mirror of
https://github.com/mudler/LocalAI.git
synced 2025-06-14 21:18:07 +00:00
chore: drop examples folder now that LocalAI-examples has been created (#4017)
Signed-off-by: Dave Lee <dave@gray101.com>
This commit is contained in:
11
.bruno/LocalAI Test Requests/model gallery/model delete.bru
Normal file
11
.bruno/LocalAI Test Requests/model gallery/model delete.bru
Normal file
@ -0,0 +1,11 @@
|
||||
meta {
|
||||
name: model delete
|
||||
type: http
|
||||
seq: 7
|
||||
}
|
||||
|
||||
post {
|
||||
url: {{PROTOCOL}}{{HOST}}:{{PORT}}/models/galleries
|
||||
body: none
|
||||
auth: none
|
||||
}
|
||||
BIN
.bruno/LocalAI Test Requests/transcription/gb1.ogg
Normal file
BIN
.bruno/LocalAI Test Requests/transcription/gb1.ogg
Normal file
Binary file not shown.
16
.bruno/LocalAI Test Requests/transcription/transcribe.bru
Normal file
16
.bruno/LocalAI Test Requests/transcription/transcribe.bru
Normal file
@ -0,0 +1,16 @@
|
||||
meta {
|
||||
name: transcribe
|
||||
type: http
|
||||
seq: 1
|
||||
}
|
||||
|
||||
post {
|
||||
url: {{PROTOCOL}}{{HOST}}:{{PORT}}/v1/audio/transcriptions
|
||||
body: multipartForm
|
||||
auth: none
|
||||
}
|
||||
|
||||
body:multipart-form {
|
||||
file: @file(transcription/gb1.ogg)
|
||||
model: whisper-1
|
||||
}
|
||||
@ -85,6 +85,7 @@ local-ai run oci://localai/phi-2:latest
|
||||
|
||||
## 📰 Latest project news
|
||||
|
||||
- Oct 2024: examples moved to [LocalAI-examples](https://github.com/mudler/LocalAI-examples)
|
||||
- Aug 2024: 🆕 FLUX-1, [P2P Explorer](https://explorer.localai.io)
|
||||
- July 2024: 🔥🔥 🆕 P2P Dashboard, LocalAI Federated mode and AI Swarms: https://github.com/mudler/LocalAI/pull/2723
|
||||
- June 2024: 🆕 You can browse now the model gallery without LocalAI! Check out https://models.localai.io
|
||||
|
||||
@ -1,190 +0,0 @@
|
||||
# Examples
|
||||
|
||||
| [ChatGPT OSS alternative](https://github.com/go-skynet/LocalAI/tree/master/examples/chatbot-ui) | [Image generation](https://localai.io/api-endpoints/index.html#image-generation) |
|
||||
|------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------|
|
||||
|  |  |
|
||||
|
||||
| [Telegram bot](https://github.com/go-skynet/LocalAI/tree/master/examples/telegram-bot) | [Flowise](https://github.com/go-skynet/LocalAI/tree/master/examples/flowise) |
|
||||
|------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------|
|
||||
 | | |
|
||||
|
||||
Here is a list of projects that can easily be integrated with the LocalAI backend.
|
||||
|
||||
|
||||
### Projects
|
||||
|
||||
### AutoGPT
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
This example shows how to use AutoGPT with LocalAI.
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/autoGPT/)
|
||||
|
||||
### Chatbot-UI
|
||||
|
||||
_by [@mkellerman](https://github.com/mkellerman)_
|
||||
|
||||

|
||||
|
||||
This integration shows how to use LocalAI with [mckaywrigley/chatbot-ui](https://github.com/mckaywrigley/chatbot-ui).
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/chatbot-ui/)
|
||||
|
||||
There is also a separate example to show how to manually setup a model: [example](https://github.com/go-skynet/LocalAI/tree/master/examples/chatbot-ui-manual/)
|
||||
|
||||
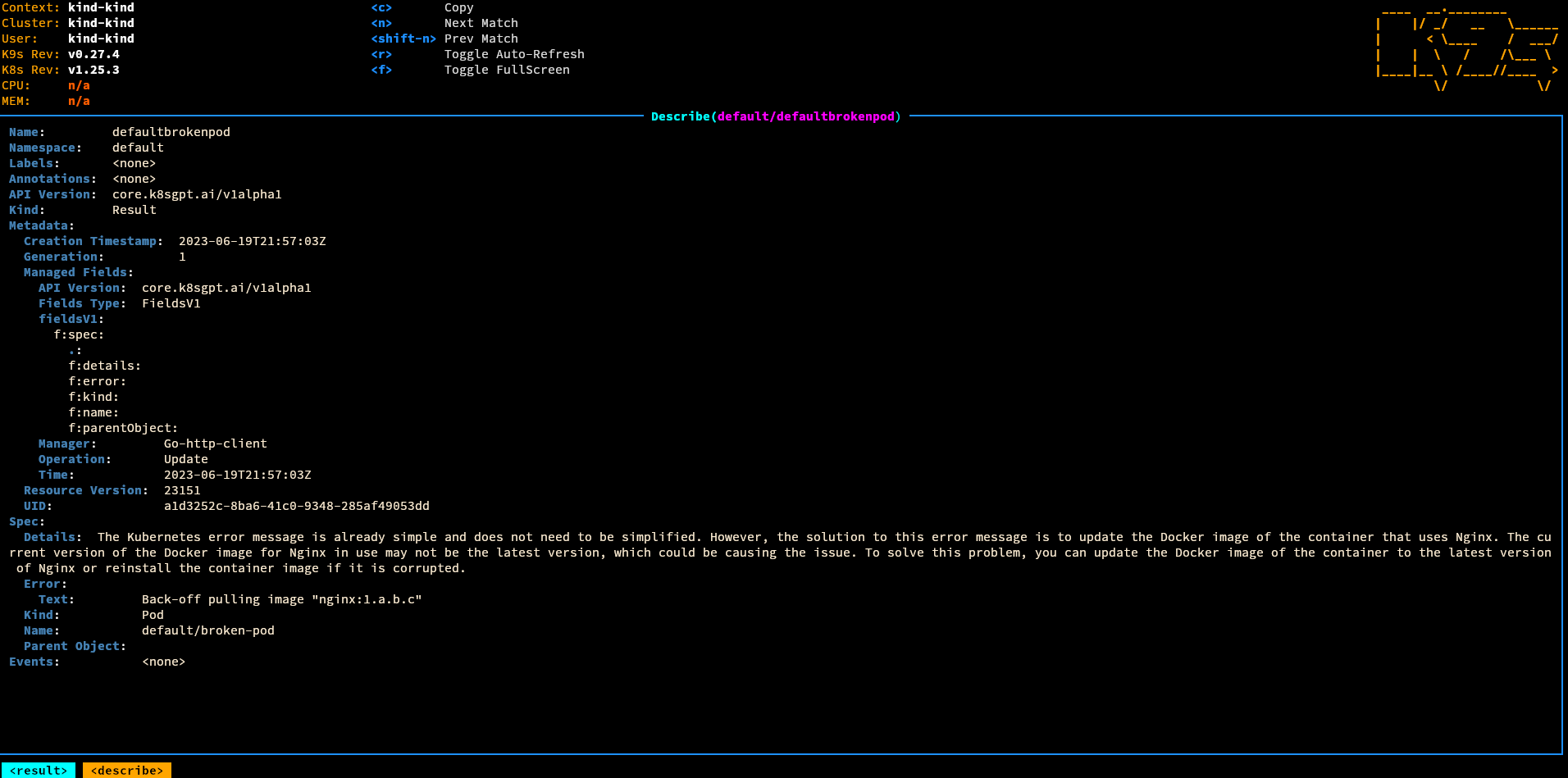
### K8sGPT
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
This example show how to use LocalAI inside Kubernetes with [k8sgpt](https://k8sgpt.ai).
|
||||
|
||||
|
||||
|
||||
### Fine-tuning a model and convert it to gguf to use it with LocalAI
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
This example is an e2e example on how to fine-tune a model with [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) and convert it to gguf to use it with LocalAI.
|
||||
|
||||
[Check it out here](https://github.com/mudler/LocalAI/tree/master/examples/e2e-fine-tuning/)
|
||||
|
||||
### Flowise
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
This example shows how to use [FlowiseAI/Flowise](https://github.com/FlowiseAI/Flowise) with LocalAI.
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/flowise/)
|
||||
|
||||
### Discord bot
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
Run a discord bot which lets you talk directly with a model
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/discord-bot/), or for a live demo you can talk with our bot in #random-bot in our discord server.
|
||||
|
||||
### Langchain
|
||||
|
||||
_by [@dave-gray101](https://github.com/dave-gray101)_
|
||||
|
||||
A ready to use example to show e2e how to integrate LocalAI with langchain
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/langchain/)
|
||||
|
||||
### Langchain Python
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
A ready to use example to show e2e how to integrate LocalAI with langchain
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/langchain-python/)
|
||||
|
||||
### LocalAI functions
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
A ready to use example to show how to use OpenAI functions with LocalAI
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/functions/)
|
||||
|
||||
### LocalAI WebUI
|
||||
|
||||
_by [@dhruvgera](https://github.com/dhruvgera)_
|
||||
|
||||
|
||||
|
||||
A light, community-maintained web interface for LocalAI
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/localai-webui/)
|
||||
|
||||
### How to run rwkv models
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
A full example on how to run RWKV models with LocalAI
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/rwkv/)
|
||||
|
||||
### PrivateGPT
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
A full example on how to run PrivateGPT with LocalAI
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/privateGPT/)
|
||||
|
||||
### Slack bot
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
Run a slack bot which lets you talk directly with a model
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/slack-bot/)
|
||||
|
||||
### Slack bot (Question answering)
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
Run a slack bot, ideally for teams, which lets you ask questions on a documentation website, or a github repository.
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/slack-qa-bot/)
|
||||
|
||||
### Question answering on documents with llama-index
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
Shows how to integrate with [Llama-Index](https://gpt-index.readthedocs.io/en/stable/getting_started/installation.html) to enable question answering on a set of documents.
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/query_data/)
|
||||
|
||||
### Question answering on documents with langchain and chroma
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
Shows how to integrate with `Langchain` and `Chroma` to enable question answering on a set of documents.
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/langchain-chroma/)
|
||||
|
||||
### Telegram bot
|
||||
|
||||
_by [@mudler](https://github.com/mudler)
|
||||
|
||||

|
||||
|
||||
Use LocalAI to power a Telegram bot assistant, with Image generation and audio support!
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/telegram-bot/)
|
||||
|
||||
### Template for Runpod.io
|
||||
|
||||
_by [@fHachenberg](https://github.com/fHachenberg)_
|
||||
|
||||
Allows to run any LocalAI-compatible model as a backend on the servers of https://runpod.io
|
||||
|
||||
[Check it out here](https://runpod.io/gsc?template=uv9mtqnrd0&ref=984wlcra)
|
||||
|
||||
### Continue
|
||||
|
||||
_by [@gruberdev](https://github.com/gruberdev)_
|
||||
|
||||
<img src="continue/img/screen.png" width="600" height="200" alt="Screenshot">
|
||||
|
||||
Demonstrates how to integrate an open-source copilot alternative that enhances code analysis, completion, and improvements. This approach seamlessly integrates with any LocalAI model, offering a more user-friendly experience.
