInput` and call itself.
|
||||
|
||||
# Patching
|
||||
Consider the [following](test/js/test2.c) test code...
|
||||
|
||||
```c
|
||||
/*
|
||||
american fuzzy lop++ - a trivial program to test the build
|
||||
--------------------------------------------------------
|
||||
Originally written by Michal Zalewski
|
||||
Copyright 2014 Google Inc. All rights reserved.
|
||||
Copyright 2019-2020 AFLplusplus Project. All rights reserved.
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at:
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
*/
|
||||
|
||||
#include <fcntl.h>
|
||||
#include <stdbool.h>
|
||||
#include <stdio.h>
|
||||
#include <stdint.h>
|
||||
#include <stdlib.h>
|
||||
#include <unistd.h>
|
||||
|
||||
const uint32_t crc32_tab[] = {
|
||||
0x00000000, 0x77073096, 0xee0e612c, 0x990951ba, 0x076dc419, 0x706af48f,
|
||||
|
||||
...
|
||||
|
||||
0xb40bbe37, 0xc30c8ea1, 0x5a05df1b, 0x2d02ef8d
|
||||
};
|
||||
|
||||
uint32_t
|
||||
crc32(const void *buf, size_t size)
|
||||
{
|
||||
const uint8_t *p = buf;
|
||||
uint32_t crc;
|
||||
crc = ~0U;
|
||||
while (size--)
|
||||
crc = crc32_tab[(crc ^ *p++) & 0xFF] ^ (crc >> 8);
|
||||
return crc ^ ~0U;
|
||||
}
|
||||
|
||||
/*
|
||||
* Don't you hate those contrived examples which CRC their data. We can use
|
||||
* FRIDA to patch this function out and always return success. Otherwise, we
|
||||
* could change it to actually correct the checksum.
|
||||
*/
|
||||
int crc32_check (char * buf, int len) {
|
||||
if (len < sizeof(uint32_t)) { return 0; }
|
||||
uint32_t expected = *(uint32_t *)&buf[len - sizeof(uint32_t)];
|
||||
uint32_t calculated = crc32(buf, len - sizeof(uint32_t));
|
||||
return expected == calculated;
|
||||
}
|
||||
|
||||
/*
|
||||
* So you've found a really boring bug in an earlier campaign which results in
|
||||
* a NULL dereference or something like that. That bug can get in the way,
|
||||
* causing the persistent loop to exit whenever it is triggered, and can also
|
||||
* cloud your output unnecessarily. Again, we can use FRIDA to patch it out.
|
||||
*/
|
||||
void some_boring_bug(char c) {
|
||||
switch (c) {
|
||||
case 'A'...'Z':
|
||||
case 'a'...'z':
|
||||
__builtin_trap();
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
void LLVMFuzzerTestOneInput(char *buf, int len) {
|
||||
|
||||
if (!crc32_check(buf, len)) return;
|
||||
|
||||
some_boring_bug(buf[0]);
|
||||
|
||||
if (buf[0] == '0') {
|
||||
printf("Looks like a zero to me!\n");
|
||||
}
|
||||
else if (buf[0] == '1') {
|
||||
printf("Pretty sure that is a one!\n");
|
||||
}
|
||||
else if (buf[0] == '2') {
|
||||
if (buf[1] == '3') {
|
||||
if (buf[2] == '4') {
|
||||
printf("Oh we, weren't expecting that!");
|
||||
__builtin_trap();
|
||||
}
|
||||
}
|
||||
}
|
||||
else
|
||||
printf("Neither one or zero? How quaint!\n");
|
||||
|
||||
}
|
||||
|
||||
int main(int argc, char **argv) {
|
||||
|
||||
int fd = -1;
|
||||
off_t len;
|
||||
char * buf = NULL;
|
||||
size_t n_read;
|
||||
int result = -1;
|
||||
|
||||
if (argc != 2) { return 1; }
|
||||
|
||||
printf("Running: %s\n", argv[1]);
|
||||
|
||||
fd = open(argv[1], O_RDONLY);
|
||||
if (fd < 0) { return 1; }
|
||||
|
||||
len = lseek(fd, 0, SEEK_END);
|
||||
if (len < 0) { return 1; }
|
||||
|
||||
if (lseek(fd, 0, SEEK_SET) != 0) { return 1; }
|
||||
|
||||
buf = malloc(len);
|
||||
if (buf == NULL) { return 1; }
|
||||
|
||||
n_read = read(fd, buf, len);
|
||||
if (n_read != len) { return 1; }
|
||||
|
||||
printf("Running: %s: (%zd bytes)\n", argv[1], n_read);
|
||||
|
||||
LLVMFuzzerTestOneInput(buf, len);
|
||||
printf("Done: %s: (%zd bytes)\n", argv[1], n_read);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
There are a couple of obstacles with our target application. Unlike when fuzzing
|
||||
source code, though, we can't simply edit it and recompile it. The following
|
||||
script shows how we can use the normal functionality of FRIDA to modify any
|
||||
troublesome behaviour.
