mirror of
https://github.com/mudler/LocalAI.git
synced 2025-05-07 11:08:27 +00:00
example(k8sgpt): Add k8sgpt example (#631)
Signed-off-by: mudler <mudler@localai.io>
This commit is contained in:
parent
6da892758b
commit
7da07e8af9
@ -24,6 +24,14 @@ This integration shows how to use LocalAI with [mckaywrigley/chatbot-ui](https:/
|
|||||||
|
|
||||||
There is also a separate example to show how to manually setup a model: [example](https://github.com/go-skynet/LocalAI/tree/master/examples/chatbot-ui-manual/)
|
There is also a separate example to show how to manually setup a model: [example](https://github.com/go-skynet/LocalAI/tree/master/examples/chatbot-ui-manual/)
|
||||||
|
|
||||||
|
### K8sGPT
|
||||||
|
|
||||||
|
_by [@mudler](https://github.com/mudler)_
|
||||||
|
|
||||||
|
This example show how to use LocalAI inside Kubernetes with [k8sgpt](https://k8sgpt.ai).
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Flowise
|
### Flowise
|
||||||
|
|
||||||
_by [@mudler](https://github.com/mudler)_
|
_by [@mudler](https://github.com/mudler)_
|
||||||
|
|||||||
70
examples/k8sgpt/README.md
Normal file
70
examples/k8sgpt/README.md
Normal file
@ -0,0 +1,70 @@
|
|||||||
|
# k8sgpt example
|
||||||
|
|
||||||
|
This example show how to use LocalAI with k8sgpt
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Create the cluster locally with Kind (optional)
|
||||||
|
|
||||||
|
If you want to test this locally without a remote Kubernetes cluster, you can use kind.
|
||||||
|
|
||||||
|
Install [kind](https://kind.sigs.k8s.io/) and create a cluster:
|
||||||
|
|
||||||
|
```
|
||||||
|
kind create cluster
|
||||||
|
```
|
||||||
|
|
||||||
|
## Setup LocalAI
|
||||||
|
|
||||||
|
We will use [helm](https://helm.sh/docs/intro/install/):
|
||||||
|
|
||||||
|
```
|
||||||
|
helm repo add go-skynet https://go-skynet.github.io/helm-charts/
|
||||||
|
helm repo update
|
||||||
|
|
||||||
|
# Clone LocalAI
|
||||||
|
git clone https://github.com/go-skynet/LocalAI
|
||||||
|
|
||||||
|
cd LocalAI/examples/k8sgpt
|
||||||
|
|
||||||
|
# modify values.yaml preload_models with the models you want to install.
|
||||||
|
# CHANGE the URL to a model in huggingface.
|
||||||
|
helm install local-ai go-skynet/local-ai --create-namespace --namespace local-ai --values values.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
## Setup K8sGPT
|
||||||
|
|
||||||
|
```
|
||||||
|
# Install k8sgpt
|
||||||
|
helm repo add k8sgpt https://charts.k8sgpt.ai/
|
||||||
|
helm repo update
|
||||||
|
helm install release k8sgpt/k8sgpt-operator -n k8sgpt-operator-system --create-namespace