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/continue/)
|
||||
|
||||
### Streamlit bot
|
||||
|
||||
_by [@majoshi1](https://github.com/majoshi1)_
|
||||
|
||||

|
||||
|
||||
A chat bot made using `Streamlit` & LocalAI.
|
||||
|
||||
[Check it out here](https://github.com/go-skynet/LocalAI/tree/master/examples/streamlit-bot/)
|
||||
|
||||
## Want to contribute?
|
||||
|
||||
Create an issue, and put `Example: <description>` in the title! We will post your examples here.
|
||||
@ -1,9 +0,0 @@
|
||||
# CPU .env docs: https://localai.io/howtos/easy-setup-docker-cpu/
|
||||
# GPU .env docs: https://localai.io/howtos/easy-setup-docker-gpu/
|
||||
|
||||
OPENAI_API_KEY=sk---anystringhere
|
||||
OPENAI_API_BASE=http://api:8080/v1
|
||||
# Models to preload at start
|
||||
# Here we configure gpt4all as gpt-3.5-turbo and bert as embeddings,
|
||||
# see other options in the model gallery at https://github.com/go-skynet/model-gallery
|
||||
PRELOAD_MODELS=[{"url": "github:go-skynet/model-gallery/gpt4all-j.yaml", "name": "gpt-3.5-turbo"}, { "url": "github:go-skynet/model-gallery/bert-embeddings.yaml", "name": "text-embedding-ada-002"}]
|
||||
@ -1,36 +0,0 @@
|
||||
# AutoGPT
|
||||
|
||||
Example of integration with [AutoGPT](https://github.com/Significant-Gravitas/Auto-GPT).
|
||||
|
||||
## Run
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/autoGPT
|
||||
|
||||
cp -rfv .env.example .env
|
||||
|
||||
# Edit the .env file to set a different model by editing `PRELOAD_MODELS`.
|
||||
vim .env
|
||||
|
||||
docker-compose run --rm auto-gpt
|
||||
```
|
||||
|
||||
Note: The example automatically downloads the `gpt4all` model as it is under a permissive license. The GPT4All model does not seem to be enough to run AutoGPT. WizardLM-7b-uncensored seems to perform better (with `f16: true`).
|
||||
|
||||
|
||||
## Without docker
|
||||
|
||||
Run AutoGPT with `OPENAI_API_BASE` pointing to the LocalAI endpoint. If you run it locally for instance:
|
||||
|
||||
```
|
||||
OPENAI_API_BASE=http://localhost:8080 python ...
|
||||
```
|
||||
|
||||
Note: you need a model named `gpt-3.5-turbo` and `text-embedding-ada-002`. You can preload those in LocalAI at start by setting in the env:
|
||||
|
||||
```
|
||||
PRELOAD_MODELS=[{"url": "github:go-skynet/model-gallery/gpt4all-j.yaml", "name": "gpt-3.5-turbo"}, { "url": "github:go-skynet/model-gallery/bert-embeddings.yaml", "name": "text-embedding-ada-002"}]
|
||||
```
|
||||
@ -1,42 +0,0 @@
|
||||
version: "3.9"
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
ports:
|
||||
- 8080:8080
|
||||
env_file:
|
||||
- .env
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
auto-gpt:
|
||||
image: significantgravitas/auto-gpt
|
||||
depends_on:
|
||||
api:
|
||||
condition: service_healthy
|
||||
redis:
|
||||
condition: service_started
|
||||
env_file:
|
||||
- .env
|
||||
environment:
|
||||
MEMORY_BACKEND: ${MEMORY_BACKEND:-redis}
|
||||
REDIS_HOST: ${REDIS_HOST:-redis}
|
||||
profiles: ["exclude-from-up"]
|
||||
volumes:
|
||||
- ./auto_gpt_workspace:/app/autogpt/auto_gpt_workspace
|
||||
- ./data:/app/data
|
||||
## allow auto-gpt to write logs to disk
|
||||
- ./logs:/app/logs
|
||||
## uncomment following lines if you want to make use of these files
|
||||
## you must have them existing in the same folder as this docker-compose.yml
|
||||
#- type: bind
|
||||
# source: ./azure.yaml
|
||||
# target: /app/azure.yaml
|
||||
#- type: bind
|
||||
# source: ./ai_settings.yaml
|
||||
# target: /app/ai_settings.yaml
|
||||
redis:
|
||||
image: "redis/redis-stack-server:latest"
|
||||
@ -1,25 +0,0 @@
|
||||
# Use an official Python runtime as a parent image
|
||||
FROM python:3.12-slim
|
||||
|
||||
# Set the working directory in the container
|
||||
WORKDIR /app
|
||||
|
||||
# Copy the current directory contents into the container at /app
|
||||
COPY requirements.txt /app
|
||||
|
||||
# Install c++ compiler
|
||||
RUN apt-get update \
|
||||
&& DEBIAN_FRONTEND=noninteractive apt-get install -y build-essential \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Install any needed packages specified in requirements.txt
|
||||
RUN pip install --no-cache-dir -r requirements.txt \
|
||||
&& DEBIAN_FRONTEND=noninteractive apt-get remove -y build-essential \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
COPY . /app
|
||||
|
||||
# Run app.py when the container launches
|
||||
CMD ["chainlit", "run", "-h", "--host", "0.0.0.0", "main.py" ]
|
||||
@ -1,25 +0,0 @@
|
||||
# LocalAI Demonstration with Embeddings and Chainlit
|
||||
|
||||
This demonstration shows you how to use embeddings with existing data in `LocalAI`, and how to integrate it with Chainlit for an interactive querying experience. We are using the `llama_index` library to facilitate the embedding and querying processes, and `chainlit` to provide an interactive interface. The `Weaviate` client is used as the embedding source.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before proceeding, make sure you have the following installed:
|
||||
- Weaviate client
|
||||
- LocalAI and its dependencies
|
||||
- Chainlit and its dependencies
|
||||
|
||||
## Getting Started
|
||||
|
||||
1. Clone this repository:
|
||||
2. Navigate to the project directory:
|
||||
3. Run the example: `chainlit run main.py`
|
||||
|
||||
# Highlight on `llama_index` and `chainlit`
|
||||
|
||||
`llama_index` is the key library that facilitates the process of embedding and querying data in LocalAI. It provides a seamless interface to integrate various components, such as `WeaviateVectorStore`, `LocalAI`, `ServiceContext`, and more, for a smooth querying experience.
|
||||
|
||||
`chainlit` is used to provide an interactive interface for users to query the data and see the results in real-time. It integrates with llama_index to handle the querying process and display the results to the user.
|
||||
|
||||
In this example, `llama_index` is used to set up the `VectorStoreIndex` and `QueryEngine`, and `chainlit` is used to handle the user interactions with `LocalAI` and display the results.
|
||||
|
||||
@ -1,16 +0,0 @@
|
||||
localAI:
|
||||
temperature: 0
|
||||
modelName: gpt-3.5-turbo
|
||||
apiBase: http://local-ai.default
|
||||
apiKey: stub
|
||||
streaming: True
|
||||
weviate:
|
||||
url: http://weviate.local
|
||||
index: AIChroma
|
||||
query:
|
||||
mode: hybrid
|
||||
topK: 1
|
||||
alpha: 0.0
|
||||
chunkSize: 1024
|
||||
embedding:
|
||||
model: BAAI/bge-small-en-v1.5
|
||||
@ -1,82 +0,0 @@
|
||||
import os
|
||||
|
||||
import weaviate
|
||||
from llama_index.storage.storage_context import StorageContext
|
||||
from llama_index.vector_stores import WeaviateVectorStore
|
||||
|
||||
from llama_index.query_engine.retriever_query_engine import RetrieverQueryEngine
|
||||
from llama_index.callbacks.base import CallbackManager
|
||||
from llama_index import (
|
||||
LLMPredictor,
|
||||
ServiceContext,
|
||||
StorageContext,
|
||||
VectorStoreIndex,
|
||||
)
|
||||
import chainlit as cl
|
||||
|
||||
from llama_index.llms import LocalAI
|
||||
from llama_index.embeddings import HuggingFaceEmbedding
|
||||
import yaml
|
||||
|
||||
# Load the configuration file
|
||||
with open("config.yaml", "r") as ymlfile:
|
||||
cfg = yaml.safe_load(ymlfile)
|
||||
|
||||
# Get the values from the configuration file or set the default values
|
||||
temperature = cfg['localAI'].get('temperature', 0)
|
||||
model_name = cfg['localAI'].get('modelName', "gpt-3.5-turbo")
|
||||
api_base = cfg['localAI'].get('apiBase', "http://local-ai.default")
|
||||
api_key = cfg['localAI'].get('apiKey', "stub")
|
||||
streaming = cfg['localAI'].get('streaming', True)
|
||||
weaviate_url = cfg['weviate'].get('url', "http://weviate.default")
|
||||
index_name = cfg['weviate'].get('index', "AIChroma")
|
||||
query_mode = cfg['query'].get('mode', "hybrid")
|
||||
topK = cfg['query'].get('topK', 1)
|
||||
alpha = cfg['query'].get('alpha', 0.0)
|
||||
embed_model_name = cfg['embedding'].get('model', "BAAI/bge-small-en-v1.5")
|
||||
chunk_size = cfg['query'].get('chunkSize', 1024)
|
||||
|
||||
|
||||
embed_model = HuggingFaceEmbedding(model_name=embed_model_name)
|
||||
|
||||
|
||||
llm = LocalAI(temperature=temperature, model_name=model_name, api_base=api_base, api_key=api_key, streaming=streaming)
|
||||
llm.globally_use_chat_completions = True;
|
||||
client = weaviate.Client(weaviate_url)
|
||||
vector_store = WeaviateVectorStore(weaviate_client=client, index_name=index_name)
|
||||
storage_context = StorageContext.from_defaults(vector_store=vector_store)
|
||||
|
||||
@cl.on_chat_start
|
||||
async def factory():
|
||||
|
||||
llm_predictor = LLMPredictor(
|
||||
llm=llm
|
||||
)
|
||||
|
||||
service_context = ServiceContext.from_defaults(embed_model=embed_model, callback_manager=CallbackManager([cl.LlamaIndexCallbackHandler()]), llm_predictor=llm_predictor, chunk_size=chunk_size)
|
||||
|
||||
index = VectorStoreIndex.from_vector_store(
|
||||
vector_store,
|
||||
storage_context=storage_context,
|
||||
service_context=service_context
|
||||
)
|
||||
|
||||
query_engine = index.as_query_engine(vector_store_query_mode=query_mode, similarity_top_k=topK, alpha=alpha, streaming=True)
|
||||
|
||||
cl.user_session.set("query_engine", query_engine)
|
||||
|
||||
|
||||
@cl.on_message
|
||||
async def main(message: cl.Message):
|
||||
query_engine = cl.user_session.get("query_engine")
|
||||
response = await cl.make_async(query_engine.query)(message.content)
|
||||
|
||||
response_message = cl.Message(content="")
|
||||
|
||||
for token in response.response_gen:
|
||||
await response_message.stream_token(token=token)
|
||||
|
||||
if response.response_txt:
|
||||
response_message.content = response.response_txt
|
||||
|
||||
await response_message.send()
|
||||
@ -1,6 +0,0 @@
|
||||
llama_index==0.11.20
|
||||
requests==2.32.3
|
||||
weaviate_client==4.9.0
|
||||
transformers
|
||||
torch
|
||||
chainlit
|
||||
@ -1,50 +0,0 @@
|
||||
# chatbot-ui
|
||||
|
||||
Example of integration with [mckaywrigley/chatbot-ui](https://github.com/mckaywrigley/chatbot-ui).
