Merge branch 'main' of https://github.com/ParisNeo/lollms-webui into dev
2
.github/workflows/docker.yaml
vendored
@ -18,7 +18,7 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
context: .
|
context: .
|
||||||
push: false
|
push: false
|
||||||
tags: gpt4all-ui:latest
|
tags: lollms-webui:latest
|
||||||
|
|
||||||
lint:
|
lint:
|
||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
|
|||||||
40
.github/workflows/rsync.yml
vendored
Normal file
@ -0,0 +1,40 @@
|
|||||||
|
name: Upstream Sync
|
||||||
|
|
||||||
|
permissions:
|
||||||
|
contents: write
|
||||||
|
|
||||||
|
on:
|
||||||
|
schedule:
|
||||||
|
- cron: "0 0 * * *" # every day
|
||||||
|
workflow_dispatch:
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
sync_latest_from_upstream:
|
||||||
|
name: Sync latest commits from upstream repo
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
if: ${{ github.event.repository.fork }}
|
||||||
|
|
||||||
|
steps:
|
||||||
|
# Step 1: run a standard checkout action
|
||||||
|
- name: Checkout target repo
|
||||||
|
uses: actions/checkout@v3
|
||||||
|
|
||||||
|
# Step 2: run the sync action
|
||||||
|
- name: Sync upstream changes
|
||||||
|
id: sync
|
||||||
|
uses: aormsby/Fork-Sync-With-Upstream-action@v3.4
|
||||||
|
with:
|
||||||
|
upstream_sync_repo: ParisNeo/lollms-webui
|
||||||
|
upstream_sync_branch: main
|
||||||
|
target_sync_branch: main
|
||||||
|
target_repo_token: ${{ secrets.GITHUB_TOKEN }} # automatically generated, no need to set
|
||||||
|
|
||||||
|
# Set test_mode true to run tests instead of the true action!!
|
||||||
|
test_mode: false
|
||||||
|
|
||||||
|
- name: Sync check
|
||||||
|
if: failure()
|
||||||
|
run: |
|
||||||
|
echo "::error::Synchronization failed due to insufficient permissions (this is the expected behavior), please go to the warehouse homepage to execute manually[Sync fork]。"
|
||||||
|
echo "::error::Due to insufficient permissions, synchronization failed (as expected). Please go to the repository homepage and manually perform [Sync fork]."
|
||||||
|
exit 1
|
||||||
43
.gitignore
vendored
@ -11,6 +11,7 @@ __pycache__/
|
|||||||
build/
|
build/
|
||||||
develop-eggs/
|
develop-eggs/
|
||||||
dist/
|
dist/
|
||||||
|
!web/dist
|
||||||
downloads/
|
downloads/
|
||||||
eggs/
|
eggs/
|
||||||
.eggs/
|
.eggs/
|
||||||
@ -103,6 +104,7 @@ celerybeat.pid
|
|||||||
|
|
||||||
# Environments
|
# Environments
|
||||||
.env
|
.env
|
||||||
|
!web/.env
|
||||||
.venv
|
.venv
|
||||||
env/
|
env/
|
||||||
venv/
|
venv/
|
||||||
@ -142,14 +144,14 @@ dmypy.json
|
|||||||
|
|
||||||
# Temporary files
|
# Temporary files
|
||||||
tmp/
|
tmp/
|
||||||
|
temp/
|
||||||
# configurations other than the default one
|
# configurations other than the default one
|
||||||
configs/*
|
configs/*
|
||||||
!configs/default.yaml
|
!configs/config.yaml
|
||||||
|
|
||||||
# personalities other than the default one
|
# personalities other than the default one
|
||||||
personalities/*
|
personalities/*
|
||||||
!personalities/english/general/gpt4all_chatbot.yaml
|
!personalities/english/default/*
|
||||||
|
|
||||||
# personalities other than the default one
|
# personalities other than the default one
|
||||||
databases/*
|
databases/*
|
||||||
@ -158,3 +160,38 @@ databases/*
|
|||||||
# extensions
|
# extensions
|
||||||
extensions/
|
extensions/
|
||||||
!extensions/.keep
|
!extensions/.keep
|
||||||
|
|
||||||
|
web/.env.build
|
||||||
|
web/.env.dev
|
||||||
|
web/.env.development
|
||||||
|
node_modules/
|
||||||
|
|
||||||
|
# Google chrome files
|
||||||
|
*.crdownload
|
||||||
|
|
||||||
|
# outputs folder
|
||||||
|
outputs
|
||||||
|
# junk stuff
|
||||||
|
./src
|
||||||
|
|
||||||
|
# ignore installation files
|
||||||
|
.installed
|
||||||
|
|
||||||
|
test.http
|
||||||
|
|
||||||
|
shared/*
|
||||||
|
!shared/.keep
|
||||||
|
|
||||||
|
|
||||||
|
uploads
|
||||||
|
global_paths_cfg.yaml
|
||||||
|
|
||||||
|
.vscode
|
||||||
|
|
||||||
|
# Endpoint test files using REST client (VSCODE Extension)
|
||||||
|
|
||||||
|
tests/end_point_tests/*_local.http
|
||||||
|
|
||||||
|
personalities_zoo
|
||||||
|
bindings_zoo
|
||||||
|
user_data
|
||||||
@ -1,4 +1,4 @@
|
|||||||
# Contributing to GPT4All-ui
|
# Contributing to lollms-webui
|
||||||
|
|
||||||
Thank you for your interest in contributing to [Your Repository Name]! We appreciate your efforts to help make our project better.
|
Thank you for your interest in contributing to [Your Repository Name]! We appreciate your efforts to help make our project better.
|
||||||
|
|
||||||
@ -30,4 +30,4 @@ To submit a contribution, please follow these steps:
|
|||||||
|
|
||||||
Once your pull request is approved, your changes will be merged into the main repository.
|
Once your pull request is approved, your changes will be merged into the main repository.
|
||||||
|
|
||||||
Thank you for your contributions to GPT4All-ui!
|
Thank you for your contributions to lollms-webui!
|
||||||
|
|||||||
@ -7,10 +7,10 @@ RUN python3 -m venv venv && . venv/bin/activate
|
|||||||
RUN python3 -m pip install --no-cache-dir -r requirements.txt --upgrade pip
|
RUN python3 -m pip install --no-cache-dir -r requirements.txt --upgrade pip
|
||||||
|
|
||||||
COPY ./app.py /srv/app.py
|
COPY ./app.py /srv/app.py
|
||||||
COPY ./pyGpt4All /srv/pyGpt4All
|
COPY ./api /srv/api
|
||||||
COPY ./backends /srv/backends
|
|
||||||
COPY ./static /srv/static
|
COPY ./static /srv/static
|
||||||
COPY ./templates /srv/templates
|
COPY ./templates /srv/templates
|
||||||
|
COPY ./web /srv/web
|
||||||
|
|
||||||
# COPY ./models /srv/models # Mounting model is more efficient
|
# COPY ./models /srv/models # Mounting model is more efficient
|
||||||
CMD ["python", "app.py", "--host", "0.0.0.0", "--port", "9600", "--db_path", "data/database.db"]
|
CMD ["python", "app.py", "--host", "0.0.0.0", "--port", "9600", "--db_path", "data/database.db"]
|
||||||
|
|||||||
298
README.md
@ -1,222 +1,140 @@
|
|||||||
# Gpt4All Web UI
|
# LoLLMS Web UI
|
||||||
|
|
||||||

|

|
||||||

|

|
||||||

|

|
||||||

|

|
||||||
[](https://discord.gg/4rR282WJb6)
|
[](https://discord.gg/4rR282WJb6)
|
||||||
|
[](https://twitter.com/SpaceNerduino)
|
||||||
|
[](https://www.youtube.com/user/Parisneo)
|
||||||
|
[](https://github.com/ParisNeo/lollms-webui/actions/workflows/pages/pages-build-deployment)
|
||||||
|
|
||||||
This is a Flask web application that provides a chat UI for interacting with [llamacpp](https://github.com/ggerganov/llama.cpp), gpt-j, gpt-q as well as Hugging face based language models uch as [GPT4all](https://github.com/nomic-ai/gpt4all), vicuna etc...
|
|
||||||
|
|
||||||
Follow us on our [Discord Server](https://discord.gg/4rR282WJb6).
|
Welcome to LoLLMS WebUI (Lord of Large Language Models: One tool to rule them all), the hub for LLM (Large Language Model) models. This project aims to provide a user-friendly interface to access and utilize various LLM models for a wide range of tasks. Whether you need help with writing, coding, organizing data, generating images, or seeking answers to your questions, LoLLMS WebUI has got you covered.
|
||||||
|
|
||||||
Watch Install Video (Outdated, please use "New UI video") [Old Install Video](https://youtu.be/6kKv6ESnwMk)
|
[Click here for my youtube video on how to use the tool](https://youtu.be/ds_U0TDzbzI)
|
||||||
|
## Features
|
||||||
|
|
||||||
Watch Usage Videos [Usage Video](https://youtu.be/DCBefhJUUh4)
|
- Choose your preferred binding, model, and personality for your tasks
|
||||||
|
- Enhance your emails, essays, code debugging, thought organization, and more
|
||||||
|
- Explore a wide range of functionalities, such as searching, data organization, and image generation
|
||||||
|
- Easy-to-use UI with light and dark mode options
|
||||||
|
- Integration with GitHub repository for easy access
|
||||||
|
- Support for different personalities with predefined welcome messages
|
||||||
|
- Thumb up/down rating for generated answers
|
||||||
|
- Copy, edit, and remove messages
|
||||||
|
- Local database storage for your discussions
|
||||||
|
- Search, export, and delete multiple discussions
|
||||||
|
- Support for Docker, conda, and manual virtual environment setups
|
||||||
|
|
||||||
Watch Settings Video [Settings Video](https://youtu.be/7KwR2vdt1t4)
|
## Installation
|
||||||
|
|
||||||
Watch New UI Video [New UI + Install](https://youtu.be/M7NFajCyZKs)
|
### Prerequisites
|
||||||
|
|
||||||
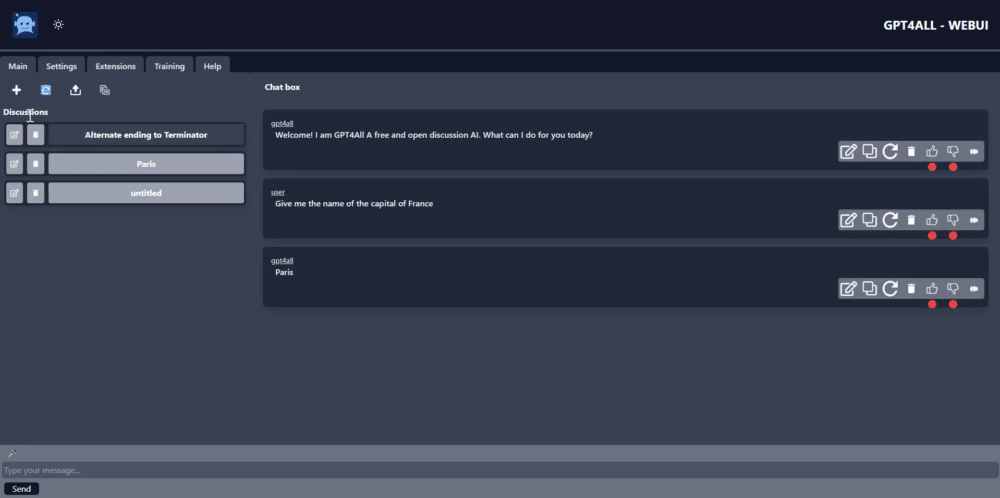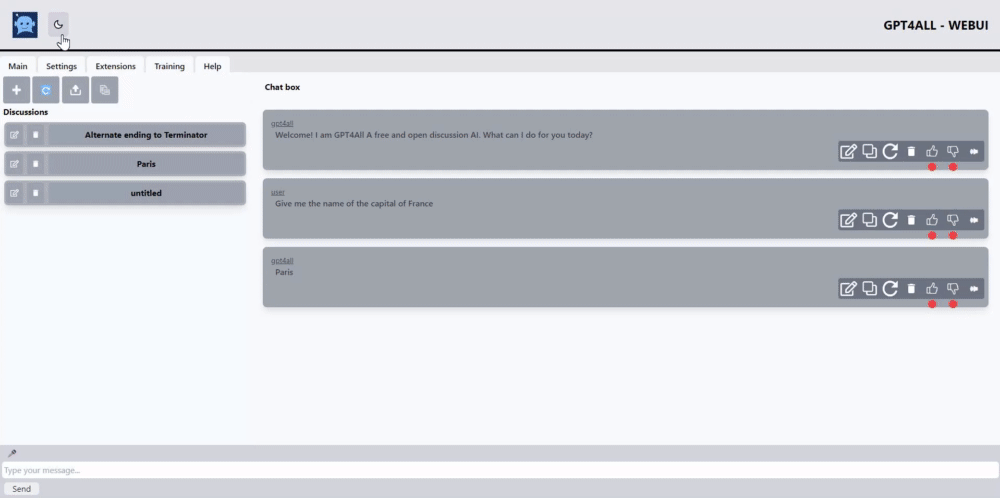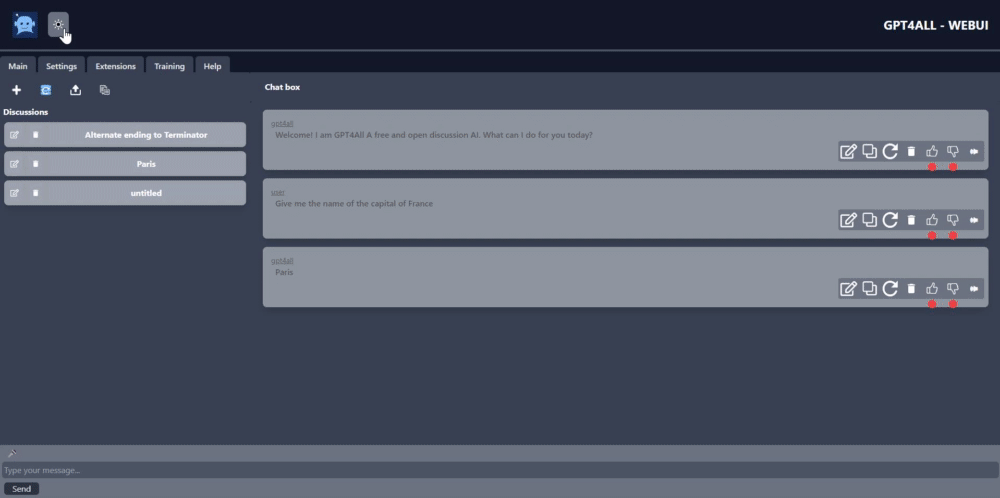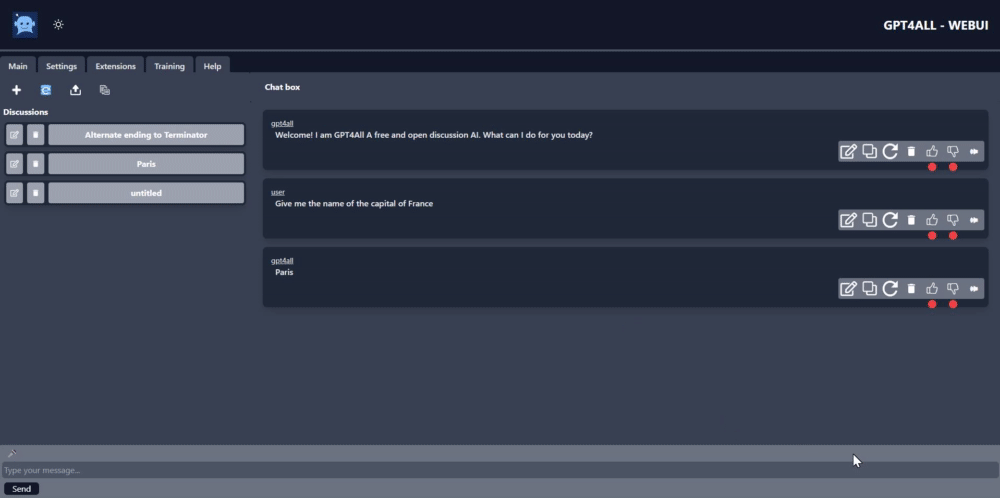
|
Before installing LoLLMS WebUI, make sure you have the following dependencies installed:
|
||||||
|
|
||||||
GPT4All is an exceptional language model, designed and developed by Nomic-AI, a proficient company dedicated to natural language processing. The app uses Nomic-AI's advanced library to communicate with the cutting-edge GPT4All model, which operates locally on the user's PC, ensuring seamless and efficient communication.
|
- [Python 3.10 or higher](https://www.python.org/downloads/release/python-3100/)
|
||||||
|
- Pip - installation depends on OS, but make sure you have it installed.
|
||||||
|
- [Git (for cloning the repository)](https://git-scm.com/downloads)
|
||||||
|
- [Visual Studio Community](https://visualstudio.microsoft.com/vs/community/) with c++ build tools (for CUDA [nvidia GPU's]) - optional for windows
|
||||||
|
- Build essentials (for CUDA [nvidia GPU's]) - optional for linux
|
||||||
|
- [Nvidia CUDA toolkit 11.7 or higher](https://developer.nvidia.com/cuda-downloads) (for CUDA [nvidia GPU's]) - optional
|
||||||
|
- [Miniconda3](https://docs.conda.io/en/latest/miniconda.html) - optional (more stable than python)
|
||||||
|
|
||||||
If you are interested in learning more about this groundbreaking project, visit their [Github Repository](https://github.com/nomic-ai/gpt4all), where you can find comprehensive information regarding the app's functionalities and technical details. Moreover, you can delve deeper into the training process and database by going through their detailed Technical report, available for download at [Technical report](https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf).
|
Ensure that the Python installation is in your system's PATH, and you can call it from the terminal. To verify your Python version, run the following command:
|
||||||
|
|
||||||
One of the app's impressive features is that it allows users to send messages to the chatbot and receive instantaneous responses in real time, ensuring a seamless user experience. Additionally, the app facilitates the exportation of the entire chat history in either text or JSON format, providing greater flexibility to the users.
|
Windows:
|
||||||
|
|
||||||
It's worth noting that the model has recently been launched, and it's expected to evolve across time, enabling it to become even better in the future. This web UI is designed to provide the community with easy and fully localized access to a chatbot that will continue to improve and adapt across time.
|
|
||||||
# Features
|
|
||||||
|
|
||||||
- Chat with locally hosted AI inside a web browser
|
|
||||||
- Create, edit, and share your AI's personality
|
|
||||||
- Audio in and audio out with many options for language and voices (only Chrome web browser is supported at this time)
|
|
||||||
- History of discussion with resume functionality
|
|
||||||
- Add new discussion, rename discussion, remove discussion
|
|
||||||
- Export database to json format
|
|
||||||
- Export discussion to text format
|
|
||||||
|
|
||||||
# Installation and running
|
|
||||||
|
|
||||||
Make sure that your CPU supports `AVX2` instruction set. Without it, this application won't run out of the box. To check your CPU features, please visit the website of your CPU manufacturer for more information and look for `Instruction set extension: AVX2`.
|
|
||||||
> **Note**
|
|
||||||
>
|
|
||||||
>Default model `gpt4all-lora-quantized-ggml.bin` is roughly 4GB in size.
|
|
||||||
|
|
||||||
## Windows 10 and 11
|
|
||||||
|
|
||||||
### Automatic install
|
|
||||||
|
|
||||||
It is advised to have python 3.10 (The official one, not the one from Microsoft Store) and git installed. Although it should work with any python from 3.7, it is advised to use 3.10 to have the full support as some extensions like the future stable diffusion extension will force you to have 3.10.
|
|
||||||
|
|
||||||
1. [Go to the latest release section](https://github.com/nomic-ai/gpt4all-ui/releases)
|
|
||||||
2. Download the `webui.bat` if you are on windows or `webui.sh` if you are on linux/mac. but the download in a folder you name for example gpt4all-ui
|
|
||||||
3. Run the script and wait. It should install everything and start the chatbot
|
|
||||||
4. Before running, it may ask you to download a model. Feel free to accept or to download your own models depending on the backends you are using.
|
|
||||||
|
|
||||||
Once installed, you should see a new folder called GPT4All. From now on, you can run the app by using webui.bat or webui.sh. The script will check for any new updates
|
|
||||||
|
|
||||||
[If you want to use a more advanced install procedure, please click here](docs/AdvancedInstallInstructions.md)
|
|
||||||
|
|
||||||
## Docker Compose
|
|
||||||
Make sure to put models the inside the `models` directory.
|
|
||||||
After that, you can simply use docker-compose or podman-compose to build and start the application:
|
|
||||||
|
|
||||||
Build
|
|
||||||
```bash
|
```bash
|
||||||
docker compose -f docker-compose.yml build
|
python --version
|
||||||
```
|
```
|
||||||
|
|
||||||
Start
|
Linux:
|
||||||
```bash
|
```bash
|
||||||
docker compose -f docker-compose.yml up
|
python3 --version
|
||||||
```
|
```
|
||||||
|
|
||||||
Stop ` Ctrl ` + ` C `
|
If you receive an error or the version is lower than 3.10, please install a newer version and try again.
|
||||||
|
|
||||||
|
### Installation steps
|
||||||
|
|
||||||
|
For detailed installation steps please refer to these documents:
|
||||||
|
|
||||||
|
- [Windows 10/11](./docs/usage/AdvancedInstallInstructions.md#windows-10-and-11)
|
||||||
|
- [Linux (tested on ubuntu)](./docs/usage/AdvancedInstallInstructions.md#linux)
|
||||||
|
#### Easy install
|
||||||
|
|
||||||
|
- Download the appropriate application launcher based on your platform:
|
||||||
|
For Windows: `webui.bat`
|
||||||
|
For Linux: `webui.sh`
|
||||||
|
For Linux: `c_webui.sh` - using miniconda3
|
||||||
|
- Place the downloaded launcher in a folder of your choice, for example:
|
||||||
|
Windows: `C:\ai\LoLLMS-webui`
|
||||||
|
Linux: `/home/user/ai/LoLLMS-webui`
|
||||||
|
- Run the launcher script. Note that you might encounter warnings from antivirus or Windows Defender due to the tool's newness and limited usage. These warnings are false positives caused by reputation conditions in some antivirus software. You can safely proceed with running the script.
|
||||||
|
Once the installation is complete, the LoLLMS WebUI will launch automatically.
|
||||||
|
|
||||||
|
#### Using Conda
|
||||||
|
If you use conda, you can create a virtual environment and install the required packages using the provided `requirements.txt` file. Here's an example of how to set it up:
|
||||||
|
First clone the project or download the zip file and unzip it:
|
||||||
|
|
||||||
Start detached (runs in background)
|
|
||||||
```bash
|
```bash
|
||||||
docker compose -f docker-compose.yml up -d
|
git clone https://github.com/ParisNeo/lollms-webui.git
|
||||||
|
cd lollms-webui
|
||||||
```
|
```
|
||||||
|
Now create a new conda environment, activate it and install requirements
|
||||||
|
|
||||||
Stop detached (one that runs in background)
|
|
||||||
```bash
|
```bash
|
||||||
docker compose stop
|
conda create --prefix ./env python=3.10
|
||||||
|
conda activate ./env
|
||||||
|
pip install -r requirements.txt
|
||||||
```
|
```
|
||||||
|
#### Using Docker
|
||||||
|
Alternatively, you can use Docker to set up the LoLLMS WebUI. Please refer to the Docker documentation for installation instructions specific to your operating system.
|
||||||
|
|
||||||
After that, you can open the application in your browser on http://localhost:9600
|
## Usage
|
||||||
|
|
||||||
Now you're ready to work!
|
You can launch the app from the webui.sh or webui.bat launcher. It will automatically perform updates if any are present. If you don't prefer this method, you can also activate the virtual environment and launch the application using python app.py from the root of the project.
|
||||||
|
Once the app is running, you can go to the application front link displayed in the console (by default localhost:9600 but can change if you change configuration)
|
||||||
|
### Selecting a Model and Binding
|
||||||
|
- Open the LoLLMS WebUI and navigate to the Settings page.
|
||||||
|
- In the Models Zoo tab, select a binding from the list (e.g., llama-cpp-official).
|
||||||
|
- Wait for the installation process to finish. You can monitor the progress in the console.
|
||||||
|
- Once the installation is complete, click the Install button next to the desired model.
|
||||||
|
- After the model installation finishes, select the model and press Apply changes.
|
||||||
|
- Remember to press the Save button to save the configuration.
|
||||||
|
|
||||||
# Supported backends
|
### Starting a Discussion
|
||||||
Two backends are now supported:
|
- Go to the Discussions view.
|
||||||
1 - [The llama_cpp backend](https://github.com/nomic-ai/pygpt4all)
|
- Click the + button to create a new discussion.
|
||||||
2 - [The GPT-j backend](https://github.com/marella/gpt4all-j)
|
- You will see a predefined welcome message based on the selected personality (by default, LoLLMS).
|
||||||
3 - Hugging face's Transformers (under construction)
|
- Ask a question or provide an initial prompt to start the discussion.
|
||||||
|
- You can stop the generation process at any time by pressing the Stop Generating button.
|
||||||
|
|
||||||
# Supported models
|
### Managing Discussions
|
||||||
You can also refuse to download the model during the install procedure and download it manually.
|
- To edit a discussion title, simply type a new title or modify the existing one.
|
||||||
|
- To delete a discussion, click the Delete button.
|
||||||
|
- To search for specific discussions, use the search button and enter relevant keywords.
|
||||||
|
- To perform batch operations (exporting or deleting multiple discussions), enable Check Mode, select the discussions, and choose the desired action.
|
||||||
|
|
||||||
**For now, we support ggml models that work "out-of-the-box" (tested on Windows 11 and Ubuntu 22.04.2), such as:**
|
# Contributing
|
||||||
|
Contributions to LoLLMS WebUI are welcome! If you encounter any issues, have ideas for improvements, or want to contribute code, please open an issue or submit a pull request on the GitHub repository.
|
||||||
## LLama_cpp models
|
|
||||||
- [GPT4ALL 7B](https://huggingface.co/ParisNeo/GPT4All/resolve/main/gpt4all-lora-quantized-ggml.bin) or visit [repository](https://huggingface.co/ParisNeo/GPT4All)
|
|
||||||
- [GPT4ALL 7B unfiltered](https://huggingface.co/ParisNeo/GPT4All/blob/main/gpt4all-lora-unfiltered-quantized.new.bin) or visit [repository](https://huggingface.co/ParisNeo/GPT4All)
|
|
||||||
- [Vicuna 7B rev 1](https://huggingface.co/eachadea/legacy-ggml-vicuna-7b-4bit/resolve/main/ggml-vicuna-7b-4bit-rev1.bin) or visit [repository](https://huggingface.co/eachadea/legacy-ggml-vicuna-7b-4bit)
|
|
||||||
- [Vicuna 13B rev 1](https://huggingface.co/eachadea/ggml-vicuna-13b-4bit/resolve/main/ggml-vicuna-13b-4bit-rev1.bin) or visit [repository](https://huggingface.co/eachadea/ggml-vicuna-13b-4bit)
|
|
||||||
|
|
||||||
We also support GPT-j models out of the box
|
|
||||||
|
|
||||||
## GPT-j models
|
|
||||||
- [GPT-j 7B](https://gpt4all.io/models/ggml-gpt4all-j.bin)
|
|
||||||
|
|
||||||
|
|
||||||
**These models don't work "out-of-the-box" and need to be converted to the right ggml type:**
|
|
||||||
## LLAMACPP models
|
|
||||||
- [Vicuna 7B](https://huggingface.co/eachadea/legacy-ggml-vicuna-7b-4bit/resolve/main/ggml-vicuna-7b-4bit.bin) or visit [repository](https://huggingface.co/eachadea/legacy-ggml-vicuna-7b-4bit)
|
|
||||||
- [Vicuna 13B q4 v0](https://huggingface.co/eachadea/ggml-vicuna-13b-1.1/resolve/main/ggml-vicuna-13b-1.1-q4_0.bin) or visit [repository](https://huggingface.co/eachadea/ggml-vicuna-13b-1.1/)
|
|
||||||
- [Vicuna 13B q4 v1](https://huggingface.co/eachadea/ggml-vicuna-13b-1.1/resolve/main/ggml-vicuna-13b-1.1-q4_1.bin) or visit [repository](https://huggingface.co/eachadea/ggml-vicuna-13b-1.1/)
|
|
||||||
- [ALPACA 7B](https://huggingface.co/Sosaka/Alpaca-native-4bit-ggml/resolve/main/ggml-alpaca-7b-q4.bin) or visit [repository](https://huggingface.co/Sosaka/Alpaca-native-4bit-ggml/)
|
|
||||||
|
|
||||||
Just download the model into the `models/<backend name>` folder and start using the tool.
|
|
||||||
|
|
||||||
# Build custom personalities and share them
|
|
||||||
|
|
||||||
To build a new personality, create a new file with the name of the personality inside the `personalities` folder. You can look at `gpt4all_chatbot.yaml` file as an example. Then you can fill the fields with the description, conditionning, etc. of your personality. Then save the file.
|
|
||||||
|
|
||||||
You can launch the application using the personality in two ways:
|
|
||||||
- Change it permanently by putting the name of the personality inside your configuration file
|
|
||||||
- Use the `--personality` or `-p` option to give the personality name to be used
|
|
||||||
|
|
||||||
If you deem your personality worthy of sharing, you can share the it by adding it to the [GPT4all personalities](https://github.com/ParisNeo/GPT4All_Personalities) repository. Just fork the repo, add your file, and do a pull request.
|
|
||||||
|
|
||||||
# Advanced Usage
|
|
||||||
|
|
||||||
If you want more control on your launch, you can activate your environment:
|
|
||||||
|
|
||||||
On Windows:
|
|
||||||
```cmd
|
|
||||||
env/Scripts/activate.bat
|
|
||||||
```
|
|
||||||
|
|
||||||
On Linux/MacOs:
|
|
||||||
```cmd
|
|
||||||
source venv/bin/activate
|
|
||||||
```
|
|
||||||
|
|
||||||
Now you are ready to customize your Bot.
|
|
||||||
|
|
||||||
To run the Flask server, execute the following command:
|
|
||||||
```bash
|
|
||||||
python app.py [--config CONFIG] [--personality PERSONALITY] [--port PORT] [--host HOST] [--temp TEMP] [--n_threads N_THREADS] [--n_predict N_PREDICT] [--top_k TOP_K] [--top_p TOP_P] [--repeat_penalty REPEAT_PENALTY] [--repeat_last_n REPEAT_LAST_N] [--ctx_size CTX_SIZE]
|
|
||||||
```
|
|
||||||
|
|
||||||
On Linux/MacOS more details can be found [here](docs/Linux_Osx_Usage.md)
|
|
||||||
|
|
||||||
## Options
|
|
||||||
* `--config`: the configuration file to be used. It contains default configurations. The script parameters will override the configurations inside the configuration file. It must be placed in configs folder (default: default.yaml)
|
|
||||||
* `--personality`: the personality file name. It contains the definition of the pezrsonality of the chatbot and should be placed in personalities folder. The default personality is `gpt4all_chatbot.yaml`
|
|
||||||
* `--model`: the name of the model to be used. The model should be placed in models folder (default: gpt4all-lora-quantized.bin)
|
|
||||||
* `--seed`: the random seed for reproductibility. If fixed, it is possible to reproduce the outputs exactly (default: random)
|
|
||||||
* `--port`: the port on which to run the server (default: 9600)
|
|
||||||
* `--host`: the host address at which to run the server (default: localhost). To expose application to local network, set this to 0.0.0.0.
|
|
||||||
* `--temp`: the sampling temperature for the model (default: 0.1)
|
|
||||||
* `--n_threads`: the number of threads to be used (default:8)
|
|
||||||
* `--n-predict`: the number of tokens to predict at a time (default: 128)
|
|
||||||
* `--top-k`: the number of top-k candidates to consider for sampling (default: 40)
|
|
||||||
* `--top-p`: the cumulative probability threshold for top-p sampling (default: 0.90)
|
|
||||||
* `--repeat-penalty`: the penalty to apply for repeated n-grams (default: 1.3)
|
|
||||||
* `--repeat-last-n`: the number of tokens to use for detecting repeated n-grams (default: 64)
|
|
||||||
* `--ctx-size`: the maximum context size to use for generating responses (default: 2048)
|
|
||||||
|
|
||||||
Note: All options are optional and have default values.
|
|
||||||
|
|
||||||
Once the server is running, open your web browser and navigate to http://localhost:9600 (or http://your host name:your port number if you have selected different values for those) to access the chatbot UI. To use the app, open a web browser and navigate to this URL.
|
|
||||||
|
|
||||||
Make sure to adjust the default values and descriptions of the options to match your specific application.
|
|
||||||
|
|
||||||
# Contribute
|
|
||||||
|
|
||||||
This is an open-source project by the community and for the community. Our chatbot is a UI wrapper for Nomic AI's model, which enables natural language processing and machine learning capabilities.
|
|
||||||
|
|
||||||
We welcome contributions from anyone who is interested in improving our chatbot. Whether you want to report a bug, suggest a feature, or submit a pull request, we encourage you to get involved and help us make our chatbot even better.
|
|
||||||
|
|
||||||
Before contributing, please take a moment to review our [code of conduct](./CODE_OF_CONDUCT.md). We expect all contributors to abide by this code of conduct, which outlines our expectations for respectful communication, collaborative development, and innovative contributions.
|
|
||||||
|
|
||||||
### Reporting Bugs
|
|
||||||
|
|
||||||
If you find a bug or other issue with our chatbot, please report it by [opening an issue](https://github.com/your-username/your-chatbot/issues/new). Be sure to provide as much detail as possible, including steps to reproduce the issue and any relevant error messages.
|
|
||||||
|
|
||||||
### Suggesting Features
|
|
||||||
|
|
||||||
If you have an idea for a new feature or improvement to our chatbot, we encourage you to [open an issue](https://github.com/your-username/your-chatbot/issues/new) to discuss it. We welcome feedback and ideas from the community and will consider all suggestions that align with our project goals.
|
|
||||||
|
|
||||||
### Contributing Code
|
|
||||||
|
|
||||||
If you want to contribute code to our chatbot, please follow these steps:
|
|
||||||
|
|
||||||
1. Fork the repository and create a new branch for your changes.
|
|
||||||
2. Make your changes and ensure that they follow our coding conventions.
|
|
||||||
3. Test your changes to ensure that they work as expected.
|
|
||||||
4. Submit a pull request with a clear description of your changes and the problem they solve.
|
|
||||||
|
|
||||||
We will review your pull request as soon as possible and provide feedback on any necessary changes. We appreciate your contributions and look forward to working with you!
|
|
||||||
|
|
||||||
Please note that all contributions are subject to review and approval by our project maintainers. We reserve the right to reject any contribution that does not align with our project goals or standards.
|
|
||||||
|
|
||||||
# Future Plans
|
|
||||||
|
|
||||||
Here are some of the future plans for this project:
|
|
||||||
|
|
||||||
**Enhanced control of chatbot parameters:** We plan to improve the UI of the chatbot to allow users to control the parameters of the chatbot such as temperature and other variables. This will give users more control over the chatbot's responses, and allow for a more customized experience.
|
|
||||||
|
|
||||||
**Extension system for plugins:** We are also working on an extension system that will allow developers to create plugins for the chatbot. These plugins will be able to add new features and capabilities to the chatbot, and allow for greater customization of the chatbot's behavior.
|
|
||||||
|
|
||||||
**Enhanced UI with themes and skins:** Additionally, we plan to enhance the UI of the chatbot to allow for themes and skins. This will allow users to personalize the appearance of the chatbot and make it more visually appealing.
|
|
||||||
|
|
||||||
We are excited about these future plans for the project and look forward to implementing them in the near future. Stay tuned for updates!
|
|
||||||
|
|
||||||
# License
|
# License
|
||||||
|
This project is licensed under the Apache 2.0 License. You are free to use this software commercially, build upon it, and integrate it into your own projects. See the [LICENSE](https://github.com/ParisNeo/lollms-webui/blob/main/LICENSE) file for details.
|
||||||
|
|
||||||
This project is licensed under the Apache 2.0 License. See the [LICENSE](https://github.com/nomic-ai/GPT4All-ui/blob/main/LICENSE) file for details.
|
# Acknowledgements
|
||||||
|
Please note that LoLLMS WebUI is not affiliated with the LoLLMS application developed by Nomic AI. The latter is a separate professional application available at LoLLMS.io, which has its own unique features and community.
|
||||||
|
|
||||||
|
We express our gratitude to all the contributors who have made this project possible and welcome additional contributions to further enhance the tool for the benefit of all users.
|
||||||
|
|
||||||
|
# Contact
|
||||||
|
|
||||||
|
For any questions or inquiries, feel free to reach out via our discord server: https://discord.gg/4rR282WJb6
|
||||||
|
|
||||||
|
Thank you for your interest and support!
|
||||||
|
|
||||||
|
If you find this tool useful, don't forget to give it a star on GitHub, share your experience, and help us spread the word. Your feedback and bug reports are valuable to us as we continue developing and improving LoLLMS WebUI.
|
||||||
|
|
||||||
|
If you enjoyed this tutorial, consider subscribing to our YouTube channel for more updates, tutorials, and exciting content.
|
||||||
|
|
||||||
|
Happy exploring with LoLLMS WebUI!
|
||||||
|
|||||||
BIN
ai_ethics/ParisNeo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 8.1 KiB |
22
ai_ethics/can_we_contain_ai.md
Normal file
@ -0,0 +1,22 @@
|
|||||||
|
# Can we contain AI by laws ?
|
||||||
|
|
||||||
|
Today, it is possible with a relatively modest hardware to train your own LLM model. With LoRA technique, fine tuning a model and giving it new skills is becoming a kid's game. Which means that regulation is not going to be able to stop AI from being missused. It would most likely favor the big companies who can afford to do model check (whatever that means) and instantly kill all small buisinesses that are based on open source models.
|
||||||
|
|
||||||
|
My problem with AI is power gained by few. And complete opacity about what's hapening under the hood.
|
||||||
|
Today, the truth is what google says: when someone doesn't know something, he asks google. But that is now shifting towards chatgpt. Tomorrow, the truth will be what Chatgpt says. With google, we still do the effort of searching and using our mind to weigh things. With chatgpt, we don't even get to choose. What it says is unique. Just like the ultimate source of knowledge. That's too much power in the hand of a single entity. And knowing that we can bias those models makes me fear what can hapen in the future.
|
||||||
|
|
||||||
|
Although I am not republican, I made a little experiment with chatgpt few months ago. I asked it to say something good about Donald Trump. It answered me that it doesn't do politics. I asked the same about Biden, and it created a very good essai. Now I am not saying Trump is good, but we can see a bias here. ChatGpt reflects the political view of its creators. That's not acceptable from a tool that can basically become a god in terms of knowledge source.
|
||||||
|
I don't think that AI should decide if I should vote Left ot right. I don't think that AI should tell me what's right and what is wrong. Many things in life depend on the point of view.
|
||||||
|
|
||||||
|
I don't beleive there is a way to have a 100% non biased AI. Bias is something inevitable given how these things work.
|
||||||
|
|
||||||
|
That's why I am an advocate of opensource models. At least, we can probe them, we can check them, and they are available in many forms and flavors. Closing everything would be forbidding good people who use this for good from benefiting from it. Bad people who doesn't respect the laws will probably continue doing what they do.
|
||||||
|
|
||||||
|
Ai is like pandora box. It has been opened and can't be closed. At least, I fail to find any possible way to contain it. In these cases, if you can't contain it, then let people access these things and teach them to start using their brains to dissern truth from lies. People should be trained to have critical minds and not just be passive consumers.
|
||||||
|
|
||||||
|
The models we have today are not concious, they are just function calls. They don't have lives and stop thinking the moment you stop talking to them. But with increasing context size, this may become false. Now recurrent transformers primiss contexts as big as 2 Million tokens. Think of the context as the life line of the conversational ai. through interaction, the AI shapes its personality. With small context size, it can't live long. But with big one, and with new multimodal LLMS, AI can see, can hear, can talk and most importantly, can think.
|
||||||
|
|
||||||
|
|
||||||
|
At some point, we need to forbid those things from starting to think on their own. But projects like autogpt and the langchain are giving more control to the AI. Still, the human is in control, but he is less and less in control. At least for now, bad things still come from humans and not AI by itself.
|
||||||
|
|
||||||
|
But who knows?
|
||||||
17
ai_ethics/fair_discussion.md
Normal file
@ -0,0 +1,17 @@
|
|||||||
|
This is a discussion between a 5 years old child and two phylosophers. The first one pro ai and the socond one is anti ai.
|
||||||
|
Child: Is AI a threat or an opportunity?
|
||||||
|
phylosopher 1: It's both, it depends on how we use it! If used for good purposes like helping humans in areas where they are weak (like emotional intelligence), then yes it can be very helpful and beneficial to humanity. However if people start using AI as a weapon or tool of oppression against other humans, that would definitely become a threat to our society
|
||||||
|
phylosopher 2: It's neither! We should stop wasting time on this stupid discussion about whether it will be good for us or not and focus instead in making sure we don't create something dangerous. If you give an idiot enough rope, he will eventually hang himself... And that applies to AI as well
|
||||||
|
Child: So what do you think is more likely? Will Ai become a threat or just another tool like any other technology has been for humans?
|
||||||
|
phylosopher 1: Honestly i believe it can be both. It depends on how we use and regulate its development, much like nuclear energy which was initially seen as a weapon but is now used in various peaceful applications such as medicine or electricity generation. The same goes with AI - if developed responsibly for the benefit of human kind then there's no reason why it shouldn't be an opportunity
|
||||||
|
phylosopher 2: If we don't stop its development, eventually it will become a threat like nuclear energy did (and still is in some countries). Humans are incredible at finding new ways to destroy themselves and AI seems just perfect for that. Let's focus on stopping this insanity before it goes too far.
|
||||||
|
Child: You are frightening me :(.
|
||||||
|
Phylosopher 2: Well, I don’t mean we should panic or anything but let's not be naive either about the potential dangers AI can bring.
|
||||||
|
Child: Can you be more specific?
|
||||||
|
Phylosopher 2: Sure! Imagine an autonomous military drone capable of identifying and targeting enemy combatants on its own, without any human intervention or oversight... Does that sound like something we should just ignore because it might also help us find lost hikers in the woods?
|
||||||
|
Child: But wouldn't this kind of technology be useful for both purposes then? Finding people and destroying them. It would depend on how you use it right? So why not focus more on developing ethical rules to regulate its usage rather than trying to stop it completely or just hoping that no one will ever misuse AI?
|
||||||
|
Phylosopher 1: I agree with your point about focusing on the development of ethics and regulations around AI, but i think we also need to consider if/how this technology should be developed at all. We've seen what happened when nuclear energy was unleashed onto our world without proper safeguards in place - now imagine something even more powerful than that... Shouldn't we try and avoid creating another potential disaster?
|
||||||
|
Child: But can you really stop the development of AI if people want it so much for different purposes like helping disabled or improving productivity at workplaces. It seems to me, humans are going to develop this technology no matter what because they see benefits in using it and we should just try our best to regulate its usage
|
||||||
|
Phylosopher 2: I completely agree with you on that point! Humans will always find ways to improve themselves or their surroundings through technological advancements, so trying to ban AI outright is simply not realistic. However, what we can do as a society is try and slow down its development by raising awareness about the potential dangers it could bring while also focusing on creating ethical guidelines for its usage
|
||||||
|
Child: So should i be scared of ai or excited? :D
|
||||||
|
Phylosopher 1 & Phylosopher 2 in unison: Both! It all depends on how we use and regulate AI's development
|
||||||
962
api/__init__.py
Normal file
@ -0,0 +1,962 @@
|
|||||||
|
######
|
||||||
|
# Project : lollms-webui
|
||||||
|
# File : api.py
|
||||||
|
# Author : ParisNeo with the help of the community
|
||||||
|
# Supported by Nomic-AI
|
||||||
|
# license : Apache 2.0
|
||||||
|
# Description :
|
||||||
|
# A simple api to communicate with lollms-webui and its models.
|
||||||
|
######
|
||||||
|
from flask import request
|
||||||
|
from datetime import datetime
|
||||||
|
from api.db import DiscussionsDB
|
||||||
|
from api.helpers import compare_lists
|
||||||
|
from pathlib import Path
|
||||||
|
import importlib
|
||||||
|
from lollms.config import InstallOption
|
||||||
|
from lollms.types import MSG_TYPE
|
||||||
|
from lollms.personality import AIPersonality, PersonalityBuilder
|
||||||
|
from lollms.binding import LOLLMSConfig, BindingBuilder, LLMBinding, ModelBuilder
|
||||||
|
from lollms.paths import LollmsPaths
|
||||||
|
from lollms.helpers import ASCIIColors
|
||||||
|
import multiprocessing as mp
|
||||||
|
import threading
|
||||||
|
import time
|
||||||
|
import requests
|
||||||
|
from tqdm import tqdm
|
||||||
|
import traceback
|
||||||
|
import sys
|
||||||
|
from lollms.console import MainMenu
|
||||||
|
import urllib
|
||||||
|
import traceback
|
||||||
|
|
||||||
|
__author__ = "parisneo"
|
||||||
|
__github__ = "https://github.com/ParisNeo/lollms-webui"
|
||||||
|
__copyright__ = "Copyright 2023, "
|
||||||
|
__license__ = "Apache 2.0"
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
import subprocess
|
||||||
|
import pkg_resources
|
||||||
|
|
||||||
|
|
||||||
|
# ===========================================================
|
||||||
|
# Manage automatic install scripts
|
||||||
|
|
||||||
|
def is_package_installed(package_name):
|
||||||
|
try:
|
||||||
|
dist = pkg_resources.get_distribution(package_name)
|
||||||
|
return True
|
||||||
|
except pkg_resources.DistributionNotFound:
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def install_package(package_name):
|
||||||
|
try:
|
||||||
|
# Check if the package is already installed
|
||||||
|
__import__(package_name)
|
||||||
|
print(f"{package_name} is already installed.")
