mirror of
https://github.com/mudler/LocalAI.git
synced 2025-05-22 10:14:21 +00:00
docs: add fine-tuning example (#1374)
Signed-off-by: Ettore Di Giacinto <mudler@localai.io>
This commit is contained in:
parent
e94a34be8c
commit
2b2007ae9e
30
README.md
30
README.md
@ -81,10 +81,15 @@ Note that this started just as a [fun weekend project](https://localai.io/#backs
|
||||
|
||||
## 🔥🔥 Hot topics / Roadmap
|
||||
|
||||
- [Roadmap](https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3Aroadmap)
|
||||
[Roadmap](https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3Aroadmap)
|
||||
|
||||
Hot topics:
|
||||
- https://github.com/mudler/LocalAI/issues/1126
|
||||
🆕 New! [LLM finetuning guide](https://localai.io/advanced/fine-tuning/)
|
||||
|
||||
Hot topics (looking for contributors):
|
||||
- Backends v2: https://github.com/mudler/LocalAI/issues/1126
|
||||
- Improving UX v2: https://github.com/mudler/LocalAI/issues/1373
|
||||
|
||||
If you want to help and contribute, issues up for grabs: https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3A%22up+for+grabs%22
|
||||
|
||||
## 🚀 [Features](https://localai.io/features/)
|
||||
|
||||
@ -98,20 +103,13 @@ Hot topics:
|
||||
- 🖼️ [Download Models directly from Huggingface ](https://localai.io/models/)
|
||||
- 🆕 [Vision API](https://localai.io/features/gpt-vision/)
|
||||
|
||||
## :book: 🎥 [Media, Blogs, Social](https://localai.io/basics/news/#media-blogs-social)
|
||||
|
||||
- [Create a slackbot for teams and OSS projects that answer to documentation](https://mudler.pm/posts/smart-slackbot-for-teams/)
|
||||
- [LocalAI meets k8sgpt](https://www.youtube.com/watch?v=PKrDNuJ_dfE)
|
||||
- [Question Answering on Documents locally with LangChain, LocalAI, Chroma, and GPT4All](https://mudler.pm/posts/localai-question-answering/)
|
||||
- [Tutorial to use k8sgpt with LocalAI](https://medium.com/@tyler_97636/k8sgpt-localai-unlock-kubernetes-superpowers-for-free-584790de9b65)
|
||||
|
||||
## 💻 Usage
|
||||
|
||||
Check out the [Getting started](https://localai.io/basics/getting_started/index.html) section in our documentation.
|
||||
|
||||
### Community
|
||||
### 🔗 Community and integrations
|
||||
|
||||
WebUI
|
||||
WebUIs:
|
||||
- https://github.com/Jirubizu/localai-admin
|
||||
- https://github.com/go-skynet/LocalAI-frontend
|
||||
|
||||
@ -123,11 +121,19 @@ Other:
|
||||
|
||||
### 🔗 Resources
|
||||
|
||||
- 🆕 New! [LLM finetuning guide](https://localai.io/advanced/fine-tuning/)
|
||||
- [How to build locally](https://localai.io/basics/build/index.html)
|
||||
- [How to install in Kubernetes](https://localai.io/basics/getting_started/index.html#run-localai-in-kubernetes)
|
||||
- [Projects integrating LocalAI](https://localai.io/integrations/)
|
||||
- [How tos section](https://localai.io/howtos/) (curated by our community)
|
||||
|
||||
## :book: 🎥 [Media, Blogs, Social](https://localai.io/basics/news/#media-blogs-social)
|
||||
|
||||
- [Create a slackbot for teams and OSS projects that answer to documentation](https://mudler.pm/posts/smart-slackbot-for-teams/)
|
||||
- [LocalAI meets k8sgpt](https://www.youtube.com/watch?v=PKrDNuJ_dfE)
|
||||