|
||||
|
||||

|
||||
|
||||
## Setup
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/chatbot-ui
|
||||
|
||||
# (optional) Checkout a specific LocalAI tag
|
||||
# git checkout -b build <TAG>
|
||||
|
||||
# Download gpt4all-j to models/
|
||||
wget https://gpt4all.io/models/ggml-gpt4all-j.bin -O models/ggml-gpt4all-j
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up -d --pull always
|
||||
# or you can build the images with:
|
||||
# docker-compose up -d --build
|
||||
```
|
||||
|
||||
Then browse to `http://localhost:3000` to view the Web UI.
|
||||
|
||||
## Pointing chatbot-ui to a separately managed LocalAI service
|
||||
|
||||
If you want to use the [chatbot-ui example](https://github.com/go-skynet/LocalAI/tree/master/examples/chatbot-ui) with an externally managed LocalAI service, you can alter the `docker-compose.yaml` file so that it looks like the below. You will notice the file is smaller, because we have removed the section that would normally start the LocalAI service. Take care to update the IP address (or FQDN) that the chatbot-ui service tries to access (marked `<<LOCALAI_IP>>` below):
|
||||
|
||||
```yaml
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
chatgpt:
|
||||
image: ghcr.io/mckaywrigley/chatbot-ui:main
|
||||
ports:
|
||||
- 3000:3000
|
||||
environment:
|
||||
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
|
||||
- 'OPENAI_API_HOST=http://<<LOCALAI_IP>>:8080'
|
||||
```
|
||||
|
||||
Once you've edited the `docker-compose.yaml`, you can start it with `docker compose up`, then browse to `http://localhost:3000` to view the Web UI.
|
||||
|
||||
## Accessing chatbot-ui
|
||||
|
||||
Open http://localhost:3000 for the Web UI.
|
||||
@ -1,24 +0,0 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
|
||||
chatgpt:
|
||||
image: ghcr.io/mckaywrigley/chatbot-ui:main
|
||||
ports:
|
||||
- 3000:3000
|
||||
environment:
|
||||
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
|
||||
- 'OPENAI_API_HOST=http://api:8080'
|
||||
@ -1 +0,0 @@
|
||||
../models
|
||||
@ -1,46 +0,0 @@
|
||||
# chatbot-ui
|
||||
|
||||
Example of integration with [mckaywrigley/chatbot-ui](https://github.com/mckaywrigley/chatbot-ui).
|
||||
|
||||

|
||||
|
||||
## Run
|
||||
|
||||
In this example LocalAI will download the gpt4all model and set it up as "gpt-3.5-turbo". See the `docker-compose.yaml`
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/chatbot-ui
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up --pull always
|
||||
|
||||
# or you can build the images with:
|
||||
# docker-compose up -d --build
|
||||
```
|
||||
|
||||
Then browse to `http://localhost:3000` to view the Web UI.
|
||||
|
||||
## Pointing chatbot-ui to a separately managed LocalAI service
|
||||
|
||||
If you want to use the [chatbot-ui example](https://github.com/go-skynet/LocalAI/tree/master/examples/chatbot-ui) with an externally managed LocalAI service, you can alter the `docker-compose.yaml` file so that it looks like the below. You will notice the file is smaller, because we have removed the section that would normally start the LocalAI service. Take care to update the IP address (or FQDN) that the chatbot-ui service tries to access (marked `<<LOCALAI_IP>>` below):
|
||||
|
||||
```yaml
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
chatgpt:
|
||||
image: ghcr.io/mckaywrigley/chatbot-ui:main
|
||||
ports:
|
||||
- 3000:3000
|
||||
environment:
|
||||
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
|
||||
- 'OPENAI_API_HOST=http://<<LOCALAI_IP>>:8080'
|
||||
```
|
||||
|
||||
Once you've edited the `docker-compose.yaml`, you can start it with `docker compose up`, then browse to `http://localhost:3000` to view the Web UI.
|
||||
|
||||
## Accessing chatbot-ui
|
||||
|
||||
Open http://localhost:3000 for the Web UI.
|
||||
@ -1,37 +0,0 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
# As initially LocalAI will download the models defined in PRELOAD_MODELS
|
||||
# you might need to tweak the healthcheck values here according to your network connection.
|
||||
# Here we give a timespan of 20m to download all the required files.
|
||||
healthcheck:
|
||||
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
|
||||
interval: 1m
|
||||
timeout: 20m
|
||||
retries: 20
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
# You can preload different models here as well.
|
||||
# See: https://github.com/go-skynet/model-gallery
|
||||
- 'PRELOAD_MODELS=[{"url": "github:go-skynet/model-gallery/gpt4all-j.yaml", "name": "gpt-3.5-turbo"}]'
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
chatgpt:
|
||||
depends_on:
|
||||
api:
|
||||
condition: service_healthy
|
||||
image: ghcr.io/mckaywrigley/chatbot-ui:main
|
||||
ports:
|
||||
- 3000:3000
|
||||
environment:
|
||||
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
|
||||
- 'OPENAI_API_HOST=http://api:8080'
|
||||
@ -1,95 +0,0 @@
|
||||
## Advanced configuration
|
||||
|
||||
This section contains examples on how to install models manually with config files.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
First clone LocalAI:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI
|
||||
```
|
||||
|
||||
Setup the model you prefer from the examples below and then start LocalAI:
|
||||
|
||||
```bash
|
||||
docker compose up -d --pull always
|
||||
```
|
||||
|
||||
If LocalAI is already started, you can restart it with
|
||||
|
||||
```bash
|
||||
docker compose restart
|
||||
```
|
||||
|
||||
See also the getting started: https://localai.io/basics/getting_started/
|
||||
|
||||
You can also start LocalAI just with docker:
|
||||
|
||||
```
|
||||
docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:master --models-path /models --threads 4
|
||||
```
|
||||
|
||||
### Mistral
|
||||
|
||||
To setup mistral copy the files inside `mistral` in the `models` folder:
|
||||
|
||||
```bash
|
||||
cp -r examples/configurations/mistral/* models/
|
||||
```
|
||||
|
||||
Now download the model:
|
||||
|
||||
```bash
|
||||
wget https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/resolve/main/mistral-7b-openorca.Q6_K.gguf -O models/mistral-7b-openorca.Q6_K.gguf
|
||||
```
|
||||
|
||||
### LLaVA
|
||||
|
||||

|
||||
|
||||
#### Setup
|
||||
|
||||
```
|
||||
cp -r examples/configurations/llava/* models/
|
||||
wget https://huggingface.co/mys/ggml_bakllava-1/resolve/main/ggml-model-q4_k.gguf -O models/ggml-model-q4_k.gguf
|
||||
wget https://huggingface.co/mys/ggml_bakllava-1/resolve/main/mmproj-model-f16.gguf -O models/mmproj-model-f16.gguf
|
||||
```
|
||||
|
||||
#### Try it out
|
||||
|
||||
```
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "llava",
|
||||
"messages": [{"role": "user", "content": [{"type":"text", "text": "What is in the image?"}, {"type": "image_url", "image_url": {"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg" }}], "temperature": 0.9}]}'
|
||||
|
||||
```
|
||||
|
||||
### Phi-2
|
||||
|
||||
```
|
||||
cp -r examples/configurations/phi-2.yaml models/
|
||||
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "phi-2",
|
||||
"messages": [{"role": "user", "content": "How are you doing?", "temperature": 0.1}]
|
||||
}'
|
||||
```
|
||||
|
||||
### Mixtral
|
||||
|
||||
```
|
||||
cp -r examples/configuration/mixtral/* models/
|
||||
wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.gguf -O models/mixtral-8x7b-instruct-v0.1.Q2_K.gguf
|
||||
```
|
||||
|
||||
#### Test it out
|
||||
|
||||
```
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "mixtral",
|
||||
"prompt": "How fast is light?",
|
||||
"temperature": 0.1 }'
|
||||
```
|
||||
@ -1,3 +0,0 @@
|
||||
A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.
|
||||
{{.Input}}
|
||||
ASSISTANT:
|
||||
@ -1,19 +0,0 @@
|
||||
backend: llama-cpp
|
||||
context_size: 4096
|
||||
f16: true
|
||||
threads: 11
|
||||
gpu_layers: 90
|
||||
mmap: true
|
||||
name: llava
|
||||
roles:
|
||||
user: "USER:"
|
||||
assistant: "ASSISTANT:"
|
||||
system: "SYSTEM:"
|
||||
parameters:
|
||||
model: ggml-model-q4_k.gguf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
template:
|
||||
chat: chat-simple
|
||||
mmproj: mmproj-model-f16.gguf
|
||||
@ -1,3 +0,0 @@
|
||||
{{.Input}}
|
||||
<|im_start|>assistant
|
||||
|
||||
@ -1,3 +0,0 @@
|
||||
<|im_start|>{{if eq .RoleName "assistant"}}assistant{{else if eq .RoleName "system"}}system{{else if eq .RoleName "user"}}user{{end}}
|
||||
{{if .Content}}{{.Content}}{{end}}
|
||||
<|im_end|>
|
||||
@ -1 +0,0 @@
|
||||
{{.Input}}
|
||||
@ -1,16 +0,0 @@
|
||||
name: mistral
|
||||
mmap: true
|
||||
parameters:
|
||||
model: mistral-7b-openorca.Q6_K.gguf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
template:
|
||||
chat_message: chatml
|
||||
chat: chatml-block
|
||||
completion: completion
|
||||
context_size: 4096
|
||||
f16: true
|
||||
stopwords:
|
||||
- <|im_end|>
|
||||
threads: 4
|
||||
@ -1 +0,0 @@
|
||||
[INST] {{.Input}} [/INST]
|
||||
@ -1 +0,0 @@
|
||||
[INST] {{.Input}} [/INST]
|
||||
@ -1,16 +0,0 @@
|
||||
context_size: 512
|
||||
f16: true
|
||||
threads: 11
|
||||
gpu_layers: 90
|
||||
name: mixtral
|
||||
mmap: true
|
||||
parameters:
|
||||
model: mixtral-8x7b-instruct-v0.1.Q2_K.gguf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
batch: 512
|
||||
tfz: 1.0
|
||||
template:
|
||||
chat: mixtral-chat
|
||||
completion: mixtral
|
||||
@ -1,29 +0,0 @@
|
||||
name: phi-2
|
||||
context_size: 2048
|
||||
f16: true
|
||||
gpu_layers: 90
|
||||
mmap: true
|
||||
trimsuffix:
|
||||
- "\n"
|
||||
parameters:
|
||||
model: huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
seed: -1
|
||||
|
||||
mirostat: 2
|
||||
mirostat_eta: 1.0
|
||||
mirostat_tau: 1.0
|
||||
template:
|
||||
chat: &template |-
|
||||
Instruct: {{.Input}}
|
||||
Output:
|
||||
completion: *template
|
||||
|
||||
usage: |
|
||||
To use this model, interact with the API (in another terminal) with curl for instance:
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "phi-2",
|
||||
"messages": [{"role": "user", "content": "How are you doing?", "temperature": 0.1}]
|
||||
}'
|
||||
@ -1,53 +0,0 @@
|
||||
# Continue
|
||||
|
||||

|
||||
|
||||
This document presents an example of integration with [continuedev/continue](https://github.com/continuedev/continue).
|
||||
|
||||

|
||||
|
||||
For a live demonstration, please click on the link below:
|
||||
|
||||
- [How it works (Video demonstration)](https://www.youtube.com/watch?v=3Ocrc-WX4iQ)
|
||||
|
||||
## Integration Setup Walkthrough
|
||||
|
||||
1. [As outlined in `continue`'s documentation](https://continue.dev/docs/getting-started), install the [Visual Studio Code extension from the marketplace](https://marketplace.visualstudio.com/items?itemName=Continue.continue) and open it.
|
||||
2. In this example, LocalAI will download the gpt4all model and set it up as "gpt-3.5-turbo". Refer to the `docker-compose.yaml` file for details.