|
||||
|
||||
```js
|
||||
Afl.print('******************');
|
||||
Afl.print('* AFL FRIDA MODE *');
|
||||
Afl.print('******************');
|
||||
Afl.print('');
|
||||
|
||||
const main = DebugSymbol.fromName('main').address;
|
||||
Afl.print(`main: ${main}`);
|
||||
Afl.setEntryPoint(main);
|
||||
Afl.setPersistentAddress(main);
|
||||
Afl.setPersistentCount(10000000);
|
||||
|
||||
const crc32_check = DebugSymbol.fromName('crc32_check').address;
|
||||
const crc32_replacement = new NativeCallback(
|
||||
(buf, len) => {
|
||||
Afl.print(`len: ${len}`);
|
||||
if (len < 4) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
return 1;
|
||||
},
|
||||
'int',
|
||||
['pointer', 'int']);
|
||||
Interceptor.replace(crc32_check, crc32_replacement);
|
||||
|
||||
const some_boring_bug = DebugSymbol.fromName('some_boring_bug').address
|
||||
const boring_replacement = new NativeCallback(
|
||||
(c) => { },
|
||||
'void',
|
||||
['char']);
|
||||
Interceptor.replace(some_boring_bug, boring_replacement);
|
||||
|
||||
Afl.done();
|
||||
Afl.print("done");
|
||||
```
|
||||
|
||||
# Advanced Patching
|
||||
Consider the following code fragment...
|
||||
```c
|
||||
extern void some_boring_bug2(char c);
|
||||
|
||||
__asm__ (
|
||||
".text \n"
|
||||
"some_boring_bug2: \n"
|
||||
".global some_boring_bug2 \n"
|
||||
".type some_boring_bug2, @function \n"
|
||||
"mov %edi, %eax \n"
|
||||
"cmp $0xb4, %al \n"
|
||||
"jne ok \n"
|
||||
"ud2 \n"
|
||||
"ok: \n"
|
||||
"ret \n");
|
||||
|
||||
void LLVMFuzzerTestOneInput(char *buf, int len) {
|
||||
|
||||
...
|
||||
|
||||
some_boring_bug2(buf[0]);
|
||||
|
||||
...
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Rather than using FRIDAs `Interceptor.replace` or `Interceptor.attach` APIs, it
|
||||
is possible to apply much more fine grained modification to the target
|
||||
application by means of using the Stalker APIs.
|
||||
|
||||
The following code locates the function of interest and patches out the UD2
|
||||
instruction signifying a crash.
|
||||
|
||||
```js
|
||||
/* Modify the instructions */
|
||||
const some_boring_bug2 = DebugSymbol.fromName('some_boring_bug2').address
|
||||
const pid = Memory.alloc(4);
|
||||
pid.writeInt(Process.id);
|
||||
|
||||
const cm = new CModule(`
|
||||
#include <stdio.h>
|
||||
#include <gum/gumstalker.h>
|
||||
|
||||
typedef int pid_t;
|
||||
|
||||
#define STDERR_FILENO 2
|
||||
#define BORING2_LEN 10
|
||||
|
||||
extern int dprintf(int fd, const char *format, ...);
|
||||
extern void some_boring_bug2(char c);
|
||||
extern pid_t getpid(void);
|
||||
extern pid_t pid;
|
||||
|
||||
gboolean js_stalker_callback(const cs_insn *insn, gboolean begin,
|
||||
gboolean excluded, GumStalkerOutput *output)
|
||||
{
|
||||
pid_t my_pid = getpid();
|
||||
GumX86Writer *cw = output->writer.x86;
|
||||
|
||||
if (GUM_ADDRESS(insn->address) < GUM_ADDRESS(some_boring_bug2)) {
|
||||
|
||||
return TRUE;
|
||||
|
||||
}
|
||||
|
||||
if (GUM_ADDRESS(insn->address) >=
|
||||
GUM_ADDRESS(some_boring_bug2) + BORING2_LEN) {
|
||||
|
||||
return TRUE;
|
||||
|
||||
}
|
||||
|
||||
if (my_pid == pid) {
|
||||
|
||||
if (begin) {
|
||||
|
||||
dprintf(STDERR_FILENO, "\n> 0x%016lX: %s %s\n", insn->address,
|
||||
insn->mnemonic, insn->op_str);
|
||||
|
||||
} else {
|
||||
|
||||
dprintf(STDERR_FILENO, " 0x%016lX: %s %s\n", insn->address,
|
||||
insn->mnemonic, insn->op_str);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (insn->id == X86_INS_UD2) {
|
||||
|
||||
gum_x86_writer_put_nop(cw);
|
||||
return FALSE;
|
||||
|
||||
} else {
|
||||
|
||||
return TRUE;
|
||||
|
||||
}
|
||||
}
|
||||
`,
|
||||
{
|
||||
dprintf: Module.getExportByName(null, 'dprintf'),
|
||||
getpid: Module.getExportByName(null, 'getpid'),
|
||||
some_boring_bug2: some_boring_bug2,
|
||||
pid: pid
|
||||
});
|
||||
Afl.setStalkerCallback(cm.js_stalker_callback)
|
||||
Afl.setStdErr("/tmp/stderr.txt");
|
||||
```
|
||||
|
||||
Note that you will more likely want to find the
|
||||
patch address by using:
|
||||
|
||||
```js
|
||||
const module = Process.getModuleByName('target.exe');
|
||||
/* Hardcoded offset within the target image */
|
||||
const address = module.base.add(0xdeadface);
|
||||
```
|
||||
OR
|
||||
```
|
||||
const address = DebugSymbol.fromName("my_function").address.add(0xdeadface);
|
||||
```
|
||||
OR
|
||||
```
|
||||
const address = Module.getExportByName(null, "my_function").add(0xdeadface);
|
||||
```
|
||||
|
||||
The function `js_stalker_callback` should return `TRUE` if the original
|
||||
instruction should be emitted in the instrumented code, or `FALSE` otherwise.
|
||||
In the example above, we can see it is replaced with a `NOP`.
