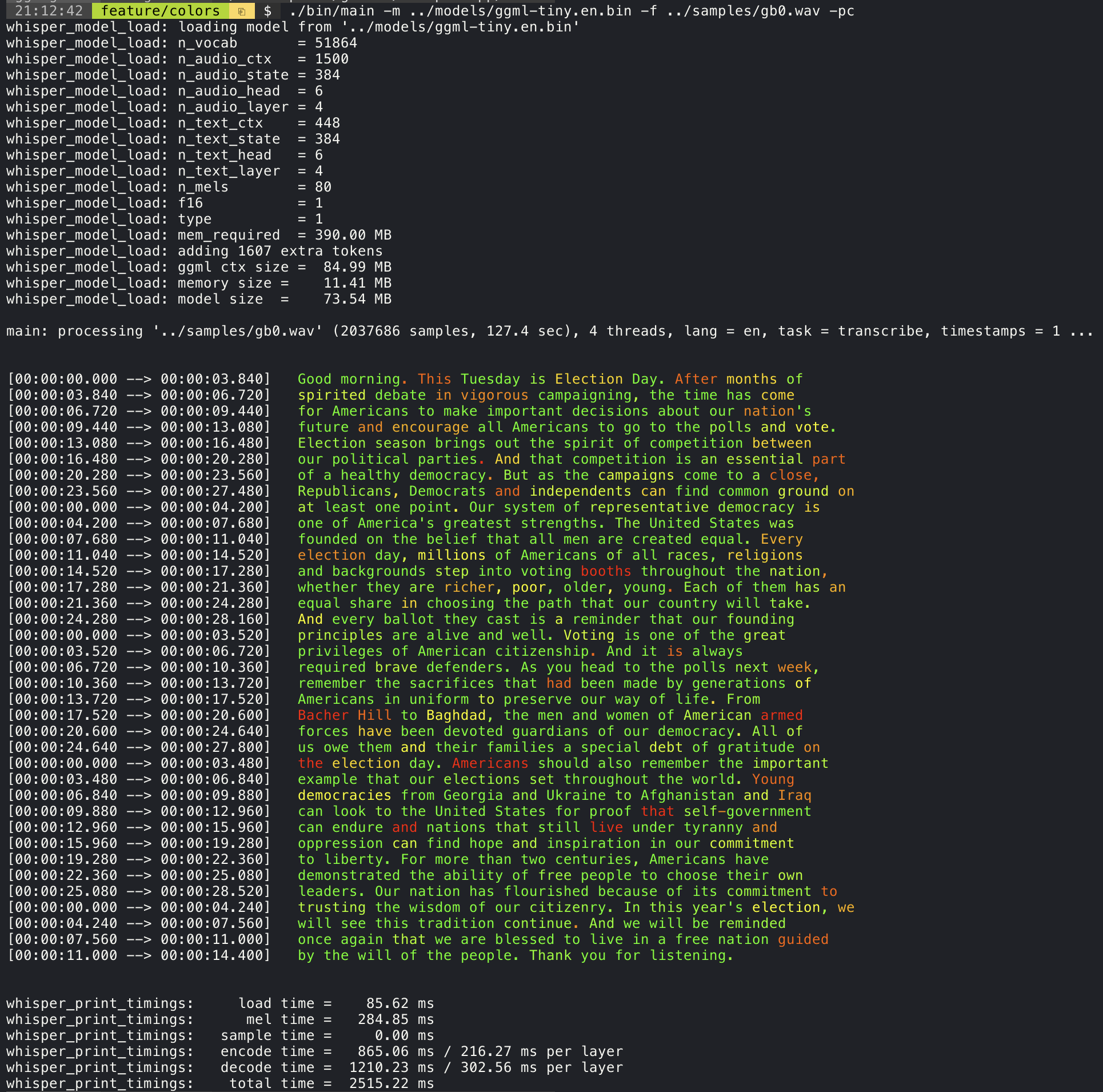
 @@ -640,7 +404,7 @@ to highlight words with high or low confidence:
For example, to limit the line length to a maximum of 16 characters, simply add `-ml 16`:
```text
-$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
+$ ./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
@@ -664,7 +428,7 @@ main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 pr
The `--max-len` argument can be used to obtain word-level timestamps. Simply use `-ml 1`:
```text
-$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
+$ ./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
@@ -711,7 +475,7 @@ Sample usage:
./models/download-ggml-model.sh small.en-tdrz
# run as usual, adding the "-tdrz" command-line argument
-./main -f ./samples/a13.wav -m ./models/ggml-small.en-tdrz.bin -tdrz
+./build/bin/whisper-cli -f ./samples/a13.wav -m ./models/ggml-small.en-tdrz.bin -tdrz
...
main: processing './samples/a13.wav' (480000 samples, 30.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, tdrz = 1, timestamps = 1 ...
...