- [Question Answering on Documents locally with LangChain, LocalAI, Chroma, and GPT4All](https://mudler.pm/posts/localai-question-answering/)
|
||||
- [Tutorial to use k8sgpt with LocalAI](https://medium.com/@tyler_97636/k8sgpt-localai-unlock-kubernetes-superpowers-for-free-584790de9b65)
|
||||
|
||||
## Citation
|
||||
|
||||
If you utilize this repository, data in a downstream project, please consider citing it with:
|
||||
|
||||
@ -89,10 +89,15 @@ Note that this started just as a [fun weekend project](https://localai.io/#backs
|
||||
|
||||
## 🔥🔥 Hot topics / Roadmap
|
||||
|
||||
- [Roadmap](https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3Aroadmap)
|
||||
[Roadmap](https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3Aroadmap)
|
||||
|
||||
Hot topics:
|
||||
- https://github.com/mudler/LocalAI/issues/1126
|
||||
🆕 New! [LLM finetuning guide](https://localai.io/advanced/fine-tuning/)
|
||||
|
||||
Hot topics (looking for contributors):
|
||||
- Backends v2: https://github.com/mudler/LocalAI/issues/1126
|
||||
- Improving UX v2: https://github.com/mudler/LocalAI/issues/1373
|
||||
|
||||
If you want to help and contribute, issues up for grabs: https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3A%22up+for+grabs%22
|
||||
|
||||
## How does it work?
|
||||
|
||||
|
||||
134
docs/content/advanced/fine-tuning.md
Normal file
134
docs/content/advanced/fine-tuning.md
Normal file
@ -0,0 +1,134 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Fine-tuning LLMs for text generation"
|
||||
weight = 3
|
||||
+++
|
||||
|
||||
{{% notice note %}}
|
||||
Section under construction
|
||||
{{% /notice %}}
|
||||
|
||||
This section covers how to fine-tune a language model for text generation and consume it in LocalAI.
|
||||
|
||||
## Requirements
|
||||
|
||||
For this example you will need at least a 12GB VRAM of GPU and a Linux box.
|
||||
|
||||
## Fine-tuning
|
||||
|
||||
Fine-tuning a language model is a process that requires a lot of computational power and time.
|
||||
|
||||
Currently LocalAI doesn't support the fine-tuning endpoint as LocalAI but there are are [plans](https://github.com/mudler/LocalAI/issues/596) to support that. For the time being a guide is proposed here to give a simple starting point on how to fine-tune a model and use it with LocalAI (but also with llama.cpp).
|
||||
|
||||
There is an e2e example of fine-tuning a LLM model to use with [LocalAI](https://github/mudler/LocalAI) written by [@mudler](https://github.com/mudler) available [here](https://github.com/mudler/LocalAI/tree/master/examples/e2e-fine-tuning/).
|
||||
|
||||
The steps involved are:
|
||||
|
||||
- Preparing a dataset
|
||||
- Prepare the environment and install dependencies
|
||||
- Fine-tune the model
|
||||
- Merge the Lora base with the model
|
||||
- Convert the model to gguf
|
||||
- Use the model with LocalAI
|
||||
|
||||
## Dataset preparation
|
||||
|
||||
We are going to need a dataset or a set of datasets.
|
||||
|
||||
Axolotl supports a variety of formats, in the notebook and in this example we are aiming for a very simple dataset and build that manually, so we are going to use the `completion` format which requires the full text to be used for fine-tuning.