|
||||
|
||||
Lastly, note that the same callback will be called when compiling instrumented
|
||||
code both in the child of the forkserver (as it is executed) and also in the
|
||||
parent of the forserver (when prefetching is enabled) so that it can be
|
||||
inherited by the next forked child. It is **VERY** important that the same
|
||||
instructions be generated in both the parent and the child, or if prefetching is
|
||||
disabled that the same instructions are generated every time the block is
|
||||
compiled. Failure to do so will likely lead to bugs which are incredibly
|
||||
difficult to diagnose. The code above only prints the instructions when running
|
||||
in the parent process (the one provided by `Process.id` when the JS script is
|
||||
executed).
|
||||
|
||||
# OSX
|
||||
Note that the JavaScript debug symbol api for OSX makes use of the
|
||||
`CoreSymbolication` APIs and as such the `CoreFoundation` module must be loaded
|
||||
into the target to make use of it. This can be done by setting:
|
||||
|
||||
```
|
||||
AFL_PRELOAD=/System/Library/Frameworks/CoreFoundation.framework/CoreFoundation
|
||||
```
|
||||
|
||||
It should be noted that `CoreSymbolication` API may take a while to initialize
|
||||
and build its caches. For this reason, it may be nescessary to also increase the
|
||||
value of the `-t` flag passed to `afl-fuzz`.
|
||||
|
||||
# API
|
||||
```js
|
||||
class Afl {
|
||||
|
||||
/**
|
||||
* Field containing the `Module` object for `afl-frida-trace.so` (the FRIDA mode
|
||||
* implementation).
|
||||
*/
|
||||
public static module: Module = Process.getModuleByName("afl-frida-trace.so");
|
||||
|
||||
/**
|
||||
* This is equivalent to setting a value in `AFL_FRIDA_EXCLUDE_RANGES`,
|
||||
* it takes as arguments a `NativePointer` and a `number`. It can be
|
||||
* called multiple times to exclude several ranges.
|
||||
*/
|
||||
public static addExcludedRange(addressess: NativePointer, size: number): void {
|
||||
Afl.jsApiAddExcludeRange(addressess, size);
|
||||
}
|
||||
|
||||
/**
|
||||
* This is equivalent to setting a value in `AFL_FRIDA_INST_RANGES`,
|
||||
* it takes as arguments a `NativePointer` and a `number`. It can be
|
||||
* called multiple times to include several ranges.
|
||||
*/
|
||||
public static addIncludedRange(addressess: NativePointer, size: number): void {
|
||||
Afl.jsApiAddIncludeRange(addressess, size);
|
||||
}
|
||||
|
||||
/**
|
||||
* This must always be called at the end of your script. This lets
|
||||
* FRIDA mode know that your configuration is finished and that
|
||||
* execution has reached the end of your script. Failure to call
|
||||
* this will result in a fatal error.
|
||||
*/
|
||||
public static done(): void {
|
||||
Afl.jsApiDone();
|
||||
}
|
||||
|
||||
/**
|
||||
* This function can be called within your script to cause FRIDA
|
||||
* mode to trigger a fatal error. This is useful if for example you
|
||||
* discover a problem you weren't expecting and want everything to
|
||||
* stop. The user will need to enable `AFL_DEBUG_CHILD=1` to view
|
||||
* this error message.
|
||||
*/
|
||||
public static error(msg: string): void {
|
||||
const buf = Memory.allocUtf8String(msg);
|
||||
Afl.jsApiError(buf);
|
||||
}
|
||||
|
||||
/**
|
||||
* Function used to provide access to `__afl_fuzz_ptr`, which contains the length of
|
||||
* fuzzing data when using in-memory test case fuzzing.
|
||||
*/
|
||||
public static getAflFuzzLen(): NativePointer {
|
||||
|
||||
return Afl.jsApiGetSymbol("__afl_fuzz_len");
|
||||
}
|
||||
|
||||
/**
|
||||
* Function used to provide access to `__afl_fuzz_ptr`, which contains the fuzzing
|
||||
* data when using in-memory test case fuzzing.
|
||||
*/
|
||||
public static getAflFuzzPtr(): NativePointer {
|
||||
|
||||
return Afl.jsApiGetSymbol("__afl_fuzz_ptr");
|
||||
}
|
||||
|
||||
/**
|
||||
* Print a message to the STDOUT. This should be preferred to
|
||||
* FRIDA's `console.log` since FRIDA will queue it's log messages.
|
||||
* If `console.log` is used in a callback in particular, then there
|
||||
* may no longer be a thread running to service this queue.
|
||||
*/
|
||||
public static print(msg: string): void {
|
||||
const STDOUT_FILENO = 2;
|
||||
const log = `${msg}\n`;
|
||||
const buf = Memory.allocUtf8String(log);
|
||||
Afl.jsApiWrite(STDOUT_FILENO, buf, log.length);
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_DEBUG_MAPS`.
|
||||
*/
|
||||
public static setDebugMaps(): void {
|
||||
Afl.jsApiSetDebugMaps();
|
||||
}
|
||||
|
||||
/**
|
||||
* This has the same effect as setting `AFL_ENTRYPOINT`, but has the
|
||||
* convenience of allowing you to use FRIDAs APIs to determine the
|
||||
* address you would like to configure, rather than having to grep
|
||||
* the output of `readelf` or something similarly ugly. This
|
||||
* function should be called with a `NativePointer` as its
|
||||
* argument.