@@ -728,14 +492,14 @@ main: processing './samples/a13.wav' (480000 samples, 30.0 sec), 4 threads, 1 pr
## Karaoke-style movie generation (experimental)
-The [main](examples/main) example provides support for output of karaoke-style movies, where the
+The [whisper-cli](examples/cli) example provides support for output of karaoke-style movies, where the
currently pronounced word is highlighted. Use the `-wts` argument and run the generated bash script.
This requires to have `ffmpeg` installed.
Here are a few _"typical"_ examples:
```bash
-./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
+./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4
```
@@ -745,7 +509,7 @@ https://user-images.githubusercontent.com/1991296/199337465-dbee4b5e-9aeb-48a3-b
---
```bash
-./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
+./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4
```
@@ -755,7 +519,7 @@ https://user-images.githubusercontent.com/1991296/199337504-cc8fd233-0cb7-4920-9
---
```bash
-./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
+./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4
```
@@ -780,7 +544,7 @@ https://user-images.githubusercontent.com/1991296/223206245-2d36d903-cf8e-4f09-8
## Benchmarks
In order to have an objective comparison of the performance of the inference across different system configurations,
-use the [bench](examples/bench) tool. The tool simply runs the Encoder part of the model and prints how much time it
+use the [whisper-bench](examples/bench) tool. The tool simply runs the Encoder part of the model and prints how much time it
took to execute it. The results are summarized in the following Github issue:
[Benchmark results](https://github.com/ggerganov/whisper.cpp/issues/89)
@@ -843,13 +607,12 @@ Some of the examples are even ported to run in the browser using WebAssembly. Ch
| Example | Web | Description |
| --------------------------------------------------- | ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------- |
-| [main](examples/main) | [whisper.wasm](examples/whisper.wasm) | Tool for translating and transcribing audio using Whisper |
-| [bench](examples/bench) | [bench.wasm](examples/bench.wasm) | Benchmark the performance of Whisper on your machine |
-| [stream](examples/stream) | [stream.wasm](examples/stream.wasm) | Real-time transcription of raw microphone capture |
-| [command](examples/command) | [command.wasm](examples/command.wasm) | Basic voice assistant example for receiving voice commands from the mic |
-| [wchess](examples/wchess) | [wchess.wasm](examples/wchess) | Voice-controlled chess |
-| [talk](examples/talk) | [talk.wasm](examples/talk.wasm) | Talk with a GPT-2 bot |
-| [talk-llama](examples/talk-llama) | | Talk with a LLaMA bot |
+| [whisper-cli](examples/cli) | [whisper.wasm](examples/whisper.wasm) | Tool for translating and transcribing audio using Whisper |
+| [whisper-bench](examples/bench) | [bench.wasm](examples/bench.wasm) | Benchmark the performance of Whisper on your machine |
+| [whisper-stream](examples/stream) | [stream.wasm](examples/stream.wasm) | Real-time transcription of raw microphone capture |
+| [whisper-command](examples/command) | [command.wasm](examples/command.wasm) | Basic voice assistant example for receiving voice commands from the mic |
+| [whisper-server](examples/server) | | HTTP transcription server with OAI-like API |
+| [whisper-talk-llama](examples/talk-llama) | | Talk with a LLaMA bot |
| [whisper.objc](examples/whisper.objc) | | iOS mobile application using whisper.cpp |
| [whisper.swiftui](examples/whisper.swiftui) | | SwiftUI iOS / macOS application using whisper.cpp |
| [whisper.android](examples/whisper.android) | | Android mobile application using whisper.cpp |
@@ -857,7 +620,7 @@ Some of the examples are even ported to run in the browser using WebAssembly. Ch
| [generate-karaoke.sh](examples/generate-karaoke.sh) | | Helper script to easily [generate a karaoke video](https://youtu.be/uj7hVta4blM) of raw audio capture |
| [livestream.sh](examples/livestream.sh) | | [Livestream audio transcription](https://github.com/ggerganov/whisper.cpp/issues/185) |
| [yt-wsp.sh](examples/yt-wsp.sh) | | Download + transcribe and/or translate any VOD [(original)](https://gist.github.com/DaniruKun/96f763ec1a037cc92fe1a059b643b818) |
-| [server](examples/server) | | HTTP transcription server with OAI-like API |
+| [wchess](examples/wchess) | [wchess.wasm](examples/wchess) | Voice-controlled chess |