|
||||
|
||||
A dataset for an instructor model (like Alpaca) can look like the following:
|
||||
|
||||
```json
|
||||
[
|
||||
{
|
||||
"text": "As an AI language model you are trained to reply to an instruction. Try to be as much polite as possible\n\n## Instruction\n\nWrite a poem about a tree.\n\n## Response\n\nTrees are beautiful, ...",
|
||||
},
|
||||
{
|
||||
"text": "As an AI language model you are trained to reply to an instruction. Try to be as much polite as possible\n\n## Instruction\n\nWrite a poem about a tree.\n\n## Response\n\nTrees are beautiful, ...",
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
Every block in the text is the whole text that is used to fine-tune. For example, for an instructor model it follows the following format (more or less):
|
||||
|
||||
```
|
||||
<System prompt>
|
||||
|
||||
## Instruction
|
||||
|
||||
<Question, instruction>
|
||||
|
||||
## Response
|
||||
|
||||
<Expected response from the LLM>
|
||||
```
|
||||
|
||||
The instruction format works such as when we are going to inference with the model, we are going to feed it only the first part up to the `## Instruction` block, and the model is going to complete the text with the `## Response` block.
|
||||
|
||||
Prepare a dataset, and upload it to your Google Drive in case you are using the Google colab. Otherwise place it next the `axolotl.yaml` file as `dataset.json`.
|
||||
|
||||
### Install dependencies
|
||||
|
||||
```bash
|
||||
# Install axolotl and dependencies
|
||||
git clone https://github.com/OpenAccess-AI-Collective/axolotl && pushd axolotl && git checkout 797f3dd1de8fd8c0eafbd1c9fdb172abd9ff840a && popd #0.3.0
|
||||
pip install packaging
|
||||
pushd axolotl && pip install -e '.[flash-attn,deepspeed]' && popd
|
||||
|
||||
# https://github.com/oobabooga/text-generation-webui/issues/4238
|
||||
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.3.0/flash_attn-2.3.0+cu117torch2.0cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
|
||||
```
|
||||
|
||||
Configure accelerate:
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
## Fine-tuning
|
||||
|
||||
We will need to configure axolotl. In this example is provided a file to use `axolotl.yaml` that uses openllama-3b for fine-tuning. Copy the `axolotl.yaml` file and edit it to your needs. The dataset needs to be next to it as `dataset.json`. You can find the axolotl.yaml file [here](https://github.com/mudler/LocalAI/tree/master/examples/e2e-fine-tuning/).
|
||||
|
||||
If you have a big dataset, you can pre-tokenize it to speedup the fine-tuning process:
|
||||
|
||||
```bash
|
||||
# Optional pre-tokenize (run only if big dataset)
|
||||
python -m axolotl.cli.preprocess axolotl.yaml
|
||||
```
|
||||
|
||||
Now we are ready to start the fine-tuning process:
|
||||
```bash
|
||||
# Fine-tune
|
||||
accelerate launch -m axolotl.cli.train axolotl.yaml
|
||||
```
|
||||
|
||||
After we have finished the fine-tuning, we merge the Lora base with the model:
|
||||
```bash
|
||||
# Merge lora
|
||||
python3 -m axolotl.cli.merge_lora axolotl.yaml --lora_model_dir="./qlora-out" --load_in_8bit=False --load_in_4bit=False
|
||||
```
|
||||
|
||||
And we convert it to the gguf format that LocalAI can consume:
|
||||
|
||||
```bash
|
||||
|
||||
# Convert to gguf
|
||||
git clone https://github.com/ggerganov/llama.cpp.git
|
||||
pushd llama.cpp && make LLAMA_CUBLAS=1 && popd
|
||||
|
||||
# We need to convert the pytorch model into ggml for quantization
|
||||
# It crates 'ggml-model-f16.bin' in the 'merged' directory.
|
||||
pushd llama.cpp && python convert.py --outtype f16 \
|
||||
../qlora-out/merged/pytorch_model-00001-of-00002.bin && popd
|
||||
|
||||
# Start off by making a basic q4_0 4-bit quantization.
|
||||
# It's important to have 'ggml' in the name of the quant for some
|
||||
# software to recognize it's file format.
|
||||
pushd llama.cpp && ./quantize ../qlora-out/merged/ggml-model-f16.gguf \
|
||||
../custom-model-q4_0.bin q4_0
|
||||
|
||||
```
|
||||
|
||||
Now you should have ended up with a `custom-model-q4_0.bin` file that you can copy in the LocalAI models directory and use it with LocalAI.