|
||||
*/
|
||||
public static setEntryPoint(address: NativePointer): void {
|
||||
Afl.jsApiSetEntryPoint(address);
|
||||
}
|
||||
|
||||
/**
|
||||
* Function used to enable in-memory test cases for fuzzing.
|
||||
*/
|
||||
public static setInMemoryFuzzing(): void {
|
||||
Afl.jsApiAflSharedMemFuzzing.writeInt(1);
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_INST_DEBUG_FILE`. This function takes a single `string` as
|
||||
* an argument.
|
||||
*/
|
||||
public static setInstrumentDebugFile(file: string): void {
|
||||
const buf = Memory.allocUtf8String(file);
|
||||
Afl.jsApiSetInstrumentDebugFile(buf);
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_INST_TRACE`.
|
||||
*/
|
||||
public static setInstrumentEnableTracing(): void {
|
||||
Afl.jsApiSetInstrumentTrace();
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_INST_LIBS`.
|
||||
*/
|
||||
public static setInstrumentLibraries(): void {
|
||||
Afl.jsApiSetInstrumentLibraries();
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_INST_NO_OPTIMIZE`
|
||||
*/
|
||||
public static setInstrumentNoOptimize(): void {
|
||||
Afl.jsApiSetInstrumentNoOptimize();
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_INST_TRACE_UNIQUE`.
|
||||
*/
|
||||
public static setInstrumentTracingUnique(): void {
|
||||
Afl.jsApiSetInstrumentTraceUnique();
|
||||
}
|
||||
|
||||
/**
|
||||
* This is equivalent to setting `AFL_FRIDA_PERSISTENT_ADDR`, again a
|
||||
* `NativePointer` should be provided as it's argument.
|
||||
*/
|
||||
public static setPersistentAddress(address: NativePointer): void {
|
||||
Afl.jsApiSetPersistentAddress(address);
|
||||
}
|
||||
|
||||
/**
|
||||
* This is equivalent to setting `AFL_FRIDA_PERSISTENT_CNT`, a
|
||||
* `number` should be provided as it's argument.
|
||||
*/
|
||||
public static setPersistentCount(count: number): void {
|
||||
Afl.jsApiSetPersistentCount(count);
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_PERSISTENT_DEBUG`.
|
||||
*/
|
||||
public static setPersistentDebug(): void {
|
||||
Afl.jsApiSetPersistentDebug();
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_PERSISTENT_ADDR`. This function takes a NativePointer as an
|
||||
* argument. See above for examples of use.
|
||||
*/
|
||||
public static setPersistentHook(address: NativePointer): void {
|
||||
Afl.jsApiSetPersistentHook(address);
|
||||
}
|
||||
|
||||
/**
|
||||
* This is equivalent to setting `AFL_FRIDA_PERSISTENT_RET`, again a
|
||||
* `NativePointer` should be provided as it's argument.
|
||||
*/
|
||||
public static setPersistentReturn(address: NativePointer): void {
|
||||
Afl.jsApiSetPersistentReturn(address);
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_INST_NO_PREFETCH`.
|
||||
*/
|
||||
public static setPrefetchDisable(): void {
|
||||
Afl.jsApiSetPrefetchDisable();
|
||||
}
|
||||
|
||||
/*
|
||||
* Set a function to be called for each instruction which is instrumented
|
||||
* by AFL FRIDA mode.
|
||||
*/
|
||||
public static setStalkerCallback(callback: NativePointer): void {
|
||||
Afl.jsApiSetStalkerCallback(callback);
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_STATS_FILE`. This function takes a single `string` as
|
||||
* an argument.
|
||||
*/
|
||||
public static setStatsFile(file: string): void {
|
||||
const buf = Memory.allocUtf8String(file);
|
||||
Afl.jsApiSetStatsFile(buf);
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_STATS_INTERVAL`. This function takes a `number` as an
|
||||
* argument
|
||||
*/
|
||||
public static setStatsInterval(interval: number): void {
|
||||
Afl.jsApiSetStatsInterval(interval);
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_STATS_TRANSITIONS`
|
||||
*/
|
||||
public static setStatsTransitions(): void {
|
||||
Afl.jsApiSetStatsTransitions();
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_OUTPUT_STDERR`. This function takes a single `string` as
|
||||
* an argument.
|
||||
*/
|
||||
public static setStdErr(file: string): void {
|
||||
const buf = Memory.allocUtf8String(file);
|
||||
Afl.jsApiSetStdErr(buf);
|
||||
}
|
||||
|
||||
/**
|
||||
* See `AFL_FRIDA_OUTPUT_STDOUT`. This function takes a single `string` as
|
||||
* an argument.
|
||||
*/
|
||||
public static setStdOut(file: string): void {
|
||||
const buf = Memory.allocUtf8String(file);
|
||||
Afl.jsApiSetStdOut(buf);
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
@ -1,35 +0,0 @@
|
||||
{
|
||||
global:
|
||||
__afl_fuzz_len;
|
||||
__afl_fuzz_ptr;
|
||||
__afl_sharedmem_fuzzing;
|
||||
afl_frida_start;
|
||||
js_api_add_exclude_range;
|
||||
js_api_add_include_range;
|
||||
js_api_done;
|
||||
js_api_error;
|
||||
js_api_set_debug_maps;
|
||||
js_api_set_entrypoint;
|
||||
js_api_set_instrument_debug_file;
|
||||
js_api_set_instrument_jit;
|
||||
js_api_set_instrument_libraries;
|
||||
js_api_set_instrument_no_optimize;
|
||||
js_api_set_instrument_seed;
|
||||
js_api_set_instrument_trace;
|
||||
js_api_set_instrument_trace_unique;
|
||||
js_api_set_persistent_address;
|
||||
js_api_set_persistent_count;
|
||||
js_api_set_persistent_debug;
|
||||
js_api_set_persistent_hook;
|
||||
js_api_set_persistent_return;
|
||||
js_api_set_prefetch_disable;
|
||||
js_api_set_stalker_callback;
|
||||
js_api_set_stats_file;
|
||||
js_api_set_stats_interval;
|
||||
js_api_set_stats_transitions;
|
||||
js_api_set_stderr;
|
||||
js_api_set_stdout;
|
||||
|
||||
local:
|
||||
*;
|
||||
};
|
||||
@ -1,64 +0,0 @@
|
||||
/*
|
||||
*
|
||||
* Modify this file to set the right registers with the fuzz input and length.