## [Discussions](https://github.com/ggerganov/whisper.cpp/discussions)
diff --git a/examples/CMakeLists.txt b/examples/CMakeLists.txt
index addfa1d4..3e03c95e 100644
--- a/examples/CMakeLists.txt
+++ b/examples/CMakeLists.txt
@@ -97,52 +97,33 @@ include_directories(${CMAKE_CURRENT_SOURCE_DIR})
if (EMSCRIPTEN)
add_subdirectory(whisper.wasm)
- set_target_properties(libmain PROPERTIES FOLDER "libs")
add_subdirectory(stream.wasm)
- set_target_properties(libstream PROPERTIES FOLDER "libs")
add_subdirectory(command.wasm)
- set_target_properties(libcommand PROPERTIES FOLDER "libs")
- #add_subdirectory(talk.wasm)
- #set_target_properties(libtalk PROPERTIES FOLDER "libs")
add_subdirectory(bench.wasm)
- set_target_properties(libbench PROPERTIES FOLDER "libs")
elseif(CMAKE_JS_VERSION)
add_subdirectory(addon.node)
- set_target_properties(addon.node PROPERTIES FOLDER "examples")
else()
- add_subdirectory(main)
- set_target_properties(main PROPERTIES FOLDER "examples")
+ add_subdirectory(cli)
if (WHISPER_SDL2)
add_subdirectory(stream)
- set_target_properties(stream PROPERTIES FOLDER "examples")
endif (WHISPER_SDL2)
add_subdirectory(server)
- set_target_properties(server PROPERTIES FOLDER "examples")
if (WHISPER_SDL2)
add_subdirectory(command)
- set_target_properties(command PROPERTIES FOLDER "examples")
endif (WHISPER_SDL2)
add_subdirectory(bench)
- set_target_properties(bench PROPERTIES FOLDER "examples")
add_subdirectory(quantize)
- set_target_properties(quantize PROPERTIES FOLDER "examples")
if (WHISPER_SDL2)
- # TODO: disabled until update
- # https://github.com/ggerganov/whisper.cpp/issues/1818
- #add_subdirectory(talk)
- #set_target_properties(talk PROPERTIES FOLDER "examples")
add_subdirectory(talk-llama)
- set_target_properties(talk-llama PROPERTIES FOLDER "examples")
add_subdirectory(lsp)
- set_target_properties(lsp PROPERTIES FOLDER "examples")
if (GGML_SYCL)
add_subdirectory(sycl)
- set_target_properties(ls-sycl-device PROPERTIES FOLDER "examples")
endif()
endif (WHISPER_SDL2)
endif()
if (WHISPER_SDL2)
add_subdirectory(wchess)
- set_target_properties(wchess PROPERTIES FOLDER "examples")
endif (WHISPER_SDL2)
+
+add_subdirectory(deprecation-warning)
diff --git a/examples/bench/CMakeLists.txt b/examples/bench/CMakeLists.txt
index f8a72ffd..f255f2dc 100644
--- a/examples/bench/CMakeLists.txt
+++ b/examples/bench/CMakeLists.txt
@@ -1,6 +1,8 @@
-set(TARGET bench)
+set(TARGET whisper-bench)
add_executable(${TARGET} bench.cpp)
include(DefaultTargetOptions)
target_link_libraries(${TARGET} PRIVATE whisper ${CMAKE_THREAD_LIBS_INIT})
+
+install(TARGETS ${TARGET} RUNTIME)
diff --git a/examples/bench/README.md b/examples/bench/README.md
index 5b42cb4d..cf58665a 100644
--- a/examples/bench/README.md
+++ b/examples/bench/README.md
@@ -1,4 +1,4 @@
-# bench
+# whisper.cpp/examples/bench
A very basic tool for benchmarking the inference performance on your device. The tool simply runs the Encoder part of
the transformer on some random audio data and records the execution time. This way we can have an objective comparison
@@ -7,11 +7,8 @@ of the performance of the model for various setups.
Benchmark results are tracked in the following Github issue: https://github.com/ggerganov/whisper.cpp/issues/89
```bash
-# build the bench tool
-$ make bench
-
-# run it on the small.en model using 4 threads
-$ ./bench -m ./models/ggml-small.en.bin -t 4
+# run the bench too on the small.en model using 4 threads
+$ ./build/bin/whisper-bench -m ./models/ggml-small.en.bin -t 4
whisper_model_load: loading model from './models/ggml-small.en.bin'
whisper_model_load: n_vocab = 51864
diff --git a/examples/main/CMakeLists.txt b/examples/cli/CMakeLists.txt
similarity index 58%
rename from examples/main/CMakeLists.txt
rename to examples/cli/CMakeLists.txt
index 1e66e4b5..3a73776c 100644
--- a/examples/main/CMakeLists.txt
+++ b/examples/cli/CMakeLists.txt
@@ -1,6 +1,8 @@
-set(TARGET main)
-add_executable(${TARGET} main.cpp)
+set(TARGET whisper-cli)
+add_executable(${TARGET} cli.cpp)
include(DefaultTargetOptions)
target_link_libraries(${TARGET} PRIVATE common whisper ${FFMPEG_LIBRARIES} ${CMAKE_THREAD_LIBS_INIT})
+
+install(TARGETS ${TARGET} RUNTIME)
diff --git a/examples/main/README.md b/examples/cli/README.md
similarity index 75%
rename from examples/main/README.md
rename to examples/cli/README.md
index 2d868810..1847134e 100644
--- a/examples/main/README.md
+++ b/examples/cli/README.md
@@ -1,12 +1,12 @@
-# main
+# whisper.cpp/examples/cli
This is the main example demonstrating most of the functionality of the Whisper model.