|
||||
@ -41,6 +41,14 @@ This example show how to use LocalAI inside Kubernetes with [k8sgpt](https://k8s
|
||||
|
||||
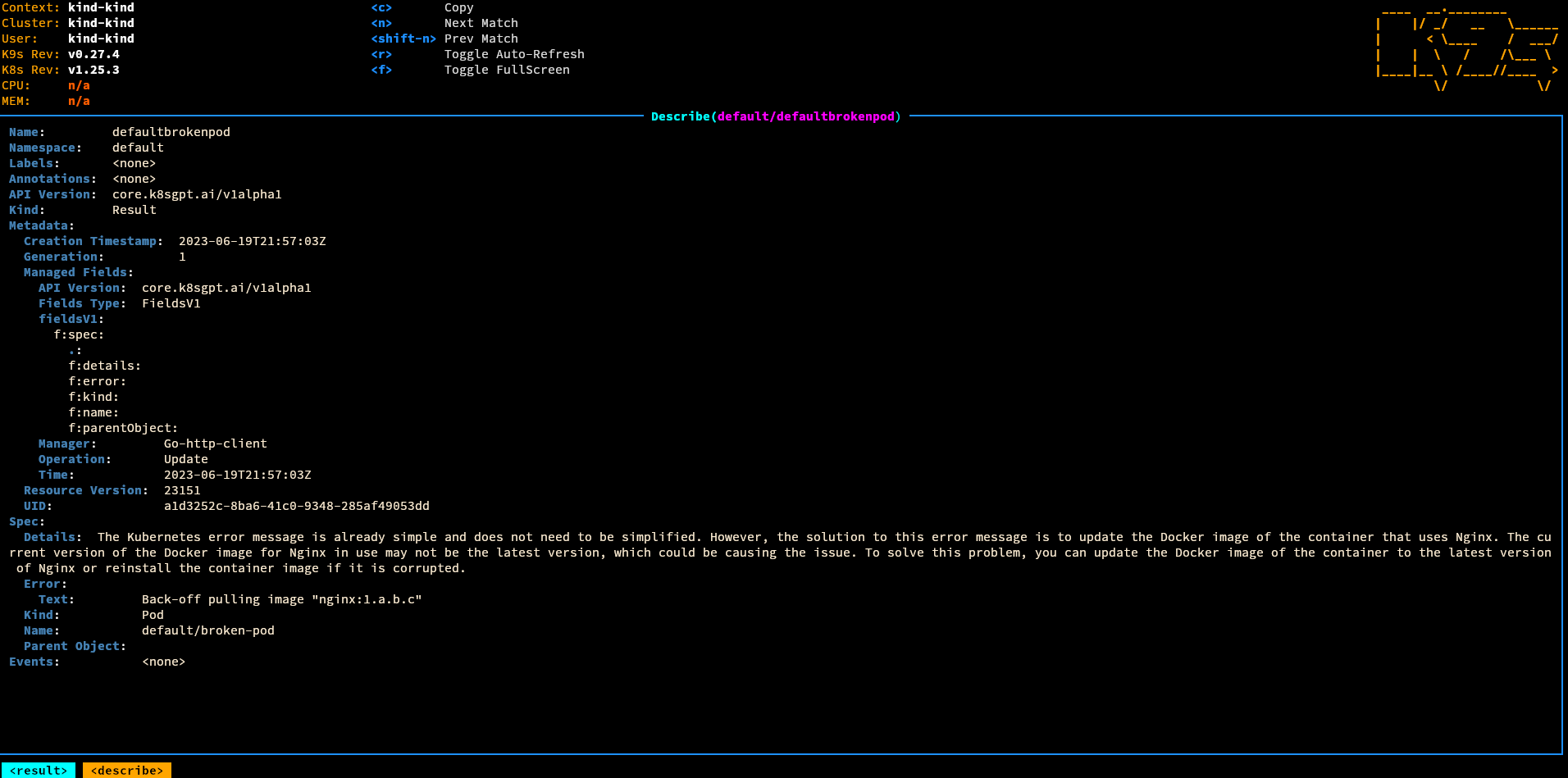
|
||||
|
||||
### Fine-tuning a model and convert it to gguf to use it with LocalAI
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
This example is an e2e example on how to fine-tune a model with [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) and convert it to gguf to use it with LocalAI.