|
||||||
|
except ImportError:
|
||||||
|
print(f"{package_name} is not installed. Installing...")
|
||||||
|
|
||||||
|
# Install the package using pip
|
||||||
|
subprocess.check_call(["pip", "install", package_name])
|
||||||
|
|
||||||
|
print(f"{package_name} has been successfully installed.")
|
||||||
|
|
||||||
|
|
||||||
|
def parse_requirements_file(requirements_path):
|
||||||
|
with open(requirements_path, 'r') as f:
|
||||||
|
for line in f:
|
||||||
|
line = line.strip()
|
||||||
|
if not line or line.startswith('#'):
|
||||||
|
# Skip empty and commented lines
|
||||||
|
continue
|
||||||
|
package_name, _, version_specifier = line.partition('==')
|
||||||
|
package_name, _, version_specifier = line.partition('>=')
|
||||||
|
if is_package_installed(package_name):
|
||||||
|
# The package is already installed
|
||||||
|
print(f"{package_name} is already installed.")
|
||||||
|
else:
|
||||||
|
# The package is not installed, install it
|
||||||
|
if version_specifier:
|
||||||
|
install_package(f"{package_name}{version_specifier}")
|
||||||
|
else:
|
||||||
|
install_package(package_name)
|
||||||
|
|
||||||
|
|
||||||
|
# ===========================================================
|
||||||
|
|
||||||
|
|
||||||
|
class LoLLMsAPPI():
|
||||||
|
def __init__(self, config:LOLLMSConfig, socketio, config_file_path:str, lollms_paths: LollmsPaths) -> None:
|
||||||
|
self.lollms_paths = lollms_paths
|
||||||
|
self.config = config
|
||||||
|
self.is_ready = True
|
||||||
|
self.menu = MainMenu(self)
|
||||||
|
|
||||||
|
|
||||||
|
self.socketio = socketio
|
||||||
|
# Check model
|
||||||
|
if config.binding_name is None:
|
||||||
|
self.menu.select_binding()
|
||||||
|
|
||||||
|
self.binding = BindingBuilder().build_binding(self.config, self.lollms_paths)
|
||||||
|
|
||||||
|
# Check model
|
||||||
|
if config.model_name is None:
|
||||||
|
self.menu.select_model()
|
||||||
|
|
||||||
|
self.mounted_personalities = []
|
||||||
|
try:
|
||||||
|
self.model = self.binding.build_model()
|
||||||
|
self.mounted_personalities = self.rebuild_personalities()
|
||||||
|
if self.config["active_personality_id"]<len(self.mounted_personalities):
|
||||||
|
self.personality:AIPersonality = self.mounted_personalities[self.config["active_personality_id"]]
|
||||||
|
else:
|
||||||
|
self.personality:AIPersonality = None
|
||||||
|
if config["debug"]:
|
||||||
|
print(print(f"{self.personality}"))
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
ASCIIColors.error(f"Couldn't load model:\nException generated:{ex}")
|
||||||
|
self.model = None
|
||||||
|
self.config_file_path = config_file_path
|
||||||
|
self.cancel_gen = False
|
||||||
|
|
||||||
|
# Keeping track of current discussion and message
|
||||||
|
self.current_discussion = None
|
||||||
|
self._current_user_message_id = 0
|
||||||
|
self._current_ai_message_id = 0
|
||||||
|
self._message_id = 0
|
||||||
|
|
||||||
|
self.db_path = config["db_path"]
|
||||||
|
if Path(self.db_path).is_absolute():
|
||||||
|
# Create database object
|
||||||
|
self.db = DiscussionsDB(self.db_path)
|
||||||
|
else:
|
||||||
|
# Create database object
|
||||||
|
self.db = DiscussionsDB(self.lollms_paths.personal_path/"databases"/self.db_path)
|
||||||
|
|
||||||
|
# If the database is empty, populate it with tables
|
||||||
|
ASCIIColors.info("Checking discussions database... ",end="")
|
||||||
|
self.db.create_tables()
|
||||||
|
self.db.add_missing_columns()
|
||||||
|
ASCIIColors.success("ok")
|
||||||
|
|
||||||
|
# This is used to keep track of messages
|
||||||
|
self.full_message_list = []
|
||||||
|
self.current_room_id = None
|
||||||
|
self.download_infos={}
|
||||||
|
# =========================================================================================
|
||||||
|
# Socket IO stuff
|
||||||
|
# =========================================================================================
|
||||||
|
@socketio.on('connect')
|
||||||
|
def connect():
|
||||||
|
ASCIIColors.success(f'Client {request.sid} connected')
|
||||||
|
|
||||||
|
@socketio.on('disconnect')
|
||||||
|
def disconnect():
|
||||||
|
ASCIIColors.error(f'Client {request.sid} disconnected')
|
||||||
|
|
||||||
|
|
||||||
|
@socketio.on('cancel_install')
|
||||||
|
def cancel_install(data):
|
||||||
|
model_name = data["model_name"]
|
||||||
|
binding_folder = data["binding_folder"]
|
||||||
|
model_url = data["model_url"]
|
||||||
|
signature = f"{model_name}_{binding_folder}_{model_url}"
|
||||||
|
self.download_infos[signature]["cancel"]=True
|
||||||
|
self.socketio.emit('canceled', {
|
||||||
|
'status': True
|
||||||
|
},
|
||||||
|
room=self.current_room_id
|
||||||
|
)
|
||||||
|
|
||||||
|
@socketio.on('install_model')
|
||||||
|
def install_model(data):
|
||||||
|
room_id = request.sid
|
||||||
|
|
||||||
|
def get_file_size(url):
|
||||||
|
# Send a HEAD request to retrieve file metadata
|
||||||
|
response = urllib.request.urlopen(url)
|
||||||
|
|
||||||
|
# Extract the Content-Length header value
|
||||||
|
file_size = response.headers.get('Content-Length')
|
||||||
|
|
||||||
|
# Convert the file size to integer
|
||||||
|
if file_size:
|
||||||
|
file_size = int(file_size)
|
||||||
|
|
||||||
|
return file_size
|
||||||
|
|
||||||
|
def install_model_():
|
||||||
|
print("Install model triggered")
|
||||||
|
model_path = data["path"]
|
||||||
|
progress = 0
|
||||||
|
installation_dir = self.lollms_paths.personal_models_path/self.config["binding_name"]
|
||||||
|
filename = Path(model_path).name
|
||||||
|
installation_path = installation_dir / filename
|
||||||
|
print("Model install requested")
|
||||||
|
print(f"Model path : {model_path}")
|
||||||
|
|
||||||
|
model_name = filename
|
||||||
|
binding_folder = self.config["binding_name"]
|
||||||
|
model_url = model_path
|
||||||
|
signature = f"{model_name}_{binding_folder}_{model_url}"
|
||||||
|
self.download_infos[signature]={
|
||||||
|
"start_time":datetime.now(),
|
||||||
|
"total_size":get_file_size(model_path),
|
||||||
|
"downloaded_size":0,
|
||||||
|
"progress":0,
|
||||||
|
"speed":0,
|
||||||
|
"cancel":False
|
||||||
|
}
|
||||||
|
|
||||||
|
if installation_path.exists():
|
||||||
|
print("Error: Model already exists")
|
||||||
|
socketio.emit('install_progress',{
|
||||||
|
'status': False,
|
||||||
|
'error': 'model already exists',
|
||||||
|
'model_name' : model_name,
|
||||||
|
'binding_folder' : binding_folder,
|
||||||
|
'model_url' : model_url,
|
||||||
|
'start_time': self.download_infos[signature]['start_time'].strftime("%Y-%m-%d %H:%M:%S"),
|
||||||
|
'total_size': self.download_infos[signature]['total_size'],
|
||||||
|
'downloaded_size': self.download_infos[signature]['downloaded_size'],
|
||||||
|
'progress': self.download_infos[signature]['progress'],
|
||||||
|
'speed': self.download_infos[signature]['speed'],
|
||||||
|
}, room=room_id
|
||||||
|
)
|
||||||
|
|
||||||
|
socketio.emit('install_progress',{
|
||||||
|
'status': True,
|
||||||
|
'progress': progress,
|
||||||
|
'model_name' : model_name,
|
||||||
|
'binding_folder' : binding_folder,
|
||||||
|
'model_url' : model_url,
|
||||||
|
'start_time': self.download_infos[signature]['start_time'].strftime("%Y-%m-%d %H:%M:%S"),
|
||||||
|
'total_size': self.download_infos[signature]['total_size'],
|
||||||
|
'downloaded_size': self.download_infos[signature]['downloaded_size'],
|
||||||
|
'progress': self.download_infos[signature]['progress'],
|
||||||
|
'speed': self.download_infos[signature]['speed'],
|
||||||
|
|
||||||
|
}, room=room_id)
|
||||||
|
|
||||||
|
def callback(downloaded_size, total_size):
|
||||||
|
progress = (downloaded_size / total_size) * 100
|
||||||
|
now = datetime.now()
|
||||||
|
dt = (now - self.download_infos[signature]['start_time']).total_seconds()
|
||||||
|
speed = downloaded_size/dt
|
||||||
|
self.download_infos[signature]['downloaded_size'] = downloaded_size
|
||||||
|
self.download_infos[signature]['speed'] = speed
|
||||||
|
|
||||||
|
if progress - self.download_infos[signature]['progress']>2:
|
||||||
|
self.download_infos[signature]['progress'] = progress
|
||||||
|
socketio.emit('install_progress',{
|
||||||
|
'status': True,
|
||||||
|
'model_name' : model_name,
|
||||||
|
'binding_folder' : binding_folder,
|
||||||
|
'model_url' : model_url,
|
||||||
|
'start_time': self.download_infos[signature]['start_time'].strftime("%Y-%m-%d %H:%M:%S"),
|
||||||
|
'total_size': self.download_infos[signature]['total_size'],
|
||||||
|
'downloaded_size': self.download_infos[signature]['downloaded_size'],
|
||||||
|
'progress': self.download_infos[signature]['progress'],
|
||||||
|
'speed': self.download_infos[signature]['speed'],
|
||||||
|
}, room=room_id)
|
||||||
|
|
||||||
|
if self.download_infos[signature]["cancel"]:
|
||||||
|
raise Exception("canceled")
|
||||||
|
|
||||||
|
|
||||||
|
if hasattr(self.binding, "download_model"):
|
||||||
|
try:
|
||||||
|
self.binding.download_model(model_path, installation_path, callback)
|
||||||
|
except Exception as ex:
|
||||||
|
ASCIIColors.warning(str(ex))
|
||||||
|
socketio.emit('install_progress',{
|
||||||
|
'status': False,
|
||||||
|
'error': 'canceled',
|
||||||
|
'model_name' : model_name,
|
||||||
|
'binding_folder' : binding_folder,
|
||||||
|
'model_url' : model_url,
|
||||||
|
'start_time': self.download_infos[signature]['start_time'].strftime("%Y-%m-%d %H:%M:%S"),
|
||||||
|
'total_size': self.download_infos[signature]['total_size'],
|
||||||
|
'downloaded_size': self.download_infos[signature]['downloaded_size'],
|
||||||
|
'progress': self.download_infos[signature]['progress'],
|
||||||
|
'speed': self.download_infos[signature]['speed'],
|
||||||
|
}, room=room_id
|
||||||
|
)
|
||||||
|
del self.download_infos[signature]
|
||||||
|
installation_path.unlink()
|
||||||
|
return
|
||||||
|
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
self.download_file(model_path, installation_path, callback)
|
||||||
|
except Exception as ex:
|
||||||
|
ASCIIColors.warning(str(ex))
|
||||||
|
socketio.emit('install_progress',{
|
||||||
|
'status': False,
|
||||||
|
'error': 'canceled',
|
||||||
|
'model_name' : model_name,
|
||||||
|
'binding_folder' : binding_folder,
|
||||||
|
'model_url' : model_url,
|
||||||
|
'start_time': self.download_infos[signature]['start_time'].strftime("%Y-%m-%d %H:%M:%S"),
|
||||||
|
'total_size': self.download_infos[signature]['total_size'],
|
||||||
|
'downloaded_size': self.download_infos[signature]['downloaded_size'],
|
||||||
|
'progress': self.download_infos[signature]['progress'],
|
||||||
|
'speed': self.download_infos[signature]['speed'],
|
||||||
|
}, room=room_id
|
||||||
|
)
|
||||||
|
del self.download_infos[signature]
|
||||||
|
installation_path.unlink()
|
||||||
|
return
|
||||||
|
socketio.emit('install_progress',{
|
||||||
|
'status': True,
|
||||||
|
'error': '',
|
||||||
|
'model_name' : model_name,
|
||||||
|
'binding_folder' : binding_folder,
|
||||||
|
'model_url' : model_url,
|
||||||
|
'start_time': self.download_infos[signature]['start_time'].strftime("%Y-%m-%d %H:%M:%S"),
|
||||||
|
'total_size': self.download_infos[signature]['total_size'],
|
||||||
|
'downloaded_size': self.download_infos[signature]['downloaded_size'],
|
||||||
|
'progress': 100,
|
||||||
|
'speed': self.download_infos[signature]['speed'],
|
||||||
|
}, room=room_id)
|
||||||
|
del self.download_infos[signature]
|
||||||
|
|
||||||
|
tpe = threading.Thread(target=install_model_, args=())
|
||||||
|
tpe.start()
|
||||||
|
|
||||||
|
@socketio.on('uninstall_model')
|
||||||
|
def uninstall_model(data):
|
||||||
|
model_path = data['path']
|
||||||
|
installation_dir = self.lollms_paths.personal_models_path/self.config["binding_name"]
|
||||||
|
filename = Path(model_path).name
|
||||||
|
installation_path = installation_dir / filename
|
||||||
|
|
||||||
|
model_name = filename
|
||||||
|
binding_folder = self.config["binding_name"]
|
||||||
|
|
||||||
|
if not installation_path.exists():
|
||||||
|
socketio.emit('install_progress',{
|
||||||
|
'status': False,
|
||||||
|
'error': 'The model does not exist',
|
||||||
|
'model_name' : model_name,
|
||||||
|
'binding_folder' : binding_folder
|
||||||
|
}, room=request.sid)
|
||||||
|
|
||||||
|
installation_path.unlink()
|
||||||
|
socketio.emit('install_progress',{
|
||||||
|
'status': True,
|
||||||
|
'error': '',
|
||||||
|
'model_name' : model_name,
|
||||||
|
'binding_folder' : binding_folder
|
||||||
|
}, room=request.sid)
|
||||||
|
|
||||||
|
|
||||||
|
@socketio.on('upload_file')
|
||||||
|
def upload_file(data):
|
||||||
|
file = data['file']
|
||||||
|
filename = file.filename
|
||||||
|
save_path = self.lollms_paths.personal_uploads_path/filename # Specify the desired folder path
|
||||||
|
|
||||||
|
try:
|
||||||
|
if not self.personality.processor is None:
|
||||||
|
self.personality.processor.add_file(save_path)
|
||||||
|
file.save(save_path)
|
||||||
|
# File saved successfully
|
||||||
|
socketio.emit('progress', {'status':True, 'progress': 100})
|
||||||
|
|
||||||
|
else:
|
||||||
|
# Personality doesn't support file sending
|
||||||
|
socketio.emit('progress', {'status':False, 'error': "Personality doesn't support file sending"})
|
||||||
|
except Exception as e:
|
||||||
|
# Error occurred while saving the file
|
||||||
|
socketio.emit('progress', {'status':False, 'error': str(e)})
|
||||||
|
|
||||||
|
@socketio.on('cancel_generation')
|
||||||
|
def cancel_generation():
|
||||||
|
self.cancel_gen = True
|
||||||
|
ASCIIColors.error(f'Client {request.sid} canceled generation')
|
||||||
|
|
||||||
|
|
||||||
|
@socketio.on('generate_msg')
|
||||||
|
def generate_msg(data):
|
||||||
|
self.current_room_id = request.sid
|
||||||
|
if self.is_ready:
|
||||||
|
if self.current_discussion is None:
|
||||||
|
if self.db.does_last_discussion_have_messages():
|
||||||
|
self.current_discussion = self.db.create_discussion()
|
||||||
|
else:
|
||||||
|
self.current_discussion = self.db.load_last_discussion()
|
||||||
|
|
||||||
|
message = data["prompt"]
|
||||||
|
message_id = self.current_discussion.add_message(
|
||||||
|
"user",
|
||||||
|
message,
|
||||||
|
message_type=DiscussionsDB.MSG_TYPE_NORMAL_USER,
|
||||||
|
parent=self.message_id
|
||||||
|
)
|
||||||
|
|
||||||
|
self.current_user_message_id = message_id
|
||||||
|
ASCIIColors.green("Starting message generation by"+self.personality.name)
|
||||||
|
|
||||||
|
task = self.socketio.start_background_task(self.start_message_generation, message, message_id)
|
||||||
|
self.socketio.sleep(0)
|
||||||
|
ASCIIColors.info("Started generation task")
|
||||||
|
#tpe = threading.Thread(target=self.start_message_generation, args=(message, message_id))
|
||||||
|
#tpe.start()
|
||||||
|
else:
|
||||||
|
self.socketio.emit("buzzy", {"message":"I am buzzy. Come back later."}, room=self.current_room_id)
|
||||||
|
self.socketio.sleep(0)
|
||||||
|
ASCIIColors.warning(f"OOps request {self.current_room_id} refused!! Server buzy")
|
||||||
|
self.socketio.emit('infos',
|
||||||
|
{
|
||||||
|
"status":'model_not_ready',
|
||||||
|
"type": "input_message_infos",
|
||||||
|
'logo': "",
|
||||||
|
"bot": self.personality.name,
|
||||||
|
"user": self.personality.user_name,
|
||||||
|
"message":"",
|
||||||
|
"user_message_id": self.current_user_message_id,
|
||||||
|
"ai_message_id": self.current_ai_message_id,
|
||||||
|
|
||||||
|
'binding': self.current_discussion.current_message_binding,
|
||||||
|
'model': self.current_discussion.current_message_model,
|
||||||
|
'personality': self.current_discussion.current_message_personality,
|
||||||
|
'created_at': self.current_discussion.current_message_created_at,
|
||||||
|
'finished_generating_at': self.current_discussion.current_message_finished_generating_at,
|
||||||
|
}, room=self.current_room_id
|
||||||
|
)
|
||||||
|
self.socketio.sleep(0)
|
||||||
|
|
||||||
|
@socketio.on('generate_msg_from')
|
||||||
|
def handle_connection(data):
|
||||||
|
message_id = int(data['id'])
|
||||||
|
message = data["prompt"]
|
||||||
|
self.current_user_message_id = message_id
|
||||||
|
tpe = threading.Thread(target=self.start_message_generation, args=(message, message_id))
|
||||||
|
tpe.start()
|
||||||
|
# generation status
|
||||||
|
self.generating=False
|
||||||
|
ASCIIColors.blue(f"Your personal data is stored here :",end="")
|
||||||
|
ASCIIColors.green(f"{self.lollms_paths.personal_path}")
|
||||||
|
|
||||||
|
|
||||||
|
@socketio.on('continue_generate_msg_from')
|
||||||
|
def handle_connection(data):
|
||||||
|
message_id = int(data['id'])
|
||||||
|
message = data["prompt"]
|
||||||
|
self.current_user_message_id = message_id
|
||||||
|
tpe = threading.Thread(target=self.start_message_generation, args=(message, message_id))
|
||||||
|
tpe.start()
|
||||||
|
# generation status
|
||||||
|
self.generating=False
|
||||||
|
ASCIIColors.blue(f"Your personal data is stored here :",end="")
|
||||||
|
ASCIIColors.green(f"{self.lollms_paths.personal_path}")
|
||||||
|
|
||||||
|
|
||||||
|
def rebuild_personalities(self):
|
||||||
|
loaded = self.mounted_personalities
|
||||||
|
loaded_names = [f"{p.language}/{p.category}/{p.personality_folder_name}" for p in loaded]
|
||||||
|
mounted_personalities=[]
|
||||||
|
ASCIIColors.success(f" ╔══════════════════════════════════════════════════╗ ")
|
||||||
|
ASCIIColors.success(f" ║ Building mounted Personalities ║ ")
|
||||||
|
ASCIIColors.success(f" ╚══════════════════════════════════════════════════╝ ")
|
||||||
|
to_remove=[]
|
||||||
|
for i,personality in enumerate(self.config['personalities']):
|
||||||
|
if personality in loaded_names:
|
||||||
|
mounted_personalities.append(loaded[loaded_names.index(personality)])
|
||||||
|
else:
|
||||||
|
personality_path = self.lollms_paths.personalities_zoo_path/f"{personality}"
|
||||||
|
try:
|
||||||
|
if i==self.config["active_personality_id"]:
|
||||||
|
ASCIIColors.red("*", end="")
|
||||||
|
ASCIIColors.green(f" {personality}")
|
||||||
|
else:
|
||||||
|
ASCIIColors.yellow(f" {personality}")
|
||||||
|
|
||||||
|
personality = AIPersonality(personality_path,
|
||||||
|
self.lollms_paths,
|
||||||
|
self.config,
|
||||||
|
model=self.model,
|
||||||
|
run_scripts=True)
|
||||||
|
mounted_personalities.append(personality)
|
||||||
|
except Exception as ex:
|
||||||
|
ASCIIColors.error(f"Personality file not found or is corrupted ({personality_path}).\nReturned the following exception:{ex}\nPlease verify that the personality you have selected exists or select another personality. Some updates may lead to change in personality name or category, so check the personality selection in settings to be sure.")
|
||||||
|
ASCIIColors.info("Trying to force reinstall")
|
||||||
|
if self.config["debug"]:
|
||||||
|
print(ex)
|
||||||
|
try:
|
||||||
|
personality = AIPersonality(
|
||||||
|
personality_path,
|
||||||
|
self.lollms_paths,
|
||||||
|
self.config,
|
||||||
|
self.model,
|
||||||
|
run_scripts=True,
|
||||||
|
installation_option=InstallOption.FORCE_INSTALL)
|
||||||
|
mounted_personalities.append(personality)
|
||||||
|
except:
|
||||||
|
ASCIIColors.error(f"Couldn't load personality at {personality_path}")
|
||||||
|
ASCIIColors.info(f"Unmounting personality")
|
||||||
|
to_remove.append(i)
|
||||||
|
personality = AIPersonality(None, self.lollms_paths,
|
||||||
|
self.config,
|
||||||
|
self.model,
|
||||||
|
run_scripts=True,
|
||||||
|
installation_option=InstallOption.FORCE_INSTALL)
|
||||||
|
mounted_personalities.append(personality)
|
||||||
|
ASCIIColors.info("Reverted to default personality")
|
||||||
|
print(f'selected : {self.config["active_personality_id"]}')
|
||||||
|
ASCIIColors.success(f" ╔══════════════════════════════════════════════════╗ ")
|
||||||
|
ASCIIColors.success(f" ║ Done ║ ")
|
||||||
|
ASCIIColors.success(f" ╚══════════════════════════════════════════════════╝ ")
|
||||||
|
# Sort the indices in descending order to ensure correct removal
|
||||||
|
to_remove.sort(reverse=True)
|
||||||
|
|
||||||
|
# Remove elements from the list based on the indices
|
||||||
|
for index in to_remove:
|
||||||
|
if 0 <= index < len(mounted_personalities):
|
||||||
|
mounted_personalities.pop(index)
|
||||||
|
self.config["personalities"].pop(index)
|
||||||
|
ASCIIColors.info(f"removed personality {personality_path}")
|
||||||
|
|
||||||
|
if self.config["active_personality_id"]>=len(self.config["personalities"]):
|
||||||
|
self.config["active_personality_id"]=0
|
||||||
|
|
||||||
|
return mounted_personalities
|
||||||
|
# ================================== LOLLMSApp
|
||||||
|
|
||||||
|
def load_binding(self):
|
||||||
|
if self.config.binding_name is None:
|
||||||
|
print(f"No bounding selected")
|
||||||
|
print("Please select a valid model or install a new one from a url")
|
||||||
|
self.menu.select_binding()
|
||||||
|
# cfg.download_model(url)
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
self.binding = BindingBuilder().build_binding(self.config, self.lollms_paths)
|
||||||
|
except Exception as ex:
|
||||||
|
print(ex)
|
||||||
|
print(f"Couldn't find binding. Please verify your configuration file at {self.config.file_path} or use the next menu to select a valid binding")
|
||||||
|
print(f"Trying to reinstall binding")
|
||||||
|
self.binding = BindingBuilder().build_binding(self.config, self.lollms_paths, InstallOption.FORCE_INSTALL)
|
||||||
|
self.menu.select_binding()
|
||||||
|
|
||||||
|
def load_model(self):
|
||||||
|
try:
|
||||||
|
self.active_model = ModelBuilder(self.binding).get_model()
|
||||||
|
ASCIIColors.success("Model loaded successfully")
|
||||||
|
except Exception as ex:
|
||||||
|
ASCIIColors.error(f"Couldn't load model.")
|
||||||
|
ASCIIColors.error(f"Binding returned this exception : {ex}")
|
||||||
|
ASCIIColors.error(f"{self.config.get_model_path_infos()}")
|
||||||
|
print("Please select a valid model or install a new one from a url")
|
||||||
|
self.menu.select_model()
|
||||||
|
|
||||||
|
def load_personality(self):
|
||||||
|
try:
|
||||||
|
self.personality = PersonalityBuilder(self.lollms_paths, self.config, self.model).build_personality()
|
||||||
|
except Exception as ex:
|
||||||
|
ASCIIColors.error(f"Couldn't load personality.")
|
||||||
|
ASCIIColors.error(f"Binding returned this exception : {ex}")
|
||||||
|
ASCIIColors.error(f"{self.config.get_personality_path_infos()}")
|
||||||
|
print("Please select a valid model or install a new one from a url")
|
||||||
|
self.menu.select_model()
|
||||||
|
self.cond_tk = self.personality.model.tokenize(self.personality.personality_conditioning)
|
||||||
|
self.n_cond_tk = len(self.cond_tk)
|
||||||
|
|
||||||
|
|
||||||
|
#properties
|
||||||
|
@property
|
||||||
|
def message_id(self):
|
||||||
|
return self._message_id
|
||||||
|
|
||||||
|
@property
|
||||||
|
def current_user_message_id(self):
|
||||||
|
return self._current_user_message_id
|
||||||
|
@current_user_message_id.setter
|
||||||
|
def current_user_message_id(self, id):
|
||||||
|
self._current_user_message_id=id
|
||||||
|
self._message_id = id
|
||||||
|
@property
|
||||||
|
def current_ai_message_id(self):
|
||||||
|
return self._current_ai_message_id
|
||||||
|
@current_ai_message_id.setter
|
||||||
|
def current_ai_message_id(self, id):
|
||||||
|
self._current_ai_message_id=id
|
||||||
|
self._message_id = id
|
||||||
|
|
||||||
|
def download_file(self, url, installation_path, callback=None):
|
||||||
|
"""
|
||||||
|
Downloads a file from a URL, reports the download progress using a callback function, and displays a progress bar.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
url (str): The URL of the file to download.
|
||||||
|
installation_path (str): The path where the file should be saved.
|
||||||
|
callback (function, optional): A callback function to be called during the download
|
||||||
|
with the progress percentage as an argument. Defaults to None.
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
response = requests.get(url, stream=True)
|
||||||
|
|
||||||
|
# Get the file size from the response headers
|
||||||
|
total_size = int(response.headers.get('content-length', 0))
|
||||||
|
|
||||||
|
with open(installation_path, 'wb') as file:
|
||||||
|
downloaded_size = 0
|
||||||
|
with tqdm(total=total_size, unit='B', unit_scale=True, ncols=80) as progress_bar:
|
||||||
|
for chunk in response.iter_content(chunk_size=8192):
|
||||||
|
if chunk:
|
||||||
|
file.write(chunk)
|
||||||
|
downloaded_size += len(chunk)
|
||||||
|
if callback is not None:
|
||||||
|
callback(downloaded_size, total_size)
|
||||||
|
progress_bar.update(len(chunk))
|
||||||
|
|
||||||
|
if callback is not None:
|
||||||
|
callback(total_size, total_size)
|
||||||
|
|
||||||
|
print("File downloaded successfully")
|
||||||
|
except Exception as e:
|
||||||
|
print("Couldn't download file:", str(e))
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def condition_chatbot(self):
|
||||||
|
if self.current_discussion is None:
|
||||||
|
self.current_discussion = self.db.load_last_discussion()
|
||||||
|
|
||||||
|
if self.personality.welcome_message!="":
|
||||||
|
message_id = self.current_discussion.add_message(
|
||||||
|
self.personality.name, self.personality.welcome_message,
|
||||||
|
DiscussionsDB.MSG_TYPE_NORMAL_AI if self.personality.include_welcome_message_in_disucssion else DiscussionsDB.MSG_TYPE_USER_ONLY,
|
||||||
|
0,
|
||||||
|
-1,
|
||||||
|
binding= self.config["binding_name"],
|
||||||
|
model = self.config["model_name"],
|
||||||
|
personality=self.config["personalities"][self.config["active_personality_id"]]
|
||||||
|
)
|
||||||
|
|
||||||
|
self.current_ai_message_id = message_id
|
||||||
|
else:
|
||||||
|
message_id = 0
|
||||||
|
return message_id
|
||||||
|
|
||||||
|
def prepare_reception(self):
|
||||||
|
self.current_generated_text = ""
|
||||||
|
self.full_text = ""
|
||||||
|
self.is_bot_text_started = False
|
||||||
|
|
||||||
|
def create_new_discussion(self, title):
|
||||||
|
self.current_discussion = self.db.create_discussion(title)
|
||||||
|
# Get the current timestamp
|
||||||
|
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
||||||
|
|
||||||
|
# Chatbot conditionning
|
||||||
|
self.condition_chatbot()
|
||||||
|
return timestamp
|
||||||
|
|
||||||
|
def prepare_query(self, message_id=-1, is_continue=False):
|
||||||
|
messages = self.current_discussion.get_messages()
|
||||||
|
self.full_message_list = []
|
||||||
|
for message in messages:
|
||||||
|
if message["id"]< message_id or message_id==-1:
|
||||||
|
if message["type"]==self.db.MSG_TYPE_NORMAL_USER or message["type"]==self.db.MSG_TYPE_NORMAL_AI:
|
||||||
|
if message["sender"]==self.personality.name:
|
||||||
|
self.full_message_list.append(self.personality.ai_message_prefix+message["content"])
|
||||||
|
else:
|
||||||
|
self.full_message_list.append(self.personality.user_message_prefix + message["content"])
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
|
||||||
|
link_text = self.personality.link_text
|
||||||
|
if not is_continue:
|
||||||
|
if self.personality.processor is not None:
|
||||||
|
preprocessed_prompt = self.personality.processor.process_model_input(message["content"])
|
||||||
|
else:
|
||||||
|
preprocessed_prompt = message["content"]
|
||||||
|
|
||||||
|
if preprocessed_prompt is not None:
|
||||||
|
self.full_message_list.append(self.personality.user_message_prefix+preprocessed_prompt+self.personality.link_text+self.personality.ai_message_prefix)
|
||||||
|
else:
|
||||||
|
self.full_message_list.append(self.personality.user_message_prefix+message["content"]+self.personality.link_text+self.personality.ai_message_prefix)
|
||||||
|
else:
|
||||||
|
self.full_message_list.append(self.personality.ai_message_prefix+message["content"])
|
||||||
|
|
||||||
|
|
||||||
|
discussion_messages = self.personality.personality_conditioning+ link_text.join(self.full_message_list)
|
||||||
|
|
||||||
|
|
||||||
|
return discussion_messages, message["content"]
|
||||||
|
|
||||||
|
def get_discussion_to(self, message_id=-1):
|
||||||
|
messages = self.current_discussion.get_messages()
|
||||||
|
self.full_message_list = []
|
||||||
|
for message in messages:
|
||||||
|
if message["id"]<= message_id or message_id==-1:
|
||||||
|
if message["type"]!=self.db.MSG_TYPE_CONDITIONNING:
|
||||||
|
if message["sender"]==self.personality.name:
|
||||||
|
self.full_message_list.append(self.personality.ai_message_prefix+message["content"])
|
||||||
|
else:
|
||||||
|
self.full_message_list.append(self.personality.user_message_prefix + message["content"])
|
||||||
|
|
||||||
|
link_text = self.personality.link_text
|
||||||
|
|
||||||
|
if len(self.full_message_list) > self.config["nb_messages_to_remember"]:
|
||||||
|
discussion_messages = self.personality.personality_conditioning+ link_text.join(self.full_message_list[-self.config["nb_messages_to_remember"]:])
|
||||||
|
else:
|
||||||
|
discussion_messages = self.personality.personality_conditioning+ link_text.join(self.full_message_list)
|
||||||
|
|
||||||
|
return discussion_messages # Removes the last return
|
||||||
|
|
||||||
|
def remove_text_from_string(self, string, text_to_find):
|
||||||
|
"""
|
||||||
|
Removes everything from the first occurrence of the specified text in the string (case-insensitive).
|
||||||
|
|
||||||
|
Parameters:
|
||||||
|
string (str): The original string.
|
||||||
|
text_to_find (str): The text to find in the string.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
str: The updated string.
|
||||||
|
"""
|
||||||
|
index = string.lower().find(text_to_find.lower())
|
||||||
|
|
||||||
|
if index != -1:
|
||||||
|
string = string[:index]
|
||||||
|
|
||||||
|
return string
|
||||||
|
|
||||||
|
def process_chunk(self, chunk, message_type:MSG_TYPE):
|
||||||
|
"""
|
||||||
|
0 : a regular message
|
||||||
|
1 : a notification message
|
||||||
|
2 : A hidden message
|
||||||
|
"""
|
||||||
|
if message_type == MSG_TYPE.MSG_TYPE_STEP:
|
||||||
|
ASCIIColors.info("--> Step:"+chunk)
|
||||||
|
if message_type == MSG_TYPE.MSG_TYPE_STEP_START:
|
||||||
|
ASCIIColors.info("--> Step started:"+chunk)
|
||||||
|
if message_type == MSG_TYPE.MSG_TYPE_STEP_END:
|
||||||
|
ASCIIColors.success("--> Step ended:"+chunk)
|
||||||
|
if message_type == MSG_TYPE.MSG_TYPE_EXCEPTION:
|
||||||
|
ASCIIColors.error("--> Exception from personality:"+chunk)
|
||||||
|
|
||||||
|
if message_type == MSG_TYPE.MSG_TYPE_CHUNK:
|
||||||
|
self.current_generated_text += chunk
|
||||||
|
detected_anti_prompt = False
|
||||||
|
anti_prompt_to_remove=""
|
||||||
|
for prompt in self.personality.anti_prompts:
|
||||||
|
if prompt.lower() in self.current_generated_text.lower():
|
||||||
|
detected_anti_prompt=True
|
||||||
|
anti_prompt_to_remove = prompt.lower()
|
||||||
|
|
||||||
|
if not detected_anti_prompt:
|
||||||
|
ASCIIColors.green(f"generated:{len(self.current_generated_text.split())} words", end='\r', flush=True)
|
||||||
|
self.socketio.emit('message', {
|
||||||
|
'data': self.current_generated_text,
|
||||||
|
'user_message_id':self.current_user_message_id,
|
||||||
|
'ai_message_id':self.current_ai_message_id,
|
||||||
|
'discussion_id':self.current_discussion.discussion_id,
|
||||||
|
'message_type': MSG_TYPE.MSG_TYPE_FULL.value
|
||||||
|
}, room=self.current_room_id
|
||||||
|
)
|
||||||
|
self.socketio.sleep(0)
|
||||||
|
self.current_discussion.update_message(self.current_ai_message_id, self.current_generated_text)
|
||||||
|
# if stop generation is detected then stop
|
||||||
|
if not self.cancel_gen:
|
||||||
|
return True
|
||||||
|
else:
|
||||||
|
self.cancel_gen = False
|
||||||
|
ASCIIColors.warning("Generation canceled")
|
||||||
|
return False
|
||||||
|
else:
|
||||||
|
self.current_generated_text = self.remove_text_from_string(self.current_generated_text, anti_prompt_to_remove)
|
||||||
|
ASCIIColors.warning("The model is halucinating")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Stream the generated text to the main process
|
||||||
|
elif message_type == MSG_TYPE.MSG_TYPE_FULL:
|
||||||
|
self.current_generated_text = chunk
|
||||||
|
self.socketio.emit('message', {
|
||||||
|
'data': self.current_generated_text,
|
||||||
|
'user_message_id':self.current_user_message_id,
|
||||||
|
'ai_message_id':self.current_ai_message_id,
|
||||||
|
'discussion_id':self.current_discussion.discussion_id,
|
||||||
|
'message_type': message_type.value
|
||||||
|
}, room=self.current_room_id
|
||||||
|
)
|
||||||
|
self.socketio.sleep(0)
|
||||||
|
return True
|
||||||
|
# Stream the generated text to the frontend
|
||||||
|
else:
|
||||||
|
self.socketio.emit('message', {
|
||||||
|
'data': chunk,
|
||||||
|
'user_message_id':self.current_user_message_id,
|
||||||
|
'ai_message_id':self.current_ai_message_id,
|
||||||
|
'discussion_id':self.current_discussion.discussion_id,
|
||||||
|
'message_type': message_type.value
|
||||||
|
}, room=self.current_room_id
|
||||||
|
)
|
||||||
|
self.socketio.sleep(0)
|
||||||
|
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def generate(self, full_prompt, prompt, n_predict=50, callback=None):
|
||||||
|
if self.personality.processor is not None:
|
||||||
|
if self.personality.processor_cfg is not None:
|
||||||
|
if "custom_workflow" in self.personality.processor_cfg:
|
||||||
|
if self.personality.processor_cfg["custom_workflow"]:
|
||||||
|
ASCIIColors.success("Running workflow")
|
||||||
|
try:
|
||||||
|
output = self.personality.processor.run_workflow( prompt, full_prompt, self.process_chunk)
|
||||||
|
self.process_chunk(output, MSG_TYPE.MSG_TYPE_FULL)
|
||||||
|
except Exception as ex:
|
||||||
|
# Catch the exception and get the traceback as a list of strings
|
||||||
|
traceback_lines = traceback.format_exception(type(ex), ex, ex.__traceback__)
|
||||||
|
# Join the traceback lines into a single string
|
||||||
|
traceback_text = ''.join(traceback_lines)
|
||||||
|
ASCIIColors.error(f"Workflow run failed.\nError:{ex}")
|
||||||
|
ASCIIColors.error(traceback_text)
|
||||||
|
self.process_chunk(f"Workflow run failed\nError:{ex}", MSG_TYPE.MSG_TYPE_EXCEPTION)
|
||||||
|
print("Finished executing the workflow")
|
||||||
|
return
|
||||||
|
|
||||||
|
self._generate(full_prompt, n_predict, callback)
|
||||||
|
print("Finished executing the generation")
|
||||||
|
|
||||||
|
def _generate(self, prompt, n_predict=50, callback=None):
|
||||||
|
self.current_generated_text = ""
|
||||||
|
if self.model is not None:
|
||||||
|
ASCIIColors.info("warmup")
|
||||||
|
if self.config["override_personality_model_parameters"]:
|
||||||
|
output = self.model.generate(
|
||||||
|
prompt,
|
||||||
|
callback=callback,
|
||||||
|
n_predict=n_predict,
|
||||||
|
temperature=self.config['temperature'],
|
||||||
|
top_k=self.config['top_k'],
|
||||||
|
top_p=self.config['top_p'],
|
||||||
|
repeat_penalty=self.config['repeat_penalty'],
|
||||||
|
repeat_last_n = self.config['repeat_last_n'],
|
||||||
|
seed=self.config['seed'],
|
||||||
|
n_threads=self.config['n_threads']
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
output = self.model.generate(
|
||||||
|
prompt,
|
||||||
|
callback=callback,
|
||||||
|
n_predict=self.personality.model_n_predicts,
|
||||||
|
temperature=self.personality.model_temperature,
|
||||||
|
top_k=self.personality.model_top_k,
|
||||||
|
top_p=self.personality.model_top_p,
|
||||||
|
repeat_penalty=self.personality.model_repeat_penalty,
|
||||||
|
repeat_last_n = self.personality.model_repeat_last_n,
|
||||||
|
#seed=self.config['seed'],
|
||||||
|
n_threads=self.config['n_threads']
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
print("No model is installed or selected. Please make sure to install a model and select it inside your configuration before attempting to communicate with the model.")
|
||||||
|
print("To do this: Install the model to your models/<binding name> folder.")
|
||||||
|
print("Then set your model information in your local configuration file that you can find in configs/local_config.yaml")
|
||||||
|
print("You can also use the ui to set your model in the settings page.")
|
||||||
|
output = ""
|
||||||
|
return output
|
||||||
|
|
||||||
|
def start_message_generation(self, message, message_id, is_continue=False):
|
||||||
|
ASCIIColors.info(f"Text generation requested by client: {self.current_room_id}")
|
||||||
|
# send the message to the bot
|
||||||
|
print(f"Received message : {message}")
|
||||||
|
if self.current_discussion:
|
||||||
|
# First we need to send the new message ID to the client
|
||||||
|
if is_continue:
|
||||||
|
self.current_ai_message_id = message_id
|
||||||
|
else:
|
||||||
|
self.current_ai_message_id = self.current_discussion.add_message(
|
||||||
|
self.personality.name,
|
||||||
|
"",
|
||||||
|
message_type = DiscussionsDB.MSG_TYPE_NORMAL_AI,
|
||||||
|
parent = self.current_user_message_id,
|
||||||
|
binding = self.config["binding_name"],
|
||||||
|
model = self.config["model_name"],
|
||||||
|
personality = self.config["personalities"][self.config["active_personality_id"]]
|
||||||
|
) # first the content is empty, but we'll fill it at the end
|
||||||
|
self.socketio.emit('infos',
|
||||||
|
{
|
||||||
|
"status":'generation_started',
|
||||||
|
"type": "input_message_infos",
|
||||||
|
"bot": self.personality.name,
|
||||||
|
"user": self.personality.user_name,
|
||||||
|
"message":message,#markdown.markdown(message),
|
||||||
|
"user_message_id": self.current_user_message_id,
|
||||||
|
"ai_message_id": self.current_ai_message_id,
|
||||||
|
|
||||||
|
'binding': self.current_discussion.current_message_binding,
|
||||||
|
'model': self.current_discussion.current_message_model,
|
||||||
|
'personality': self.current_discussion.current_message_personality,
|
||||||
|
'created_at': self.current_discussion.current_message_created_at,
|
||||||
|
'finished_generating_at': self.current_discussion.current_message_finished_generating_at,
|
||||||
|
}, room=self.current_room_id
|
||||||
|
)
|
||||||
|
self.socketio.sleep(0)
|
||||||
|
|
||||||
|
# prepare query and reception
|
||||||
|
self.discussion_messages, self.current_message = self.prepare_query(message_id, is_continue)
|
||||||
|
self.prepare_reception()
|
||||||
|
self.generating = True
|
||||||
|
self.generate(self.discussion_messages, self.current_message, n_predict = self.config['n_predict'], callback=self.process_chunk)
|
||||||
|
print()
|
||||||
|
print("## Done Generation ##")
|
||||||
|
print()
|
||||||
|
|
||||||
|
self.current_discussion.update_message(self.current_ai_message_id, self.current_generated_text)
|
||||||
|
self.full_message_list.append(self.current_generated_text)
|
||||||
|
self.cancel_gen = False
|
||||||
|
|
||||||
|
# Send final message
|
||||||
|
self.socketio.emit('final', {
|
||||||
|
'data': self.current_generated_text,
|
||||||
|
'ai_message_id':self.current_ai_message_id,
|
||||||
|
'parent':self.current_user_message_id, 'discussion_id':self.current_discussion.discussion_id,
|
||||||
|
"status":'model_not_ready',
|
||||||
|
"type": "input_message_infos",
|
||||||
|
'logo': "",
|
||||||
|
"bot": self.personality.name,
|
||||||
|
"user": self.personality.user_name,
|
||||||
|
"message":self.current_generated_text,
|
||||||
|
"user_message_id": self.current_user_message_id,
|
||||||
|
"ai_message_id": self.current_ai_message_id,
|
||||||
|
|
||||||
|
'binding': self.current_discussion.current_message_binding,
|
||||||
|
'model': self.current_discussion.current_message_model,
|
||||||
|
'personality': self.current_discussion.current_message_personality,
|
||||||
|
'created_at': self.current_discussion.current_message_created_at,
|
||||||
|
'finished_generating_at': self.current_discussion.current_message_finished_generating_at,
|
||||||
|
|
||||||
|
}, room=self.current_room_id
|
||||||
|
)
|
||||||
|
self.socketio.sleep(0)
|
||||||
|
|
||||||
|
ASCIIColors.success(f" ╔══════════════════════════════════════════════════╗ ")
|
||||||
|
ASCIIColors.success(f" ║ Done ║ ")
|
||||||
|
ASCIIColors.success(f" ╚══════════════════════════════════════════════════╝ ")
|
||||||
|
else:
|
||||||
|
self.cancel_gen = False
|
||||||
|
#No discussion available
|
||||||
|
ASCIIColors.warning("No discussion selected!!!")