It can be used as a reference for using the `whisper.cpp` library in other projects.
```
-./main -h
+./build/bin/whisper-cli -h
-usage: ./main [options] file0.wav file1.wav ...
+usage: ./build-pkg/bin/whisper-cli [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
@@ -20,9 +20,12 @@ options:
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
+ -ac N, --audio-ctx N [0 ] audio context size (0 - all)
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
+ -tp, --temperature N [0.00 ] The sampling temperature, between 0 and 1
+ -tpi, --temperature-inc N [0.20 ] The increment of temperature, between 0 and 1
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
@@ -38,16 +41,23 @@ options:
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
+ -np, --no-prints [false ] do not print anything other than the results
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
- --prompt PROMPT [ ] initial prompt
+ --prompt PROMPT [ ] initial prompt (max n_text_ctx/2 tokens)
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
+ -dtw MODEL --dtw MODEL [ ] compute token-level timestamps
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
+ -fa, --flash-attn [false ] flash attention
+ --suppress-regex REGEX [ ] regular expression matching tokens to suppress
+ --grammar GRAMMAR [ ] GBNF grammar to guide decoding
+ --grammar-rule RULE [ ] top-level GBNF grammar rule name
+ --grammar-penalty N [100.0 ] scales down logits of nongrammar tokens
```
diff --git a/examples/main/main.cpp b/examples/cli/cli.cpp
similarity index 100%
rename from examples/main/main.cpp
rename to examples/cli/cli.cpp
diff --git a/examples/command/CMakeLists.txt b/examples/command/CMakeLists.txt
index 40f278c1..c929a6f5 100644
--- a/examples/command/CMakeLists.txt
+++ b/examples/command/CMakeLists.txt
@@ -1,9 +1,10 @@
if (WHISPER_SDL2)
- # command
- set(TARGET command)
+ set(TARGET whisper-command)
add_executable(${TARGET} command.cpp)
include(DefaultTargetOptions)
target_link_libraries(${TARGET} PRIVATE common common-sdl whisper ${CMAKE_THREAD_LIBS_INIT})
+
+ install(TARGETS ${TARGET} RUNTIME)
endif ()
diff --git a/examples/command/README.md b/examples/command/README.md
index 46b14e93..7eb2bb60 100644
--- a/examples/command/README.md
+++ b/examples/command/README.md
@@ -1,14 +1,14 @@
-# command
+# whisper.cpp/examples/command
This is a basic Voice Assistant example that accepts voice commands from the microphone.
More info is available in [issue #171](https://github.com/ggerganov/whisper.cpp/issues/171).
```bash
# Run with default arguments and small model
-./command -m ./models/ggml-small.en.bin -t 8
+./whisper-command -m ./models/ggml-small.en.bin -t 8
# On Raspberry Pi, use tiny or base models + "-ac 768" for better performance
-./command -m ./models/ggml-tiny.en.bin -ac 768 -t 3 -c 0
+./whisper-command -m ./models/ggml-tiny.en.bin -ac 768 -t 3 -c 0
```
https://user-images.githubusercontent.com/1991296/204038393-2f846eae-c255-4099-a76d-5735c25c49da.mp4
@@ -23,10 +23,10 @@ Initial tests show that this approach might be extremely efficient in terms of p
```bash
# Run in guided mode, the list of allowed commands is in commands.txt
-./command -m ./models/ggml-base.en.bin -cmd ./examples/command/commands.txt
+./whisper-command -m ./models/ggml-base.en.bin -cmd ./examples/command/commands.txt
# On Raspberry Pi, in guided mode you can use "-ac 128" for extra performance
-./command -m ./models/ggml-tiny.en.bin -cmd ./examples/command/commands.txt -ac 128 -t 3 -c 0
+./whisper-command -m ./models/ggml-tiny.en.bin -cmd ./examples/command/commands.txt -ac 128 -t 3 -c 0
```
https://user-images.githubusercontent.com/1991296/207435352-8fc4ed3f-bde5-4555-9b8b-aeeb76bee969.mp4
@@ -34,7 +34,7 @@ https://user-images.githubusercontent.com/1991296/207435352-8fc4ed3f-bde5-4555-9
## Building
-The `command` tool depends on SDL2 library to capture audio from the microphone. You can build it like this:
+The `whisper-command` tool depends on SDL2 library to capture audio from the microphone. You can build it like this:
```bash
# Install SDL2
@@ -47,5 +47,6 @@ sudo dnf install SDL2 SDL2-devel
# Install SDL2 on Mac OS
brew install sdl2
-make command
+cmake -B build -DWHISPER_SDL2=ON
+cmake --build build --config Release
```
diff --git a/examples/deprecation-warning/CMakeLists.txt b/examples/deprecation-warning/CMakeLists.txt
new file mode 100644
index 00000000..f845e6cc
--- /dev/null
+++ b/examples/deprecation-warning/CMakeLists.txt
@@ -0,0 +1,4 @@
+add_executable(main ./deprecation-warning.cpp)
+add_executable(bench ./deprecation-warning.cpp)
+add_executable(stream ./deprecation-warning.cpp)
+add_executable(command ./deprecation-warning.cpp)
diff --git a/examples/deprecation-warning/README.md b/examples/deprecation-warning/README.md
new file mode 100644
index 00000000..e07e134b
--- /dev/null
+++ b/examples/deprecation-warning/README.md
@@ -0,0 +1,17 @@
+# Migration notice for binary filenames
+
+> [!IMPORTANT]
+[2024 Dec 20] Binaries have been renamed w/ a `whisper-` prefix. `main` is now `whisper-cli`, `server` is `whisper-server`, etc (https://github.com/ggerganov/whisper.cpp/pull/2648)
+
+This migration was important, but it is a breaking change that may not always be immediately obvious to users.