|
||||
* It is a good idea to check input_buf_len to be not larger than the
|
||||
* destination buffer!
|
||||
*
|
||||
*/
|
||||
|
||||
#include <stdint.h>
|
||||
#include <string.h>
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
#if defined(__x86_64__)
|
||||
|
||||
__attribute__((visibility("default"))) void afl_persistent_hook(
|
||||
GumCpuContext *regs, uint8_t *input_buf, uint32_t input_buf_len) {
|
||||
|
||||
// do a length check matching the target!
|
||||
|
||||
memcpy((void *)regs->rdi, input_buf, input_buf_len);
|
||||
regs->rsi = input_buf_len;
|
||||
|
||||
}
|
||||
|
||||
#elif defined(__i386__)
|
||||
|
||||
__attribute__((visibility("default"))) void afl_persistent_hook(
|
||||
GumCpuContext *regs, uint8_t *input_buf, uint32_t input_buf_len) {
|
||||
|
||||
// do a length check matching the target!
|
||||
|
||||
void **esp = (void **)regs->esp;
|
||||
void * arg1 = esp[0];
|
||||
void **arg2 = &esp[1];
|
||||
memcpy(arg1, input_buf, input_buf_len);
|
||||
*arg2 = (void *)input_buf_len;
|
||||
|
||||
}
|
||||
|
||||
#elif defined(__aarch64__)
|
||||
|
||||
__attribute__((visibility("default"))) void afl_persistent_hook(
|
||||
GumCpuContext *regs, uint8_t *input_buf, uint32_t input_buf_len) {
|
||||
|
||||
// do a length check matching the target!
|
||||
|
||||
memcpy((void *)regs->x[0], input_buf, input_buf_len);
|
||||
regs->x[1] = input_buf_len;
|
||||
|
||||
}
|
||||
|
||||
#else
|
||||
#pragma error "Unsupported architecture"
|
||||
#endif
|
||||
|
||||
__attribute__((visibility("default"))) int afl_persistent_hook_init(void) {
|
||||
|
||||
// 1 for shared memory input (faster), 0 for normal input (you have to use
|
||||
// read(), input_buf will be NULL)
|
||||
return 1;
|
||||
|
||||
}
|
||||
|
||||
@ -1,195 +0,0 @@
|
||||
#include <stdint.h>
|
||||
#include <string.h>
|
||||
|
||||
#if defined(__x86_64__)
|
||||
|
||||
struct x86_64_regs {
|
||||
|
||||
uint64_t rax, rbx, rcx, rdx, rdi, rsi, rbp, r8, r9, r10, r11, r12, r13, r14,
|
||||
r15;
|
||||
|
||||
union {
|
||||
|
||||
uint64_t rip;
|
||||
uint64_t pc;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t rsp;
|
||||
uint64_t sp;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t rflags;
|
||||
uint64_t flags;
|
||||
|
||||
};
|
||||
|
||||
uint8_t zmm_regs[32][64];
|
||||
|
||||
};
|
||||
|
||||
void afl_persistent_hook(struct x86_64_regs *regs, uint64_t guest_base,
|
||||
uint8_t *input_buf, uint32_t input_buf_len) {
|
||||
|
||||
(void)guest_base; /* unused */
|
||||
memcpy((void *)regs->rdi, input_buf, input_buf_len);
|
||||
regs->rsi = input_buf_len;
|
||||
|
||||
}
|
||||
|
||||
#elif defined(__i386__)
|
||||
|
||||
struct x86_regs {
|
||||
|
||||
uint32_t eax, ebx, ecx, edx, edi, esi, ebp;
|
||||
|
||||
union {
|
||||
|
||||
uint32_t eip;
|
||||
uint32_t pc;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint32_t esp;
|
||||
uint32_t sp;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint32_t eflags;
|
||||
uint32_t flags;
|
||||
|
||||
};
|
||||
|
||||
uint8_t xmm_regs[8][16];
|
||||
|
||||
};
|
||||
|
||||
void afl_persistent_hook(struct x86_regs *regs, uint64_t guest_base,
|
||||
uint8_t *input_buf, uint32_t input_buf_len) {
|
||||
|
||||
(void)guest_base; /* unused */
|
||||
void **esp = (void **)regs->esp;
|
||||
void * arg1 = esp[1];
|
||||
void **arg2 = &esp[2];
|
||||
memcpy(arg1, input_buf, input_buf_len);
|
||||
*arg2 = (void *)input_buf_len;
|
||||
|
||||
}
|
||||
#elif defined(__aarch64__)
|
||||
|
||||
struct arm64_regs {
|
||||
|
||||
uint64_t x0, x1, x2, x3, x4, x5, x6, x7, x8, x9, x10;
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x11;
|
||||
uint32_t fp_32;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x12;
|
||||
uint32_t ip_32;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x13;
|
||||
uint32_t sp_32;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x14;
|
||||
uint32_t lr_32;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x15;
|
||||
uint32_t pc_32;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x16;
|
||||
uint64_t ip0;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x17;
|
||||
uint64_t ip1;
|
||||
|
||||
};
|
||||
|
||||
uint64_t x18, x19, x20, x21, x22, x23, x24, x25, x26, x27, x28;
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x29;
|
||||
uint64_t fp;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x30;
|
||||
uint64_t lr;
|
||||
|
||||
};
|
||||
|
||||
union {
|
||||
|
||||
uint64_t x31;
|
||||