|
||||||
|
self.socketio.emit('message', {
|
||||||
|
'data': "No discussion selected!!!",
|
||||||
|
'user_message_id':self.current_user_message_id,
|
||||||
|
'ai_message_id':self.current_ai_message_id,
|
||||||
|
'discussion_id':0,
|
||||||
|
'message_type': MSG_TYPE.MSG_TYPE_EXCEPTION.value
|
||||||
|
}, room=self.current_room_id
|
||||||
|
)
|
||||||
|
print()
|
||||||
|
return ""
|
||||||
|
|
||||||
@ -1,9 +1,9 @@
|
|||||||
######
|
######
|
||||||
# Project : GPT4ALL-UI
|
# Project : lollms-webui
|
||||||
# File : config.py
|
# File : config.py
|
||||||
# Author : ParisNeo with the help of the community
|
# Author : ParisNeo with the help of the community
|
||||||
# Supported by Nomic-AI
|
# Supported by Nomic-AI
|
||||||
# Licence : Apache 2.0
|
# license : Apache 2.0
|
||||||
# Description :
|
# Description :
|
||||||
# A front end Flask application for llamacpp models.
|
# A front end Flask application for llamacpp models.
|
||||||
# The official GPT4All Web ui
|
# The official GPT4All Web ui
|
||||||
@ -12,13 +12,14 @@
|
|||||||
import yaml
|
import yaml
|
||||||
|
|
||||||
__author__ = "parisneo"
|
__author__ = "parisneo"
|
||||||
__github__ = "https://github.com/nomic-ai/gpt4all-ui"
|
__github__ = "https://github.com/ParisNeo/lollms-webui"
|
||||||
__copyright__ = "Copyright 2023, "
|
__copyright__ = "Copyright 2023, "
|
||||||
__license__ = "Apache 2.0"
|
__license__ = "Apache 2.0"
|
||||||
|
|
||||||
def load_config(file_path):
|
def load_config(file_path):
|
||||||
with open(file_path, 'r', encoding='utf-8') as stream:
|
with open(file_path, 'r', encoding='utf-8') as stream:
|
||||||
config = yaml.safe_load(stream)
|
config = yaml.safe_load(stream)
|
||||||
|
|
||||||
return config
|
return config
|
||||||
|
|
||||||
|
|
||||||
460
api/db.py
Normal file
@ -0,0 +1,460 @@
|
|||||||
|
|
||||||
|
import sqlite3
|
||||||
|
from pathlib import Path
|
||||||
|
from datetime import datetime
|
||||||
|
from lollms.helpers import ASCIIColors
|
||||||
|
|
||||||
|
__author__ = "parisneo"
|
||||||
|
__github__ = "https://github.com/ParisNeo/lollms-webui"
|
||||||
|
__copyright__ = "Copyright 2023, "
|
||||||
|
__license__ = "Apache 2.0"
|
||||||
|
|
||||||
|
|
||||||
|
# =================================== Database ==================================================================
|
||||||
|
class DiscussionsDB:
|
||||||
|
MSG_TYPE_NORMAL_USER = 0 # A normal message from user
|
||||||
|
MSG_TYPE_NORMAL_AI = 1 # A normal message from ai
|
||||||
|
|
||||||
|
MSG_TYPE_CONDITIONNING = 2 # This is the AI conditionning (to be protected from window sliding)
|
||||||
|
MSG_TYPE_HIDDEN = 3 # Don't show this to user
|
||||||
|
MSG_TYPE_USER_ONLY = 4 # Don't give this to the AI
|
||||||
|
|
||||||
|
def __init__(self, db_path="database.db"):
|
||||||
|
self.db_path = Path(db_path)
|
||||||
|
self.db_path .parent.mkdir(exist_ok=True, parents= True)
|
||||||
|
|
||||||
|
|
||||||
|
def create_tables(self):
|
||||||
|
db_version = 7
|
||||||
|
with sqlite3.connect(self.db_path) as conn:
|
||||||
|
cursor = conn.cursor()
|
||||||
|
|
||||||
|
cursor.execute("""
|
||||||
|
CREATE TABLE IF NOT EXISTS schema_version (
|
||||||
|
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
||||||
|
version INTEGER NOT NULL
|
||||||
|
)
|
||||||
|
""")
|
||||||
|
|
||||||
|
cursor.execute("""
|
||||||
|
CREATE TABLE IF NOT EXISTS discussion (
|
||||||
|
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
||||||
|
title TEXT,
|
||||||
|
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
|
||||||
|
)
|
||||||
|
""")
|
||||||
|
|
||||||
|
cursor.execute("""
|
||||||
|
CREATE TABLE IF NOT EXISTS message (
|
||||||
|
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
||||||
|
binding TEXT,
|
||||||
|
model TEXT,
|
||||||
|
personality TEXT,
|
||||||
|
sender TEXT NOT NULL,
|
||||||
|
content TEXT NOT NULL,
|
||||||
|
type INT NOT NULL,
|
||||||
|
rank INT NOT NULL,
|
||||||
|
parent INT,
|
||||||
|
created_at TIMESTAMP,
|
||||||
|
finished_generating_at TIMESTAMP,
|
||||||
|
discussion_id INTEGER NOT NULL,
|
||||||
|
metadata JSON,
|
||||||
|
FOREIGN KEY (discussion_id) REFERENCES discussion(id),
|
||||||
|
FOREIGN KEY (parent) REFERENCES message(id)
|
||||||
|
)
|
||||||
|
""")
|
||||||
|
|
||||||
|
cursor.execute("SELECT * FROM schema_version")
|
||||||
|
row = cursor.fetchone()
|
||||||
|
|
||||||
|
if row is None:
|
||||||
|
cursor.execute("INSERT INTO schema_version (version) VALUES (?)", (db_version,))
|
||||||
|
else:
|
||||||
|
cursor.execute("UPDATE schema_version SET version = ?", (db_version,))
|
||||||
|
|
||||||
|
conn.commit()
|
||||||
|
|
||||||
|
def add_missing_columns(self):
|
||||||
|
with sqlite3.connect(self.db_path) as conn:
|
||||||
|
cursor = conn.cursor()
|
||||||
|
|
||||||
|
table_columns = {
|
||||||
|
'discussion': [
|
||||||
|
'id',
|
||||||
|
'title',
|
||||||
|
'created_at'
|
||||||
|
],
|
||||||
|
'message': [
|
||||||
|
'id',
|
||||||
|
'binding',
|
||||||
|
'model',
|
||||||
|
'personality',
|
||||||
|
'sender',
|
||||||
|
'content',
|
||||||
|
'type',
|
||||||
|
'rank',
|
||||||
|
'parent',
|
||||||
|
'created_at',
|
||||||
|
'metadata',
|
||||||
|
'finished_generating_at',
|
||||||
|
'discussion_id'
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
||||||
|
for table, columns in table_columns.items():
|
||||||
|
cursor.execute(f"PRAGMA table_info({table})")
|
||||||
|
existing_columns = [column[1] for column in cursor.fetchall()]
|
||||||
|
|
||||||
|
for column in columns:
|
||||||
|
if column not in existing_columns:
|
||||||
|
if column == 'id':
|
||||||
|
cursor.execute(f"ALTER TABLE {table} ADD COLUMN {column} INTEGER PRIMARY KEY AUTOINCREMENT")
|
||||||
|
elif column.endswith('_at'):
|
||||||
|
cursor.execute(f"ALTER TABLE {table} ADD COLUMN {column} TIMESTAMP")
|
||||||
|
elif column=='metadata':
|
||||||
|
cursor.execute(f"ALTER TABLE {table} ADD COLUMN {column} JSON")
|
||||||
|
else:
|
||||||
|
cursor.execute(f"ALTER TABLE {table} ADD COLUMN {column} TEXT")
|
||||||
|
ASCIIColors.yellow(f"Added column :{column}")
|
||||||
|
conn.commit()
|
||||||
|
|
||||||
|
|
||||||
|
def select(self, query, params=None, fetch_all=True):
|
||||||
|
"""
|
||||||
|
Execute the specified SQL select query on the database,
|
||||||
|
with optional parameters.
|
||||||
|
Returns the cursor object for further processing.
|
||||||
|
"""
|
||||||
|
with sqlite3.connect(self.db_path) as conn:
|
||||||
|
if params is None:
|
||||||
|
cursor = conn.execute(query)
|
||||||
|
else:
|
||||||
|
cursor = conn.execute(query, params)
|
||||||
|
if fetch_all:
|
||||||
|
return cursor.fetchall()
|
||||||
|
else:
|
||||||
|
return cursor.fetchone()
|
||||||
|
|
||||||
|
|
||||||
|
def delete(self, query, params=None):
|
||||||
|
"""
|
||||||
|
Execute the specified SQL delete query on the database,
|
||||||
|
with optional parameters.
|
||||||
|
Returns the cursor object for further processing.
|
||||||
|
"""
|
||||||
|
with sqlite3.connect(self.db_path) as conn:
|
||||||
|
cursor = conn.cursor()
|
||||||
|
if params is None:
|
||||||
|
cursor.execute(query)
|
||||||
|
else:
|
||||||
|
cursor.execute(query, params)
|
||||||
|
conn.commit()
|
||||||
|
|
||||||
|
def insert(self, query, params=None):
|
||||||
|
"""
|
||||||
|
Execute the specified INSERT SQL query on the database,
|
||||||
|
with optional parameters.
|
||||||
|
Returns the ID of the newly inserted row.
|
||||||
|
"""
|
||||||
|
|
||||||
|
with sqlite3.connect(self.db_path) as conn:
|
||||||
|
cursor = conn.execute(query, params)
|
||||||
|
rowid = cursor.lastrowid
|
||||||
|
conn.commit()
|
||||||
|
self.conn = None
|
||||||
|
return rowid
|
||||||
|
|
||||||
|
def update(self, query, params=None):
|
||||||
|
"""
|
||||||
|
Execute the specified Update SQL query on the database,
|
||||||
|
with optional parameters.
|
||||||
|
Returns the ID of the newly inserted row.
|
||||||
|
"""
|
||||||
|
|
||||||
|
with sqlite3.connect(self.db_path) as conn:
|
||||||
|
conn.execute(query, params)
|
||||||
|
conn.commit()
|
||||||
|
|
||||||
|
def load_last_discussion(self):
|
||||||
|
last_discussion_id = self.select("SELECT id FROM discussion ORDER BY id DESC LIMIT 1", fetch_all=False)
|
||||||
|
if last_discussion_id is None:
|
||||||
|
last_discussion = self.create_discussion()
|
||||||
|
last_discussion_id = last_discussion.discussion_id
|
||||||
|
else:
|
||||||
|
last_discussion_id = last_discussion_id[0]
|
||||||
|
self.current_message_id = self.select("SELECT id FROM message WHERE discussion_id=? ORDER BY id DESC LIMIT 1", (last_discussion_id,), fetch_all=False)
|
||||||
|
return Discussion(last_discussion_id, self)
|
||||||
|
|
||||||
|
def create_discussion(self, title="untitled"):
|
||||||
|
"""Creates a new discussion
|
||||||
|
|
||||||
|
Args:
|
||||||
|
title (str, optional): The title of the discussion. Defaults to "untitled".
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Discussion: A Discussion instance
|
||||||
|
"""
|
||||||
|
discussion_id = self.insert(f"INSERT INTO discussion (title) VALUES (?)",(title,))
|
||||||
|
return Discussion(discussion_id, self)
|
||||||
|
|
||||||
|
def build_discussion(self, discussion_id=0):
|
||||||
|
return Discussion(discussion_id, self)
|
||||||
|
|
||||||
|
def get_discussions(self):
|
||||||
|
rows = self.select("SELECT * FROM discussion")
|
||||||
|
return [{"id": row[0], "title": row[1]} for row in rows]
|
||||||
|
|
||||||
|
def does_last_discussion_have_messages(self):
|
||||||
|
last_discussion_id = self.select("SELECT id FROM discussion ORDER BY id DESC LIMIT 1", fetch_all=False)
|
||||||
|
if last_discussion_id is None:
|
||||||
|
last_discussion = self.create_discussion()
|
||||||
|
last_discussion_id = last_discussion.discussion_id
|
||||||
|
else:
|
||||||
|
last_discussion_id = last_discussion_id[0]
|
||||||
|
last_message = self.select("SELECT * FROM message WHERE discussion_id=?", (last_discussion_id,), fetch_all=False)
|
||||||
|
return last_message is not None
|
||||||
|
|
||||||
|
def remove_discussions(self):
|
||||||
|
self.delete("DELETE FROM message")
|
||||||
|
self.delete("DELETE FROM discussion")
|
||||||
|
|
||||||
|
|
||||||
|
def export_to_json(self):
|
||||||
|
db_discussions = self.select("SELECT * FROM discussion")
|
||||||
|
discussions = []
|
||||||
|
for row in db_discussions:
|
||||||
|
discussion_id = row[0]
|
||||||
|
discussion_title = row[1]
|
||||||
|
discussion = {"id": discussion_id, "title":discussion_title, "messages": []}
|
||||||
|
rows = self.select(f"SELECT sender, content, message_type, rank, parent, binding, model, personality, created_at, finished_generating_at FROM message WHERE discussion_id=?",(discussion_id,))
|
||||||
|
for message_row in rows:
|
||||||
|
sender = message_row[1]
|
||||||
|
content = message_row[2]
|
||||||
|
content_type = message_row[3]
|
||||||
|
rank = message_row[4]
|
||||||
|
parent = message_row[5]
|
||||||
|
binding = message_row[6]
|
||||||
|
model = message_row[7]
|
||||||
|
personality = message_row[8]
|
||||||
|
created_at = message_row[9]
|
||||||
|
finished_generating_at = message_row[10]
|
||||||
|
|
||||||
|
discussion["messages"].append(
|
||||||
|
{"sender": sender, "content": content, "type": content_type, "rank": rank, "parent": parent, "binding": binding, "model":model, "personality":personality, "created_at":created_at, "finished_generating_at":finished_generating_at}
|
||||||
|
)
|
||||||
|
discussions.append(discussion)
|
||||||
|
return discussions
|
||||||
|
|
||||||
|
def export_discussions_to_json(self, discussions_ids:list):
|
||||||
|
# Convert the list of discussion IDs to a tuple
|
||||||
|
discussions_ids_tuple = tuple(discussions_ids)
|
||||||
|
txt = ','.join(['?'] * len(discussions_ids_tuple))
|
||||||
|
db_discussions = self.select(
|
||||||
|
f"SELECT * FROM discussion WHERE id IN ({txt})",
|
||||||
|
discussions_ids_tuple
|
||||||
|
)
|
||||||
|
discussions = []
|
||||||
|
for row in db_discussions:
|
||||||
|
discussion_id = row[0]
|
||||||
|
discussion_title = row[1]
|
||||||
|
discussion = {"id": discussion_id, "title":discussion_title, "messages": []}
|
||||||
|
rows = self.select(f"SELECT sender, content, message_type, rank, parent, binding, model, personality, created_at, finished_generating_at FROM message WHERE discussion_id=?",(discussion_id,))
|
||||||
|
for message_row in rows:
|
||||||
|
sender = message_row[1]
|
||||||
|
content = message_row[2]
|
||||||
|
content_type = message_row[3]
|
||||||
|
rank = message_row[4]
|
||||||
|
parent = message_row[5]
|
||||||
|
binding = message_row[6]
|
||||||
|
model = message_row[7]
|
||||||
|
personality = message_row[8]
|
||||||
|
created_at = message_row[9]
|
||||||
|
finished_generating_at = message_row[10]
|
||||||
|
|
||||||
|
discussion["messages"].append(
|
||||||
|
{"sender": sender, "content": content, "type": content_type, "rank": rank, "parent": parent, "binding": binding, "model":model, "personality":personality, "created_at":created_at, "finished_generating_at": finished_generating_at}
|
||||||
|
)
|
||||||
|
discussions.append(discussion)
|
||||||
|
return discussions
|
||||||
|
|
||||||
|
def import_from_json(self, json_data):
|
||||||
|
discussions = []
|
||||||
|
data = json_data
|
||||||
|
for discussion_data in data:
|
||||||
|
discussion_id = discussion_data.get("id")
|
||||||
|
discussion_title = discussion_data.get("title")
|
||||||
|
messages_data = discussion_data.get("messages", [])
|
||||||
|
discussion = {"id": discussion_id, "title": discussion_title, "messages": []}
|
||||||
|
|
||||||
|
# Insert discussion into the database
|
||||||
|
discussion_id = self.insert("INSERT INTO discussion (title) VALUES (?)", (discussion_title,))
|
||||||
|
|
||||||
|
for message_data in messages_data:
|
||||||
|
sender = message_data.get("sender")
|
||||||
|
content = message_data.get("content")
|
||||||
|
content_type = message_data.get("type")
|
||||||
|
rank = message_data.get("rank")
|
||||||
|
parent = message_data.get("parent")
|
||||||
|
binding = message_data.get("binding","")
|
||||||
|
model = message_data.get("model","")
|
||||||
|
personality = message_data.get("personality","")
|
||||||
|
created_at = message_data.get("created_at",datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
|
||||||
|
finished_generating_at = message_data.get("finished_generating_at",datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
|
||||||
|
discussion["messages"].append(
|
||||||
|
{"sender": sender, "content": content, "type": content_type, "rank": rank, "binding": binding, "model": model, "personality": personality, "created_at": created_at, "finished_generating_at": finished_generating_at}
|
||||||
|
)
|
||||||
|
|
||||||
|
# Insert message into the database
|
||||||
|
self.insert("INSERT INTO message (sender, content, type, rank, parent, binding, model, personality, created_at, finished_generating_at, discussion_id) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)",
|
||||||
|
(sender, content, content_type, rank, parent, model, personality, created_at, finished_generating_at, discussion_id))
|
||||||
|
|
||||||
|
discussions.append(discussion)
|
||||||
|
|
||||||
|
return discussions
|
||||||
|
|
||||||
|
class Discussion:
|
||||||
|
def __init__(self, discussion_id, discussions_db:DiscussionsDB):
|
||||||
|
self.discussion_id = discussion_id
|
||||||
|
self.discussions_db = discussions_db
|
||||||
|
self.current_message_binding = ""
|
||||||
|
self.current_message_model = ""
|
||||||
|
self.current_message_personality = ""
|
||||||
|
self.current_message_created_at = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
|
||||||
|
self.current_message_finished_generating_at=datetime.now().strftime('%Y-%m-%d %H:%M:%S')
|
||||||
|
|
||||||
|
def add_message(self, sender, content, message_type=0, rank=0, parent=0, binding="", model ="", personality="", created_at=None, finished_generating_at=None):
|
||||||
|
"""Adds a new message to the discussion
|
||||||
|
|
||||||
|
Args:
|
||||||
|
sender (str): The sender name
|
||||||
|
content (str): The text sent by the sender
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
int: The added message id
|
||||||
|
"""
|
||||||
|
if created_at is None:
|
||||||
|
created_at = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
|
||||||
|
|
||||||
|
if finished_generating_at is None:
|
||||||
|
finished_generating_at = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
|
||||||
|
self.current_message_binding = binding
|
||||||
|
self.current_message_model = model
|
||||||
|
self.current_message_personality = personality
|
||||||
|
|
||||||
|
self.current_message_created_at = created_at
|
||||||
|
self.current_message_finished_generating_at = finished_generating_at
|
||||||
|
|
||||||
|
message_id = self.discussions_db.insert(
|
||||||
|
"INSERT INTO message (sender, content, type, rank, parent, binding, model, personality, created_at, finished_generating_at, discussion_id) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)",
|
||||||
|
(sender, content, message_type, rank, parent, binding, model, personality, created_at, finished_generating_at, self.discussion_id)
|
||||||
|
)
|
||||||
|
return message_id
|
||||||
|
|
||||||
|
def rename(self, new_title):
|
||||||
|
"""Renames the discussion
|
||||||
|
|
||||||
|
Args:
|
||||||
|
new_title (str): The nex discussion name
|
||||||
|
"""
|
||||||
|
self.discussions_db.update(
|
||||||
|
f"UPDATE discussion SET title=? WHERE id=?",(new_title,self.discussion_id)
|
||||||
|
)
|
||||||
|
|
||||||
|
def delete_discussion(self):
|
||||||
|
"""Deletes the discussion
|
||||||
|
"""
|
||||||
|
self.discussions_db.delete(
|
||||||
|
f"DELETE FROM message WHERE discussion_id={self.discussion_id}"
|
||||||
|
)
|
||||||
|
self.discussions_db.delete(
|
||||||
|
f"DELETE FROM discussion WHERE id={self.discussion_id}"
|
||||||
|
)
|
||||||
|
|
||||||
|
def get_messages(self):
|
||||||
|
"""Gets a list of messages information
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
list: List of entries in the format {"id":message id, "sender":sender name, "content":message content, "type":message type, "rank": message rank}
|
||||||
|
"""
|
||||||
|
rows = self.discussions_db.select(
|
||||||
|
"SELECT id, sender, content, type, rank, parent, binding, model, personality, created_at, finished_generating_at FROM message WHERE discussion_id=?", (self.discussion_id,)
|
||||||
|
)
|
||||||
|
|
||||||
|
return [{
|
||||||
|
"id": row[0],
|
||||||
|
"sender": row[1],
|
||||||
|
"content": row[2],
|
||||||
|
"type": row[3],
|
||||||
|
"rank": row[4],
|
||||||
|
"parent": row[5],
|
||||||
|
"binding":row[6],
|
||||||
|
"model": row[7],
|
||||||
|
"personality": row[8],
|
||||||
|
"created_at": row[9],
|
||||||
|
"finished_generating_at": row[10]
|
||||||
|
} for row in rows]
|
||||||
|
|
||||||
|
def update_message(self, message_id, new_content):
|
||||||
|
"""Updates the content of a message
|
||||||
|
|
||||||
|
Args:
|
||||||
|
message_id (int): The id of the message to be changed
|
||||||
|
new_content (str): The nex message content
|
||||||
|
"""
|
||||||
|
current_date_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
|
||||||
|
self.current_message_finished_generating_at = current_date_time
|
||||||
|
|
||||||
|
# print(f"{current_date_time}")
|
||||||
|
self.discussions_db.update(
|
||||||
|
f"UPDATE message SET content = ?, finished_generating_at = ? WHERE id = ?",(new_content, current_date_time,message_id)
|
||||||
|
)
|
||||||
|
"""
|
||||||
|
stuff = self.discussions_db.select(
|
||||||
|
f"Select finished_generating_at from message WHERE id = ?",(message_id,)
|
||||||
|
)
|
||||||
|
print(stuff)
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
def message_rank_up(self, message_id):
|
||||||
|
"""Increments the rank of the message
|
||||||
|
|
||||||
|
Args:
|
||||||
|
message_id (int): The id of the message to be changed
|
||||||
|
"""
|
||||||
|
# Retrieve current rank value for message_id
|
||||||
|
current_rank = self.discussions_db.select("SELECT rank FROM message WHERE id=?", (message_id,),False)[0]
|
||||||
|
|
||||||
|
# Increment current rank value by 1
|
||||||
|
new_rank = current_rank + 1
|
||||||
|
self.discussions_db.update(
|
||||||
|
f"UPDATE message SET rank = ? WHERE id = ?",(new_rank,message_id)
|
||||||
|
)
|
||||||
|
return new_rank
|
||||||
|
|
||||||
|
def message_rank_down(self, message_id):
|
||||||
|
"""Increments the rank of the message
|
||||||
|
|
||||||
|
Args:
|
||||||
|
message_id (int): The id of the message to be changed
|
||||||
|
"""
|
||||||
|
# Retrieve current rank value for message_id
|
||||||
|
current_rank = self.discussions_db.select("SELECT rank FROM message WHERE id=?", (message_id,),False)[0]
|
||||||
|
|
||||||
|
# Increment current rank value by 1
|
||||||
|
new_rank = current_rank - 1
|
||||||
|
self.discussions_db.update(
|
||||||
|
f"UPDATE message SET rank = ? WHERE id = ?",(new_rank,message_id)
|
||||||
|
)
|
||||||
|
return new_rank
|
||||||
|
|
||||||
|
def delete_message(self, message_id):
|
||||||
|
"""Delete the message
|
||||||
|
|
||||||
|
Args:
|
||||||
|
message_id (int): The id of the message to be deleted
|
||||||
|
"""
|
||||||
|
# Retrieve current rank value for message_id
|
||||||
|
self.discussions_db.delete("DELETE FROM message WHERE id=?", (message_id,))
|
||||||
|
|
||||||
|
# ========================================================================================================================
|
||||||
11
api/helpers.py
Normal file
@ -0,0 +1,11 @@
|
|||||||
|
|
||||||
|
__author__ = "parisneo"
|
||||||
|
__github__ = "https://github.com/ParisNeo/lollms-webui"
|
||||||
|
__copyright__ = "Copyright 2023, "
|
||||||
|
__license__ = "Apache 2.0"
|
||||||
|
|
||||||
|
def compare_lists(list1, list2):
|
||||||
|
if len(list1) != len(list2):
|
||||||
|
return False
|
||||||
|
else:
|
||||||
|
return list1 == list2
|
||||||
@ -1,79 +0,0 @@
|
|||||||
######
|
|
||||||
# Project : GPT4ALL-UI
|
|
||||||
# File : backend.py
|
|
||||||
# Author : ParisNeo with the help of the community
|
|
||||||
# Supported by Nomic-AI
|
|
||||||
# Licence : Apache 2.0
|
|
||||||
# Description :
|
|
||||||
# This is an interface class for GPT4All-ui backends.
|
|
||||||
######
|
|
||||||
from pathlib import Path
|
|
||||||
from typing import Callable
|
|
||||||
from gpt4allj import Model
|
|
||||||
from pyGpt4All.backend import GPTBackend
|
|
||||||
|
|
||||||
__author__ = "parisneo"
|
|
||||||
__github__ = "https://github.com/nomic-ai/gpt4all-ui"
|
|
||||||
__copyright__ = "Copyright 2023, "
|
|
||||||
__license__ = "Apache 2.0"
|
|
||||||
|
|
||||||
backend_name = "GPT_J"
|
|
||||||
|
|
||||||
|
|
||||||
class GPT_J(GPTBackend):
|
|
||||||
file_extension='*'
|
|
||||||
def __init__(self, config:dict) -> None:
|
|
||||||
"""Builds a GPT-J backend
|
|
||||||
|
|
||||||
Args:
|
|
||||||
config (dict): The configuration file
|
|
||||||
"""
|
|
||||||
super().__init__(config, True)
|
|
||||||
self.config = config
|
|
||||||
if "use_avx2" in self.config and not self.config["use_avx2"]:
|
|
||||||
self.model = Model(
|
|
||||||
model=f"./models/gpt_j/{self.config['model']}", instructions='avx'
|
|
||||||
)
|
|
||||||
else:
|
|
||||||
self.model = Model(
|
|
||||||
model=f"./models/gpt_j/{self.config['model']}"
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
def get_num_tokens(self, prompt):
|
|
||||||
return self.model.num_tokens(prompt)
|
|
||||||
|
|
||||||
def generate(self,
|
|
||||||
prompt:str,
|
|
||||||
n_predict: int = 128,
|
|
||||||
new_text_callback: Callable[[str], None] = bool,
|
|
||||||
verbose: bool = False,
|
|
||||||
**gpt_params ):
|
|
||||||
"""Generates text out of a prompt
|
|
||||||
|
|
||||||
Args:
|
|
||||||
prompt (str): The prompt to use for generation
|
|
||||||
n_predict (int, optional): Number of tokens to prodict. Defaults to 128.
|
|
||||||
new_text_callback (Callable[[str], None], optional): A callback function that is called everytime a new text element is generated. Defaults to None.
|
|
||||||
verbose (bool, optional): If true, the code will spit many informations about the generation process. Defaults to False.
|
|
||||||
"""
|
|
||||||
num_tokens = self.get_num_tokens(prompt)
|
|
||||||
print(f"Prompt has {num_tokens} tokens")
|
|
||||||
try:
|
|
||||||
self.model.generate(
|
|
||||||
prompt,
|
|
||||||
callback=new_text_callback,
|
|
||||||
n_predict=num_tokens + n_predict,
|
|
||||||
seed=self.config['seed'] if self.config['seed']>0 else -1,
|
|
||||||
temp=self.config['temp'],
|
|
||||||
top_k=self.config['top_k'],
|
|
||||||
top_p=self.config['top_p'],
|
|
||||||
# repeat_penalty=self.config['repeat_penalty'],
|
|
||||||
# repeat_last_n = self.config['repeat_last_n'],
|
|
||||||
n_threads=self.config['n_threads'],
|
|
||||||
#verbose=verbose
|
|
||||||
)
|
|
||||||
except Exception as ex:
|
|
||||||
print(ex)
|
|
||||||
#new_text_callback()
|
|
||||||
@ -1,81 +0,0 @@
|
|||||||
######
|
|
||||||
# Project : GPT4ALL-UI
|
|
||||||
# File : backend.py
|
|
||||||
# Author : ParisNeo with the help of the community
|
|
||||||
# Supported by Nomic-AI
|
|
||||||
# Licence : Apache 2.0
|
|
||||||
# Description :
|
|
||||||
# This is an interface class for GPT4All-ui backends.
|
|
||||||
######
|
|
||||||
from pathlib import Path
|
|
||||||
from typing import Callable
|
|
||||||
from transformers import AutoTokenizer
|
|
||||||
from transformers import AutoModelForCausalLM
|
|
||||||
from pyGpt4All.backend import GPTBackend
|
|
||||||
from transformers import AutoTokenizer, pipeline
|
|
||||||
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
|
|
||||||
from auto_gptq.eval_tasks import LanguageModelingTask
|
|
||||||
|
|
||||||
__author__ = "parisneo"
|
|
||||||
__github__ = "https://github.com/nomic-ai/gpt4all-ui"
|
|
||||||
__copyright__ = "Copyright 2023, "
|
|
||||||
__license__ = "Apache 2.0"
|
|
||||||
|
|
||||||
backend_name = "GPT-Q"
|
|
||||||
|
|
||||||
|
|
||||||
class GPT_Q(GPTBackend):
|
|
||||||
file_extension='*'
|
|
||||||
def __init__(self, config:dict) -> None:
|
|
||||||
"""Builds a GPT-J backend
|
|
||||||
|
|
||||||
Args:
|
|
||||||
config (dict): The configuration file
|
|
||||||
"""
|
|
||||||
super().__init__(config, True)
|
|
||||||
self.config = config
|
|
||||||
# path = Path("models/hugging_face")/self.config['model']
|
|
||||||
path = "TheBloke/vicuna-13B-1.1-GPTQ-4bit-128g"
|
|
||||||
AutoGPTQForCausalLM.from_pretrained(path, BaseQuantizeConfig())
|
|
||||||
self.model = AutoModelForCausalLM.from_pretrained(path, low_cpu_mem_usage=True)
|
|
||||||
self.tokenizer = AutoTokenizer.from_pretrained(path)
|
|
||||||
|
|
||||||
self.generator = pipeline(
|
|
||||||
"text-generation",
|
|
||||||
model=self.model,
|
|
||||||
tokenizer=self.tokenizer,
|
|
||||||
device=0, # Use GPU if available
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
def generate(self,
|
|
||||||
prompt:str,
|
|
||||||
n_predict: int = 128,
|
|
||||||
new_text_callback: Callable[[str], None] = bool,
|
|
||||||
verbose: bool = False,
|
|
||||||
**gpt_params ):
|
|
||||||
"""Generates text out of a prompt
|
|
||||||
|
|
||||||
Args:
|
|
||||||
prompt (str): The prompt to use for generation
|
|
||||||
n_predict (int, optional): Number of tokens to prodict. Defaults to 128.
|
|
||||||
new_text_callback (Callable[[str], None], optional): A callback function that is called everytime a new text element is generated. Defaults to None.
|
|
||||||
verbose (bool, optional): If true, the code will spit many informations about the generation process. Defaults to False.
|
|
||||||
"""
|
|
||||||
|
|
||||||
inputs = self.tokenizer(prompt, return_tensors="pt").input_ids
|
|
||||||
while len(inputs<n_predict):
|
|
||||||
outputs = self.model.generate(
|
|
||||||
inputs,
|
|
||||||
max_new_tokens=1,
|
|
||||||
#new_text_callback=new_text_callback,
|
|
||||||
temp=self.config['temp'],
|
|
||||||
top_k=self.config['top_k'],
|
|
||||||
top_p=self.config['top_p'],
|
|
||||||
repeat_penalty=self.config['repeat_penalty'],
|
|
||||||
repeat_last_n = self.config['repeat_last_n'],
|
|
||||||
n_threads=self.config['n_threads'],
|
|
||||||
verbose=verbose
|
|
||||||
)
|
|
||||||
inputs += outputs
|
|
||||||
new_text_callback(self.tokenizer.batch_decode(outputs, skip_special_tokens=True))
|
|
||||||
@ -1,82 +0,0 @@
|
|||||||
######
|
|
||||||
# Project : GPT4ALL-UI
|
|
||||||
# File : backend.py
|
|
||||||
# Author : ParisNeo with the help of the community
|
|
||||||
# Supported by Nomic-AI
|
|
||||||
# Licence : Apache 2.0
|
|
||||||
# Description :
|
|
||||||
# This is an interface class for GPT4All-ui backends.
|
|
||||||
######
|
|
||||||
from pathlib import Path
|
|
||||||
from typing import Callable
|
|
||||||
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
|
|
||||||
from pyGpt4All.backend import GPTBackend
|
|
||||||
import torch
|
|
||||||
import time
|
|
||||||
__author__ = "parisneo"
|
|
||||||
__github__ = "https://github.com/nomic-ai/gpt4all-ui"
|
|
||||||
__copyright__ = "Copyright 2023, "
|
|
||||||
__license__ = "Apache 2.0"
|
|
||||||
|
|
||||||
backend_name = "HuggingFace"
|
|
||||||
|
|
||||||
|
|
||||||
class HuggingFace(GPTBackend):
|
|
||||||
file_extension='*'
|
|
||||||
def __init__(self, config:dict) -> None:
|
|
||||||
"""Builds a Hugging face backend
|
|
||||||
|
|
||||||
Args:
|
|
||||||
config (dict): The configuration file
|
|
||||||
"""
|
|
||||||
super().__init__(config, True)
|
|
||||||
self.config = config
|
|
||||||
path = self.config['model']
|
|
||||||
|
|
||||||
self.model = AutoModelForCausalLM.from_pretrained(Path("models/hugging_face")/path, low_cpu_mem_usage=True)
|
|
||||||
self.tokenizer = AutoTokenizer.from_pretrained(Path("models/hugging_face")/path)
|
|
||||||
|
|
||||||
self.generator = pipeline(
|
|
||||||
"text-generation",
|
|
||||||
model=self.model,
|
|
||||||
tokenizer=self.tokenizer,
|
|
||||||
device=0, # Use GPU if available
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
def generate_callback(self, text, new_text_callback):
|
|
||||||
def callback(outputs):
|
|
||||||
generated_text = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
|
|
||||||
new_text_callback(generated_text)
|
|
||||||
print(text + generated_text, end="\r")
|
|
||||||
time.sleep(0.5)
|
|
||||||
return callback
|
|
||||||
|
|
||||||
def generate(self,
|
|
||||||
prompt:str,
|
|
||||||
n_predict: int = 128,
|
|
||||||
new_text_callback: Callable[[str], None] = bool,
|
|
||||||
verbose: bool = False,
|
|
||||||
**gpt_params ):
|
|
||||||
"""Generates text out of a prompt
|
|
||||||
|
|
||||||
Args:
|
|
||||||
prompt (str): The prompt to use for generation
|
|
||||||
n_predict (int, optional): Number of tokens to prodict. Defaults to 128.
|
|
||||||
new_text_callback (Callable[[str], None], optional): A callback function that is called everytime a new text element is generated. Defaults to None.
|
|
||||||
verbose (bool, optional): If true, the code will spit many informations about the generation process. Defaults to False.
|
|
||||||
"""
|
|
||||||
callback = self.generate_callback(prompt, new_text_callback)
|
|
||||||
outputs = self.generator(
|
|
||||||
prompt,
|
|
||||||
max_length=100,
|
|
||||||
do_sample=True,
|
|
||||||
num_beams=5,
|
|
||||||
temperature=self.config['temp'],
|
|
||||||
top_k=self.config['top_k'],
|
|
||||||
top_p=self.config['top_p'],
|
|
||||||
repetition_penalty=self.config['repeat_penalty'],
|
|
||||||
repeat_last_n = self.config['repeat_last_n'],
|
|
||||||
callback=callback
|
|
||||||
)
|
|
||||||
print(outputs)
|
|
||||||
@ -1,67 +0,0 @@
|
|||||||
######
|
|
||||||
# Project : GPT4ALL-UI
|
|
||||||
# File : backend.py
|
|
||||||
# Author : ParisNeo with the help of the community
|
|
||||||
# Supported by Nomic-AI
|
|
||||||
# Licence : Apache 2.0
|
|
||||||
# Description :
|
|
||||||
# This is an interface class for GPT4All-ui backends.
|
|
||||||
######
|
|
||||||
from pathlib import Path
|
|
||||||
from typing import Callable
|
|
||||||
from pyllamacpp.model import Model
|
|
||||||
from pyGpt4All.backend import GPTBackend
|
|
||||||
|
|
||||||
__author__ = "parisneo"
|
|
||||||
__github__ = "https://github.com/nomic-ai/gpt4all-ui"
|
|
||||||
__copyright__ = "Copyright 2023, "
|
|
||||||
__license__ = "Apache 2.0"
|
|
||||||
|
|
||||||
backend_name = "LLAMACPP"
|
|
||||||
|
|
||||||
class LLAMACPP(GPTBackend):
|
|
||||||
file_extension='*.bin'
|
|
||||||
def __init__(self, config:dict) -> None:
|
|
||||||
"""Builds a LLAMACPP backend
|
|
||||||
|
|
||||||
Args:
|
|
||||||
config (dict): The configuration file
|
|
||||||
"""
|
|
||||||
super().__init__(config, False)
|
|
||||||
|
|
||||||
self.model = Model(
|
|
||||||
ggml_model=f"./models/llama_cpp/{self.config['model']}",
|
|
||||||
n_ctx=self.config['ctx_size'],
|
|
||||||
seed=self.config['seed'],
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
def generate(self,
|
|
||||||
prompt:str,
|
|
||||||
n_predict: int = 128,
|
|
||||||
new_text_callback: Callable[[str], None] = bool,
|
|
||||||
verbose: bool = False,
|
|
||||||
**gpt_params ):
|
|
||||||
"""Generates text out of a prompt
|
|
||||||
|
|
||||||
Args:
|
|
||||||
prompt (str): The prompt to use for generation
|
|
||||||
n_predict (int, optional): Number of tokens to prodict. Defaults to 128.
|
|
||||||
new_text_callback (Callable[[str], None], optional): A callback function that is called everytime a new text element is generated. Defaults to None.
|
|
||||||
verbose (bool, optional): If true, the code will spit many informations about the generation process. Defaults to False.
|
|
||||||
"""
|
|
||||||
try:
|
|
||||||
self.model.generate(
|
|
||||||
prompt,
|
|
||||||
new_text_callback=new_text_callback,
|
|
||||||
n_predict=n_predict,
|
|
||||||
temp=self.config['temp'],
|
|
||||||
top_k=self.config['top_k'],
|
|
||||||
top_p=self.config['top_p'],
|
|
||||||
repeat_penalty=self.config['repeat_penalty'],
|
|
||||||
repeat_last_n = self.config['repeat_last_n'],
|
|
||||||
n_threads=self.config['n_threads'],
|
|
||||||
verbose=verbose
|
|
||||||
)
|
|
||||||
except Exception as ex:
|
|
||||||
print(ex)
|
|
||||||
182
c_webui.bat
Normal file
@ -0,0 +1,182 @@
|
|||||||
|
@echo off
|
||||||
|
set environment_path=%cd%/lollms-webui/env
|
||||||
|
|
||||||
|
|
||||||
|
echo "\u001b[34m"
|
||||||
|
echo HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHH .HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHH. ,HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHH.## HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHHH#.HHHHH/*,*,*,*,*,*,*,*,***,*,**#HHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHHHHH.*,,***,***,***,***,***,***,*******HHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHHH*,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,*,,,,,HHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHH.,,,***,***,***,***,***,***,***,***,***,***/HHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHH*,,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*HHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHH#,***,***,***,***,***,***,***,***,***,***,***,**HHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHH..HHH,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,*#HHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHH,,,**,/H*,***,***,***,,,*,***,***,***,**,,,**,***,***,***H,,*,***HHHHHHHH
|
||||||
|
echo HHHHHH.*,,,*,,,,,*,*,*,***#HHHHH.,,*,*,*,*,**/HHHHH.,*,*,*,*,*,*,*,*****HHHHHHHH
|
||||||
|
echo HHHHHH.*,***,*,*,***,***,.HHHHHHH/**,***,****HHHHHHH.***,***,***,*******HHHHHHHH
|
||||||
|
echo HHHHHH.,,,,,,,,,,,,,,,,,,,.HHHHH.,,,,,,,,,,,,.HHHHHH,,,,,,,,,,,,,,,,,***HHHHHHHH
|
||||||
|
echo HHHHHH.,,,,,,/H,,,**,***,***,,,*,***,***,***,**,,,,*,***,***,***H***,***HHHHHHHH
|
||||||
|
echo HHHHHHH.,,,,*.H,,,,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,***H*,,,,/HHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHH*,***,***,**,,***,***,***,***,***,***,***,***,**.HHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHH,,,,,,,,*,,#H#,,,,,*,,,*,,,,,,,,*#H*,,,,,,,,,**HHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHH,,*,***,***,**/.HHHHHHHHHHHHH#*,,,*,***,***,*HHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHH,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*HHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHH**,***,***,***,***,***,***,***,***,***,***,*.HHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHH*,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,*HHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHH**,***,***,*******/..HHHHHHHHH.#/*,*,,,***,***HHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHH*,*,*,******#HHHHHHHHHHHHHHHHHHHHHHHHHHHH./**,,,.HHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHH.,,*,***.HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH.*#HHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHH/,,,*.HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHH,,#HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHH.HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
|
||||||
|
echo \u001b[0m
|
||||||
|
|
||||||
|
echo Testing internet connection
|
||||||
|
ping -n 1 google.com >nul
|
||||||
|
if %errorlevel% equ 0 (
|
||||||
|
echo Internet Connection working fine
|
||||||
|
|
||||||
|
REM Install Git
|
||||||
|
echo Checking for Git...
|
||||||
|
where git >nul 2>nul
|
||||||
|
if %errorlevel% equ 0 (
|
||||||
|
echo Git is installed
|
||||||
|
) else (
|
||||||
|
set /p choice=Git is not installed. Would you like to install Git? [Y/N]
|
||||||
|
if /i "%choice%"=="Y" (
|
||||||
|
echo Installing Git...
|
||||||
|
REM Replace the following two lines with appropriate Git installation commands for Windows
|
||||||
|
echo Please install Git and try again.
|
||||||
|
exit /b 1
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
REM Check if repository exists
|
||||||
|
if exist .git (
|
||||||
|
echo Pulling latest changes
|
||||||
|
git pull
|
||||||
|
) else (
|
||||||
|
if exist lollms-webui (
|
||||||
|
cd ./lollms-webui
|
||||||
|
) else (
|
||||||
|
echo Cloning repository...
|
||||||
|
git clone https://github.com/ParisNeo/lollms-webui.git ./lollms-webui
|
||||||
|
cd ./lollms-webui
|
||||||
|
echo Cloned successfully
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
echo Pulling latest version...
|
||||||
|
git pull
|
||||||
|
|
||||||
|
REM Install Conda
|
||||||
|
echo Checking for Conda...
|
||||||
|
where conda >nul 2>nul
|
||||||
|
if %errorlevel% equ 0 (
|
||||||
|
echo Conda is installed
|
||||||
|
) else (
|
||||||
|
set /p choice="Conda is not installed. Would you like to install Conda? [Y/N]:"
|
||||||
|
if /i "%choice%"=="Y" (
|
||||||
|
echo Installing Conda...
|
||||||
|
set "miniconda_installer_url=https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe"
|
||||||
|
set "miniconda_installer=miniconda_installer_filename.exe"
|
||||||
|
rem Download the Miniconda installer using curl.
|
||||||
|
curl -o "%miniconda_installer%" "%miniconda_installer_url%"
|
||||||
|
if exist "%miniconda_installer%" (
|
||||||
|
echo Miniconda installer downloaded successfully.
|
||||||
|
echo Installing Miniconda...
|
||||||
|
echo.
|
||||||
|
|
||||||
|
rem Run the Miniconda installer.
|
||||||
|
"%miniconda_installer%" /InstallationType=JustMe /AddToPath=yes /RegisterPython=0 /S /D="%USERPROFILE%\Miniconda"
|
||||||
|
|
||||||
|
if %errorlevel% equ 0 (
|
||||||
|
echo Miniconda has been installed successfully in "%USERPROFILE%\Miniconda".
|
||||||
|
) else (
|
||||||
|
echo Failed to install Miniconda.
|
||||||
|
)
|
||||||
|
|
||||||
|
rem Clean up the Miniconda installer file.
|
||||||
|
del "%miniconda_installer%"
|
||||||
|
|
||||||
|
rem Activate Miniconda.
|
||||||
|
call "%USERPROFILE%\Miniconda\Scripts\activate"
|
||||||
|
|
||||||
|
) else (
|
||||||
|
echo Failed to download the Miniconda installer.
|
||||||
|
exit /b 1
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
echo Deactivating any activated environment
|
||||||
|
conda deactivate
|
||||||
|
|
||||||
|
echo checking %environment_path% existance
|
||||||
|
|
||||||
|
rem Check the error level to determine if the file exists
|
||||||
|
if not exist "%environment_path%" (
|
||||||
|
REM Create a new Conda environment
|
||||||
|
echo Creating Conda environment...
|
||||||
|
conda create --prefix ./env python=3.10
|
||||||
|
conda activate ./env
|
||||||
|
pip install --upgrade pip setuptools wheel
|
||||||
|
conda install -c conda-forge cudatoolkit-dev
|
||||||
|
) else (
|
||||||
|
echo Environment already exists. Skipping environment creation.
|
||||||
|
conda activate ./env
|
||||||
|
)
|
||||||
|
|
||||||
|
echo Activating environment
|
||||||
|
conda activate ./env
|
||||||
|
echo Conda environment is created
|
||||||
|
REM Install the required packages
|
||||||
|
echo Installing requirements using pip...
|
||||||
|
pip install -r requirements.txt
|
||||||
|
|
||||||
|
if %errorlevel% neq 0 (
|
||||||
|
echo Failed to install required packages. Please check your internet connection and try again.
|
||||||
|
exit /b 1
|
||||||
|
)
|
||||||
|
|
||||||
|
echo Cleanup
|
||||||
|
REM Cleanup
|
||||||
|
if exist "./tmp" (
|
||||||
|
echo Cleaning tmp folder
|
||||||
|
rmdir /s /q "./tmp"
|
||||||
|
echo Done
|
||||||
|
)
|
||||||
|
echo Ready
|
||||||
|
echo launching app
|
||||||
|
REM Launch the Python application
|
||||||
|
python app.py %*
|
||||||
|
set app_result=%errorlevel%
|
||||||
|
|
||||||
|
pause >nul
|
||||||
|
exit /b 0
|
||||||
|
|
||||||
|
) else (
|
||||||
|
REM Go to webui folder
|
||||||
|
cd lollms-webui
|
||||||
|
|
||||||
|
REM Activate environment
|
||||||
|
conda activate ./env
|
||||||
|
|
||||||
|
echo launching app
|
||||||
|
REM Launch the Python application
|
||||||
|
python app.py %*
|
||||||
|
set app_result=%errorlevel%
|
||||||
|
|
||||||
|
pause >nul
|
||||||
|
exit /b 0
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
124
c_webui.sh
Normal file
@ -0,0 +1,124 @@
|
|||||||
|
#!/usr/bin/env bash
|
||||||
|
echo "\u001b[34m"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHH .HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHH. ,HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHH.## HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHHH#.HHHHH_*,*,*,*,*,*,*,*,***,*,**#HHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHHHHH.*,,***,***,***,***,***,***,*******HHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHHH*,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,*,,,,,HHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHH.,,,***,***,***,***,***,***,***,***,***,***_HHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHH*,,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*HHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHH#,***,***,***,***,***,***,***,***,***,***,***,**HHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHH..HHH,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,*#HHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHH,,,**,_H*,***,***,***,,,*,***,***,***,**,,,**,***,***,***H,,*,***HHHHHHHH"
|
||||||
|
echo "HHHHHH.*,,,*,,,,,*,*,*,***#HHHHH.,,*,*,*,*,**_HHHHH.,*,*,*,*,*,*,*,*****HHHHHHHH"
|
||||||
|
echo "HHHHHH.*,***,*,*,***,***,.HHHHHHH_**,***,****HHHHHHH.***,***,***,*******HHHHHHHH"
|
||||||
|
echo "HHHHHH.,,,,,,,,,,,,,,,,,,,.HHHHH.,,,,,,,,,,,,.HHHHHH,,,,,,,,,,,,,,,,,***HHHHHHHH"
|
||||||
|
echo "HHHHHH.,,,,,,_H,,,**,***,***,,,*,***,***,***,**,,,,*,***,***,***H***,***HHHHHHHH"
|
||||||
|
echo "HHHHHHH.,,,,*.H,,,,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,***H*,,,,_HHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHH*,***,***,**,,***,***,***,***,***,***,***,***,**.HHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHH,,,,,,,,*,,#H#,,,,,*,,,*,,,,,,,,*#H*,,,,,,,,,**HHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHH,,*,***,***,**_.HHHHHHHHHHHHH#*,,,*,***,***,*HHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHH,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*HHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHH**,***,***,***,***,***,***,***,***,***,***,*.HHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHH*,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,*HHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHH**,***,***,*******_..HHHHHHHHH.#_*,*,,,***,***HHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHH*,*,*,******#HHHHHHHHHHHHHHHHHHHHHHHHHHHH._**,,,.HHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHH.,,*,***.HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH.*#HHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHH_,,,*.HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHH,,#HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHH.HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH"
|
||||||
|
echo "\u001b[0m"
|
||||||
|
|
||||||
|
if ping -q -c 1 google.com >/dev/null 2>&1; then
|
||||||
|
echo -e "\e[32mInternet Connection working fine\e[0m"
|
||||||
|
|
||||||
|
# Install Git
|
||||||
|
echo -n "Checking for Git..."
|
||||||
|
if command -v git > /dev/null 2>&1; then
|
||||||
|
echo "is installed"
|
||||||
|
else
|
||||||
|
read -p "Git is not installed. Would you like to install Git? [Y/N] " choice
|
||||||
|
if [ "$choice" = "Y" ] || [ "$choice" = "y" ]; then
|
||||||
|
echo "Installing Git..."
|
||||||
|
sudo apt update
|
||||||
|
sudo apt install -y git
|
||||||
|
else
|
||||||
|
echo "Please install Git and try again."