|
||||||
|
```
|
||||||
|
|
||||||
|
Apply the k8sgpt-operator configuration:
|
||||||
|
|
||||||
|
```
|
||||||
|
kubectl apply -f - << EOF
|
||||||
|
apiVersion: core.k8sgpt.ai/v1alpha1
|
||||||
|
kind: K8sGPT
|
||||||
|
metadata:
|
||||||
|
name: k8sgpt-local-ai
|
||||||
|
namespace: default
|
||||||
|
spec:
|
||||||
|
backend: localai
|
||||||
|
baseUrl: http://local-ai.local-ai.svc.cluster.local:8080/v1
|
||||||
|
noCache: false
|
||||||
|
model: gpt-3.5-turbo
|
||||||
|
noCache: false
|
||||||
|
version: v0.3.0
|
||||||
|
enableAI: true
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
## Test
|
||||||
|
|
||||||
|
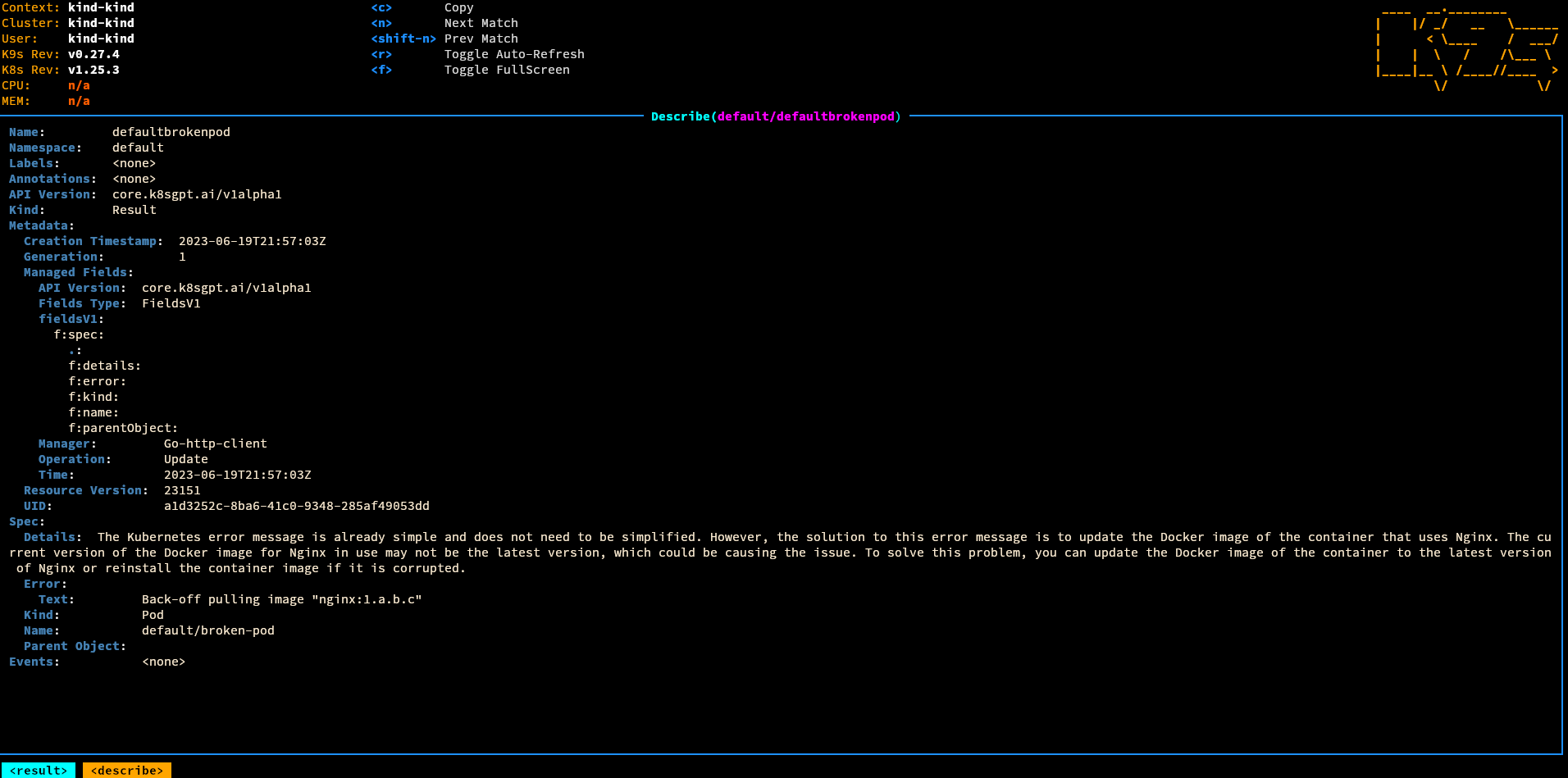
Apply a broken pod:
|
||||||
|
|
||||||
|
```
|
||||||
|
kubectl apply -f broken-pod.yaml
|
||||||
|
```
|
||||||
14
examples/k8sgpt/broken-pod.yaml
Normal file
14
examples/k8sgpt/broken-pod.yaml
Normal file
@ -0,0 +1,14 @@
|
|||||||
|
apiVersion: v1
|
||||||
|
kind: Pod
|
||||||
|
metadata:
|
||||||
|
name: broken-pod
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: broken-pod
|
||||||
|
image: nginx:1.a.b.c
|
||||||
|
livenessProbe:
|
||||||
|
httpGet:
|
||||||
|
path: /
|
||||||
|
port: 90
|
||||||
|
initialDelaySeconds: 3
|
||||||
|
periodSeconds: 3
|
||||||
95
examples/k8sgpt/values.yaml
Normal file
95
examples/k8sgpt/values.yaml
Normal file
@ -0,0 +1,95 @@
|
|||||||
|
replicaCount: 1
|
||||||
|
|
||||||
|
deployment:
|
||||||
|
# https://quay.io/repository/go-skynet/local-ai?tab=tags
|
||||||
|
image: quay.io/go-skynet/local-ai:latest
|
||||||
|
env:
|
||||||
|
threads: 4
|
||||||
|
debug: "true"
|
||||||
|
context_size: 512
|
||||||
|
preload_models: '[{ "url": "github:go-skynet/model-gallery/wizard.yaml", "name": "gpt-3.5-turbo", "overrides": { "parameters": { "model": "WizardLM-7B-uncensored.ggmlv3.q5_1" }},"files": [ { "uri": "https://huggingface.co//WizardLM-7B-uncensored-GGML/resolve/main/WizardLM-7B-uncensored.ggmlv3.q5_1.bin", "sha256": "d92a509d83a8ea5e08ba4c2dbaf08f29015932dc2accd627ce0665ac72c2bb2b", "filename": "WizardLM-7B-uncensored.ggmlv3.q5_1" }]}]'
|
||||||
|
modelsPath: "/models"
|
||||||
|
|
||||||
|
resources:
|
||||||
|
{}
|
||||||
|
# We usually recommend not to specify default resources and to leave this as a conscious
|
||||||
|
# choice for the user. This also increases chances charts run on environments with little
|
||||||
|
# resources, such as Minikube. If you do want to specify resources, uncomment the following
|
||||||
|
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
|
||||||