+
+Please update all scripts and workflows to use the new binary names.
+
+| Old Filename | New Filename |
+| ---- | ---- |
+| main | whisper-cli |
+| bench | whisper-bench |
+| stream | whisper-stream |
+| command | whisper-command |
+| server | whisper-server |
+| talk-llama | whisper-talk-llama |
diff --git a/examples/deprecation-warning/deprecation-warning.cpp b/examples/deprecation-warning/deprecation-warning.cpp
new file mode 100644
index 00000000..7247f0e0
--- /dev/null
+++ b/examples/deprecation-warning/deprecation-warning.cpp
@@ -0,0 +1,34 @@
+// Warns users that this filename was deprecated, and provides a link for more information.
+
+#include
@@ -640,7 +404,7 @@ to highlight words with high or low confidence:
For example, to limit the line length to a maximum of 16 characters, simply add `-ml 16`:
```text
-$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
+$ ./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
@@ -664,7 +428,7 @@ main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 pr
The `--max-len` argument can be used to obtain word-level timestamps. Simply use `-ml 1`:
```text
-$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
+$ ./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
@@ -711,7 +475,7 @@ Sample usage:
./models/download-ggml-model.sh small.en-tdrz
# run as usual, adding the "-tdrz" command-line argument
-./main -f ./samples/a13.wav -m ./models/ggml-small.en-tdrz.bin -tdrz
+./build/bin/whisper-cli -f ./samples/a13.wav -m ./models/ggml-small.en-tdrz.bin -tdrz
...
main: processing './samples/a13.wav' (480000 samples, 30.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, tdrz = 1, timestamps = 1 ...
...
@@ -728,14 +492,14 @@ main: processing './samples/a13.wav' (480000 samples, 30.0 sec), 4 threads, 1 pr
## Karaoke-style movie generation (experimental)
-The [main](examples/main) example provides support for output of karaoke-style movies, where the
+The [whisper-cli](examples/cli) example provides support for output of karaoke-style movies, where the
currently pronounced word is highlighted. Use the `-wts` argument and run the generated bash script.
This requires to have `ffmpeg` installed.
Here are a few _"typical"_ examples:
```bash
-./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
+./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4
```
@@ -745,7 +509,7 @@ https://user-images.githubusercontent.com/1991296/199337465-dbee4b5e-9aeb-48a3-b
---
```bash
-./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
+./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4
```
@@ -755,7 +519,7 @@ https://user-images.githubusercontent.com/1991296/199337504-cc8fd233-0cb7-4920-9
---
```bash
-./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
+./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4
```
@@ -780,7 +544,7 @@ https://user-images.githubusercontent.com/1991296/223206245-2d36d903-cf8e-4f09-8
## Benchmarks
In order to have an objective comparison of the performance of the inference across different system configurations,
-use the [bench](examples/bench) tool. The tool simply runs the Encoder part of the model and prints how much time it
+use the [whisper-bench](examples/bench) tool. The tool simply runs the Encoder part of the model and prints how much time it
took to execute it. The results are summarized in the following Github issue:
[Benchmark results](https://github.com/ggerganov/whisper.cpp/issues/89)
@@ -843,13 +607,12 @@ Some of the examples are even ported to run in the browser using WebAssembly. Ch
| Example | Web | Description |
| --------------------------------------------------- | ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------- |
-| [main](examples/main) | [whisper.wasm](examples/whisper.wasm) | Tool for translating and transcribing audio using Whisper |
-| [bench](examples/bench) | [bench.wasm](examples/bench.wasm) | Benchmark the performance of Whisper on your machine |
-| [stream](examples/stream) | [stream.wasm](examples/stream.wasm) | Real-time transcription of raw microphone capture |
-| [command](examples/command) | [command.wasm](examples/command.wasm) | Basic voice assistant example for receiving voice commands from the mic |
-| [wchess](examples/wchess) | [wchess.wasm](examples/wchess) | Voice-controlled chess |
-| [talk](examples/talk) | [talk.wasm](examples/talk.wasm) | Talk with a GPT-2 bot |