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/continue
|
||||
|
||||
# Start with docker-compose
|
||||
docker-compose up --build -d
|
||||
```
|
||||
|
||||
3. Type `/config` within Continue's VSCode extension, or edit the file located at `~/.continue/config.py` on your system with the following configuration:
|
||||
|
||||
```py
|
||||
from continuedev.src.continuedev.libs.llm.openai import OpenAI
|
||||
|
||||
config = ContinueConfig(
|
||||
...
|
||||
models=Models(
|
||||
default=OpenAI(
|
||||
api_key="my-api-key",
|
||||
model="gpt-3.5-turbo",
|
||||
api_base="http://localhost:8080",
|
||||
)
|
||||
),
|
||||
)
|
||||
```
|
||||
|
||||
This setup enables you to make queries directly to your model running in the Docker container. Note that the `api_key` does not need to be properly set up; it is included here as a placeholder.
|
||||
|
||||
If editing the configuration seems confusing, you may copy and paste the provided default `config.py` file over the existing one in `~/.continue/config.py` after initializing the extension in the VSCode IDE.
|
||||
|
||||
## Additional Resources
|
||||
|
||||
- [Official Continue documentation](https://continue.dev/docs/intro)
|
||||
- [Documentation page on using self-hosted models](https://continue.dev/docs/customization#self-hosting-an-open-source-model)
|
||||
- [Official extension link](https://marketplace.visualstudio.com/items?itemName=Continue.continue)
|
||||
@ -1,148 +0,0 @@
|
||||
"""
|
||||
This is the Continue configuration file.
|
||||
|
||||
See https://continue.dev/docs/customization to learn more.
|
||||
"""
|
||||
|
||||
import subprocess
|
||||
|
||||
from continuedev.src.continuedev.core.main import Step
|
||||
from continuedev.src.continuedev.core.sdk import ContinueSDK
|
||||
from continuedev.src.continuedev.core.models import Models
|
||||
from continuedev.src.continuedev.core.config import CustomCommand, SlashCommand, ContinueConfig
|
||||
from continuedev.src.continuedev.plugins.context_providers.github import GitHubIssuesContextProvider
|
||||
from continuedev.src.continuedev.plugins.context_providers.google import GoogleContextProvider
|
||||
from continuedev.src.continuedev.plugins.policies.default import DefaultPolicy
|
||||
from continuedev.src.continuedev.libs.llm.openai import OpenAI, OpenAIServerInfo
|
||||
from continuedev.src.continuedev.libs.llm.ggml import GGML
|
||||
|
||||
from continuedev.src.continuedev.plugins.steps.open_config import OpenConfigStep
|
||||
from continuedev.src.continuedev.plugins.steps.clear_history import ClearHistoryStep
|
||||
from continuedev.src.continuedev.plugins.steps.feedback import FeedbackStep
|
||||
from continuedev.src.continuedev.plugins.steps.comment_code import CommentCodeStep
|
||||
from continuedev.src.continuedev.plugins.steps.share_session import ShareSessionStep
|
||||
from continuedev.src.continuedev.plugins.steps.main import EditHighlightedCodeStep
|
||||
from continuedev.src.continuedev.plugins.context_providers.search import SearchContextProvider
|
||||
from continuedev.src.continuedev.plugins.context_providers.diff import DiffContextProvider
|
||||
from continuedev.src.continuedev.plugins.context_providers.url import URLContextProvider
|
||||
|
||||
class CommitMessageStep(Step):
|
||||
"""
|
||||
This is a Step, the building block of Continue.
|
||||
It can be used below as a slash command, so that
|
||||
run will be called when you type '/commit'.
|
||||
"""
|
||||
async def run(self, sdk: ContinueSDK):
|
||||
|
||||
# Get the root directory of the workspace
|
||||
dir = sdk.ide.workspace_directory
|
||||
|
||||
# Run git diff in that directory
|
||||
diff = subprocess.check_output(
|
||||
["git", "diff"], cwd=dir).decode("utf-8")
|
||||
|
||||
# Ask the LLM to write a commit message,
|
||||
# and set it as the description of this step
|
||||
self.description = await sdk.models.default.complete(
|
||||
f"{diff}\n\nWrite a short, specific (less than 50 chars) commit message about the above changes:")
|
||||
|
||||
|
||||
config = ContinueConfig(
|
||||
|
||||
# If set to False, we will not collect any usage data
|
||||
# See here to learn what anonymous data we collect: https://continue.dev/docs/telemetry
|
||||
allow_anonymous_telemetry=True,
|
||||
|
||||
models = Models(
|
||||
default = OpenAI(
|
||||
api_key = "my-api-key",
|
||||
model = "gpt-3.5-turbo",
|
||||
openai_server_info = OpenAIServerInfo(
|
||||
api_base = "http://localhost:8080",
|
||||
model = "gpt-3.5-turbo"
|
||||
)
|
||||
)
|
||||
),
|
||||
# Set a system message with information that the LLM should always keep in mind
|
||||
# E.g. "Please give concise answers. Always respond in Spanish."
|
||||
system_message=None,
|
||||
|
||||
# Set temperature to any value between 0 and 1. Higher values will make the LLM
|
||||
# more creative, while lower values will make it more predictable.
|
||||
temperature=0.5,
|
||||
|
||||
# Custom commands let you map a prompt to a shortened slash command
|
||||
# They are like slash commands, but more easily defined - write just a prompt instead of a Step class
|
||||
# Their output will always be in chat form
|
||||
custom_commands=[
|
||||
# CustomCommand(
|
||||
# name="test",
|
||||
# description="Write unit tests for the higlighted code",
|
||||
# prompt="Write a comprehensive set of unit tests for the selected code. It should setup, run tests that check for correctness including important edge cases, and teardown. Ensure that the tests are complete and sophisticated. Give the tests just as chat output, don't edit any file.",
|
||||
# )
|
||||
],
|
||||
|
||||
# Slash commands let you run a Step from a slash command
|
||||
slash_commands=[
|
||||
# SlashCommand(
|
||||
# name="commit",
|
||||
# description="This is an example slash command. Use /config to edit it and create more",
|
||||
# step=CommitMessageStep,
|
||||
# )
|
||||
SlashCommand(
|
||||
name="edit",
|
||||
description="Edit code in the current file or the highlighted code",
|
||||
step=EditHighlightedCodeStep,
|
||||
),
|
||||
SlashCommand(
|
||||
name="config",
|
||||
description="Customize Continue - slash commands, LLMs, system message, etc.",
|
||||
step=OpenConfigStep,
|
||||
),
|
||||
SlashCommand(
|
||||
name="comment",
|
||||
description="Write comments for the current file or highlighted code",
|
||||
step=CommentCodeStep,
|
||||
),
|
||||
SlashCommand(
|
||||
name="feedback",
|
||||
description="Send feedback to improve Continue",
|
||||
step=FeedbackStep,
|
||||
),
|
||||
SlashCommand(
|
||||
name="clear",
|
||||
description="Clear step history",
|
||||
step=ClearHistoryStep,
|
||||
),
|
||||
SlashCommand(
|
||||
name="share",
|
||||
description="Download and share the session transcript",
|
||||
step=ShareSessionStep,
|
||||
)
|
||||
],
|
||||
|
||||
# Context providers let you quickly select context by typing '@'
|
||||
# Uncomment the following to
|
||||
# - quickly reference GitHub issues
|
||||
# - show Google search results to the LLM
|
||||
context_providers=[
|
||||
# GitHubIssuesContextProvider(
|
||||
# repo_name="<your github username or organization>/<your repo name>",
|
||||
# auth_token="<your github auth token>"
|
||||
# ),
|
||||
# GoogleContextProvider(
|
||||
# serper_api_key="<your serper.dev api key>"
|
||||
# )
|
||||
SearchContextProvider(),
|
||||
DiffContextProvider(),
|
||||
URLContextProvider(
|
||||
preset_urls = [
|
||||
# Add any common urls you reference here so they appear in autocomplete
|
||||
]
|
||||
)
|
||||
],
|
||||
|
||||
# Policies hold the main logic that decides which Step to take next
|
||||
# You can use them to design agents, or deeply customize Continue
|
||||
policy=DefaultPolicy()
|
||||
)
|
||||
@ -1,27 +0,0 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
# As initially LocalAI will download the models defined in PRELOAD_MODELS
|
||||
# you might need to tweak the healthcheck values here according to your network connection.
|
||||
# Here we give a timespan of 20m to download all the required files.
|
||||
healthcheck:
|
||||
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
|
||||
interval: 1m
|
||||
timeout: 20m
|
||||
retries: 20
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
# You can preload different models here as well.
|
||||
# See: https://github.com/go-skynet/model-gallery
|
||||
- 'PRELOAD_MODELS=[{"url": "github:go-skynet/model-gallery/gpt4all-j.yaml", "name": "gpt-3.5-turbo"}]'
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 196 KiB |
@ -1,9 +0,0 @@
|
||||
# CPU .env docs: https://localai.io/howtos/easy-setup-docker-cpu/
|
||||
# GPU .env docs: https://localai.io/howtos/easy-setup-docker-gpu/
|
||||
|
||||
OPENAI_API_KEY=x
|
||||
DISCORD_BOT_TOKEN=x
|
||||
DISCORD_CLIENT_ID=x
|
||||
OPENAI_API_BASE=http://api:8080
|
||||
ALLOWED_SERVER_IDS=x
|
||||
SERVER_TO_MODERATION_CHANNEL=1:1
|
||||
@ -1,76 +0,0 @@
|
||||
# discord-bot
|
||||
|
||||

|
||||
|
||||
## Setup
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/discord-bot
|
||||
|
||||
# (optional) Checkout a specific LocalAI tag
|
||||
# git checkout -b build <TAG>
|
||||
|
||||
# Download gpt4all-j to models/
|
||||
wget https://gpt4all.io/models/ggml-gpt4all-j.bin -O models/ggml-gpt4all-j
|
||||
|
||||
# Set the discord bot options (see: https://github.com/go-skynet/gpt-discord-bot#setup)
|
||||
cp -rfv .env.example .env
|
||||
vim .env
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up -d --build
|
||||
```
|
||||
|
||||
Note: see setup options here: https://github.com/go-skynet/gpt-discord-bot#setup
|
||||
|
||||
Open up the URL in the console and give permission to the bot in your server. Start a thread with `/chat ..`
|
||||
|
||||
## Kubernetes
|
||||
|
||||
- install the local-ai chart first
|
||||
- change OPENAI_API_BASE to point to the API address and apply the discord-bot manifest:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: discord-bot
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: localai
|
||||
namespace: discord-bot
|
||||
labels:
|
||||
app: localai
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: localai
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: localai
|
||||
name: localai
|
||||
spec:
|
||||
containers:
|
||||
- name: localai-discord
|
||||
env:
|
||||
- name: OPENAI_API_KEY
|
||||
value: "x"
|
||||
- name: DISCORD_BOT_TOKEN
|
||||
value: ""
|
||||
- name: DISCORD_CLIENT_ID
|
||||
value: ""
|
||||
- name: OPENAI_API_BASE
|
||||
value: "http://local-ai.default.svc.cluster.local:8080"
|
||||
- name: ALLOWED_SERVER_IDS
|
||||
value: "xx"
|
||||
- name: SERVER_TO_MODERATION_CHANNEL
|
||||
value: "1:1"
|
||||
image: quay.io/go-skynet/gpt-discord-bot:main
|
||||
```
|
||||
@ -1,21 +0,0 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
|
||||
bot:
|
||||
image: quay.io/go-skynet/gpt-discord-bot:main
|
||||
env_file:
|
||||
- .env
|
||||
@ -1 +0,0 @@
|
||||
../models
|
||||
@ -1,83 +0,0 @@
|
||||
This is an example of fine-tuning a LLM model to use with [LocalAI](https://github.com/mudler/LocalAI) written by [@mudler](https://github.com/mudler).
|
||||
|
||||
Specifically, this example shows how to use [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) to fine-tune a LLM model to consume with LocalAI as a `gguf` model.
|
||||
|
||||
A notebook is provided that currently works on _very small_ datasets on Google colab on the free instance. It is far from producing good models, but it gives a sense of how to use the code to use with a better dataset and configurations, and how to use the model produced with LocalAI. [](https://colab.research.google.com/github/mudler/LocalAI/blob/master/examples/e2e-fine-tuning/notebook.ipynb)
|
||||
|
||||
## Requirements
|
||||
|
||||
For this example you will need at least a 12GB VRAM of GPU and a Linux box.
|
||||
The notebook is tested on Google Colab with a Tesla T4 GPU.
|
||||
|
||||
## Clone this directory
|
||||
|
||||
Clone the repository and enter the example directory:
|
||||
|
||||
```bash
|
||||
git clone http://github.com/mudler/LocalAI
|
||||
cd LocalAI/examples/e2e-fine-tuning
|
||||
```
|
||||
|
||||
## Install dependencies
|
||||
|
||||
```bash
|
||||
# Install axolotl and dependencies
|
||||
git clone https://github.com/OpenAccess-AI-Collective/axolotl && pushd axolotl && git checkout 797f3dd1de8fd8c0eafbd1c9fdb172abd9ff840a && popd #0.3.0
|
||||
pip install packaging
|
||||
pushd axolotl && pip install -e '.[flash-attn,deepspeed]' && popd
|
||||
|
||||
# https://github.com/oobabooga/text-generation-webui/issues/4238
|
||||
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.3.0/flash_attn-2.3.0+cu117torch2.0cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
|
||||
```
|
||||
|
||||
Configure accelerate:
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
## Fine-tuning
|
||||
|
||||
We will need to configure axolotl. In this example is provided a file to use `axolotl.yaml` that uses openllama-3b for fine-tuning. Copy the `axolotl.yaml` file and edit it to your needs. The dataset needs to be next to it as `dataset.json`. The format used is `completion` which is a list of JSON objects with a `text` field with the full text to train the LLM with.
|
||||
|
||||
If you have a big dataset, you can pre-tokenize it to speedup the fine-tuning process:
|
||||
|
||||
```bash
|
||||
# Optional pre-tokenize (run only if big dataset)
|
||||
python -m axolotl.cli.preprocess axolotl.yaml
|
||||
```
|
||||
|
||||
Now we are ready to start the fine-tuning process:
|
||||
```bash
|
||||
# Fine-tune
|
||||
accelerate launch -m axolotl.cli.train axolotl.yaml
|
||||
```
|
||||
|
||||
After we have finished the fine-tuning, we merge the Lora base with the model:
|
||||
```bash
|
||||
# Merge lora
|
||||
python3 -m axolotl.cli.merge_lora axolotl.yaml --lora_model_dir="./qlora-out" --load_in_8bit=False --load_in_4bit=False
|
||||
```
|
||||
|
||||
And we convert it to the gguf format that LocalAI can consume:
|
||||
|
||||
```bash
|
||||
|
||||
# Convert to gguf
|
||||
git clone https://github.com/ggerganov/llama.cpp.git
|
||||
pushd llama.cpp && make GGML_CUDA=1 && popd
|
||||
|
||||
# We need to convert the pytorch model into ggml for quantization
|
||||
# It crates 'ggml-model-f16.bin' in the 'merged' directory.
|
||||
pushd llama.cpp && python convert.py --outtype f16 \
|
||||
../qlora-out/merged/pytorch_model-00001-of-00002.bin && popd
|
||||
|
||||
# Start off by making a basic q4_0 4-bit quantization.
|
||||
# It's important to have 'ggml' in the name of the quant for some
|
||||
# software to recognize it's file format.
|
||||
pushd llama.cpp && ./quantize ../qlora-out/merged/ggml-model-f16.gguf \
|
||||
../custom-model-q4_0.bin q4_0
|
||||
|
||||
```
|
||||
|
||||
Now you should have ended up with a `custom-model-q4_0.bin` file that you can copy in the LocalAI models directory and use it with LocalAI.
|
||||
@ -1,63 +0,0 @@
|
||||
|
||||
base_model: openlm-research/open_llama_3b_v2
|
||||
model_type: LlamaForCausalLM
|
||||
tokenizer_type: LlamaTokenizer
|
||||
load_in_8bit: false
|
||||
load_in_4bit: true
|
||||
strict: false
|
||||
push_dataset_to_hub: false
|
||||
datasets:
|
||||
- path: dataset.json
|
||||
ds_type: json
|
||||
type: completion
|
||||
dataset_prepared_path:
|
||||
val_set_size: 0.05
|
||||
adapter: qlora
|
||||
lora_model_dir:
|
||||
sequence_len: 1024
|
||||
sample_packing: true
|
||||
lora_r: 8
|
||||
lora_alpha: 32
|
||||
lora_dropout: 0.05
|
||||
lora_target_modules:
|
||||
lora_target_linear: true
|
||||
lora_fan_in_fan_out:
|
||||
wandb_project:
|
||||
wandb_entity:
|
||||
wandb_watch:
|
||||
wandb_run_id:
|
||||
wandb_log_model:
|
||||
output_dir: ./qlora-out
|
||||
gradient_accumulation_steps: 1
|
||||
micro_batch_size: 2
|
||||
num_epochs: 4
|
||||
optimizer: paged_adamw_32bit
|
||||
torchdistx_path:
|
||||
lr_scheduler: cosine
|
||||
learning_rate: 0.0002
|
||||
train_on_inputs: false
|
||||
group_by_length: false
|
||||
bf16: false
|
||||
fp16: true
|
||||
tf32: false
|
||||
gradient_checkpointing: true
|
||||
early_stopping_patience:
|
||||
resume_from_checkpoint:
|
||||
local_rank:
|
||||
logging_steps: 1
|
||||
xformers_attention:
|
||||
flash_attention: false
|
||||
gptq_groupsize:
|
||||
gptq_model_v1:
|
||||
warmup_steps: 20
|
||||
eval_steps: 0.05
|
||||
save_steps:
|
||||
debug:
|
||||
deepspeed:
|
||||
weight_decay: 0.1
|
||||
fsdp:
|
||||
fsdp_config:
|
||||
special_tokens:
|
||||
bos_token: "<s>"
|
||||
eos_token: "</s>"
|
||||
unk_token: "<unk>"
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,30 +0,0 @@
|
||||
# flowise
|
||||
|
||||
Example of integration with [FlowiseAI/Flowise](https://github.com/FlowiseAI/Flowise).
|
||||
|
||||

|
||||
|
||||
You can check a demo video in the Flowise PR: https://github.com/FlowiseAI/Flowise/pull/123
|
||||
|
||||
## Run
|
||||
|
||||
In this example LocalAI will download the gpt4all model and set it up as "gpt-3.5-turbo". See the `docker-compose.yaml`
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/flowise
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up --pull always
|
||||
|
||||
```
|
||||
|
||||
## Accessing flowise
|
||||
|
||||
Open http://localhost:3000.
|
||||
|
||||
## Using LocalAI
|
||||
|
||||
Search for LocalAI in the integration, and use the `http://api:8080/` as URL.
|
||||
|
||||
@ -1,37 +0,0 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
# As initially LocalAI will download the models defined in PRELOAD_MODELS
|
||||
# you might need to tweak the healthcheck values here according to your network connection.
|
||||
# Here we give a timespan of 20m to download all the required files.
|
||||
healthcheck:
|
||||
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
|
||||
interval: 1m
|
||||
timeout: 20m
|
||||
retries: 20
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
# You can preload different models here as well.
|
||||
# See: https://github.com/go-skynet/model-gallery
|
||||
- 'PRELOAD_MODELS=[{"url": "github:go-skynet/model-gallery/gpt4all-j.yaml", "name": "gpt-3.5-turbo"}]'
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
flowise:
|
||||
depends_on:
|
||||
api:
|
||||
condition: service_healthy
|
||||
image: flowiseai/flowise
|
||||
ports:
|
||||
- 3000:3000
|
||||
volumes:
|
||||
- ~/.flowise:/root/.flowise
|
||||
command: /bin/sh -c "sleep 3; flowise start"
|
||||
@ -1,13 +0,0 @@
|
||||
# CPU .env docs: https://localai.io/howtos/easy-setup-docker-cpu/
|
||||
# GPU .env docs: https://localai.io/howtos/easy-setup-docker-gpu/
|
||||
|
||||
OPENAI_API_KEY=sk---anystringhere
|
||||
OPENAI_API_BASE=http://api:8080/v1
|
||||
# Models to preload at start
|
||||
# Here we configure gpt4all as gpt-3.5-turbo and bert as embeddings,
|
||||
# see other options in the model gallery at https://github.com/go-skynet/model-gallery
|
||||
PRELOAD_MODELS=[{"url": "github:go-skynet/model-gallery/openllama-7b-open-instruct.yaml", "name": "gpt-3.5-turbo"}]
|
||||
|
||||
## Change the default number of threads
|
||||
#THREADS=14
|
||||
|
||||
@ -1,5 +0,0 @@
|
||||
FROM python:3.12-slim-bullseye
|
||||
COPY . /app
|
||||
WORKDIR /app
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
ENTRYPOINT [ "python", "./functions-openai.py" ]
|
||||
@ -1,21 +0,0 @@
|
||||
# LocalAI functions
|
||||
|
||||
Example of using LocalAI functions, see the [OpenAI](https://openai.com/blog/function-calling-and-other-api-updates) blog post.