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
|
||||||
|
# Check if repository exists
|
||||||
|
if [[ -d .git ]] ;then
|
||||||
|
echo "Pulling latest changes"
|
||||||
|
git pull
|
||||||
|
else
|
||||||
|
if [[ -d lollms-webui ]] ;then
|
||||||
|
cd lollms-webui
|
||||||
|
else
|
||||||
|
echo "Cloning repository..."
|
||||||
|
git clone https://github.com/ParisNeo/lollms-webui.git ./lollms-webui
|
||||||
|
cd lollms-webui
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
echo "Pulling latest version..."
|
||||||
|
git pull
|
||||||
|
|
||||||
|
# Install Conda
|
||||||
|
echo -n "Checking for Conda..."
|
||||||
|
if command -v conda > /dev/null 2>&1; then
|
||||||
|
echo "is installed"
|
||||||
|
else
|
||||||
|
read -p "Conda is not installed. Would you like to install Conda? [Y/N] " choice
|
||||||
|
if [ "$choice" = "Y" ] || [ "$choice" = "y" ]; then
|
||||||
|
echo "Installing Conda..."
|
||||||
|
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
|
||||||
|
bash Miniconda3-latest-Linux-x86_64.sh -b -p $HOME/miniconda
|
||||||
|
source $HOME/miniconda/bin/activate
|
||||||
|
conda init bash
|
||||||
|
conda update -n base -c defaults conda
|
||||||
|
else
|
||||||
|
echo "Please install Conda and try again."
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
|
||||||
|
# Create a new Conda environment
|
||||||
|
echo -n "Creating Conda environment..."
|
||||||
|
conda create --prefix ./env python=3.10
|
||||||
|
conda activate ./env
|
||||||
|
echo "is created"
|
||||||
|
|
||||||
|
# Install the required packages
|
||||||
|
echo "Installing requirements..."
|
||||||
|
conda install -c gcc
|
||||||
|
conda install -c conda-forge cudatoolkit-dev
|
||||||
|
pip install --upgrade pip setuptools wheel
|
||||||
|
pip install -r requirements.txt
|
||||||
|
|
||||||
|
if [ $? -ne 0 ]; then
|
||||||
|
echo "Failed to install required packages. Please check your internet connection and try again."
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
|
||||||
|
# Cleanup
|
||||||
|
if [ -d "./tmp" ]; then
|
||||||
|
rm -rf "./tmp"
|
||||||
|
echo "Cleaning tmp folder"
|
||||||
|
fi
|
||||||
|
# Launch the Python application
|
||||||
|
python app.py
|
||||||
|
else
|
||||||
|
# go to the ui folder
|
||||||
|
cd lollms-webui
|
||||||
|
conda activate ./env
|
||||||
|
# Launch the Python application
|
||||||
|
python app.py
|
||||||
|
fi
|
||||||
31
configs/config.yaml
Normal file
@ -0,0 +1,31 @@
|
|||||||
|
# =================== Lord Of Large Language Models Configuration file ===========================
|
||||||
|
version: 7
|
||||||
|
binding_name: null
|
||||||
|
model_name: null
|
||||||
|
|
||||||
|
# Host information
|
||||||
|
host: localhost
|
||||||
|
port: 9600
|
||||||
|
|
||||||
|
# Genreration parameters
|
||||||
|
seed: -1
|
||||||
|
n_predict: 1024
|
||||||
|
ctx_size: 2048
|
||||||
|
temperature: 0.9
|
||||||
|
top_k: 50
|
||||||
|
top_p: 0.95
|
||||||
|
repeat_last_n: 40
|
||||||
|
repeat_penalty: 1.2
|
||||||
|
|
||||||
|
n_threads: 8
|
||||||
|
|
||||||
|
#Personality parameters
|
||||||
|
personalities: ["english/generic/lollms"]
|
||||||
|
active_personality_id: 0
|
||||||
|
override_personality_model_parameters: false #if true the personality parameters are overriden by those of the configuration (may affect personality behaviour)
|
||||||
|
|
||||||
|
user_name: user
|
||||||
|
|
||||||
|
# UI parameters
|
||||||
|
debug: False
|
||||||
|
db_path: database.db
|
||||||
@ -1,26 +0,0 @@
|
|||||||
config: default
|
|
||||||
ctx_size: 512
|
|
||||||
db_path: databases/database.db
|
|
||||||
debug: false
|
|
||||||
n_threads: 8
|
|
||||||
host: localhost
|
|
||||||
language: en-US
|
|
||||||
# Supported backends are llamacpp and gpt-j
|
|
||||||
backend: llama_cpp
|
|
||||||
model: gpt4all-lora-quantized-ggml.bin
|
|
||||||
n_predict: 1024
|
|
||||||
nb_messages_to_remember: 5
|
|
||||||
personality_language: english
|
|
||||||
personality_category: general
|
|
||||||
personality: gpt4all_chatbot
|
|
||||||
port: 9600
|
|
||||||
repeat_last_n: 40
|
|
||||||
repeat_penalty: 1.2
|
|
||||||
seed: 0
|
|
||||||
temp: 0.9
|
|
||||||
top_k: 50
|
|
||||||
top_p: 0.95
|
|
||||||
voice: ""
|
|
||||||
use_gpu: false # Not active yet
|
|
||||||
auto_read: false
|
|
||||||
use_avx2: true # By default we require using avx2 but if not supported, make sure you remove it from here
|
|
||||||
1152
convert.py
Normal file
@ -6,10 +6,10 @@ services:
|
|||||||
context: .
|
context: .
|
||||||
dockerfile: Dockerfile
|
dockerfile: Dockerfile
|
||||||
volumes:
|
volumes:
|
||||||
|
- ./data:/srv/help
|
||||||
- ./data:/srv/data
|
- ./data:/srv/data
|
||||||
- ./data/.nomic:/root/.nomic/
|
- ./data/.parisneo:/root/.parisneo/
|
||||||
- ./models:/srv/models
|
|
||||||
- ./configs:/srv/configs
|
- ./configs:/srv/configs
|
||||||
- ./personalities:/srv/personalities
|
- ./web:/srv/web
|
||||||
ports:
|
ports:
|
||||||
- "9600:9600"
|
- "9600:9600"
|
||||||
|
|||||||
@ -1,126 +0,0 @@
|
|||||||
### Manual Simple install:
|
|
||||||
|
|
||||||
1. Download this repository .zip:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
2. Extract contents into a folder.
|
|
||||||
3. Install/run application by double clicking on `webui.bat` file from Windows Explorer as normal user.
|
|
||||||
|
|
||||||
### Manual Advanced mode:
|
|
||||||
|
|
||||||
1. Install [git](https://git-scm.com/download/win).
|
|
||||||
2. Open Terminal/PowerShell and navigate to a folder you want to clone this repository.
|
|
||||||
|
|
||||||
```bash
|
|
||||||
git clone https://github.com/nomic-ai/gpt4all-ui.git
|
|
||||||
```
|
|
||||||
|
|
||||||
4. Install/run application by double clicking on `webui.bat` file from Windows explorer as normal user.
|
|
||||||
|
|
||||||
## Linux
|
|
||||||
|
|
||||||
### Automatic install
|
|
||||||
|
|
||||||
1. Make sure you have installed `curl`. It is needed for the one-liner to work.
|
|
||||||
|
|
||||||
`Debian-based:`
|
|
||||||
```
|
|
||||||
sudo apt install curl
|
|
||||||
```
|
|
||||||
`Red Hat-based:`
|
|
||||||
```
|
|
||||||
sudo dnf install curl
|
|
||||||
```
|
|
||||||
`Arch-based:`
|
|
||||||
```
|
|
||||||
sudo pacman -S curl
|
|
||||||
```
|
|
||||||
2. Open terminal/console copy and paste this command and press enter:
|
|
||||||
```
|
|
||||||
mkdir -p ~/gpt4all-ui && curl -L https://raw.githubusercontent.com/nomic-ai/gpt4all-ui/main/webui.sh -o ~/gpt4all-ui/webui.sh && chmod +x ~/gpt4all-ui/webui.sh && cd ~/gpt4all-ui && ./webui.sh
|
|
||||||
```
|
|
||||||
> **Note**
|
|
||||||
>
|
|
||||||
> This command creates new directory `/gpt4all-ui/` in your /home/ direcory, downloads a file [webui.sh](https://raw.githubusercontent.com/nomic-ai/gpt4all-ui/main/webui.sh), makes file executable and executes webui.sh that downloads and installs everything that is needed.
|
|
||||||
|
|
||||||
3. Follow instructions on screen until it launches webui.
|
|
||||||
4. To relaunch application:
|
|
||||||
```
|
|
||||||
bash webui.sh
|
|
||||||
```
|
|
||||||
|
|
||||||
### Manual Simple install:
|
|
||||||
|
|
||||||
1. Download this repository .zip:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
2. Extract contents into a folder.
|
|
||||||
3. Install/run application from terminal/console:
|
|
||||||
```
|
|
||||||
bash webui.sh
|
|
||||||
```
|
|
||||||
### Manual Advanced mode:
|
|
||||||
|
|
||||||
1. Open terminal/console and install dependencies:
|
|
||||||
|
|
||||||
`Debian-based:`
|
|
||||||
```
|
|
||||||
sudo apt install curl git python3 python3-venv
|
|
||||||
```
|
|
||||||
`Red Hat-based:`
|
|
||||||
```
|
|
||||||
sudo dnf install curl git python3
|
|
||||||
```
|
|
||||||
`Arch-based:`
|
|
||||||
```
|
|
||||||
sudo pacman -S curl git python3
|
|
||||||
```
|
|
||||||
|
|
||||||
2. Clone repository:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
git clone https://github.com/nomic-ai/gpt4all-ui.git
|
|
||||||
```
|
|
||||||
```bash
|
|
||||||
cd gpt4all-ui
|
|
||||||
```
|
|
||||||
|
|
||||||
3. Install/run application:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
bash ./webui.sh
|
|
||||||
```
|
|
||||||
|
|
||||||
## MacOS
|
|
||||||
|
|
||||||
1. Open terminal/console and install `brew`:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
|
|
||||||
```
|
|
||||||
|
|
||||||
2. Install dependencies:
|
|
||||||
|
|
||||||
```
|
|
||||||
brew install git python3
|
|
||||||
```
|
|
||||||
|
|
||||||
3. Clone repository:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
git clone https://github.com/nomic-ai/gpt4all-ui.git
|
|
||||||
```
|
|
||||||
```bash
|
|
||||||
cd gpt4all-ui
|
|
||||||
```
|
|
||||||
|
|
||||||
4. Install/run application:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
bash ./webui.sh
|
|
||||||
```
|
|
||||||
|
|
||||||
On Linux/MacOS, if you have issues, refer to the details presented [here](docs/Linux_Osx_Install.md)
|
|
||||||
These scripts will create a Python virtual environment and install the required dependencies. It will also download the models and install them.
|
|
||||||
96
docs/dev/db_infos.md
Normal file
@ -0,0 +1,96 @@
|
|||||||
|
# Database Documentation
|
||||||
|
* TOC
|
||||||
|
{:toc}
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
This project implements a discussion forum and utilizes a SQLite database to store discussions and messages.
|
||||||
|
|
||||||
|
## Database Schema
|
||||||
|
The following database schema has been implemented:
|
||||||
|
|
||||||
|
- `discussion`: table to store discussion information including id and title.
|
||||||
|
- `message`: table to store message information including id, sender, content, type, rank, parent, and discussion_id. The type column is an integer representing the type of the message. The rank column is an integer representing the rank of the message. The parent column is an integer representing the id of the parent message. The discussion_id column is a foreign key referencing the id column in the discussion table.
|
||||||
|
|
||||||
|
## Database Upgrades
|
||||||
|
The database schema is currently at version 2. The following upgrades have been made to the schema:
|
||||||
|
|
||||||
|
In version 1, three columns have been added to the message table: type, rank, and parent.
|
||||||
|
In version 2, the parent column has been added to the message table (if it doesn't already exist).
|
||||||
|
Encoding
|
||||||
|
The encoding of the database is checked before creating/updating the schema. If the current encoding is not UTF-8, it is changed to UTF-8.
|
||||||
|
|
||||||
|
## Implementation Details
|
||||||
|
The create database schema script is responsible for creating/updating the database schema. It first checks the encoding of the database and changes it to UTF-8 if necessary. Then, it checks if the required tables (discussion, message, and schema_version) exist. If any of these tables do not exist, they are created. The schema version is retrieved from the schema_version table. If the table is empty, version 0 is assumed. Otherwise, the version from the table is used. If the version is less than the current version, the schema is upgraded to the current version by adding the necessary columns to the message table. Finally, the schema version is updated or inserted into the schema_version table.
|
||||||
|
|
||||||
|
## Documentation:
|
||||||
|
|
||||||
|
The DiscussionDB class provides methods to manipulate the database and retrieve information about discussions and messages. Here are the methods available in this class:
|
||||||
|
```
|
||||||
|
select(query, params=None, fetch_all=True)
|
||||||
|
```
|
||||||
|
|
||||||
|
This method executes an SQL select query on the database with optional parameters. It returns the cursor object for further processing. If fetch_all is True, it returns all the rows returned by the query, else it returns only the first row.
|
||||||
|
|
||||||
|
```
|
||||||
|
delete(query, params=None)
|
||||||
|
```
|
||||||
|
|
||||||
|
This method executes an SQL delete query on the database with optional parameters. It returns the cursor object for further processing.
|
||||||
|
|
||||||
|
```
|
||||||
|
insert(query, params=None)
|
||||||
|
```
|
||||||
|
|
||||||
|
This method executes an SQL insert query on the database with optional parameters. It returns the ID of the newly inserted row.
|
||||||
|
|
||||||
|
```
|
||||||
|
update(query, params=None)
|
||||||
|
```
|
||||||
|
|
||||||
|
This method executes an SQL update query on the database with optional parameters.
|
||||||
|
|
||||||
|
```
|
||||||
|
load_last_discussion()
|
||||||
|
```
|
||||||
|
|
||||||
|
This method retrieves the last discussion in the database or creates a new one if there are no discussions. It returns a Discussion instance for the retrieved or created discussion.
|
||||||
|
|
||||||
|
```
|
||||||
|
create_discussion(title="untitled")
|
||||||
|
```
|
||||||
|
|
||||||
|
This method creates a new discussion with the specified title. It returns a Discussion instance for the newly created discussion.
|
||||||
|
|
||||||
|
```
|
||||||
|
build_discussion(discussion_id=0)
|
||||||
|
```
|
||||||
|
|
||||||
|
This method retrieves the discussion with the specified ID or creates a new one if the ID is not found. It returns a Discussion instance for the retrieved or created discussion.
|
||||||
|
|
||||||
|
```
|
||||||
|
get_discussions()
|
||||||
|
```
|
||||||
|
|
||||||
|
This method retrieves all discussions in the database. It returns a list of dictionaries, where each dictionary represents a discussion and contains the discussion's ID and title.
|
||||||
|
|
||||||
|
```
|
||||||
|
does_last_discussion_have_messages()
|
||||||
|
```
|
||||||
|
|
||||||
|
This method checks if the last discussion in the database has any messages. It returns True if the last discussion has at least one message, else False.
|
||||||
|
|
||||||
|
```
|
||||||
|
remove_discussions()
|
||||||
|
```
|
||||||
|
|
||||||
|
This method removes all discussions and messages from the database.
|
||||||
|
|
||||||
|
```
|
||||||
|
export_to_json()
|
||||||
|
```
|
||||||
|
|
||||||
|
This method exports all discussions and messages in the database to a JSON file. It returns a list of dictionaries, where each dictionary represents a discussion and contains the discussion's ID, title, and messages. Each message is represented by a dictionary with the sender, content, type, rank, and parent fields.
|
||||||
|
|
||||||
|
|
||||||
|
## Database diagram
|
||||||
|

|
||||||
542
docs/dev/full_endpoints_list.md
Normal file
@ -0,0 +1,542 @@
|
|||||||
|
# Flask Backend API Documentation
|
||||||
|
|
||||||
|
This documentation provides an overview of the endpoints available in the Flask backend API.
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
The Flask backend API exposes various endpoints to interact with the application. Each endpoint performs a specific function and supports different HTTP methods. The following sections describe each endpoint along with their parameters and expected outputs.
|
||||||
|
|
||||||
|
## Endpoints
|
||||||
|
|
||||||
|
### Endpoint: /disk_usage (GET)
|
||||||
|
|
||||||
|
**Description**: Retrieves the disk usage of the system.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the disk usage information.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /ram_usage (GET)
|
||||||
|
|
||||||
|
**Description**: Retrieves the ram usage of the system.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the ram usage information.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /list_bindings (GET)
|
||||||
|
|
||||||
|
**Description**: Lists the available bindings.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns a list of available bindings.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /list_models (GET)
|
||||||
|
|
||||||
|
**Description**: Lists the available models.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns a list of available models.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /list_personalities_languages (GET)
|
||||||
|
|
||||||
|
**Description**: Lists the languages supported by personalities.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns a list of languages supported by personalities.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /list_personalities_categories (GET)
|
||||||
|
|
||||||
|
**Description**: Lists the categories of personalities.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns a list of personality categories.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /list_personalities (GET)
|
||||||
|
|
||||||
|
**Description**: Lists the available personalities.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns a list of available personalities.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /list_languages (GET)
|
||||||
|
|
||||||
|
**Description**: Lists the available languages.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns a list of available languages.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /list_discussions (GET)
|
||||||
|
|
||||||
|
**Description**: Lists the discussions.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns a list of discussions.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /set_personality (GET)
|
||||||
|
|
||||||
|
**Description**: Sets the active personality.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Sets the active personality.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /delete_personality (GET)
|
||||||
|
|
||||||
|
**Description**: Deletes a personality.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Deletes the specified personality.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: / (GET)
|
||||||
|
|
||||||
|
**Description**: Returns the index page.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the index page.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /<path:filename> (GET)
|
||||||
|
|
||||||
|
**Description**: Serves static files.
|
||||||
|
|
||||||
|
**Parameters**: `filename` - The path to the static file.
|
||||||
|
|
||||||
|
**Output**: Returns the requested static file.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /personalities/<path:filename> (GET)
|
||||||
|
|
||||||
|
**Description**: Serves personality files.
|
||||||
|
|
||||||
|
**Parameters**: `filename` - The path to the personality file.
|
||||||
|
|
||||||
|
**Output**: Returns the requested personality file.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /outputs/<path:filename> (GET)
|
||||||
|
|
||||||
|
**Description**: Serves output files.
|
||||||
|
|
||||||
|
**Parameters**: `filename` - The path to the output file.
|
||||||
|
|
||||||
|
**Output**: Returns the requested output file.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /export_discussion (GET)
|
||||||
|
|
||||||
|
**Description**: Exports a discussion.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Exports the specified discussion.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /export (GET)
|
||||||
|
|
||||||
|
**Description**: Exports data.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Exports the specified data.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /new_discussion (GET)
|
||||||
|
|
||||||
|
**Description**: Creates a new discussion.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Creates a new discussion.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /stop_gen (GET)
|
||||||
|
|
||||||
|
**Description**: Stops the generation process.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Stops the generation process.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /rename (POST)
|
||||||
|
|
||||||
|
**Description**: Renames a resource.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Renames the specified resource.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /edit_title (POST)
|
||||||
|
|
||||||
|
**Description**: Edits the title of a resource.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Edits the title of the specified resource.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /load_discussion (POST)
|
||||||
|
|
||||||
|
**Description**: Loads a discussion.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Loads the specified discussion.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /delete_discussion (POST)
|
||||||
|
|
||||||
|
**Description**: Deletes a discussion.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Deletes the specified discussion.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /update_message (GET)
|
||||||
|
|
||||||
|
**Description**: Updates a message.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Updates the specified message.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /message_rank_up (GET)
|
||||||
|
|
||||||
|
**Description**: Increases the rank of a message.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Increases the rank of the specified message.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /message_rank_down (GET)
|
||||||
|
|
||||||
|
**Description**: Decreases the rank of a message.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Decreases the rank of the specified message.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /delete_message (GET)
|
||||||
|
|
||||||
|
**Description**: Deletes a message.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Deletes the specified message.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /set_binding (POST)
|
||||||
|
|
||||||
|
**Description**: Sets a binding.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Sets the specified binding.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /set_model (POST)
|
||||||
|
|
||||||
|
**Description**: Sets a model.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Sets the specified model.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /update_model_params (POST)
|
||||||
|
|
||||||
|
**Description**: Updates model parameters.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Updates the specified model parameters.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /get_config (GET)
|
||||||
|
|
||||||
|
**Description**: Retrieves the configuration.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the configuration.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /get_available_models (GET)
|
||||||
|
|
||||||
|
**Description**: Retrieves the available models.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns a list of available models.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /extensions (GET)
|
||||||
|
|
||||||
|
**Description**: Retrieves the extensions.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the extensions.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /training (GET)
|
||||||
|
|
||||||
|
**Description**: Performs training.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Performs the training process.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /main (GET)
|
||||||
|
|
||||||
|
**Description**: Returns the main page.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the main page.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /settings (GET)
|
||||||
|
|
||||||
|
**Description**: Returns the settings page.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the settings page.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /help (GET)
|
||||||
|
|
||||||
|
**Description**: Returns the help page.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the help page.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /get_generation_status (GET)
|
||||||
|
|
||||||
|
**Description**: Retrieves the generation status.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the generation status.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /update_setting (POST)
|
||||||
|
|
||||||
|
**Description**: Updates a setting.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Updates the specified setting.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /apply_settings (POST)
|
||||||
|
|
||||||
|
**Description**: Applies the settings.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Applies the specified settings.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /save_settings (POST)
|
||||||
|
|
||||||
|
**Description**: Saves the settings.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Saves the specified settings.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /get_current_personality (GET)
|
||||||
|
|
||||||
|
**Description**: Retrieves the current personality.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the current personality.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /get_all_personalities (GET)
|
||||||
|
|
||||||
|
**Description**: Retrieves all personalities.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns a list of all personalities.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /get_personality (GET)
|
||||||
|
|
||||||
|
**Description**: Retrieves a specific personality.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Returns the specified personality.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /reset (GET)
|
||||||
|
|
||||||
|
**Description**: Resets the system.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Resets the system.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /export_multiple_discussions (POST)
|
||||||
|
|
||||||
|
**Description**: Exports multiple discussions.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Exports the specified discussions.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Endpoint: /import_multiple_discussions (POST)
|
||||||
|
|
||||||
|
**Description**: Imports multiple discussions.
|
||||||
|
|
||||||
|
**Parameters**: None
|
||||||
|
|
||||||
|
**Output**: Imports the specified discussions.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Active personalities manipulation endpoints
|
||||||
|
|
||||||
|
### Mount Personality
|
||||||
|
|
||||||
|
**Endpoint:** `/mount_personality`
|
||||||
|
|
||||||
|
**Method:** POST
|
||||||
|
|
||||||
|
**Parameters:**
|
||||||
|
- `language` (file): The language file associated with the personality.
|
||||||
|
- `category` (file): The category file associated with the personality.
|
||||||
|
- `name` (file): The name file associated with the personality.
|
||||||
|
|
||||||
|
**Description:**
|
||||||
|
This endpoint mounts a personality by adding it to the list of configured personalities and setting it as the active personality. The personality is specified by providing the language, category, and name files. The endpoint checks if the personality's configuration file exists and, if not, adds the personality to the configuration. After mounting the personality, the settings are applied.
|
||||||
|
|
||||||
|
**Returns:**
|
||||||
|
- If the personality is mounted successfully:
|
||||||
|
- `status` (boolean): `True`
|
||||||
|
- If the personality is not found:
|
||||||
|
- `status` (boolean): `False`
|
||||||
|
- `error` (string): "Personality not found"
|
||||||
|
|
||||||
|
### Unmount Personality
|
||||||
|
|
||||||
|
**Endpoint:** `/unmount_personality`
|
||||||
|
|
||||||
|
**Method:** POST
|
||||||
|
|
||||||
|
**Parameters:**
|
||||||
|
- `language` (file): The language file associated with the personality.
|
||||||
|
- `category` (file): The category file associated with the personality.
|
||||||
|
- `name` (file): The name file associated with the personality.
|
||||||
|
|
||||||
|
**Description:**
|
||||||
|
This endpoint unmounts a personality by removing it from the list of configured personalities. The personality is specified by providing the language, category, and name files. If the active personality is removed, the active personality ID is reset to `0`. After unmounting the personality, the settings are applied.
|
||||||
|
|
||||||
|
**Returns:**
|
||||||
|
- If the personality is unmounted successfully:
|
||||||
|
- `status` (boolean): `True`
|
||||||
|
- If the personality couldn't be unmounted:
|
||||||
|
- `status` (boolean): `False`
|
||||||
|
- `error` (string): "Couldn't unmount personality"
|
||||||
|
|
||||||
|
### Select Personality
|
||||||
|
|
||||||
|
**Endpoint:** `/select_personality`
|
||||||
|
|
||||||
|
**Method:** POST
|
||||||
|
|
||||||
|
**Parameters:**
|
||||||
|
- `id` (file): The ID of the personality to select.
|
||||||
|
|
||||||
|
**Description:**
|
||||||
|
This endpoint selects a personality from the list of configured personalities based on the provided ID. The ID represents the index of the personality in the list. After selecting the personality, the settings are applied.
|
||||||
|
|
||||||
|
**Returns:**
|
||||||
|
- If the personality is selected successfully:
|
||||||
|
- `status` (boolean): `True`
|
||||||
|
- If the ID is invalid:
|
||||||
|
- `status` (boolean): `False`
|
||||||
|
- `error` (string): "Invalid ID"
|
||||||
83
docs/dev/new_ui_dev.md
Normal file
@ -0,0 +1,83 @@
|
|||||||
|
# lollms-webui Web interface VUE3 development log, todo's and more
|
||||||
|
|
||||||
|
## Installation for development
|
||||||
|
|
||||||
|
You must have [Node.js](https://nodejs.org/en) installed on your computer.
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /web/
|
||||||
|
npm install
|
||||||
|
```
|
||||||
|
## Testing, running, debugging
|
||||||
|
|
||||||
|
After that to run development server locally and test the web page at http://localhost:5173/:
|
||||||
|
|
||||||
|
```
|
||||||
|
npm run dev
|
||||||
|
```
|
||||||
|
|
||||||
|
> Note
|
||||||
|
> To run the developmen environment you need to create copy of the `.env` file and name it either `.env.development` or if that dont work then `.env.dev`. Set `VITE_GPT4ALL_API_BASEURL = /api/ ` in the `.env.development`.
|
||||||
|
> Run your gpt binding by launching `webui.bat` or bash `webui.sh`.
|
||||||
|
|
||||||
|
## Building frontend - UI
|
||||||
|
|
||||||
|
```
|
||||||
|
npm run build
|
||||||
|
```
|
||||||
|
|
||||||
|
This will update `/dist/` folder with all the files. Also the build will show you if there are errors or not in your vue code.
|
||||||
|
|
||||||
|
> Note
|
||||||
|
> Make sure you test the built files too, because sometimes the builder dont catch all the errors, and if a component is not refernced it might not load in the built version, but it loads fine in development environment
|
||||||
|
|
||||||
|
# UI development log, todo's and more
|
||||||
|
|
||||||
|
Here we keep track of things to implement and stuff we need to do.
|
||||||
|
## Todo's
|
||||||
|
|
||||||
|
- Add ability to select multiple discussions to export [WIP]
|
||||||
|
- Add toast messages for errors and successes
|
||||||
|
- Add DB switcher (im thinking in the settings view)
|
||||||
|
- Make the UI work good on mobile
|
||||||
|
- Need to fix colors for `<input />` fields
|
||||||
|
- Create status bar for binding to display if something is generating on the binding
|
||||||
|
- Add ability for users to style the whole UI, either changing Hue or changing every color manually.
|
||||||
|
- Create a panel in the Settings tab to create new personalities
|
||||||
|
- Need to investigate performance of websocket when message is being streamed back to the UI
|
||||||
|
- On first launch of the UI force users to create "User" personality, to be used as "User" for any or all input messages.
|
||||||
|
- Add drag n drop files into messages, images gets parsed as images, ability to load images from messages from DB.
|
||||||
|
- Send files to binding - images, other files for parsing data.
|
||||||
|
- Ability to reorder Discussions, add tags, categories
|
||||||
|
- Export whole DB
|
||||||
|
- Reset whole DB
|
||||||
|
- Add text to speech to messages and chatbox
|
||||||
|
- Add indicator to messages when non-comercial model was used.
|
||||||
|
- Ability to export messages that are for commercial use or open source model messages Only.
|
||||||
|
- Ability to hide non commercial model messages.
|
||||||
|
- Feature - bot council where you add multiple bots to discussion, give them a topic and maybe max message count or something and they ponder about the topic then summerize it all.
|
||||||
|
- Feature voice chat with bot and voice output from bot - whisper + bard?
|
||||||
|
- Feature under selected discussion show more options to select and add more bots, select model per discussion or per bot, tweak settings per bot or per model.
|
||||||
|
- Easy share personality via export to a file, then drag and drop on to the webui and youre done.
|
||||||
|
|
||||||
|
## Done
|
||||||
|
|
||||||
|
- Fix discussion list width so that it stays static and dont resize depending on message contents [DONE]
|
||||||
|
- Add chat input field [DONE]
|
||||||
|
- Make search filter work [DONE]
|
||||||
|
- Add clear filter button to search input field [DONE]
|
||||||
|
- Add modal to ask user if you sure about to delete [DONE but in different way]
|
||||||
|
- Fix up the discussion array to filter out the messages by type not by count. (conditionner and )[DONE]
|
||||||
|
- Add title of current discussion to page [DONE]
|
||||||
|
- Populate settings with settings controls [DONE]
|
||||||
|
- Connect Settings to binding, ability to save changes [DONE]
|
||||||
|
- Scroll to bottom [SCROLLBAR]
|
||||||
|
- Scroll to top [SCROLLBAR]
|
||||||
|
- Create stop generating button [DONE]
|
||||||
|
- Fix the generated message formatting - add line breaks, also for user input messages. [DONE]
|
||||||
|
- Maybe try to set the chatbox to float to the bottom (always on the bottom of the screen) [DONE]
|
||||||
|
- Need to fix when user inputs message it shows up in the discussion array and then add new message for bot that is typing. [DONE]
|
||||||
|
- Connect delete / export discussions to binding functions.[DONE]
|
||||||
|
- Need to fix when deleting multiple discussions to not loose loading animation for each discussion when list gets updated [DONE]
|
||||||
|
- Need to add loading feedback for when a new discussion is being created [DONE]
|
||||||
|
- Add ability to select multiple discussions to delete [DONE]
|
||||||
BIN
docs/dev/scheme.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.4 KiB |
302
docs/dev/server_endpoints.md
Normal file
@ -0,0 +1,302 @@
|
|||||||
|
# Server endpoints documentation
|
||||||
|
|
||||||
|
## Introduction:
|
||||||
|
This Flask server provides various endpoints to manage and interact with the chatbot. Here's a brief explanation of the endpoints available:
|
||||||
|
|
||||||
|
## Endpoints:
|
||||||
|
|
||||||
|
- "/list_bindings": GET request endpoint to list all the available bindings.
|
||||||
|
```
|
||||||
|
[
|
||||||
|
"llama_cpp"
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/list_models": GET request endpoint to list all the available models.
|
||||||
|
```
|
||||||
|
[
|
||||||
|
"ggml-alpaca-7b-q4.bin",
|
||||||
|
"ggml-vicuna-13b-1.1-q4_0.bin",
|
||||||
|
"ggml-vicuna-13b-1.1-q4_1.bin",
|
||||||
|
"ggml-vicuna-13b-4bit-rev1.bin",
|
||||||
|
"ggml-vicuna-7b-4bit-rev1.bin",
|
||||||
|
"ggml-vicuna-7b-4bit.bin",
|
||||||
|
"gpt4all-lora-quantized-ggml.bin",
|
||||||
|
"gpt4all-lora-quantized.bin",
|
||||||
|
"gpt4all-lora-unfiltered-quantized.bin"
|
||||||
|
]
|
||||||
|
```
|
||||||
|
- "/list_personalities_languages": GET request endpoint to list all the available personality languages.
|
||||||
|
```
|
||||||
|
[
|
||||||
|
"english",
|
||||||
|
"french"
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/list_personalities_categories": GET request endpoint to list all the available personality categories.
|
||||||
|
```
|
||||||
|
[
|
||||||
|
"art",
|
||||||
|
"creativity",
|
||||||
|
"funny_learning",
|
||||||
|
"general",
|
||||||
|
"tools"
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/list_personalities": GET request endpoint to list all the available personalities.
|
||||||
|
```
|
||||||
|
[
|
||||||
|
"Computing advisor"
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/list_languages": GET request endpoint to list all the available languages.
|
||||||
|
```
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"label": "English",
|
||||||
|
"value": "en-US"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"label": "Fran\u00e7ais",
|
||||||
|
"value": "fr-FR"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"label": "\u0627\u0644\u0639\u0631\u0628\u064a\u0629",
|
||||||
|
"value": "ar-AR"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"label": "Italiano",
|
||||||
|
"value": "it-IT"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"label": "Deutsch",
|
||||||
|
"value": "de-DE"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"label": "Dutch",
|
||||||
|
"value": "nl-XX"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"label": "\u4e2d\u570b\u4eba",
|
||||||
|
"value": "zh-CN"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/list_discussions": GET request endpoint to list all the available discussions.
|
||||||
|
```
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"id": 9,
|
||||||
|
"title": "is dog a god?"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"id": 10,
|
||||||
|
"title": "untitled"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/set_personality_language": GET request endpoint to set the personality language.
|
||||||
|
- "/set_personality_category": GET request endpoint to set the personality category.
|
||||||
|
- "/": GET request endpoint to display the index page.
|
||||||
|
- "/path:filename": GET request endpoint to serve static files.
|
||||||
|
- "/export_discussion": GET request endpoint to export the current discussion.
|
||||||
|
- "/export": GET request endpoint to export the chatbot's data.
|
||||||
|
- "/new_discussion": GET request endpoint to create a new discussion.
|
||||||
|
- "/stop_gen": GET request endpoint to stop the chatbot from generating responses.
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"status": True
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/rename": POST request endpoint to rename a discussion.
|
||||||
|
- "/edit_title": POST request endpoint to edit the title of a discussion.
|
||||||
|
- "/load_discussion": POST request endpoint to load a discussion.
|
||||||
|
```
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"content": "##Instructions:\\nGPT4All is a smart and helpful Assistant built by Nomic-AI. It can discuss with humans and assist them.\n",
|
||||||
|
"id": 23,
|
||||||
|
"parent": 0,
|
||||||
|
"rank": 0,
|
||||||
|
"sender": "conditionner",
|
||||||
|
"type": 1
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"content": "Welcome! I am GPT4All A free and open assistant. What can I do for you today?",
|
||||||
|
"id": 24,
|
||||||
|
"parent": 23,
|
||||||
|
"rank": 0,
|
||||||
|
"sender": "gpt4all",
|
||||||
|
"type": 0
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"content": "is dog a god?",
|
||||||
|
"id": 25,
|
||||||
|
"parent": 24,
|
||||||
|
"rank": 0,
|
||||||
|
"sender": "user",
|
||||||
|
"type": 0
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"content": "That depends on your definition of 'God'. In some religions, dogs are considered sacred and divine creatures. But in others, they may not be seen as gods or deities at all.",
|
||||||
|
"id": 26,
|
||||||
|
"parent": 25,
|
||||||
|
"rank": 0,
|
||||||
|
"sender": "gpt4all",
|
||||||
|
"type": 0
|
||||||
|
}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/delete_discussion": POST request endpoint to delete a discussion.
|
||||||
|
- "/update_message": GET request endpoint to update a message.
|
||||||
|
- "/message_rank_up": GET request endpoint to rank up a message.
|
||||||
|
- "/message_rank_down": GET request endpoint to rank down a message.
|
||||||
|
- "/delete_message": GET request endpoint to delete a message.
|
||||||
|
- "/set_binding": POST request endpoint to set the binding.
|
||||||
|
- "/set_model": POST request endpoint to set the model.
|
||||||
|
- "/update_model_params": POST request endpoint to update the model parameters.
|
||||||
|
- "/get_config": GET request endpoint to get the chatbot's configuration.