uint64_t sp;
|
||||
|
||||
};
|
||||
|
||||
// the zero register is not saved here ofc
|
||||
|
||||
uint64_t pc;
|
||||
|
||||
uint32_t cpsr;
|
||||
|
||||
uint8_t vfp_zregs[32][16 * 16];
|
||||
uint8_t vfp_pregs[17][32];
|
||||
uint32_t vfp_xregs[16];
|
||||
|
||||
};
|
||||
|
||||
void afl_persistent_hook(struct arm64_regs *regs, uint64_t guest_base,
|
||||
uint8_t *input_buf, uint32_t input_buf_len) {
|
||||
|
||||
(void)guest_base; /* unused */
|
||||
memcpy((void *)regs->x0, input_buf, input_buf_len);
|
||||
regs->x1 = input_buf_len;
|
||||
}
|
||||
|
||||
#else
|
||||
#pragma error "Unsupported architecture"
|
||||
#endif
|
||||
|
||||
int afl_persistent_hook_init(void) {
|
||||
|
||||
// 1 for shared memory input (faster), 0 for normal input (you have to use
|
||||
// read(), input_buf will be NULL)
|
||||
return 1;
|
||||
|
||||
}
|
||||
@ -1,14 +0,0 @@
|
||||
#ifndef _ASAN_H
|
||||
#define _ASAN_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
extern gboolean asan_initialized;
|
||||
|
||||
void asan_config(void);
|
||||
void asan_init(void);
|
||||
void asan_arch_init(void);
|
||||
void asan_instrument(const cs_insn *instr, GumStalkerIterator *iterator);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,18 +0,0 @@
|
||||
#ifndef _CTX_H
|
||||
#define _CTX_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
#if defined(__x86_64__)
|
||||
gsize ctx_read_reg(GumX64CpuContext *ctx, x86_reg reg);
|
||||
#elif defined(__i386__)
|
||||
gsize ctx_read_reg(GumIA32CpuContext *ctx, x86_reg reg);
|
||||
#elif defined(__aarch64__)
|
||||
gsize ctx_read_reg(GumArm64CpuContext *ctx, arm64_reg reg);
|
||||
size_t ctx_get_size(const cs_insn *instr, cs_arm64_op *operand);
|
||||
#elif defined(__arm__)
|
||||
gsize ctx_read_reg(GumArmCpuContext *ctx, arm_reg reg);
|
||||
#endif
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,18 +0,0 @@
|
||||
#ifndef _ENTRY_H
|
||||
#define _ENTRY_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
extern guint64 entry_point;
|
||||
extern gboolean entry_reached;
|
||||
|
||||
void entry_config(void);
|
||||
|
||||
void entry_init(void);
|
||||
|
||||
void entry_start(void);
|
||||
|
||||
void entry_prologue(GumStalkerIterator *iterator, GumStalkerOutput *output);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,15 +0,0 @@
|
||||
#ifndef _CMPLOG_H
|
||||
#define _CMPLOG_H
|
||||
|
||||
extern struct cmp_map *__afl_cmp_map;
|
||||
|
||||
void cmplog_config(void);
|
||||
void cmplog_init(void);
|
||||
|
||||
/* Functions to be implemented by the different architectures */
|
||||
void cmplog_instrument(const cs_insn *instr, GumStalkerIterator *iterator);
|
||||
|
||||
gboolean cmplog_is_readable(guint64 addr, size_t size);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,46 +0,0 @@
|
||||
#ifndef _INSTRUMENT_H
|
||||
#define _INSTRUMENT_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
#include "config.h"
|
||||
|
||||
extern char * instrument_debug_filename;
|
||||
extern gboolean instrument_tracing;
|
||||
extern gboolean instrument_optimize;
|
||||
extern gboolean instrument_unique;
|
||||
extern __thread guint64 instrument_previous_pc;
|
||||
extern guint64 instrument_hash_zero;
|
||||
|
||||
extern gboolean instrument_use_fixed_seed;
|
||||
extern guint64 instrument_fixed_seed;
|
||||
|
||||
extern uint8_t *__afl_area_ptr;
|
||||
extern uint32_t __afl_map_size;
|
||||
|
||||
void instrument_config(void);
|
||||
|
||||
void instrument_init(void);
|
||||
|
||||
GumStalkerTransformer *instrument_get_transformer(void);
|
||||
|
||||
/* Functions to be implemented by the different architectures */
|
||||
gboolean instrument_is_coverage_optimize_supported(void);
|
||||
|
||||
void instrument_coverage_optimize(const cs_insn * instr,
|
||||
GumStalkerOutput *output);
|
||||
|
||||
void instrument_debug_config(void);
|
||||
void instrument_debug_init(void);
|
||||
void instrument_debug_start(uint64_t address, GumStalkerOutput *output);
|
||||
void instrument_debug_instruction(uint64_t address, uint16_t size);
|
||||
void instrument_debug_end(GumStalkerOutput *output);
|
||||
void instrument_flush(GumStalkerOutput *output);
|
||||
gpointer instrument_cur(GumStalkerOutput *output);
|
||||
|
||||
void instrument_on_fork();
|
||||
|
||||
guint64 instrument_get_offset_hash(GumAddress current_rip);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,11 +0,0 @@
|
||||
#ifndef _INTERCEPTOR_H
|
||||
#define _INTERCEPTOR_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