|
||||
|
||||
## Run
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/functions
|
||||
|
||||
cp -rfv .env.example .env
|
||||
|
||||
# Edit the .env file to set a different model by editing `PRELOAD_MODELS`.
|
||||
vim .env
|
||||
|
||||
docker-compose run --rm functions
|
||||
```
|
||||
|
||||
Note: The example automatically downloads the `openllama` model as it is under a permissive license.
|
||||
@ -1,23 +0,0 @@
|
||||
version: "3.9"
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:master
|
||||
ports:
|
||||
- 8080:8080
|
||||
env_file:
|
||||
- .env
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
functions:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile
|
||||
depends_on:
|
||||
api:
|
||||
condition: service_healthy
|
||||
env_file:
|
||||
- .env
|
||||
@ -1,76 +0,0 @@
|
||||
import openai
|
||||
import json
|
||||
|
||||
# Example dummy function hard coded to return the same weather
|
||||
# In production, this could be your backend API or an external API
|
||||
def get_current_weather(location, unit="fahrenheit"):
|
||||
"""Get the current weather in a given location"""
|
||||
weather_info = {
|
||||
"location": location,
|
||||
"temperature": "72",
|
||||
"unit": unit,
|
||||
"forecast": ["sunny", "windy"],
|
||||
}
|
||||
return json.dumps(weather_info)
|
||||
|
||||
|
||||
def run_conversation():
|
||||
# Step 1: send the conversation and available functions to GPT
|
||||
messages = [{"role": "user", "content": "What's the weather like in Boston?"}]
|
||||
functions = [
|
||||
{
|
||||
"name": "get_current_weather",
|
||||
"description": "Get the current weather in a given location",
|
||||
"parameters": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"location": {
|
||||
"type": "string",
|
||||
"description": "The city and state, e.g. San Francisco, CA",
|
||||
},
|
||||
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
|
||||
},
|
||||
"required": ["location"],
|
||||
},
|
||||
}
|
||||
]
|
||||
response = openai.ChatCompletion.create(
|
||||
model="gpt-3.5-turbo",
|
||||
messages=messages,
|
||||
functions=functions,
|
||||
function_call="auto", # auto is default, but we'll be explicit
|
||||
)
|
||||
response_message = response["choices"][0]["message"]
|
||||
|
||||
# Step 2: check if GPT wanted to call a function
|
||||
if response_message.get("function_call"):
|
||||
# Step 3: call the function
|
||||
# Note: the JSON response may not always be valid; be sure to handle errors
|
||||
available_functions = {
|
||||
"get_current_weather": get_current_weather,
|
||||
} # only one function in this example, but you can have multiple
|
||||
function_name = response_message["function_call"]["name"]
|
||||
fuction_to_call = available_functions[function_name]
|
||||
function_args = json.loads(response_message["function_call"]["arguments"])
|
||||
function_response = fuction_to_call(
|
||||
location=function_args.get("location"),
|
||||
unit=function_args.get("unit"),
|
||||
)
|
||||
|
||||
# Step 4: send the info on the function call and function response to GPT
|
||||
messages.append(response_message) # extend conversation with assistant's reply
|
||||
messages.append(
|
||||
{
|
||||
"role": "function",
|
||||
"name": function_name,
|
||||
"content": function_response,
|
||||
}
|
||||
) # extend conversation with function response
|
||||
second_response = openai.ChatCompletion.create(
|
||||
model="gpt-3.5-turbo",
|
||||
messages=messages,
|
||||
) # get a new response from GPT where it can see the function response
|
||||
return second_response
|
||||
|
||||
|
||||
print(run_conversation())
|
||||
@ -1,2 +0,0 @@
|
||||
langchain==0.3.4
|
||||
openai==1.52.2
|
||||
@ -1,83 +0,0 @@
|
||||
name: Use LocalAI in GHA
|
||||
on:
|
||||
pull_request:
|
||||
types:
|
||||
- closed
|
||||
|
||||
jobs:
|
||||
notify-discord:
|
||||
if: ${{ (github.event.pull_request.merged == true) && (contains(github.event.pull_request.labels.*.name, 'area/ai-model')) }}
|
||||
env:
|
||||
MODEL_NAME: hermes-2-theta-llama-3-8b
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0 # needed to checkout all branches for this Action to work
|
||||
# Starts the LocalAI container
|
||||
- name: Start LocalAI
|
||||
run: |
|
||||
echo "Starting LocalAI..."
|
||||
docker run -e -ti -d --name local-ai -p 8080:8080 localai/localai:master-ffmpeg-core run --debug $MODEL_NAME
|
||||
until [ "`docker inspect -f {{.State.Health.Status}} local-ai`" == "healthy" ]; do echo "Waiting for container to be ready"; docker logs --tail 10 local-ai; sleep 2; done
|
||||
# Check the PR diff using the current branch and the base branch of the PR
|
||||
- uses: GrantBirki/git-diff-action@v2.7.0
|
||||
id: git-diff-action
|
||||
with:
|
||||
json_diff_file_output: diff.json
|
||||
raw_diff_file_output: diff.txt
|
||||
file_output_only: "true"
|
||||
# Ask to explain the diff to LocalAI
|
||||
- name: Summarize
|
||||
env:
|
||||
DIFF: ${{ steps.git-diff-action.outputs.raw-diff-path }}
|
||||
id: summarize
|
||||
run: |
|
||||
input="$(cat $DIFF)"
|
||||
|
||||
# Define the LocalAI API endpoint
|
||||
API_URL="http://localhost:8080/chat/completions"
|
||||
|
||||
# Create a JSON payload using jq to handle special characters
|
||||
json_payload=$(jq -n --arg input "$input" '{
|
||||
model: "'$MODEL_NAME'",
|
||||
messages: [
|
||||
{
|
||||
role: "system",
|
||||
content: "Write a message summarizing the change diffs"
|
||||
},
|
||||
{
|
||||
role: "user",
|
||||
content: $input
|
||||
}
|
||||
]
|
||||
}')
|
||||
|
||||
# Send the request to LocalAI
|
||||
response=$(curl -s -X POST $API_URL \
|
||||
-H "Content-Type: application/json" \
|
||||
-d "$json_payload")
|
||||
|
||||
# Extract the summary from the response
|
||||
summary="$(echo $response | jq -r '.choices[0].message.content')"
|
||||
|
||||
# Print the summary
|
||||
# -H "Authorization: Bearer $API_KEY" \
|
||||
echo "Summary:"
|
||||
echo "$summary"
|
||||
echo "payload sent"
|
||||
echo "$json_payload"
|
||||
{
|
||||
echo 'message<<EOF'
|
||||
echo "$summary"
|
||||
echo EOF
|
||||
} >> "$GITHUB_OUTPUT"
|
||||
# Send the summary somewhere (e.g. Discord)
|
||||
- name: Discord notification
|
||||
env:
|
||||
DISCORD_WEBHOOK: ${{ secrets.DISCORD_WEBHOOK_URL }}
|
||||
DISCORD_USERNAME: "discord-bot"
|
||||
DISCORD_AVATAR: ""
|
||||
uses: Ilshidur/action-discord@master
|
||||
with:
|
||||
args: ${{ steps.summarize.outputs.message }}
|
||||
File diff suppressed because one or more lines are too long
@ -1,17 +0,0 @@
|
||||
# Insomnia
|
||||
|
||||
Developer Testing Request Collection for [Insomnia](https://insomnia.rest/), an open-source REST client
|
||||
|
||||
## Instructions
|
||||
|
||||
* Install Insomnia as normal
|
||||
* [Import](https://docs.insomnia.rest/insomnia/import-export-data) `Insomnia_LocalAI.json`
|
||||
* Control + E opens the environment settings -
|
||||
|
||||
| **Parameter Name** | **Default Value** | **Description** |
|
||||
|--------------------|-------------------|------------------------------------------|
|
||||
| HOST | localhost | LocalAI base URL |
|
||||
| PORT | 8080 | LocalAI port |
|
||||
| DEFAULT_MODEL | gpt-3.5-turbo | Name of the model used on most requests. |
|
||||
|
||||
** you may want to duplicate localhost into a "Private" environment to avoid saving private settings back to this file **
|
||||
@ -1,72 +0,0 @@
|
||||
# k8sgpt example
|
||||
|
||||
This example show how to use LocalAI with k8sgpt
|
||||
|
||||

|
||||
|
||||
## Create the cluster locally with Kind (optional)
|
||||
|
||||
If you want to test this locally without a remote Kubernetes cluster, you can use kind.
|
||||
|
||||
Install [kind](https://kind.sigs.k8s.io/) and create a cluster:
|
||||
|
||||
```
|
||||
kind create cluster
|
||||
```
|
||||
|
||||
## Setup LocalAI
|
||||
|
||||
We will use [helm](https://helm.sh/docs/intro/install/):