-| [talk-llama](examples/talk-llama) | | Talk with a LLaMA bot |
+| [whisper-cli](examples/cli) | [whisper.wasm](examples/whisper.wasm) | Tool for translating and transcribing audio using Whisper |
+| [whisper-bench](examples/bench) | [bench.wasm](examples/bench.wasm) | Benchmark the performance of Whisper on your machine |
+| [whisper-stream](examples/stream) | [stream.wasm](examples/stream.wasm) | Real-time transcription of raw microphone capture |
+| [whisper-command](examples/command) | [command.wasm](examples/command.wasm) | Basic voice assistant example for receiving voice commands from the mic |
+| [whisper-server](examples/server) | | HTTP transcription server with OAI-like API |
+| [whisper-talk-llama](examples/talk-llama) | | Talk with a LLaMA bot |
| [whisper.objc](examples/whisper.objc) | | iOS mobile application using whisper.cpp |
| [whisper.swiftui](examples/whisper.swiftui) | | SwiftUI iOS / macOS application using whisper.cpp |
| [whisper.android](examples/whisper.android) | | Android mobile application using whisper.cpp |
@@ -857,7 +620,7 @@ Some of the examples are even ported to run in the browser using WebAssembly. Ch
| [generate-karaoke.sh](examples/generate-karaoke.sh) | | Helper script to easily [generate a karaoke video](https://youtu.be/uj7hVta4blM) of raw audio capture |
| [livestream.sh](examples/livestream.sh) | | [Livestream audio transcription](https://github.com/ggerganov/whisper.cpp/issues/185) |
| [yt-wsp.sh](examples/yt-wsp.sh) | | Download + transcribe and/or translate any VOD [(original)](https://gist.github.com/DaniruKun/96f763ec1a037cc92fe1a059b643b818) |
-| [server](examples/server) | | HTTP transcription server with OAI-like API |
+| [wchess](examples/wchess) | [wchess.wasm](examples/wchess) | Voice-controlled chess |
## [Discussions](https://github.com/ggerganov/whisper.cpp/discussions)
diff --git a/examples/CMakeLists.txt b/examples/CMakeLists.txt
index addfa1d4..3e03c95e 100644
--- a/examples/CMakeLists.txt
+++ b/examples/CMakeLists.txt
@@ -97,52 +97,33 @@ include_directories(${CMAKE_CURRENT_SOURCE_DIR})
if (EMSCRIPTEN)
add_subdirectory(whisper.wasm)
- set_target_properties(libmain PROPERTIES FOLDER "libs")
add_subdirectory(stream.wasm)
- set_target_properties(libstream PROPERTIES FOLDER "libs")
add_subdirectory(command.wasm)
- set_target_properties(libcommand PROPERTIES FOLDER "libs")
- #add_subdirectory(talk.wasm)
- #set_target_properties(libtalk PROPERTIES FOLDER "libs")
add_subdirectory(bench.wasm)
- set_target_properties(libbench PROPERTIES FOLDER "libs")
elseif(CMAKE_JS_VERSION)
add_subdirectory(addon.node)
- set_target_properties(addon.node PROPERTIES FOLDER "examples")
else()
- add_subdirectory(main)
- set_target_properties(main PROPERTIES FOLDER "examples")
+ add_subdirectory(cli)
if (WHISPER_SDL2)
add_subdirectory(stream)
- set_target_properties(stream PROPERTIES FOLDER "examples")
endif (WHISPER_SDL2)
add_subdirectory(server)
- set_target_properties(server PROPERTIES FOLDER "examples")
if (WHISPER_SDL2)
add_subdirectory(command)
- set_target_properties(command PROPERTIES FOLDER "examples")
endif (WHISPER_SDL2)
add_subdirectory(bench)
- set_target_properties(bench PROPERTIES FOLDER "examples")
add_subdirectory(quantize)
- set_target_properties(quantize PROPERTIES FOLDER "examples")
if (WHISPER_SDL2)
- # TODO: disabled until update
- # https://github.com/ggerganov/whisper.cpp/issues/1818
- #add_subdirectory(talk)
- #set_target_properties(talk PROPERTIES FOLDER "examples")
add_subdirectory(talk-llama)
- set_target_properties(talk-llama PROPERTIES FOLDER "examples")
add_subdirectory(lsp)
- set_target_properties(lsp PROPERTIES FOLDER "examples")
if (GGML_SYCL)
add_subdirectory(sycl)
- set_target_properties(ls-sycl-device PROPERTIES FOLDER "examples")
endif()
endif (WHISPER_SDL2)
endif()
if (WHISPER_SDL2)
add_subdirectory(wchess)
- set_target_properties(wchess PROPERTIES FOLDER "examples")
endif (WHISPER_SDL2)
+
+add_subdirectory(deprecation-warning)
diff --git a/examples/bench/CMakeLists.txt b/examples/bench/CMakeLists.txt
index f8a72ffd..f255f2dc 100644
--- a/examples/bench/CMakeLists.txt
+++ b/examples/bench/CMakeLists.txt
@@ -1,6 +1,8 @@
-set(TARGET bench)
+set(TARGET whisper-bench)
add_executable(${TARGET} bench.cpp)
include(DefaultTargetOptions)
target_link_libraries(${TARGET} PRIVATE whisper ${CMAKE_THREAD_LIBS_INIT})
+
+install(TARGETS ${TARGET} RUNTIME)