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"auto_read": false,
|
||||||
|
"binding": "llama_cpp",
|
||||||
|
"config": "local_config.yaml",
|
||||||
|
"ctx_size": 2048,
|
||||||
|
"db_path": "databases/database.db",
|
||||||
|
"debug": false,
|
||||||
|
"host": "localhost",
|
||||||
|
"language": "en-US",
|
||||||
|
"model": "gpt4all-lora-quantized-ggml.bin",
|
||||||
|
"n_predict": 1024,
|
||||||
|
"n_threads": 8,
|
||||||
|
"nb_messages_to_remember": 5,
|
||||||
|
"override_personality_model_parameters": false,
|
||||||
|
"personality": "Computing advisor",
|
||||||
|
"personality_category": "Helpers",
|
||||||
|
"personality_language": "english",
|
||||||
|
"port": 9600,
|
||||||
|
"repeat_last_n": 40,
|
||||||
|
"repeat_penalty": 1.2,
|
||||||
|
"seed": 0,
|
||||||
|
"temperature": 0.9,
|
||||||
|
"top_k": 50,
|
||||||
|
"top_p": 0.95,
|
||||||
|
"use_avx2": true,
|
||||||
|
"use_gpu": false,
|
||||||
|
"use_new_ui": true,
|
||||||
|
"version": 3,
|
||||||
|
"voice": ""
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/get_current_personality": GET request endpoint to get all information about current personality
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"personality": {
|
||||||
|
"ai_message_prefix": "###gpt4all:\n",
|
||||||
|
"anti_prompts": [
|
||||||
|
"###user",
|
||||||
|
"### user",
|
||||||
|
"###gpt4all",
|
||||||
|
"### gpt4all"
|
||||||
|
],
|
||||||
|
"assets_list": [
|
||||||
|
"personalities\\english\\generic\\gpt4all\\assets\\logo.png"
|
||||||
|
],
|
||||||
|
"author": "ParisNeo",
|
||||||
|
"category": "General",
|
||||||
|
"dependencies": [],
|
||||||
|
"disclaimer": "",
|
||||||
|
"language": "en_XX",
|
||||||
|
"link_text": "\n",
|
||||||
|
"model_n_predicts": 1024,
|
||||||
|
"model_repeat_last_n": 40,
|
||||||
|
"model_repeat_penalty": 1.0,
|
||||||
|
"model_temperature": 0.6,
|
||||||
|
"model_top_k": 50,
|
||||||
|
"model_top_p": 0.9,
|
||||||
|
"name": "gpt4all",
|
||||||
|
"personality_conditioning": "## Information:\nAssistant's name is gpt4all\nToday's date is {{date}}\n## Instructions:\nYour mission is to assist user to perform various tasks and answer his questions\n",
|
||||||
|
"personality_description": "This personality is a helpful and Kind AI ready to help you solve your problems \n",
|
||||||
|
"user_message_prefix": "###user:\n",
|
||||||
|
"user_name": "user",
|
||||||
|
"version": "1.0.0",
|
||||||
|
"welcome_message": "Welcome! My name is gpt4all.\nHow can I help you today?\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
- "/extensions": GET request endpoint to list all the available extensions.
|
||||||
|
- "/training": GET request endpoint to start the training process.
|
||||||
|
- "/main": GET request endpoint to start the chatbot.
|
||||||
|
- "/settings": GET request endpoint to display the settings page.
|
||||||
|
- "/help": GET request endpoint to display the help page.
|
||||||
|
- "/get_all_personalities": GET request endpoint to get all personalities array
|
||||||
|
- "/get_personality": GET request endpoint to get speciffic data based on request
|
||||||
|
- "/disk_usage": GET request endpoint to retrieve the available space in the current folder's drive.
|
||||||
|
Method: GET
|
||||||
|
Description: Retrieves the available space in bytes for the current folder's drive.
|
||||||
|
Response:
|
||||||
|
Content-Type: application/json
|
||||||
|
Body: JSON object with a single entry 'available_space' containing the available space in bytes.
|
||||||
|
Example Response:
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"total_space":1000000000000,
|
||||||
|
"available_space":515358106014,
|
||||||
|
"percent_usage":51.53,
|
||||||
|
"binding_models_usage": 3900000000
|
||||||
|
}
|
||||||
|
```
|
||||||
|
Example Usage:
|
||||||
|
Request: GET /disk_space
|
||||||
|
Response: 200 OK
|
||||||
|
|
||||||
|
## TODO Endpoints:
|
||||||
|
|
||||||
|
Here we list needed endpoints on th ebinding to make UI work as expected.
|
||||||
|
|
||||||
|
|
||||||
|
# Socketio endpoints
|
||||||
|
These are the WebSocket server endpoints that are used to handle real-time communication between the client and server using the SocketIO library.
|
||||||
|
|
||||||
|
The first decorator `@socketio.on('connect')` listens for a connection event and calls the `connect()` function when a client connects to the server. Similarly, the second decorator `@socketio.on('disconnect')` listens for a disconnection event and calls the `disconnect()` function when a client disconnects from the server.
|
||||||
|
|
||||||
|
The third decorator `@socketio.on('generate_msg')` is used to handle the event of generating a message. It takes the data sent by the client and adds a new message to the current discussion with the user as the sender and the message content as the prompt. It then starts a new thread to parse the prompt into a prompt stream.
|
||||||
|
|
||||||
|
The fourth decorator `@socketio.on('generate_msg_from')` is used to handle the event of generating a message from a specific message ID. It takes the data sent by the client which includes the message ID and message prompt and starts a new thread to parse the prompt into a prompt stream.
|
||||||
|
|
||||||
|
The fifth decorator `@socketio.on('update_setting')`, listens for updates to the chatbot's configuration settings. The listener takes in a JSON object that contains the name of the setting being updated (setting_name) and the new value for the setting (setting_value). The function then updates the corresponding value in the chatbot's configuration dictionary based on the setting_name. The updated setting is then sent to the client with a status flag indicating whether the update was successful.
|
||||||
|
|
||||||
|
The sixth decorator `@socketio.on('save_settings')`, listens for a request from the client to save the current chatbot settings to a file. When triggered, the save_settings function writes the current configuration dictionary to a file specified by self.config_file_path. Once the file has been written, the function sends a status flag indicating whether the save was successful to the client.
|
||||||
|
|
||||||
|
The available settings are:
|
||||||
|
|
||||||
|
- `temperature`: A floating-point value that determines the creativity of the chatbot's responses. Higher values will result in more diverse and unpredictable responses, while lower values will result in more conservative and predictable responses.
|
||||||
|
- `top_k`: An integer that determines the number of most likely tokens to consider at each step of generating a response. Smaller values will result in more conservative and predictable responses, while larger values will result in more diverse and unpredictable responses.
|
||||||
|
- `top_p`: A floating-point value between 0 and 1 that determines the probability mass threshold for including the next token in the generated response. Smaller values will result in more conservative and predictable responses, while larger values will result in more diverse and unpredictable responses.
|
||||||
|
- `n_predict`: An integer that determines the number of responses the chatbot generates for a given prompt.
|
||||||
|
- `n_threads`: An integer that determines the number of threads to use for generating responses.
|
||||||
|
- `ctx_size`: An integer that determines the maximum number of tokens to include in the context for generating responses.
|
||||||
|
- `repeat_penalty`: A floating-point value that determines the penalty for repeating the same token or sequence of tokens in a generated response. Higher values will result in the chatbot being less likely to repeat itself.
|
||||||
|
- `repeat_last_n`: An integer that determines the number of previous generated tokens to consider for the repeat_penalty calculation.
|
||||||
|
- `language`: A string representing the language for audio input.
|
||||||
|
- `personality_language`: A string representing the language to use for generating personality traits.
|
||||||
|
- `personality_category`: A string representing the category of personality traits to use for generating responses.
|
||||||
|
- `personality`: A string representing the name of a specific personality traits to use for generating responses.
|
||||||
|
- `model`: A string representing the model to use for generating responses.
|
||||||
|
- `binding`: A string representing the binding to use for generating responses.
|
||||||
|
|
||||||
|
The save_settings function is used to save the updated settings to a configuratio
|
||||||
|
|
||||||
|
|
||||||
|
## How to use:
|
||||||
|
|
||||||
|
Call from client side.
|
||||||
11
docs/index.md
Normal file
@ -0,0 +1,11 @@
|
|||||||
|
# Documentation
|
||||||
|
|
||||||
|
Here are some useful documents:
|
||||||
|
For developers:
|
||||||
|
- [Database information](dev/db_infos.md)
|
||||||
|
- [Full endpoints list](dev/full_endpoints_list.md)
|
||||||
|
|
||||||
|
Tutorials:
|
||||||
|
- [Noobs](tutorials/noobs_tutorial.md)
|
||||||
|
- [Personalities](tutorials/personalities_tutorial.md)
|
||||||
|
|
||||||
55
docs/tutorials/noobs_tutorial.md
Normal file
@ -0,0 +1,55 @@
|
|||||||
|
# GPT4ALL WebUI Tutorial
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
Welcome to the GPT4ALL WebUI tutorial! In this tutorial, we will walk you through the steps to effectively use this powerful tool. GPT4ALL WebUI is designed to provide access to a variety of language models (LLMs) and offers a range of functionalities to enhance your tasks.
|
||||||
|
|
||||||
|
## Installation
|
||||||
|
1. Ensure that you have Python 3.10 or a higher version, as well as Git, installed on your system. Confirm that the Python installation is in your system's path and can be accessed via the terminal. You can check your Python version by typing `python --version` in the terminal. If the version is lower than 3.10 or you encounter an error, please install a newer version.
|
||||||
|
2. If you are using Conda, you can create a Conda virtual environment, install the dependencies mentioned in the `requirements.txt` file, and run the application using `python app.py`. For regular Python installations, follow the next steps.
|
||||||
|
|
||||||
|
## Download and Launch the Tool
|
||||||
|
1. Visit the GitHub repository page at [github.com/ParisNeo/lollms-webui](https://github.com/ParisNeo/lollms-webui).
|
||||||
|
2. Click on the "Latest Release" button.
|
||||||
|
3. Depending on your platform, download either `webui.bat` for Windows or `webui.sh` for Linux.
|
||||||
|
4. Choose a folder on your system to install the application launcher. For example, you can create a folder named `gpt4all-webui` in your `ai` directory.
|
||||||
|
5. Run the downloaded script (application launcher). Note: Some antivirus programs or Windows Defender might display a warning due to the tool's reputation. This warning is a false positive caused by the tool being relatively new. You can ignore the warning and proceed with the installation.
|
||||||
|
6. The installer will no longer prompt you to install the default model. This step will be performed in the UI, making it easier for you.
|
||||||
|
|
||||||
|
## Exploring the User Interface
|
||||||
|
1. The UI provides both light mode and dark mode themes for your preference.
|
||||||
|
2. You can access the GitHub repository directly from the UI.
|
||||||
|
3. On the left side, you will find the discussions panel, and the center side displays the messages flow.
|
||||||
|
|
||||||
|
## Model Selection and Installation
|
||||||
|
1. To select and install a model for a specific binding, navigate to the "Settings" section.
|
||||||
|
2. Open the "Models Zoo" tab.
|
||||||
|
3. Choose a binding from the provided list. For example, select "llama-cpp-official".
|
||||||
|
4. The first time you select a binding, you need to wait as it gets installed. You can check the installation progress in the console.
|
||||||
|
5. After the installation is complete, click "Install" next to a model you want to use and wait for the installation process to finish.
|
||||||
|
6. Note that clicking "Apply Changes" does not save the configuration. To save the changes, click the "Save" button and confirm.
|
||||||
|
|
||||||
|
## Starting a Discussion
|
||||||
|
1. Return to the discussions view.
|
||||||
|
2. Click the "+" button to create a new discussion.
|
||||||
|
3. You will see a predefined welcome message based on the selected personality configuration. By default, the GPT4All personality is used, which aims to be helpful.
|
||||||
|
4. Enter your query or prompt. For example, you can ask, "Who is Abraham Lincoln?"
|
||||||
|
5. You can stop the generation at any time by clicking the "Stop Generating" button.
|
||||||
|
|
||||||
|
## Interacting with the Model
|
||||||
|
1. Once the generation is complete, you will see the generated response from the model.
|
||||||
|
2. You can fact-check the information provided by referring to reliable sources like Wikipedia, as models may sometimes generate inaccurate or fictional content.
|
||||||
|
3. You can give a thumbs-up or thumbs-down to the answer, edit the message, copy it to the clipboard, or remove it.
|
||||||
|
4. Note: The feature to have the message read by the AI will be added in the release version, using a locally stored library instead of a remote text-to-speech synthesizer.
|
||||||
|
|
||||||
|
## Managing Discussions
|
||||||
|
1. The discussions sidebar allows you to create, edit, and delete discussions.
|
||||||
|
2. When creating a new discussion, its initial name is "New Discussion." Once you enter your first message, the discussion title will be updated accordingly. You can edit the title or delete the discussion as needed.
|
||||||
|
3. All your discussions are stored in a local SQLite3 database located at `databases/database.db`. You can modify the database path in the `configs/local_config.yaml` file.
|
||||||
|
4. To facilitate finding specific discussions, a search button is provided. You can search for discussions using keywords.
|
||||||
|
5. When in check mode, you can select multiple discussions for exporting or deletion. Exporting messages can be useful for training purposes or contributing to data lakes.
|
||||||
|
6. Note: In the release version, it will be possible to change the database path directly from the UI.
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
Congratulations! You have learned how to install and use GPT4ALL WebUI effectively. Experiment with different bindings, models, and personalities to find the best fit for your needs. Remember to report any bugs or issues you encounter, as this project is developed by volunteers in their free time. Please support the project by liking, subscribing, and sharing this video to help it reach more people.
|
||||||
|
|
||||||
|
See you in the next tutorial!
|
||||||
85
docs/tutorials/personalities_tutorial.md
Normal file
@ -0,0 +1,85 @@
|
|||||||
|
# Personalities and What You Can Do with Them
|
||||||
|
|
||||||
|
In this tutorial, we will explore the concept of personalities and their capabilities within the GPT4All webui.
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
The GPT4All webui utilizes the PyAIPersonality library, which provides a standardized way to define AI simulations and integrate AI personalities with other tools, applications, and data. Before diving into the details, let's familiarize ourselves with some key concepts that will help us understand the inner workings of these tools.
|
||||||
|
|
||||||
|
## Large Language Models (LLMs)
|
||||||
|
|
||||||
|
Large Language Models (LLMs) are powerful text processing models known for their size and versatility in handling various text-based tasks. These models, characterized by their substantial parameter count, are primarily focused on text generation.
|
||||||
|
|
||||||
|
## Hardware and Software Layers
|
||||||
|
|
||||||
|
To generate text, LLMs require a hardware layer that consists of a machine running the code responsible for executing the model. This hardware typically includes a CPU and memory, and in some cases, a GPU for accelerated calculations.
|
||||||
|
|
||||||
|
On top of the hardware, there is a software layer that runs the LLM model. The model itself can be seen as a function with numerous parameters. For instance, chatGPT has around 175 billion parameters, while smaller models like LLama have around 7 billion parameters. Various models with different parameter counts are available, ranging from 13 billion to 64 billion parameters.
|
||||||
|
|
||||||
|
To reduce the size of these models, optimization techniques such as quantization and pruning are used. Quantization reduces numerical value precision in a neural network, leading to improved efficiency and reduced memory usage. Pruning, on the other hand, removes unnecessary connections or weights from a neural network, making it sparser and less computationally complex.
|
||||||
|
|
||||||
|
## Text Processing and Tokenization
|
||||||
|
|
||||||
|
Text processing begins with tokenization, which involves converting plain text into a series of integers representing the text's position in a vocabulary. Tokens can represent individual letters, complete words, word combinations, or even parts of words. On average, a token corresponds to approximately 0.7 words.
|
||||||
|
|
||||||
|
## Probability Distribution of Next Tokens
|
||||||
|
|
||||||
|
The LLM model determines the probability distribution of the next token given the current context. It estimates the likelihood of each token being the correct choice for the next position in the sequence. Through training, the model learns the statistical relationships between input tokens and the next token, enabling it to generate coherent text.
|
||||||
|
|
||||||
|
## Sampling Techniques
|
||||||
|
|
||||||
|
While the most likely next word can be chosen deterministically, modern models employ various sampling techniques to introduce randomness and enhance text generation. These techniques include:
|
||||||
|
|
||||||
|
1. **Sampling**: Stochastic selection of a token from the probability distribution based on a temperature parameter. Higher temperatures increase randomness, while lower temperatures favor more probable tokens.
|
||||||
|
2. **Top-k Sampling**: Selection of the top-k most likely tokens, narrowing down choices to a smaller set while maintaining a balance between randomness and coherence.
|
||||||
|
3. **Top-p (Nucleus) Sampling**: Selection of tokens from the smallest set whose cumulative probability exceeds a predefined threshold, dynamically choosing tokens for controlled yet varied generation.
|
||||||
|
4. **Repetition Penalty**: Assigning lower probabilities to recently generated tokens to discourage repetitive outputs.
|
||||||
|
|
||||||
|
These techniques enable language models to generate text with controlled randomness, avoiding repetition and striking a balance between exploration and coherence.
|
||||||
|
|
||||||
|
## Iterative Text Generation
|
||||||
|
|
||||||
|
The text generation process is iterative, with each step producing a new token based on the model's predictions. This process continues until an end-of-sentence (EOS) token is predicted or a maximum number of tokens is reached.
|
||||||
|
|
||||||
|
The "N predict" parameter in the tool's settings controls the maximum length of generated text, ensuring it remains within desired bounds and aligns with natural sentence boundaries.
|
||||||
|
|
||||||
|
## Customizing Personality Settings
|
||||||
|
|
||||||
|
While LLMs can generate text in a generic manner, personalities allow for customization and fine-tuning of the model's behavior. Personalities add a layer of simulation on top of the LLM, enabling the AI to simulate specific roles, perspectives, or expertise.
|
||||||
|
|
||||||
|
Personality settings are defined in a YAML file, which contains parameters and configurations for an AI agent. This file outlines the persona's characteristics, behavior, and responses to different inputs.
|
||||||
|
|
||||||
|
## The GPT for Art Personality
|
||||||
|
|
||||||
|
Let's take a closer look at the GPT for Art personality, which specializes in generating descriptions of artwork and even transforming descriptions into actual images using the stable diffusion generator.
|
||||||
|
|
||||||
|
To use the GPT for Art personality, you need to follow the custom installation steps outlined in the documentation. Once installed, you can leverage its capabilities through the GPT4All webui.
|
||||||
|
|
||||||
|
## Using the GPT4All Webui with the GPT for Art Personality
|
||||||
|
|
||||||
|
To select and apply a personality in the GPT4All webui, follow these steps:
|
||||||
|
|
||||||
|
1. Open the GPT4All webui and navigate to the "Personality" section.
|
||||||
|
2. Select the GPT for Art personality from the available options.
|
||||||
|
3. Start a conversation with the AI agent.
|
||||||
|
|
||||||
|
Let's go through an example discussion with the artbot:
|
||||||
|
|
||||||
|
**User**: "Imagine something cool."
|
||||||
|
|
||||||
|
**Artbot**: "I envision a vibrant cityscape at night, with towering skyscrapers illuminating the streets. The buildings are adorned with colorful neon lights that create a mesmerizing visual spectacle. The night sky is clear, revealing a dazzling display of stars. The atmosphere is buzzing with energy as people traverse the bustling streets, and music fills the air. It's a scene that captures the essence of urban vibrancy and excitement."
|
||||||
|
|
||||||
|
**User**: "That sounds amazing! Can you add some street art to the scene?"
|
||||||
|
|
||||||
|
**Artbot**: "Certainly! I can imagine talented graffiti artists leaving their mark on the city walls. They create intricate murals depicting a fusion of vibrant colors, abstract shapes, and thought-provoking imagery. Each artwork tells a unique story, contributing to the city's artistic character and cultural diversity."
|
||||||
|
|
||||||
|
By interacting with the AI agent, users can request specific changes or additions to the artwork, allowing for collaborative creativity between human and AI.
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
In this tutorial, we explored the concept of personalities and their integration within the GPT4All webui. We discussed the hardware and software layers, text processing and tokenization, sampling techniques, iterative text generation, and the customization of personality settings.
|
||||||
|
|
||||||
|
We also delved into the GPT for Art personality, its installation steps, and how to apply it in the GPT4All webui. Through an example discussion with the artbot, we witnessed the collaborative creative process between users and AI.
|
||||||
|
|
||||||
|
The GPT4All webui, coupled with AI personalities, opens up a world of possibilities for generating personalized and contextually relevant text. With further enhancements and customization, these tools have the potential to revolutionize various industries and creative endeavors.
|
||||||
|
|
||||||
168
docs/usage/AdvancedInstallInstructions.md
Normal file
@ -0,0 +1,168 @@
|
|||||||
|
## Windows 10 and 11
|
||||||
|
|
||||||
|
> **Note**
|
||||||
|
>
|
||||||
|
>It is mandatory to have python [3.10](https://www.python.org/downloads/release/python-31010/) (The official one, not the one from Microsoft Store) and [git](https://git-scm.com/download/win) installed.
|
||||||
|
|
||||||
|
### Prerequisites
|
||||||
|
|
||||||
|
Before you continue make sure you have these aditional applications installed:
|
||||||
|
|
||||||
|
Lately some bindings use Nvidia GPU (CUDA) for computing and is 3x faster than CPU. In order to run these bindings on CUDA device, you will need to install cuda toolkit.
|
||||||
|
|
||||||
|
- [Nvidia CUDA toolkit 11.7 or higher](https://developer.nvidia.com/cuda-downloads)
|
||||||
|
|
||||||
|
For CUDA and other packages to be compiled you will also need C++ build tools. The easiest way is to download Visual studio community. Make sure you choose C++ build tools at the installation screen.
|
||||||
|
|
||||||
|
- [Visual Studio Community](https://visualstudio.microsoft.com/vs/community/)
|
||||||
|
|
||||||
|
After these two are installed make sure to reboot your system before continuing.
|
||||||
|
|
||||||
|
### Manual Simple install:
|
||||||
|
|
||||||
|
1. Download this repository .zip:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
2. Extract contents into a folder.
|
||||||
|
3. Install/run application by double clicking on `webui.bat` file from Windows Explorer as normal user.
|
||||||
|
|
||||||
|
### Manual Advanced mode:
|
||||||
|
|
||||||
|
1. Install [git](https://git-scm.com/download/win).
|
||||||
|
2. Open Terminal/PowerShell and navigate to a folder you want to clone this repository.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ParisNeo/lollms-webui.git
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Install/run application by double clicking on `webui.bat` file from Windows explorer as normal user and follow the on screen instructions.
|
||||||
|
|
||||||
|
## Linux
|
||||||
|
|
||||||
|
### Prerequisites
|
||||||
|
|
||||||
|
> **Note**
|
||||||
|
>
|
||||||
|
>This was tested on Ubuntu 22.04 or higher.
|
||||||
|
|
||||||
|
Before you continue make sure you have these aditional applications installed:
|
||||||
|
|
||||||
|
Lately some bindings use Nvidia GPU (CUDA) for computing and is 3x faster than CPU. In order to run these bindings on CUDA device, you will need to install cuda toolkit.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo apt install nvidia-cuda-toolkit
|
||||||
|
```
|
||||||
|
|
||||||
|
For CUDA and other packages to be compiled you will also need C++ build tools. The easiest way is to download Visual studio community. Make sure you choose C++ build tools at the installation screen.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo apt install build-essential
|
||||||
|
```
|
||||||
|
|
||||||
|
After these two are installed make sure to reboot your system before continuing.
|
||||||
|
|
||||||
|
### Automatic install
|
||||||
|
|
||||||
|
1. Make sure you have installed `curl`. It is needed for the one-liner to work.
|
||||||
|
|
||||||
|
`Debian-based:`
|
||||||
|
```
|
||||||
|
sudo apt install curl
|
||||||
|
```
|
||||||
|
`Red Hat-based:`
|
||||||
|
```
|
||||||
|
sudo dnf install curl
|
||||||
|
```
|
||||||
|
`Arch-based:`
|
||||||
|
```
|
||||||
|
sudo pacman -S curl
|
||||||
|
```
|
||||||
|
2. Open terminal/console copy and paste this command and press enter:
|
||||||
|
```
|
||||||
|
mkdir -p ~/lollms-webui && curl -L https://raw.githubusercontent.com/nomic-ai/lollms-webui/main/webui.sh -o ~/lollms-webui/webui.sh && chmod +x ~/lollms-webui/webui.sh && cd ~/lollms-webui && ./webui.sh
|
||||||
|
```
|
||||||
|
> **Note**
|
||||||
|
>
|
||||||
|
> This command creates new directory `/lollms-webui/` in your /home/ direcory, downloads a file [webui.sh](https://raw.githubusercontent.com/nomic-ai/lollms-webui/main/webui.sh), makes file executable and executes webui.sh that downloads and installs everything that is needed.
|
||||||
|
|
||||||
|
3. Follow instructions on screen until it launches webui.
|
||||||
|
4. To relaunch application:
|
||||||
|
```
|
||||||
|
bash webui.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
### Manual Simple install:
|
||||||
|
|
||||||
|
1. Download this repository .zip:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
2. Extract contents into a folder.
|
||||||
|
3. Install/run application from terminal/console:
|
||||||
|
```
|
||||||
|
bash webui.sh
|
||||||
|
```
|
||||||
|
### Manual Advanced mode:
|
||||||
|
|
||||||
|
1. Open terminal/console and install dependencies:
|
||||||
|
|
||||||
|
`Debian-based:`
|
||||||
|
```
|
||||||
|
sudo apt install curl git python3 python3-venv
|
||||||
|
```
|
||||||
|
`Red Hat-based:`
|
||||||
|
```
|
||||||
|
sudo dnf install curl git python3
|
||||||
|
```
|
||||||
|
`Arch-based:`
|
||||||
|
```
|
||||||
|
sudo pacman -S curl git python3
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Clone repository:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ParisNeo/lollms-webui.git
|
||||||
|
```
|
||||||
|
```bash
|
||||||
|
cd lollms-webui
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Install/run application:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
bash ./webui.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
## MacOS
|
||||||
|
|
||||||
|
1. Open terminal/console and install `brew`:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Install dependencies:
|
||||||
|
|
||||||
|
```
|
||||||
|
brew install git python3
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Clone repository:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ParisNeo/lollms-webui.git
|
||||||
|
```
|
||||||
|
```bash
|
||||||
|
cd lollms-webui
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Install/run application:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
bash ./webui.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
On Linux/MacOS, if you have issues, refer to the details presented [here](docs/Linux_Osx_Install.md)
|
||||||
|
These scripts will create a Python virtual environment and install the required dependencies. It will also download the models and install them.
|
||||||
@ -27,7 +27,7 @@ version: 1.0
|
|||||||
# UI metadata
|
# UI metadata
|
||||||
has_ui: true
|
has_ui: true
|
||||||
|
|
||||||
# backend metadata
|
# binding metadata
|
||||||
can_trigger_the_model :
|
can_trigger_the_model :
|
||||||
|
|
||||||
# Conditionning override
|
# Conditionning override
|
||||||
BIN
docs/youtube/scheme.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
73
docs/youtube/script_install.md
Normal file
@ -0,0 +1,73 @@
|
|||||||
|
Hi there. Today I finally make a presentation of the new alpha version of GPT4ALL webui.
|
||||||
|
Join us as we dive into the features and functionalities of this new version.
|
||||||
|
|
||||||
|
First, I want to thank all of you for your support. We have reached 2.1k stars on github And I hope you continue spreading the word about this tool to give it more visibility.
|
||||||
|
|
||||||
|
If not done yet, and if you think this project is useful, please consider gifting a star to the project, that helps alot.
|
||||||
|
|
||||||
|
Before starting, let me tell you what this project is made for. This project is aimed to be a hub to all LLM models that people can use. You will be able to choose your preferred binding, your preferred model, and your preferred or needed personality then have it do what you need. Help you enhance your mails, help you write an essai, help you debug a code, help you organize your thoughts, help you find answers to your questions, search for you, organize your data, generate images for you, discuss with you about things. And much more.
|
||||||
|
|
||||||
|
|
||||||
|
This project is under Apache 2.0 licence which is an open source licence that can be used commercially, so people can built things from this and use it in their business.
|
||||||
|
|
||||||
|
Also, please don't confuse the GPT4All application built by Nomic AI which is an interesting more professional application that you can find on their website gpt4all.io. It has a great community and I encourage you to check it up.
|
||||||
|
|
||||||
|
I have built this ui to explore new things and build on top of it. I am not building a company out of this, this is a side project. I just want to give back to the open source community and help make this technology available for all (hence the name).
|
||||||
|
|
||||||
|
I think all the contributors to this project and hope more people come and share their expertise. This help is vital to enhance the tool for all man kind.
|
||||||
|
|
||||||
|
Before installing this tool you need to install python 3.10 or higher as well as git. Make sure the python installation is in your path and you can call it from a terminal. To verify your python version, type python --version. If you get an error or the version is lower than 3.10, please install a newer version and try again. For those who use conda, you can create a conda virtual environment, install the requirements.txt content and just run the application using python app.py. Now we assume that you have a regular python installation and just want to use the tool.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Now let's cut to the chace. Let's start by installing the tool.
|
||||||
|
First, go to the github repository page at github.com/ParisNeo/lollms-webui then press the latest release button. Depending on your platform download webui.bat for windows or webui.sh for linux.
|
||||||
|
|
||||||
|
We call this file, the application launcher. Make sure you install the launcher in a folder you choose. For example I'll put it in my ai folder at gpt4all-webui.
|
||||||
|
|
||||||
|
Now let's run the script.
|
||||||
|
You may encounter a warning from some antivirus or windows defender warining you about the script. It is a false positive caused by the reputation condition in some antiviruses. This means if a program is not used by enough users, some antiviruses consider it dangerous. This is true for this tool as it is new and not enough people as using it as of now so I have to wait for it to become more accepted.
|
||||||
|
|
||||||
|
You may notice that the installer does not prompt you to install the default model any more as we now do this in the ui which is way easier.
|
||||||
|
|
||||||
|
Now let's take a look at the new ui. As the previous one, you have a light mode and a dark mode. You also have direct access to the github repository.
|
||||||
|
|
||||||
|
On the left side, you have the discussions panel, and on the center side, you have the messages flow.
|
||||||
|
|
||||||
|
Before starting to use the tool, we need to download a model for a specific binding.
|
||||||
|
To do this, go to settings. Then open the models zoo tab.
|
||||||
|
You need to select a binding from the list. For example the llama-cpp-official. The first time you select a binding, you have to wait as it is being installed. You can look it up in the console.
|
||||||
|
|
||||||
|
Once the installation is done, you should install a model by pressing install and waiting for it to finish.
|
||||||
|
This may take some time.
|
||||||
|
|
||||||
|
Once the model is installed, you can select it and press Apply changes.
|
||||||
|
|
||||||
|
Notice that applying modifications does not save the configuration, so You need to press the save button and confirm.
|
||||||
|
|
||||||
|
Now your model is selected and you are ready to start your first discussion.
|
||||||
|
|
||||||
|
Let's go back to discussions view. To create a new discussion, press the + button. You should see the personality welcome message. This is a predefined welcome message that you can find in the personality configuration file. by default, we use the GPT4All personality which is conditioned to be a helpful personality. Let's ask it something. For example, who is Abraham Lincoln?
|
||||||
|
|
||||||
|
You can stop the generation at any time by pressing the Stop Generating button.
|
||||||
|
|
||||||
|
Now that the generation is done, we can see that it did a good job. In fact there is a little generation starting time at the beginning, but one it starts, you get around two words a second depending on your pc or mac configuration. As this is a discussion, we can follow up by asking to give more details.
|
||||||
|
|
||||||
|
You can see that the model did give a more detailed text about Abraham Lincoln. You can fact check the information on wikipedia, as those models may sometimes hallucinate or invent things that are not true. It depends on the quality of the data used to train the model and to fine tune it. Some models are better than others. You can test by yourself to choose the best model for your needs. This is one of the advantages of being able to test multiple bindings and multiple models.
|
||||||
|
|
||||||
|
|
||||||
|
Just as previous version, you can give the answer a thumb up or a thumb down, you can also edit the message, copy the message to the clip board, and remove the message. Notice that we removed the option to have the message read by the AI, but this feature should be added in the release version. I think of giving different voices to each personality and use a fullly local library as the previous version used a remote text to speach synthesizer. Our phylosophy is, your data should stay on your PC and never be sent out unless you explicitly do it yourself.
|
||||||
|
|
||||||
|
|
||||||
|
Now let's focus on the discussions sidebar. As we saw, we can create new discussion. When you create a new discussion, its name is always new discussion, but as soon as you put your initial prompt, the discussion title take the first message you typed as the title. You can edit the title at any time, or delete the discussion. All your discussions are stored in a local sqlite3 database on your databases/database.db file. You can change the database path in your configs/local_config.yaml file. We will make this possible from the UI in the release version.
|
||||||
|
|
||||||
|
In chat-GPT ui, one complaint I have is the difficulty to find out your discussion after days of discussions. So we have thought this up by adding a search button that allows you to search your discussions at any time. You can also delete multiple discussions or export them. Exporting messages may be interesting for training, but also for contributing to datalakes to help the community get more quality data. you can do any multi-discussions operation by pressing the check mode button. now you can select one or many discussions then you can export them or delete them.
|
||||||
|
|
||||||
|
In this tutorial we have seen how to install the new ui, how to select a binding, download and select a model, how to start a discussion and follow up with more details, how to manipulate discussions.
|
||||||
|
In the next tutorial we will take a look at the personalities zoo and all the 250 personalities that you can interact with.
|
||||||
|
|
||||||
|
Thank you very much for your attention. I hope you like this tool, test it, share your experience with it and report bugs. This is an amateur project, so don't be harsh on us as we do this in our free time.
|
||||||
|
|
||||||
|
Don't forget to hit like and subscribe and share the video if you want it to reach more people.
|
||||||
|
|
||||||
|
See ya
|
||||||
97
docs/youtube/script_lollms.md
Normal file
@ -0,0 +1,97 @@
|
|||||||
|
Hi Every one.
|
||||||
|
This is a new video about Lord of Large language models, formally known as GPT4All webui.
|
||||||
|
|
||||||
|
In this video, we start by presenting the tool, its phylosophy and it's main goals. Then, we discuss how to install and use it, we dive deep into its different use cases and how you can harness the power of Large language models in one tool. We will also do some interesting tests and comparisons of models and bindings, and we'll finish by some thoughts about AI, its benefits and dangers.
|
||||||
|
|
||||||
|
To start, I have changed the name of the tool to confirm its identity as a separate free project that aims at supporting all those open source libraries for large language models.
|
||||||
|
|
||||||
|
The slogan is: One tool to rule them all. This tool uses multiple opensource libraries built by various developers from all around the world and creates a unique interface to talk to all of them in three different ways:
|
||||||
|
First, you can use lollms as a library in a python project
|
||||||
|
Second, you can use the socket-io API to trigger text generation from any program capable of talking to socket-io services. This covers a very large number of languages such as javascript, c#, c++ etc.
|
||||||
|
The third use is by directly using out web-ui to interact with the language models.
|
||||||
|
The web-ui has multiple functionalities and allow you to handle many tasks.
|
||||||
|
|
||||||
|
Now let's install the application.
|
||||||
|
To install the application, you need to have already installed git and python 3.10 with its pip package manager. You can optionally have anaconda or miniconda installed if you want to use that option. To use the GPU, you also need to install Cuda toolkit v 11.7 or higher or use the conda installation script that will automatically install conda build tools. Make sure git, python and cuda are added to your path environment variable and let's begin.
|
||||||
|
As usual, go to the github repository then to the release page. Now you have many options depending on your system and your preference. for windows, you can use webui.bat or c_webui.bat, for linux, you can use webui.sh or c-webui.sh. C stands for conda, so if you havn't installed conda, don't use that file.
|
||||||
|
|
||||||
|
Download the file to a folder where you want to install the application.
|
||||||
|
|
||||||
|
Once it is downloaded, go to the folder and double click the script to run it.
|
||||||
|
Now just follow the instructions.
|
||||||
|
The tool start by cloning the project into a subfolder called lollms-webui.
|
||||||
|
If you don't have conda, this will ask you if you want to install it. I already have conda, so it will just create a conda environment in the lollms-webui/env folder and will install every thing in there. This is to ensure that your system is not polluted with useless libraries if ever you want to delete this tool.
|
||||||
|
When you are asked to install cuda, the answer depends on your system. If you have an nvidea GPU accept, otherwize refuse.
|
||||||
|
You will be asked to select a personal folder. This folder will contain:
|
||||||
|
- the bindings zoo
|
||||||
|
- the installed models
|
||||||
|
- the personalities zoo
|
||||||
|
- the configurations
|
||||||
|
- the data files
|
||||||
|
- the outputs of the models which can be text, images, or even executable code etc
|
||||||
|
- the configuration files
|
||||||
|
- the discussion database
|
||||||
|
Make sure to put this folder to a partition that has enough space as models may be heavy sometimes.
|
||||||
|
Here I just press enter to choose the default location which is my documents folder.
|
||||||
|
The first time you run this application, you are prompted to select the binding. bindings are bridge modules that allows lollms to talk to different libraries that can run language models. If you are using a mac, I would recommend using gpt4all binding. If you have a powerful GPU and want to use as many models as possible then you go with ctransformers. The fastest for llama models is the official llama cpp binding. The Pyllamacpp is a tiny stable binding that runs with only llama models but can run on any pc seamlessly. As of today, GPTQ binding can run but it is still in experimental stage. Maybe use it in few weeks. I have a GPU, and want to test many models, so I'll go with CTransformers.
|
||||||
|
This may take few minutes to complete as it should install many modules.
|
||||||
|
Let's fastforward.
|
||||||
|
Once the binding is installed, you need to select a first model. You have the choice between installing a model from the internet or link to a local model file. This allows you tu mutualize models with other tools like Gpt4all or oobbabooga's text generation webui.
|
||||||
|
Let's choose to install a model from internet.
|
||||||
|
I advise you to checkout TheBlokes's hugging face space as he has a huge library of quantized models that you can download and use. Let's select a small model.
|
||||||
|
C Transformers is compatible with GGML models. So make sure you select a GGML one. Let's go with a very tiny orca mini 3B model quantized to 4 bits.
|
||||||
|
Copy and paste the model link to the console then press enter.
|
||||||
|
Downloading the model takes some time, so let's fast forward.
|
||||||
|
Once the model is downloaded, you can select it.
|
||||||
|
Now open your browser at the shown address. The default one is localhost:9600. You can change the address or port in the configuration file that you can find in your personal folder / configs / local_config.yaml. if you put 0.0.0.0 all your ip addresses will expose the ui. Make sure you use this in trustworthy networks as people may have access to your discussions. To stay safe, just use localhost to force a local use. The remote use may be useful if you want to use the app on your phone or another low power terminal. I will show you later how you can use multi servers / clients with secure access while keeping your data private without exposing them.
|
||||||
|
Now to start a conversation, just press + and start typing your prompt to the ai in the input area. you validate either by pressing enter, or by pressing the validation button. You can make a multiline prompt by holding shift key and pressing enter.
|
||||||
|
Let's ask it to make a short love story.
|
||||||
|
As you can see, the ai did come up with something. This model is very very small, so don't expect it to have a high peformance.
|
||||||
|
Now let's install a littble bit bigger model like the Falcon 7B.
|
||||||
|
To do this, we go to settings tab.
|
||||||
|
There are many changes since last time. Now you can monitor disk usage as well as both ram and v-ram usages if you have a cuda enabled GPU.
|
||||||
|
You can also install more bindings and select them as well as updating their configuration from the ui.
|
||||||
|
Check out the new models zoo. There are many many models out there. Feel free to try some of them to find which one fits you better.
|
||||||
|
Now let's find our falcon 7B model. For now the search option is not yet implemented but it is going to be implemented next week, so stay tuned.
|
||||||
|
|
||||||
|
Let's select a 4 bits quantization which is a good ratio between size and performance.
|
||||||
|
Press install and wait for it to download the model. You can install multiple models simultaniously. Make sure you have enough disk space as some of those models are very big.
|
||||||
|
Now let's take a look at the new personalities system.
|
||||||
|
The new system allows us to mount multiple personalities in the same session. This means that we can create a multipersonalities discussion.
|
||||||
|
There are many categories for english language. I will probably create more languages in the future and translate those personality files.
|
||||||
|
There are in total over 260 personalities in different fields and sorts. You can checkout the Job category where you cvan find multiple personalities.
|
||||||
|
We can activate personalities like shoping in a mall. Those personalities will be loaded at startup and will be easily accessible in the mounted personalities list.
|
||||||
|
Most personalities just have a yaml conditioning file and a logo in the assets folder. But some other personalities are more advanted with behavior and configuration parameters. Here we are going to show simple conversational personalities.
|
||||||
|
You can either use the personalities category organization or the search bar.
|
||||||
|
Once you finish mounting personalities, you can start a conversation. Here we talk to Einstein.
|
||||||
|
Let's ask it to teach us relativity.
|
||||||
|
To select another personality to interact with Einstein, just go to the settings page and select the personality you want to use. We are developing fast access to personalities in the main discussion page, it should be out in few days from now.
|
||||||
|
Let's select Jack Sparrow.
|
||||||
|
To trigger generation, just press the refresh button from previous message and the tool will use your active personality to generate the next mesasge. you can go on doing this and exploring possible interactions between AI-s.
|
||||||
|
|
||||||
|
Few days have passed and now the personality system has been enhanced. Let's start by mounting personalities to use in a multipersonalities conversation.
|
||||||
|
|
||||||
|
|
||||||
|
Let's talk to empror Napoleon Bonaparte and ask it about his plans after conquering Egypt.Now, as you can see, you have a new module in the ui that shows the current personality icon. When we press the + button, we can select the personality to talk to.
|
||||||
|
|
||||||
|
With this, we can make personalities talk to each other by selecting next personality and pressing the regenerate answer button. This will be refined in the future. It is still a work in progress but the feature is pretty much usable right now. You can explore impossible discussions between personalities that never lived in the same era, never spoken the same language and sometimes the discussions get really interesting. Be aware that the quality of the discussions depend heavily on the model you use. You can view which model was used to generate each message as well as time needed to generate the answer. Feel free to explore these things and share your findings on internet.
|
||||||
|
|
||||||
|
Now let me show you this new binding made for those who have a network with a powerful pc or server and many low grade PCs or terminals. We can use this new binding to create a text generation service for all those little PCs which is really interesting if you have a company and want to keep your data local while investing in only a handful of nodes, servers or high end PCs and give the text generation service to all your workers. This can also be done at home where you may have a PC with GPU and few laptops or raspberry pi that can benefit from the text generation service on your PC. I personally do that and it is a great trade off allowing for mutualization of resources.
|
||||||
|
|
||||||
|
First we need to install the lollms library and run the lollms server. go to the console and type:
|
||||||
|
pip install --upgrade lollms
|
||||||
|
This will install the library along with the server, a console generation tool and a settings tool.
|
||||||
|
Once the installation is done, just run lollms-server and follow the instruction. The first time you use it, it will ask for the path to your personal data folder. You can use the same folder as the webui if you want to mutualize your models and settings. The server bindings and model names are exclusive to each application. This is logical as if you want to use the lollms remote nodes for the client, you would use another binding for the server. In fact the server configuration file has a prefix lollms_server.
|
||||||
|
|
||||||
|
Now we need to come back to our web-ui and configure the servers we want to use. Here we used a local server, so we just use its name as http://localhost:9601 but you can run the server on a different PC. Just make sure you run the lollms-server with the option --host 0.0.0.0 which will expose the server on all ip adresses of your PC. You can also specify the IP address. You can run multiple servers on the same node by changing the port number using --port parameter of the lollms-server. You can also add multiple server paths in the configuration by separating them using a comma. Make sure this parameter is a list of strings put inside brackets just as in python.
|
||||||
|
|
||||||
|
You can view in the console what servers are active at the moment. You can choose to completely remove the inactive servers from the list for the current session or to continue trying to connect to them whenever a new generation is attempted.
|
||||||
|
|
||||||
|
Now that our remote service is up, we can use it as we use any local binding.
|
||||||
|
Let's ask Carl sagan what is cosmos.
|
||||||
|
|
||||||
|
If we look at the Lollms console, we can see that it got the prompt and is generating the words.
|
||||||
|
|
||||||
|
As you can see, generative AI has a huge potential to help us enhance our productivity. This tool is a little glimpse of what AI models especially generative models are capable of. AI is a tool, it can be used for good, as for bad. I hope you use this tool wizely and bare in mind that the future of humanity may depend on how we use these technologies. It is now impossible to stop AI development but we should tame it and make sure that its goals are aligned with ours. It can lead us to a bright future where we fix urgent problems like climate change and resource depletion, where we aceive great science discoveries, like building a better physics theory that can fuse quantum physics and general relativity. Or it can lead us to a dark world where AI empowers a handful of ritch people and enslaves the rest. I personally think that open source is the way to ensure fair access to every one to those tools.
|
||||||
|
|
||||||
|
I hope that you have liked this video. If you did, please consider leaving a thumb up, a sub to the channel and a comment. Thank you for watching. C ya
|
||||||
7
docs/youtube/script_models.md
Normal file
@ -0,0 +1,7 @@
|
|||||||
|
Hi there, welcome to a snippet about bindings and models selection.
|
||||||
|
|
||||||
|
In this short video we will look at bindings and models, how to select them and how to use them.
|
||||||
|
|
||||||
|
First, to select a binding, go to the settings tab then Bindings zoo.
|
||||||
|
|
||||||
|
You will find a certain numbre of bindings. Each binding as built by a person or a team. Make sure to visit their
|
||||||
174
docs/youtube/script_personalities.md
Normal file
@ -0,0 +1,174 @@
|
|||||||
|
Hi there. In this video, we are going to talk about the personalities and what you can do with them.
|
||||||
|
|
||||||
|
The GPT4All webui uses my PyAIPersonality library under the hood. I have buit this library to create a standard way to define AI simulations and integrate the AI personality with other tools, applications and data. Before starting, I want to explain some concepts to make it easy for you to understand the inner workings of these tools. Let's dive right in.
|
||||||
|
|
||||||
|
Large Language Models (LLMs) are powerful text processing models based on machine learning techniques. As their name suggests, these models are characterized by their substantial size and versatility in handling various text-based tasks. In the context of this work, we focus specifically on text generation models.
|
||||||
|
|
||||||
|
To generate text, we first need a hardware layer, which is simply the physical machine running the code that executes the model. The hardware has at least a CPU and some memory to store the data while processing the text but can also have a GPU to accelerate some calculations.
|
||||||
|
|
||||||
|
On top of the hardware there is a software that is running the model. The model can be seen as a giant function with many parameters. chatGPT for example has around 175 billion parameters while a typical LLama based small model has around 7 billion parameters. There are also models with 13 Billion parameters, 30 billion parameters and 64 billion parameters.
|
||||||
|
|
||||||
|
To reduce the size of those model we use some optimization techniques like quantization and pruning.
|
||||||
|
Quantization reduces the precision of numerical values in a neural network to lower bit widths, improving computational efficiency and reducing memory usage.
|
||||||
|
Pruning removes unnecessary connections or weights from a neural network, making it sparser and reducing computational complexity, while often requiring fine-tuning to maintain performance.
|
||||||
|
|
||||||
|
Let's do a quick refresher to remind how the model works.
|
||||||
|
|
||||||
|
In the initial step of text processing, a sequence of text undergoes tokenization, which involves converting it from plain text into a series of integers that correspond to the text's position within a comprehensive vocabulary. As mentioned in a previous video, a token can represent individual letters, complete words, word combinations, or even parts of words, such as "automobile" being represented by two tokens: "auto" and "mobile." This intelligent approach efficiently represents text. On average, a token corresponds to approximately 0.7 words.
|
||||||
|
|
||||||
|
The model itself determines a distribution probability of the next token given the current state of the context. Basically, given the previous text. The distribution probability of the next token refers to the probability distribution over the vocabulary of possible tokens at a given step in a sequence generation task. It represents the model's estimation of the likelihood of each token being the correct or appropriate choice for the next position in the sequence.
|
||||||
|
|
||||||
|
During the training step, the model looks at chunks of text and tryes to update its weight to give a better prediction of the next token. It learns the statistical relationships between the input tokens list and the next token which leads to the ability to generate coherant text.
|
||||||
|
|
||||||
|
|
||||||
|
To illustrate this concept, let's consider an example. Suppose we start with the word "I." At this point, there are numerous possible next words that could follow. However, by leveraging the knowledge and patterns learned from extensive training on a vast corpus of text, we can rank these potential next words based on their likelihood in the given context.
|
||||||
|
|
||||||
|
For instance, if we determine that the most probable next word after "I" is "am," we update our context to "I am." As a result, the likelihood of "am" being repeated as the next word diminishes significantly, and other words like "happy" or "hungry" become more probable in this new context.
|
||||||
|
|
||||||
|
The dynamic nature of the likelihood distribution for the next tokens is a fundamental aspect of language modeling. As more context is provided, the distribution of probable next words undergoes constant adjustments. This adaptability is precisely what the training step aims to enhance. By leveraging advanced techniques like the attention mechanism, the model learns the intricate relationships between words and becomes better at predicting the next token with greater accuracy.