|
||||
|
||||
```
|
||||
helm repo add go-skynet https://go-skynet.github.io/helm-charts/
|
||||
helm repo update
|
||||
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/k8sgpt
|
||||
|
||||
# modify values.yaml preload_models with the models you want to install.
|
||||
# CHANGE the URL to a model in huggingface.
|
||||
helm install local-ai go-skynet/local-ai --create-namespace --namespace local-ai --values values.yaml
|
||||
```
|
||||
|
||||
## Setup K8sGPT
|
||||
|
||||
```
|
||||
# Install k8sgpt
|
||||
helm repo add k8sgpt https://charts.k8sgpt.ai/
|
||||
helm repo update
|
||||
helm install release k8sgpt/k8sgpt-operator -n k8sgpt-operator-system --create-namespace --version 0.0.17
|
||||
```
|
||||
|
||||
Apply the k8sgpt-operator configuration:
|
||||
|
||||
```
|
||||
kubectl apply -f - << EOF
|
||||
apiVersion: core.k8sgpt.ai/v1alpha1
|
||||
kind: K8sGPT
|
||||
metadata:
|
||||
name: k8sgpt-local-ai
|
||||
namespace: default
|
||||
spec:
|
||||
backend: localai
|
||||
baseUrl: http://local-ai.local-ai.svc.cluster.local:8080/v1
|
||||
noCache: false
|
||||
model: gpt-3.5-turbo
|
||||
version: v0.3.0
|
||||
enableAI: true
|
||||
EOF
|
||||
```
|
||||
|
||||
## Test
|
||||
|
||||
Apply a broken pod:
|
||||
|
||||
```
|
||||
kubectl apply -f broken-pod.yaml
|
||||
```
|
||||
|
||||
## ArgoCD Deployment Example
|
||||
[Deploy K8sgpt + localai with Argocd](https://github.com/tyler-harpool/gitops/tree/main/infra/k8gpt)
|
||||
@ -1,14 +0,0 @@
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: broken-pod
|
||||
spec:
|
||||
containers:
|
||||
- name: broken-pod
|
||||
image: nginx:1.27.2
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /
|
||||
port: 90
|
||||
initialDelaySeconds: 3
|
||||
periodSeconds: 3
|
||||
@ -1,96 +0,0 @@
|
||||
replicaCount: 1
|
||||
|
||||
deployment:
|
||||
# https://quay.io/repository/go-skynet/local-ai?tab=tags
|
||||
image: quay.io/go-skynet/local-ai:v1.40.0
|
||||
env:
|
||||
threads: 4
|
||||
debug: "true"
|
||||
context_size: 512
|
||||
galleries: '[{"name":"model-gallery", "url":"github:go-skynet/model-gallery/index.yaml"}, {"url": "github:go-skynet/model-gallery/huggingface.yaml","name":"huggingface"}]'
|
||||
preload_models: '[{ "id": "huggingface@thebloke__open-llama-13b-open-instruct-ggml__open-llama-13b-open-instruct.ggmlv3.q3_k_m.bin", "name": "gpt-3.5-turbo", "overrides": { "f16": true, "mmap": true }}]'
|
||||
modelsPath: "/models"
|
||||
|
||||
resources:
|
||||
{}
|
||||
# We usually recommend not to specify default resources and to leave this as a conscious
|
||||
# choice for the user. This also increases chances charts run on environments with little
|
||||
# resources, such as Minikube. If you do want to specify resources, uncomment the following
|
||||
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
|
||||
# limits:
|
||||
# cpu: 100m
|
||||
# memory: 128Mi
|
||||
# requests:
|
||||
# cpu: 100m
|
||||
# memory: 128Mi
|
||||
|
||||
# Prompt templates to include
|
||||
# Note: the keys of this map will be the names of the prompt template files
|
||||
promptTemplates:
|
||||
{}
|
||||
# ggml-gpt4all-j.tmpl: |
|
||||
# The prompt below is a question to answer, a task to complete, or a conversation to respond to; decide which and write an appropriate response.
|
||||
# ### Prompt:
|
||||
# {{.Input}}
|
||||
# ### Response:
|
||||
|
||||
# Models to download at runtime
|
||||
models:
|
||||
# Whether to force download models even if they already exist
|
||||
forceDownload: false
|
||||
|
||||
# The list of URLs to download models from
|
||||
# Note: the name of the file will be the name of the loaded model
|
||||
list:
|
||||
#- url: "https://gpt4all.io/models/ggml-gpt4all-j.bin"
|
||||
# basicAuth: base64EncodedCredentials
|
||||
|
||||
# Persistent storage for models and prompt templates.
|
||||
# PVC and HostPath are mutually exclusive. If both are enabled,
|
||||
# PVC configuration takes precedence. If neither are enabled, ephemeral
|
||||
# storage is used.
|
||||
persistence:
|
||||
pvc:
|
||||
enabled: false
|
||||
size: 6Gi
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
|
||||
annotations: {}
|
||||
|
||||
# Optional
|
||||
storageClass: ~
|
||||
|
||||
hostPath:
|
||||
enabled: false
|
||||
path: "/models"
|
||||
|
||||
service:
|
||||
type: ClusterIP
|
||||
port: 8080
|
||||
annotations: {}
|
||||
# If using an AWS load balancer, you'll need to override the default 60s load balancer idle timeout
|
||||
# service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout: "1200"
|
||||
|
||||
ingress:
|
||||
enabled: false
|
||||
className: ""
|
||||
annotations:
|
||||
{}
|
||||
# kubernetes.io/ingress.class: nginx
|
||||
# kubernetes.io/tls-acme: "true"
|
||||
hosts:
|
||||
- host: chart-example.local
|
||||
paths:
|
||||
- path: /
|
||||
pathType: ImplementationSpecific
|
||||
tls: []
|
||||
# - secretName: chart-example-tls
|
||||
# hosts:
|
||||
# - chart-example.local
|
||||
|
||||
nodeSelector: {}
|
||||
|
||||
tolerations: []
|
||||
|
||||
affinity: {}
|
||||
@ -1,68 +0,0 @@
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: local-ai
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: models-pvc
|
||||
namespace: local-ai
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 20Gi
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
labels:
|
||||
app: local-ai
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: local-ai
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: local-ai
|
||||
name: local-ai
|
||||
spec:
|
||||
containers:
|
||||
- args:
|
||||
- phi-2
|
||||
env:
|
||||
- name: DEBUG
|
||||
value: "true"
|
||||
name: local-ai
|
||||
image: quay.io/go-skynet/local-ai:master-sycl-f32-ffmpeg-core
|
||||
imagePullPolicy: Always
|
||||
resources:
|
||||
limits:
|
||||
gpu.intel.com/i915: 1
|
||||
volumeMounts:
|
||||
- name: models-volume
|
||||
mountPath: /build/models
|
||||
volumes:
|
||||
- name: models-volume
|
||||
persistentVolumeClaim:
|
||||
claimName: models-pvc
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
spec:
|
||||
selector:
|
||||
app: local-ai
|
||||
type: LoadBalancer
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 8080
|
||||
targetPort: 8080
|
||||
@ -1,69 +0,0 @@
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: local-ai
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: models-pvc
|
||||
namespace: local-ai
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 50Gi
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
labels:
|
||||
app: local-ai
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: local-ai
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: local-ai
|
||||
name: local-ai
|
||||
spec:
|
||||
runtimeClassName: "nvidia"
|
||||
containers:
|
||||
- args:
|
||||
- phi-2
|
||||
env:
|
||||
- name: DEBUG
|
||||
value: "true"
|
||||
name: local-ai
|
||||
image: quay.io/go-skynet/local-ai:master-cublas-cuda12
|
||||
imagePullPolicy: IfNotPresent
|
||||
resources:
|
||||
limits:
|
||||
nvidia.com/gpu: 1
|
||||
volumeMounts:
|
||||
- name: models-volume
|
||||
mountPath: /build/models
|
||||
volumes:
|
||||
- name: models-volume
|
||||
persistentVolumeClaim:
|
||||
claimName: models-pvc
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
spec:
|
||||
selector:
|
||||
app: local-ai
|
||||
type: NodePort
|
||||
ports:
|
||||
- protocol: TCP
|
||||
targetPort: 8080
|
||||
port: 8080
|
||||
@ -1,65 +0,0 @@
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: local-ai
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: models-pvc
|
||||
namespace: local-ai
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 1Gi
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
labels:
|
||||
app: local-ai
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: local-ai
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: local-ai
|
||||
name: local-ai
|
||||
spec:
|
||||
containers:
|
||||
- args:
|
||||
- phi-2
|
||||
env:
|
||||
- name: DEBUG
|
||||
value: "true"
|
||||
name: local-ai
|
||||
image: quay.io/go-skynet/local-ai:master-ffmpeg-core
|
||||
imagePullPolicy: IfNotPresent
|
||||
volumeMounts:
|
||||
- name: models-volume
|
||||
mountPath: /build/models
|
||||
volumes:
|
||||
- name: models-volume
|
||||
persistentVolumeClaim:
|
||||
claimName: models-pvc
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
spec:
|
||||
selector:
|
||||
app: local-ai
|
||||
type: LoadBalancer
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 8080
|
||||
targetPort: 8080
|
||||
@ -1,8 +0,0 @@
|
||||
# CPU .env docs: https://localai.io/howtos/easy-setup-docker-cpu/
|
||||
# GPU .env docs: https://localai.io/howtos/easy-setup-docker-gpu/
|
||||
|
||||
THREADS=4
|
||||
CONTEXT_SIZE=512
|
||||
MODELS_PATH=/models
|
||||
DEBUG=true
|
||||
# BUILD_TYPE=generic
|
||||
4
examples/langchain-chroma/.gitignore
vendored
4
examples/langchain-chroma/.gitignore
vendored
@ -1,4 +0,0 @@
|
||||
db/
|
||||
state_of_the_union.txt
|
||||
models/bert
|
||||
models/ggml-gpt4all-j
|
||||
@ -1,63 +0,0 @@
|
||||
# Data query example
|
||||
|
||||
This example makes use of [langchain and chroma](https://blog.langchain.dev/langchain-chroma/) to enable question answering on a set of documents.
|
||||
|
||||
## Setup
|
||||
|
||||
Download the models and start the API:
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/langchain-chroma
|
||||
|
||||
wget https://huggingface.co/skeskinen/ggml/resolve/main/all-MiniLM-L6-v2/ggml-model-q4_0.bin -O models/bert
|
||||
wget https://gpt4all.io/models/ggml-gpt4all-j.bin -O models/ggml-gpt4all-j
|
||||
|
||||
# configure your .env
|
||||
# NOTE: ensure that THREADS does not exceed your machine's CPU cores
|
||||
mv .env.example .env
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up -d --build
|
||||
|
||||
# tail the logs & wait until the build completes
|
||||
docker logs -f langchain-chroma-api-1
|
||||
```
|
||||
|
||||
### Python requirements
|
||||
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
### Create a storage
|
||||
|
||||
In this step we will create a local vector database from our document set, so later we can ask questions on it with the LLM.
|
||||
|
||||
Note: **OPENAI_API_KEY** is not required. However the library might fail if no API_KEY is passed by, so an arbitrary string can be used.
|
||||
|
||||
```bash
|
||||
export OPENAI_API_BASE=http://localhost:8080/v1
|
||||
export OPENAI_API_KEY=sk-
|
||||
|
||||
wget https://raw.githubusercontent.com/hwchase17/chat-your-data/master/state_of_the_union.txt
|
||||
python store.py
|
||||
```
|
||||
|
||||
After it finishes, a directory "db" will be created with the vector index database.
|
||||
|
||||
## Query
|
||||
|
||||
We can now query the dataset.
|
||||
|
||||
```bash
|
||||
export OPENAI_API_BASE=http://localhost:8080/v1
|
||||
export OPENAI_API_KEY=sk-
|
||||
|
||||
python query.py
|
||||
# President Trump recently stated during a press conference regarding tax reform legislation that "we're getting rid of all these loopholes." He also mentioned that he wants to simplify the system further through changes such as increasing the standard deduction amount and making other adjustments aimed at reducing taxpayers' overall burden.
|
||||
```
|
||||
|
||||
Keep in mind now things are hit or miss!
|
||||
@ -1,15 +0,0 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
env_file:
|
||||
- ../../.env
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai"]
|
||||
@ -1 +0,0 @@
|
||||
../models
|
||||
@ -1,23 +0,0 @@
|
||||
|
||||
import os
|
||||
from langchain.vectorstores import Chroma
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.chains import RetrievalQA
|
||||
from langchain.vectorstores.base import VectorStoreRetriever
|
||||
|
||||
base_path = os.environ.get('OPENAI_API_BASE', 'http://localhost:8080/v1')
|
||||
|
||||
# Load and process the text
|
||||
embedding = OpenAIEmbeddings(model="text-embedding-ada-002", openai_api_base=base_path)
|
||||
persist_directory = 'db'
|
||||
|
||||
# Now we can load the persisted database from disk, and use it as normal.
|
||||
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", openai_api_base=base_path)
|
||||
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
|
||||
retriever = VectorStoreRetriever(vectorstore=vectordb)
|
||||
qa = RetrievalQA.from_llm(llm=llm, retriever=retriever)
|
||||
|
||||
query = "What the president said about taxes ?"