void intercept_hook(void *address, gpointer replacement, gpointer user_data);
|
||||
void intercept_unhook(void *address);
|
||||
void intercept_unhook_self(void);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,26 +0,0 @@
|
||||
#ifndef _JS_H
|
||||
#define _JS_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
typedef gboolean (*js_api_stalker_callback_t)(const cs_insn *insn,
|
||||
gboolean begin, gboolean excluded,
|
||||
GumStalkerOutput *output);
|
||||
|
||||
extern unsigned char api_js[];
|
||||
extern unsigned int api_js_len;
|
||||
|
||||
extern gboolean js_done;
|
||||
extern js_api_stalker_callback_t js_user_callback;
|
||||
|
||||
/* Frida Mode */
|
||||
|
||||
void js_config(void);
|
||||
|
||||
void js_start(void);
|
||||
|
||||
gboolean js_stalker_callback(const cs_insn *insn, gboolean begin,
|
||||
gboolean excluded, GumStalkerOutput *output);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,15 +0,0 @@
|
||||
#ifndef _LIB_H
|
||||
#define _LIB_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
void lib_config(void);
|
||||
|
||||
void lib_init(void);
|
||||
|
||||
guint64 lib_get_text_base(void);
|
||||
|
||||
guint64 lib_get_text_limit(void);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,13 +0,0 @@
|
||||
#ifndef _OUTPUT_H
|
||||
#define _OUTPUT_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
extern char *output_stdout;
|
||||
extern char *output_stderr;
|
||||
|
||||
void output_config(void);
|
||||
void output_init(void);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,39 +0,0 @@
|
||||
|
||||
#ifndef _PERSISTENT_H
|
||||
#define _PERSISTENT_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
#include "config.h"
|
||||
|
||||
typedef struct arch_api_regs api_regs;
|
||||
|
||||
typedef void (*afl_persistent_hook_fn)(api_regs *regs, uint64_t guest_base,
|
||||
uint8_t *input_buf,
|
||||
uint32_t input_buf_len);
|
||||
|
||||
extern int __afl_persistent_loop(unsigned int max_cnt);
|
||||
|
||||
extern unsigned int * __afl_fuzz_len;
|
||||
extern unsigned char *__afl_fuzz_ptr;
|
||||
|
||||
extern guint64 persistent_start;
|
||||
extern guint64 persistent_count;
|
||||
extern guint64 persistent_ret;
|
||||
extern gboolean persistent_debug;
|
||||
extern afl_persistent_hook_fn persistent_hook;
|
||||
|
||||
void persistent_config(void);
|
||||
|
||||
void persistent_init(void);
|
||||
|
||||
/* Functions to be implemented by the different architectures */
|
||||
gboolean persistent_is_supported(void);
|
||||
|
||||
void persistent_prologue(GumStalkerOutput *output);
|
||||
void persistent_prologue_arch(GumStalkerOutput *output);
|
||||
|
||||
void persistent_epilogue(GumStalkerOutput *output);
|
||||
void persistent_epilogue_arch(GumStalkerOutput *output);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,14 +0,0 @@
|
||||
#ifndef _PREFETCH_H
|
||||
#define _PREFETCH_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
extern gboolean prefetch_enable;
|
||||
|
||||
void prefetch_config(void);
|
||||
void prefetch_init(void);
|
||||
void prefetch_write(void *addr);
|
||||
void prefetch_read(void);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,21 +0,0 @@
|
||||
#ifndef _RANGES_H
|
||||
#define _RANGES_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
extern gboolean ranges_debug_maps;
|
||||
extern gboolean ranges_inst_libs;
|
||||
extern gboolean ranges_inst_jit;
|
||||
|
||||
void ranges_config(void);
|
||||
void ranges_init(void);
|
||||
|
||||
gboolean range_is_excluded(gpointer address);
|
||||
|
||||
void ranges_exclude();
|
||||
|
||||
void ranges_add_include(GumMemoryRange *range);
|
||||
void ranges_add_exclude(GumMemoryRange *range);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,13 +0,0 @@
|
||||
#ifndef _STALKER_H
|
||||
#define _STALKER_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
void stalker_config(void);
|
||||
void stalker_init(void);
|
||||
GumStalker *stalker_get(void);
|
||||
void stalker_start(void);
|
||||
void stalker_trust(void);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,34 +0,0 @@
|
||||
#ifndef _STATS_H
|
||||
#define _STATS_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
typedef struct {
|
||||
|
||||
guint64 num_blocks;
|
||||
guint64 num_instructions;
|
||||
guint64 stats_last_time;
|
||||
guint64 stats_idx;
|
||||
guint64 transitions_idx;
|
||||
|
||||
} stats_data_header_t;
|
||||
|
||||
extern stats_data_header_t *stats_data;