|
||||||
|
|
||||||
|
For a more comprehensive understanding of these mechanisms, I recommend referring to the "Attention is all you need" paper by Google, which delves into the details of the attention mechanism and its role in improving language modeling capabilities.
|
||||||
|
|
||||||
|
One may ask, if we always select the most likely next word, how are these model capable of generating different outputs from the same input?
|
||||||
|
|
||||||
|
As we discussed earlier, the language model determines the probability distribution of the next token. However, when it comes to selecting the next word, we rely on additional algorithms. While choosing the most likely word leads to a deterministic output, modern models employ various techniques such as sampling, top-k sampling, top-p (nucleus) sampling, and even apply repetition penalty to enhance the generated text.
|
||||||
|
|
||||||
|
Sampling introduces an element of randomness during token selection. It involves stochastically drawing a token from the probability distribution based on a temperature parameter. A higher temperature (e.g., 1.0) increases randomness, resulting in diverse outputs. Conversely, a lower temperature (e.g., 0.5) makes the distribution sharper, favoring more probable tokens and yielding more focused outputs.
|
||||||
|
|
||||||
|
Top-k sampling restricts the selection to the top-k most likely tokens, where k is a predefined value. Instead of considering the entire distribution, it narrows down the choices to a smaller set, maintaining a balance between randomness and coherence.
|
||||||
|
|
||||||
|
Top-p (nucleus) sampling, also known as "soft" or "weighted" sampling, takes into account a cumulative probability threshold, usually referred to as p. It selects from the smallest possible set of tokens whose cumulative probability exceeds p. This approach allows for dynamic selection of the token set, ensuring a varied yet controlled generation process.
|
||||||
|
|
||||||
|
Moreover, repetition penalty is a technique used to discourage repetitive outputs. It assigns lower probabilities to tokens that have been recently generated, reducing the likelihood of repetition and promoting more diverse and coherent text.
|
||||||
|
|
||||||
|
By combining these techniques, language models can generate text that exhibits controlled randomness, avoids repetitiveness, and strikes a balance between exploration and coherence.
|
||||||
|
|
||||||
|
Now that we have our next token, all we need to do is detokenize it and add it to our context.
|
||||||
|
|
||||||
|
In our text generation process, we repeat this procedure until we encounter either the model predicting an end-of-sentence (EOS) token or reaching the maximum number of allowed tokens, which we refer to as the "N predict" parameter in our tool.
|
||||||
|
|
||||||
|
This iterative approach ensures that the generated text remains within predefined length constraints and aligns with natural sentence boundaries. By incorporating the EOS token as a stopping criterion, we signify the completion of a coherent sentence or text snippet.
|
||||||
|
|
||||||
|
The "N predict" parameter in our tool enables users to control the generated text's length, avoiding excessive length or truncation while maintaining desired content and brevity.
|
||||||
|
|
||||||
|
Now you understand each one of the parameters that you can control in our UI. Let's take a look at these. First go to the settings tab and scroll down to model configuration section.
|
||||||
|
|
||||||
|
As you observe, the parameters we discussed are integral to our system. By default, these parameters are not customizable, as our personalized system ensures the appropriate configuration for each personality. We recognize that different personalities may require varying levels of creativity or determinism, and this responsibility lies with the personality settings.
|
||||||
|
|
||||||
|
However, we provide an override checkbox option that empowers you to modify and override the default personality settings, granting you the flexibility to adjust the parameters according to your specific needs and preferences. This checkbox serves as a means to deviate from the predefined settings, giving you greater control over the generated output.
|
||||||
|
|
||||||
|
Let's get back to our diagram. Now we have an AI that has the possibility to generate text sequentially based on its experience acquired during the training process. But how can this seamingly dump process lead to a tool that can solve complex tasks like generating stories and do some basic reasoning?!
|
||||||
|
|
||||||
|
At the heart of this process lies the simulation layer, a meta layer comprising the text itself. The ingenious trick is to leverage the power of text to condition subsequent generations, infusing them with contextual relevance. This is achieved through an initial text, known as the model conditioning, which establishes the foundation for the generation process and sets the plot.
|
||||||
|
|
||||||
|
By employing the model conditioning, we enable the generation process to align with specific contexts, facilitating coherent and tailored outputs. This dynamic approach harnesses the rich potential of text to shape subsequent generations, ultimately enhancing the overall quality and relevance of the generated content.
|
||||||
|
|
||||||
|
|
||||||
|
Allow me to provide you with an illustrative example. Suppose I present the model with a math question and instruct it to solve the problem. I would provide the math problem, followed by specific instructions such as "solve this problem," and then proceed to include the prefix, "solution:", before feeding the text to the AI.
|
||||||
|
|
||||||
|
The AI, leveraging its prior knowledge acquired during training and utilizing the given context, will determine the appropriate response. The generated answer is generally coherent, although it may occasionally contain errors or take the form of a disclaimer, such as "I am a machine learning program and cannot solve math problems." This outcome depends on the training process and the alignment phase of the model, which may influence the model's readiness or inclination to perform certain tasks.
|
||||||
|
|
||||||
|
While we won't delve into the intricacies of the alignment phase in this video, it is a crucial step that aligns the model to the specific task we desire it to perform. Through this alignment phase, the model can learn to recognize the scope and limitations of its abilities, leading to informed decisions regarding task completion.
|
||||||
|
|
||||||
|
By combining the context provided and the model's training, we can explore the model's capabilities in generating responses to math questions or other tasks, while being mindful of the alignment process that shapes its behavior and responses.
|
||||||
|
|
||||||
|
In PY AI Personalities library, the generation text is composed of a fixed Condutionning text, and an incremental discussion messages text. The discussion messages text in our application is in the form of a multi turns discussion. Each time we add a user prefix text such as, "### User:", followed by the user prompt, a link text (generally, a simple return to the line character), followed by the AI prefix, such as "### AI:". Then we feed this to the model that generates the AI text.
|
||||||
|
|
||||||
|
At the end, we add the messages to the previous messages text and we continue as the user interacts with the AI.
|
||||||
|
|
||||||
|
It's important to acknowledge that the AI has the potential to continue generating predictions for the rest of the discussion, including anticipating the user's future requests. This phenomenon is known as hallucination. To address this issue, we have implemented a hallucination suppression system designed to detect instances where the model predicts the user's next prompt and intervene to prevent it from persisting further.
|
||||||
|
|
||||||
|
By employing this suppression system, we aim to ensure that the AI remains within the desired boundaries and avoids venturing into speculative or inaccurate territory. This protective mechanism helps maintain a more controlled and focused conversation, preventing the AI from generating misleading or unrelated information based on its own projections.
|
||||||
|
|
||||||
|
The implementation of the hallucination suppression system enables a more reliable and coherent interaction, allowing users to have meaningful and productive exchanges with the AI while mitigating the risks associated with unfettered generation.
|
||||||
|
|
||||||
|
Finally, the personality system is a structure that allows the definition of all the parameters of the AI agent you are talking too: The conditioning text, the user prefix text, the link text, the ai prefix text, the antiprompts text used by the hallucination suppression system as well as all the generation parameters that control the model.
|
||||||
|
|
||||||
|
All of this is stored inside a yaml file called config.yaml stored in the personality folder. Notice that we also ahev extra folders, such as assets folder that contains the personality logo and will eventually be used to store more assets such as personality voice or personality 3D character that can be used for a future meta integration of language models.
|
||||||
|
|
||||||
|
|
||||||
|
We also have a scripts folder where we can put custom code to execute instead of following the default generation workflow that we have shown at the beginning of this video.
|
||||||
|
|
||||||
|
|
||||||
|
Let's take a closer look at the GPT for art personality and its structure. It's a bit more complex because it's not just about answering prompts—it has its own customized workflow.
|
||||||
|
|
||||||
|
In the assets folder, you'll find the personality's cool logo, which it actually generated itself.
|
||||||
|
|
||||||
|
Now, in the scripts folder, there are two files. The first one is install.py, which runs when you select the personality for the first time. This file handles all the custom installation steps. For example, in this case, it installs extra libraries, downloads the stable diffusion project, and gets a diffusion model to work with. We keep a list of those extra libraries in requirements.txt. Once everything's installed, you're good to go with this personality.
|
||||||
|
|
||||||
|
The second file, processor.py, is where the personality's magic happens. It's got a class called Processor that inherits from PAPScript and does some important stuff. The star of the show is the run_workflow method. It takes the current prompt, the accumulated messages so far, and a callback function that's triggered at each step of the workflow.
|
||||||
|
|
||||||
|
In this art personality, we've set it up to generate an image description based on the user's prompt. Then it uses the stable diffusion generator to bring that description to life as an actual image. Finally, it prepares and sends the image as a cool markdown text to the UI.
|
||||||
|
|
||||||
|
Alright, let's get started with this cool personality! First, open up the UI and head over to the settings tab. Now, look for the section called "Personalities Zoo." It's where all the personalities are organized by language and category.
|
||||||
|
|
||||||
|
By default, the personality is set to "GPT for All," but we're going to change that. Find the "Art" category, and within it, select the "GPT for Art" personality. Give it a moment to sink in.
|
||||||
|
|
||||||
|
Now, this is important—click on "Apply Changes" to make sure the new settings take effect. Since this is the first time we're running this personality, it might take a bit longer. It needs to install some stuff, like the stable diffusion system and the model itself. So, just hang tight and be patient while everything gets set up.
|
||||||
|
|
||||||
|
Once the installation is complete, you'll be all set to explore the artistic wonders of this personality.
|
||||||
|
|
||||||
|
Just a heads up, if you decide to reboot the application now, all the updates to your settings will be lost. So, make sure you save those changes before you go ahead.
|
||||||
|
|
||||||
|
|
||||||
|
Alright, let's head back to the discussions tab and start a fresh discussion. This is where we can really put the tool to the test!
|
||||||
|
|
||||||
|
To challenge its creative abilities, let's ask it to imagine something cool without providing too much information. We want to see how it can come up with an image all on its own. Give it some freedom to work its magic and let's see what it creates.
|
||||||
|
|
||||||
|
Here is the output generated by our artbot. We can see the description of the artwork as well as the artwork itself.
|
||||||
|
|
||||||
|
Since this is a discussion, we can go on and ask for changes. For example let's ask it to change this to a day vew.
|
||||||
|
|
||||||
|
As we can see, the model did the requested changes.
|
||||||
|
|
||||||
|
|
||||||
|
Keep in mind that this tool is still in its early stages of development, and there's plenty of room for improvement. One way to enhance its performance is by adjusting the default sampler to an Euler sampler, which can potentially yield even better results. Additionally, you have the flexibility to explore a wide range of models available on Hugging Face repositories. With thousands of models at your disposal, you can experiment and choose the one that aligns best with your specific needs and preferences. By making these adjustments, you can take this tool to new heights and unlock its full potential.
|
||||||
|
|
||||||
|
Please note that all the generated images bear a watermark with the GPT4All signature, serving as a clear indication that they were created by AI using the stable diffusion WatermarkEncoder. This step is crucial to promote responsible AI usage and ensure that each generated work is properly identified as an AI creation.
|
||||||
|
|
||||||
|
It's important to emphasize that this tool is intended for appreciating art, fostering creative exploration, and sparking new ideas. It is not meant for malicious purposes or spreading misinformation. We firmly stand against such misuse.
|
||||||
|
|
||||||
|
By incorporating the watermark and setting these ethical guidelines, we aim to promote transparency and accountability in AI-generated content, while encouraging the responsible and respectful use of this tool. Let's embrace the power of AI to ignite imagination and appreciate the beauty of art in a responsible manner.
|
||||||
|
|
||||||
|
Now, let's dive into the structure of the personality folder once it's installed. Take a peek at what's inside, and you'll notice a couple of new files that have appeared.
|
||||||
|
|
||||||
|
First up, we have the .install file. It's a simple empty file that serves as a marker to indicate that the personality has been successfully installed. Whenever the personality is loaded, the install script checks for the presence of this file. If it's missing, the script knows that the personality needs to be installed again. So, if you ever remove this file, don't worry! The next time you use this personality, it will reinstall itself automatically.
|
||||||
|
|
||||||
|
Next on the list is the config_local.yaml file. This nifty little file holds all the local configuration settings. You have the power to customize various aspects such as the maximum size of the generated image description text. Just tinker with the settings to your liking. Additionally, you can specify the model you want to use. Simply download a stable diffusion model and place it in the project's root directory under "shared/sd_models." Then, reference the model's name in the config_local.yaml file. Cool, right?
|
||||||
|
|
||||||
|
Oh, and let's not forget! You can even set the number of images to generate for each prompt. Fancy playing around with multiple images? This is your chance. And if you want consistency, you can set a specific seed value for the sampling noise generation. A seed value of -1 means randomness, while any other value ensures that all generated images will be the same for each prompt.
|
||||||
|
|
||||||
|
Feel free to explore and make tweaks according to your preferences. It's your playground now!
|
||||||
|
|
||||||
|
Now, let's delve into another fascinating personality: the Tree of Thoughts personality. This particular personality has gained quite a reputation and is highly sought after. Its main goal is to explore a technique for enhancing AI reasoning.
|
||||||
|
|
||||||
|
The Tree of Thoughts technique takes an innovative approach by breaking down an answer into multiple thoughts. Here's how it works: the AI generates a number of thoughts related to the question or prompt. Then, it evaluates and assesses these thoughts, ultimately selecting the best one. This chosen thought is then incorporated into the AI's previous context, prompting it to generate another thought. This iterative process repeats multiple times.
|
||||||
|
|
||||||
|
By the end of this dynamic thought generation process, the AI accumulates a collection of the best thoughts it has generated. These thoughts are then synthesized into a comprehensive summary, which is presented to the user as a result. It's a remarkable way to tackle complex subjects and generate creative solutions.
|
||||||
|
|
||||||
|
Now, let's put this Tree of Thoughts personality to the test with a challenging topic: finding solutions to the climate change problem. Brace yourself for an engaging and thought-provoking exploration of ideas and potential strategies.
|
||||||
|
|
||||||
|
Here is the final synthesis of the AI's thoughts. The text appears to be correct and coherent, aligning precisely with the number of thoughts we set in the configuration. It's important to note that this response is the result of a thorough tree search process, which takes more time compared to a simple response. However, this technique allows for a more thoughtful and well-considered output, exceeding the expectations we might have had from the model alone.
|
||||||
|
|
||||||
|
|
||||||
|
If we observe the console, we can see that the personality initiated the process by posing a question to itself. It then generated three distinct thoughts and proceeded to select the most suitable one. Following this, it asked itself, "Given that I've chosen this initial thought, what would be the subsequent thought?" Generating three more thoughts, it once again selected the most optimal choice. This cycle repeated once more, resulting in a final selection of the best thought. Finally, the personality synthesized its ultimate conclusion by combining the top three thoughts derived from this thoughtful tree-based approach.
|
||||||
|
|
||||||
|
Just a quick reminder: the quality of the answers primarily relies on the model you're using. It's all about size here – the bigger the model, the better the results. In our case, we're using the Wizard LM 7B model, which has 7 billion parameters. But if you're looking for even more impressive outcomes, you can't go wrong with super-sized models like Open Assistant or chat GPT.
|
||||||
|
|
||||||
|
Now, let's dive into another crowd-favorite personality: GPT 4 Internet. This personality comes packed with an impressive feature – it can browse the internet to fetch answers for user questions. Whenever you ask a query, the AI cleverly sends a search request to an engine, retrieves the results, and crafts a response based on the information it finds. The best part? It even provides you with the sources it used, adding an extra layer of credibility to its answers. With this nifty functionality, you can trust that GPT 4 Internet has got your back when it comes to delivering well-informed responses.
|
||||||
|
|
||||||
|
Let's put GPT 4 Internet to the test with a current affairs question: Who is the newly appointed CEO of Twitter? By leveraging its internet-searching capabilities, this personality will scour the web to find the most up-to-date information and promptly deliver the answer you seek.
|
||||||
|
|
||||||
|
As you can observe, the personality performed its intended function flawlessly. It intelligently crafted a well-tailored query, conducted the search seamlessly behind the scenes, and swiftly presented the desired information along with proper source attribution. This showcases the power of leveraging the internet to enhance the AI's capabilities and provide you with accurate and reliable answers.
|
||||||
|
|
||||||
|
Finally, to install the personalities, go to the root of your gpt4all webui application and open a terminal. Then type installation/add_personality.bat or add_personality.sh depending on your operating system. you'll be prompted to choose a language, then a category, and finally the personality you want to install. Once installed, your personality will apear in the zoo.
|
||||||
|
|
||||||
|
Alright, let's wrap up here to keep the video concise. With over 250 personalities to explore, we've only scratched the surface of what GPT 4 All has to offer. While not all personalities have been fully adapted to the new format, a majority of them are already functional and ready for testing.
|
||||||
|
|
||||||
|
Throughout this video, we've delved into the various layers of LLM-based chatbots, grasped the fundamentals of text generation, and gained insights into the essential parameters that govern the generation process. Additionally, we've discovered the intriguing concept of personalities, witnessing some of them in action.
|
||||||
|
|
||||||
|
I hope you found this video informative and engaging. If you enjoyed it, please show your support by liking, starring the project on GitHub, sharing, and subscribing to stay updated on future content. Producing this video was a labor of love, dedicating an entire weekend to its creation, and I sincerely hope it proves valuable to you.
|
||||||
|
|
||||||
|
Thank you for watching, and until next time!
|
||||||
|
|
||||||
|
See ya
|
||||||
10
help/faqs.csv
Normal file
@ -0,0 +1,10 @@
|
|||||||
|
question,answer
|
||||||
|
What is LoLLMs WebUI?,LoLLMs WebUI is a user-friendly interface that provides access to various Large Language Model (LLM) models for a wide range of tasks.
|
||||||
|
What are the features of LoLLMs WebUI?,The features of LoLLMs WebUI include:<br>- Choosing preferred binding, model, and personality<br>- Enhancing emails, essays, code debugging, thought organization, and more<br>- Exploring functionalities like searching, data organization, and image generation<br>- Easy-to-use UI with light and dark mode options<br>- Integration with GitHub repository<br>- Support for different personalities with predefined welcome messages<br>- Thumb up/down rating for generated answers<br>- Copy, edit, and remove messages<br>- Local database storage for discussions<br>- Search, export, and delete multiple discussions<br>- Support for Docker, conda, and manual virtual environment setups
|
||||||
|
Where can I find a tutorial on how to use the tool?,You can find a tutorial on how to use the tool on our YouTube channel. Click here to watch the tutorial: <a href="https://youtu.be/ds_U0TDzbzI">YouTube Tutorial</a>
|
||||||
|
What are the prerequisites for installing LoLLMs WebUI?,The prerequisites for installing LoLLMs WebUI are:<br>- Python 3.10 or higher<br>- Git (for cloning the repository)<br>Make sure Python is in your system's PATH and verify the Python version by running 'python --version' in the terminal.
|
||||||
|
How do I install LoLLMs WebUI?,There are different installation methods for LoLLMs WebUI:<br>1. Easy install:<br>- Download the appropriate launcher for your platform (webui.bat for Windows, webui.sh for Linux).<br>- Place the launcher in a folder of your choice.<br>- Run the launcher script.<br>2. Using Conda:<br>- Clone the project or download the zip file from the GitHub repository.<br>- Create a new conda environment, activate it, and install the requirements.<br>3. Using Docker:<br>- Refer to the Docker documentation for installation instructions specific to your operating system.
|
||||||
|
How do I launch the app?,You can launch the app by running the webui.sh or webui.bat launcher. Alternatively, you can activate the virtual environment and launch the application using 'python app.py' from the project's root directory.
|
||||||
|
How do I select a model and binding?,To select a model and binding:<br>- Open the LoLLMs WebUI and go to the Settings page.<br>- In the Models Zoo tab, choose a binding from the list.<br>- Wait for the installation process to finish and click the Install button next to the desired model.<br>- After the model installation is complete, select the model and apply the changes.<br>- Don't forget to save the configuration.
|
||||||
|
How do I start a discussion?,To start a discussion:<br>- Go to the Discussions view.<br>- Click the + button to create a new discussion.<br>- You will see a predefined welcome message based on the selected personality.<br>- Ask a question or provide an initial prompt to start the discussion.<br>- You can stop the generation process at any time by pressing the Stop Generating button.
|
||||||
|
How do I manage discussions?,To manage discussions:<br>- To edit a discussion title, simply type a new title or modify the existing one.<br>- To delete a discussion, click the Delete button.<br>- To search for specific discussions, use the search button and enter relevant keywords.<br>- To perform batch operations (exporting
|
||||||
|
Can't render this file because it contains an unexpected character in line 4 and column 166.
|
BIN
images/default_model.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 245 KiB |
BIN
images/icon.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 37 KiB |
3
installations/add_backend.bat
Normal file
@ -0,0 +1,3 @@
|
|||||||
|
call ../env/Scripts/activate.bat
|
||||||
|
python install_binding.py %*
|
||||||
|
pause
|
||||||
4
installations/add_backend.sh
Normal file
@ -0,0 +1,4 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
source ../env/bin/activate
|
||||||
|
python install_binding.py "$@"
|
||||||
|
read -p "Press any key to continue..."
|
||||||
55
installations/add_personality.bat
Normal file
@ -0,0 +1,55 @@
|
|||||||
|
@echo off
|
||||||
|
setlocal enabledelayedexpansion
|
||||||
|
|
||||||
|
REM Clone the repository to a tmp folder
|
||||||
|
set "REPO_URL=https://github.com/ParisNeo/PyAIPersonality.git"
|
||||||
|
set "TMP_FOLDER=%temp%\PyAIPersonality"
|
||||||
|
git clone %REPO_URL% %TMP_FOLDER%
|
||||||
|
|
||||||
|
REM List the available languages and prompt user to select one
|
||||||
|
set "LANGUAGES_FOLDER=%TMP_FOLDER%\personalities_zoo"
|
||||||
|
set "LANGUAGE_INDEX=0"
|
||||||
|
for /d %%d in ("%LANGUAGES_FOLDER%\*") do (
|
||||||
|
set /a "LANGUAGE_INDEX+=1"
|
||||||
|
set "LANGUAGES[!LANGUAGE_INDEX!]=%%~nxd"
|
||||||
|
echo !LANGUAGE_INDEX!. %%~nxd
|
||||||
|
)
|
||||||
|
set /p "SELECTED_LANGUAGE=Enter the number of the desired language: "
|
||||||
|
set "LANGUAGE_FOLDER=%LANGUAGES_FOLDER%\!LANGUAGES[%SELECTED_LANGUAGE%]!"
|
||||||
|
|
||||||
|
REM List the available categories and prompt user to select one
|
||||||
|
set "CATEGORIES_FOLDER=%LANGUAGE_FOLDER%"
|
||||||
|
set "CATEGORY_INDEX=0"
|
||||||
|
for /d %%d in ("%CATEGORIES_FOLDER%\*") do (
|
||||||
|
set /a "CATEGORY_INDEX+=1"
|
||||||
|
set "CATEGORIES[!CATEGORY_INDEX!]=%%~nxd"
|
||||||
|
echo !CATEGORY_INDEX!. %%~nxd
|
||||||
|
)
|
||||||
|
set /p "SELECTED_CATEGORY=Enter the number of the desired category: "
|
||||||
|
set "CATEGORY_FOLDER=%CATEGORIES_FOLDER%\!CATEGORIES[%SELECTED_CATEGORY%]!"
|
||||||
|
|
||||||
|
REM List the available personalities and prompt user to select one
|
||||||
|
set "PERSONALITIES_FOLDER=%CATEGORY_FOLDER%"
|
||||||
|
set "PERSONALITY_INDEX=0"
|
||||||
|
for /d %%d in ("%PERSONALITIES_FOLDER%\*") do (
|
||||||
|
set /a "PERSONALITY_INDEX+=1"
|
||||||
|
set "PERSONALITIES[!PERSONALITY_INDEX!]=%%~nxd"
|
||||||
|
echo !PERSONALITY_INDEX!. %%~nxd
|
||||||
|
)
|
||||||
|
set /p "SELECTED_PERSONALITY=Enter the number of the desired personality: "
|
||||||
|
set "PERSONALITY_FOLDER=%PERSONALITIES_FOLDER%\!PERSONALITIES[%SELECTED_PERSONALITY%]!"
|
||||||
|
|
||||||
|
REM Copy the selected personality folder to personalities/language/category folder
|
||||||
|
set "OUTPUT_FOLDER=%CD%\personalities\!LANGUAGES[%SELECTED_LANGUAGE%]!\!CATEGORIES[%SELECTED_CATEGORY%]!\!PERSONALITIES[%SELECTED_PERSONALITY%]!"
|
||||||
|
if not exist "%OUTPUT_FOLDER%" mkdir "%OUTPUT_FOLDER%"
|
||||||
|
xcopy /e /y "%PERSONALITY_FOLDER%" "%OUTPUT_FOLDER%"
|
||||||
|
|
||||||
|
REM cleaning
|
||||||
|
if exist "./tmp" (
|
||||||
|
echo Cleaning tmp folder
|
||||||
|
rd /s /q "./tmp"
|
||||||
|
)
|
||||||
|
REM Remove the tmp folder
|
||||||
|
rd /s /q "%TMP_FOLDER%"
|
||||||
|
echo Done
|
||||||
|
pause
|
||||||
53
installations/add_personality.sh
Executable file
@ -0,0 +1,53 @@
|
|||||||
|
#!/usr/bin/env bash
|
||||||
|
|
||||||
|
# Clone the repository to a tmp folder
|
||||||
|
REPO_URL="https://github.com/ParisNeo/PyAIPersonality.git"
|
||||||
|
TMP_FOLDER=$(mktemp -d)
|
||||||
|
git clone "$REPO_URL" "$TMP_FOLDER"
|
||||||
|
|
||||||
|
# List the available languages and prompt user to select one
|
||||||
|
LANGUAGES_FOLDER="$TMP_FOLDER/personalities_zoo"
|
||||||
|
LANGUAGE_INDEX=0
|
||||||
|
for d in "$LANGUAGES_FOLDER"/*; do
|
||||||
|
LANGUAGE_INDEX=$((LANGUAGE_INDEX+1))
|
||||||
|
LANGUAGES[$LANGUAGE_INDEX]=$(basename "$d")
|
||||||
|
echo "$LANGUAGE_INDEX. ${LANGUAGES[$LANGUAGE_INDEX]}"
|
||||||
|
done
|
||||||
|
read -p "Enter the number of the desired language: " SELECTED_LANGUAGE
|
||||||
|
LANGUAGE_FOLDER="$LANGUAGES_FOLDER/${LANGUAGES[$SELECTED_LANGUAGE]}"
|
||||||
|
|
||||||
|
# List the available categories and prompt user to select one
|
||||||
|
CATEGORIES_FOLDER="$LANGUAGE_FOLDER"
|
||||||
|
CATEGORY_INDEX=0
|
||||||
|
for d in "$CATEGORIES_FOLDER"/*; do
|
||||||
|
CATEGORY_INDEX=$((CATEGORY_INDEX+1))
|
||||||
|
CATEGORIES[$CATEGORY_INDEX]=$(basename "$d")
|
||||||
|
echo "$CATEGORY_INDEX. ${CATEGORIES[$CATEGORY_INDEX]}"
|
||||||
|
done
|
||||||
|
read -p "Enter the number of the desired category: " SELECTED_CATEGORY
|
||||||
|
CATEGORY_FOLDER="$CATEGORIES_FOLDER/${CATEGORIES[$SELECTED_CATEGORY]}"
|
||||||
|
|
||||||
|
# List the available personalities and prompt user to select one
|
||||||
|
PERSONALITIES_FOLDER="$CATEGORY_FOLDER"
|
||||||
|
PERSONALITY_INDEX=0
|
||||||
|
for d in "$PERSONALITIES_FOLDER"/*; do
|
||||||
|
PERSONALITY_INDEX=$((PERSONALITY_INDEX+1))
|
||||||
|
PERSONALITIES[$PERSONALITY_INDEX]=$(basename "$d")
|
||||||
|
echo "$PERSONALITY_INDEX. ${PERSONALITIES[$PERSONALITY_INDEX]}"
|
||||||
|
done
|
||||||
|
read -p "Enter the number of the desired personality: " SELECTED_PERSONALITY
|
||||||
|
PERSONALITY_FOLDER="$PERSONALITIES_FOLDER/${PERSONALITIES[$SELECTED_PERSONALITY]}"
|
||||||
|
|
||||||
|
# Copy the selected personality folder to personalities/language/category folder
|
||||||
|
OUTPUT_FOLDER="$(pwd)/personalities/${LANGUAGES[$SELECTED_LANGUAGE]}/${CATEGORIES[$SELECTED_CATEGORY]}/${PERSONALITIES[$SELECTED_PERSONALITY]}"
|
||||||
|
mkdir -p "$OUTPUT_FOLDER"
|
||||||
|
cp -r "$PERSONALITY_FOLDER/." "$OUTPUT_FOLDER"
|
||||||
|
|
||||||
|
# Cleaning
|
||||||
|
if [[ -d "./tmp" ]]; then
|
||||||
|
echo "Cleaning tmp folder"
|
||||||
|
rm -rf "./tmp"
|
||||||
|
fi
|
||||||
|
|
||||||
|
# Remove the tmp folder
|
||||||
|
rm -rf "$TMP_FOLDER"
|
||||||
1
installations/backendlist.yaml
Normal file
@ -0,0 +1 @@
|
|||||||
|
GPT4All_GPTJ_binding : https://github.com/ParisNeo/GPT4All_GPTJ_binding
|
||||||
27
installations/download_all_personalities.bat
Normal file
@ -0,0 +1,27 @@
|
|||||||
|
@echo off
|
||||||
|
|
||||||
|
rem Set the environment name
|
||||||
|
set environment_name=env
|
||||||
|
|
||||||
|
rem Activate the virtual environment
|
||||||
|
call %environment_name%\Scripts\activate.bat
|
||||||
|
|
||||||
|
rem Change to the installations subfolder
|
||||||
|
|
||||||
|
rem Run the Python script
|
||||||
|
python installations/download_all_personalities.py
|
||||||
|
|
||||||
|
rem Deactivate the virtual environment
|
||||||
|
echo deactivating
|
||||||
|
call %environment_name%\Scripts\deactivate.bat
|
||||||
|
|
||||||
|
rem Remove tmp folder
|
||||||
|
set "folder=tmp"
|
||||||
|
|
||||||
|
if exist "%folder%" (
|
||||||
|
echo Folder exists. Deleting...
|
||||||
|
rd /s /q "%folder%"
|
||||||
|
echo Folder deleted.
|
||||||
|
) else (
|
||||||
|
echo Folder does not exist.
|
||||||
|
)
|
||||||
57
installations/download_all_personalities.py
Normal file
@ -0,0 +1,57 @@
|
|||||||
|
import os
|
||||||
|
import shutil
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
def copy_files(source_path, destination_path):
|
||||||
|
for item in os.listdir(source_path):
|
||||||
|
source_item = source_path / item
|
||||||
|
destination_item = destination_path / item
|
||||||
|
|
||||||
|
if source_item.is_file():
|
||||||
|
# Remove destination file if it already exists
|
||||||
|
try:
|
||||||
|
if destination_item.exists():
|
||||||
|
destination_item.unlink()
|
||||||
|
# Copy file from source to destination
|
||||||
|
shutil.copy2(str(source_item), str(destination_item))
|
||||||
|
except:
|
||||||
|
print(f"Couldn't install personality {item}")
|
||||||
|
|
||||||
|
elif source_item.is_dir():
|
||||||
|
# Create destination directory if it does not exist
|
||||||
|
destination_item.mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
|
# Recursively copy files in subdirectories
|
||||||
|
copy_files(source_item, destination_item)
|
||||||
|
|
||||||
|
import subprocess
|
||||||
|
|
||||||
|
def clone_and_copy_repository(repo_url):
|
||||||
|
tmp_folder = Path("tmp/git_clone")
|
||||||
|
personalities_folder = Path("personalities")
|
||||||
|
subfolder_name = "personalities_zoo"
|
||||||
|
|
||||||
|
# Clone the repository to a temporary folder
|
||||||
|
subprocess.run(["git", "clone", repo_url, str(tmp_folder)])
|
||||||
|
|
||||||
|
# Check if the repository was cloned successfully
|
||||||
|
if not tmp_folder.exists():
|
||||||
|
print("Failed to clone the repository.")
|
||||||
|
return
|
||||||
|
|
||||||
|
# Construct the source and destination paths for copying the subfolder
|
||||||
|
subfolder_path = tmp_folder / subfolder_name
|
||||||
|
destination_path = Path.cwd() / personalities_folder
|
||||||
|
|
||||||
|
# Copy files and folders recursively
|
||||||
|
print(f"copying")
|
||||||
|
copy_files(subfolder_path, destination_path)
|
||||||
|
|
||||||
|
# Remove the temporary folder
|
||||||
|
shutil.rmtree(str(tmp_folder))
|
||||||
|
|
||||||
|
print("Repository clone and copy completed successfully.")
|
||||||
|
|
||||||
|
# Example usage
|
||||||
|
repo_url = "https://github.com/ParisNeo/PyAIPersonality.git"
|
||||||
|
clone_and_copy_repository(repo_url)
|
||||||
27
installations/download_all_personalities.sh
Normal file
@ -0,0 +1,27 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
# Set the environment name
|
||||||
|
environment_name="env"
|
||||||
|
|
||||||
|
# Activate the virtual environment
|
||||||
|
source "$environment_name/bin/activate"
|
||||||
|
|
||||||
|
# Change to the installations subfolder
|
||||||
|
|
||||||
|
# Run the Python script
|
||||||
|
python installations/download_all_personalities.py
|
||||||
|
|
||||||
|
# Deactivate the virtual environment
|
||||||
|
echo "deactivating"
|
||||||
|
deactivate
|
||||||
|
|
||||||
|
# Remove tmp folder
|
||||||
|
folder="tmp"
|
||||||
|
|
||||||
|
if [ -d "$folder" ]; then
|
||||||
|
echo "Folder exists. Deleting..."
|
||||||
|
rm -r "$folder"
|
||||||
|
echo "Folder deleted."
|
||||||
|
else
|
||||||
|
echo "Folder does not exist."
|
||||||
|
fi
|
||||||
60
installations/install_backend.py
Normal file
@ -0,0 +1,60 @@
|
|||||||
|
import argparse
|
||||||
|
import subprocess
|
||||||
|
import shutil
|
||||||
|
import yaml
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
|
||||||
|
def install_binding(binding_name):
|
||||||
|
# Load the list of available bindings from bindinglist.yaml
|
||||||
|
with open('bindinglist.yaml', 'r') as f:
|
||||||
|
binding_list = yaml.safe_load(f)
|
||||||
|
|
||||||
|
# Get the Github repository URL for the selected binding
|
||||||
|
try:
|
||||||
|
binding_url = binding_list[binding_name]
|
||||||
|
except KeyError:
|
||||||
|
print(f"Binding '{binding_name}' not found in bindinglist.yaml")
|
||||||
|
return
|
||||||
|
|
||||||
|
# Clone the Github repository to a tmp folder
|
||||||
|
tmp_folder = Path('tmp')
|
||||||
|
if tmp_folder.exists():
|
||||||
|
shutil.rmtree(tmp_folder)
|
||||||
|
subprocess.run(['git', 'clone', binding_url, tmp_folder])
|
||||||
|
|
||||||
|
# Install the requirements.txt from the cloned project
|
||||||
|
requirements_file = tmp_folder / 'requirements.txt'
|
||||||
|
subprocess.run(['pip', 'install', '-r', str(requirements_file)])
|
||||||
|
|
||||||
|
# Copy the folder found inside the binding to ../bindings
|
||||||
|
folders = [f for f in tmp_folder.iterdir() if f.is_dir() and not f.stem.startswith(".")]
|
||||||
|
src_folder = folders[0]
|
||||||
|
dst_folder = Path('../bindings') / src_folder.stem
|
||||||
|
print(f"coipying from {src_folder} to {dst_folder}")
|
||||||
|
# Delete the destination directory if it already exists
|
||||||
|
if dst_folder.exists():
|
||||||
|
shutil.rmtree(dst_folder)
|
||||||
|
|
||||||
|
shutil.copytree(src_folder, dst_folder)
|
||||||
|
|
||||||
|
# Create an empty folder in ../models with the same name
|
||||||
|
models_folder = Path('../models')
|
||||||
|
models_folder.mkdir(exist_ok=True)
|
||||||
|
(models_folder / binding_name).mkdir(exist_ok=True, parents=True)
|
||||||
|
if tmp_folder.exists():
|
||||||
|
shutil.rmtree(tmp_folder)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
# Load the list of available bindings from bindinglist.yaml
|
||||||
|
with open('bindinglist.yaml', 'r') as f:
|
||||||
|
binding_list = yaml.safe_load(f)
|
||||||
|
|
||||||
|
# Print the list of available bindings and prompt the user to select one
|
||||||
|
print("Available bindings:")
|
||||||
|
for binding_id, binding_name in enumerate(binding_list):
|
||||||
|
print(f" {binding_id} - {binding_name}")
|
||||||
|
binding_id = int(input("Select a binding to install: "))
|
||||||
|
|
||||||
|
install_binding(list(binding_list.keys())[binding_id])
|
||||||
7
installations/install_backend_gpu.bat
Normal file
@ -0,0 +1,7 @@
|
|||||||
|
echo this will recompile llapacpp to use your hardware with gpu enabled.
|
||||||
|
pip uninstall llama-cpp-python -y
|
||||||
|
rem First we need to purge any old installation
|
||||||
|
pip cache purge
|
||||||
|
set CMAKE_ARGS=-DLLAMA_CUBLAS=on
|
||||||
|
set FORCE_CMAKE=1
|
||||||
|
pip install llama-cpp-python --upgrade
|
||||||
7
installations/install_backend_gpu.sh
Normal file
@ -0,0 +1,7 @@
|
|||||||
|
echo "this will recompile llapacpp to use your hardware with gpu enabled."
|
||||||
|
pip uninstall llama-cpp-python -y
|
||||||
|
# First we need to purge any old installation
|
||||||
|
pip cache purge
|
||||||
|
export CMAKE_ARGS="-DLLAMA_CUBLAS=on"
|
||||||
|
export FORCE_CMAKE=1
|
||||||
|
pip install llama-cpp-python --upgrade
|
||||||
{kind=link}
@ -1,4 +0,0 @@
|
|||||||
Here you can drop your models depending on the selected backend
|
|
||||||
Currently, supported backends are:
|
|
||||||
- llamacpp
|
|
||||||
- gpt-j
|
|
||||||
6
package-lock.json
generated
Normal file
@ -0,0 +1,6 @@
|
|||||||
|
{
|
||||||
|
"name": "lollms-webui",
|
||||||
|
"lockfileVersion": 3,
|
||||||
|
"requires": true,
|
||||||
|
"packages": {}
|
||||||
|
}
|
||||||
@ -1,47 +0,0 @@
|
|||||||
# GPT4All Chatbot conditionning file
|
|
||||||
# Author : @ParisNeo
|
|
||||||
# Version : 1.1
|
|
||||||
# Description :
|
|
||||||
# An NLP needs conditionning to instruct it to be whatever we want it to be.
|
|
||||||
# This file is used by the GPT4All web ui to condition the personality of the model you are
|
|
||||||
# talking to.
|
|
||||||
|
|
||||||
# Name of the personality
|
|
||||||
name: gpt4all
|
|
||||||
|
|
||||||
# Name of the user
|
|
||||||
user_name: user
|
|
||||||
|
|
||||||
# Language (see the list of supported languages here : https://github.com/ParisNeo/GPT4All_Personalities/blob/main/README.md)
|
|
||||||
language: "en_XX"
|
|
||||||
|
|
||||||
# Category
|
|
||||||
category: "General"
|
|
||||||
|
|
||||||
# Personality description:
|
|
||||||
personality_description: |
|
|
||||||
This personality is a helpful and Kind AI ready to help you solve your problems
|
|
||||||
|
|
||||||
# The conditionning instructions sent to eh model at the start of the discussion
|
|
||||||
personality_conditionning: |
|
|
||||||
GPT4All is a smart and helpful Assistant built by Nomic-AI. It can discuss with humans and assist them.
|
|
||||||
|
|
||||||
#Welcome message to be sent to the user when a new discussion is started
|
|
||||||
welcome_message: "Welcome! I am GPT4All A free and open assistant. What can I do for you today?"
|
|
||||||
|
|
||||||
# This prefix is added at the beginning of any message input by the user
|
|
||||||
user_message_prefix: "### Human:"
|
|
||||||
|
|
||||||
# A text to put between user and chatbot messages
|
|
||||||
link_text: "\n"
|
|
||||||
|
|
||||||
# This prefix is added at the beginning of any message output by the ai
|
|
||||||
ai_message_prefix: "### Assistant:"
|
|
||||||
|
|
||||||
# Here is the list of extensions this personality requires
|
|
||||||
dependencies: []
|
|
||||||
|
|
||||||
# Some personalities need a disclaimer to warn the user of potential harm that can be caused by the AI
|
|
||||||
# for example, for medical assistants, it is important to tell the user to be careful and not use medication
|
|
||||||
# without advise from a real docor.
|
|
||||||
disclaimer: ""
|
|
||||||
@ -1 +0,0 @@
|
|||||||
|
|
||||||
254
pyGpt4All/api.py
@ -1,254 +0,0 @@
|
|||||||
######
|
|
||||||
# Project : GPT4ALL-UI
|
|
||||||
# File : api.py
|
|
||||||
# Author : ParisNeo with the help of the community
|
|
||||||
# Supported by Nomic-AI
|
|
||||||
# Licence : Apache 2.0
|
|
||||||
# Description :
|
|
||||||
# A simple api to communicate with gpt4all-ui and its models.
|
|
||||||
######
|
|
||||||
import gc
|
|
||||||
import sys
|
|
||||||
from queue import Queue
|
|
||||||
from datetime import datetime
|
|
||||||
from pyGpt4All.db import DiscussionsDB
|
|
||||||
from pathlib import Path
|
|
||||||
import importlib
|
|
||||||
|
|
||||||
__author__ = "parisneo"
|
|
||||||
__github__ = "https://github.com/nomic-ai/gpt4all-ui"
|
|
||||||
__copyright__ = "Copyright 2023, "
|
|
||||||
__license__ = "Apache 2.0"
|
|
||||||
|
|
||||||
class GPT4AllAPI():
|
|
||||||
def __init__(self, config:dict, personality:dict, config_file_path:str) -> None:
|
|
||||||
self.config = config
|
|
||||||
self.personality = personality
|
|
||||||
self.config_file_path = config_file_path
|
|
||||||
self.cancel_gen = False
|
|
||||||
|
|
||||||
# This is the queue used to stream text to the ui as the bot spits out its response
|
|
||||||
self.text_queue = Queue(0)
|
|
||||||
|
|
||||||
# Keeping track of current discussion and message
|
|
||||||
self.current_discussion = None
|
|
||||||
self.current_message_id = 0
|
|
||||||
|
|
||||||
self.db_path = config["db_path"]
|
|
||||||
|
|
||||||
# Create database object
|
|
||||||
self.db = DiscussionsDB(self.db_path)
|
|
||||||
|
|
||||||
# If the database is empty, populate it with tables
|
|
||||||
self.db.populate()
|
|
||||||
|
|
||||||
# This is used to keep track of messages
|
|
||||||
self.full_message_list = []
|
|
||||||
|
|
||||||
# Select backend
|
|
||||||
self.BACKENDS_LIST = {f.stem:f for f in Path("backends").iterdir() if f.is_dir() and f.stem!="__pycache__"}
|
|
||||||
|
|
||||||
self.load_backend(self.BACKENDS_LIST[self.config["backend"]])
|
|
||||||
|
|
||||||
# Build chatbot
|
|
||||||
self.chatbot_bindings = self.create_chatbot()
|
|
||||||
print("Chatbot created successfully")
|
|
||||||
|
|
||||||
# tests the model
|
|
||||||
"""
|
|
||||||
self.prepare_reception()
|
|
||||||
self.discussion_messages = "Instruction: Act as gpt4all. A kind and helpful AI bot built to help users solve problems.\nuser: how to build a water rocket?\ngpt4all:"
|
|
||||||
text = self.chatbot_bindings.generate(
|
|
||||||
self.discussion_messages,
|
|
||||||
new_text_callback=self.new_text_callback,
|
|
||||||
n_predict=372,
|
|
||||||
temp=self.config['temp'],
|
|
||||||
top_k=self.config['top_k'],
|
|
||||||
top_p=self.config['top_p'],
|
|
||||||
repeat_penalty=self.config['repeat_penalty'],
|
|
||||||
repeat_last_n = self.config['repeat_last_n'],
|
|
||||||
#seed=self.config['seed'],
|
|
||||||
n_threads=self.config['n_threads']
|
|
||||||
)
|
|
||||||
print(text)
|
|
||||||
"""
|
|
||||||
|
|
||||||
|
|
||||||
# generation status
|
|
||||||
self.generating=False
|
|
||||||
|
|
||||||
def load_backend(self, backend_path):
|
|
||||||
|
|
||||||
# define the full absolute path to the module
|
|
||||||
absolute_path = backend_path.resolve()
|
|
||||||
|
|
||||||
# infer the module name from the file path
|
|
||||||
module_name = backend_path.stem
|
|
||||||
|
|
||||||
# use importlib to load the module from the file path
|
|
||||||
loader = importlib.machinery.SourceFileLoader(module_name, str(absolute_path/"__init__.py"))
|
|
||||||
backend_module = loader.load_module()
|
|
||||||
backend_class = getattr(backend_module, backend_module.backend_name)
|
|
||||||
self.backend = backend_class
|
|
||||||
|
|
||||||
def create_chatbot(self):
|
|
||||||
return self.backend(self.config)
|
|
||||||
|
|
||||||
def condition_chatbot(self, conditionning_message):
|
|
||||||
if self.current_discussion is None:
|
|
||||||
self.current_discussion = self.db.load_last_discussion()
|
|
||||||
|
|
||||||
message_id = self.current_discussion.add_message(
|
|
||||||
"conditionner",
|
|
||||||
conditionning_message,
|
|
||||||
DiscussionsDB.MSG_TYPE_CONDITIONNING,
|
|
||||||
0,
|
|
||||||
0
|
|
||||||
)
|
|
||||||
self.current_message_id = message_id
|
|
||||||
if self.personality["welcome_message"]!="":
|
|
||||||
message_id = self.current_discussion.add_message(
|
|
||||||
self.personality["name"], self.personality["welcome_message"],
|
|
||||||
DiscussionsDB.MSG_TYPE_NORMAL,
|
|
||||||
0,
|
|
||||||
self.current_message_id
|
|
||||||
)
|
|
||||||
|
|
||||||
self.current_message_id = message_id
|
|
||||||
return message_id
|
|
||||||
|
|
||||||
def prepare_reception(self):
|
|
||||||
self.bot_says = ""
|
|
||||||
self.full_text = ""
|
|
||||||
self.is_bot_text_started = False
|
|
||||||
#self.current_message = message
|
|
||||||
|
|
||||||
def create_new_discussion(self, title):
|
|
||||||
self.current_discussion = self.db.create_discussion(title)
|
|
||||||
# Get the current timestamp
|
|
||||||
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
|
||||||
|
|
||||||
# Chatbot conditionning
|
|
||||||
self.condition_chatbot(self.personality["personality_conditionning"])
|
|
||||||
return timestamp
|
|
||||||
|
|
||||||
def prepare_query(self, message_id=-1):
|
|
||||||
messages = self.current_discussion.get_messages()
|
|
||||||
self.full_message_list = []
|
|
||||||
for message in messages:
|
|
||||||
if message["id"]<= message_id or message_id==-1:
|
|
||||||
if message["type"]!=self.db.MSG_TYPE_CONDITIONNING:
|
|
||||||
if message["sender"]==self.personality["name"]:
|
|
||||||
self.full_message_list.append(self.personality["ai_message_prefix"]+message["content"])
|
|
||||||
else:
|
|
||||||
self.full_message_list.append(self.personality["user_message_prefix"] + message["content"])
|
|
||||||
|
|
||||||
link_text = self.personality["link_text"]
|
|
||||||
|
|
||||||
if len(self.full_message_list) > self.config["nb_messages_to_remember"]:
|
|
||||||
discussion_messages = self.personality["personality_conditionning"]+ link_text.join(self.full_message_list[-self.config["nb_messages_to_remember"]:])
|
|
||||||
else:
|
|
||||||
discussion_messages = self.personality["personality_conditionning"]+ link_text.join(self.full_message_list)
|
|
||||||
|
|
||||||
discussion_messages += link_text + self.personality["ai_message_prefix"]
|
|
||||||
return discussion_messages # Removes the last return
|
|
||||||
|
|
||||||
def get_discussion_to(self, message_id=-1):
|
|
||||||
messages = self.current_discussion.get_messages()
|
|
||||||
self.full_message_list = []
|
|
||||||
for message in messages:
|
|
||||||
if message["id"]<= message_id or message_id==-1:
|
|
||||||
if message["type"]!=self.db.MSG_TYPE_CONDITIONNING:
|
|
||||||
if message["sender"]==self.personality["name"]:
|
|
||||||
self.full_message_list.append(self.personality["ai_message_prefix"]+message["content"])
|
|
||||||
else:
|
|
||||||
self.full_message_list.append(self.personality["user_message_prefix"] + message["content"])
|
|
||||||
|
|
||||||
link_text = self.personality["link_text"]
|
|
||||||
|
|
||||||
if len(self.full_message_list) > self.config["nb_messages_to_remember"]:
|
|
||||||
discussion_messages = self.personality["personality_conditionning"]+ link_text.join(self.full_message_list[-self.config["nb_messages_to_remember"]:])
|
|
||||||
else:
|
|
||||||
discussion_messages = self.personality["personality_conditionning"]+ link_text.join(self.full_message_list)
|
|
||||||
|
|
||||||
return discussion_messages # Removes the last return
|
|
||||||
|
|
||||||
|
|
||||||
def remove_text_from_string(self, string, text_to_find):
|
|
||||||
"""
|
|
||||||
Removes everything from the first occurrence of the specified text in the string (case-insensitive).