|
||||
|
||||
[Check it out here](https://github.com/mudler/LocalAI/tree/master/examples/e2e-fine-tuning/)
|
||||
|
||||
### Flowise
|
||||
|
||||
_by [@mudler](https://github.com/mudler)_
|
||||
|
||||
83
examples/e2e-fine-tuning/README.md
Normal file
83
examples/e2e-fine-tuning/README.md
Normal file
@ -0,0 +1,83 @@
|
||||
This is an example of fine-tuning a LLM model to use with [LocalAI](https://github/mudler/LocalAI) written by [@mudler](https://github.com/mudler).
|
||||
|
||||
Specifically, this example shows how to use [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) to fine-tune a LLM model to consume with LocalAI as a `gguf` model.
|
||||
|
||||
A notebook is provided that currently works on _very small_ datasets on Google colab on the free instance. It is far from producing good models, but it gives a sense of how to use the code to use with a better dataset and configurations, and how to use the model produced with LocalAI.
|
||||
|
||||
## Requirements
|
||||
|
||||
For this example you will need at least a 12GB VRAM of GPU and a Linux box.
|
||||
The notebook is tested on Google Colab with a Tesla T4 GPU.
|
||||
|
||||
## Clone this directory
|
||||
|
||||
Clone the repository and enter the example directory:
|
||||
|
||||
```bash
|
||||
git clone http://github.com/mudler/LocalAI
|
||||
cd LocalAI/examples/e2e-fine-tuning
|
||||
```
|
||||
|
||||
## Install dependencies
|
||||
|
||||
```bash
|
||||
# Install axolotl and dependencies
|
||||
git clone https://github.com/OpenAccess-AI-Collective/axolotl && pushd axolotl && git checkout 797f3dd1de8fd8c0eafbd1c9fdb172abd9ff840a && popd #0.3.0
|
||||
pip install packaging
|
||||
pushd axolotl && pip install -e '.[flash-attn,deepspeed]' && popd
|
||||
|
||||
# https://github.com/oobabooga/text-generation-webui/issues/4238
|
||||
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.3.0/flash_attn-2.3.0+cu117torch2.0cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
|
||||
```
|
||||
|
||||
Configure accelerate:
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
## Fine-tuning
|
||||
|
||||
We will need to configure axolotl. In this example is provided a file to use `axolotl.yaml` that uses openllama-3b for fine-tuning. Copy the `axolotl.yaml` file and edit it to your needs. The dataset needs to be next to it as `dataset.json`. The format used is `completion` which is a list of JSON objects with a `text` field with the full text to train the LLM with.
|
||||
|
||||
If you have a big dataset, you can pre-tokenize it to speedup the fine-tuning process:
|
||||
|
||||
```bash
|
||||
# Optional pre-tokenize (run only if big dataset)
|
||||
python -m axolotl.cli.preprocess axolotl.yaml
|
||||
```
|
||||
|
||||
Now we are ready to start the fine-tuning process:
|
||||
```bash
|
||||
# Fine-tune
|
||||
accelerate launch -m axolotl.cli.train axolotl.yaml
|
||||
```
|
||||
|
||||
After we have finished the fine-tuning, we merge the Lora base with the model:
|
||||
```bash
|
||||
# Merge lora
|
||||
python3 -m axolotl.cli.merge_lora axolotl.yaml --lora_model_dir="./qlora-out" --load_in_8bit=False --load_in_4bit=False
|
||||
```
|
||||
|
||||
And we convert it to the gguf format that LocalAI can consume:
|
||||
|
||||
```bash
|
||||
|
||||
# Convert to gguf
|
||||
git clone https://github.com/ggerganov/llama.cpp.git
|
||||
pushd llama.cpp && make LLAMA_CUBLAS=1 && popd
|
||||
|
||||
# We need to convert the pytorch model into ggml for quantization
|
||||
# It crates 'ggml-model-f16.bin' in the 'merged' directory.
|
||||
pushd llama.cpp && python convert.py --outtype f16 \
|
||||
../qlora-out/merged/pytorch_model-00001-of-00002.bin && popd
|
||||
|
||||
# Start off by making a basic q4_0 4-bit quantization.
|
||||
# It's important to have 'ggml' in the name of the quant for some
|
||||
# software to recognize it's file format.
|
||||
pushd llama.cpp && ./quantize ../qlora-out/merged/ggml-model-f16.gguf \
|
||||
../custom-model-q4_0.bin q4_0
|
||||
|
||||
```
|
||||
|
||||
Now you should have ended up with a `custom-model-q4_0.bin` file that you can copy in the LocalAI models directory and use it with LocalAI.
|
||||
63
examples/e2e-fine-tuning/axolotl.yaml
Normal file
63
examples/e2e-fine-tuning/axolotl.yaml
Normal file
@ -0,0 +1,63 @@
|
||||
|
||||
base_model: openlm-research/open_llama_3b_v2
|
||||
model_type: LlamaForCausalLM
|
||||
tokenizer_type: LlamaTokenizer
|
||||
load_in_8bit: false
|
||||
load_in_4bit: true
|
||||
strict: false
|
||||
push_dataset_to_hub: false
|
||||
datasets:
|
||||
- path: dataset.json
|
||||
ds_type: json
|
||||
type: completion
|
||||
dataset_prepared_path:
|
||||
val_set_size: 0.05
|
||||
adapter: qlora
|
||||
lora_model_dir:
|
||||
sequence_len: 1024
|
||||
sample_packing: true
|
||||
lora_r: 8
|
||||
lora_alpha: 32
|
||||
lora_dropout: 0.05
|
||||
lora_target_modules:
|
||||
lora_target_linear: true
|
||||
lora_fan_in_fan_out:
|
||||
wandb_project:
|
||||
wandb_entity:
|
||||
wandb_watch:
|
||||
wandb_run_id:
|
||||
wandb_log_model:
|
||||
output_dir: ./qlora-out
|
||||
gradient_accumulation_steps: 1
|
||||
micro_batch_size: 2
|
||||
num_epochs: 4
|
||||
optimizer: paged_adamw_32bit
|
||||
torchdistx_path:
|
||||
lr_scheduler: cosine
|
||||
learning_rate: 0.0002
|
||||
train_on_inputs: false
|
||||
group_by_length: false
|
||||
bf16: false
|
||||
fp16: true
|
||||
tf32: false
|
||||
gradient_checkpointing: true
|
||||
early_stopping_patience:
|
||||
resume_from_checkpoint:
|
||||
local_rank:
|
||||
logging_steps: 1
|
||||
xformers_attention:
|
||||
flash_attention: false
|
||||
gptq_groupsize:
|
||||
gptq_model_v1:
|
||||
warmup_steps: 20
|
||||
eval_steps: 0.05
|
||||
save_steps:
|
||||
debug:
|
||||
deepspeed:
|
||||
weight_decay: 0.1
|
||||
fsdp:
|
||||
fsdp_config:
|
||||
special_tokens:
|
||||
bos_token: "<s>"
|
||||
eos_token: "</s>"
|
||||
unk_token: "<unk>"
|
||||
1655
examples/e2e-fine-tuning/notebook.ipynb
Normal file
1655
examples/e2e-fine-tuning/notebook.ipynb
Normal file
File diff suppressed because it is too large
Load Diff
Loading…
x
Reference in New Issue
Block a user