|
||||
|
||||
extern char * stats_filename;
|
||||
extern guint64 stats_interval;
|
||||
extern gboolean stats_transitions;
|
||||
|
||||
void stats_config(void);
|
||||
void stats_init(void);
|
||||
void stats_collect(const cs_insn *instr, gboolean begin);
|
||||
void stats_print(char *format, ...);
|
||||
|
||||
gboolean stats_is_supported_arch(void);
|
||||
size_t stats_data_size_arch(void);
|
||||
void stats_collect_arch(const cs_insn *instr);
|
||||
void stats_write_arch(void);
|
||||
void stats_on_fork(void);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,14 +0,0 @@
|
||||
#ifndef _UTIL_H
|
||||
#define _UTIL_H
|
||||
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
#define UNUSED_PARAMETER(x) (void)(x)
|
||||
#define IGNORED_RETURN(x) (void)!(x)
|
||||
|
||||
guint64 util_read_address(char *key);
|
||||
|
||||
guint64 util_read_num(char *key);
|
||||
|
||||
#endif
|
||||
|
||||
@ -1,24 +0,0 @@
|
||||
FROM fridadotre/manylinux-x86_64
|
||||
|
||||
COPY realpath /bin/realpath
|
||||
RUN chmod +x /bin/realpath
|
||||
|
||||
RUN yum -y install xz
|
||||
RUN yum -y install vim-common
|
||||
|
||||
WORKDIR /
|
||||
RUN git clone https://github.com/AFLplusplus/AFLplusplus.git
|
||||
|
||||
WORKDIR /AFLplusplus
|
||||
RUN mkdir -p /AFLplusplus/frida_mode/build/frida/
|
||||
RUN curl -L -o /AFLplusplus/frida_mode/build/frida/frida-gumjs-devkit-15.0.0-linux-x86_64.tar.xz "https://github.com/frida/frida/releases/download/15.0.0/frida-gumjs-devkit-15.0.0-linux-x86_64.tar.xz"
|
||||
|
||||
WORKDIR /AFLplusplus
|
||||
RUN git checkout dev
|
||||
WORKDIR /AFLplusplus/frida_mode
|
||||
ENV CFLAGS="\
|
||||
-DADDR_NO_RANDOMIZE=0x0040000 \
|
||||
-Wno-implicit-function-declaration \
|
||||
"
|
||||
ENV CXX=$CC
|
||||
RUN make
|
||||
@ -1,21 +0,0 @@
|
||||
PWD:=$(shell pwd)/
|
||||
BUILD_DIR:=$(PWD)build/
|
||||
|
||||
.PHONY: all clean shell
|
||||
|
||||
all: | $(BUILD_DIR)
|
||||
docker build --tag many-afl-frida .
|
||||
docker run --rm \
|
||||
-v $(PWD)build/:/export \
|
||||
many-afl-frida \
|
||||
cp /AFLplusplus/afl-frida-trace.so /export
|
||||
|
||||
$(BUILD_DIR):
|
||||
mkdir -p $@
|
||||
|
||||
clean:
|
||||
rm -rf $(BUILD_DIR)
|
||||
docker images --filter 'dangling=true' -q --no-trunc | xargs -L1 docker rmi --force
|
||||
|
||||
shell:
|
||||
docker run -ti --rm many-afl-frida /bin/bash
|
||||
@ -1,9 +0,0 @@
|
||||
all:
|
||||
@echo trying to use GNU make...
|
||||
@gmake all || echo please install GNUmake
|
||||
|
||||
clean:
|
||||
@gmake clean
|
||||
|
||||
shell:
|
||||
@gmake shell
|
||||
@ -1,8 +0,0 @@
|
||||
# many-linux
|
||||
|
||||
This folder contains a Docker image to allow the building of
|
||||
`afl-frida-trace.so` using the `many-linux` docker image. This docker image is
|
||||
based on CentOS Linux 5. By building `afl-frida-trace.so` for such an old
|
||||
version of Linux, given the strong backward compatibility of Linux, this should
|
||||
work on the majority of Linux environments. This may be useful for targetting
|
||||
Linux distributions other than your development environment.
|
||||
@ -1,2 +0,0 @@
|
||||
#!/bin/sh
|
||||
readlink -f -- "$@"
|
||||
@ -1,35 +0,0 @@
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
#include "debug.h"
|
||||
|
||||
#include "asan.h"
|
||||
|
||||
static gboolean asan_enabled = FALSE;
|
||||
gboolean asan_initialized = FALSE;
|
||||
|
||||
void asan_config(void) {
|
||||
|
||||
if (getenv("AFL_USE_FASAN") != NULL) {
|
||||
|
||||
OKF("Frida ASAN mode enabled");
|
||||
asan_enabled = TRUE;
|
||||
|
||||
} else {
|
||||
|
||||
OKF("Frida ASAN mode disabled");
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void asan_init(void) {
|
||||
|
||||
if (asan_enabled) {
|
||||
|
||||
asan_arch_init();
|
||||
asan_initialized = TRUE;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@ -1,28 +0,0 @@
|
||||
#include "frida-gumjs.h"
|
||||
|
||||
#include "debug.h"
|
||||
|
||||
#include "asan.h"
|
||||
#include "util.h"
|
||||
|
||||
#if defined(__arm__)
|
||||
void asan_instrument(const cs_insn *instr, GumStalkerIterator *iterator) {
|
||||
|
||||
UNUSED_PARAMETER(instr);
|
||||
UNUSED_PARAMETER(iterator);
|
||||
if (asan_initialized) {
|
||||
|
||||
FATAL("ASAN mode not supported on this architecture");
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void asan_arch_init(void) {
|
||||
|
||||
FATAL("ASAN mode not supported on this architecture");
|
||||
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user