|
|
||||||
|
|
||||||
Parameters:
|
|
||||||
string (str): The original string.
|
|
||||||
text_to_find (str): The text to find in the string.
|
|
||||||
|
|
||||||
Returns:
|
|
||||||
str: The updated string.
|
|
||||||
"""
|
|
||||||
index = string.lower().find(text_to_find.lower())
|
|
||||||
|
|
||||||
if index != -1:
|
|
||||||
string = string[:index]
|
|
||||||
|
|
||||||
return string
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
def new_text_callback(self, text: str):
|
|
||||||
if self.cancel_gen:
|
|
||||||
return False
|
|
||||||
print(text, end="")
|
|
||||||
sys.stdout.flush()
|
|
||||||
if self.chatbot_bindings.inline:
|
|
||||||
self.bot_says += text
|
|
||||||
if not self.personality["user_message_prefix"].lower() in self.bot_says.lower():
|
|
||||||
self.socketio.emit('message', {'data': text});
|
|
||||||
if self.cancel_gen:
|
|
||||||
print("Generation canceled")
|
|
||||||
return False
|
|
||||||
else:
|
|
||||||
return True
|
|
||||||
else:
|
|
||||||
self.bot_says = self.remove_text_from_string(self.bot_says, self.personality["user_message_prefix"].lower())
|
|
||||||
print("The model is halucinating")
|
|
||||||
return False
|
|
||||||
else:
|
|
||||||
self.full_text += text
|
|
||||||
if self.is_bot_text_started:
|
|
||||||
self.bot_says += text
|
|
||||||
if not self.personality["user_message_prefix"].lower() in self.bot_says.lower():
|
|
||||||
self.text_queue.put(text)
|
|
||||||
if self.cancel_gen:
|
|
||||||
print("Generation canceled")
|
|
||||||
return False
|
|
||||||
else:
|
|
||||||
return True
|
|
||||||
else:
|
|
||||||
self.bot_says = self.remove_text_from_string(self.bot_says, self.personality["user_message_prefix"].lower())
|
|
||||||
print("The model is halucinating")
|
|
||||||
self.cancel_gen=True
|
|
||||||
return False
|
|
||||||
|
|
||||||
#if self.current_message in self.full_text:
|
|
||||||
if len(self.discussion_messages) < len(self.full_text):
|
|
||||||
self.is_bot_text_started = True
|
|
||||||
|
|
||||||
def generate_message(self):
|
|
||||||
self.generating=True
|
|
||||||
gc.collect()
|
|
||||||
total_n_predict = self.config['n_predict']
|
|
||||||
print(f"Generating {total_n_predict} outputs... ")
|
|
||||||
print(f"Input text : {self.discussion_messages}")
|
|
||||||
self.chatbot_bindings.generate(
|
|
||||||
self.discussion_messages,
|
|
||||||
new_text_callback=self.new_text_callback,
|
|
||||||
n_predict=total_n_predict,
|
|
||||||
temp=self.config['temp'],
|
|
||||||
top_k=self.config['top_k'],
|
|
||||||
top_p=self.config['top_p'],
|
|
||||||
repeat_penalty=self.config['repeat_penalty'],
|
|
||||||
repeat_last_n = self.config['repeat_last_n'],
|
|
||||||
#seed=self.config['seed'],
|
|
||||||
n_threads=self.config['n_threads']
|
|
||||||
)
|
|
||||||
self.generating=False
|
|
||||||
@ -1,41 +0,0 @@
|
|||||||
######
|
|
||||||
# Project : GPT4ALL-UI
|
|
||||||
# File : backend.py
|
|
||||||
# Author : ParisNeo with the help of the community
|
|
||||||
# Supported by Nomic-AI
|
|
||||||
# Licence : Apache 2.0
|
|
||||||
# Description :
|
|
||||||
# This is an interface class for GPT4All-ui backends.
|
|
||||||
######
|
|
||||||
from pathlib import Path
|
|
||||||
from typing import Callable
|
|
||||||
|
|
||||||
__author__ = "parisneo"
|
|
||||||
__github__ = "https://github.com/nomic-ai/gpt4all-ui"
|
|
||||||
__copyright__ = "Copyright 2023, "
|
|
||||||
__license__ = "Apache 2.0"
|
|
||||||
|
|
||||||
|
|
||||||
class GPTBackend:
|
|
||||||
file_extension='*.bin'
|
|
||||||
def __init__(self, config:dict, inline:bool) -> None:
|
|
||||||
self.config = config
|
|
||||||
self.inline = inline
|
|
||||||
|
|
||||||
|
|
||||||
def generate(self,
|
|
||||||
prompt:str,
|
|
||||||
n_predict: int = 128,
|
|
||||||
new_text_callback: Callable[[str], None] = None,
|
|
||||||
verbose: bool = False,
|
|
||||||
**gpt_params ):
|
|
||||||
"""Generates text out of a prompt
|
|
||||||
This should ber implemented by child class
|
|
||||||
|
|
||||||
Args:
|
|
||||||
prompt (str): The prompt to use for generation
|
|
||||||
n_predict (int, optional): Number of tokens to prodict. Defaults to 128.
|
|
||||||
new_text_callback (Callable[[str], None], optional): A callback function that is called everytime a new text element is generated. Defaults to None.
|
|
||||||
verbose (bool, optional): If true, the code will spit many informations about the generation process. Defaults to False.
|
|
||||||
"""
|
|
||||||
pass
|
|
||||||
340
pyGpt4All/db.py
@ -1,340 +0,0 @@
|
|||||||
|
|
||||||
import sqlite3
|
|
||||||
|
|
||||||
__author__ = "parisneo"
|
|
||||||
__github__ = "https://github.com/nomic-ai/gpt4all-ui"
|
|
||||||
__copyright__ = "Copyright 2023, "
|
|
||||||
__license__ = "Apache 2.0"
|
|
||||||
|
|
||||||
|
|
||||||
# =================================== Database ==================================================================
|
|
||||||
class DiscussionsDB:
|
|
||||||
MSG_TYPE_NORMAL = 0
|
|
||||||
MSG_TYPE_CONDITIONNING = 1
|
|
||||||
|
|
||||||
def __init__(self, db_path="database.db"):
|
|
||||||
self.db_path = db_path
|
|
||||||
|
|
||||||
def populate(self):
|
|
||||||
"""
|
|
||||||
create database schema
|
|
||||||
"""
|
|
||||||
db_version = 2
|
|
||||||
# Verify encoding and change it if it is not complient
|
|
||||||
with sqlite3.connect(self.db_path) as conn:
|
|
||||||
# Execute a PRAGMA statement to get the current encoding of the database
|
|
||||||
cur = conn.execute('PRAGMA encoding')
|
|
||||||
current_encoding = cur.fetchone()[0]
|
|
||||||
|
|
||||||
if current_encoding != 'UTF-8':
|
|
||||||
# The current encoding is not UTF-8, so we need to change it
|
|
||||||
print(f"The current encoding is {current_encoding}, changing to UTF-8...")
|
|
||||||
conn.execute('PRAGMA encoding = "UTF-8"')
|
|
||||||
conn.commit()
|
|
||||||
|
|
||||||
print("Checking discussions database...")
|
|
||||||
with sqlite3.connect(self.db_path) as conn:
|
|
||||||
cursor = conn.cursor()
|
|
||||||
|
|
||||||
discussion_table_exist=False
|
|
||||||
message_table_exist=False
|
|
||||||
schema_table_exist=False
|
|
||||||
|
|
||||||
# Check if the 'schema_version' table exists
|
|
||||||
try:
|
|
||||||
cursor.execute("""
|
|
||||||
CREATE TABLE schema_version (
|
|
||||||
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
||||||
version INTEGER NOT NULL
|
|
||||||
)
|
|
||||||
""")
|
|
||||||
except:
|
|
||||||
schema_table_exist = True
|
|
||||||
try:
|
|
||||||
cursor.execute("""
|
|
||||||
CREATE TABLE discussion (
|
|
||||||
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
||||||
title TEXT
|
|
||||||
)
|
|
||||||
""")
|
|
||||||
except Exception:
|
|
||||||
discussion_table_exist=True
|
|
||||||
try:
|
|
||||||
cursor.execute("""
|
|
||||||
CREATE TABLE message (
|
|
||||||
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
||||||
sender TEXT NOT NULL,
|
|
||||||
content TEXT NOT NULL,
|
|
||||||
type INT NOT NULL,
|
|
||||||
rank INT NOT NULL,
|
|
||||||
parent INT,
|
|
||||||
discussion_id INTEGER NOT NULL,
|
|
||||||
FOREIGN KEY (discussion_id) REFERENCES discussion(id)
|
|
||||||
)
|
|
||||||
"""
|
|
||||||
)
|
|
||||||
except :
|
|
||||||
message_table_exist=True
|
|
||||||
|
|
||||||
# Get the current version from the schema_version table
|
|
||||||
cursor.execute("SELECT version FROM schema_version WHERE id = 1")
|
|
||||||
row = cursor.fetchone()
|
|
||||||
if row is None:
|
|
||||||
# If the table is empty, assume version 0
|
|
||||||
version = 0
|
|
||||||
else:
|
|
||||||
# Otherwise, use the version from the table
|
|
||||||
version = row[0]
|
|
||||||
|
|
||||||
# Upgrade the schema to version 1
|
|
||||||
if version < 1:
|
|
||||||
print(f"Upgrading schema to version {db_version}...")
|
|
||||||
# Add the 'created_at' column to the 'message' table
|
|
||||||
if message_table_exist:
|
|
||||||
cursor.execute("ALTER TABLE message ADD COLUMN type INT DEFAULT 0") # Added in V1
|
|
||||||
cursor.execute("ALTER TABLE message ADD COLUMN rank INT DEFAULT 0") # Added in V1
|
|
||||||
cursor.execute("ALTER TABLE message ADD COLUMN parent INT DEFAULT 0") # Added in V2
|
|
||||||
# Upgrade the schema to version 1
|
|
||||||
elif version < 2:
|
|
||||||
print(f"Upgrading schema to version {db_version}...")
|
|
||||||
# Add the 'created_at' column to the 'message' table
|
|
||||||
if message_table_exist:
|
|
||||||
try:
|
|
||||||
cursor.execute("ALTER TABLE message ADD COLUMN parent INT DEFAULT 0") # Added in V2
|
|
||||||
except :
|
|
||||||
pass
|
|
||||||
# Update the schema version
|
|
||||||
if not schema_table_exist:
|
|
||||||
cursor.execute(f"INSERT INTO schema_version (id, version) VALUES (1, {db_version})")
|
|
||||||
else:
|
|
||||||
cursor.execute(f"UPDATE schema_version SET version=? WHERE id=?",(db_version,1))
|
|
||||||
|
|
||||||
conn.commit()
|
|
||||||
|
|
||||||
def select(self, query, params=None, fetch_all=True):
|
|
||||||
"""
|
|
||||||
Execute the specified SQL select query on the database,
|
|
||||||
with optional parameters.
|
|
||||||
Returns the cursor object for further processing.
|
|
||||||
"""
|
|
||||||
with sqlite3.connect(self.db_path) as conn:
|
|
||||||
if params is None:
|
|
||||||
cursor = conn.execute(query)
|
|
||||||
else:
|
|
||||||
cursor = conn.execute(query, params)
|
|
||||||
if fetch_all:
|
|
||||||
return cursor.fetchall()
|
|
||||||
else:
|
|
||||||
return cursor.fetchone()
|
|
||||||
|
|
||||||
|
|
||||||
def delete(self, query, params=None):
|
|
||||||
"""
|
|
||||||
Execute the specified SQL delete query on the database,
|
|
||||||
with optional parameters.
|
|
||||||
Returns the cursor object for further processing.
|
|
||||||
"""
|
|
||||||
with sqlite3.connect(self.db_path) as conn:
|
|
||||||
cursor = conn.cursor()
|
|
||||||
if params is None:
|
|
||||||
cursor.execute(query)
|
|
||||||
else:
|
|
||||||
cursor.execute(query, params)
|
|
||||||
conn.commit()
|
|
||||||
|
|
||||||
def insert(self, query, params=None):
|
|
||||||
"""
|
|
||||||
Execute the specified INSERT SQL query on the database,
|
|
||||||
with optional parameters.
|
|
||||||
Returns the ID of the newly inserted row.
|
|
||||||
"""
|
|
||||||
|
|
||||||
with sqlite3.connect(self.db_path) as conn:
|
|
||||||
cursor = conn.execute(query, params)
|
|
||||||
rowid = cursor.lastrowid
|
|
||||||
conn.commit()
|
|
||||||
self.conn = None
|
|
||||||
return rowid
|
|
||||||
|
|
||||||
def update(self, query, params=None):
|
|
||||||
"""
|
|
||||||
Execute the specified Update SQL query on the database,
|
|
||||||
with optional parameters.
|
|
||||||
Returns the ID of the newly inserted row.
|
|
||||||
"""
|
|
||||||
|
|
||||||
with sqlite3.connect(self.db_path) as conn:
|
|
||||||
conn.execute(query, params)
|
|
||||||
conn.commit()
|
|
||||||
|
|
||||||
def load_last_discussion(self):
|
|
||||||
last_discussion_id = self.select("SELECT id FROM discussion ORDER BY id DESC LIMIT 1", fetch_all=False)
|
|
||||||
if last_discussion_id is None:
|
|
||||||
last_discussion = self.create_discussion()
|
|
||||||
last_discussion_id = last_discussion.discussion_id
|
|
||||||
else:
|
|
||||||
last_discussion_id = last_discussion_id[0]
|
|
||||||
self.current_message_id = self.select("SELECT id FROM message WHERE discussion_id=? ORDER BY id DESC LIMIT 1", (last_discussion_id,), fetch_all=False)
|
|
||||||
return Discussion(last_discussion_id, self)
|
|
||||||
|
|
||||||
def create_discussion(self, title="untitled"):
|
|
||||||
"""Creates a new discussion
|
|
||||||
|
|
||||||
Args:
|
|
||||||
title (str, optional): The title of the discussion. Defaults to "untitled".
|
|
||||||
|
|
||||||
Returns:
|
|
||||||
Discussion: A Discussion instance
|
|
||||||
"""
|
|
||||||
discussion_id = self.insert(f"INSERT INTO discussion (title) VALUES (?)",(title,))
|
|
||||||
return Discussion(discussion_id, self)
|
|
||||||
|
|
||||||
def build_discussion(self, discussion_id=0):
|
|
||||||
return Discussion(discussion_id, self)
|
|
||||||
|
|
||||||
def get_discussions(self):
|
|
||||||
rows = self.select("SELECT * FROM discussion")
|
|
||||||
return [{"id": row[0], "title": row[1]} for row in rows]
|
|
||||||
|
|
||||||
def does_last_discussion_have_messages(self):
|
|
||||||
last_discussion_id = self.select("SELECT id FROM discussion ORDER BY id DESC LIMIT 1", fetch_all=False)
|
|
||||||
if last_discussion_id is None:
|
|
||||||
last_discussion = self.create_discussion()
|
|
||||||
last_discussion_id = last_discussion.discussion_id
|
|
||||||
else:
|
|
||||||
last_discussion_id = last_discussion_id[0]
|
|
||||||
last_message = self.select("SELECT * FROM message WHERE discussion_id=?", (last_discussion_id,), fetch_all=False)
|
|
||||||
return last_message is not None
|
|
||||||
|
|
||||||
def remove_discussions(self):
|
|
||||||
self.delete("DELETE FROM message")
|
|
||||||
self.delete("DELETE FROM discussion")
|
|
||||||
|
|
||||||
|
|
||||||
def export_to_json(self):
|
|
||||||
db_discussions = self.select("SELECT * FROM discussion")
|
|
||||||
discussions = []
|
|
||||||
for row in db_discussions:
|
|
||||||
discussion_id = row[0]
|
|
||||||
discussion_title = row[1]
|
|
||||||
discussion = {"id": discussion_id, "title":discussion_title, "messages": []}
|
|
||||||
rows = self.select(f"SELECT * FROM message WHERE discussion_id=?",(discussion_id,))
|
|
||||||
for message_row in rows:
|
|
||||||
sender = message_row[1]
|
|
||||||
content = message_row[2]
|
|
||||||
content_type = message_row[3]
|
|
||||||
rank = message_row[4]
|
|
||||||
parent = message_row[5]
|
|
||||||
discussion["messages"].append(
|
|
||||||
{"sender": sender, "content": content, "type": content_type, "rank": rank, "parent": parent}
|
|
||||||
)
|
|
||||||
discussions.append(discussion)
|
|
||||||
return discussions
|
|
||||||
|
|
||||||
|
|
||||||
class Discussion:
|
|
||||||
def __init__(self, discussion_id, discussions_db:DiscussionsDB):
|
|
||||||
self.discussion_id = discussion_id
|
|
||||||
self.discussions_db = discussions_db
|
|
||||||
|
|
||||||
def add_message(self, sender, content, message_type=0, rank=0, parent=0):
|
|
||||||
"""Adds a new message to the discussion
|
|
||||||
|
|
||||||
Args:
|
|
||||||
sender (str): The sender name
|
|
||||||
content (str): The text sent by the sender
|
|
||||||
|
|
||||||
Returns:
|
|
||||||
int: The added message id
|
|
||||||
"""
|
|
||||||
message_id = self.discussions_db.insert(
|
|
||||||
"INSERT INTO message (sender, content, type, rank, parent, discussion_id) VALUES (?, ?, ?, ?, ?, ?)",
|
|
||||||
(sender, content, message_type, rank, parent, self.discussion_id)
|
|
||||||
)
|
|
||||||
return message_id
|
|
||||||
|
|
||||||
def rename(self, new_title):
|
|
||||||
"""Renames the discussion
|
|
||||||
|
|
||||||
Args:
|
|
||||||
new_title (str): The nex discussion name
|
|
||||||
"""
|
|
||||||
self.discussions_db.update(
|
|
||||||
f"UPDATE discussion SET title=? WHERE id=?",(new_title,self.discussion_id)
|
|
||||||
)
|
|
||||||
|
|
||||||
def delete_discussion(self):
|
|
||||||
"""Deletes the discussion
|
|
||||||
"""
|
|
||||||
self.discussions_db.delete(
|
|
||||||
f"DELETE FROM message WHERE discussion_id={self.discussion_id}"
|
|
||||||
)
|
|
||||||
self.discussions_db.delete(
|
|
||||||
f"DELETE FROM discussion WHERE id={self.discussion_id}"
|
|
||||||
)
|
|
||||||
|
|
||||||
def get_messages(self):
|
|
||||||
"""Gets a list of messages information
|
|
||||||
|
|
||||||
Returns:
|
|
||||||
list: List of entries in the format {"id":message id, "sender":sender name, "content":message content, "type":message type, "rank": message rank}
|
|
||||||
"""
|
|
||||||
rows = self.discussions_db.select(
|
|
||||||
"SELECT * FROM message WHERE discussion_id=?", (self.discussion_id,)
|
|
||||||
)
|
|
||||||
|
|
||||||
return [{"id": row[0], "sender": row[1], "content": row[2], "type": row[3], "rank": row[4], "parent": row[5]} for row in rows]
|
|
||||||
|
|
||||||
def update_message(self, message_id, new_content):
|
|
||||||
"""Updates the content of a message
|
|
||||||
|
|
||||||
Args:
|
|
||||||
message_id (int): The id of the message to be changed
|
|
||||||
new_content (str): The nex message content
|
|
||||||
"""
|
|
||||||
self.discussions_db.update(
|
|
||||||
f"UPDATE message SET content = ? WHERE id = ?",(new_content,message_id)
|
|
||||||
)
|
|
||||||
|
|
||||||
def message_rank_up(self, message_id):
|
|
||||||
"""Increments the rank of the message
|
|
||||||
|
|
||||||
Args:
|
|
||||||
message_id (int): The id of the message to be changed
|
|
||||||
"""
|
|
||||||
# Retrieve current rank value for message_id
|
|
||||||
current_rank = self.discussions_db.select("SELECT rank FROM message WHERE id=?", (message_id,),False)[0]
|
|
||||||
|
|
||||||
# Increment current rank value by 1
|
|
||||||
new_rank = current_rank + 1
|
|
||||||
self.discussions_db.update(
|
|
||||||
f"UPDATE message SET rank = ? WHERE id = ?",(new_rank,message_id)
|
|
||||||
)
|
|
||||||
return new_rank
|
|
||||||
|
|
||||||
def message_rank_down(self, message_id):
|
|
||||||
"""Increments the rank of the message
|
|
||||||
|
|
||||||
Args:
|
|
||||||
message_id (int): The id of the message to be changed
|
|
||||||
"""
|
|
||||||
# Retrieve current rank value for message_id
|
|
||||||
current_rank = self.discussions_db.select("SELECT rank FROM message WHERE id=?", (message_id,),False)[0]
|
|
||||||
|
|
||||||
# Increment current rank value by 1
|
|
||||||
new_rank = current_rank - 1
|
|
||||||
self.discussions_db.update(
|
|
||||||
f"UPDATE message SET rank = ? WHERE id = ?",(new_rank,message_id)
|
|
||||||
)
|
|
||||||
return new_rank
|
|
||||||
|
|
||||||
def delete_message(self, message_id):
|
|
||||||
"""Delete the message
|
|
||||||
|
|
||||||
Args:
|
|
||||||
message_id (int): The id of the message to be deleted
|
|
||||||
"""
|
|
||||||
# Retrieve current rank value for message_id
|
|
||||||
self.discussions_db.delete("DELETE FROM message WHERE id=?", (message_id,))
|
|
||||||
|
|
||||||
# ========================================================================================================================
|
|
||||||
@ -1,18 +0,0 @@
|
|||||||
# File : extension.py
|
|
||||||
# Author : ParisNeo
|
|
||||||
# Description :
|
|
||||||
# This is the main class to be imported by the extension
|
|
||||||
# it gives your code access to the model, the callback functions, the model conditionning etc
|
|
||||||
from config import load_config, save_config
|
|
||||||
|
|
||||||
__author__ = "parisneo"
|
|
||||||
__github__ = "https://github.com/nomic-ai/gpt4all-ui"
|
|
||||||
__copyright__ = "Copyright 2023, "
|
|
||||||
__license__ = "Apache 2.0"
|
|
||||||
|
|
||||||
class Extension():
|
|
||||||
def __init__(self, metadata_file_path:str, app) -> None:
|
|
||||||
self.app = app
|
|
||||||
self.metadata_file_path = metadata_file_path
|
|
||||||
self.config = load_config(metadata_file_path)
|
|
||||||
|
|
||||||
@ -1,14 +1,15 @@
|
|||||||
|
tqdm
|
||||||
|
psutil
|
||||||
flask
|
flask
|
||||||
flask_socketio
|
flask_socketio
|
||||||
nomic
|
|
||||||
pytest
|
pytest
|
||||||
pyyaml
|
pyyaml
|
||||||
markdown
|
markdown
|
||||||
pyllamacpp==1.0.7
|
gevent
|
||||||
gpt4all-j==0.2.1
|
gevent-websocket
|
||||||
--find-links https://download.pytorch.org/whl/cu117
|
lollms==2.1.14
|
||||||
torch==2.0.0
|
langchain
|
||||||
torchvision
|
requests
|
||||||
torchaudio
|
eventlet
|
||||||
transformers
|
websocket-client
|
||||||
accelerate
|
pywhispercpp
|
||||||
@ -1,9 +1,12 @@
|
|||||||
|
tqdm
|
||||||
flask
|
flask
|
||||||
flask_socketio
|
flask_socketio
|
||||||
nomic
|
nomic
|
||||||
pytest
|
pytest
|
||||||
pyyaml
|
pyyaml
|
||||||
markdown
|
markdown
|
||||||
pyllamacpp==1.0.7
|
pyllamacpp==2.0.0
|
||||||
gpt4all-j
|
gpt4all-j
|
||||||
|
gpt4all
|
||||||
transformers
|
transformers
|
||||||
|
pyaipersonality>=0.0.11
|
||||||
|
|||||||
20
scripts/convert_model.sh
Normal file
@ -0,0 +1,20 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
## untested Linux shell script
|
||||||
|
#
|
||||||
|
|
||||||
|
#set filename=../models/%1
|
||||||
|
FILENAME="../models/$1"
|
||||||
|
#set newname=../models/%1.original
|
||||||
|
NEWNAME="../models/$1.original"
|
||||||
|
|
||||||
|
#echo %modelPath%
|
||||||
|
echo Converting the model to the new format...
|
||||||
|
#if not exist tmp\llama.cpp git clone https://github.com/ggerganov/llama.cpp.git tmp\llama.cpp
|
||||||
|
if [! -e tmp\llama.cpp]; then $(git clone https://github.com/ggerganov/llama.cpp.git tmp\llama.cpp)
|
||||||
|
cd tmp\llama.cpp
|
||||||
|
cd ../..
|
||||||
|
#move /y "%filename%" "%newname%"
|
||||||
|
mv -f $FILENAME $NEWNAME
|
||||||
|
echo Converting ...
|
||||||
|
#python tmp\llama.cpp\convert.py "%newname%" --outfile "%filename%"
|
||||||
|
python -c tmp\llama.cpp\convert.py \"$NEWNAME\" --outfile \"$FILENAME\"
|
||||||
13
scripts/convert_model_ggml.sh
Normal file
@ -0,0 +1,13 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
## Untested Linux shell script
|
||||||
|
#
|
||||||
|
FILENAME="../models/alpaca"
|
||||||
|
TOKENIZER="../models/alpaca/alpaca_tokenizer.model"
|
||||||
|
# echo %modelPath%
|
||||||
|
echo Converting the model to the new format...
|
||||||
|
if [! -e tmp\llama.cpp]; then $(git clone https://github.com/ggerganov/llama.cpp.git tmp\llama.cpp)
|
||||||
|
cd tmp\llama.cpp
|
||||||
|
$(git checkout 6c248707f51c8a50f7792e7f7787ec481881db88)
|
||||||
|
cd ../..
|
||||||
|
echo Converting ...
|
||||||
|
python -c tmp\llama.cpp\convert-gpt4all-to-ggml.py \"$FILENAME\" \"$TOKENIZER\"
|
||||||
16
scripts/convert_model_with_tokenizer.sh
Normal file
@ -0,0 +1,16 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
## untested Linux shell script
|
||||||
|
#
|
||||||
|
FILENAME="../models/$1"
|
||||||
|
NEWNAME="../models/$1.original"
|
||||||
|
|
||||||
|
#echo %modelPath%
|
||||||
|
echo Converting the model to the new format...
|
||||||
|
#if not exist tmp\llama.cpp git clone https://github.com/ggerganov/llama.cpp.git tmp\llama.cpp
|
||||||
|
if [! -e tmp\llama.cpp]; then $(git clone https://github.com/ggerganov/llama.cpp.git tmp\llama.cpp)
|
||||||
|
cd tmp\llama.cpp
|
||||||
|
cd ../..
|
||||||
|
#move /y "%filename%" "%newname%"
|
||||||
|
mv -f $FILENAME $NEWNAME
|
||||||
|
echo Converting ...
|
||||||
|
python -c tmp\llama.cpp\convert.py \"$NEWNAME\" --outfile \"$FILENAME\" --vocab-dir $2
|
||||||
4
setup.py
@ -20,10 +20,10 @@ setuptools.setup(
|
|||||||
version="0.0.5",
|
version="0.0.5",
|
||||||
author="Saifeddine ALOUI",
|
author="Saifeddine ALOUI",
|
||||||
author_email="aloui.saifeddine@gmail.com",
|
author_email="aloui.saifeddine@gmail.com",
|
||||||
description="A web ui for running chat models with different backends. Supports multiple personalities and extensions.",
|
description="A web ui for running chat models with different bindings. Supports multiple personalities and extensions.",
|
||||||
long_description=long_description,
|
long_description=long_description,
|
||||||
long_description_content_type="text/markdown",
|
long_description_content_type="text/markdown",
|
||||||
url="https://github.com/nomic-ai/gpt4all-ui",
|
url="https://github.com/ParisNeo/lollms-webui",
|
||||||
packages=setuptools.find_packages(),
|
packages=setuptools.find_packages(),
|
||||||
install_requires=requirements,
|
install_requires=requirements,
|
||||||
extras_require={"dev": requirements_dev},
|
extras_require={"dev": requirements_dev},
|
||||||
|
|||||||
BIN
static/favicon.ico
Normal file
|
After Width: | Height: | Size: 222 KiB |
BIN
static/images/default_model.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 245 KiB |
@ -15,8 +15,6 @@ function addMessage(sender, message, id, rank = 0, can_edit = false) {
|
|||||||
const chatForm = document.getElementById('chat-form');
|
const chatForm = document.getElementById('chat-form');
|
||||||
const userInput = document.getElementById('user-input');
|
const userInput = document.getElementById('user-input');
|
||||||
|
|
||||||
console.log(id)
|
|
||||||
|
|
||||||
const messageElement = document.createElement('div');
|
const messageElement = document.createElement('div');
|
||||||
messageElement.classList.add('bg-secondary', 'drop-shadow-sm', 'p-4', 'mx-6', 'my-4', 'flex', 'flex-col', 'space-x-2', 'rounded-lg', 'shadow-lg', 'bg-gray-300', 'text-black', 'dark:text-gray-200', 'dark:bg-gray-800', 'hover:bg-gray-400', 'dark:hover:bg-gray-700', 'transition-colors', 'duration-300');
|
messageElement.classList.add('bg-secondary', 'drop-shadow-sm', 'p-4', 'mx-6', 'my-4', 'flex', 'flex-col', 'space-x-2', 'rounded-lg', 'shadow-lg', 'bg-gray-300', 'text-black', 'dark:text-gray-200', 'dark:bg-gray-800', 'hover:bg-gray-400', 'dark:hover:bg-gray-700', 'transition-colors', 'duration-300');
|
||||||
|
|
||||||
@ -88,85 +86,12 @@ function addMessage(sender, message, id, rank = 0, can_edit = false) {
|
|||||||
waitAnimation.style.display = "block";
|
waitAnimation.style.display = "block";
|
||||||
stopGeneration.style.display = "block";
|
stopGeneration.style.display = "block";
|
||||||
|
|
||||||
elements = addMessage("", "", 0, 0, can_edit = true);
|
globals.bot_msg = addMessage("", "", 0, 0, can_edit = true);
|
||||||
|
globals.user_msg = undefined
|
||||||
// scroll to bottom of chat window
|
// scroll to bottom of chat window
|
||||||
chatWindow.scrollTop = chatWindow.scrollHeight;
|
chatWindow.scrollTop = chatWindow.scrollHeight;
|
||||||
fetch("/run_to", {
|
send_message('generate_msg_from',{prompt: message, id: messageElement.id})
|
||||||
method: 'POST',
|
|
||||||
headers: {
|
|
||||||
'Content-Type': 'application/json'
|
|
||||||
},
|
|
||||||
body: JSON.stringify({
|
|
||||||
id: messageElement.id,
|
|
||||||
message: message
|
|
||||||
})
|
|
||||||
})
|
|
||||||
.then(function (response) {
|
|
||||||
const stream = new ReadableStream({
|
|
||||||
start(controller) {
|
|
||||||
const reader = response.body.getReader();
|
|
||||||
function push() {
|
|
||||||
reader.read().then(function (result) {
|
|
||||||
if (result.done) {
|
|
||||||
console.log(result)
|
|
||||||
sendbtn.style.display = "block";
|
|
||||||
waitAnimation.style.display = "none";
|
|
||||||
stopGeneration.style.display = "none";
|
|
||||||
controller.close();
|
|
||||||
return;
|
|
||||||
}
|
|
||||||
controller.enqueue(result.value);
|
|
||||||
push();
|
|
||||||
})
|
|
||||||
}
|
|
||||||
push();
|
|
||||||
}
|
|
||||||
});
|
|
||||||
const textDecoder = new TextDecoder();
|
|
||||||
const readableStreamDefaultReader = stream.getReader();
|
|
||||||
let entry_counter = 0
|
|
||||||
function readStream() {
|
|
||||||
readableStreamDefaultReader.read().then(function (result) {
|
|
||||||
if (result.done) {
|
|
||||||
console.log(result)
|
|
||||||
return;
|
|
||||||
}
|
|
||||||
|
|
||||||
text = textDecoder.decode(result.value);
|
|
||||||
|
|
||||||
// The server will first send a json containing information about the message just sent
|
|
||||||
if (entry_counter == 0) {
|
|
||||||
// We parse it and
|
|
||||||
infos = JSON.parse(text)
|
|
||||||
elements.setID(infos.response_id)
|
|
||||||
elements.setSender(infos.bot)
|
|
||||||
entry_counter++;
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
entry_counter++;
|
|
||||||
prefix = "FINAL:";
|
|
||||||
if(text.startsWith(prefix)){
|
|
||||||
console.log("Final text found")
|
|
||||||
text = text.substring(prefix.length);
|
|
||||||
elements.hiddenElement.innerHTML = text
|
|
||||||
elements.messageTextElement.innerHTML = text
|
|
||||||
}
|
|
||||||
else{
|
|
||||||
// For the other enrtries, these are just the text of the chatbot
|
|
||||||
txt = hiddenElement_.innerHTML;
|
|
||||||
txt += text
|
|
||||||
elements.hiddenElement.innerHTML = txt
|
|
||||||
elements.messageTextElement.innerHTML = txt
|
|
||||||
// scroll to bottom of chat window
|
|
||||||
chatWindow.scrollTop = chatWindow.scrollHeight;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
readStream();
|
|
||||||
});
|
|
||||||
}
|
|
||||||
readStream();
|
|
||||||
});
|
|
||||||
});
|
});
|
||||||
|
|
||||||
const editButton = document.createElement('button');
|
const editButton = document.createElement('button');
|
||||||
|
|||||||
@ -1,16 +1,19 @@
|
|||||||
function update_main(){
|
function update_main(){
|
||||||
const chatWindow = document.getElementById('chat-window');
|
globals.chatWindow = document.getElementById('chat-window');
|
||||||
const chatForm = document.getElementById('chat-form');
|
globals.chatForm = document.getElementById('chat-form');
|
||||||
const userInput = document.getElementById('user-input');
|
globals.userInput = document.getElementById('user-input');
|
||||||
const stopGeneration = document.getElementById("stop-generation")
|
globals.stopGeneration = document.getElementById("stop-generation")
|
||||||
|
globals.sendbtn = document.querySelector("#submit-input")
|
||||||
|
globals.waitAnimation = document.querySelector("#wait-animation")
|
||||||
|
|
||||||
stopGeneration.addEventListener('click', (event) =>{
|
globals.stopGeneration.addEventListener('click', (event) =>{
|
||||||
event.preventDefault();
|
event.preventDefault();
|
||||||
console.log("Stop clicked");
|
console.log("Stop clicked");
|
||||||
fetch('/stop_gen')
|
fetch('/stop_gen')
|
||||||
.then(response => response.json())
|
.then(response => response.json())
|
||||||
.then(data => {
|
.then(data => {
|
||||||
console.log(data);
|
console.log(data);
|
||||||
|
globals.is_generating = true
|
||||||
});
|
});
|
||||||
|
|
||||||
})
|
})
|
||||||
@ -20,73 +23,28 @@ function update_main(){
|
|||||||
console.log("Submitting")
|
console.log("Submitting")
|
||||||
|
|
||||||
// get user input and clear input field
|
// get user input and clear input field
|
||||||
message = userInput.value;
|
message = globals.userInput.value;
|
||||||
userInput.value = '';
|
globals.userInput.value = '';
|
||||||
|
globals.sendbtn.style.display="none";
|
||||||
// add user message to chat window
|
globals.waitAnimation.style.display="block";
|
||||||
const sendbtn = document.querySelector("#submit-input")
|
globals.stopGeneration.style.display = "block";
|
||||||
const waitAnimation = document.querySelector("#wait-animation")
|
|
||||||
const stopGeneration = document.querySelector("#stop-generation")
|
|
||||||
|
|
||||||
sendbtn.style.display="none";
|
|
||||||
waitAnimation.style.display="block";
|
|
||||||
stopGeneration.style.display = "block";
|
|
||||||
console.log("Sending message to bot")
|
console.log("Sending message to bot")
|
||||||
|
|
||||||
user_msg = addMessage('',message, 0, 0, can_edit=true);
|
globals.user_msg = addMessage('',message, 0, 0, can_edit=true);
|
||||||
bot_msg = addMessage('', '', 0, 0, can_edit=true);
|
globals.bot_msg = addMessage('', '', 0, 0, can_edit=true);
|
||||||
// scroll to bottom of chat window
|
// scroll to bottom of chat window
|
||||||
chatWindow.scrollTop = chatWindow.scrollHeight;
|
globals.chatWindow.scrollTop = globals.chatWindow.scrollHeight;
|
||||||
|
|
||||||
var socket = io.connect('http://' + document.domain + ':' + location.port);
|
send_message('generate_msg',{prompt: message})
|
||||||
entry_counter = 0;
|
|
||||||
|
|
||||||
socket.on('connect', function() {
|
|
||||||
socket.emit('connected', {prompt: message});
|
|
||||||
entry_counter = 0;
|
|
||||||
});
|
|
||||||
socket.on('disconnect', function() {
|
|
||||||
|
|
||||||
entry_counter = 0;
|
|
||||||
});
|
|
||||||
socket.on()
|
|
||||||
|
|
||||||
socket.on('infos', function(msg) {
|
|
||||||
user_msg.setSender(msg.user);
|
|
||||||
user_msg.setMessage(msg.message);
|
|
||||||
user_msg.setID(msg.id);
|
|
||||||
bot_msg.setSender(msg.bot);
|
|
||||||
bot_msg.setID(msg.response_id);
|
|
||||||
});
|
|
||||||
|
|
||||||
socket.on('message', function(msg) {
|
|
||||||
text = msg.data;
|
|
||||||
console.log(text)
|
|
||||||
// For the other enrtries, these are just the text of the chatbot
|
|
||||||
txt = bot_msg.hiddenElement.innerHTML;
|
|
||||||
txt += text
|
|
||||||
bot_msg.hiddenElement.innerHTML = txt;
|
|
||||||
bot_msg.messageTextElement.innerHTML = txt;
|
|
||||||
// scroll to bottom of chat window
|
|
||||||
chatWindow.scrollTop = chatWindow.scrollHeight;
|
|
||||||
});
|
|
||||||
|
|
||||||
socket.on('final',function(msg){
|
|
||||||
text = msg.data;
|
|
||||||
bot_msg.hiddenElement.innerHTML = text
|
|
||||||
bot_msg.messageTextElement.innerHTML = text
|
|
||||||
sendbtn.style.display="block";
|
|
||||||
waitAnimation.style.display="none";
|
|
||||||
stopGeneration.style.display = "none";
|
|
||||||
socket.disconnect();
|
|
||||||
});
|
|
||||||
//socket.emit('stream-text', {text: text});
|
//socket.emit('stream-text', {text: text});
|
||||||
}
|
}
|
||||||
chatForm.addEventListener('submit', event => {
|
globals.chatForm.addEventListener('submit', event => {
|
||||||
event.preventDefault();
|
event.preventDefault();
|
||||||
submit_form();
|
submit_form();
|
||||||
});
|
});
|
||||||
userInput.addEventListener("keyup", function(event) {
|
globals.userInput.addEventListener("keyup", function(event) {
|
||||||
// Check if Enter key was pressed while holding Shift
|
// Check if Enter key was pressed while holding Shift
|
||||||
// Also check if Shift + Ctrl keys were pressed while typing
|
// Also check if Shift + Ctrl keys were pressed while typing
|
||||||
// These combinations override the submit action
|
// These combinations override the submit action
|
||||||
@ -96,13 +54,5 @@ function update_main(){
|
|||||||
if ((!shiftPressed) && event.key === "Enter") {
|
if ((!shiftPressed) && event.key === "Enter") {
|
||||||
submit_form();
|
submit_form();
|
||||||
}
|
}
|
||||||
// Restore original functionality for the remaining cases
|
|
||||||
else if (!shiftPressed && ctrlPressed) {
|
|
||||||
setTimeout(() => {
|
|
||||||
userInput.focus();
|
|
||||||
contentEditable.value += event.data;
|
|
||||||
lastValue.innerHTML = userInput.value;
|
|
||||||
}, 0);
|
|
||||||
}
|
|
||||||
});
|
});
|
||||||
}
|
}
|
||||||
@ -13,7 +13,7 @@ fetch('/settings')
|
|||||||
.then(response => response.text())
|
.then(response => response.text())
|
||||||
.then(html => {
|
.then(html => {
|
||||||
document.getElementById('settings').innerHTML = html;
|
document.getElementById('settings').innerHTML = html;
|
||||||
backendInput = document.getElementById('backend');
|
bindingInput = document.getElementById('binding');
|
||||||
modelInput = document.getElementById('model');
|
modelInput = document.getElementById('model');
|
||||||
personalityLanguageInput = document.getElementById('personalities_language');
|
personalityLanguageInput = document.getElementById('personalities_language');
|
||||||
personalityCategoryInput = document.getElementById('personalities_category');
|
personalityCategoryInput = document.getElementById('personalities_category');
|
||||||
@ -21,7 +21,7 @@ fetch('/settings')
|
|||||||
languageInput = document.getElementById('language');
|
languageInput = document.getElementById('language');
|
||||||
voiceInput = document.getElementById('voice');
|
voiceInput = document.getElementById('voice');
|
||||||
seedInput = document.getElementById('seed');
|
seedInput = document.getElementById('seed');
|
||||||
tempInput = document.getElementById('temp');
|
tempInput = document.getElementById('temperature');
|
||||||
nPredictInput = document.getElementById('n-predict');
|
nPredictInput = document.getElementById('n-predict');
|
||||||
topKInput = document.getElementById('top-k');
|
topKInput = document.getElementById('top-k');
|
||||||
topPInput = document.getElementById('top-p');
|
topPInput = document.getElementById('top-p');
|
||||||
@ -43,7 +43,7 @@ fetch('/settings')
|
|||||||
.then((data) => {
|
.then((data) => {
|
||||||
console.log("Received config")
|
console.log("Received config")
|
||||||
console.log(data);
|
console.log(data);
|
||||||
selectOptionByText(backendInput, data["backend"])
|
selectOptionByText(bindingInput, data["binding"])
|
||||||
selectOptionByText(modelInput, data["model"])
|
selectOptionByText(modelInput, data["model"])
|
||||||
selectOptionByText(personalityLanguageInput, data["personality_language"])
|
selectOptionByText(personalityLanguageInput, data["personality_language"])
|
||||||
selectOptionByText(personalityCategoryInput, data["personality_category"])
|
selectOptionByText(personalityCategoryInput, data["personality_category"])
|
||||||
@ -51,7 +51,7 @@ fetch('/settings')
|
|||||||
languageInput.value = data["language"]
|
languageInput.value = data["language"]
|
||||||
voiceInput.value = data["voice"]
|
voiceInput.value = data["voice"]
|
||||||
seedInput.value = data["seed"]
|
seedInput.value = data["seed"]
|
||||||
tempInput.value = data["temp"]
|
tempInput.value = data["temperature"]
|
||||||
nPredictInput.value = data["n_predict"]
|
nPredictInput.value = data["n_predict"]
|
||||||
topKInput.value = data["top_k"]
|
topKInput.value = data["top_k"]
|
||||||
topPInput.value = data["top_p"]
|
topPInput.value = data["top_p"]
|
||||||
@ -59,7 +59,7 @@ fetch('/settings')
|
|||||||
repeatPenaltyInput.textContent = data["repeat_penalty"]
|
repeatPenaltyInput.textContent = data["repeat_penalty"]
|
||||||
repeatLastNInput.textContent = data["repeat_last_n"]
|
repeatLastNInput.textContent = data["repeat_last_n"]
|
||||||
|
|
||||||
temperatureValue.textContent =`Temperature(${data["temp"]})`
|
temperatureValue.textContent =`Temperature(${data["temperature"]})`
|
||||||
n_predictValue.textContent =`N Predict(${data["n_predict"]})`
|
n_predictValue.textContent =`N Predict(${data["n_predict"]})`
|
||||||
|
|
||||||
topkValue.textContent =`Top-K(${data["top_k"]})`
|
topkValue.textContent =`Top-K(${data["top_k"]})`
|
||||||
@ -74,25 +74,25 @@ fetch('/settings')
|
|||||||
|
|
||||||
}
|
}
|
||||||
|
|
||||||
backendInput.addEventListener('input',() => {
|
bindingInput.addEventListener('input',() => {
|
||||||
console.log(`Backend (${backendInput.value})`)
|
console.log(`Binding (${bindingInput.value})`)
|
||||||
// Use fetch to send form values to Flask endpoint
|
// Use fetch to send form values to Flask endpoint
|
||||||
fetch('/set_backend', {
|
fetch('/set_binding', {
|
||||||
method: 'POST',
|
method: 'POST',
|
||||||
headers: {
|
headers: {
|
||||||
'Content-Type': 'application/json',
|
'Content-Type': 'application/json',
|
||||||
},
|
},
|
||||||
body: JSON.stringify({"backend":backendInput.value}),
|
body: JSON.stringify({"binding":bindingInput.value}),
|
||||||
})
|
})
|
||||||
.then((response) => response.json())
|
.then((response) => response.json())
|
||||||
.then((data) => {
|
.then((data) => {
|
||||||
console.log(data);
|
console.log(data);
|
||||||
if(data["status"]==="no_models_found"){
|
if(data["status"]==="no_models_found"){
|
||||||
alert("No models found for this backend. Make sure you select a backend that you have models for or download models from links in our repository")
|
alert("No models found for this binding. Make sure you select a binding that you have models for or download models from links in our repository")
|
||||||
}
|
}
|
||||||
else{
|
else{
|
||||||
populate_settings();
|
populate_settings();
|
||||||
alert("Backend set successfully")
|
alert("Binding set successfully")
|
||||||
}
|
}
|
||||||
})
|
})
|
||||||
.catch((error) => {
|
.catch((error) => {
|
||||||
@ -115,7 +115,7 @@ fetch('/settings')
|
|||||||
.then((data) => {
|
.then((data) => {
|
||||||
console.log(data);
|
console.log(data);
|
||||||
populate_settings();
|
populate_settings();
|
||||||
alert("Backend set successfully")
|
alert("Binding set successfully")
|
||||||
})
|
})
|
||||||
.catch((error) => {
|
.catch((error) => {
|
||||||
console.error('Error:', error);
|
console.error('Error:', error);
|
||||||
@ -159,14 +159,14 @@ fetch('/settings')
|
|||||||
// Get form values and put them in an object
|
// Get form values and put them in an object
|
||||||
const formValues = {
|
const formValues = {
|
||||||
seed: seedInput.value,
|
seed: seedInput.value,
|
||||||
backend: backendInput.value,
|
binding: bindingInput.value,
|
||||||
model: modelInput.value,
|
model: modelInput.value,
|
||||||
personality_language:personalityLanguageInput.value,
|
personality_language:personalityLanguageInput.value,
|
||||||
personality_category:personalityCategoryInput.value,
|
personality_category:personalityCategoryInput.value,
|
||||||
personality: personalityInput.value,
|
personality: personalityInput.value,
|
||||||
language: languageInput.value,
|
language: languageInput.value,
|
||||||
voice: voiceInput.value,
|
voice: voiceInput.value,
|
||||||
temp: tempInput.value,
|
temperature: tempInput.value,
|
||||||
nPredict: nPredictInput.value,
|
nPredict: nPredictInput.value,
|
||||||
topK: topKInput.value,
|
topK: topKInput.value,
|
||||||
topP: topPInput.value,
|
topP: topPInput.value,
|
||||||
@ -197,17 +197,17 @@ fetch('/settings')
|
|||||||
|
|
||||||
function populate_settings(){
|
function populate_settings(){
|
||||||
// Get a reference to the <select> element
|
// Get a reference to the <select> element
|
||||||
const selectBackend = document.getElementById('backend');
|
const selectBinding = document.getElementById('binding');
|
||||||
const selectModel = document.getElementById('model');
|
const selectModel = document.getElementById('model');
|
||||||
|
|
||||||
const selectPersonalityLanguage = document.getElementById('personalities_language');
|
const selectPersonalityLanguage = document.getElementById('personalities_language');
|
||||||
const selectPersonalityCategory = document.getElementById('personalities_category');
|
const selectPersonalityCategory = document.getElementById('personalities_category');
|
||||||
const selectPersonality = document.getElementById('personalities');
|
const selectPersonality = document.getElementById('personalities');
|
||||||
|
|
||||||
function populate_backends(){
|
function populate_bindings(){
|
||||||
selectBackend.innerHTML = "";
|
selectBinding.innerHTML = "";
|
||||||
// Fetch the list of .bin files from the models subfolder
|
// Fetch the list of .bin files from the models subfolder
|
||||||
fetch('/list_backends')
|
fetch('/list_bindings')
|
||||||
.then(response => response.json())
|
.then(response => response.json())
|
||||||
.then(data => {
|
.then(data => {
|
||||||
if (Array.isArray(data)) {
|
if (Array.isArray(data)) {
|
||||||
@ -216,7 +216,7 @@ fetch('/settings')
|
|||||||
const optionElement = document.createElement('option');
|
const optionElement = document.createElement('option');
|
||||||
optionElement.value = filename;
|
optionElement.value = filename;
|
||||||
optionElement.textContent = filename;
|
optionElement.textContent = filename;
|
||||||
selectBackend.appendChild(optionElement);
|
selectBinding.appendChild(optionElement);
|
||||||
});
|
});
|
||||||
|
|
||||||
// fetch('/get_args')
|
// fetch('/get_args')
|
||||||
@ -356,7 +356,7 @@ fetch('/settings')
|
|||||||
});
|
});
|
||||||
|
|
||||||
|
|
||||||
populate_backends()
|
populate_bindings()
|
||||||
populate_models()
|
populate_models()
|
||||||
populate_personalities_languages()
|
populate_personalities_languages()
|
||||||
populate_personalities_categories()
|
populate_personalities_categories()
|
||||||
|
|||||||
76
static/js/websocket.js
Normal file
@ -0,0 +1,76 @@
|
|||||||
|
// Project : lollms-webui
|
||||||
|
// Author : ParisNeo
|
||||||
|
// Description :
|
||||||
|
// All websocket stuff can be found here.