diff --git a/examples/bench/README.md b/examples/bench/README.md
index 5b42cb4d..cf58665a 100644
--- a/examples/bench/README.md
+++ b/examples/bench/README.md
@@ -1,4 +1,4 @@
-# bench
+# whisper.cpp/examples/bench
A very basic tool for benchmarking the inference performance on your device. The tool simply runs the Encoder part of
the transformer on some random audio data and records the execution time. This way we can have an objective comparison
@@ -7,11 +7,8 @@ of the performance of the model for various setups.
Benchmark results are tracked in the following Github issue: https://github.com/ggerganov/whisper.cpp/issues/89
```bash
-# build the bench tool
-$ make bench
-
-# run it on the small.en model using 4 threads
-$ ./bench -m ./models/ggml-small.en.bin -t 4
+# run the bench too on the small.en model using 4 threads
+$ ./build/bin/whisper-bench -m ./models/ggml-small.en.bin -t 4
whisper_model_load: loading model from './models/ggml-small.en.bin'
whisper_model_load: n_vocab = 51864
diff --git a/examples/main/CMakeLists.txt b/examples/cli/CMakeLists.txt
similarity index 58%
rename from examples/main/CMakeLists.txt
rename to examples/cli/CMakeLists.txt
index 1e66e4b5..3a73776c 100644
--- a/examples/main/CMakeLists.txt
+++ b/examples/cli/CMakeLists.txt
@@ -1,6 +1,8 @@
-set(TARGET main)
-add_executable(${TARGET} main.cpp)
+set(TARGET whisper-cli)
+add_executable(${TARGET} cli.cpp)
include(DefaultTargetOptions)
target_link_libraries(${TARGET} PRIVATE common whisper ${FFMPEG_LIBRARIES} ${CMAKE_THREAD_LIBS_INIT})
+
+install(TARGETS ${TARGET} RUNTIME)
diff --git a/examples/main/README.md b/examples/cli/README.md
similarity index 75%
rename from examples/main/README.md
rename to examples/cli/README.md
index 2d868810..1847134e 100644
--- a/examples/main/README.md
+++ b/examples/cli/README.md
@@ -1,12 +1,12 @@
-# main
+# whisper.cpp/examples/cli
This is the main example demonstrating most of the functionality of the Whisper model.
It can be used as a reference for using the `whisper.cpp` library in other projects.
```
-./main -h
+./build/bin/whisper-cli -h
-usage: ./main [options] file0.wav file1.wav ...
+usage: ./build-pkg/bin/whisper-cli [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
@@ -20,9 +20,12 @@ options:
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
+ -ac N, --audio-ctx N [0 ] audio context size (0 - all)
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
+ -tp, --temperature N [0.00 ] The sampling temperature, between 0 and 1
+ -tpi, --temperature-inc N [0.20 ] The increment of temperature, between 0 and 1
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
@@ -38,16 +41,23 @@ options:
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
+ -np, --no-prints [false ] do not print anything other than the results
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
- --prompt PROMPT [ ] initial prompt
+ --prompt PROMPT [ ] initial prompt (max n_text_ctx/2 tokens)
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
+ -dtw MODEL --dtw MODEL [ ] compute token-level timestamps
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
+ -fa, --flash-attn [false ] flash attention
+ --suppress-regex REGEX [ ] regular expression matching tokens to suppress
+ --grammar GRAMMAR [ ] GBNF grammar to guide decoding
+ --grammar-rule RULE [ ] top-level GBNF grammar rule name
+ --grammar-penalty N [100.0 ] scales down logits of nongrammar tokens
```
diff --git a/examples/main/main.cpp b/examples/cli/cli.cpp
similarity index 100%
rename from examples/main/main.cpp
rename to examples/cli/cli.cpp
diff --git a/examples/command/CMakeLists.txt b/examples/command/CMakeLists.txt
index 40f278c1..c929a6f5 100644
--- a/examples/command/CMakeLists.txt
+++ b/examples/command/CMakeLists.txt
@@ -1,9 +1,10 @@
if (WHISPER_SDL2)
- # command
- set(TARGET command)
+ set(TARGET whisper-command)
add_executable(${TARGET} command.cpp)
include(DefaultTargetOptions)
target_link_libraries(${TARGET} PRIVATE common common-sdl whisper ${CMAKE_THREAD_LIBS_INIT})
+
+ install(TARGETS ${TARGET} RUNTIME)
endif ()
diff --git a/examples/command/README.md b/examples/command/README.md
index 46b14e93..7eb2bb60 100644
--- a/examples/command/README.md
+++ b/examples/command/README.md
@@ -1,14 +1,14 @@
-# command
+# whisper.cpp/examples/command
This is a basic Voice Assistant example that accepts voice commands from the microphone.