|
# limits:
|
||||||
|
# cpu: 100m
|
||||||
|
# memory: 128Mi
|
||||||
|
# requests:
|
||||||
|
# cpu: 100m
|
||||||
|
# memory: 128Mi
|
||||||
|
|
||||||
|
# Prompt templates to include
|
||||||
|
# Note: the keys of this map will be the names of the prompt template files
|
||||||
|
promptTemplates:
|
||||||
|
{}
|
||||||
|
# ggml-gpt4all-j.tmpl: |
|
||||||
|
# The prompt below is a question to answer, a task to complete, or a conversation to respond to; decide which and write an appropriate response.
|
||||||
|
# ### Prompt:
|
||||||
|
# {{.Input}}
|
||||||
|
# ### Response:
|
||||||
|
|
||||||
|
# Models to download at runtime
|
||||||
|
models:
|
||||||
|
# Whether to force download models even if they already exist
|
||||||
|
forceDownload: false
|
||||||
|
|
||||||
|
# The list of URLs to download models from
|
||||||
|
# Note: the name of the file will be the name of the loaded model
|
||||||
|
list:
|
||||||
|
#- url: "https://gpt4all.io/models/ggml-gpt4all-j.bin"
|
||||||
|
# basicAuth: base64EncodedCredentials
|
||||||
|
|
||||||
|
# Persistent storage for models and prompt templates.
|
||||||
|
# PVC and HostPath are mutually exclusive. If both are enabled,
|
||||||
|
# PVC configuration takes precedence. If neither are enabled, ephemeral
|
||||||
|
# storage is used.
|
||||||
|
persistence:
|
||||||
|
pvc:
|
||||||
|
enabled: false
|
||||||
|
size: 6Gi
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteOnce
|
||||||
|
|
||||||
|
annotations: {}
|
||||||
|
|
||||||
|
# Optional
|
||||||
|
storageClass: ~
|
||||||
|
|
||||||
|
hostPath:
|
||||||
|
enabled: false
|
||||||
|
path: "/models"
|
||||||
|
|
||||||
|
service:
|
||||||
|
type: ClusterIP
|
||||||
|
port: 8080
|
||||||
|
annotations: {}
|
||||||
|
# If using an AWS load balancer, you'll need to override the default 60s load balancer idle timeout
|
||||||
|
# service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout: "1200"
|
||||||
|
|
||||||
|
ingress:
|
||||||
|
enabled: false
|
||||||
|
className: ""
|
||||||
|
annotations:
|
||||||
|
{}
|
||||||
|
# kubernetes.io/ingress.class: nginx
|
||||||
|
# kubernetes.io/tls-acme: "true"
|
||||||
|
hosts:
|
||||||
|
- host: chart-example.local
|
||||||
|
paths:
|
||||||
|
- path: /
|
||||||
|
pathType: ImplementationSpecific
|
||||||
|
tls: []
|
||||||
|
# - secretName: chart-example-tls
|
||||||
|
# hosts:
|
||||||
|
# - chart-example.local
|
||||||
|
|
||||||
|
nodeSelector: {}
|
||||||
|
|
||||||
|
tolerations: []
|
||||||
|
|
||||||
|
affinity: {}
|
||||||
Loading…
x
Reference in New Issue
Block a user