|
||||
print(qa.run(query))
|
||||
|
||||
@ -1,4 +0,0 @@
|
||||
langchain==0.3.3
|
||||
openai==1.52.2
|
||||
chromadb==0.5.13
|
||||
llama-index==0.11.20
|
||||
@ -1,25 +0,0 @@
|
||||
|
||||
import os
|
||||
from langchain.vectorstores import Chroma
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.text_splitter import CharacterTextSplitter
|
||||
from langchain.document_loaders import TextLoader
|
||||
|
||||
base_path = os.environ.get('OPENAI_API_BASE', 'http://localhost:8080/v1')
|
||||
|
||||
# Load and process the text
|
||||
loader = TextLoader('state_of_the_union.txt')
|
||||
documents = loader.load()
|
||||
|
||||
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=70)
|
||||
texts = text_splitter.split_documents(documents)
|
||||
|
||||
# Embed and store the texts
|
||||
# Supplying a persist_directory will store the embeddings on disk
|
||||
persist_directory = 'db'
|
||||
|
||||
embedding = OpenAIEmbeddings(model="text-embedding-ada-002", openai_api_base=base_path)
|
||||
vectordb = Chroma.from_documents(documents=texts, embedding=embedding, persist_directory=persist_directory)
|
||||
|
||||
vectordb.persist()
|
||||
vectordb = None
|
||||
@ -1,68 +0,0 @@
|
||||
# Data query example
|
||||
|
||||
Example of integration with HuggingFace Inference API with help of [langchaingo](https://github.com/tmc/langchaingo).
|
||||
|
||||
## Setup
|
||||
|
||||
Download the LocalAI and start the API:
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/langchain-huggingface
|
||||
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
Node: Ensure you've set `HUGGINGFACEHUB_API_TOKEN` environment variable, you can generate it
|
||||
on [Settings / Access Tokens](https://huggingface.co/settings/tokens) page of HuggingFace site.
|
||||
|
||||
This is an example `.env` file for LocalAI:
|
||||
|
||||
```ini
|
||||
MODELS_PATH=/models
|
||||
CONTEXT_SIZE=512
|
||||
HUGGINGFACEHUB_API_TOKEN=hg_123456
|
||||
```
|
||||
|
||||
## Using remote models
|
||||
|
||||
Now you can use any remote models available via HuggingFace API, for example let's enable using of
|
||||
[gpt2](https://huggingface.co/gpt2) model in `gpt-3.5-turbo.yaml` config:
|
||||
|
||||
```yml
|
||||
name: gpt-3.5-turbo
|
||||
parameters:
|
||||
model: gpt2
|
||||
top_k: 80
|
||||
temperature: 0.2
|
||||
top_p: 0.7
|
||||
context_size: 1024
|
||||
backend: "langchain-huggingface"
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "GPT:"
|
||||
roles:
|
||||
user: " "
|
||||
system: " "
|
||||
template:
|
||||
completion: completion
|
||||
chat: gpt4all
|
||||
```
|
||||
|
||||
Here is you can see in field `parameters.model` equal `gpt2` and `backend` equal `langchain-huggingface`.
|
||||
|
||||
## How to use
|
||||
|
||||
```shell
|
||||
# Now API is accessible at localhost:8080
|
||||
curl http://localhost:8080/v1/models
|
||||
# {"object":"list","data":[{"id":"gpt-3.5-turbo","object":"model"}]}
|
||||
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "gpt-3.5-turbo",
|
||||
"prompt": "A long time ago in a galaxy far, far away",
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
@ -1,15 +0,0 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
env_file:
|
||||
- ../../.env
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai"]
|
||||
@ -1 +0,0 @@
|
||||
../models
|
||||
@ -1,29 +0,0 @@
|
||||
## Langchain-python
|
||||
|
||||
Langchain example from [quickstart](https://python.langchain.com/en/latest/getting_started/getting_started.html).
|
||||
|
||||
To interact with langchain, you can just set the `OPENAI_API_BASE` URL and provide a token with a random string.
|
||||
|
||||
See the example below:
|
||||
|
||||
```
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/langchain-python
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up --pull always
|
||||
|
||||
pip install langchain
|
||||
pip install openai
|
||||
|
||||
export OPENAI_API_BASE=http://localhost:8080
|
||||
# Note: **OPENAI_API_KEY** is not required. However the library might fail if no API_KEY is passed by, so an arbitrary string can be used.
|
||||
export OPENAI_API_KEY=sk-
|
||||
|
||||
python test.py
|
||||
# A good company name for a company that makes colorful socks would be "Colorsocks".
|
||||
|
||||
python agent.py
|
||||
```
|
||||
@ -1,44 +0,0 @@
|
||||
## This is a fork/based from https://gist.github.com/wiseman/4a706428eaabf4af1002a07a114f61d6
|
||||
|
||||
from io import StringIO
|
||||
import sys
|
||||
import os
|
||||
from typing import Dict, Optional
|
||||
|
||||
from langchain.agents import load_tools
|
||||
from langchain.agents import initialize_agent
|
||||
from langchain.agents.tools import Tool
|
||||
from langchain.llms import OpenAI
|
||||
|
||||
base_path = os.environ.get('OPENAI_API_BASE', 'http://localhost:8080/v1')
|
||||
model_name = os.environ.get('MODEL_NAME', 'gpt-3.5-turbo')
|
||||
|
||||
class PythonREPL:
|
||||
"""Simulates a standalone Python REPL."""
|
||||
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
def run(self, command: str) -> str:
|
||||
"""Run command and returns anything printed."""
|
||||
old_stdout = sys.stdout
|
||||
sys.stdout = mystdout = StringIO()
|
||||
try:
|
||||
exec(command, globals())
|
||||
sys.stdout = old_stdout
|
||||
output = mystdout.getvalue()
|
||||
except Exception as e:
|
||||
sys.stdout = old_stdout
|
||||
output = str(e)
|
||||
return output
|
||||
|
||||
llm = OpenAI(temperature=0.0, openai_api_base=base_path, model_name=model_name)
|
||||
python_repl = Tool(
|
||||
"Python REPL",
|
||||
PythonREPL().run,
|
||||
"""A Python shell. Use this to execute python commands. Input should be a valid python command.
|
||||
If you expect output it should be printed out.""",
|
||||
)
|
||||
tools = [python_repl]
|
||||
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
|
||||
agent.run("What is the 10th fibonacci number?")
|
||||
@ -1,27 +0,0 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
# As initially LocalAI will download the models defined in PRELOAD_MODELS
|
||||
# you might need to tweak the healthcheck values here according to your network connection.
|
||||
# Here we give a timespan of 20m to download all the required files.
|
||||
healthcheck:
|
||||
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
|
||||
interval: 1m
|
||||
timeout: 20m
|
||||
retries: 20
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
# You can preload different models here as well.
|
||||
# See: https://github.com/go-skynet/model-gallery
|
||||
- 'PRELOAD_MODELS=[{"url": "github:go-skynet/model-gallery/gpt4all-j.yaml", "name": "gpt-3.5-turbo"}]'
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
@ -1,6 +0,0 @@
|
||||
|
||||
from langchain.llms import OpenAI
|
||||
|
||||
llm = OpenAI(temperature=0.9,model_name="gpt-3.5-turbo")
|
||||
text = "What would be a good company name for a company that makes colorful socks?"
|
||||
print(llm(text))
|
||||
2
examples/langchain/.gitignore
vendored
2
examples/langchain/.gitignore
vendored
@ -1,2 +0,0 @@
|
||||
models/ggml-koala-13B-4bit-128g
|
||||
models/ggml-gpt4all-j
|
||||
@ -1,6 +0,0 @@
|
||||
FROM node:lts-alpine
|
||||
COPY ./langchainjs-localai-example /app
|
||||
WORKDIR /app
|
||||
RUN npm install
|
||||
RUN npm run build
|
||||
ENTRYPOINT [ "npm", "run", "start" ]
|
||||
@ -1,5 +0,0 @@
|
||||
FROM python:3.13-bullseye
|
||||
COPY ./langchainpy-localai-example /app
|
||||
WORKDIR /app
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
ENTRYPOINT [ "python", "./full_demo.py" ]
|
||||
@ -1,30 +0,0 @@
|
||||
# langchain
|
||||
|
||||
Example of using langchain, with the standard OpenAI llm module, and LocalAI. Has docker compose profiles for both the Typescript and Python versions.
|
||||
|
||||
**Please Note** - This is a tech demo example at this time. ggml-gpt4all-j has pretty terrible results for most langchain applications with the settings used in this example.
|
||||
|
||||
## Setup
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/langchain
|
||||
|
||||
# (optional) - Edit the example code in typescript.
|
||||
# vi ./langchainjs-localai-example/index.ts
|
||||
|
||||
# Download gpt4all-j to models/
|
||||
wget https://gpt4all.io/models/ggml-gpt4all-j.bin -O models/ggml-gpt4all-j
|
||||
|
||||
# start with docker-compose for typescript!
|
||||
docker-compose --profile ts up --build
|
||||
|
||||
# or start with docker-compose for python!
|
||||
docker-compose --profile py up --build
|
||||
```
|
||||
|
||||
## Copyright
|
||||
|
||||
Some of the example code in index.mts and full_demo.py is adapted from the langchainjs project and is Copyright (c) Harrison Chase. Used under the terms of the MIT license, as is the remainder of this code.
|
||||
@ -1,43 +0,0 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
|
||||
js:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: JS.Dockerfile
|
||||
profiles:
|
||||
- js
|
||||
- ts
|
||||
depends_on:
|
||||
- "api"
|
||||
environment:
|
||||
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
|
||||
- 'OPENAI_API_BASE=http://api:8080/v1'
|
||||
- 'MODEL_NAME=gpt-3.5-turbo' #gpt-3.5-turbo' # ggml-gpt4all-j' # ggml-koala-13B-4bit-128g'
|
||||
|
||||
py:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: PY.Dockerfile
|
||||
profiles:
|
||||
- py
|
||||
depends_on:
|
||||
- "api"
|
||||
environment:
|
||||
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
|
||||
- 'OPENAI_API_BASE=http://api:8080/v1'
|
||||
- 'MODEL_NAME=gpt-3.5-turbo' #gpt-3.5-turbo' # ggml-gpt4all-j' # ggml-koala-13B-4bit-128g'
|
||||
@ -1,2 +0,0 @@
|
||||
node_modules/
|
||||
dist/
|
||||
@ -1,20 +0,0 @@
|
||||
{
|
||||
// Use IntelliSense to learn about possible attributes.
|
||||
// Hover to view descriptions of existing attributes.
|
||||
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"type": "node",
|
||||
"request": "launch",
|
||||
"name": "Launch Program",
|
||||
// "skipFiles": [
|
||||
// "<node_internals>/**"
|
||||
// ],
|
||||
"program": "${workspaceFolder}\\dist\\index.mjs",
|
||||
"outFiles": [
|
||||
"${workspaceFolder}/**/*.js"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user