More info is available in [issue #171](https://github.com/ggerganov/whisper.cpp/issues/171).
```bash
# Run with default arguments and small model
-./command -m ./models/ggml-small.en.bin -t 8
+./whisper-command -m ./models/ggml-small.en.bin -t 8
# On Raspberry Pi, use tiny or base models + "-ac 768" for better performance
-./command -m ./models/ggml-tiny.en.bin -ac 768 -t 3 -c 0
+./whisper-command -m ./models/ggml-tiny.en.bin -ac 768 -t 3 -c 0
```
https://user-images.githubusercontent.com/1991296/204038393-2f846eae-c255-4099-a76d-5735c25c49da.mp4
@@ -23,10 +23,10 @@ Initial tests show that this approach might be extremely efficient in terms of p
```bash
# Run in guided mode, the list of allowed commands is in commands.txt
-./command -m ./models/ggml-base.en.bin -cmd ./examples/command/commands.txt
+./whisper-command -m ./models/ggml-base.en.bin -cmd ./examples/command/commands.txt
# On Raspberry Pi, in guided mode you can use "-ac 128" for extra performance
-./command -m ./models/ggml-tiny.en.bin -cmd ./examples/command/commands.txt -ac 128 -t 3 -c 0
+./whisper-command -m ./models/ggml-tiny.en.bin -cmd ./examples/command/commands.txt -ac 128 -t 3 -c 0
```
https://user-images.githubusercontent.com/1991296/207435352-8fc4ed3f-bde5-4555-9b8b-aeeb76bee969.mp4
@@ -34,7 +34,7 @@ https://user-images.githubusercontent.com/1991296/207435352-8fc4ed3f-bde5-4555-9
## Building
-The `command` tool depends on SDL2 library to capture audio from the microphone. You can build it like this:
+The `whisper-command` tool depends on SDL2 library to capture audio from the microphone. You can build it like this:
```bash
# Install SDL2
@@ -47,5 +47,6 @@ sudo dnf install SDL2 SDL2-devel
# Install SDL2 on Mac OS
brew install sdl2
-make command
+cmake -B build -DWHISPER_SDL2=ON
+cmake --build build --config Release
```
diff --git a/examples/deprecation-warning/CMakeLists.txt b/examples/deprecation-warning/CMakeLists.txt
new file mode 100644
index 00000000..f845e6cc
--- /dev/null
+++ b/examples/deprecation-warning/CMakeLists.txt
@@ -0,0 +1,4 @@
+add_executable(main ./deprecation-warning.cpp)
+add_executable(bench ./deprecation-warning.cpp)
+add_executable(stream ./deprecation-warning.cpp)
+add_executable(command ./deprecation-warning.cpp)
diff --git a/examples/deprecation-warning/README.md b/examples/deprecation-warning/README.md
new file mode 100644
index 00000000..e07e134b
--- /dev/null
+++ b/examples/deprecation-warning/README.md
@@ -0,0 +1,17 @@
+# Migration notice for binary filenames
+
+> [!IMPORTANT]
+[2024 Dec 20] Binaries have been renamed w/ a `whisper-` prefix. `main` is now `whisper-cli`, `server` is `whisper-server`, etc (https://github.com/ggerganov/whisper.cpp/pull/2648)
+
+This migration was important, but it is a breaking change that may not always be immediately obvious to users.
+
+Please update all scripts and workflows to use the new binary names.
+
+| Old Filename | New Filename |
+| ---- | ---- |
+| main | whisper-cli |
+| bench | whisper-bench |
+| stream | whisper-stream |
+| command | whisper-command |
+| server | whisper-server |
+| talk-llama | whisper-talk-llama |
diff --git a/examples/deprecation-warning/deprecation-warning.cpp b/examples/deprecation-warning/deprecation-warning.cpp
new file mode 100644
index 00000000..7247f0e0
--- /dev/null
+++ b/examples/deprecation-warning/deprecation-warning.cpp
@@ -0,0 +1,34 @@
+// Warns users that this filename was deprecated, and provides a link for more information.
+
+#include