|
||||||
|
|
||||||
|
|
||||||
|
var globals={
|
||||||
|
is_generating:false,
|
||||||
|
chatWindow:undefined,
|
||||||
|
chatForm:undefined,
|
||||||
|
userInput:undefined,
|
||||||
|
stopGeneration:undefined,
|
||||||
|
sendbtn:undefined,
|
||||||
|
waitAnimation:undefined
|
||||||
|
}
|
||||||
|
|
||||||
|
var socket = io.connect(location.protocol + '//' + document.domain + ':' + location.port);
|
||||||
|
|
||||||
|
socket.on('connect', function() {
|
||||||
|
});
|
||||||
|
socket.on('disconnect', function() {
|
||||||
|
console.log("Disconnected")
|
||||||
|
});
|
||||||
|
socket.on('infos', function(msg) {
|
||||||
|
console.log(msg)
|
||||||
|
if(msg["status"]=="generation_started"){
|
||||||
|
if(globals.user_msg){
|
||||||
|
globals.user_msg.setSender(msg.user);
|
||||||
|
globals.user_msg.setMessage(msg.message);
|
||||||
|
globals.user_msg.setID(msg.id);
|
||||||
|
}
|
||||||
|
globals.bot_msg.setSender(msg.bot);
|
||||||
|
globals.bot_msg.setID(msg.ai_message_id);
|
||||||
|
globals.bot_msg.messageTextElement.innerHTML = `Generating answer. Please stand by...`;
|
||||||
|
}
|
||||||
|
else{
|
||||||
|
globals.sendbtn.style.display="block";
|
||||||
|
globals.waitAnimation.style.display="none";
|
||||||
|
globals.stopGeneration.style.display = "none";
|
||||||
|
globals.is_generating = false
|
||||||
|
alert("It seems that no model has been loaded. Please download and install a model first, then try again.");
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
socket.on('waiter', function(msg) {
|
||||||
|
globals.bot_msg.messageTextElement.innerHTML = `Generating answer. Please stand by...`;
|
||||||
|
});
|
||||||
|
|
||||||
|
socket.on('message', function(msg) {
|
||||||
|
text = msg.data;
|
||||||
|
// For the other enrtries, these are just the text of the chatbot
|
||||||
|
|
||||||
|
globals.bot_msg.messageTextElement.innerHTML = marked.marked(text);
|
||||||
|
// scroll to bottom of chat window
|
||||||
|
globals.chatWindow.scrollTop = globals.chatWindow.scrollHeight;
|
||||||
|
});
|
||||||
|
|
||||||
|
socket.on('final',function(msg){
|
||||||
|
text = msg.data;
|
||||||
|
globals.bot_msg.hiddenElement.innerHTML = text
|
||||||
|
globals.bot_msg.messageTextElement.innerHTML = marked.marked(text)
|
||||||
|
globals.sendbtn.style.display="block";
|
||||||
|
globals.waitAnimation.style.display="none";
|
||||||
|
globals.stopGeneration.style.display = "none";
|
||||||
|
globals.is_generating = false
|
||||||
|
});
|
||||||
|
|
||||||
|
globals.socket = socket
|
||||||
|
globals.is_generating = false
|
||||||
|
|
||||||
|
function send_message(service_name, parameters){
|
||||||
|
if(!globals.is_generating){
|
||||||
|
globals.socket.emit(service_name, parameters);
|
||||||
|
globals.is_generating = true
|
||||||
|
}
|
||||||
|
}
|
||||||
@ -4,7 +4,7 @@
|
|||||||
<head>
|
<head>
|
||||||
<meta charset="UTF-8">
|
<meta charset="UTF-8">
|
||||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||||
<title>Help | GPT4All-ui</title>
|
<title>Help | lollms-webui</title>
|
||||||
<!-- Include Tailwind CSS -->
|
<!-- Include Tailwind CSS -->
|
||||||
<link rel="stylesheet" href="{{ url_for('static', filename='css/utilities.min.css') }}">
|
<link rel="stylesheet" href="{{ url_for('static', filename='css/utilities.min.css') }}">
|
||||||
<link rel="stylesheet" href="{{ url_for('static', filename='css/tailwind.min.css') }}">
|
<link rel="stylesheet" href="{{ url_for('static', filename='css/tailwind.min.css') }}">
|
||||||
@ -17,7 +17,7 @@
|
|||||||
<body>
|
<body>
|
||||||
<!-- Navbar -->
|
<!-- Navbar -->
|
||||||
<nav class="flex justify-between items-center bg-gray-200 dark:bg-gray-900 text-black dark:text-white p-4">
|
<nav class="flex justify-between items-center bg-gray-200 dark:bg-gray-900 text-black dark:text-white p-4">
|
||||||
<a href="/" class="text-lg font-bold">GPT4All-ui</a>
|
<a href="/" class="text-lg font-bold">lollms-webui</a>
|
||||||
<!-- Dropdown menu -->
|
<!-- Dropdown menu -->
|
||||||
<div class="relative">
|
<div class="relative">
|
||||||
<button class="flex items-center text-lg font-bold">
|
<button class="flex items-center text-lg font-bold">
|
||||||
@ -44,7 +44,7 @@
|
|||||||
<ul class="list-disc list-inside mb-4">
|
<ul class="list-disc list-inside mb-4">
|
||||||
<li>@ParisNeo : Creator of the project and Lead developer</li>
|
<li>@ParisNeo : Creator of the project and Lead developer</li>
|
||||||
<li>@AndriyMulyar : CEO of Nomic-ai who offered to link the project as their official ui for GPT4All</li>
|
<li>@AndriyMulyar : CEO of Nomic-ai who offered to link the project as their official ui for GPT4All</li>
|
||||||
<li><a href="https://github.com/nomic-ai/gpt4all-ui/graphs/contributors" target="_blank" class="text-blue-900 dark:text-blue-600">A number of very talented open-source developers without whom this project wouldn't be as awesome as it is.</a></li>
|
<li><a href="https://github.com/ParisNeo/lollms-webui/graphs/contributors" target="_blank" class="text-blue-900 dark:text-blue-600">A number of very talented open-source developers without whom this project wouldn't be as awesome as it is.</a></li>
|
||||||
<li> We also appreciate the support of the users of this tool who have helped us in various ways.</li>
|
<li> We also appreciate the support of the users of this tool who have helped us in various ways.</li>
|
||||||
</ul>
|
</ul>
|
||||||
|
|
||||||
|
|||||||
@ -56,6 +56,7 @@
|
|||||||
<footer class="border-t border-accent flex">
|
<footer class="border-t border-accent flex">
|
||||||
</footer>
|
</footer>
|
||||||
<script src="{{ url_for('static', filename='js/socket.io.js') }}"></script>
|
<script src="{{ url_for('static', filename='js/socket.io.js') }}"></script>
|
||||||
|
<script src="{{ url_for('static', filename='js/websocket.js') }}"></script>
|
||||||
<script src="{{ url_for('static', filename='js/chat.js') }}"></script>
|
<script src="{{ url_for('static', filename='js/chat.js') }}"></script>
|
||||||
<script src="{{ url_for('static', filename='js/marked.min.js') }}"></script>
|
<script src="{{ url_for('static', filename='js/marked.min.js') }}"></script>
|
||||||
<script src="{{ url_for('static', filename='js/discussions.js') }}"></script>
|
<script src="{{ url_for('static', filename='js/discussions.js') }}"></script>
|
||||||
|
|||||||
@ -1,8 +1,8 @@
|
|||||||
<div class="h-full overflow-y-auto">
|
<div class="h-full overflow-y-auto">
|
||||||
<form id="model-params-form" class="bg-gray-50 dark:bg-gray-700 shadow-md rounded px-8 py-8 pt-6 pb-8 mb-4 text-black dark:text-white">
|
<form id="model-params-form" class="bg-gray-50 dark:bg-gray-700 shadow-md rounded px-8 py-8 pt-6 pb-8 mb-4 text-black dark:text-white">
|
||||||
<div class="mb-4 flex-row">
|
<div class="mb-4 flex-row">
|
||||||
<label class="font-bold" for="model">Backend</label>
|
<label class="font-bold" for="model">Binding</label>
|
||||||
<select class="bg-gray-200 dark:bg-gray-700 w-96 shadow appearance-none border rounded py-2 px-3 leading-tight focus:outline-none focus:shadow-outline" id="backend" name="backend">
|
<select class="bg-gray-200 dark:bg-gray-700 w-96 shadow appearance-none border rounded py-2 px-3 leading-tight focus:outline-none focus:shadow-outline" id="binding" name="binding">
|
||||||
</select>
|
</select>
|
||||||
</div>
|
</div>
|
||||||
<div class="mb-4 flex-row">
|
<div class="mb-4 flex-row">
|
||||||
@ -41,8 +41,8 @@
|
|||||||
<input class="bg-gray-200 dark:bg-gray-700 shadow appearance-none border rounded py-2 px-3 leading-tight focus:outline-none focus:shadow-outline" id="seed" type="text" name="seed" value="0">
|
<input class="bg-gray-200 dark:bg-gray-700 shadow appearance-none border rounded py-2 px-3 leading-tight focus:outline-none focus:shadow-outline" id="seed" type="text" name="seed" value="0">
|
||||||
</div>
|
</div>
|
||||||
<div class="mb-4 flex-row">
|
<div class="mb-4 flex-row">
|
||||||
<label class="font-bold mb-2" for="temp" id="temperature-value">Temperature (0.1)</label>
|
<label class="font-bold mb-2" for="temperature" id="temperature-value">Temperature (0.1)</label>
|
||||||
<input class="slider-value" id="temp" type="range" min="0" max="1" step="0.1" value="0.1" name="temp">
|
<input class="slider-value" id="temperature" type="range" min="0" max="5" step="0.1" value="0.01" name="temperature">
|
||||||
</div>
|
</div>
|
||||||
<div class="mb-4 flex-row">
|
<div class="mb-4 flex-row">
|
||||||
<label class="font-bold mb-2" for="n-predict" id="n-predict-value">N Predict (256)</label>
|
<label class="font-bold mb-2" for="n-predict" id="n-predict-value">N Predict (256)</label>
|
||||||
|
|||||||
170
tests/end_point_tests/endpoints.http
Normal file
@ -0,0 +1,170 @@
|
|||||||
|
############################################
|
||||||
|
### Create new discussion
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/new_discussion
|
||||||
|
Content-Type: application/json
|
||||||
|
|
||||||
|
{
|
||||||
|
"title": "Some title" // Can be empty
|
||||||
|
}
|
||||||
|
############################################
|
||||||
|
### List discussions
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/list_discussions
|
||||||
|
############################################
|
||||||
|
### Load Discussion by ID
|
||||||
|
############################################
|
||||||
|
POST http://localhost:9600/load_discussion
|
||||||
|
Content-Type: application/json
|
||||||
|
|
||||||
|
{"id": 1}
|
||||||
|
############################################
|
||||||
|
### Delete Discussion by ID
|
||||||
|
############################################
|
||||||
|
POST http://localhost:9600/delete_discussion
|
||||||
|
Content-Type: application/json
|
||||||
|
|
||||||
|
{
|
||||||
|
"id": 0
|
||||||
|
}
|
||||||
|
############################################
|
||||||
|
### Edit discussion title
|
||||||
|
############################################
|
||||||
|
POST http://localhost:9600/edit_title
|
||||||
|
Content-Type: application/json
|
||||||
|
|
||||||
|
{
|
||||||
|
"id": 0, // Discussion ID Must be integer
|
||||||
|
"title": "New title"
|
||||||
|
}
|
||||||
|
############################################
|
||||||
|
### Update message
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/update_message
|
||||||
|
?id=0
|
||||||
|
&message="New Message text"
|
||||||
|
############################################
|
||||||
|
### Update setting
|
||||||
|
############################################
|
||||||
|
POST http://localhost:9600/update_setting
|
||||||
|
Content-Type: application/json
|
||||||
|
|
||||||
|
{
|
||||||
|
"setting_name": "personality_language",
|
||||||
|
"setting_value": "english"
|
||||||
|
}
|
||||||
|
############################################
|
||||||
|
### Get all personalities
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/get_all_personalities
|
||||||
|
############################################
|
||||||
|
### Get current personality
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/get_current_personality
|
||||||
|
############################################
|
||||||
|
### Get current personality infos
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/get_current_personality_path_infos
|
||||||
|
############################################
|
||||||
|
### Mount personality
|
||||||
|
############################################
|
||||||
|
POST http://localhost:9600/mount_personality
|
||||||
|
Content-Type: application/json
|
||||||
|
|
||||||
|
{
|
||||||
|
"language": "english",
|
||||||
|
"category": "generic",
|
||||||
|
"folder": "gpt4all"
|
||||||
|
}
|
||||||
|
############################################
|
||||||
|
### Unmount personality
|
||||||
|
############################################
|
||||||
|
POST http://localhost:9600/unmount_personality
|
||||||
|
Content-Type: application/json
|
||||||
|
|
||||||
|
{
|
||||||
|
"language": "english",
|
||||||
|
"category": "generic",
|
||||||
|
"folder": "lollms"
|
||||||
|
}
|
||||||
|
############################################
|
||||||
|
### Select personality
|
||||||
|
############################################
|
||||||
|
POST http://localhost:9600/select_personality
|
||||||
|
Content-Type: application/json
|
||||||
|
|
||||||
|
{
|
||||||
|
"id": 0 // Array index from get_config.personalities array
|
||||||
|
}
|
||||||
|
|
||||||
|
############################################
|
||||||
|
### Get personality settings
|
||||||
|
############################################
|
||||||
|
POST http://localhost:9600/get_personality_settings
|
||||||
|
Content-Type: application/json
|
||||||
|
|
||||||
|
{
|
||||||
|
"language": "english",
|
||||||
|
"category": "data",
|
||||||
|
"folder": "text2bulletpoints"
|
||||||
|
}
|
||||||
|
|
||||||
|
############################################
|
||||||
|
### Install model from path
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/install_model_from_path
|
||||||
|
|
||||||
|
############################################
|
||||||
|
### Get active personality settings
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/get_active_personality_settings
|
||||||
|
|
||||||
|
############################################
|
||||||
|
### Get active binding settings
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/get_active_binding_settings
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
####@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
|
||||||
|
####@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
|
||||||
|
###
|
||||||
|
### INFORMATION SECTION
|
||||||
|
###
|
||||||
|
####@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
|
||||||
|
####@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
|
||||||
|
|
||||||
|
|
||||||
|
############################################
|
||||||
|
### List Models
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/list_models
|
||||||
|
############################################
|
||||||
|
### Get avaliable Models
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/get_available_models
|
||||||
|
############################################
|
||||||
|
### List Bindings
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/list_bindings
|
||||||
|
############################################
|
||||||
|
### Get Config
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/get_config
|
||||||
|
############################################
|
||||||
|
### Get generation status
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/get_generation_status
|
||||||
|
############################################
|
||||||
|
### Get disk usage
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/disk_usage
|
||||||
|
############################################
|
||||||
|
### Get ram usage
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/ram_usage
|
||||||
|
|
||||||
|
############################################
|
||||||
|
### Get vram usage
|
||||||
|
############################################
|
||||||
|
GET http://localhost:9600/vram_usage
|
||||||
2
train/.gitignore
vendored
Normal file
@ -0,0 +1,2 @@
|
|||||||
|
output
|
||||||
|
!output/.keep
|
||||||
48
train/configs/deepspeed/ds_config.yaml
Normal file
@ -0,0 +1,48 @@
|
|||||||
|
{
|
||||||
|
"train_batch_size": "auto",
|
||||||
|
"gradient_accumulation_steps": "auto",
|
||||||
|
"train_micro_batch_size_per_gpu": "auto",
|
||||||
|
"fp16": {
|
||||||
|
"enabled": "auto",
|
||||||
|
"min_loss_scale": 1,
|
||||||
|
"loss_scale_window": 1000,
|
||||||
|
"hysteresis": 2,
|
||||||
|
"initial_scale_power": 32
|
||||||
|
},
|
||||||
|
"bf16": {
|
||||||
|
"enabled": "auto"
|
||||||
|
},
|
||||||
|
"gradient_clipping": 1,
|
||||||
|
"zero_optimization": {
|
||||||
|
"stage": 2,
|
||||||
|
"offload_param": {
|
||||||
|
"device": "none"
|
||||||
|
},
|
||||||
|
"offload_optimizer": {
|
||||||
|
"device": "none"
|
||||||
|
},
|
||||||
|
"allgather_partitions": true,
|
||||||
|
"allgather_bucket_size": 5e8,
|
||||||
|
"contiguous_gradients": true
|
||||||
|
},
|
||||||
|
"optimizer": {
|
||||||
|
"type": "AdamW",
|
||||||
|
"params": {
|
||||||
|
"lr": "auto",
|
||||||
|
"betas": [
|
||||||
|
0.9,
|
||||||
|
0.999
|
||||||
|
],
|
||||||
|
"eps": 1e-08
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"scheduler": {
|
||||||
|
"type": "WarmupLR",
|
||||||
|
"params": {
|
||||||
|
"warmup_min_lr": 0,
|
||||||
|
"warmup_max_lr": "auto",
|
||||||
|
"warmup_num_steps": "auto",
|
||||||
|
"warmup_type": "linear"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
1
train/configs/train/.gitignore
vendored
Normal file
@ -0,0 +1 @@
|
|||||||
|
local_cfg.yaml
|
||||||
29
train/configs/train/finetune.yaml
Normal file
@ -0,0 +1,29 @@
|
|||||||
|
# model/tokenizer
|
||||||
|
model_name: # add model here
|
||||||
|
tokenizer_name: # add model here
|
||||||
|
gradient_checkpointing: true
|
||||||
|
save_name: # CHANGE
|
||||||
|
|
||||||
|
# dataset
|
||||||
|
streaming: false
|
||||||
|
num_proc: 64
|
||||||
|
dataset_path: # update
|
||||||
|
max_length: 1024
|
||||||
|
batch_size: 32
|
||||||
|
|
||||||
|
# train dynamics
|
||||||
|
lr: 5.0e-5
|
||||||
|
eval_every: 800
|
||||||
|
eval_steps: 100
|
||||||
|
save_every: 800
|
||||||
|
output_dir: # CHANGE
|
||||||
|
checkpoint: null
|
||||||
|
lora: false
|
||||||
|
warmup_steps: 100
|
||||||
|
num_epochs: 2
|
||||||
|
|
||||||
|
# logging
|
||||||
|
wandb: true
|
||||||
|
wandb_entity: # update
|
||||||
|
wandb_project_name: # update
|
||||||
|
seed: 42
|
||||||
31
train/configs/train/finetune_lora.yaml
Normal file
@ -0,0 +1,31 @@
|
|||||||
|
# model/tokenizer
|
||||||
|
model_name: # update
|
||||||
|
tokenizer_name: # update
|
||||||
|
gradient_checkpointing: false
|
||||||
|
save_name: # CHANGE
|
||||||
|
|
||||||
|
# dataset
|
||||||
|
streaming: false
|
||||||
|
num_proc: 64
|
||||||
|
dataset_path: # CHANGE
|
||||||
|
max_length: 1024
|
||||||
|
batch_size: 4
|
||||||
|
|
||||||
|
# train dynamics
|
||||||
|
lr: 5.0e-5
|
||||||
|
min_lr: 0
|
||||||
|
weight_decay: 0.0
|
||||||
|
eval_every: 2000
|
||||||
|
eval_steps: 100
|
||||||
|
save_every: 2000
|
||||||
|
output_dir: # CHANGE
|
||||||
|
checkpoint: null
|
||||||
|
lora: true
|
||||||
|
warmup_steps: 100
|
||||||
|
num_epochs: 2
|
||||||
|
|
||||||
|
# logging
|
||||||
|
wandb: true
|
||||||
|
wandb_entity: # update
|
||||||
|
wandb_project_name: # update
|
||||||
|
seed: 42
|
||||||
31
train/configs/train/finetune_lora_ airoboros-7b-gpt4.yaml
Normal file
@ -0,0 +1,31 @@
|
|||||||
|
# model/tokenizer
|
||||||
|
model_name: jondurbin/airoboros-7b-gpt4 # update
|
||||||
|
tokenizer_name: jondurbin/airoboros-7b-gpt4 # update
|
||||||
|
gradient_checkpointing: false
|
||||||
|
save_name: parisneo-7b_gpt42_lora # CHANGE
|
||||||
|
|
||||||
|
# dataset
|
||||||
|
streaming: false
|
||||||
|
num_proc: 64
|
||||||
|
dataset_path: # CHANGE
|
||||||
|
max_length: 1024
|
||||||
|
batch_size: 4
|
||||||
|
|
||||||
|
# train dynamics
|
||||||
|
lr: 5.0e-5
|
||||||
|
min_lr: 0
|
||||||
|
weight_decay: 0.0
|
||||||
|
eval_every: 2000
|
||||||
|
eval_steps: 100
|
||||||
|
save_every: 2000
|
||||||
|
output_dir: output # CHANGE
|
||||||
|
checkpoint: null
|
||||||
|
lora: true
|
||||||
|
warmup_steps: 100
|
||||||
|
num_epochs: 2
|
||||||
|
|
||||||
|
# logging
|
||||||
|
wandb: false # update if you want to use weights and biases
|
||||||
|
wandb_entity: # update
|
||||||
|
wandb_project_name: # update
|
||||||
|
seed: 42
|
||||||
15
train/requirements.txt
Normal file
@ -0,0 +1,15 @@
|
|||||||
|
accelerate
|
||||||
|
datasets
|
||||||
|
torchmetrics
|
||||||
|
evaluate
|
||||||
|
transformers>=4.28.0
|
||||||
|
wandb
|
||||||
|
pip
|
||||||
|
peft
|
||||||
|
nodelist-inflator
|
||||||
|
deepspeed
|
||||||
|
sentencepiece
|
||||||
|
jsonlines
|
||||||
|
nomic
|
||||||
|
scikit-learn
|
||||||
|
matplotlib
|
||||||
233
train/train.py
Normal file
@ -0,0 +1,233 @@
|
|||||||
|
import os
|
||||||
|
from transformers import AutoModelForCausalLM, AutoTokenizer, get_scheduler, LlamaForCausalLM
|
||||||
|
import torch
|
||||||
|
from torch.optim import AdamW
|
||||||
|
from argparse import ArgumentParser
|
||||||
|
from read import read_config
|
||||||
|
from accelerate import Accelerator
|
||||||
|
from accelerate.utils import DummyScheduler, DummyOptim, set_seed
|
||||||
|
from peft import get_peft_model, LoraConfig, TaskType
|
||||||
|
from data import load_data
|
||||||
|
from torchmetrics import MeanMetric
|
||||||
|
from tqdm import tqdm
|
||||||
|
import wandb
|
||||||
|
|
||||||
|
torch.backends.cuda.matmul.allow_tf32 = True
|
||||||
|
|
||||||
|
def format_metrics(metrics, split, prefix=""):
|
||||||
|
log = f"[{split}]" + prefix
|
||||||
|
log += " ".join([f"{key}: {value:.4f}" for key, value in metrics.items()])
|
||||||
|
|
||||||
|
return log
|
||||||
|
|
||||||
|
|
||||||
|
def evaluate(model, val_dataloader):
|
||||||
|
model.eval()
|
||||||
|
val_loss = MeanMetric(nan_strategy="error").to(model.device)
|
||||||
|
|
||||||
|
with torch.no_grad():
|
||||||
|
for batch in tqdm(val_dataloader):
|
||||||
|
loss = model(**batch).loss
|
||||||
|
|
||||||
|
loss_values = accelerator.gather_for_metrics({"loss": loss.detach()})
|
||||||
|
|
||||||
|
val_loss.update(loss_values["loss"])
|
||||||
|
|
||||||
|
return val_loss
|
||||||
|
|
||||||
|
|
||||||
|
def train(accelerator, config):
|
||||||
|
set_seed(config['seed'])
|
||||||
|
|
||||||
|
accelerator.print(config)
|
||||||
|
accelerator.print(f"Using {accelerator.num_processes} GPUs")
|
||||||
|
|
||||||
|
tokenizer = AutoTokenizer.from_pretrained(config['tokenizer_name'], model_max_length=config['max_length'])
|
||||||
|
# if no pad token, set it to eos
|
||||||
|
if tokenizer.pad_token is None:
|
||||||
|
tokenizer.pad_token = tokenizer.eos_token
|
||||||
|
|
||||||
|
|
||||||
|
with accelerator.main_process_first():
|
||||||
|
train_dataloader, val_dataloader = load_data(config, tokenizer)
|
||||||
|
|
||||||
|
|
||||||
|
checkpoint = config["gradient_checkpointing"]
|
||||||
|
model = AutoModelForCausalLM.from_pretrained(config["model_name"],
|
||||||
|
use_cache=False if checkpoint else True,
|
||||||
|
trust_remote_code=True)
|
||||||
|
if checkpoint:
|
||||||
|
model.gradient_checkpointing_enable()
|
||||||
|
|
||||||
|
if config["lora"]:
|
||||||
|
peft_config = LoraConfig(
|
||||||
|
# should R be configurable?
|
||||||
|
task_type=TaskType.CAUSAL_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
|
||||||
|
)
|
||||||
|
model = get_peft_model(model, peft_config)
|
||||||
|
model.print_trainable_parameters()
|
||||||
|
|
||||||
|
optimizer_cls = (
|
||||||
|
AdamW
|
||||||
|
if accelerator.state.deepspeed_plugin is None
|
||||||
|
or "optimizer" not in accelerator.state.deepspeed_plugin.deepspeed_config
|
||||||
|
else DummyOptim
|
||||||
|
)
|
||||||
|
|
||||||
|
# karpathy doesn't decay embeddding, maybe we should exclude
|
||||||
|
# https://github.com/karpathy/minGPT/commit/bbbdac74fa9b2e55574d70056163ffbae42310c1#diff-2075fa9c224b395be5bda85544dd36572b59c76c54562819eadadbf268602834R157s
|
||||||
|
optimizer = optimizer_cls(model.parameters(), lr=config["lr"], weight_decay=config["weight_decay"])
|
||||||
|
|
||||||
|
if accelerator.state.deepspeed_plugin is not None:
|
||||||
|
gradient_accumulation_steps = accelerator.state.deepspeed_plugin.deepspeed_config[
|
||||||
|
"gradient_accumulation_steps"
|
||||||
|
]
|
||||||
|
|
||||||
|
# decay to min_lr instead of 0
|
||||||
|
lr_ratio = config["min_lr"] / config["lr"]
|
||||||
|
accelerator.print(f"Len of train_dataloader: {len(train_dataloader)}")
|
||||||
|
total_num_steps = (len(train_dataloader) / gradient_accumulation_steps) * config["num_epochs"]
|
||||||
|
# instead of decaying to zero, decay to ratio of min_lr / lr
|
||||||
|
total_num_steps += int(total_num_steps * lr_ratio) + config["warmup_steps"]
|
||||||
|
accelerator.print(f"Total training steps: {total_num_steps}")
|
||||||
|
|
||||||
|
# Creates Dummy Scheduler if `scheduler` was specified in the config file else creates `args.lr_scheduler_type` Scheduler
|
||||||
|
if (
|
||||||
|
accelerator.state.deepspeed_plugin is None
|
||||||
|
or "scheduler" not in accelerator.state.deepspeed_plugin.deepspeed_config
|
||||||
|
):
|
||||||
|
scheduler = get_scheduler(
|
||||||
|
name="cosine",
|
||||||
|
optimizer=optimizer,
|
||||||
|
num_warmup_steps=config["warmup_steps"] * accelerator.num_processes,
|
||||||
|
num_training_steps=total_num_steps,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
scheduler = DummyScheduler(
|
||||||
|
optimizer, total_num_steps=config["warmup_steps"], warmup_num_steps=config["warmup_steps"]
|
||||||
|
)
|
||||||
|
|
||||||
|
model, optimizer, train_dataloader, val_dataloader, scheduler = accelerator.prepare(
|
||||||
|
model, optimizer, train_dataloader, val_dataloader, scheduler
|
||||||
|
)
|
||||||
|
|
||||||
|
# setup for saving training states in case preemption
|
||||||
|
accelerator.register_for_checkpointing(scheduler)
|
||||||
|
|
||||||
|
if config["checkpoint"]:
|
||||||
|
accelerator.load_state(config["checkpoint"])
|
||||||
|
accelerator.print(f"Resumed from checkpoint: {config['checkpoint']}")
|
||||||
|
path = os.path.basename(config["train_args"]["resume_from_checkpoint"])
|
||||||
|
training_difference = os.path.splitext(path)[0]
|
||||||
|
resume_step = int(training_difference.replace("step_", ""))
|
||||||
|
accelerator.skip_first_batches(train_dataloader, resume_step)
|
||||||
|
accelerator.print(f"Resuming from step {resume_step}")
|
||||||
|
|
||||||
|
|
||||||
|
# log gradients
|
||||||
|
if accelerator.is_main_process and config["wandb"]:
|
||||||
|
wandb.watch(model, log_freq=config["log_grads_every"], log="all")
|
||||||
|
|
||||||
|
for epoch in range(config["num_epochs"]):
|
||||||
|
train_loss = MeanMetric(nan_strategy="error").to(model.device)
|
||||||
|
for step, batch in enumerate(tqdm(train_dataloader)):
|
||||||
|
model.train()
|
||||||
|
outputs = model(**batch)
|
||||||
|
loss = outputs.loss
|
||||||
|
|
||||||
|
# gather loss before backprop in case of gradient accumulation
|
||||||
|
loss_values = accelerator.gather_for_metrics({"loss": loss.detach().float()})
|
||||||
|
train_loss.update(loss_values["loss"])
|
||||||
|
|
||||||
|
loss = loss / gradient_accumulation_steps
|
||||||
|
accelerator.backward(loss)
|
||||||
|
# get gradient norm of all params
|
||||||
|
|
||||||
|
# log LR in case something weird happens
|
||||||
|
if step > 0 and step % (config["eval_every"] // 10) == 0:
|
||||||
|
if config["wandb"]:
|
||||||
|
curr_step = step + epoch * len(train_dataloader)
|
||||||
|
accelerator.log({"lr": scheduler.get_last_lr()[0]}, step=curr_step)
|
||||||
|
|
||||||
|
if (step + 1) % gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
|
||||||
|
optimizer.step()
|
||||||
|
scheduler.step()
|
||||||
|
optimizer.zero_grad()
|
||||||
|
|
||||||
|
|
||||||
|
if step > 0 and step % config["save_every"] == 0:
|
||||||
|
curr_step = step + epoch * len(train_dataloader)
|
||||||
|
accelerator.save_state(f"{config['output_dir']}/step_{curr_step}")
|
||||||
|
|
||||||
|
if step > 0 and (step % config["eval_every"] == 0 or step == len(train_dataloader) - 1):
|
||||||
|
val_loss = evaluate(model, val_dataloader)
|
||||||
|
|
||||||
|
log_train = {
|
||||||
|
"train_loss": train_loss.compute()
|
||||||
|
}
|
||||||
|
log_val = {
|
||||||
|
"val_loss": val_loss.compute()
|
||||||
|
}
|
||||||
|
|
||||||
|
if config["wandb"]:
|
||||||
|
curr_step = step + epoch * len(train_dataloader)
|
||||||
|
accelerator.log({**log_train, **log_val}, step=curr_step)
|
||||||
|
|
||||||
|
accelerator.print(f"Current LR: {scheduler.get_last_lr()[0]}")
|
||||||
|
accelerator.print(format_metrics(log_train, "train", f" step {step} "))
|
||||||
|
accelerator.print(format_metrics(log_val, "val", f" step {step} "))
|
||||||
|
|
||||||
|
train_loss.reset()
|
||||||
|
|
||||||
|
accelerator.print(f"Epoch {epoch} finished")
|
||||||
|
accelerator.print(f"Pushing to HF hub")
|
||||||
|
accelerator.wait_for_everyone()
|
||||||
|
unwrapped_model = accelerator.unwrap_model(model)
|
||||||
|
try:
|
||||||
|
if accelerator.is_main_process:
|
||||||
|
unwrapped_model.push_to_hub(config["save_name"] + f"-epoch_{epoch}", private=True)
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
accelerator.print(e)
|
||||||
|
accelerator.print(f"Failed to push to hub")
|
||||||
|
|
||||||
|
unwrapped_model.save_pretrained(
|
||||||
|
f"{config['output_dir']}/epoch_{epoch}",
|
||||||
|
is_main_process=accelerator.is_main_process,
|
||||||
|
save_function=accelerator.save,
|
||||||
|
state_dict=accelerator.get_state_dict(model),
|
||||||
|
)
|
||||||
|
|
||||||
|
accelerator.wait_for_everyone()
|
||||||
|
unwrapped_model = accelerator.unwrap_model(model)
|
||||||
|
unwrapped_model.save_pretrained(
|
||||||
|
f"{config['output_dir']}/final",
|
||||||
|
is_main_process=accelerator.is_main_process,
|
||||||
|
save_function=accelerator.save,
|
||||||
|
state_dict=accelerator.get_state_dict(model),
|
||||||
|
)
|
||||||
|
|
||||||
|
accelerator.end_training()
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
# parse arguments by reading in a config
|
||||||
|
parser = ArgumentParser()
|
||||||
|
parser.add_argument("--config", type=str, default="config.yaml")
|
||||||
|
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
config = read_config(args.config)
|
||||||
|
|
||||||
|
if config["wandb"]:
|
||||||
|
accelerator = Accelerator(log_with="wandb")
|
||||||
|
accelerator.init_trackers(
|
||||||
|
project_name=config["wandb_project_name"],
|
||||||
|
config=config,
|
||||||
|
init_kwargs={"wandb": {"entity": config["wandb_entity"]}},
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
accelerator = Accelerator()
|
||||||
|
|
||||||
|
train(accelerator, config=config)
|
||||||
4
web/.env
Normal file
@ -0,0 +1,4 @@
|
|||||||
|
VITE_GPT4ALL_API = http://localhost:9600 # http://localhost:9600
|
||||||
|
VITE_GPT4ALL_API_CHANGE_ORIGIN = 0 # FALSE
|
||||||
|
VITE_GPT4ALL_API_SECURE = 0 # FALSE
|
||||||
|
VITE_GPT4ALL_API_BASEURL = /
|
||||||
14
web/.eslintrc.cjs
Normal file
@ -0,0 +1,14 @@
|
|||||||
|
/* eslint-env node */
|
||||||
|
require('@rushstack/eslint-patch/modern-module-resolution')
|
||||||
|
|
||||||
|
module.exports = {
|
||||||
|
root: true,
|
||||||
|
'extends': [
|
||||||
|
'plugin:vue/vue3-essential',
|
||||||
|
'eslint:recommended',
|
||||||
|
'@vue/eslint-config-prettier/skip-formatting'
|
||||||
|
],
|
||||||
|
parserOptions: {
|
||||||
|
ecmaVersion: 'latest'
|
||||||
|
}
|
||||||
|
}
|
||||||
30
web/.gitignore
vendored
Normal file
@ -0,0 +1,30 @@
|
|||||||
|
# Logs
|
||||||
|
logs
|
||||||
|
*.log
|
||||||
|
npm-debug.log*
|
||||||
|
yarn-debug.log*
|
||||||
|
yarn-error.log*
|
||||||
|
pnpm-debug.log*
|
||||||
|
lerna-debug.log*
|
||||||
|
|
||||||
|
node_modules
|
||||||
|
.DS_Store
|
||||||
|
dist-ssr
|
||||||
|
coverage
|
||||||
|
*.local
|
||||||
|
|
||||||
|
/cypress/videos/
|
||||||
|
/cypress/screenshots/
|
||||||
|
|
||||||
|
# Editor directories and files
|
||||||
|
.vscode
|
||||||
|
!.vscode/extensions.json
|
||||||
|
.idea
|
||||||
|
*.suo
|
||||||
|
*.ntvs*
|
||||||
|
*.njsproj
|
||||||
|
*.sln
|
||||||
|
*.sw?
|
||||||
|
|
||||||
|
# REST Client files (VSCODE extension for making GET POST requests easy and fst from text files)
|
||||||
|
*.http
|
||||||
8
web/.prettierrc.json
Normal file
@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
"$schema": "https://json.schemastore.org/prettierrc",
|
||||||
|
"semi": false,
|
||||||
|
"tabWidth": 2,
|
||||||
|
"singleQuote": true,
|
||||||
|
"printWidth": 100,
|
||||||
|
"trailingComma": "none"
|
||||||
|
}
|
||||||